Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Tato funkce je ve verzi Public Preview. Informace o způsobilosti a povolení najdete v tématu Povolení bezserverového výpočetního prostředí.
Tento článek vysvětluje, jak používat bezserverové výpočetní prostředky pro poznámkové bloky. Informace o používání bezserverových výpočetních prostředků pro pracovní postupy najdete v tématu Spuštění úlohy Azure Databricks s bezserverovými výpočetními prostředky pro pracovní postupy.
Informace o cenách najdete v tématu o cenách Databricks.
Požadavky
Pro katalog Unity musí být povolený váš pracovní prostor.
Váš pracovní prostor musí být v podporované oblasti. Viz oblasti Azure Databricks.
Váš účet musí být povolený pro výpočetní prostředky bez serveru. Viz Povolení výpočetních prostředků bez serveru.
Připojení poznámkového bloku k bezserverovým výpočetním prostředkům
Pokud je váš pracovní prostor povolený pro bezserverové interaktivní výpočetní prostředky, mají všichni uživatelé v pracovním prostoru přístup k bezserverovému výpočetnímu prostředí pro poznámkové bloky. Nejsou vyžadována žádná další oprávnění.
Pokud se chcete připojit k bezserverovému výpočetnímu prostředí, klikněte v poznámkovém bloku na rozevírací nabídku Připojit a vyberte Bezserverový. U nových poznámkových bloků se připojené výpočetní prostředky automaticky po spuštění kódu automaticky nastaví na bezserverové, pokud nebyl vybrán žádný jiný prostředek.
Instalace závislostí poznámkového bloku
Závislosti Pythonu pro bezserverové poznámkové bloky můžete nainstalovat pomocí bočního panelu Prostředí , kde můžete upravovat, zobrazovat a exportovat požadavky na knihovnu pro poznámkový blok. Tyto závislosti je možné přidat pomocí základního prostředí nebo jednotlivě.
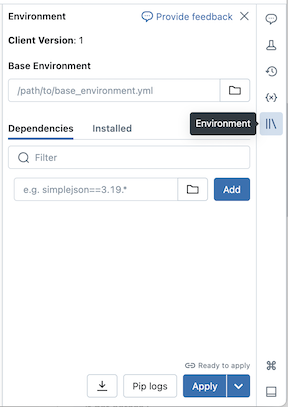
Konfigurace základního prostředí
Základní prostředí je soubor YAML uložený jako soubor pracovního prostoru nebo na svazku katalogu Unity, který určuje další závislosti prostředí. Základní prostředí je možné sdílet mezi poznámkovými bloky. Konfigurace základního prostředí:
Vytvořte soubor YAML, který definuje nastavení pro virtuální prostředí Pythonu. Následující příklad YAML, který je založen na specifikaci prostředí projektů MLflow, definuje základní prostředí s několika závislostmi knihovny:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Nahrajte soubor YAML jako soubor pracovního prostoru nebo do svazku katalogu Unity. Viz Import souboru nebo nahrání souborů do svazku katalogu Unity.
Napravo od poznámkového bloku kliknutím na
 tlačítko rozbalte panel Prostředí . Toto tlačítko se zobrazí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.
tlačítko rozbalte panel Prostředí . Toto tlačítko se zobrazí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.Do pole Základní prostředí zadejte cestu nahraného souboru YAML nebo na něj přejděte a vyberte ho.
Klikněte na tlačítko Použit. Tím se nainstalují závislosti ve virtuálním prostředí poznámkového bloku a restartuje proces Pythonu.
Uživatelé mohou přepsat závislosti zadané v základním prostředí instalací závislostí jednotlivě.
Přidání závislostí jednotlivě
Závislosti můžete také nainstalovat do poznámkového bloku připojeného k bezserverovému výpočetnímu prostředí pomocí karty Závislosti na panelu Prostředí :
- Napravo od poznámkového bloku kliknutím na tlačítko rozbalte panel Prostředí . Toto tlačítko se zobrazí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.
- V části Závislosti klepněte na tlačítko Přidat závislost a zadejte cestu závislosti knihovny do pole. Závislost můžete zadat v libovolném formátu, který je platný v souboru requirements.txt .
- Klikněte na tlačítko Použit. Tím se nainstalují závislosti ve virtuálním prostředí poznámkového bloku a restartuje proces Pythonu.
Poznámka:
Úloha využívající bezserverové výpočetní prostředky před spuštěním kódu poznámkového bloku nainstaluje specifikaci prostředí poznámkového bloku. To znamená, že při plánování poznámkových bloků jako úloh není potřeba přidávat závislosti. Viz Konfigurace prostředí a závislostí poznámkového bloku.
Zobrazení nainstalovaných závislostí a protokolů pip
Chcete-li zobrazit nainstalované závislosti, klepněte na tlačítko Nainstalováno na bočním panelu Prostředí poznámkového bloku. Protokoly instalace pipu pro prostředí poznámkového bloku jsou k dispozici také kliknutím na protokoly Pip v dolní části panelu.
Resetování prostředí
Pokud je poznámkový blok připojený k bezserverovému výpočetnímu prostředí, Databricks automaticky ukládá obsah virtuálního prostředí poznámkového bloku do mezipaměti. To znamená, že při otevření existujícího poznámkového bloku obvykle není nutné přeinstalovat závislosti Pythonu zadané na panelu prostředí , i když byl odpojen z důvodu nečinnosti.
Ukládání do mezipaměti virtuálního prostředí Pythonu platí také pro úlohy. To znamená, že následná spuštění úloh jsou rychlejší, protože požadované závislosti jsou již k dispozici.
Poznámka:
Pokud změníte implementaci vlastního balíčku Pythonu, který se používá v úloze na bezserverové verzi, musíte také aktualizovat její číslo verze, aby úlohy vyzvedly nejnovější implementaci.
Pokud chcete vymazat mezipaměť prostředí a provést novou instalaci závislostí zadaných na panelu Prostředí poznámkového bloku připojeného k bezserverovému výpočetnímu prostředí, klikněte na šipku vedle možnosti Použít a potom klikněte na tlačítko Obnovit prostředí.
Poznámka:
Pokud instalujete balíčky, které přeruší nebo změní základní poznámkový blok nebo prostředí Apache Spark, resetujte virtuální prostředí. Odpojení poznámkového bloku od bezserverového výpočetního prostředí a jeho opětovné připojení nemusí nutně vymazat celou mezipaměť prostředí.
Zobrazení přehledů dotazů
Bezserverové výpočetní prostředky pro poznámkové bloky a pracovní postupy používají k vyhodnocení výkonu spouštění Sparku přehledy dotazů. Po spuštění buňky v poznámkovém bloku můžete zobrazit přehledy související s dotazy SQL a Pythonu kliknutím na odkaz Zobrazit výkon .
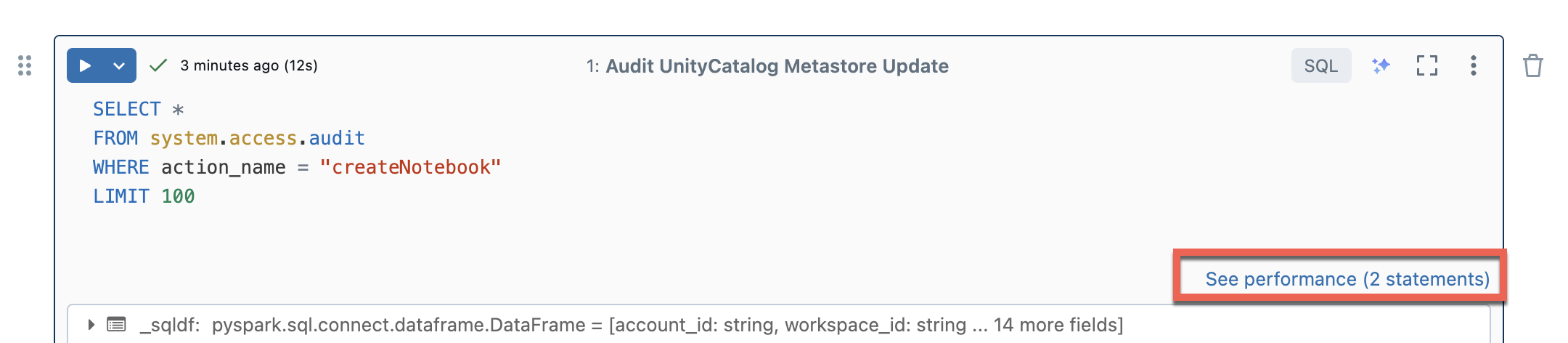
Kliknutím na některý z příkazů Sparku zobrazíte metriky dotazů. Odtud můžete kliknout na Zobrazit profil dotazu a zobrazit vizualizaci provádění dotazu. Další informace o profilech dotazů najdete v tématu Profil dotazu.
Poznámka:
Pokud chcete zobrazit přehledy výkonu pro spuštění úloh, podívejte se na zobrazení přehledů dotazů spuštění úlohy.
Historie dotazů
Všechny dotazy spouštěné na bezserverových výpočetních prostředcích se také zaznamenají na stránce historie dotazů vašeho pracovního prostoru. Informace o historii dotazů najdete v tématu Historie dotazů.
Omezení přehledů dotazů
- Profil dotazu je k dispozici pouze po ukončení provádění dotazu.
- Metriky se aktualizují živě, i když se profil dotazu během provádění nezobrazuje.
- Probírá se jenom následující stav dotazu: RUNNING, CANCELED, FAILED, FINISHED.
- Spuštěné dotazy nelze zrušit ze stránky historie dotazů. Dají se zrušit v poznámkových blocích nebo úlohách.
- Podrobné metriky nejsou k dispozici.
- Stažení profilu dotazu není k dispozici.
- Přístup k uživatelskému rozhraní Sparku není k dispozici.
- Text příkazu obsahuje pouze poslední řádek, který byl spuštěn. Před tímto řádkem však může být několik řádků, které byly spuštěny jako součást stejného příkazu.
Omezení
Seznam omezení najdete v tématu Omezení bezserverového výpočetního prostředí.