Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek vysvětluje, jak používat bezserverové výpočetní prostředky pro poznámkové bloky. Informace o používání bezserverových výpočetních prostředků pro úlohy najdete v tématu Spouštění úloh Lakeflow s bezserverovými výpočetními prostředky pro pracovní postupy.
Informace o cenách používání bezserverových výpočetních prostředků v poznámkových blocích najdete v tématu Ceny Databricks.
Požadavky
- Pro katalog Unity musí být povolený váš pracovní prostor.
- Váš pracovní prostor musí být v podporované oblasti pro výpočetní prostředky bez serveru.
Připojte notebook k bezserverovým výpočetním prostředkům
Pokud je vaše pracoviště povoleno pro bezserverové interaktivní výpočty, mají všichni uživatelé v pracovišti přístup k bezserverovým výpočtům pro notebooky. Nejsou vyžadována žádná další oprávnění.
Pokud se chcete připojit k bezserverovým výpočtům, klikněte v poznámkovém bloku na rozevírací nabídku výpočtů a vyberte Serverless. U nových poznámkových bloků se připojené výpočetní zdroje automaticky nastaví na bezserverové po spuštění kódu, pokud nebyl vybrán žádný jiný prostředek.
Zobrazení přehledů dotazů
Bezserverové výpočetní prostředky pro poznámkové bloky a úlohy používají přehledy dotazů k vyhodnocení výkonu spouštění Sparku. Po spuštění buňky v poznámkovém bloku můžete zobrazit přehledy související s dotazy SQL a Pythonu kliknutím na odkaz Zobrazit výkon .
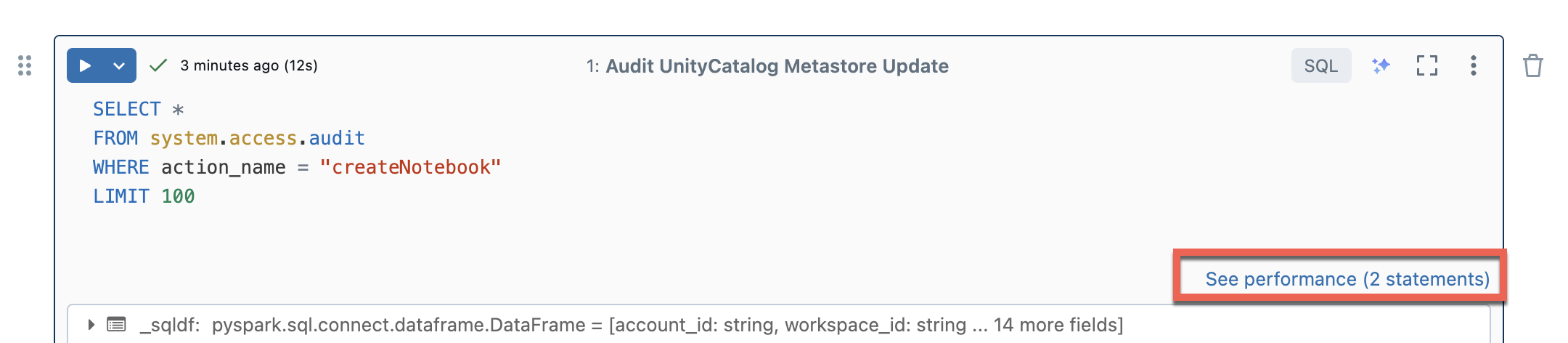
Kliknutím na některý z příkazů Sparku zobrazíte metriky dotazů. Odtud můžete kliknout na Zobrazit profil dotazu a zobrazit vizualizaci provádění dotazu. Další informace o profilech dotazů najdete v tématu Profil dotazu.
Poznámka:
Pokud chcete zobrazit přehledy výkonu pro běhy úloh, viz přehledy dotazů běhů úlohy.
Historie dotazů
Všechny dotazy spouštěné na bezserverových výpočetních prostředcích se také zaznamenají na stránce historie dotazů vašeho pracovního prostoru. Informace o historii dotazů najdete v tématu Historie dotazů.
Omezení přehledů dotazů
- Metriky se během provádění dotazů aktualizují živě, ale úplný profil dotazu je k dispozici až po ukončení dotazu.
- Pokryty jsou pouze následující stavy dotazů: Running, Canceled, Failed, Finished.
- Spuštěné dotazy nelze zrušit ze stránky historie dotazů. Dají se zrušit v poznámkových blocích nebo úlohách.
- Podrobné metriky nejsou k dispozici.
- Stažení profilu dotazu není k dispozici.
- Přístup k uživatelskému rozhraní Sparku není k dispozici.
- Text příkazu obsahuje pouze poslední řádek, který byl spuštěn. Před tímto řádkem však může být několik řádků, které byly spuštěny jako součást stejného příkazu.
Bezserverová přespendová ochrana
Pro řízení dlouhotrvajících dotazů mají bezserverové poznámkové bloky výchozí časový limit spuštění 2,5 hodiny (9 000 sekund). Dotazy, které překračují časový limit, se zruší.
Konfigurace časového limitu pro všechny poznámkové bloky v pracovním prostoru
Správci pracovního prostoru můžou změnit výchozí časový limit provádění pro bezserverové poznámkové bloky. V nastavení správce pracovního prostoru přejděte na Nastavení>Výpočetní prostředky a v části Bezserverová interaktivní konfigurace nastavení časového limitu bezserverového interaktivního spuštění . Změny se projeví přibližně za 5 minut.
Přepsat časový limit pro jeden notebook
Chcete-li pro konkrétní poznámkový blok přepsat výchozí nastavení pracovního prostoru, nastavte v poznámkovém bloku hodnotu spark.databricks.execution.timeout. Hodnota pro jednotlivé poznámkové bloky má přednost před nastavením pracovního prostoru. Viz Konfigurace vlastností Sparku pro bezserverové poznámkové bloky a úlohy.