Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Jemně odstupňované řízení přístupu umožňuje omezit přístup k určitým datům pomocí zobrazení, filtrů řádků a masek sloupců. Tato stránka vysvětluje, jak se výpočetní prostředky bez serveru používají k vynucení jemně odstupňovaného řízení přístupu u vyhrazených výpočetních prostředků.
Poznámka:
Vyhrazené výpočetní prostředky jsou pro všechny účely nebo úlohy nakonfigurované s režimem vyhrazeného přístupu (dříve režim přístupu jednoho uživatele). Viz režimy přístupu.
Požadavky
Použijte vyhrazené výpočetní prostředky k dotazování zobrazení nebo tabulky s jemně detailními ovládacími prvky přístupu:
- Vyhrazený výpočetní prostředek musí být ve službě Databricks Runtime 15.4 LTS nebo vyšší.
- Pracovní prostor musí být povolený pro bezserverové výpočetní prostředky.
Pokud váš vyhrazený výpočetní prostředek a pracovní prostor splňují tyto požadavky, spustí se filtrování dat automaticky.
Jak funguje filtrování dat na vyhrazených výpočetních prostředcích
Kdykoli dotaz přistupuje k databázovému objektu s jemně odstupňovanými ovládacími prvky přístupu, vyhrazený výpočetní prostředek předá dotaz do bezserverového výpočetního prostředí vašeho pracovního prostoru, aby provedl filtrování dat. Filtrovaná data se pak přenášejí mezi bezserverovým a vyhrazeným výpočetním prostředím pomocí dočasných souborů v interním cloudovém úložišti pracovního prostoru.
Azure Databricks přenáší filtrovaná data pomocí cloudového načtení, což je funkce, která zapisuje dočasné sady výsledků do interního úložiště pracovních prostorů ( kořen DBFS vašeho pracovního prostoru). Azure Databricks automaticky shromažďuje tyto soubory, označí je pro odstranění po 24 hodinách a trvale je odstraní po dalších 24 hodinách.
Tato funkce se vztahuje na následující databázové objekty:
- dynamická zobrazení
- Tabulky s filtry řádků nebo maskami sloupců
-
Zobrazení vytvořená na tabulkách, ke kterým uživatel nemá
SELECTprivilegia - materializovaná zobrazení
- tabulky streamování
V následujícím diagramu má uživatel SELECT oprávnění pro table_1, view_2 a table_w_rls, které mají použité filtry řádků. Uživatel nemá oprávnění SELECT na table_2, na které odkazuje view_2.

Dotaz na table_1 zpracovává výhradně vyhrazený výpočetní prostředek, protože se nevyžaduje žádné filtrování. Dotazy týkající se view_2 a table_w_rls vyžadují filtrování dat, aby se vrátila data, ke kterým má uživatel přístup. Tyto dotazy zpracovává funkce filtrování dat na bezserverových výpočetních prostředcích.
Podpora operací zápisu
V Databricks Runtime 16.3 a novějších můžete zapisovat do tabulek s použitými filtry řádků nebo maskami sloupců pomocí těchto možností:
- Příkaz MERGE INTO SQL, který můžete použít k dosažení
INSERT,UPDATEaDELETEfunkce. - Operace sloučení Delta.
- Rozhraní
DataFrame.write.mode("append")API.
K dosažení INSERT, UPDATE a DELETE funkčnosti můžete použít pracovní tabulku a příkaz MERGE INTO s klauzulí WHEN MATCHED a WHEN NOT MATCHED.
Následuje příklad použití UPDATE s MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
Následuje příklad použití INSERT s MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
Následuje příklad odstranění pomocí MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Podpora DDL, SHOW, DESCRIBE a dalších příkazů
Ve službě Databricks Runtime 17.1 a novějších můžete použít následující příkazy v kombinaci s jemně odstupňovanými objekty řízenými přístupem na vyhrazených výpočetních prostředcích:
- Příkazy DDL
- Příkazy SHOW
- Příkazy DESCRIBE
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 a novější)
V případě potřeby se tyto příkazy automaticky spouštějí na bezserverových výpočetních prostředcích.
Některé příkazy nejsou podporovány, včetně VACCUM, RESTOREa .REORG TABLE
Náklady na výpočetní prostředky bez serveru
Zákazníci se účtují za výpočetní prostředky bez serveru, které provádějí operace filtrování dat. Informace o cenách najdete v tématu Úrovně platformy a doplňky.
Uživatelé s přístupem mohou dotazovat system.billing.usage tabulku a zjistit, kolik jim bylo naúčtováno. Například následující dotaz rozdělí náklady na výpočetní prostředky podle uživatele:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Zobrazení výkonu dotazů při zapojení filtrování dat
Uživatelské rozhraní Sparku pro vyhrazené výpočetní prostředky zobrazuje metriky, které můžete použít k pochopení výkonu dotazů. Pro každý dotaz, který spustíte na výpočetním prostředku, zobrazí karta SQL/Dataframe reprezentaci grafu dotazu. Pokud byl dotaz zapojen do filtrování dat, uživatelské rozhraní zobrazí uzel operátoru RemoteSparkConnectScan v dolní části grafu. Tento uzel zobrazuje metriky, které můžete použít k prozkoumání výkonu dotazů. Viz Zobrazení informací o výpočetních prostředcích v uživatelském rozhraní Sparku.
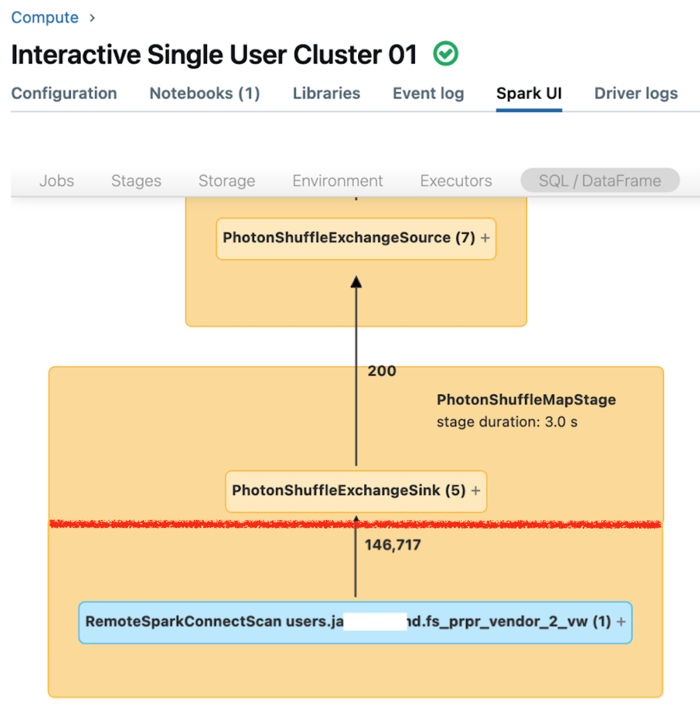
Rozbalte uzel operátoru RemoteSparkConnectScan a zobrazte metriky, které řeší například následující otázky:
- Kolik času trvalo filtrování dat? Zobrazit "celkový čas vzdáleného spuštění".
- Kolik řádků zůstalo po filtrování dat? Zobrazit "výstup řádků".
- Kolik dat (v bajtech) bylo vráceno po filtrování dat? Zobrazit "velikost výstupu řádků".
- Kolik datových souborů bylo prořezáno podle oddílů a nemuselo se číst z úložiště? Zobrazit "Soubory vyřazené" a "Velikost souborů vyříznutých".
- Kolik datových souborů nebylo možné vyříznout a muselo být načteno z úložiště? Zobrazení "Čtení souborů" a "Velikost přečtených souborů".
- Z souborů, které se musely číst, kolik už bylo v mezipaměti? Zobrazit "Velikost úspěšných přístupů do mezipaměti" a "Velikost zmeškaných přístupů do mezipaměti".
Omezení
U streamovaných tabulek se podporují pouze dávkové čtení. Tabulky s filtry řádků nebo maskami sloupců nepodporují úlohy streamování na vyhrazených výpočetních prostředcích.
Výchozí katalog (
spark.sql.catalog.spark_catalog) nelze změnit.spark.catalog.listColumns()se nepodporuje. Místo toho můžete použítSHOW COLUMNS INk výpisu názvů sloupců,SHOW PARTITIONSk výpisu sloupců oddílů neboDESCRIBE TABLE [EXTENDED [AS JSON]]k získání podrobného popisu tabulky.V Databricks Runtime 16.2 a níže neexistuje podpora operací zápisu nebo aktualizace tabulek u tabulek, které mají použité filtry řádků nebo masky sloupců.
Konkrétně se nepodporují operace DML, například
INSERT,DELETE,UPDATEREFRESH TABLE, aMERGE, . Z těchto tabulek můžete číst pouze (SELECT).V Databricks Runtime 16.3 a novějších zápis operací tabulek, jako
INSERT,DELETE, aUPDATEnejsou podporované, ale lze je provést pomocíMERGE, který je podporován.Při použití
DeltaTable.forName()neboDeltaTable.forPath()na vyhrazených výpočetních prostředcích s tabulkami s podporou FGAC se podporují pouzemerge()operace atoDF()operace. Pro jiné operace DeltaTable použijte místo toho odpovídající příkazy SQL. Například místohistory()použijteDESCRIBE HISTORYa místoclone()použijteSHALLOW CLONEneboDEEP CLONE.Ve verzi Databricks Runtime 16.2 a nižší jsou samo-spojení při použití filtrování dat ve výchozím nastavení blokována, protože tyto dotazy mohou vracet různé snímky stejné vzdálené tabulky. Tyto dotazy ale můžete povolit nastavením
spark.databricks.remoteFiltering.blockSelfJoinsnafalsena výpočetních prostředcích, na kterých tyto příkazy spouštíte.V Databricks Runtime 16.3 a novějších se snímky automaticky synchronizují mezi vyhrazenými a bezserverovými výpočetními prostředky. Kvůli této synchronizaci vrací dotazy samoobslužného spojení, které používají funkce filtrování dat, identické snímky a jsou ve výchozím nastavení povolené. Výjimky jsou materializovaná zobrazení a všechna zobrazení, materializovaná zobrazení a streamované tabulky sdílené pomocí Delta Sharing. U těchto objektů jsou ve výchozím nastavení zablokovaná samospojení, ale tyto dotazy můžete povolit nastavením
spark.databricks.remoteFiltering.blockSelfJoinsna hodnotu false na výpočetním zdroji, na kterém tyto příkazy spouštíte.Pokud povolíte dotazy s vlastním spojením pro materializovaná zobrazení a všechna zobrazení, materializovaná zobrazení a streamované tabulky, musíte zajistit, aby do objektů, které jsou spojené, nebyly souběžné zápisy.
- V Docker obrazech není podpora.
- Není poskytována podpora při používání služby Databricks Container Services.
- Pokud chcete povolit jemně odstupňované řízení přístupu na vyhrazených výpočetních prostředcích, musíte otevřít porty 8443 a 8444. Viz Nasazení Azure Databricks ve virtuální síti Azure (injektáž virtuální sítě).