Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
CI/CD (kontinuální integrace a průběžné doručování) odkazuje na automatizovaný proces pro vývoj, nasazování, monitorování a údržbu vašich aplikací. Díky automatizaci sestavování, testování a nasazení kódu můžou vývojové týmy dodávat vydané verze častěji a spolehlivěji než ruční procesy v mnoha týmech datových inženýrů a datových věd. CI/CD pro strojové učení spojuje techniky MLOps, DataOps, ModelOps a DevOps.
Tento článek popisuje, jak Databricks podporuje CI/CD pro řešení strojového učení. V aplikacích strojového učení je CI/CD důležité nejen pro kódové zdroje, ale také se aplikuje na datové pipeline, včetně vstupních dat a výsledků generovaných modelem.
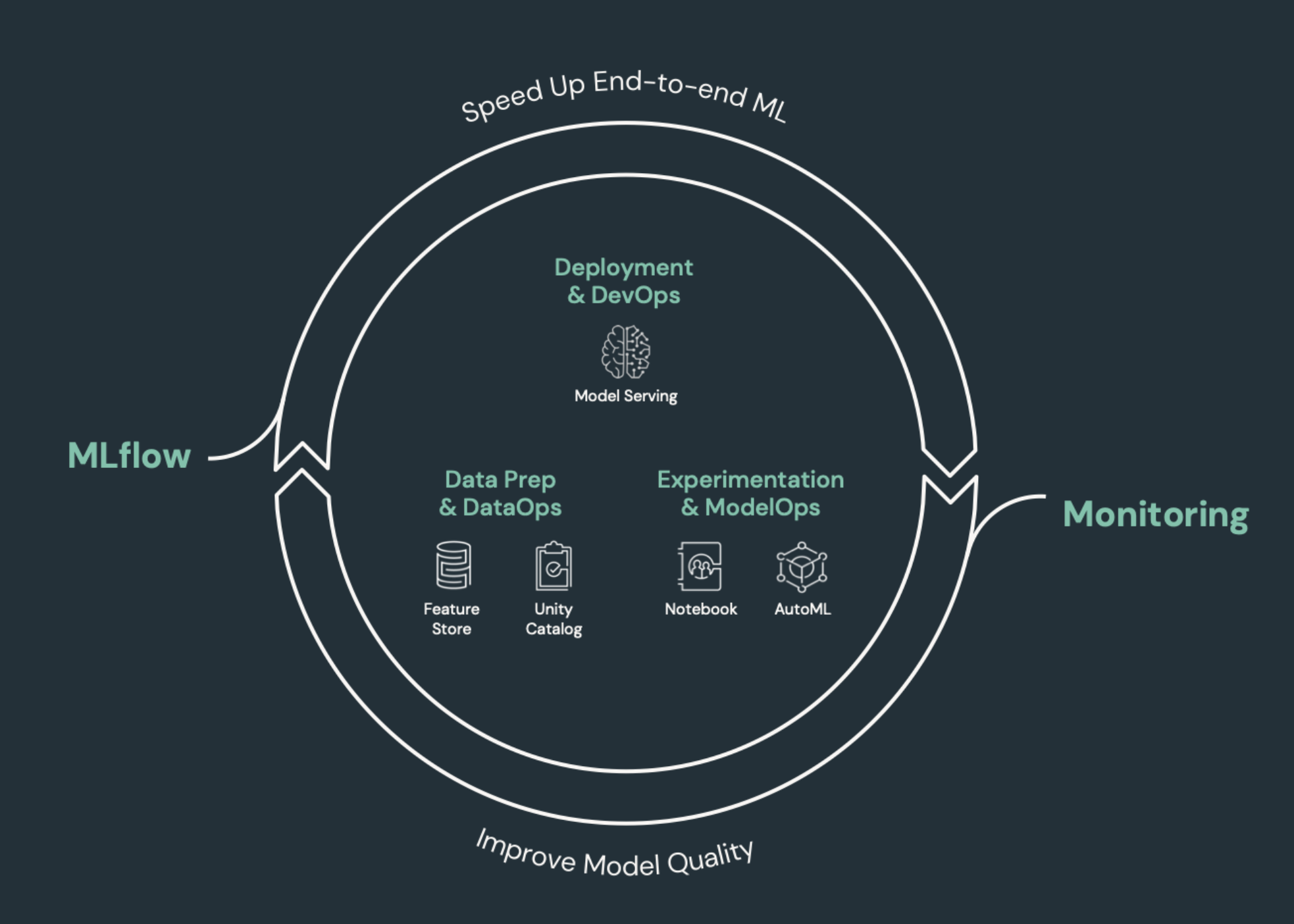
Prvky strojového učení, které potřebují CI/CD
Jednou z výzev vývoje STROJOVÉho učení je to, že různé týmy vlastní různé části procesu. Týmy můžou spoléhat na různé nástroje a mít různé plány vydávání verzí. Azure Databricks poskytuje jednu sjednocenou platformu dat a strojového učení s integrovanými nástroji, které zlepšují efektivitu týmů a zajišťují konzistenci a opakovatelnost kanálů dat a ML.
Obecně platí, že úlohy strojového učení by se měly sledovat v automatizovaném pracovním postupu CI/CD:
- Trénovací data, včetně kvality dat, změn schématu a změn distribuce.
- Vstupní datové kanály
- Kód pro trénování, ověřování a obsluhu modelu
- Predikce modelu a výkon
Integrace Databricks do procesů CI/CD
MLOps, DataOps, ModelOps a DevOps odkazují na integraci vývojových procesů s "operacemi", díky čemuž jsou procesy a infrastruktura předvídatelné a spolehlivé. Tato sada článků popisuje, jak integrovat principy operací (ops) do pracovních postupů ML na platformě Databricks.
Databricks zahrnuje všechny komponenty potřebné pro životní cyklus ML, včetně nástrojů pro sestavení "konfigurace jako kódu", aby se zajistila reprodukovatelnost a "infrastruktura jako kód" pro automatizaci zřizování cloudových služeb. Zahrnuje také služby protokolování a upozorňování, které vám pomůžou odhalit a řešit problémy, když k nim dojde.
DataOps: Spolehlivá a zabezpečená data
Vhodné modely ML závisí na spolehlivých datových kanálech a infrastruktuře. S platformou Databricks Data Intelligence Platform je celý datový kanál od ingestování dat až po výstupy z obsluhované modelu na jedné platformě a používá stejnou sadu nástrojů, která usnadňuje produktivitu, reprodukovatelnost, sdílení a řešení potíží.

Úlohy a nástroje DataOps v Databricks
V tabulce jsou uvedené běžné úlohy a nástroje DataOps v Databricks:
| Úloha DataOps | Nástroj v Databricks |
|---|---|
| Ingestování a transformace dat | Auto Loader a Apache Spark |
| Sledování změn dat včetně správy verzí a rodokmenu | Tabulky Delta |
| Vytváření, správa a monitorování kanálů zpracování dat | Deklarativní kanály Lakeflow Spark |
| Zajištění zabezpečení a zásad správného řízení dat | Katalog Unity |
| Průzkumné analýzy dat a řídicí panely | Databricks SQL, řídicí panely a poznámkové bloky Databricks |
| Obecné kódování | Databricks SQL a poznámkové bloky Databricks |
| Plánování datových kanálů | Úlohy Lakeflow |
| Automatizace obecných pracovních postupů | Úlohy Lakeflow |
| Vytváření, ukládání, správa a zjišťování funkcí pro trénování modelů | Úložiště funkcí Databricks |
| Monitorování dat | Monitorování kvality dat |
ModelOps: Vývoj a životní cyklus modelů
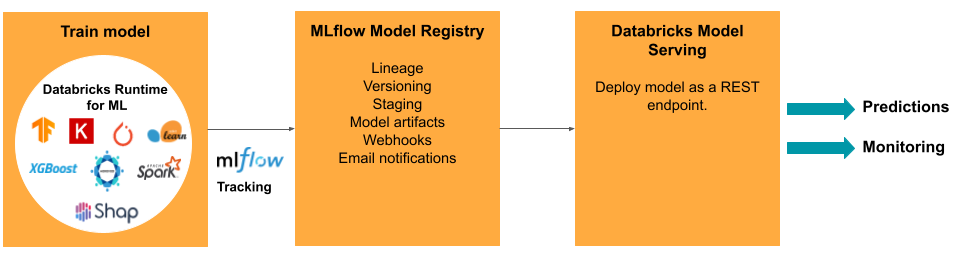
Vývoj modelu vyžaduje řadu experimentů a způsob, jak sledovat a porovnat podmínky a výsledky těchto experimentů. Platforma Databricks Data Intelligence zahrnuje MLflow pro sledování vývoje modelů a registr modelů MLflow ke správě životního cyklu modelu, včetně přípravy, obsluhy a ukládání artefaktů modelu.
Po uvolnění modelu do produkčního prostředí může dojít ke změně mnoha věcí, které můžou ovlivnit jeho výkon. Kromě monitorování výkonu předpovědi modelu byste měli také monitorovat vstupní data o změnách kvality nebo statistických charakteristik, které by mohly vyžadovat opětovné trénování modelu.
Úlohy a nástroje ModelOps v Databricks
V tabulce jsou uvedené běžné úlohy a nástroje ModelOps, které poskytuje Databricks:
| Úloha ModelOps | Nástroj v Databricks |
|---|---|
| Sledování vývoje modelů | Sledování modelů MLflow |
| Správa životního cyklu modelu | Modely v katalogu Unity |
| Správa verzí kódu modelu a sdílení | Složky Gitu pro Databricks |
| Vývoj modelů bez kódu | AutoML |
| Monitorování modelů | Profilace dat |
DevOps: Výroba a automatizace
Platforma Databricks podporuje modely ML v produkčním prostředí s následujícími funkcemi:
- Kompletní data a rodokmen modelů: Od modelů v produkčním prostředí zpět ke zdroji nezpracovaných dat na stejné platformě.
- Obsluha modelu na úrovni produkce: Automaticky vertikálně navyšuje nebo snižuje kapacitu na základě vašich obchodních potřeb.
- Úlohy: Automatizuje úlohy a vytváří naplánované pracovní postupy strojového učení.
- Složky Gitu: Správa verzí kódu a sdílení z pracovního prostoru, pomáhá týmům také dodržovat osvědčené postupy softwarového inženýrství.
- Sady prostředků Databricks: Automatizuje vytváření a nasazování prostředků Databricks, jako jsou úlohy, registrované modely a obsluha koncových bodů.
- Poskytovatel Databricks Terraform: Automatizuje infrastrukturu nasazení napříč cloudy pro úlohy odvozování ML, obsluhu koncových bodů a úlohy featurizace.
Obsluha modelu
Pro nasazení modelů do produkčního prostředí MLflow proces výrazně zjednodušuje a poskytuje jednoklikové nasazení jako dávkovou úlohu pro velké objemy dat nebo jako koncový bod REST v clusteru automatického škálování. Integrace úložiště funkcí Databricks s MLflow také zajišťuje konzistenci funkcí pro trénování a obsluhu; Modely MLflow také můžou automaticky vyhledávat funkce z úložiště funkcí, a to i kvůli nízké latenci online obsluhy.
Platforma Databricks podporuje řadu možností nasazení modelu:
- Kód a kontejnery.
- Dávkové zpracování.
- Online obsluha s nízkou latencí
- Obsluha na zařízení nebo na edge computing zařízení.
- Více cloudů, například trénování modelu v jednom cloudu a jeho nasazení s druhým.
Další informace naleznete v tématu Mosaic AI Model Servírování.
Úlohy
Úlohy Lakeflow umožňují automatizovat a naplánovat libovolný typ úlohy od ETL do ML. Databricks také podporuje integraci s oblíbenými orchestrátory třetích stran, jako je Airflow.
Složky Gitu
Platforma Databricks zahrnuje podporu Gitu v pracovním prostoru, která týmům pomáhá dodržovat osvědčené postupy softwarového inženýrství prováděním operací Gitu prostřednictvím uživatelského rozhraní. Správci a technici DevOps můžou pomocí rozhraní API nastavit automatizaci pomocí svých oblíbených nástrojů CI/CD. Databricks podporuje jakýkoli typ nasazení Gitu, včetně privátních sítí.
Další informace o osvědčených postupech pro vývoj kódu pomocí složek Git Databricks najdete v pracovních postupech CI/CD s integrací Gitu a složkami Git Databricks a používání CI/CD. Tyto techniky společně s rozhraním Databricks REST API umožňují vytvářet automatizované procesy nasazení pomocí GitHub Actions, kanálů Azure DevOps nebo úloh Jenkinse.
Katalog Unity pro zásady správného řízení a zabezpečení
Platforma Databricks zahrnuje Katalog Unity, který správcům umožňuje nastavit podrobné řízení přístupu, zásady zabezpečení a zásady správného řízení pro všechna data a prostředky AI napříč Databricks.