Co jsou zásobníky MLOps?
Tento článek popisuje, jak mlOps Stacks umožňuje implementovat proces vývoje a nasazení jako kód v úložišti řízeném zdrojem. Popisuje také výhody vývoje modelů na platformě Databricks Data Intelligence, která je jedinou platformou, která sjednocuje každý krok procesu vývoje a nasazení modelu.
Zásobníky MLOps: Proces vývoje modelů jako kód
Díky zásobníkům MLOps se celý proces vývoje modelu implementuje, ukládá a sleduje jako kód v úložišti řízeném zdrojem. Automatizace procesu tímto způsobem usnadňuje opakovatelnější, předvídatelná a systematická nasazení a umožňuje integraci s procesem CI/CD. Reprezentace procesu vývoje modelu jako kódu umožňuje nasadit kód místo nasazení modelu. Nasazení kódu automatizuje schopnost sestavit model, což v případě potřeby výrazně usnadňuje přetrénování modelu.
Při vytváření projektu pomocí zásobníků MLOps definujete komponenty procesu vývoje a nasazení ML, jako jsou poznámkové bloky, které se mají použít pro přípravu funkcí, trénování, testování a nasazení, kanály pro trénování a testování, pracovní prostory, které se použijí pro jednotlivé fáze, a pracovní postupy CI/CD pomocí GitHub Actions nebo Azure DevOps pro automatizované testování a nasazení kódu.
Prostředí vytvořené službou MLOps Stacks implementuje pracovní postup MLOps, který doporučuje Databricks. Kód můžete přizpůsobit tak, aby vytvářel zásobníky tak, aby odpovídal procesům nebo požadavkům vaší organizace.
Komponenty zásobníků MLOps
Zásobník odkazuje na sadu nástrojů používaných ve vývojovém procesu. Výchozí zásobník MLOps využívá jednotnou platformu Databricks a používá následující nástroje:
| Komponenta | Nástroj v Databricks |
|---|---|
| Vývojový kód modelu ML | Poznámkové bloky Databricks, MLflow |
| Vývoj a správa funkcí | Příprava funkcí |
| Úložiště modelů ML | Modely v katalogu Unity |
| Obsluha modelu ML | Obsluhamodeluho |
| Infrastruktura jako kód | Sady prostředků Databricks |
| Orchestrator | Pracovní postupy Databricks |
| CI/CD | GitHub Actions, Azure DevOps |
| Monitorování výkonu dat a modelů | Monitorování Lakehouse |
Jak fungují zásobníky MLOps?
K vytvoření zásobníku MLOps použijete rozhraní příkazového řádku Databricks. Podrobné pokyny najdete v tématu Sady prostředků Databricks pro zásobníky MLOps.
Když zahájíte projekt MLOps Stacks, software vás provede zadáním podrobností konfigurace a pak vytvoří adresář obsahující soubory, které tvoří váš projekt. Tento adresář nebo zásobník implementuje produkční pracovní postup MLOps, který doporučuje Databricks. Komponenty zobrazené v diagramu jsou vytvořené za vás a k přidání vlastního kódu potřebujete jenom upravit soubory.
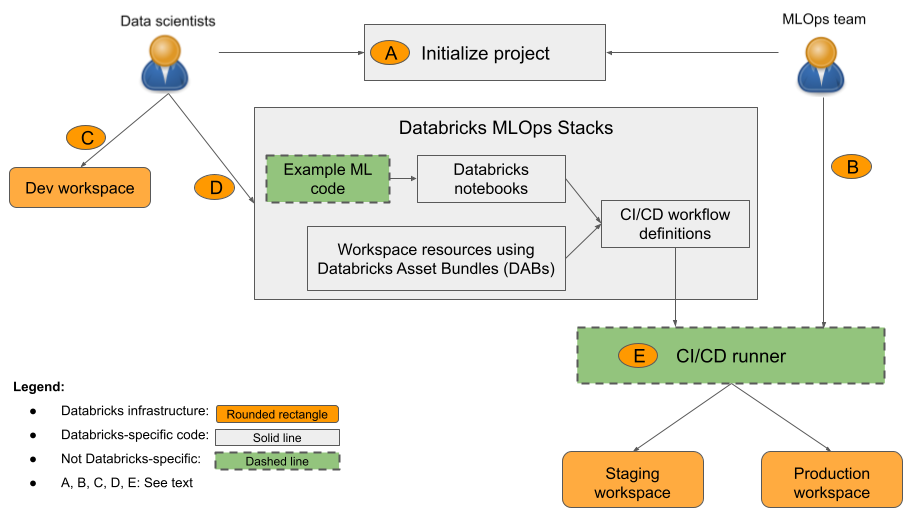
Vaše organizace může použít výchozí zásobník nebo ho podle potřeby přizpůsobit, aby přidala, odebrala nebo revidovala komponenty tak, aby vyhovovaly postupům vaší organizace. Podrobnosti najdete v souboru readme úložiště GitHub.
MlOps Stacks je navržen s modulární strukturou, která umožňuje různým týmům ML pracovat nezávisle na projektu a přitom dodržovat osvědčené postupy softwarového inženýrství a udržovat ci/CD na produkční úrovni. Produkční inženýři konfigurují infrastrukturu ML, která datovým vědcům umožňuje vyvíjet, testovat a nasazovat kanály a modely ML do produkčního prostředí.
Jak je znázorněno v diagramu, výchozí zásobník MLOps obsahuje následující tři komponenty:
- Kód ML. Zásobníky MLOps vytvoří sadu šablon pro projekt ML, včetně poznámkových bloků pro trénování, dávkové odvozování atd. Standardizovaná šablona umožňuje datovým vědcům rychle začít, sjednocuje strukturu projektů napříč týmy a vynucuje modularizovaný kód připravený k testování.
- Prostředky ML jako kód Zásobníky MLOps definují prostředky, jako jsou pracovní prostory a kanály pro úlohy, jako je trénování a dávkové odvozování. Prostředky jsou definované v sadách prostředků Databricks, které usnadňují testování, optimalizaci a správu verzí pro prostředí ML. Můžete například vyzkoušet větší typ instance pro automatické přetrénování modelu a změna se automaticky sleduje pro budoucí referenci.
- CI/CD. Pomocí GitHub Actions nebo Azure DevOps můžete testovat a nasazovat kód a prostředky ML a zajistit, aby se všechny produkční změny prováděly prostřednictvím automatizace a že se testovaný kód nasadí do prod.
Tok projektu MLOps
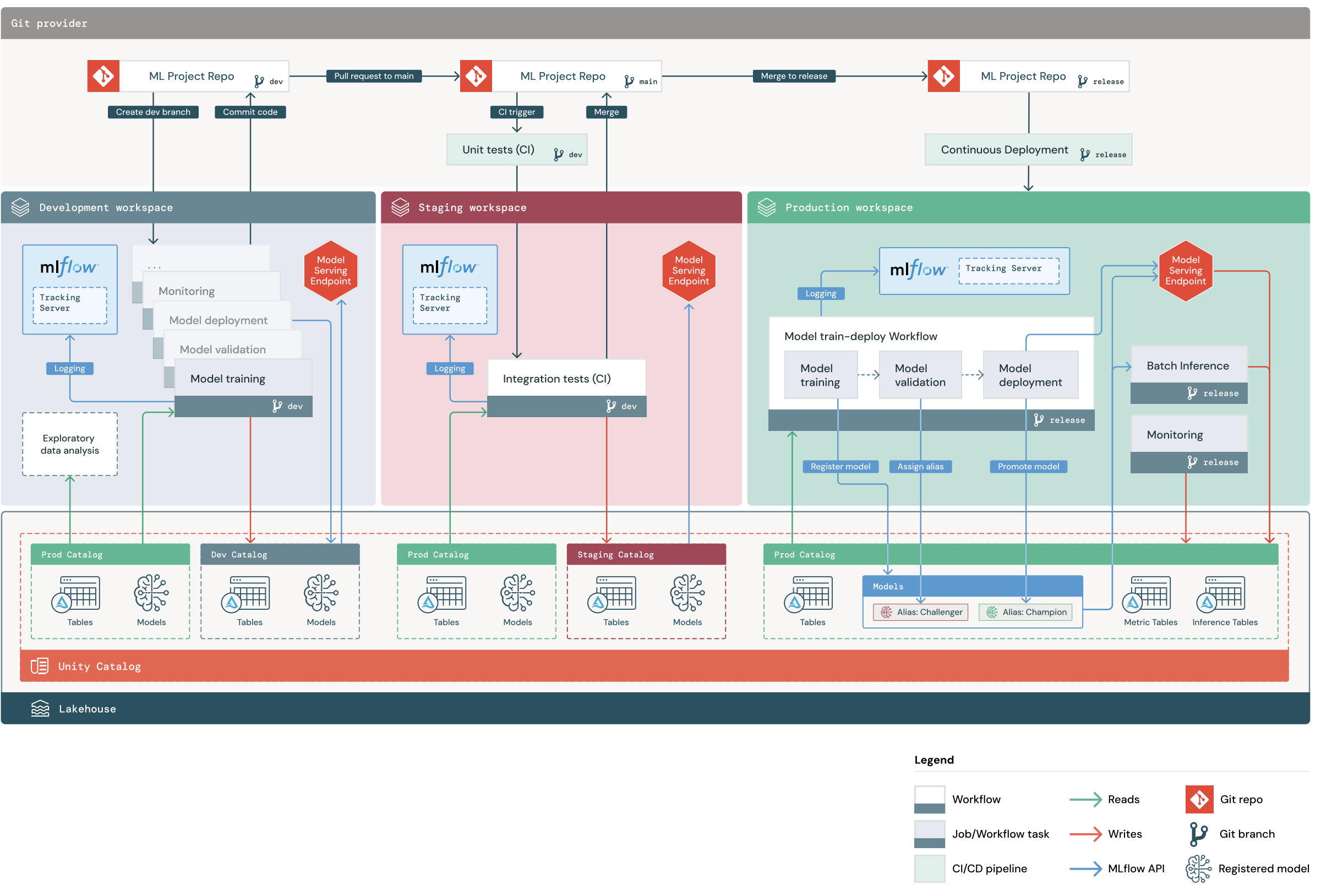
Výchozí projekt MLOps Stacks zahrnuje kanál ML s pracovními postupy CI/CD pro testování a nasazení automatizovaných trénování modelů a dávkových odvozování napříč pracovními prostory Databricks pro vývoj, přípravu a produkci. Zásobníky MLOps je možné konfigurovat, takže můžete upravit strukturu projektu tak, aby vyhovovala procesům vaší organizace.
Diagram znázorňuje proces, který je implementovaný ve výchozím zásobníku MLOps. V pracovním prostoru pro vývoj iterují datoví vědci kód ML a žádosti o přijetí změn souborů (PR). Žádosti o přijetí změn aktivují testy jednotek a integrační testy v izolovaném pracovním prostoru Databricks. Když se žádost o přijetí změn sloučí do hlavní úlohy, trénování modelu a dávkové odvozování, které se spouští v přípravné fázi, okamžitě aktualizují, aby se spustil nejnovější kód. Po sloučení žádosti o přijetí změn do hlavní verze můžete v rámci plánovaného procesu vydání vyjmout novou větev a nasadit změny kódu do produkčního prostředí.
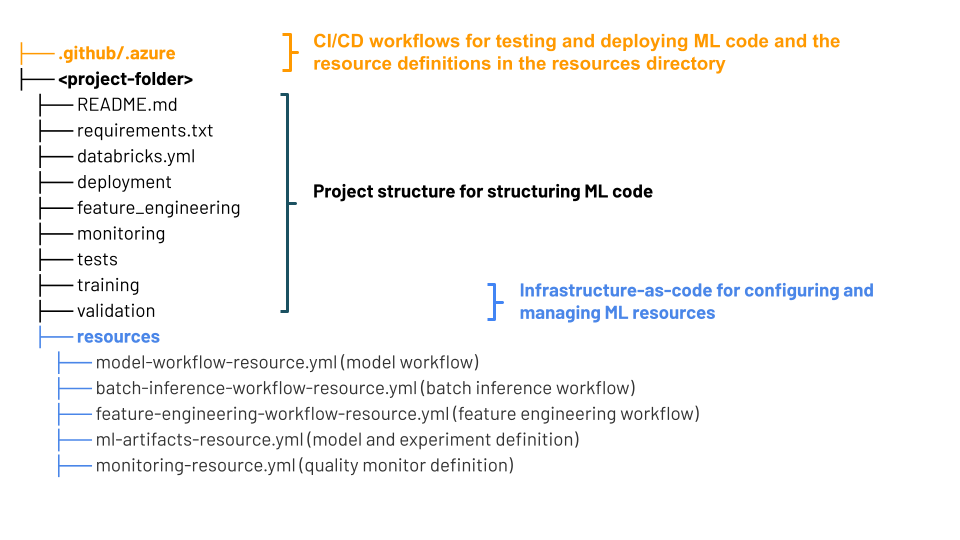
Struktura projektu zásobníků MLOps
Stack MLOps používá sady prostředků Databricks – kolekci zdrojových souborů, které slouží jako kompletní definice projektu. Mezi tyto zdrojové soubory patří informace o tom, jak se mají testovat a nasazovat. Shromažďování souborů jako sady usnadňuje spoluverzi změn a používá osvědčené postupy softwarového inženýrství, jako je správa zdrojového kódu, kontrola kódu, testování a CI/CD.
Diagram znázorňuje soubory vytvořené pro výchozí zásobník MLOps. Podrobnosti o souborech obsažených v zásobníku najdete v dokumentaci k úložišti GitHub nebo sadám prostředků Databricks pro zásobníky MLOps.
Zdroje informací
Úložiště Stacks Databricks MLOps na GitHubu
Další kroky
Pokud chcete začít, přečtěte si téma Sady prostředků Databricks pro zásobníky MLOps.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro