Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
LakeBase Autoscaling je nejnovější verze LakeBase s automatickým škálováním výpočetních prostředků, škálováním na nulu, větvením a okamžitým obnovením. Podporované oblasti najdete v tématu Dostupnost oblastí. Pokud jste uživatel Lakebase Provisioned, přečtěte si Lakebase Provisioned.
Vysoká dostupnost páruje primární výpočetní výkon pro čtení a zápis s jednou nebo více sekundárními výpočetními instancemi distribuovanými napříč zónami dostupnosti. Když se primární instance stane nedostupnou, sekundární výpočetní instance se automaticky povýší a vaše aplikace pokračuje od bodu poslední potvrzené transakce. Připojovací řetězec zůstane beze změny.
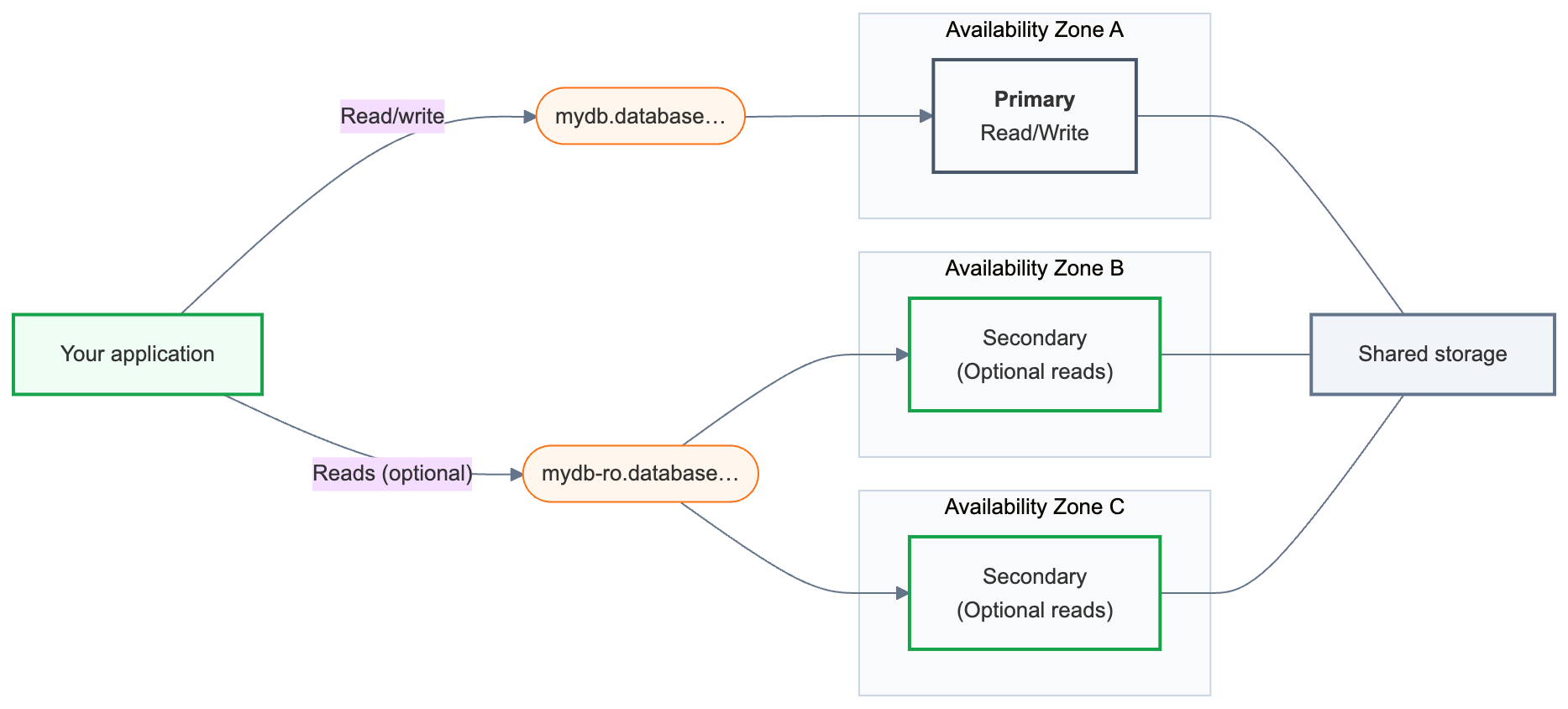
Jak funguje vysoká dostupnost
Koncový bod Lakebase je adresa databáze, ke které se vaše aplikace připojuje. Koncový bod vysoké dostupnosti zveřejňuje dva připojovací řetězce:
-
Primární (
{endpoint-id}.database.{region}.databricks.com) – hlavní připojení pro čtení a zápis. Tuto možnost použijte v každé aplikaci, která se připojuje k vaší databázi. Po převzetí služeb při selhání se automaticky přeřadí na výpočetní uzel, který je teď primární. -
Sekundární (
{endpoint-id}-ro.database.{region}.databricks.com) – k dispozici pouze v případě, že je povolený přístup k výpočetním instancím jen pro čtení . Sekundární výpočetní instance existují primárně jako pohotovostní režim pro převzetí služeb při selhání; povolením přístupu pro čtení můžete navíc směrovat dotazy pro čtení napříč nimi.
Oba připojovací řetězce jsou k dispozici v dialogovém okně Připojit ve vašem koncovém bodu.
Za těmito připojovacími řetězci má koncový bod vysoké dostupnosti vždy přesně jednu primární výpočetní instanci a jednu až tři sekundární výpočetní instance. Primární zpracovává veškerý provoz čtení a zápisu. Sekundární výpočetní instance běží v různých zónách dostupnosti a jsou povýšeny na primární v případě selhání.
Každá sekundární výpočetní instance má nastavení Accessu , které určuje, jestli také obsluhuje provoz čtení:
| Sekundární přístup | Jak funguje |
|---|---|
| Jen pro čtení | Sekundární výpočetní instance zpracovává čtení prostřednictvím připojovacího -ro řetězce a může být podle potřeby povýšena na primární instance. |
| Zakázáno | Sekundární výpočetní instance je aktivní a připravená na přepnutí, ale neobsluhuje čtení. |
To můžete řídit nastavením Povolit přístup k výpočetním instancím jen pro čtení v koncovém bodu, ke kterému máte přístup v zásobníku Upravit výpočetní prostředky . Pokud je tato možnost povolena, všechny sekundární výpočetní instance obsluhují čtení; pokud je zakázána, jsou v pohotovostním režimu a slouží pouze pro převzetí služeb při selhání. V obou případech je výpočetní hardware už přidělený a spuštěný: Upgradování nevyžaduje zřízení nových zdrojů, takže kapacita pro převzetí při selhání je rezervovaná bez ohledu na poptávku v zóně dostupnosti.
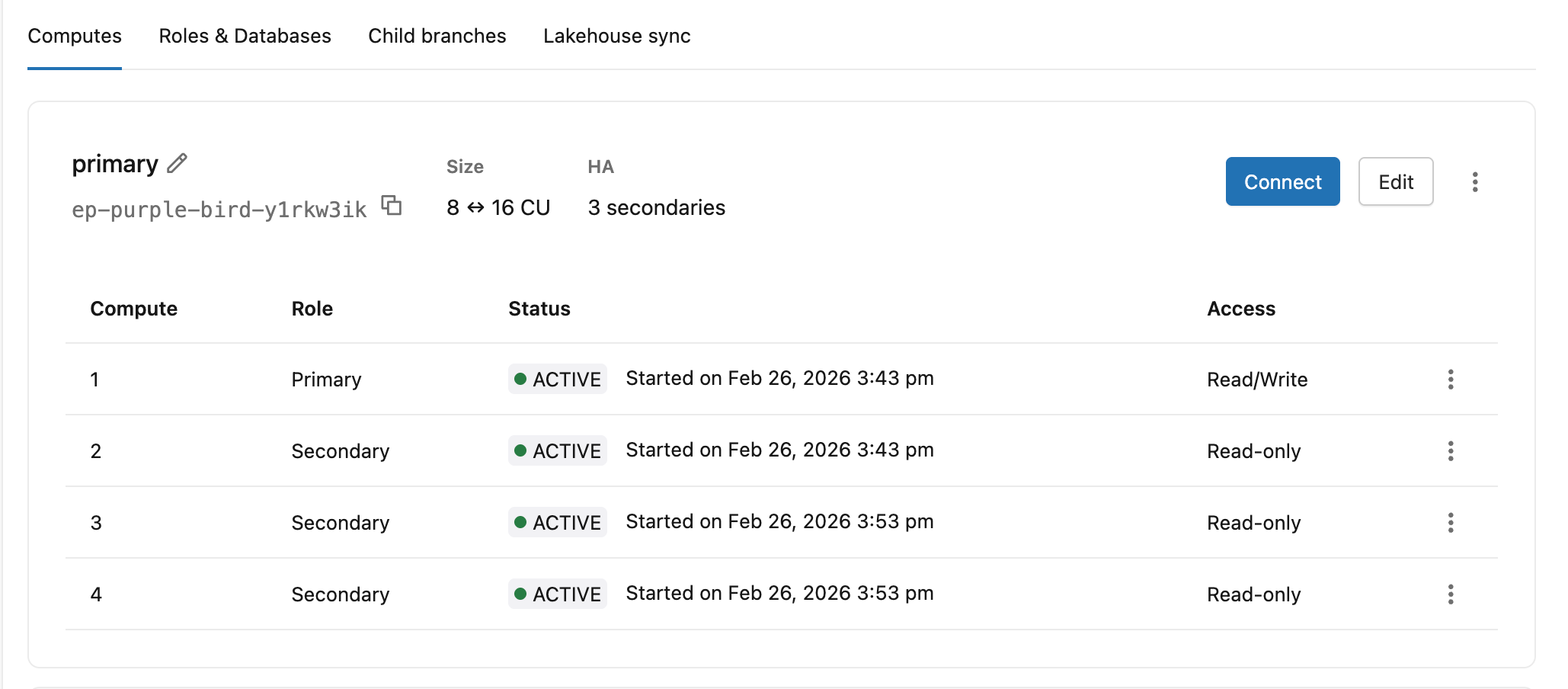
Na kartě Výpočty se zobrazí na první pohled role jednotlivých výpočetních instancí (primární nebo sekundární), stav a úroveň přístupu .
Distribuce AZ
Lakebase distribuuje primární a sekundární výpočetní instance napříč zónami dostupnosti a snižuje riziko, že selhání jediného az ovlivňuje primární i všechny sekundární výpočetní instance.
Automatické škálování ve vysoké dostupnosti
Všechny výpočetní instance v konfiguraci s vysokou dostupností mají stejný rozsah automatického škálování. Maximální rozpětí mezi minimálním a maximálním CU je 16 CU, stejné omezení jako samostatné výpočetní instance.
Sekundární výpočetní instance jsou vždy škálovány na minimálně stejnou velikost CU jako primární instance, což zajišťuje, že databázová kapacita zůstane konzistentní i po převzetí služeb při selhání.
Škálování na nulu není dostupné pro výpočetní instance v konfiguraci s vysokou dostupností. Všechny výpočetní instance můžete pozastavit ručně, ale koncový bod bude při pozastavení nedostupný.
Sekundární výpočetní instance vs. samostatné repliky pro čtení
Sekundární výpočetní instance a samostatné repliky pro čtení jsou různé funkce, které mohou existovat ve stejné větvi:
| Sekundární výpočetní instance | Samostatné repliky pro čtení | |
|---|---|---|
| Purpose | Převzetí služeb při selhání + volitelné přesměrování čtení | Jen čtení přenesení zátěže |
| Přidáno prostřednictvím | Konfigurace vysoké dostupnosti | Přidat repliku pro čtení |
| Účastní se failoveru | Ano | Ne |
| Připojovací řetězec |
-ro v primárním koncovém bodu |
Vlastní samostatný koncový bod |
| Sizing | Sdíleno s primárním na úrovni koncového bodu | Nezávisle dimenzováno |
Pokud potřebujete vysokou dostupnost i další kapacitu čtení nad rámec toho, co poskytují sekundární výpočetní instance, můžete kombinovat obě funkce ve stejné větvi. Viz repliky pro čtení.
Chování při selhání
Automatické přepnutí při selhání
Lakebase nepřetržitě monitoruje primární stav výpočetních prostředků. Pokud primární server přestane být dostupný, automaticky se aktivuje failover.
Zálohování při selhání zachovává všechny potvrzené transakce.
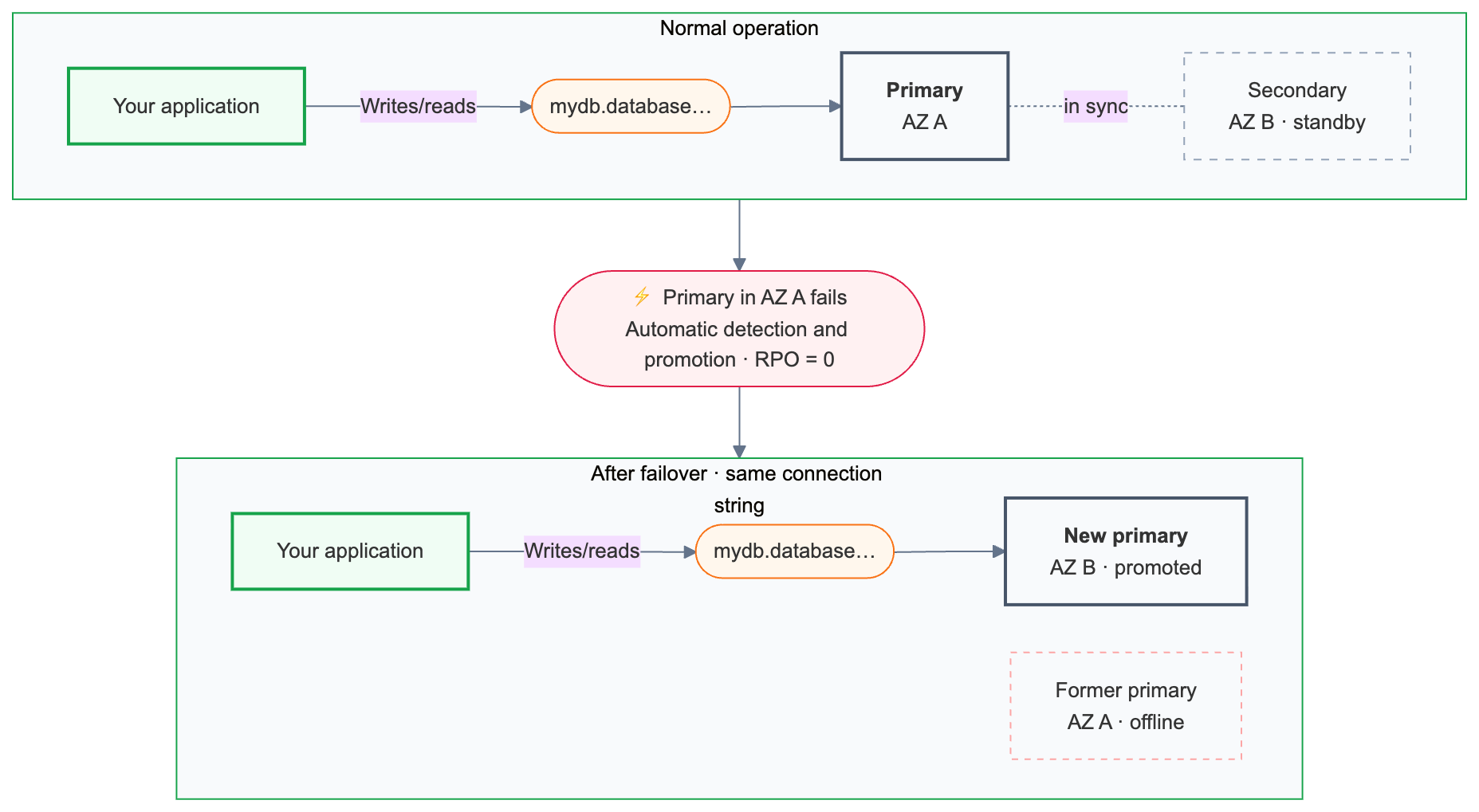
Po převzetí služeb při selhání primární připojovací řetězec ({endpoint-id}.database.{region}.databricks.com) směruje automaticky do nově povýšené výpočetní instance. Aplikace nemusí měnit konfiguraci připojení, ale stávající připojení se ukončí během přepnutí při selhání a musí se znovu připojit. Aplikace s logikou opakování to zpracovávají automaticky.
Převzetí služeb při selhání s povoleným přístupem jen pro čtení
Pokud je povolen přístup k výpočetním instancím jen pro čtení a dojde k převzetí služeb při selhání, povýšená sekundární instance se stane novou primární instancí a přestane obsluhovat čtení. Pokud máte dvě nebo více čitelných sekundárních replik, příjem datového provozu na připojovacím řetězci -ro pokračuje v omezené kapacitě, dokud se nenajde náhrada. Pokud máte jenom jeden, čtení se úplně přeruší, dokud nebude náhrada připravená.
Připojovací řetězce
Dialogové okno Připojit zobrazuje oba připojovací řetězce s aktuálním stavem výpočetních prostředků:
| Možnost Výpočty v dialogovém okně Připojit | Připojovací řetězec | Použít pro |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Všechny zápisy; čtení, která musí udeřit na aktuální primární |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Přesměrování načítání do sekundárních výpočetních instancí (k dispozici pouze v případě, že je povolený přístup k výpočetním instancím jen pro čtení ) |
Primární řetězec připojení vždy směruje na aktuální primární server, včetně po převzetí služeb při selhání.
Každá výpočetní instance má také vlastní přímý připojovací řetězec, který je přístupný z karty Computes prostřednictvím nabídky akcí (⋮) na každém řádku. Přímá připojení jsou určená k řešení potíží s jednotlivými výpočetními instancemi, ne pro použití aplikace. Přímé připojovací řetězce jsou vázané na výpočetní prostředky a můžou se změnit, když se přidají, odeberou nebo upřednostní sekundární řetězce.
Limity vysoké dostupnosti
| Limit | Hodnota |
|---|---|
| Výpočetní instance | 2, 3 nebo 4 (1 primární + 1–3 sekundární výpočetní instance) |
| Rozsah automatického škálování (max − min) | ≤ 16 CU mezi minimálním a maximálním |
| Škálování na nulu | Není k dispozici pro výpočetní instance v konfiguraci s vysokou dostupností |
Osvědčené postupy
Dodržováním těchto postupů pomáháte vaší aplikaci být odolná vůči selhání a dostupná v průběhu událostí převzetí služeb při selhání.
| Practice | Podrobnosti |
|---|---|
| Implementace logiky opakování připojení | Aktivní připojení se ukončí při selhání. Připojení k selhanému primárnímu serveru může být zaseknuté až do vypršení časového limitu — nakonfigurujte TCP keepalives nebo časový limit připojení v ovladači, aby se selhání rychle zjistilo. Připojení k sekundárnímu uzlu se aktivně ukončí a okamžitě vrátí chybu. Aplikace s logikou opakování se automaticky připojí během několika sekund. |
| Konfigurace sekundárního počtu pro váš případ použití | Každá sekundární výpočetní instance představuje předem přidělený hardware vyhrazený pro redundanci v případě selhání. Snížení počtu sekundárních instancí znamená menší kapacitu pro převzetí služeb při selhání a méně pokrytých zón dostupnosti. Jedna sekundární výpočetní instance zajišťuje pokrytí při selhání. Pokud povolíte čitelné sekundární soubory, nakonfigurujte dvě nebo více. S pouze jedním se čtení během převzetí služeb při selhání úplně přeruší, dokud se nezřídí náhrada. |
| Vyhněte se přetížení sekundárních výpočetních instancí | Služba může restartovat sekundární výpočetní instanci, která je přetížená nebo zapadající. Monitorujte zatížení dotazů a počty připojení a zvyšte velikost CU, pokud zaznamenáte trvalé vysoké využití. |
Další kroky
- Správa vysoké dostupnosti pro povolení a konfiguraci vysoké dostupnosti
- Automatické škálování pro podrobnosti o velikosti CU a rozsahech automatického škálování
- Připojovací řetězce pro kompletní odkaz na připojovací řetězec