Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
LakeBase Autoscaling je nejnovější verze LakeBase s automatickým škálováním výpočetních prostředků, škálováním na nulu, větvením a okamžitým obnovením. Podporované oblasti najdete v tématu Dostupnost oblastí. Pokud jste uživatel Lakebase Provisioned, přečtěte si Lakebase Provisioned.
Tato příručka pokrývá umožnění a správu vysoké dostupnosti vašich koncových bodů Lakebase. Základní informace o tom, jak funguje vysoká dostupnost a jak se sekundární výpočetní instance liší od samostatných replik pro čtení, najdete v tématu Vysoká dostupnost.
Povolení vysoké dostupnosti
Pokud chcete povolit vysokou dostupnost, nastavte typ výpočetních prostředků a konfiguraci vysoké dostupnosti v uživatelském rozhraní nebo nakonfigurujte koncový bod EndpointGroupSpec přes rozhraní API.
Předpoklady
- Škálování na nulu musí být deaktivováno. V uživatelském rozhraní nastavte měřítko na nulu na Vypnuto v panelu pro úpravy výpočetních prostředků. Prostřednictvím rozhraní API nastavte specifikaci pro koncový bod (použijte
no_suspension: truejako aktualizační masku).
uživatelské rozhraní
Po vytvoření projektu kliknutím na primární odkaz na výpočetní zdroj z nástěnky projektu otevřete panel pro úpravy výpočetního zdroje.
Řídicí panel projektu zobrazující produkční větev s primárním výpočetním propojením
Nastavte typ výpočetních prostředků na Vysokou dostupnost a pak v části Vysoká dostupnost zvolte konfiguraci:
- 2 (1 primární, 1 sekundární),
- 3 (1 primární, 2 sekundární),
- nebo 4 (1 primární, 3 sekundární) celkový počet výpočetních instancí.
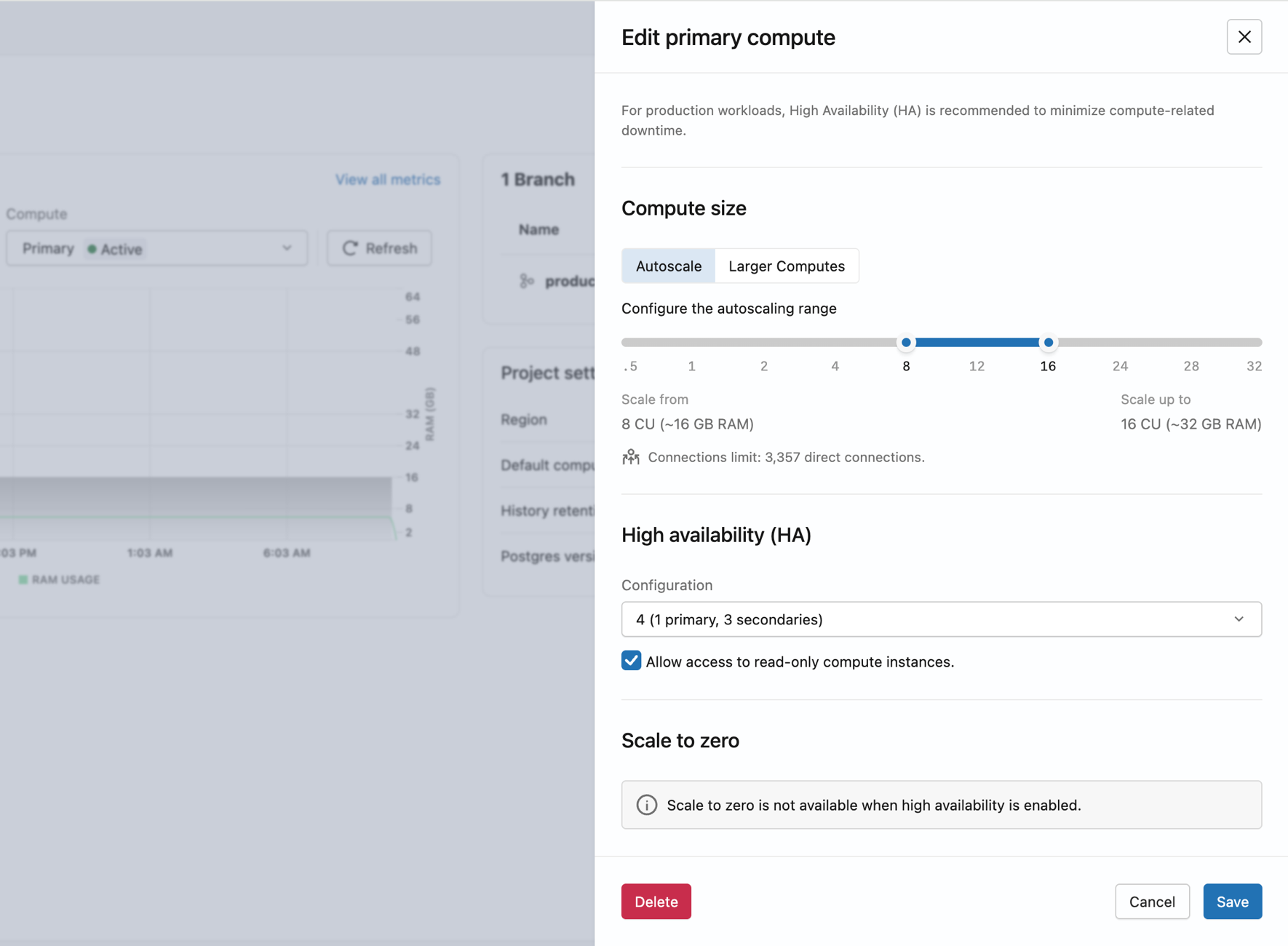
Lakebase zřizuje sekundární výpočetní instance v různých zónách dostupnosti. Jakmile jsou všechny výpočetní instance aktivní, koncový bod automaticky přebírá při selhání.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
result = w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=2,
max=2,
enable_readable_secondaries=True
)
)
),
update_mask=FieldMask(field_mask=["spec.group"])
).wait()
print(f"Group size: {result.status.group.max}")
print(f"Host: {result.status.hosts.host}")
print(f"Read-only host: {result.status.hosts.read_only_host}")
CLI
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
kroucení
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Konfigurace přístupu jen pro čtení k sekundárním výpočetním instancím
Povolit přístup k výpočetním instancím jen pro čtení určuje, jestli sekundární výpočetní instance obsluhují provoz čtení přes -ro connection string.
uživatelské rozhraní
- Na kartě Výpočty klikněte na Upravit u primárního výpočetního objektu.
- V části Vysoká dostupnost zaškrtněte nebo zrušte zaškrtnutí políčka Povolit přístup k výpočetním instancím jen pro čtení.
- Klikněte na Uložit.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Get current group size first
current = w.postgres.get_endpoint(name=endpoint_name)
current_size = current.status.group.max
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=current_size,
max=current_size,
enable_readable_secondaries=True # set False to disable
)
)
),
update_mask=FieldMask(field_mask=["spec.group.enable_readable_secondaries"])
).wait()
CLI
# Replace 2 with your current group size
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.enable_readable_secondaries" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
kroucení
# Replace 2 with your current group size
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.enable_readable_secondaries" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Výstraha
Pokud je povolena pouze jedna sekundární výpočetní instance a přístup pro čtení, veškerý provoz čtení na -ro připojovacím řetězci se během selhání přeruší, dokud se nenahradí. Pro odolný přístup pro čtení nakonfigurujte dvě nebo více sekundárních výpočetních instancí s povoleným přístupem pro čtení.
Změna počtu sekundárních výpočetních instancí
uživatelské rozhraní
- Na kartě Výpočty klikněte na Upravit u primárního výpočetního objektu.
- V části Vysoká dostupnost zvolte v rozevíracím seznamu novou konfiguraci výpočetních prostředků (2, 3 nebo 4 celkové výpočetní instance).
- Klikněte na Uložit.
Poznámka:
Pokud chcete vysokou dostupnost zakázat, nastavte typ výpočetních prostředků zpět na Jeden výpočetní objekt. Tím se odeberou všechny sekundární výpočetní instance a koncový bod se vrátí do konfigurace s jedním výpočetním objektem.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Scale to 3 compute instances (1 primary + 2 secondaries)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(min=3, max=3)
)
),
update_mask=FieldMask(field_mask=["spec.group.min", "spec.group.max"])
).wait()
CLI
# Scale to 3 compute instances (1 primary + 2 secondaries)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.min,spec.group.max" \
--json '{
"spec": {
"group": { "min": 3, "max": 3 }
}
}'
kroucení
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.min,spec.group.max" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": { "min": 3, "max": 3 }
}
}' | jq
Zobrazení stavu a rolí s vysokou dostupností
Na kartě Výpočty se zobrazí každá výpočetní instance v konfiguraci vysoké dostupnosti s aktuální rolí, stavem a úrovní přístupu.
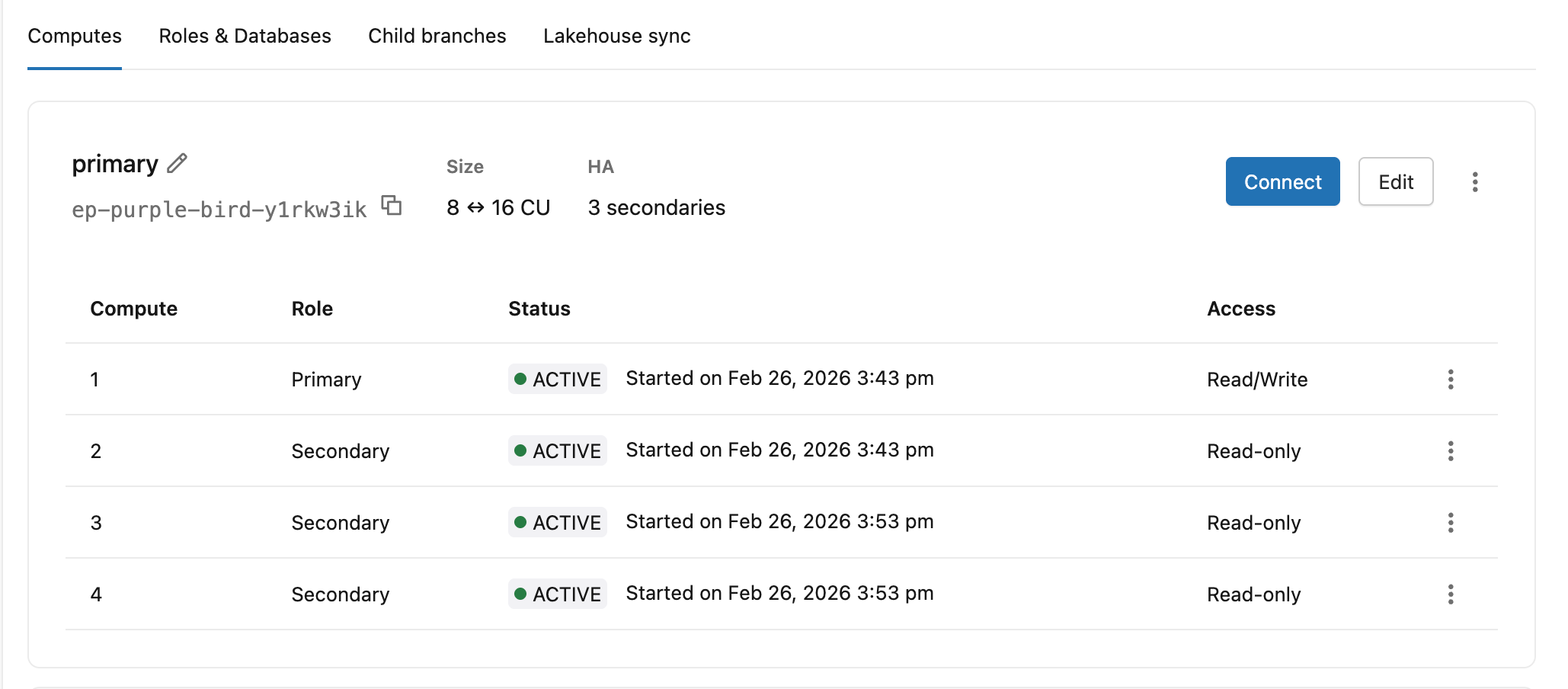
| Sloupec | Hodnoty |
|---|---|
| Role | Primární, sekundární |
| Stav | Spuštění, Aktivní |
| Access | Čtení/zápis (primární), jen pro čtení (sekundární výpočetní instance s povoleným přístupem), zakázáno (sekundární výpočetní instance bez přístupu pro čtení) |
Primární hlavička výpočetních prostředků také zobrazuje ID koncového bodu, rozsah automatického škálování a sekundární počet (např. 8 ↔ 16 CU · 3 secondaries).
Získání připojovacích řetězců
uživatelské rozhraní
Kliknutím na Připojit u primárního výpočetního prostředí otevřete dialogové okno podrobností o připojení. V rozevíracím seznamu Compute jsou uvedené obě možnosti připojení pro váš koncový bod s vysokou dostupností.
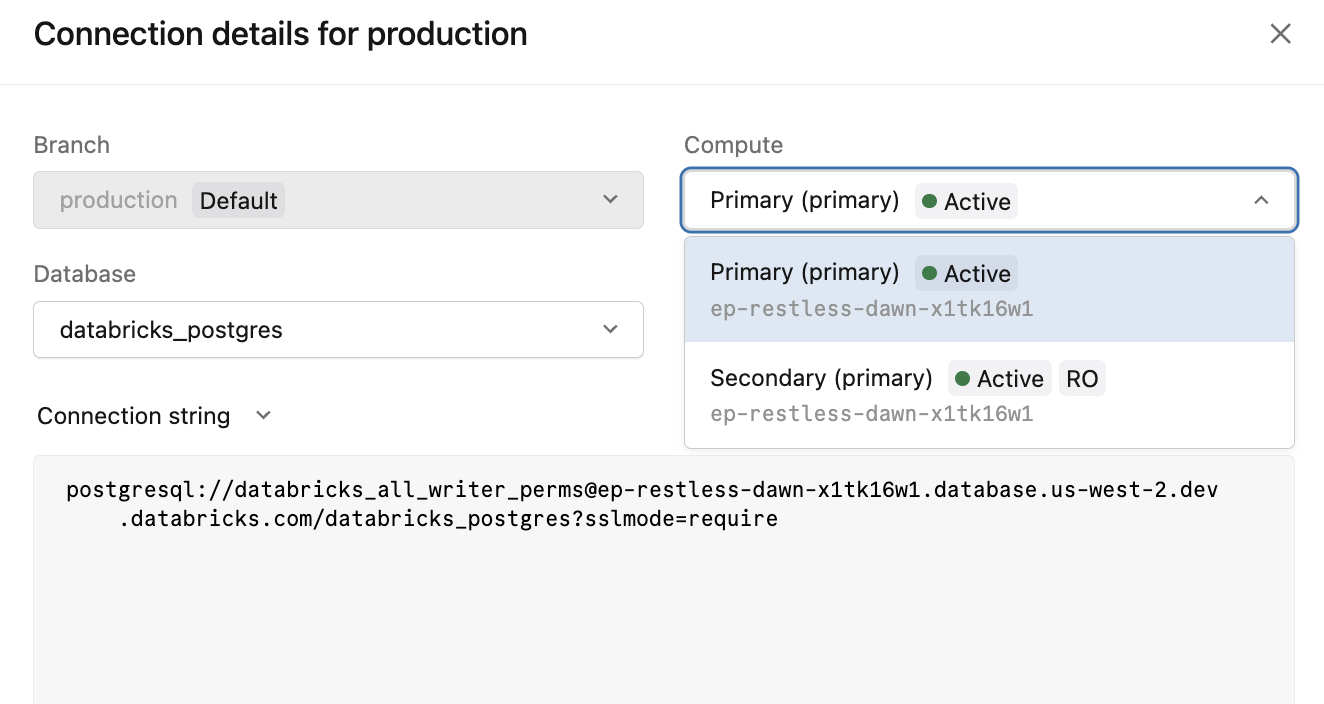
| Možnost výpočtu | Připojovací řetězec | Použít pro |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Všechna zápisová a čtecí/zápisová připojení |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Přesun čtení na sekundární výpočetní instance |
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-endpoint"
)
print(f"Read/write host: {endpoint.status.hosts.host}")
print(f"Read-only host: {endpoint.status.hosts.read_only_host}")
CLI
databricks postgres get-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
-o json | jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
kroucení
curl -X GET "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
| jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
Pro úplnou referenci připojovacích řetězců viz Připojovací řetězce.
Další kroky
- Vysoká dostupnost – koncepty, chování při selhání a osvědčené postupy
- Repliky pro čtení – samostatné repliky pro další kapacitu čtení bez zajištění vysoké dostupnosti
- Připojovací řetězce