Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Automatické škálování LakeBase je v beta verzích v následujících oblastech: eastus2, westeurope, westus.
Automatické škálování LakeBase je nejnovější verze LakeBase s automatickým škálováním výpočetních prostředků, škálováním na nulu, větvení a okamžitým obnovením. Porovnání funkcí se službou Lakebase Provisioned najdete v tématu Volba mezi verzemi.
Reverse ETL v Lakebase synchronizuje tabulky Unity Catalog do systému Postgres, takže aplikace mohou přímo používat kurátorská data z Lakehouse. Lakehouse je optimalizovaný pro analýzu a rozšiřování, zatímco Lakebase je navržená pro provozní úlohy, které vyžadují rychlé dotazy a transakční konzistenci.
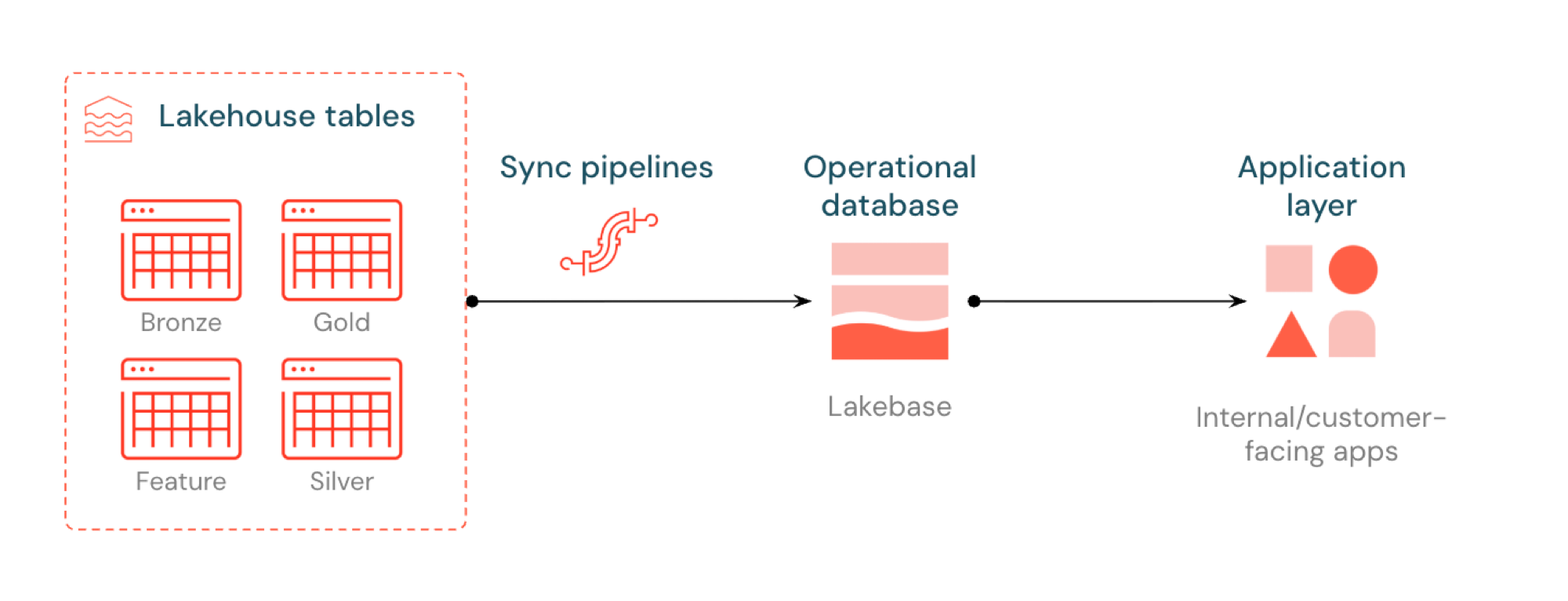
Co je zpětné ETL?
Reverse ETL umožňuje přesunout data na úrovni analýz z katalogu Unity do Lakebase Postgres, kde je můžete zpřístupnit aplikacím, které potřebují dotazy s nízkou latencí (sub-10ms) a úplné transakce ACID. Překlenuje mezeru mezi analytickým úložištěm a operačními systémy tím, že udržuje kurátorovaná data použitelná v aplikacích v reálném čase.
Jak to funguje
Synchronizované tabulky Databricks vytvoří spravovanou kopii dat katalogu Unity v Lakebase. Když vytvoříte synchronizovanou tabulku, získáte:
- Nová tabulka katalogu Unity (jen pro čtení spravovaná kanálem synchronizace)
- Tabulka Postgres v Lakebase (dotazovatelná aplikacemi)
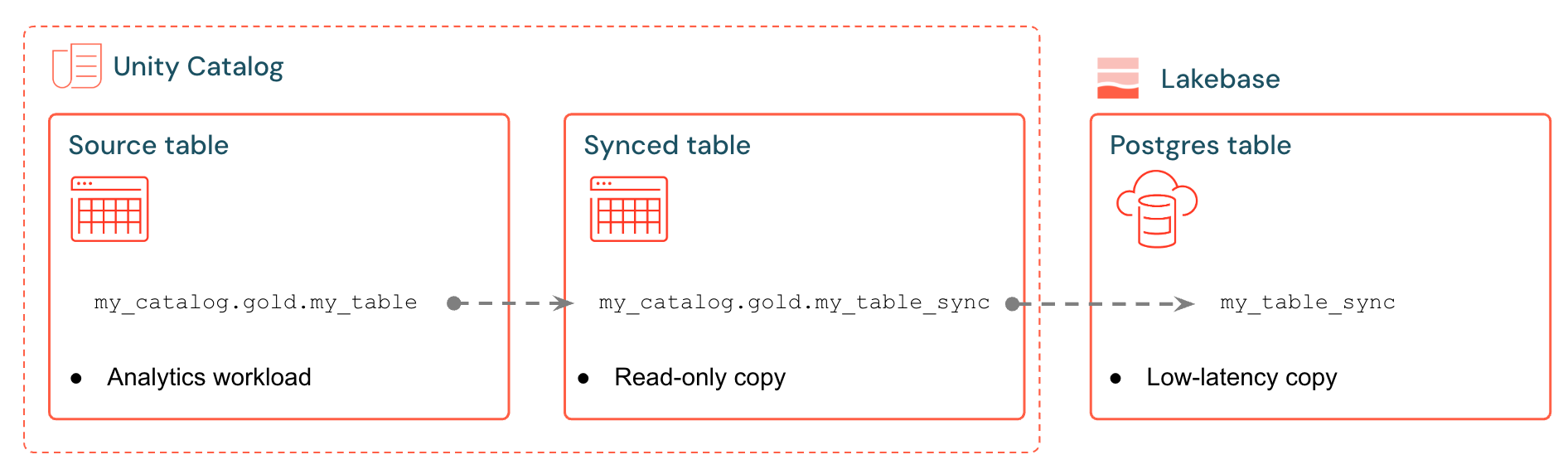
Například můžete synchronizovat standardizované tabulky, upravené funkce nebo ML výstupy analytics.gold.user_profiles do nové synchronizované tabulky analytics.gold.user_profiles_synced. V Postgres se název schématu katalogu Unity změní na název schématu Postgres, takže se zobrazí takto "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Aplikace se připojují pomocí standardních ovladačů Postgres a dotazují se na synchronizovaná data společně s vlastním provozním stavem.
Synchronizační pipeline používají spravované deklarační pipeline Lakeflow Spark pro průběžnou aktualizaci jak tabulky synchronizované s Unity Catalog, tak i tabulky Postgres a plnit je změnami ze zdrojové tabulky. Každá synchronizace může používat až 16 připojení k databázi Lakebase.
Lakebase Postgres podporuje až 1 000 souběžných připojení s transakčními zárukami, takže aplikace můžou číst rozšířená data a zároveň zpracovávat vkládání, aktualizace a odstraňování ve stejné databázi.
Režimy synchronizace
Na základě potřeb vaší aplikace zvolte správný režim synchronizace:
| Mode | Description | Nejvhodnější pro | Performance |
|---|---|---|---|
| Snapshot | Jednorázová kopie všech dat | Počáteční nastavení nebo historická analýza | 10x efektivnější při úpravě >10% zdrojových dat |
| Aktivovaný | Plánované aktualizace, které běží na vyžádání nebo v intervalech | Řídicí panely, aktualizované každou hodinu/denně | Dobrý poměr mezi náklady a prodlevou. Nákladné při běhu na intervaly po 5 minutách. |
| Nepřetržitý | Streamování v reálném čase s latencí v sekundách | Živé aplikace (vyšší náklady kvůli vyhrazenému výpočetnímu prostředí) | Nejnižší prodleva, nejvyšší náklady. Minimálně 15sekundové intervaly |
Režimy Triggered a Continuous vyžadují, aby ve zdrojové tabulce byl povolen Změna datového toku (CDF). Pokud cdF není povolené, zobrazí se v uživatelském rozhraní upozornění s přesným ALTER TABLE příkazem ke spuštění. Další podrobnosti o změně kanálu dat najdete v tématu Použití funkce změny kanálu dat v Delta Lake na Databricks.
Příklady případů použití
Reverse ETL s Lakebase podporuje běžné provozní scénáře:
- Moduly pro přizpůsobení, které potřebují nové uživatelské profily synchronizované s Databricks Apps
- Aplikace, které obsluhují predikce modelu nebo hodnoty vlastností vypočítané v lakehouse
- Řídicí panely orientované na zákazníky, které zobrazují klíčové ukazatele výkonu v reálném čase
- Služby detekce podvodů, které potřebují skóre rizika, které jsou k dispozici pro okamžitou akci
- Nástroje podpory, které obohacují záznamy zákazníků o kurátorovaná data z lakehouse
Vytvoření synchronizované tabulky (UI)
Synchronizované tabulky můžete vytvářet v uživatelském rozhraní Databricks nebo programově pomocí sady SDK. Pracovní postup uživatelského rozhraní je uveden níže.
Požadavky
Potřebujete:
- Pracovní prostor Databricks s povolenou službou LakeBase
- Projekt Lakebase (viz Vytvoření projektu).
- Tabulka katalogu Unity s kurátorovanými daty
- Oprávnění k vytváření synchronizovaných tabulek
Informace o kompatibilitě plánování kapacity a datového typu najdete v tématu Datové typy a kompatibilita a plánování kapacity.
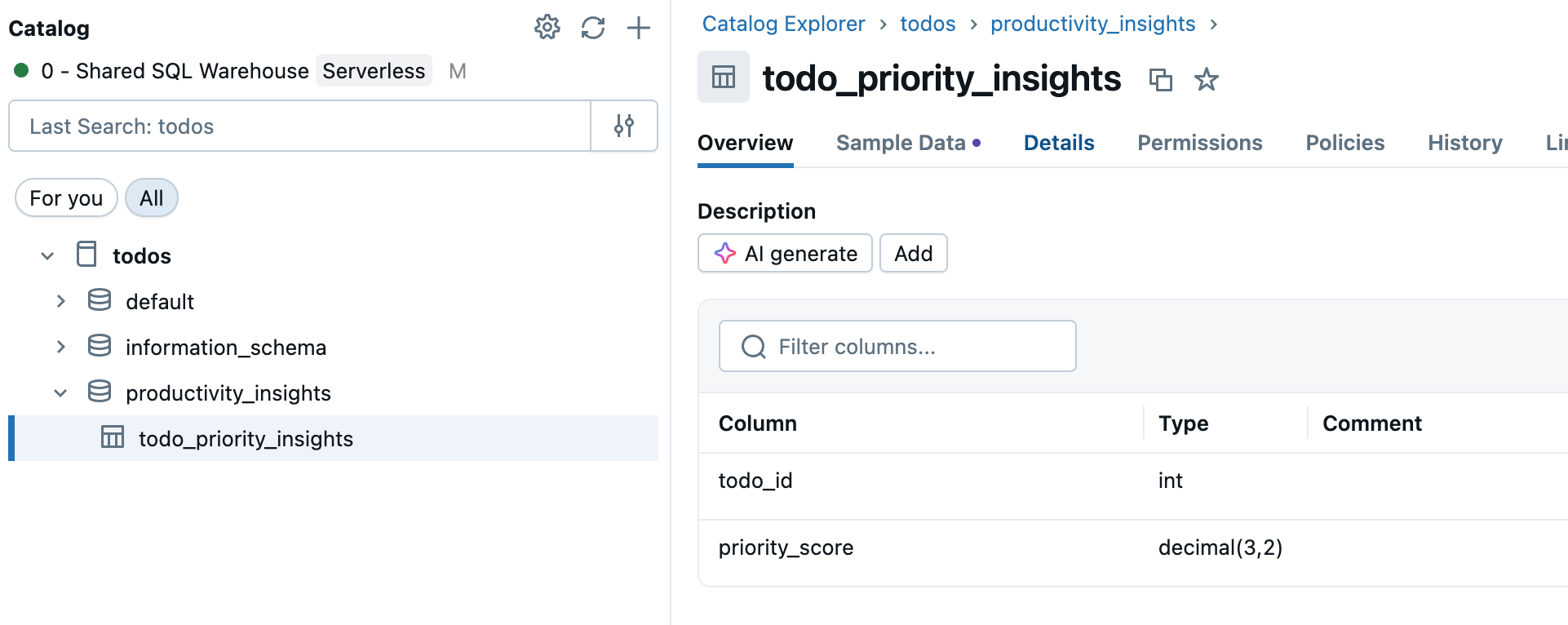
Krok 1: Výběr zdrojové tabulky
Přejděte do katalogu na bočním panelu pracovního prostoru a vyberte tabulku Katalogu Unity, kterou chcete synchronizovat.
Krok 2: Povolení změnového datového kanálu (v případě potřeby)
Pokud plánujete používat spouštěné nebo průběžné režimy synchronizace, zdrojová tabulka potřebuje mít povolený změnový datový kanál. Zkontrolujte, jestli už vaše tabulka má povolenou funkci CDF, nebo spusťte tento příkaz v editoru NEBO poznámkovém bloku SQL:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Nahraďte your_catalog.your_schema.your_table skutečným názvem tabulky.
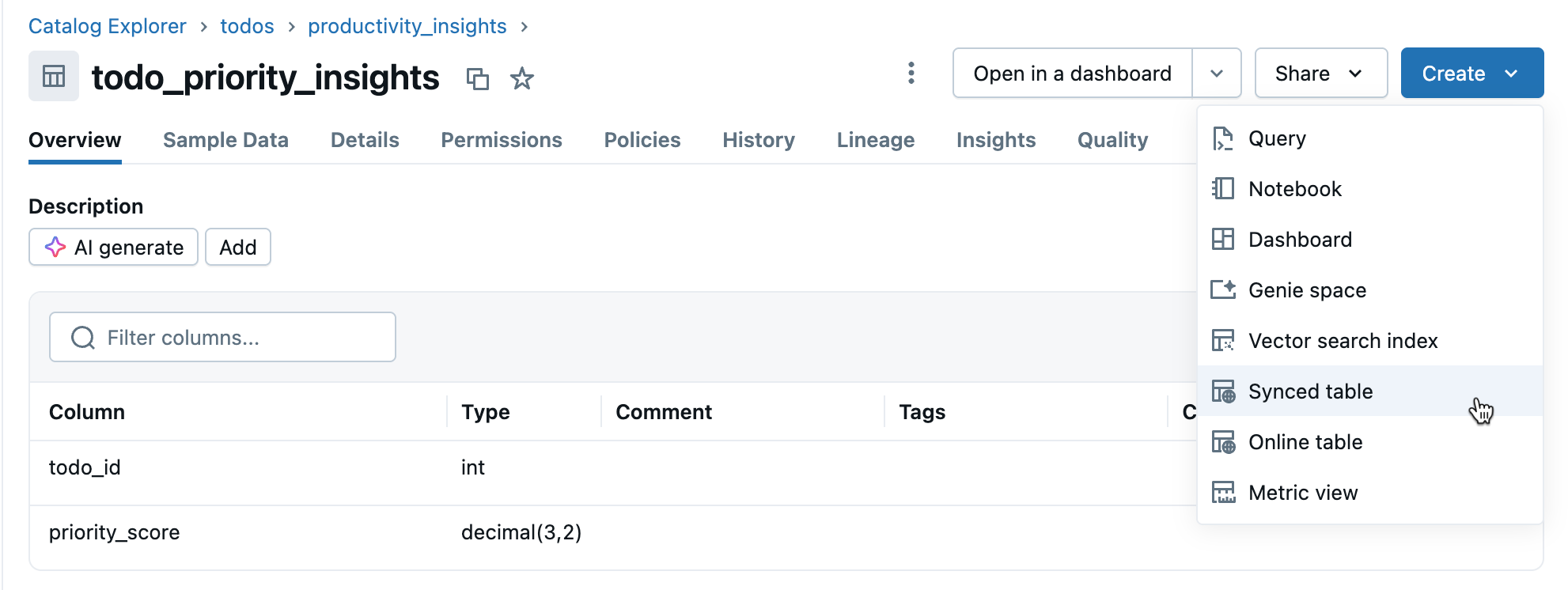
Krok 3: Vytvoření synchronizované tabulky
V zobrazení podrobností tabulky klikněte na Vytvořit>synchronizovanou tabulku .
Krok 4: Konfigurace
V dialogovém okně Vytvořit synchronizovanou tabulku :
- Název tabulky: Zadejte název synchronizované tabulky (vytvoří se ve stejném katalogu a schématu jako zdrojová tabulka). Tím se vytvoří tabulka synchronizovaná v katalogu Unity i tabulka Postgres, na kterou se můžete dotazovat.
- Typ databáze: Zvolte Bezserverová databáze Lakebase (automatické škálování).
- Režim synchronizace: V závislosti na vašich potřebách zvolte snímek, aktivovaný nebo průběžný (viz režimy synchronizace výše).
- Nakonfigurujte projekt, větev a databázi.
- Ověřte správnost primárního klíče (obvykle automaticky rozpoznaný).
Pokud jste zvolili režim Triggered nebo Continuous a ještě jste nepovolili Change Data Feed, zobrazí se upozornění s přesným příkazem, který je třeba spustit. Otázky týkající se kompatibility datových typů najdete v tématu Datové typy a kompatibilita.
Kliknutím na Vytvořit vytvoříte synchronizovanou tabulku.
Krok 5: Monitorování
Po vytvoření monitorujte synchronizovanou tabulku v katalogu. Na kartě Přehled se zobrazuje stav synchronizace, konfigurace, stav kanálu a časové razítko poslední synchronizace. Použijte Synchronizovat nyní k ruční aktualizaci.
Datové typy a kompatibilita
Datové typy Katalogu Unity se při vytváření synchronizovaných tabulek mapují na typy Postgres. Komplexní typy (ARRAY, MAP, STRUCT) se ukládají jako JSONB v Postgresu.
| Typ zdrojového sloupce | Typ sloupce Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p;s) | ČÍSELNÝ |
| DVOJITÝ | DVOJITÁ PŘESNOST |
| FLOAT | SKUTEČNÝ |
| INT | INTEGER |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| STRING | TEXT |
| ČASOVÁ ZNAČKA | ČASOVÉ RAZÍTKO S ČASOVÝM PÁSMEM |
| TIMESTAMP_NTZ | ČASOVÉ RAZÍTKO BEZ ČASOVÉHO PÁSMA |
| TINYINT | SMALLINT |
| ARRAY< elementType> | JSONB |
| MAP<keyType, valueType> | JSONB |
| STRUCT<fieldName:fieldType[, ...]> | JSONB |
Poznámka:
Typy GEOGRAPHY, GEOMETRY, VARIANT a OBJECT nejsou podporovány.
Zpracování neplatných znaků
Některé znaky, jako jsou bajty null (0x00), jsou povolené ve sloupcích Unity Catalog STRING, ARRAY, MAP nebo STRUCT, ale nejsou podporované ve sloupcích Postgres TEXT nebo JSONB. To může způsobit selhání synchronizace s chybami, jako jsou:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Řešení:
Sanitize string fields: Před synchronizací odeberte nepodporované znaky. Pro bajty null ve sloupcích STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tablePřevést na BINARY: Pro sloupce STRING, kde je nutné zachovat nezpracované bajty, převeďte na BINÁRNÍ typ.
Programové vytváření
Pro pracovní postupy automatizace můžete pomocí sady Databricks SDK, rozhraní příkazového řádku nebo rozhraní REST API vytvářet synchronizované tabulky prostřednictvím kódu programu.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.database import (
SyncedDatabaseTable,
SyncedTableSpec,
NewPipelineSpec,
SyncedTableSchedulingPolicy
)
# Initialize the Workspace client
w = WorkspaceClient()
# Create a synced table
synced_table = w.database.create_synced_database_table(
SyncedDatabaseTable(
name="lakebase_catalog.schema.synced_table", # Full three-part name
spec=SyncedTableSpec(
source_table_full_name="analytics.gold.user_profiles",
primary_key_columns=["user_id"], # Primary key columns
scheduling_policy=SyncedTableSchedulingPolicy.TRIGGERED, # SNAPSHOT, TRIGGERED, or CONTINUOUS
new_pipeline_spec=NewPipelineSpec(
storage_catalog="lakebase_catalog",
storage_schema="staging"
)
),
)
)
print(f"Created synced table: {synced_table.name}")
# Check the status of a synced table
status = w.database.get_synced_database_table(name=synced_table.name)
print(f"Synced table status: {status.data_synchronization_status.detailed_state}")
print(f"Status message: {status.data_synchronization_status.message}")
CLI
# Create a synced table
databricks database create-synced-database-table \
--json '{
"name": "lakebase_catalog.schema.synced_table",
"spec": {
"source_table_full_name": "analytics.gold.user_profiles",
"primary_key_columns": ["user_id"],
"scheduling_policy": "TRIGGERED",
"new_pipeline_spec": {
"storage_catalog": "lakebase_catalog",
"storage_schema": "staging"
}
}
}'
# Check the status of a synced table
databricks database get-synced-database-table "lakebase_catalog.schema.synced_table"
REST API
export WORKSPACE_URL="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-token"
# Create a synced table
curl -X POST "$WORKSPACE_URL/api/2.0/database/synced_tables" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
--data '{
"name": "lakebase_catalog.schema.synced_table",
"spec": {
"source_table_full_name": "analytics.gold.user_profiles",
"primary_key_columns": ["user_id"],
"scheduling_policy": "TRIGGERED",
"new_pipeline_spec": {
"storage_catalog": "lakebase_catalog",
"storage_schema": "staging"
}
}
}'
# Check the status
curl -X GET "$WORKSPACE_URL/api/2.0/database/synced_tables/lakebase_catalog.schema.synced_table" \
-H "Authorization: Bearer $DATABRICKS_TOKEN"
Plánování kapacity
Při plánování zpětné implementace ETL zvažte tyto požadavky na prostředky:
- Využití připojení: Každá synchronizovaná tabulka používá až 16 připojení k databázi Lakebase, která se počítá do limitu připojení instance.
- Omezení velikosti: Celkový limit velikosti logických dat ve všech synchronizovaných tabulkách je 8 TB. Jednotlivé tabulky nemají omezení, ale Databricks doporučuje, aby tabulky vyžadující aktualizace nepřekračovaly 1 TB.
-
Požadavky na pojmenování: Názvy databází, schémat a tabulek můžou obsahovat pouze alfanumerické znaky a podtržítka (
[A-Za-z0-9_]+). - Vývoj schématu: Pro režimy Triggered a Continuous jsou podporovány pouze přidávací změny schématu (například přidávání sloupců).
- Rychlost aktualizace:: U automatického škálování Lakebase podporuje synchronizační kanál průběžné a spouštěné zápisy přibližně 150 řádků za sekundu na jednotku kapacity (CU) a zápisy snímků až 2 000 řádků za sekundu na jednotku kapacity (CU).
Odstranění synchronizované tabulky
Pokud chcete odstranit synchronizovanou tabulku, musíte ji odebrat z katalogu Unity i z Postgresu:
Odstranit z katalogu Unity: V katalogu najděte synchronizovanou tabulku, klikněte na
 a vyberte Odstranit. Tím se zastaví aktualizace dat, ale tabulka se ponechá v Postgresu.
a vyberte Odstranit. Tím se zastaví aktualizace dat, ale tabulka se ponechá v Postgresu.Drop from Postgres: Připojte se k databázi Lakebase a vypusťte tabulku, aby se uvolnilo místo:
DROP TABLE your_database.your_schema.your_table;
K připojení k Postgresu můžete použít editor SQL nebo externí nástroje.
Další informace
| Task | Description |
|---|---|
| Vytvoření projektu | Nastavení projektu Lakebase |
| Připojení k databázi | Informace o možnostech připojení pro Lakebase |
| Registrace databáze v katalogu Unity | Umožněte, aby data Lakebase byla viditelná v katalogu Unity pro sjednocenou správu a dotazy napříč zdroji. |
| Integrace katalogu Unity | Porozumění řízení a oprávněním |
Další možnosti
Informace o synchronizaci dat do jiných systémů než Databricks najdete v tématu Reverzní řešení ETL služby Partner Connect , jako jsou Census nebo Hightouch.