sparklyr
Azure Databricks podporuje sparklyr v poznámkových blocích, úlohách a RStudio Desktopu. Tento článek popisuje, jak můžete používat sparklyr a poskytuje ukázkové skripty, které můžete spustit. Další informace najdete v rozhraní R pro Apache Spark .
Požadavky
Azure Databricks distribuuje nejnovější stabilní verzi sparklyru s každou verzí Databricks Runtime. Minigrafyr můžete použít v poznámkových blocích Azure Databricks R nebo uvnitř RStudio Serveru hostovaného v Azure Databricks importem nainstalované verze sparklyr.
V RStudio Desktopu umožňuje Databricks Connect připojit sparklyr z místního počítače ke clusterům Azure Databricks a spustit kód Apache Sparku. Viz Použití sparklyr a RStudio Desktop s Databricks Connect.
Připojení sparklyru ke clusterům Azure Databricks
Chcete-li vytvořit sparklyr připojení, můžete použít "databricks" jako metodu připojení v spark_connect().
Nejsou potřeba žádné další parametry spark_connect() ani volání spark_install() , protože Spark je už nainstalovaný v clusteru Azure Databricks.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
Indikátory průběhu a uživatelské rozhraní Sparku s minigrafem
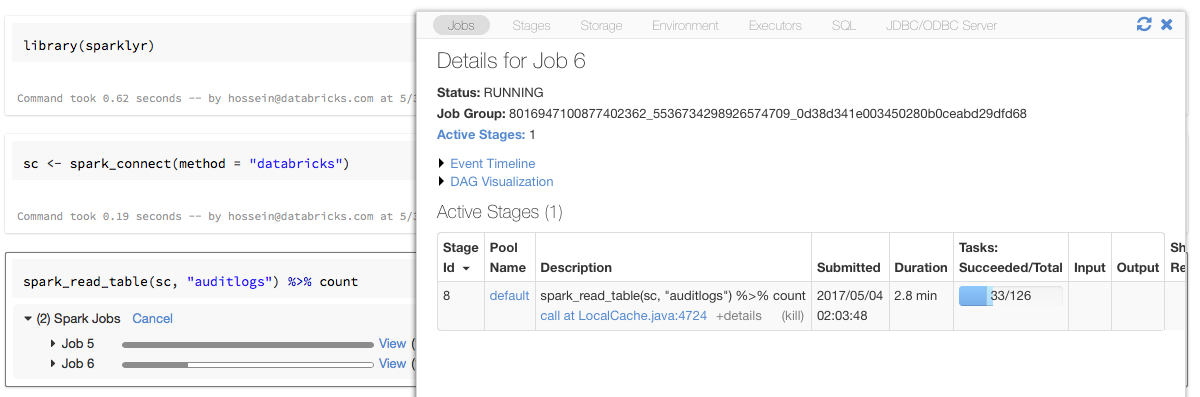
Pokud přiřadíte objekt připojení sparklyr k proměnné pojmenované sc jako v předchozím příkladu, zobrazí se indikátory průběhu Sparku v poznámkovém bloku za každým příkazem, který aktivuje úlohy Sparku.
Kromě toho můžete kliknout na odkaz vedle indikátoru průběhu a zobrazit uživatelské rozhraní Sparku přidružené k dané úloze Sparku.
Použití sparklyru
Po instalaci sparklyru a navázání připojení fungují všechny ostatní sparklyr API stejně jako normálně. Příklady najdete v ukázkovém poznámkovém bloku .
sparklyr se obvykle používá spolu s dalšími balíčky tidyverse, jako je dplyr. Většina těchto balíčků je předinstalovaná ve službě Databricks, aby vám to vyhovuje. Můžete je jednoduše importovat a začít používat rozhraní API.
Použití sparklyru a SparkR společně
SparkR a sparklyr je možné použít společně v jednom poznámkovém bloku nebo úloze. SparkR můžete importovat spolu s sparklyr a používat jeho funkce. V poznámkových blocích Azure Databricks je připojení SparkR předem nakonfigurované.
Některé funkce v SparkR maskuje řadu funkcí v dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Pokud po importu nástroje dplyr naimportujete SparkR, můžete na funkce v dplyru odkazovat pomocí plně kvalifikovaných názvů, dplyr::arrange()například .
Podobně pokud importujete dplyr po SparkR, funkce v SparkR jsou maskovány dplyr.
Alternativně můžete selektivně odpojit jeden ze dvou balíčků, zatímco ho nepotřebujete.
detach("package:dplyr")
Viz také porovnání SparkR a sparklyr.
Použití sparklyru v úlohách spark-submit
Skripty, které používají sparklyr v Azure Databricks jako úlohy spark-submit, můžete spouštět s menšími úpravami kódu. Některé z výše uvedených pokynů se nevztahují na použití sparklyr v úlohách spark-submit v Azure Databricks. Konkrétně je nutné zadat hlavní adresu URL Sparku pro spark_connect. Příklad:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Nepodporované funkce
Azure Databricks nepodporuje metody sparklyr, například spark_web() a spark_log() které vyžadují místní prohlížeč. Vzhledem k tomu, že je uživatelské rozhraní Sparku integrované v Azure Databricks, můžete snadno kontrolovat úlohy a protokoly Sparku.
Viz Protokoly ovladačů a pracovních procesů služby Compute.
Ukázkový poznámkový blok: Sparklyr – ukázka
Poznámkový blok Sparklyr
Další příklady najdete v tématu Práce s datovými rámci a tabulkami v jazyce R.