Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Apache Hadoop byl původní open source architekturou pro distribuované zpracování a analýzy velkých datových sad v clusterech. Ekosystém Hadoop zahrnuje související software a nástroje, včetně Apache Hive, Apache HBase, Sparku, Kafka a mnoha dalších.
Azure HDInsight je plně spravovaná opensourcová analytická služba v cloudu pro podniky. Typ clusteru Apache Hadoop ve službě Azure HDInsight umožňuje používat systém distribuovaných souborů Apache Hadoop (HDFS), správu prostředků Apache Hadoop YARN a jednoduchý programovací model MapReduce pro paralelní zpracování a analýzu dávkových dat. Clustery Hadoop v HDInsight jsou kompatibilní s Azure Data Lake Storage Gen2.
Komponenty technologie Hadoop dostupné ve službě HDInsight najdete v tématu Dostupné komponenty a verze ve službě HDInsight. Další informace o platformě Hadoop v prostředí HDInsight najdete v tématu Funkce Azure pro HDInsight.
Co je MapReduce
Apache Hadoop MapReduce je softwarová architektura pro psaní úloh, které zpracovávají obrovské objemy dat. Vstupní data jsou rozdělená na nezávislé bloky dat. Každý blok dat se zpracovává paralelně napříč uzly v clusteru. Úloha MapReduce se skládá ze dvou funkcí:
Mapper: Využívá vstupní data, analyzuje je (obvykle s operacemi filtrování a řazení) a generuje řazené kolekce členů (páry klíč-hodnota).
Reducer: Zpracovává dvojice vytvořené mapovačem a provádí redukční operaci, která vytvoří menší, kombinovaný výsledek z dat mapovače.
Příklad MapReduce úlohy základního počítání slov je znázorněn v následujícím diagramu:
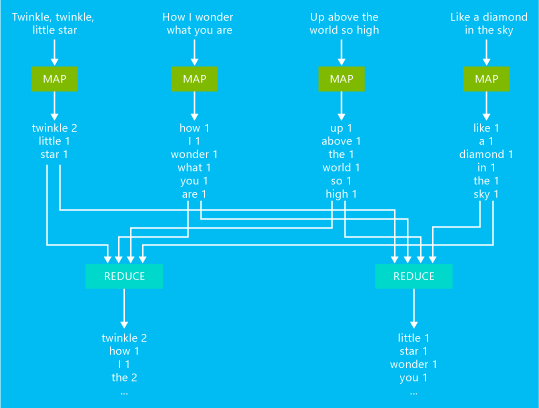
Výstupem této úlohy je počet výskytů jednotlivých slov v textu.
- Mapper vezme každý řádek ze vstupního textu jako vstup a rozdělí ho na slova. Vygeneruje dvojici klíč/hodnota při každém výskytu slova, za kterým následuje 1. Výstup se před odesláním do reduktoru seřadí.
- Reduktor sčítá jednotlivé počty pro každé slovo a vydává jeden pár klíč/hodnota, který obsahuje slovo s celkovým počtem výskytů.
MapReduce je možné implementovat v různých jazycích. Java je nejběžnější implementace a používá se pro demonstrační účely v tomto dokumentu.
Vývojové jazyky
Jazyky nebo architektury založené na Javě a virtuálním počítači Java je možné spustit přímo jako úlohu MapReduce. Příklad použitý v tomto dokumentu je aplikace Java MapReduce. Jazyky mimo Javu, jako jsou C#, Python nebo samostatné spustitelné soubory, musí používat streamování Hadoop.
Streamování Hadoop komunikuje s mapovačem a reduktorem přes STDIN a STDOUT. Mapovač a reduktor načítá data najednou z STDIN a zapisuje výstup do STDOUT. Každý řádek přečtený mapovačem a redukčním nástrojem musí být ve formátu páru klíč/hodnota oddělený znakem tabulátoru:
[key]\t[value]
Další informace najdete v tématu Hadoop Streaming.
Příklady použití streamování Hadoop se službou HDInsight najdete v následujícím dokumentu:
Kde začít
- Rychlý start: Vytvoření clusteru Apache Hadoop ve službě Azure HDInsight pomocí webu Azure Portal
- Kurz: Odesílání úloh Apache Hadoopu ve službě HDInsight
- Vývoj programů Java MapReduce pro Apache Hadoop ve službě HDInsight
- Použití Apache Hivu jako nástroje pro extrakci, transformaci a načítání (ETL)
- Extrakce, transformace a načítání (ETL) ve velkém měřítku
- Zprovoznění kanálu analýzy dat