Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Pomocí nástrojů HDInsight v sadě Azure Toolkit for Eclipse můžete vyvíjet aplikace Apache Spark napsané v Scala a odesílat je do clusteru Azure HDInsight Spark přímo z integrovaného vývojového prostředí Eclipse. Modul plug-in nástroje HDInsight můžete použít několika různými způsoby:
- Vývoj a odeslání aplikace Scala Spark v clusteru HDInsight Spark
- Přístup k prostředkům clusteru Azure HDInsight Spark
- Pokud chcete vyvíjet a spouštět aplikaci Scala Spark místně.
Požadavky
Cluster Apache Spark ve službě HDInsight Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
prostředí Eclipse IDE. Tento článek používá integrované vývojové prostředí Eclipse pro vývojáře v Javě.
Nainstalujte požadované pluginy
Instalace sady Azure Toolkit for Eclipse
Pokyny k instalaci najdete v tématu Instalace sady Azure Toolkit for Eclipse.
Instalace modulu plug-in Scala
Když otevřete Eclipse, nástroje HDInsight automaticky zjistí, jestli jste nainstalovali modul plug-in Scala. Pokračujte výběrem OK a pak podle pokynů nainstalujte modul plug-in z Eclipse Marketplace. Po dokončení instalace restartujte integrované vývojové prostředí (IDE).
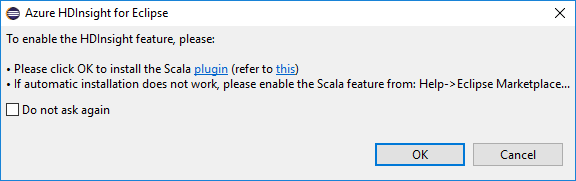
Potvrďte zásuvné moduly
Přejděte do Nápovědy>Eclipse Marketplace....
Vyberte kartu Nainstalovaná.
Měli byste vidět alespoň:
- Azure Toolkit for Eclipse <verze>.
- Scala IDE verze <>.
Přihlaste se ke svému předplatnému Azure.
Spusťte integrované vývojové prostředí Eclipse.
Přejděte do okna >Zobrazit zobrazení>Jiné...>Přihlásit se...
V dialogovém okně Zobrazit přejděte na Azure>Azure Explorera pak vyberte Otevřít.
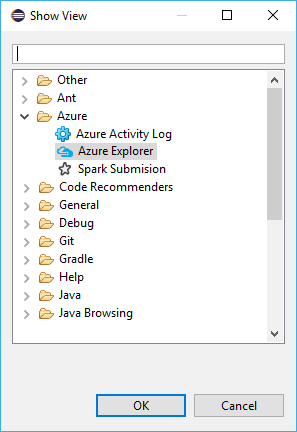
V Azure Exploreruklikněte pravým tlačítkem na uzel Azure a vyberte Přihlásit se.
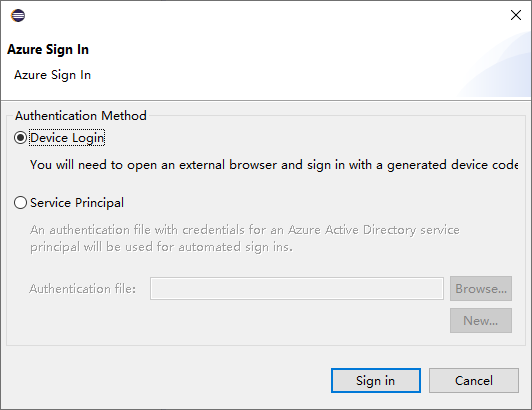
V dialogovém okně přihlášení k Azure zvolte metodu ověřování, vyberte Přihlášenía dokončete proces přihlášení.
Po přihlášení se v dialogovém okně Vaše předplatná zobrazí seznam všech předplatných Azure přidružených k přihlašovacím údajům. Stiskněte , vyberte a zavřete dialogové okno.
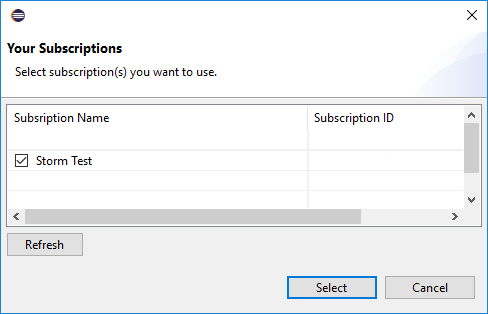
V Azure Explorerupřejděte na azure>HDInsight a prohlédněte si clustery HDInsight Spark v rámci vašeho předplatného.
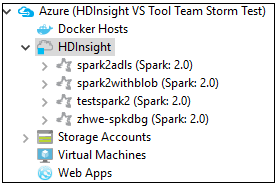
Dále můžete rozbalit uzel názvu clusteru a zobrazit prostředky (například účty úložiště) přidružené ke clusteru.
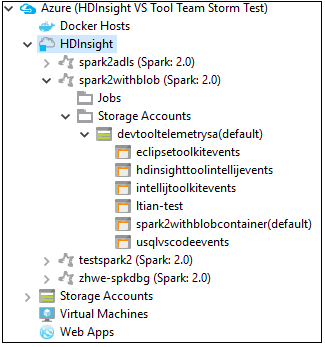
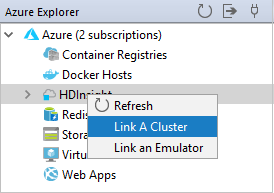
Propojení clusteru
Normální cluster můžete propojit pomocí spravovaného uživatelského jména Ambari. Podobně můžete propojit cluster HDInsight připojený k doméně pomocí domény a uživatelského jména, například user1@contoso.com.
V Průzkumníku Azureklikněte pravým tlačítkem na HDInsighta vyberte Propojit cluster.
Zadejte název clusteru, uživatelské jménoa hesloa pak vyberte OK. Volitelně můžete zadat účet úložiště, klíč úložiště a pak vybrat kontejner úložiště, aby průzkumník úložiště fungoval v levém stromovém zobrazení.
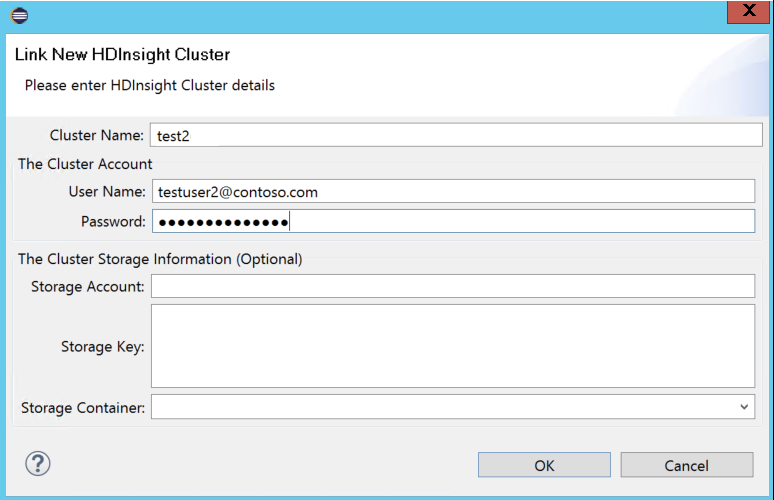
Poznámka:
Použijeme propojený klíč úložiště, uživatelské jméno a heslo, pokud je cluster přihlášen k předplatnému Azure a je propojen se clusterem.
Pokud je aktuální fokus na klávesy Storage, musíte použít Ctrl+TAB, abyste se mohli zaměřit na další pole v dialogovém okně.
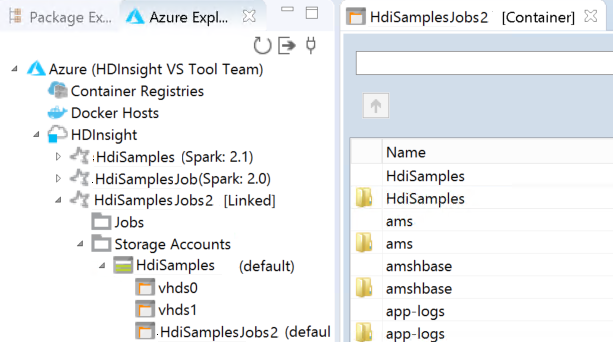
Propojený cluster můžete zobrazit pod HDInsight. Teď můžete odeslat aplikaci do tohoto propojeného clusteru.
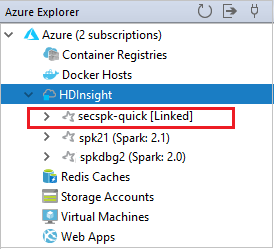
Cluster můžete také odpojit od Azure Exploreru.
Nastavení projektu Spark Scala pro cluster HDInsight Spark
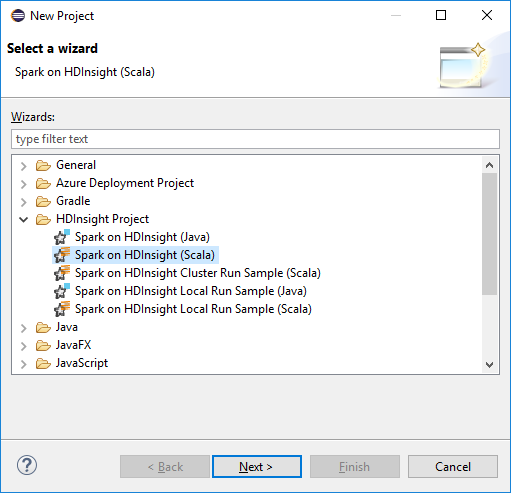
V pracovním prostoru integrovaného vývojového prostředí Eclipse vyberte Soubor>Nový projekt>....
V průvodci Nový projekt vyberte HDInsight Projekt>Spark na HDInsight (Scala). Pak vyberte Další.
V dialogovém okně Nový projekt HDInsight Scala zadejte následující hodnoty a pak vyberte Další:
- Zadejte název projektu.
- V oblasti prostředí JRE se ujistěte, že Použití spouštěcího prostředí JRE je nastaveno na JavaSE-1.7 nebo novější.
- V oblasti knihovny Sparku můžete zvolit Pomocí Mavenu nakonfigurovat sadu Spark SDK. Náš nástroj integruje správnou verzi sady Spark SDK a Scala SDK. Můžete také zvolit možnost Přidat sadu Spark SDK ručně, stáhnout a přidat sadu Spark SDK ručně.
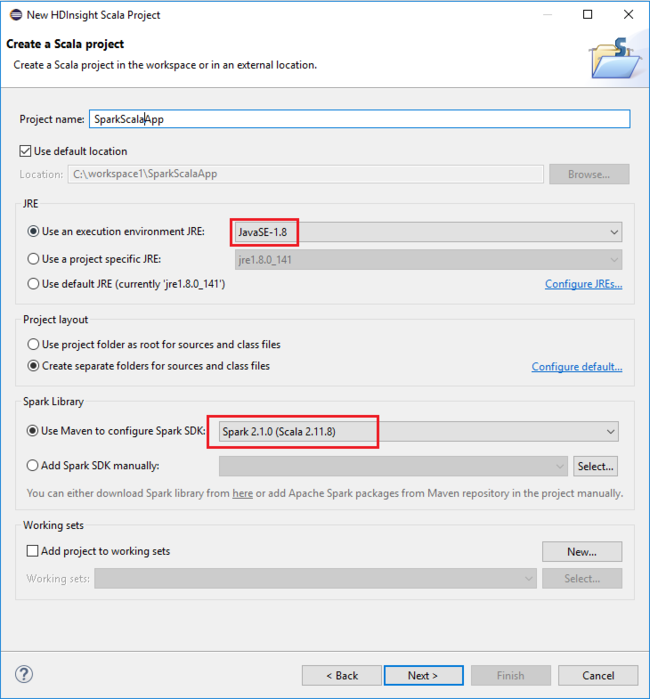
V dalším dialogovém okně zkontrolujte podrobnosti a pak vyberte Dokončit.
Vytvoření aplikace Scala pro cluster HDInsight Spark
V Průzkumníku balíčkůrozbalte projekt, který jste vytvořili dříve. Klikněte pravým tlačítkem na src, vyberte Nový>Jiný....
V dialogovém okně Vyberte průvodce vyberte Průvodci Scala>objektu Scala. Pak vyberte Další.
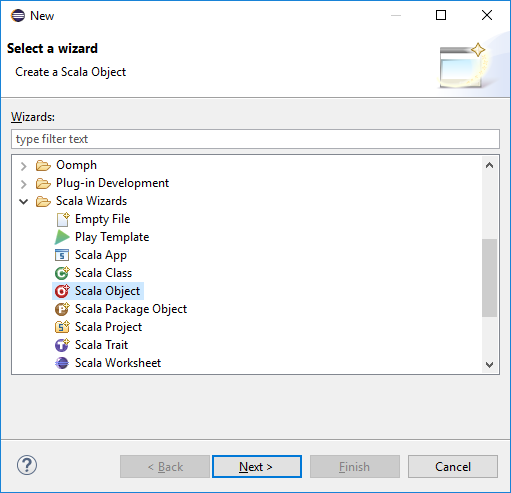
V dialogovém okně Vytvořit nový soubor zadejte název objektu a vyberte Dokončit. Otevře se textový editor.
V textovém editoru nahraďte aktuální obsah následujícím kódem:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Spusťte aplikaci v clusteru HDInsight Spark:
a. V Průzkumníku balíčků klikněte pravým tlačítkem myši na název projektu a pak vyberte Odeslat aplikaci Spark do HDInsight.
b) V dialogovém okně Spark Submission zadejte následující hodnoty a pak vyberte Odeslat:
Jako název clusteruvyberte cluster HDInsight Spark, na kterém chcete aplikaci spustit.
Vyberte artefakt z projektu Eclipse nebo ho vyberte z pevného disku. Výchozí hodnota závisí na položce, na kterou kliknete pravým tlačítkem v Průzkumníku balíčků.
V rozevíracím seznamu Název hlavní třídy průvodce odesláním zobrazí veškeré názvy objektů z vašeho projektu. Vyberte nebo zadejte, který chcete spustit. Pokud jste vybrali artefakt z pevného disku, musíte zadat název hlavní třídy ručně.
Vzhledem k tomu, že kód aplikace v tomto příkladu nevyžaduje žádné argumenty příkazového řádku ani odkazy na JARy nebo soubory, můžete zbývající textová pole ponechat prázdná.
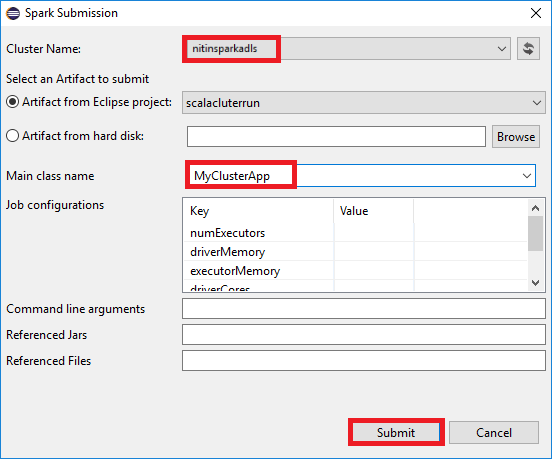
Na kartě Spark Submission by se měl začít zobrazovat průběh. Aplikaci můžete zastavit kliknutím na červené tlačítko v okně Spark Submission. Protokoly pro tuto konkrétní aplikaci můžete zobrazit také tak, že vyberete ikonu zeměkoule (označenou modrým rámečkem na obrázku).
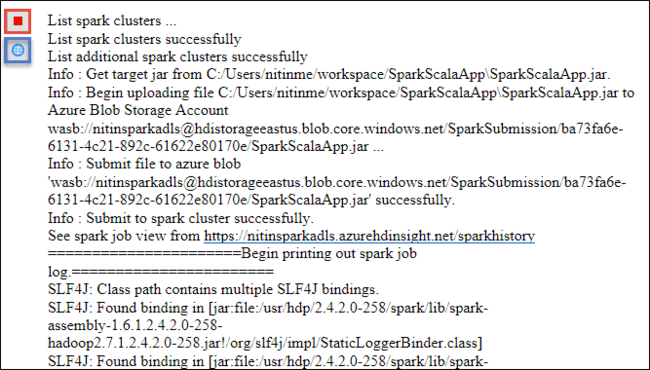
Přístup ke clusterům HDInsight Spark a jejich správa pomocí nástrojů HDInsight v sadě Azure Toolkit for Eclipse
Různé operace můžete provádět pomocí nástrojů HDInsight, včetně přístupu k výstupu úlohy.
Přístup k zobrazení úlohy
V Azure Explorerurozbalte HDInsight, pak název clusteru Spark, a pak vyberte Úlohy.
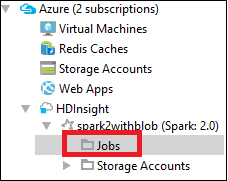
Vyberte uzel Úlohy. Pokud je verze Javy nižší než 1.8, nástroje HDInsight vás automaticky upozorní na nutnost instalace pluginu E(fx)clipse. Pokračujte výběrem OK a pak postupujte podle průvodce a nainstalujte ho z Eclipse Marketplace a restartujte Eclipse.
Otevřete Job View z uzlu Jobs. V pravém podokně se na kartě zobrazení úloh Sparku zobrazí všechny aplikace spuštěné v clusteru. Vyberte název aplikace, pro kterou chcete zobrazit další podrobnosti.
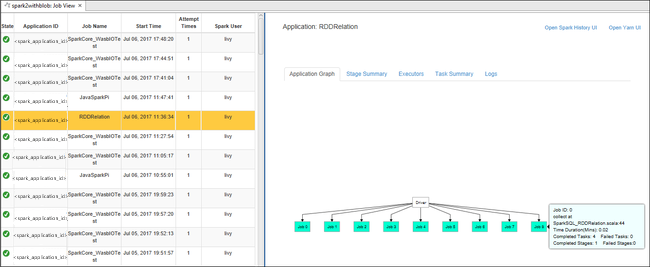
Pak můžete provést některou z těchto akcí:
Přejeďte myší nad grafem práce. Zobrazí základní údaje o spuštěné úloze. Vyberte graf úlohy a můžete zobrazit fáze a informace, které každá úloha generuje.
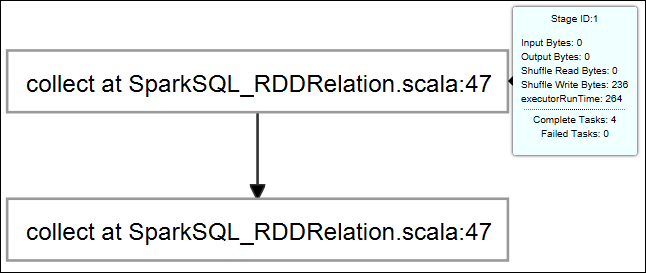
Vyberte kartu protokolu a zobrazte často používané protokoly, včetně Driver Stderr, Driver Stdouta Directory Info.
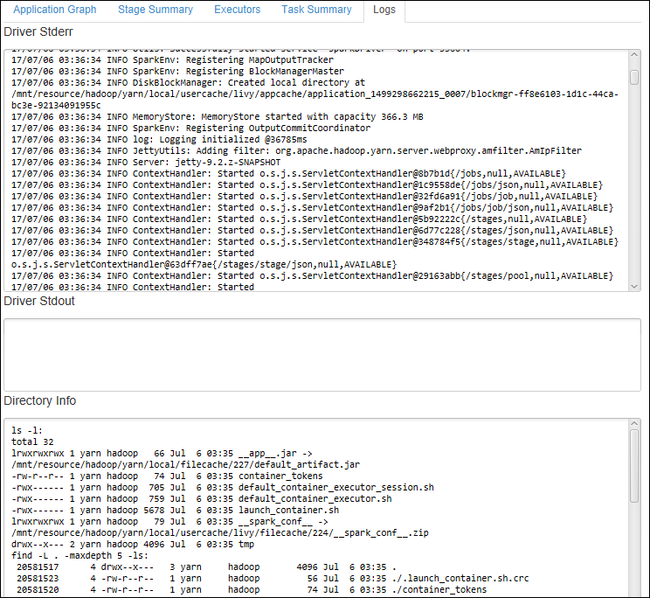
Otevřete uživatelské rozhraní historie Sparku a uživatelské rozhraní Apache Hadoop YARN (na úrovni aplikace) výběrem hypertextových odkazů v horní části okna.
Přístup ke kontejneru úložiště pro cluster
V Azure Exploreru rozbalte HDInsight kořenový uzel a zobrazte seznam dostupných clusterů HDInsight Spark.
Kliknutím na název clusteru zobrazíte účet úložiště a výchozí úložný kontejner pro cluster.
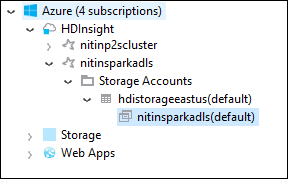
Vyberte název kontejneru úložiště přidružený ke clusteru. V pravém podokně poklikejte na složku HVACOut. Otevřete jeden z souborů, abyste viděli výstup aplikace.
Přístup k serveru historie Sparku
V Azure Exploreru klikněte pravým tlačítkem myši na název clusteru Spark a poté vyberte Otevřít uživatelské rozhraní historie Spark. Po zobrazení výzvy zadejte přihlašovací údaje správce clusteru. Zadali jste je při zřizování clusteru.
Na řídicím panelu serveru historie Sparku použijete název aplikace k vyhledání aplikace, kterou jste právě dokončili. V předchozím kódu nastavíte název aplikace pomocí
val conf = new SparkConf().setAppName("MyClusterApp"). Název aplikace Spark byl tedy MyClusterApp.
Spuštění portálu Apache Ambari
V Azure Exploreru klikněte pravým tlačítkem na název clusteru Spark a pak vyberte Otevřít portál pro správu clusteru (Ambari).
Po zobrazení výzvy zadejte přihlašovací údaje správce clusteru. Zadali jste je při zřizování clusteru.
Správa předplatných Azure
Ve výchozím nastavení obsahuje nástroj HDInsight v sadě Azure Toolkit for Eclipse seznam clusterů Spark ze všech vašich předplatných Azure. V případě potřeby můžete zadat předplatná, pro která chcete získat přístup ke clusteru.
V Azure Exploreru klikněte pravým tlačítkem na kořenový uzel Azure a pak vyberte Spravovat předplatná.
V dialogovém okně zrušte zaškrtnutí políček u předplatného, ke kterému nechcete přistupovat, a pak vyberte Zavřít. Pokud se chcete odhlásit ze svého předplatného Azure, můžete také vybrat Odhlásit se.
Místní spuštění aplikace Spark Scala
Pomocí nástrojů HDInsight v sadě Azure Toolkit for Eclipse můžete spouštět aplikace Spark Scala místně na pracovní stanici. Tyto aplikace obvykle nepotřebují přístup k prostředkům clusteru, jako je kontejner úložiště, a můžete je spustit a otestovat místně.
Předpoklad
Při spouštění místní aplikace Spark Scala na počítači s Windows se může zobrazit výjimka, jak je vysvětleno v SPARK-2356. K této výjimce dochází, protože v systému Windows chybí WinUtils.exe.
Pokud chcete tuto chybu vyřešit, potřebujete Winutils.exe do umístění, jako je C:\WinUtils\bin, a pak přidejte proměnnou prostředí HADOOP_HOME a nastavte hodnotu proměnné na C\WinUtils.
Spuštění místní aplikace Spark Scala
Spusťte Eclipse a vytvořte projekt. V dialogovém okně Nový projekt proveďte následující volby a pak vyberte Další.
V průvodci Nový projekt vyberte projekt HDInsight>Spark na HDInsight Local Run Sample (Scala). Pak vyberte Další.
Pokud chcete zadat podrobnosti o projektu, postupujte podle kroků 3 až 6 z předchozí části Nastavení projektu Spark Scala pro cluster HDInsight Spark.
Šablona přidá vzorový kód (LogQuery) do složky src, kterou můžete spustit místně na svém počítači.
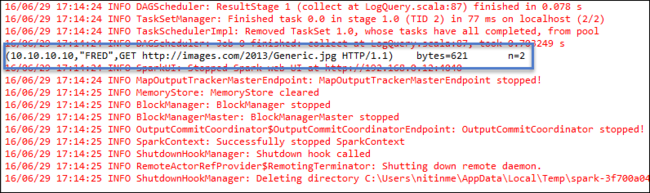
Klikněte pravým tlačítkem na LogQuery.scala a vyberte Spustit jako>1aplikace Scala . Výstup podobný tomuto se zobrazí na kartě konzoly:
Role jen pro čtení
Když uživatelé odešlou úlohu do clusteru s oprávněním role jen pro čtení, vyžaduje se přihlašovací údaje Ambari.
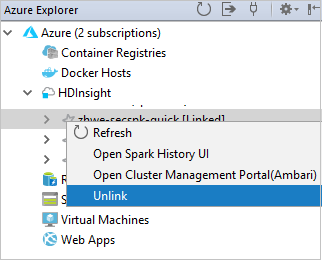
Propojení clusteru z místní nabídky
Přihlaste se pomocí účtu role jen pro čtení.
V Azure Explorerurozbalte HDInsight a zobrazte clustery HDInsight, které jsou ve vašem předplatném. Clustery označené Role:Reader mají pouze oprávnění role jen pro čtení.
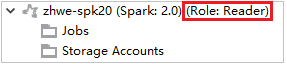
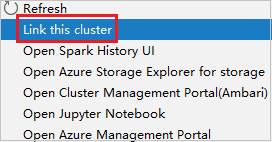
Klikněte pravým tlačítkem na cluster s oprávněním jen pro čtení. Vyberte Propojit tento cluster z místní nabídky pro propojení clusteru. Zadejte uživatelské jméno a heslo Ambari.
Pokud je cluster úspěšně propojený, služba HDInsight se aktualizuje. Fáze clusteru se propojí.
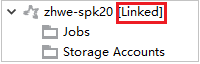
Propojení clusteru rozbalením uzlu Úlohy
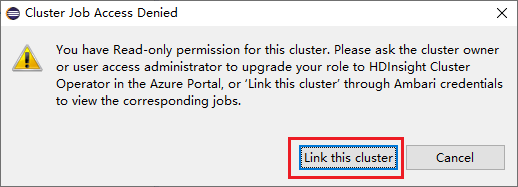
Klikněte na Uzly úloh, objeví se okno Odepření přístupu k úloze clusteru.
Klikněte na pro propojení clusteru.
Odkaz na cluster z okna pro odeslání Sparku
Vytvořte projekt HDInsight.
Klikněte pravým tlačítkem myši na balíček. Pak vyberte Odeslat aplikaci Spark do služby HDInsight.
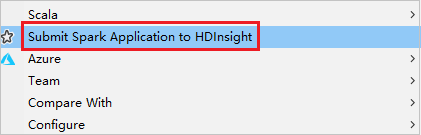
Vyberte cluster, který má oprávnění role pro čtení pro název clustera . Zobrazí se varovná zpráva. K propojení klastru můžete kliknout na Propojit tento klastr.
Zobrazení účtů úložiště
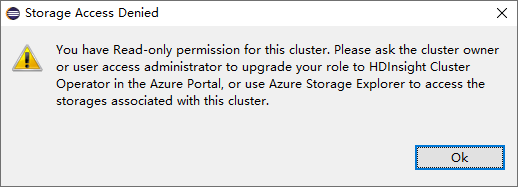
U clusterů s oprávněním role jen pro čtení klikněte na uzel účty úložiště, zobrazí se okno Odepřen přístup k úložišti.
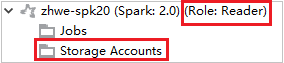
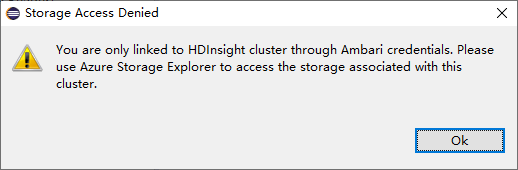
U propojených clusterů klikněte na uzel Účty úložiště a objeví se okno Přístup k úložišti byl odepřen.
Známé problémy
Při použití Link A clusterbych vám doporučil poskytnout přihlašovací údaje úložiště dat.
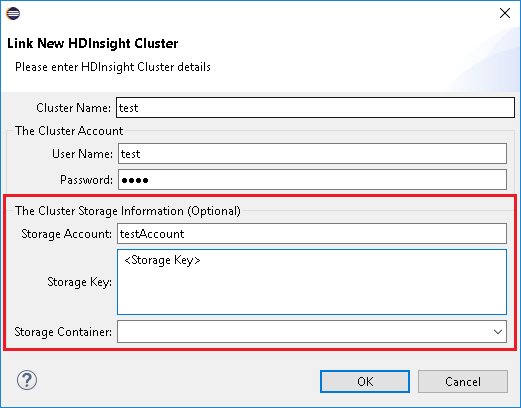
Existují dvě možnosti, jak úlohy odesílat. Pokud je k dispozici přihlašovací údaje úložiště, použije se k odeslání úlohy dávkový režim. Jinak se použije interaktivní režim. Pokud je cluster zaneprázdněný, může se zobrazit následující chyba.


Viz také
Scénáře
- Apache Spark s BI: Provádění interaktivní analýzy dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
Vytváření a spouštění aplikací
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
Nástroje a rozšíření
- použití sady Azure Toolkit for IntelliJ k vytváření a odesílání aplikací Spark Scala
- Použití sady Azure Toolkit for IntelliJ k vzdálenému ladění aplikací Apache Spark prostřednictvím sítě VPN
- použití sady Azure Toolkit for IntelliJ k vzdálenému ladění aplikací Apache Spark prostřednictvím SSH
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Dostupná jádra pro Jupyter Notebook v clusteru Apache Spark pro HDInsight
- Použití externích balíčků s Jupyter poznámkovými bloky
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark