Hluboké a strojové učení ve službě Azure Machine Learning
Tento článek vysvětluje hluboké učení vs. strojové učení a jejich přizpůsobení do širší kategorie umělé inteligence. Seznamte se s řešeními hlubokého učení, která můžete vytvářet ve službě Azure Machine Learning, jako je detekce podvodů, rozpoznávání hlasu a rozpoznávání obličeje, analýza mínění a prognózování časových řad.
Pokyny k výběru algoritmů pro vaše řešení najdete v stručné nápovědě k algoritmům strojového učení.
Základní modely ve službě Azure Machine Learning jsou předem natrénované modely hlubokého učení, které je možné vyladit pro konkrétní případy použití. Přečtěte si další informace o základních modelech (Preview) ve službě Azure Machine Learning a o tom, jak používat základní modely ve službě Azure Machine Learning (Preview).
Hluboké učení, strojové učení a AI
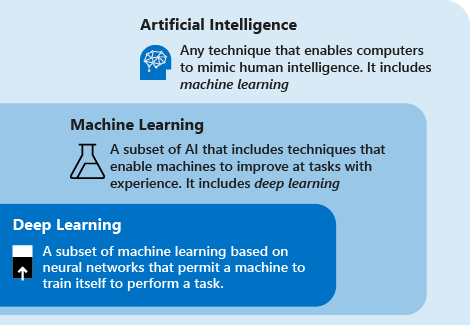
Zvažte následující definice, abyste porozuměli hlubokému učení vs. strojovému učení a umělé inteligenci:
Hluboké učení je podmnožina strojového učení, která je založená na umělých neurálních sítích. Proces učení je hluboký, protože struktura umělých neurálních sítí se skládá z několika vstupních, výstupních a skrytých vrstev. Každá vrstva obsahuje jednotky, které transformují vstupní data na informace, jež může další vrstva použít pro určitou prediktivní úlohu. Díky této struktuře se počítač může učit prostřednictvím vlastního zpracování dat.
Strojové učení je podmnožina umělé inteligence, která využívá techniky (například hluboké učení), které umožňují počítačům využívat zkušenosti ke zlepšení úloh. Proces učení je založený na následujících krocích:
- Nasílte data do algoritmu. (V tomto kroku můžete modelu poskytnout další informace, například provedením extrakce funkcí.)
- Tato data slouží k trénování modelu.
- Otestujte a nasaďte model.
- Využití nasazeného modelu k automatizované prediktivní úloze (Jinými slovy, volání a použití nasazeného modelu k přijetí předpovědí vrácených modelem.)
Umělá inteligence (AI) je technika, která umožňuje počítačům napodobovat lidskou inteligenci. Zahrnuje strojové učení.
Generování umělé inteligence je podmnožinou umělé inteligence, která používá techniky (například hluboké učení) k vygenerování nového obsahu. Pomocí generující umělé inteligence můžete například vytvářet obrázky, text nebo zvuk. Tyto modely využívají k vygenerování tohoto obsahu obrovské předem natrénované znalosti.
Pomocí technik strojového učení a hlubokého učení můžete vytvářet počítačové systémy a aplikace, které provádějí úlohy, které jsou běžně spojené s lidskou inteligencí. Mezi tyto úlohy patří rozpoznávání obrázků, rozpoznávání řeči a překlad jazyka.
Techniky hlubokého učení a strojového učení
Teď, když máte přehled strojového učení a hlubokého učení, pojďme porovnat dvě techniky. Ve strojovém učení je potřeba algoritmus říct, jak vytvořit přesnou předpověď tím, že využívá více informací (například provedením extrakce funkcí). V hlubokém učení se algoritmus může naučit, jak vytvořit přesnou předpověď prostřednictvím vlastního zpracování dat díky struktuře umělé neurální sítě.
Následující tabulka porovnává tyto dvě techniky podrobněji:
| Všechny strojové učení | Pouze hluboké učení | |
|---|---|---|
| Počet datových bodů | K předpovědím můžete použít malé množství dat. | K předpovědím je potřeba použít velké objemy trénovacích dat. |
| Hardwarové závislosti | Může pracovat na počítačích s nízkou úrovní. Nepotřebuje velké množství výpočetního výkonu. | Závisí na špičkových počítačích. Ze své podstaty se dělá velký počet operací násobení matice. GPU může tyto operace efektivně optimalizovat. |
| Proces featurizace | Vyžaduje, aby byly funkce přesně identifikovány a vytvořeny uživateli. | Naučte se funkce vysoké úrovně z dat a vytvářejí nové funkce samostatně. |
| Přístup k učení | Rozdělí proces učení na menší kroky. Potom zkombinuje výsledky z každého kroku do jednoho výstupu. | Prochází procesem učení tím, že problém vyřešíte na komplexní bázi. |
| Doba provádění | Trénování trvá poměrně málo času, od několika sekund do několika hodin. | Trénování obvykle trvá dlouho, protože algoritmus hlubokého učení zahrnuje mnoho vrstev. |
| Výstup | Výstup je obvykle číselná hodnota, například skóre nebo klasifikace. | Výstup může mít více formátů, například text, skóre nebo zvuk. |
Co je transferové učení?
Modely hlubokého učení trénování často vyžadují velké objemy trénovacích dat, vysoce endových výpočetních prostředků (GPU, TPU) a delší dobu trénování. V situacích, kdy nemáte k dispozici žádnou z těchto možností, můžete proces trénování zástupcem pomocí techniky známé jako transferové učení.
Transfer learning je technika, která využívá znalosti získané z řešení jednoho problému na jiný, ale související problém.
Vzhledem ke struktuře neurálních sítí obsahuje první sada vrstev obvykle funkce nižší úrovně, zatímco konečná sada vrstev obsahuje funkce vyšší úrovně, které jsou blíže dané doméně. Použitím konečné vrstvy pro použití v nové doméně nebo problému můžete výrazně snížit množství času, dat a výpočetních prostředků potřebných k trénování nového modelu. Pokud už například máte model, který rozpoznává auta, můžete tento model znovu použít k rozpoznávání nákladních vozů, motocyklů a dalších druhů vozidel.
Naučte se používat transferové učení pro klasifikaci obrázků pomocí opensourcové architektury ve službě Azure Machine Learning: Trénování modelu PyTorch hlubokého učení pomocí transferového učení.
Případy použití hlubokého učení
Z důvodu struktury umělé neurální sítě se hluboké učení vyniká identifikací vzorů v nestrukturovaných datech, jako jsou obrázky, zvuk, video a text. Z tohoto důvodu hluboké učení rychle transformuje mnoho odvětví, včetně zdravotnictví, energetiky, financí a dopravy. Tato odvětví nyní přemýšlí tradiční obchodní procesy.
Některé z nejběžnějších aplikací pro hluboké učení jsou popsány v následujících odstavcích. Ve službě Azure Machine Learning můžete použít model vytvořený z opensourcové architektury nebo sestavit model pomocí poskytnutých nástrojů.
Rozpoznávání pojmenovaných entit
Rozpoznávání pojmenovaných entit je metoda hlubokého učení, která přebírá část textu jako vstup a transformuje ji na předem zadanou třídu. Tyto nové informace můžou být PSČ, datum, ID produktu. Tyto informace se pak dají uložit ve strukturovaném schématu a vytvořit seznam adres nebo sloužit jako srovnávací test pro ověřovací modul identity.
Detekce objektů
Hluboké učení bylo použito v mnoha případech použití rozpoznávání objektů. Rozpoznávání objektů se používá k identifikaci objektů na obrázku (například aut nebo osob) a poskytnutí konkrétního umístění pro každý objekt s ohraničujícím rámečkem.
Rozpoznávání objektů se už používá v odvětvích, jako jsou hry, maloobchod, cestovní ruch a autojezdové automobily.
Generování titulků obrázků
Stejně jako rozpoznávání obrázků musí systém u daného obrázku vygenerovat titulek, který popisuje obsah obrázku. Když můžete rozpoznat a označovat objekty na fotografiích, dalším krokem je přeměna těchto popisků na popisné věty.
Popisky obrázků obvykle používají konvoluční neurální sítě k identifikaci objektů na obrázku a následné použití opakující se neurální sítě k přeměně popisků na konzistentní věty.
Strojový překlad
Strojový překlad přebírá slova nebo věty z jednoho jazyka a automaticky je překládá do jiného jazyka. Strojové překlady už dlouhou dobu existují, ale hluboké učení dosahuje působivých výsledků ve dvou konkrétních oblastech: automatický překlad textu (a překlad řeči na text) a automatický překlad obrázků.
S příslušnou transformací dat dokáže neurální síť porozumět textovému, zvukovému a vizuálnímu signálu. Strojový překlad lze použít k identifikaci fragmentů zvuku ve větších zvukových souborech a přepis mluveného slova nebo obrázku jako textu.
Analýza textu
Analýza textu založená na metodách hlubokého učení zahrnuje analýzu velkého množství textových dat (například lékařských dokumentů nebo účtenek výdajů), rozpoznávání vzorů a vytváření uspořádaných a stručných informací.
Společnosti používají hluboké učení k analýze textu k detekci interního obchodování a dodržování předpisů státní správy. Dalším běžným příkladem je podvod s pojištěním: Analýza textu se často používá k analýze velkých objemů dokumentů, aby bylo možné rozpoznat pravděpodobnost, že pojistné nároky jsou podvody.
Umělé neurální sítě
Umělé neurální sítě jsou tvořeny vrstvami připojených uzlů. Modely hlubokého učení používají neurální sítě, které mají velký počet vrstev.
V následujících částech jsou prozkoumány nejoblíbenější topologie umělé neurální sítě.
Informační neurální síť
Neurální síť je nejjednodušším typem umělé neurální sítě. V síti informačního kanálu se informace přesunou pouze jedním směrem ze vstupní vrstvy do výstupní vrstvy. Průchozí neurální sítě transformují vstup tím, že ho umístí do řady skrytých vrstev. Každá vrstva je tvořena sadou neuronů a každá vrstva je plně propojena se všemi neurony ve vrstvě předtím. Poslední plně propojená vrstva (výstupní vrstva) představuje vygenerované předpovědi.
Rekurentní neurální sítě (RNN)
Rekurentní neurální sítě jsou široce využívanou umělou neurální sítí. Tyto sítě ukládají výstup vrstvy a odsílají ho zpět do vstupní vrstvy, aby pomohly předpovědět výsledek vrstvy. Rekurentní neurální sítě mají skvělé schopnosti učení. Běžně se používají pro složité úlohy, jako je prognózování časových řad, učení rukopisu a rozpoznávání jazyka.
Konvoluční neurální sítě (CNN)
Konvoluční neurální síť je zvlášť efektivní umělá neurální síť a představuje jedinečnou architekturu. Vrstvy jsou uspořádány ve třech rozměrech: šířka, výška a hloubka. Neurony v jedné vrstvě se připojují ne ke všem neuronům v další vrstvě, ale pouze k malé oblasti neuronů vrstvy. Konečný výstup se zmenší na jeden vektor skóre pravděpodobnosti uspořádaného podle rozměru hloubky.
Konvoluční neurální sítě se používají v oblastech, jako je rozpoznávání videa, rozpoznávání obrázků a doporučovací systémy.
Generativní kontradiktorní sítě (GAN)
Generující nežádoucí sítě jsou generující modely natrénované tak, aby vytvářely realistický obsah, jako jsou obrázky. Skládá se ze dvou sítí označovaných jako generátor a diskriminace. Obě sítě se trénují současně. Během trénování generátor používá náhodný šum k vytvoření nových syntetických dat, která se úzce podobají skutečným datům. Diskriminátor přebírá výstup z generátoru jako vstup a používá reálná data k určení, zda je generovaný obsah skutečný nebo syntetický. Každá síť se vzájemně konkuruje. Generátor se snaží generovat syntetický obsah, který je nerozlišitelný od skutečného obsahu a diskriminátor se snaží správně klasifikovat vstupy jako skutečné nebo syntetické. Výstup se pak použije k aktualizaci váhy obou sítí, aby jim pomohl lépe dosáhnout příslušných cílů.
Generující nežádoucí sítě se používají k řešení problémů, jako je obrázek k překladu obrázků a průběh věku.
Transformátory
Transformátory jsou modelová architektura, která je vhodná pro řešení problémů obsahujících sekvence, jako jsou textová nebo časová řada dat. Skládají se z vrstvy kodéru a dekodéru. Kodér vezme vstup a mapuje ho na číselnou reprezentaci obsahující informace, jako je kontext. Dekodér používá informace z kodéru k vytvoření výstupu, jako je přeložený text. Čím se transformátory liší od jiných architektur obsahujících kodéry a dekodéry, jsou dílčí vrstvy pozornosti. Pozornost je myšlenka zaměření na konkrétní části vstupu na základě důležitosti jejich kontextu ve vztahu k jiným vstupům v sekvenci. Například při shrnutí příspěvku, ne všechny věty jsou relevantní k popisu hlavní myšlenky. Když se zaměříte na klíčová slova v celém článku, můžete souhrn provést v jedné větě, nadpisu.
Transformátory byly použity k řešení problémů se zpracováním přirozeného jazyka, jako je překlad, generování textu, zodpovězení otázek a shrnutí textu.
Mezi dobře známé implementace transformátorů patří:
- Obousměrné reprezentace kodéru z transformátorů (BERT)
- Generační předem natrénovaný transformátor 2 (GPT-2)
- Vytrénovaný předtrénovaný transformátor 3 (GPT-3)
Další kroky
Následující články ukazují další možnosti použití opensourcových modelů hlubokého učení ve službě Azure Machine Learning: