Jak používat základní modely Open Source kurátorované službou Azure Machine Učení
V tomto článku se dozvíte, jak v katalogu modelů doladit, vyhodnotit a nasadit základní modely.
Jakýkoli předem natrénovaný model můžete rychle otestovat pomocí formuláře Ukázkové odvozování na kartě modelu a zadat vlastní ukázkový vstup k otestování výsledku. Kromě toho karta modelu pro každý model obsahuje stručný popis modelu a odkazy na ukázky pro odvozování založené na kódu, vyladění a vyhodnocení modelu.
Jak vyhodnotit základní modely pomocí vlastních testovacích dat
Základní model můžete vyhodnotit pro testovací datovou sadu pomocí formuláře Vyhodnotit uživatelské rozhraní nebo pomocí ukázek založených na kódu, které jsou propojené z karty modelu.
Vyhodnocení pomocí studia
Formulář Vyhodnotit model můžete vyvolat výběrem tlačítka Vyhodnotit na kartě modelu pro libovolný základní model.
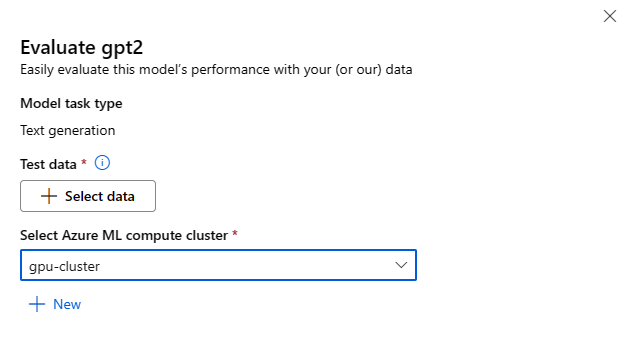
Každý model lze vyhodnotit pro konkrétní úlohu odvozování, pro kterou se model použije.
Testovací data:
- Předejte testovací data, která chcete použít k vyhodnocení modelu. Můžete buď nahrát místní soubor (ve formátu JSONL), nebo vybrat existující registrovanou datovou sadu z vašeho pracovního prostoru.
- Po výběru datové sady je potřeba namapovat sloupce ze vstupních dat na základě schématu potřebného pro úkol. Například namapujte názvy sloupců, které odpovídají klíčům "věta" a "label" pro klasifikaci textu.

Výpočty:
Zadejte cluster Azure Machine Učení Compute, který chcete použít k vyladění modelu. Vyhodnocení musí běžet na výpočetních prostředcích GPU. Ujistěte se, že máte dostatečnou kvótu výpočetních prostředků pro výpočetní skladové položky, které chcete použít.
Výběrem možnosti Dokončit ve formuláři Vyhodnocení odešlete úlohu vyhodnocení. Po dokončení úlohy můžete zobrazit metriky vyhodnocení modelu. Na základě metrik vyhodnocení se můžete rozhodnout, jestli chcete model vyladit pomocí vlastních trénovacích dat. Kromě toho se můžete rozhodnout, jestli chcete model zaregistrovat a nasadit ho do koncového bodu.
Vyhodnocení pomocí ukázek založených na kódu
Abychom uživatelům umožnili začít s vyhodnocením modelu, publikovali jsme ukázky (jak poznámkové bloky Pythonu, tak příklady rozhraní příkazového řádku) v ukázkách vyhodnocení v úložišti Git s příklady azureml.< a1/>. Každá karta modelu také odkazuje na ukázky vyhodnocení pro odpovídající úlohy.
Vyladění základních modelů pomocí vlastních trénovacích dat
Pokud chcete zlepšit výkon modelu ve vaší úloze, můžete chtít základní model doladit pomocí vlastních trénovacích dat. Tyto základní modely můžete snadno vyladit pomocí nastavení jemného ladění v sadě studio nebo pomocí ukázek založených na kódu, které jsou propojené z karty modelu.
Vyladění pomocí studia
Formulář nastavení jemného ladění můžete vyvolat tak, že vyberete tlačítko Doladit na kartě modelu pro libovolný základní model.
Vyladění Nastavení:
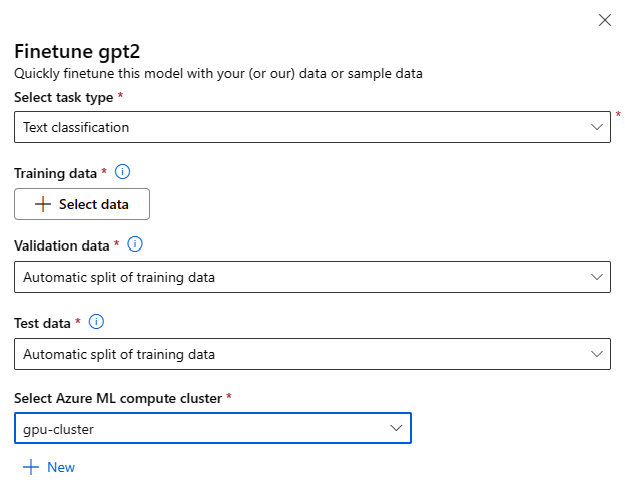
Typ úlohy jemného ladění
- Každý předem natrénovaný model z katalogu modelů je možné doladit pro určitou sadu úkolů (například klasifikace textu, klasifikace tokenu, odpověď na otázky). V rozevíracím seznamu vyberte úkol, který chcete použít.
Trénovací data
Předejte trénovací data, která chcete použít k vyladění modelu. Můžete buď nahrát místní soubor (ve formátu JSONL, CSV nebo TSV), nebo vybrat existující registrovanou datovou sadu z vašeho pracovního prostoru.
Po výběru datové sady je potřeba namapovat sloupce ze vstupních dat na základě schématu potřebného pro úkol. Příklad: mapování názvů sloupců, které odpovídají klíčům "věta" a "label" pro klasifikaci textu

- Ověřovací data: Předejte data, která chcete použít k ověření modelu. Výběrem možnosti Automatické rozdělení se automaticky rozdělí trénovací data pro ověření. Případně můžete zadat jinou ověřovací datovou sadu.
- Testovací data: Předejte testovací data, která chcete použít k vyhodnocení jemně vyladěného modelu. Výběrem možnosti Automatické rozdělení se automaticky rozdělí trénovací data pro testování.
- Výpočetní prostředky: Zadejte výpočetní cluster Azure Učení, který chcete použít k vyladění modelu. Jemné ladění musí běžet na výpočetních prostředcích GPU. Při vyladění doporučujeme používat skladové položky výpočetních prostředků s grafickými procesory A100 / V100. Ujistěte se, že máte dostatečnou kvótu výpočetních prostředků pro výpočetní skladové položky, které chcete použít.
- Výběrem možnosti Dokončit ve formuláři pro vyladění odešlete úlohu jemného ladění. Po dokončení úlohy můžete zobrazit metriky vyhodnocení pro jemně vyladěný model. Výstup jemně vyladěného modelu pak můžete zaregistrovat pomocí úlohy vyladění a nasadit tento model do koncového bodu pro odvozování.
Vyladění pomocí ukázek založených na kódu
Azure Machine Učení v současné době podporuje jemně dolaďovací modely pro následující úlohy jazyka:
- Klasifikace textu
- Klasifikace tokenů
- Odpovídání na dotazy
- Souhrn
- Překlad
Abychom uživatelům umožnili rychle začít s vyladěním, publikovali jsme ukázky (jak poznámkové bloky Pythonu, tak příklady rozhraní příkazového řádku) pro každou úlohu v ukázkách Git Finetune v úložišti Azureml-examples. Každá karta modelu také odkazuje na ukázky jemného ladění podporovaných úloh jemného ladění.
Nasazení základních modelů do koncových bodů pro odvozování
Základní modely (předem natrénované modely z katalogu modelů a jemně vyladěné modely, jakmile jsou zaregistrované do vašeho pracovního prostoru) můžete nasadit do koncového bodu, který se pak dá použít k odvozování. Podporuje se nasazení do koncových bodů v reálném čase i dávkových koncových bodů. Tyto modely můžete nasadit pomocí průvodce nasazením uživatelského rozhraní nebo pomocí ukázek založených na kódu, které jsou propojené z karty modelu.
Nasazení pomocí studia
Formulář Nasadit uživatelské rozhraní můžete vyvolat výběrem tlačítka Nasadit na kartě modelu pro libovolný základní model a výběrem koncového bodu v reálném čase nebo koncového bodu služby Batch.

Nastavení nasazení
Vzhledem k tomu, že bodovací skript a prostředí jsou automaticky součástí základního modelu, stačí zadat skladovou položku virtuálního počítače, která se má použít, počet instancí a název koncového bodu pro nasazení.
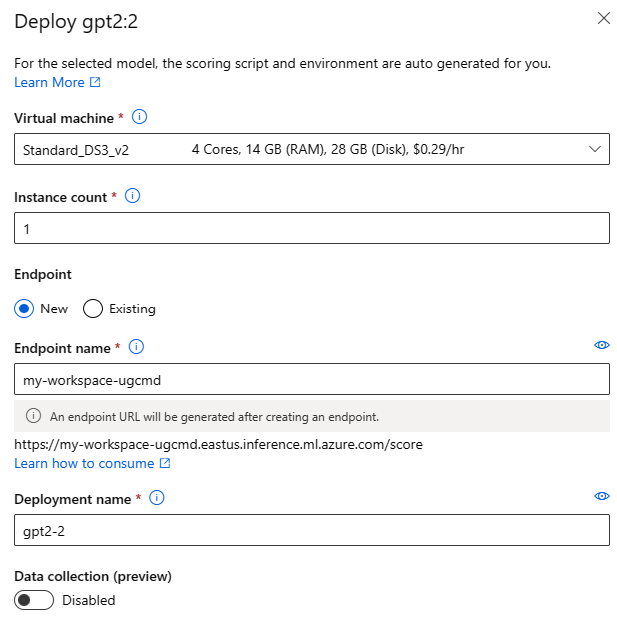
Sdílená kvóta
Pokud nasazujete model Llama-2, Phi, Nemotron, Mistral, Dolly nebo Deci-DeciLM z katalogu modelů, ale nemáte k dispozici dostatečnou kvótu pro nasazení, azure machine Učení vám umožní použít kvótu ze sdíleného fondu kvót po omezenou dobu. Další informace o sdílené kvótě najdete v tématu Sdílená kvóta služby Azure Machine Learning.

Nasazení pomocí ukázek založených na kódu
Abychom uživatelům umožnili rychle začít s nasazením a odvozováním, publikovali jsme ukázky v ukázkách odvozování v úložišti azureml-examples git. Publikované ukázky zahrnují poznámkové bloky Pythonu a příklady rozhraní příkazového řádku. Každá karta modelu také odkazuje na ukázky odvozování v reálném čase a dávkové odvozování.
Import základních modelů
Pokud chcete použít opensourcový model, který není součástí katalogu modelů, můžete model importovat z Hugging Face do svého pracovního prostoru Azure Machine Učení. Hugging Face je opensourcová knihovna pro zpracování přirozeného jazyka (NLP), která poskytuje předem natrénované modely pro oblíbené úlohy NLP. Import modelu v současné době podporuje import modelů pro následující úlohy, pokud model splňuje požadavky uvedené v poznámkovém bloku importu modelu:
- výplňová maska
- klasifikace tokenů
- odpovídání na otázky
- Souhrnu
- generování textu
- klasifikace textu
- Překlad
- klasifikace obrázků
- text-to-image
Poznámka:
Modely z Hugging Face podléhají licenčním podmínkám třetích stran, které jsou k dispozici na stránce podrobností modelu Hugging Face. Je vaší zodpovědností dodržovat licenční podmínky modelu.
Pokud chcete použít poznámkový blok importu modelu, můžete vybrat tlačítko Importovat v pravém horním rohu katalogu modelů.
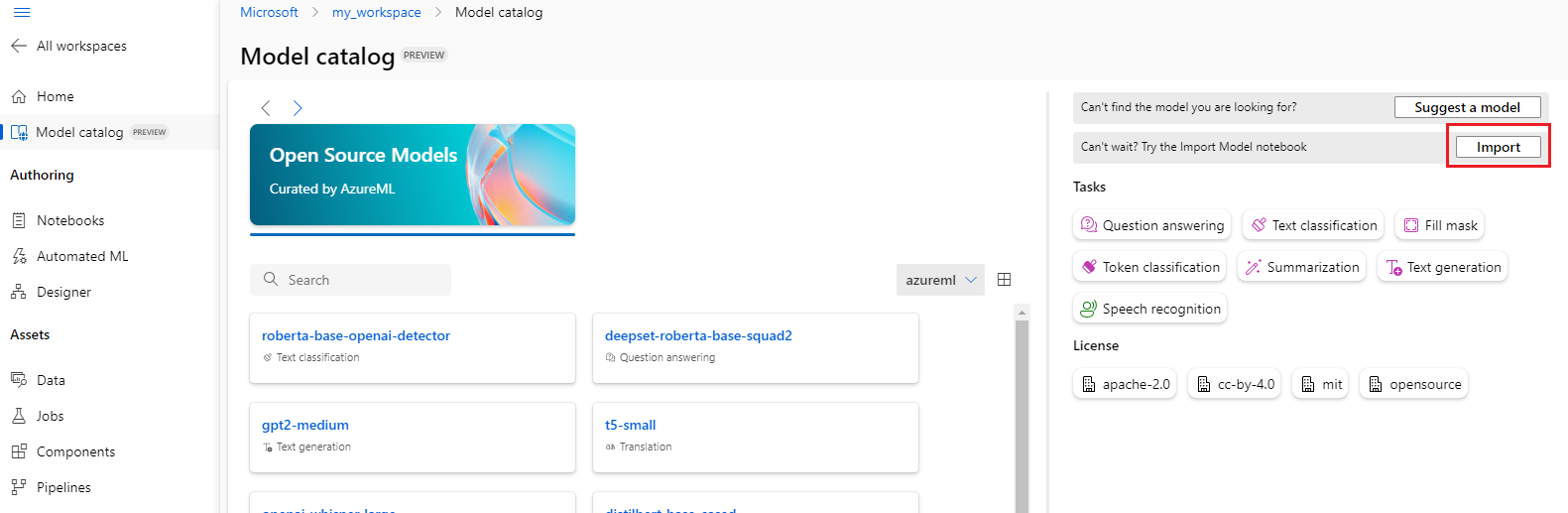
Poznámkový blok pro import modelu je také součástí úložiště Git s příklady azureml.
Pokud chcete model importovat, musíte předat MODEL_ID model, který chcete importovat z Hugging Face. Projděte si modely v centru Hugging Face a identifikujte model, který chcete importovat. Ujistěte se, že typ úlohy modelu patří mezi podporované typy úloh. Zkopírujte ID modelu, které je k dispozici v identifikátoru URI stránky nebo lze zkopírovat pomocí ikony kopírování vedle názvu modelu. Přiřaďte ji k proměnné MODEL_ID v poznámkovém bloku importu modelu. Příklad:
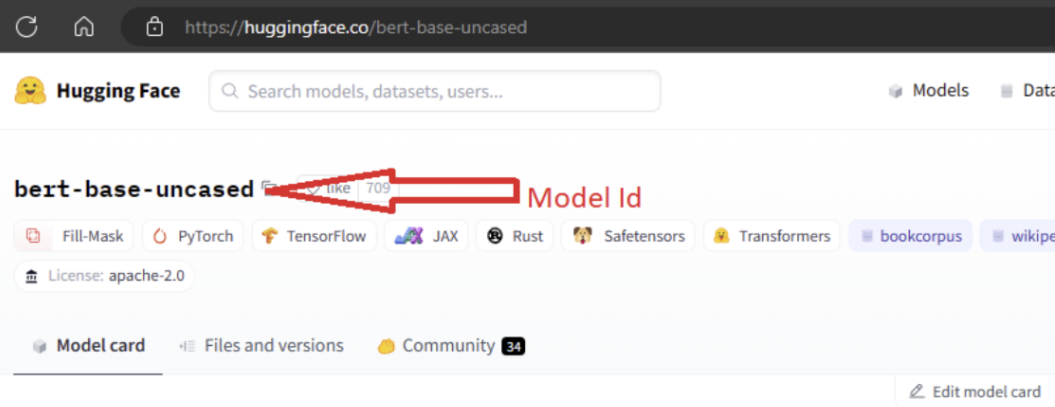
Musíte poskytnout výpočetní prostředky pro spuštění importu modelu. Spuštění importu modelu způsobí import zadaného modelu z Hugging Face a zaregistruje se do vašeho pracovního prostoru Učení Azure Machine. Pak můžete tento model doladit nebo ho nasadit do koncového bodu pro odvozování.
Další informace
- Prozkoumejte katalog modelů v studio Azure Machine Learning. K prozkoumání katalogu potřebujete pracovní prostor Azure Machine Učení.
- Prozkoumání katalogu modelů a kolekcí