Posouzení chyb v modelech strojového učení
Jedním z největších problémů s aktuálními postupy ladění modelů je použití agregovaných metrik k určení skóre modelů u datové sady srovnávacích testů. Přesnost modelu nemusí být jednotná napříč podskupinami dat a můžou existovat vstupní kohorty, pro které model častěji selže. Přímými důsledky těchto selhání jsou nedostatek spolehlivosti a bezpečnosti, vzhled problémů spravedlnosti a ztráta důvěry v strojové učení úplně.

Analýza chyb se přesune od metrik agregované přesnosti. Zpřístupňuje distribuci chyb vývojářům transparentním způsobem a umožňuje jim efektivně identifikovat a diagnostikovat chyby.
Komponenta analýzy chyb na řídicím panelu Zodpovědné umělé inteligence poskytuje odborníkům na strojové učení hlubší znalosti distribuce selhání modelu a pomáhá jim rychle identifikovat chybné kohorty dat. Tato komponenta identifikuje kohorty dat s vyšší chybovostí a celkovou chybovost srovnávacího testu. Přispívá k identifikaci fáze pracovního postupu životního cyklu modelu prostřednictvím:
- Rozhodovací strom, který odhalí kohorty s vysokými mírami chyb.
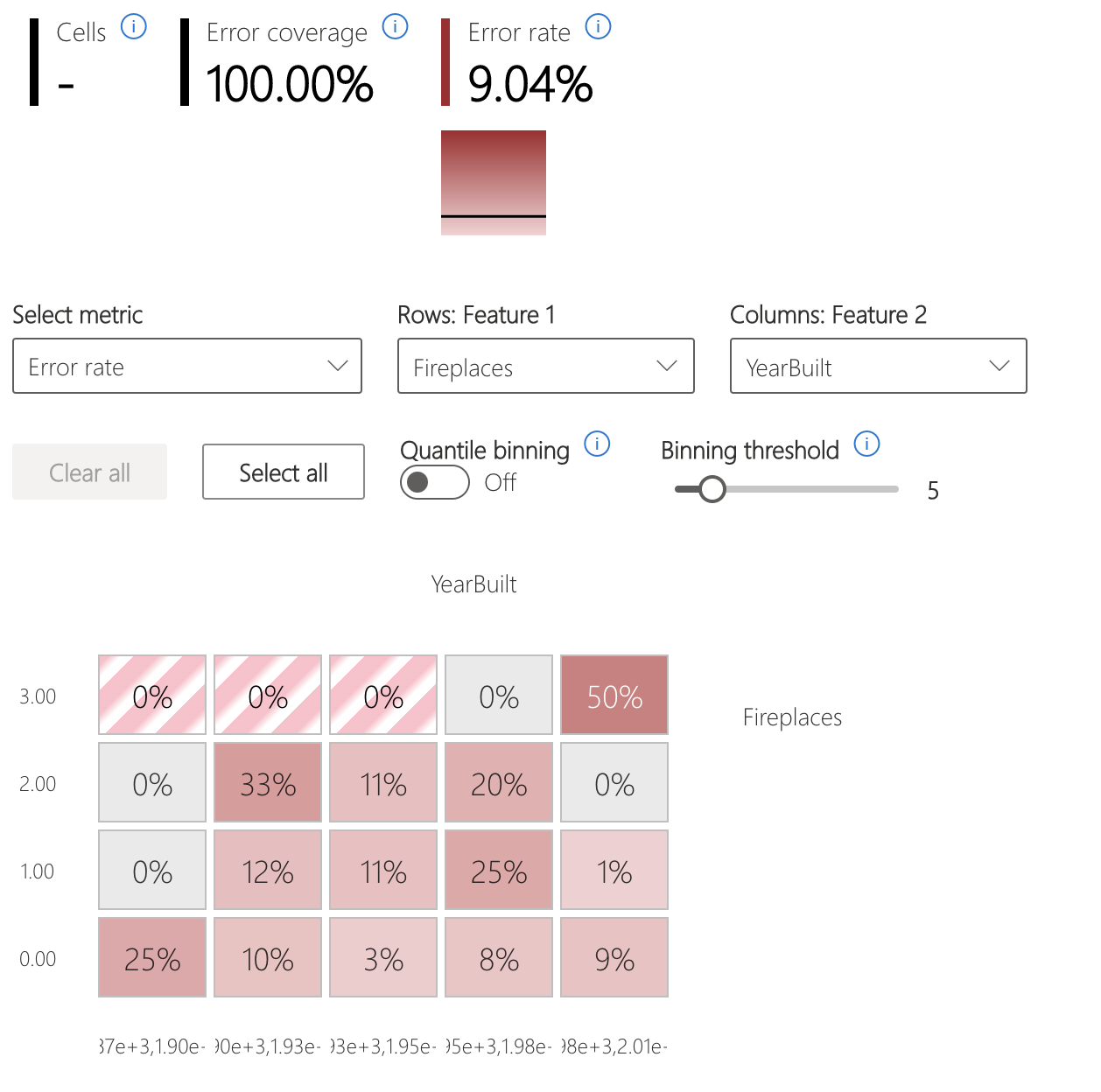
- Heat mapa, která vizualizuje, jak vstupní funkce ovlivňují chybovost napříč kohortami.
K nesrovnalostem v chybách může dojít v případě, že systém v trénovacích datech nepřesáhne určité demografické skupiny nebo zřídka pozorované vstupní kohorty.
Možnosti této komponenty pocházejí z balíčku Analýza chyb, který generuje profily chyb modelu.
Analýzu chyb použijte v případě, že potřebujete:
- Získejte hluboké znalosti o tom, jak se selhání modelu distribuují napříč datovou sadou a napříč několika dimenzemi vstupu a funkcí.
- Rozdělte agregované metriky výkonu tak, aby automaticky zjistily chybné kohorty, abyste mohli informovat cílené kroky pro zmírnění rizik.
Strom chyb
Vzory chyb jsou často složité a zahrnují více než jednu nebo dvě funkce. Vývojáři můžou mít potíže s prozkoumáním všech možných kombinací funkcí, aby objevili skryté datové kapsy s kritickými selháními.
Kvůli zmírnění zátěže vizualizace binárního stromu automaticky rozdělí data srovnávacího testu do interpretovatelných podskupin, které mají neočekávaně vysokou nebo nízkou chybovost. Jinými slovy, strom používá vstupní funkce k maximálnímu oddělení chyby modelu od úspěchu. Pro každý uzel, který definuje podskupinu dat, můžou uživatelé prozkoumat následující informace:
- Míra chyb: Část instancí v uzlu, pro kterou je model nesprávný. Zobrazuje se intenzitou červené barvy.
- Pokrytí chyb: Část všech chyb, které spadají do uzlu. Zobrazuje se v rychlosti vyplnění uzlu.
- Reprezentace dat: Počet instancí v každém uzlu stromu chyb. Zobrazuje se přes tloušťku příchozího okraje k uzlu spolu s celkovým počtem instancí v uzlu.

Chyba heat mapy
Zobrazení rozkryje data na základě jednorozměrné nebo dvourozměrné mřížky vstupních funkcí. Uživatelé můžou zvolit vstupní funkce, které jsou pro analýzu zajímavé.
Heat mapa vizualizuje buňky s vysokou chybou pomocí tmavší červené barvy, která uživatele upozorní na tyto oblasti. Tato funkce je zvlášť užitečná, když se motivy chyb liší v různých oddílech, což se často stává v praxi. V tomto zobrazení identifikace chyb je analýza vysoce řízená uživateli a jejich znalostmi nebo hypotézami o tom, jaké funkce můžou být pro pochopení selhání nejdůležitější.
Další kroky
- Zjistěte, jak vygenerovat řídicí panel zodpovědné umělé inteligence prostřednictvím rozhraní příkazového řádku a sady SDK nebo studio Azure Machine Learning uživatelského rozhraní.
- Prozkoumejte podporované vizualizace analýzy chyb.
- Zjistěte, jak vygenerovat přehled výkonnostních metrik Zodpovědné AI na základě přehledů zjištěných na řídicím panelu Zodpovědné umělé inteligence.