Nastavení trénování AutoML pomocí Pythonu
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V této příručce se dozvíte, jak nastavit automatizované strojové učení, AutoML, trénování s využitím sady Azure Machine Learning Python SDK pomocí automatizovaného strojového učení Azure Machine Learning. Automatizované strojové učení pro vás vybere algoritmus a hyperparametry a vygeneruje model připravený k nasazení. Tato příručka obsahuje podrobnosti o různých možnostech, které můžete použít ke konfiguraci experimentů automatizovaného strojového učení.
Kompletní příklad najdete v tématu Kurz: AutoML– trénovací regresní model.
Pokud dáváte přednost prostředí bez kódu, můžete také nastavit trénování AutoML bez kódu v studio Azure Machine Learning.
Požadavky
Pro tento článek potřebujete:
Pracovní prostor služby Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření prostředků pracovního prostoru.
Nainstalovaná sada Azure Machine Learning Python SDK. Pokud chcete nainstalovat sadu SDK, kterou můžete provést,
Vytvořte výpočetní instanci, která automaticky nainstaluje sadu SDK a je předem nakonfigurovaná pro pracovní postupy ML. Další informace najdete v tématu Vytvoření a správa výpočetní instance služby Azure Machine Learning.
automlNainstalujte balíček sami, který zahrnuje výchozí instalaci sady SDK.
Důležité
Příkazy Pythonu v tomto článku vyžadují nejnovější
azureml-train-automlverzi balíčku.- Nainstalujte nejnovější
azureml-train-automlbalíček do místního prostředí. - Podrobnosti o nejnovějším
azureml-train-automlbalíčku najdete v poznámkách k verzi.
Upozorňující
Python 3.8 není kompatibilní s
automl.
Výběr typu experimentu
Než začnete experimentovat, měli byste určit typ problému strojového učení, který řešíte. Automatizované strojové učení podporuje typy classificationúloh , regressiona forecasting. Přečtěte si další informace o typech úkolů.
Poznámka:
Podpora úloh zpracování přirozeného jazyka (NLP): klasifikace obrázků (více tříd a více popisků) a rozpoznávání pojmenovaných entit je k dispozici ve verzi Public Preview. Přečtěte si další informace o úlohách NLP v automatizovaném strojovém učení.
Tyto funkce ve verzi Preview jsou poskytovány bez smlouvy o úrovni služeb. Některé funkce nemusí být podporované nebo mohou mít omezené funkce. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Následující kód používá task parametr v AutoMLConfig konstruktoru k určení typu experimentu jako classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Zdroj a formát dat
Automatizované strojové učení podporuje data nacházející se na místním desktopu nebo v cloudu, například ve službě Azure Blob Storage. Data je možné číst do datového rámce Pandas nebo tabulkové datové sady Azure Machine Learning. Další informace o datových sadách
Požadavky na trénovací data ve strojovém učení:
- Data musí být v tabulkové podobě.
- Hodnota, která se má předpovědět, cílový sloupec, musí být v datech.
Důležité
Automatizované experimenty ML nepodporují trénování u datových sad, které používají přístup k datům založeným na identitě.
U vzdálených experimentů musí být trénovací data přístupná ze vzdáleného výpočetního prostředí. Automatizované strojové učení přijímá pouze tabulkové datové sady Azure Machine Learning při práci na vzdáleném výpočetním prostředí.
Datové sady Azure Machine Learning zveřejňují funkce umožňující:
- Snadno přenášet data ze statických souborů nebo zdrojů adres URL do pracovního prostoru.
- Zpřístupnění dat pro trénovací skripty při využití cloudových výpočetních prostředků Podívejte se, jak trénovat s datovými sadami , například použití
Datasettřídy k připojení dat ke vzdálenému cílovému výpočetnímu objektu.
Následující kód vytvoří TabularDataset z webové adresy URL. Informace o vytváření datových sad z jiných zdrojů, jako jsou místní soubory a úložiště dat, najdete v tématu Vytvoření tabulkové datové sady .
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Pro místní výpočetní experimenty doporučujeme datové rámce pandas pro rychlejší zpracování.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Trénování, ověřování a testování dat
Můžete zadat samostatná trénovací data a sady ověřovacích dat přímo v konstruktoru AutoMLConfig . Přečtěte si další informace o konfiguraci trénování, ověřování, křížového ověřování a testování dat pro experimenty AutoML.
Pokud explicitně nezadáte validation_data parametr nebo n_cross_validation parametr, automatizované strojové učení použije výchozí techniky k určení způsobu provedení ověření. Toto určení závisí na počtu řádků v datové sadě přiřazené k vašemu training_data parametru.
| Velikost trénovacích dat | Technika ověřování |
|---|---|
| Větší než 20 000 řádků | Použije se rozdělení dat trénování/ověření. Výchozí hodnota je 10 % počáteční trénovací sady dat jako ověřovací sady. Tato ověřovací sada se pak používá pro výpočet metrik. |
| Menší než 20 000 řádků | Použije se přístup křížového ověřování. Výchozí počet záhybů závisí na počtu řádků. Pokud je datová sada menší než 1 000 řádků, použije se 10 složených záhybů. Pokud jsou řádky v rozmezí 1 000 až 20 000, použijí se tři záhyby. |
Tip
Testovací data (Preview) můžete nahrát k vyhodnocení modelů, které pro vás automatizované strojové učení vygenerovalo. Tyto funkce jsou experimentální funkce ve verzi Preview a můžou se kdykoli změnit. Naučte se:
- Předejte testovací data do objektu AutoMLConfig.
- Otestujte modely automatizovaného strojového učení vygenerovaného pro váš experiment.
Pokud dáváte přednost prostředí bez kódu, přečtěte si krok 12 v části Nastavení AutoML pomocí uživatelského rozhraní studia.
Velké objemy dat
Automatizované strojové učení podporuje omezený počet algoritmů pro trénování velkých dat, které můžou úspěšně vytvářet modely pro velké objemy dat na malých virtuálních počítačích. Heuristika automatizovaného strojového učení závisí na vlastnostech, jako je velikost dat, velikost paměti virtuálního počítače, nastavení časového limitu experimentu a featurizace, abyste zjistili, jestli se mají použít tyto velké datové algoritmy. Přečtěte si další informace o modelech podporovaných v automatizovaném strojovém učení.
Pro regresi sestup online gradientní regresor a rychlý lineární regresor
Pro klasifikaci, Averaged Perceptron Classifier a Linear SVM Classifier; kde lineární klasifikátor SVM má velké data i malé datové verze.
Pokud chcete tyto heuristiky přepsat, použijte následující nastavení:
| Úloha | Nastavení | Notes |
|---|---|---|
| Blokování algoritmů streamování dat | blocked_modelsAutoMLConfig v objektu a vypište modely, které nechcete použít. |
Výsledkem je selhání spuštění nebo dlouhá doba běhu. |
| Použití algoritmů streamování dat | allowed_modelsAutoMLConfig v objektu a vypište modely, které chcete použít. |
|
| Použití algoritmů streamování dat (experimenty s uživatelským rozhraním studia) |
Zablokujte všechny modely s výjimkou algoritmů pro velké objemy dat, které chcete použít. |
Výpočetní prostředí pro spuštění experimentu
Dále určete, kde bude model trénován. Experiment automatizovaného trénování STROJOVÉho učení může běžet na následujících možnostech výpočetních prostředků.
Zvolte místní výpočetní prostředky: Pokud se váš scénář týká počátečních průzkumů nebo ukázek pomocí malých dat a krátkých vlaků (tj. sekund nebo pár minut na spuštění dítěte), může být lepší volbou trénování na místním počítači. Není čas nastavení, prostředky infrastruktury (váš počítač nebo virtuální počítač) jsou přímo dostupné. Příklad místního výpočetního prostředí najdete v tomto poznámkovém bloku.
Zvolte výpočetní cluster vzdáleného strojového učení: Pokud trénujete s většími datovými sadami, jako je třeba v produkčním trénování, které potřebují delší trénování, vzdálený výpočetní výkon zajistí mnohem lepší výkon na konci, protože
AutoMLbude paralelizovat trénování v uzlech clusteru. Na vzdáleném výpočetním prostředí se doba spuštění interní infrastruktury přidá přibližně 1,5 minuty na podřízené spuštění a další minuty pro infrastrukturu clusteru, pokud virtuální počítače ještě nejsou spuštěné a spuštěné.Spravované výpočetní prostředky Azure Machine Learning jsou spravovaná služba, která umožňuje trénovat modely strojového učení na clusterech virtuálních počítačů Azure. Výpočetní instance se také podporuje jako cílový výpočetní objekt.Cluster Azure Databricks ve vašem předplatném Azure. Další podrobnosti najdete v článku Nastavení clusteru Azure Databricks pro automatizované strojové učení. Příklady poznámkových bloků s využitím Azure Databricks najdete na této stránce na GitHubu.
Při výběru cílového výpočetního objektu zvažte tyto faktory:
| Výhody (výhody) | Nevýhody (Handicapy) | |
|---|---|---|
| Místní cílový výpočetní objekt | ||
| Výpočetní clustery vzdáleného strojového učení |
Konfigurace nastavení experimentu
Existuje několik možností, které můžete použít ke konfiguraci experimentu automatizovaného strojového učení. Tyto parametry jsou nastaveny vytvořením instance objektu AutoMLConfig . Úplný seznam parametrů najdete ve třídě AutoMLConfig.
Následující příklad je určen pro úkol klasifikace. Experiment používá váhu AUC jako primární metriku a má časový limit experimentu nastavený na 30 minut a 2 záhyby křížového ověření.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Můžete také nakonfigurovat úlohy prognózování, které vyžadují další nastavení. Další podrobnosti najdete v článku Nastavení AutoML pro prognózování časových řad.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Podporované modely
Automatizované strojové učení zkouší různé modely a algoritmy během procesu automatizace a ladění. Jako uživatel nemusíte zadávat algoritmus.
Tři různé task hodnoty parametrů určují seznam algoritmů nebo modelů, které se mají použít. allowed_models Pomocí parametrů můžete blocked_models dále upravit iterace s dostupnými modely, které chcete zahrnout nebo vyloučit.
Následující tabulka shrnuje podporované modely podle typu úlohy.
Poznámka:
Pokud plánujete exportovat modely vytvořené automatizovaného strojového učení do modelu ONNX, je možné převést do formátu ONNX pouze tyto algoritmy označené hvězdičkou (hvězdička). Přečtěte si další informace o převodu modelů na ONNX.
Všimněte si také, že ONNX v tuto chvíli podporuje pouze úlohy klasifikace a regrese.
Primární metrika
Parametr primary_metric určuje metriku, která se má použít během trénování modelu pro optimalizaci. Dostupné metriky, které můžete vybrat, jsou určeny typem úkolu, který zvolíte.
Výběr primární metriky pro automatizované strojové učení k optimalizaci závisí na mnoha faktorech. Doporučujeme, abyste zvolili metriku, která nejlépe reprezentuje vaše obchodní potřeby. Pak zvažte, jestli je metrika vhodná pro váš profil datové sady (velikost dat, rozsah, distribuce tříd atd.). Následující části shrnují doporučené primární metriky na základě typu úlohy a obchodního scénáře.
Seznamte se s konkrétními definicemi těchto metrik v tématu Vysvětlení výsledků automatizovaného strojového učení.
Metriky pro scénáře klasifikace
Metriky závislé na prahových hodnotách, jako accuracyje například , recall_score_weightednorm_macro_recalla precision_score_weighted nemusí se optimalizovat ani pro datové sady, které jsou malé, mají velmi velkou distribuci tříd (nevyváženost třídy) nebo pokud je očekávaná hodnota metriky velmi blízko 0,0 nebo 1,0. V takových případech AUC_weighted může být lepší volbou pro primární metriku. Po dokončení automatizovaného strojového učení si můžete vybrat vítězný model na základě metriky, která nejlépe vyhovuje vašim obchodním potřebám.
| Metrika | Příklady případů použití |
|---|---|
accuracy |
Klasifikace obrázků, analýza mínění, predikce četnosti změn |
AUC_weighted |
Detekce podvodů, klasifikace obrázků, detekce anomálií / detekce spamu |
average_precision_score_weighted |
Analýza postoje |
norm_macro_recall |
Předpověď četnosti změn |
precision_score_weighted |
Metriky pro scénáře regrese
r2_scorenormalized_mean_absolute_error a normalized_root_mean_squared_error snaží se minimalizovat chyby předpovědi. r2_score a normalized_root_mean_squared_error současně minimalizují průměrné kvadratické chyby, zatímco normalized_mean_absolute_error se při minizaci průměrné absolutní hodnoty chyb minimalizují. Absolutní hodnota zpracovává chyby ve všech velikostech stejně a kvadratické chyby budou mít mnohem větší trest za chyby s většími absolutními hodnotami. V závislosti na tom, zda by větší chyby měly být potrestány více nebo ne, můžete se rozhodnout optimalizovat kvadratické chyby nebo absolutní chybu.
Hlavní rozdíl mezi r2_score a normalized_root_mean_squared_error je způsob, jakým jsou normalizovány a jejich významy. normalized_root_mean_squared_error je odmocněná střední kvadratická chyba normalizována podle rozsahu a lze ji interpretovat jako průměrnou velikost chyby pro předpověď. r2_score je střední kvadratická chyba normalizována odhadem odchylky dat. Jedná se o poměr variant, který lze zachytit modelem.
Poznámka:
r2_score a normalized_root_mean_squared_error také se chovají podobně jako primární metriky. Pokud se použije pevná ověřovací sada, tyto dvě metriky optimalizují stejný cíl, střední kvadratická chyba a budou optimalizovány stejným modelem. Pokud je k dispozici pouze trénovací sada a použije se křížové ověření, bude se mírně lišit, protože normalizátor normalized_root_mean_squared_error pro je pevně nastaven jako rozsah trénovací sady, ale normalizátor pro r2_score každé záhyby se bude lišit, protože se jedná o odchylku pro každou složenou záhybu.
Pokud je pořadí místo přesné hodnoty zajímavé, může být lepší volbou, spearman_correlation protože měří korelaci pořadí mezi skutečnými hodnotami a předpověďmi.
V současné době ale žádné primární metriky pro regresní adresy řeší relativní rozdíl. Všechny funkce r2_score, normalized_mean_absolute_errora normalized_root_mean_squared_error zacházet s chybou předpovědi 20 000 KČ pro pracovníka s 30k platem pracovníka, který činí $20M, pokud tyto dva datové body patří do stejné datové sady pro regresi, nebo stejnou časovou řadu určenou identifikátorem časové řady. Ve skutečnosti je predikce pouze 20 tisíc dolarů z platu $20M velmi blízko (malý relativní rozdíl 0,1%), zatímco $20k off z $30k není blízko (velký 67% relativní rozdíl). Pokud chcete vyřešit problém relativního rozdílu, můžete model vytrénovat s dostupnými primárními metrikami a pak vybrat model s nejlepším mean_absolute_percentage_error nebo root_mean_squared_log_error.
| Metrika | Příklady případů použití |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Predikce ceny (house/product/tip), predikce skóre recenze |
r2_score |
Zpoždění letecké společnosti, odhad platu, doba řešení chyb |
normalized_mean_absolute_error |
Metriky pro scénáře prognózování časových řad
Doporučení jsou podobná doporučením, která jsou uvedena pro regresní scénáře.
| Metrika | Příklady případů použití |
|---|---|
normalized_root_mean_squared_error |
Predikce cen (prognózování), optimalizace zásob, prognóza poptávky |
r2_score |
Predikce cen (prognózování), optimalizace zásob, prognóza poptávky |
normalized_mean_absolute_error |
Featurizace dat
V každém automatizovaném experimentu ML se vaše data automaticky škálují a normalizují, aby pomohly určitým algoritmům citlivým na funkce, které jsou na různých škálách. Toto škálování a normalizace se označuje jako featurizace. Další podrobnosti a příklady kódu najdete v tématu Featurization v AutoML .
Poznámka:
Kroky automatického featurizace strojového učení (normalizace funkcí, zpracování chybějících dat, převod textu na číselný atd.) se stanou součástí základního modelu. Při použití modelu pro předpovědi se na vstupní data automaticky použijí stejné kroky featurizace použité během trénování.
Při konfiguraci experimentů v AutoMLConfig objektu můžete nastavení featurizationpovolit nebo zakázat . Následující tabulka ukazuje akceptovaná nastavení pro featurizaci v objektu AutoMLConfig.
| Konfigurace featurizace | Popis |
|---|---|
"featurization": 'auto' |
Označuje, že jako součást předběžného zpracování se automaticky provádějí ochranné mantinely dat a kroky featurizace. Výchozí nastavení |
"featurization": 'off' |
Označuje, že krok featurizace by neměl být proveden automaticky. |
"featurization": 'FeaturizationConfig' |
Označuje, že se má použít přizpůsobený krok featurizace. Přečtěte si, jak přizpůsobit funkcionalizaci. |
Konfigurace souboru
Modely souborů jsou ve výchozím nastavení povoleny a zobrazují se jako konečné iterace spuštění ve spuštění AutoML. Aktuálně se podporuje VotingEnsemble a StackEnsemble .
Hlasování implementuje obnovitelné hlasování, které používá vážené průměry. Implementace stackingu používá dvě implementace vrstev, kde první vrstva má stejné modely jako hlasovací soubor, a druhý model vrstvy slouží k nalezení optimální kombinace modelů z první vrstvy.
Pokud používáte modely ONNX nebo máte povolenou možnost vysvětlitelnosti modelu, je stacking zakázaný a využívá se pouze hlasování.
Souborové trénování lze zakázat pomocí logických enable_voting_ensemble enable_stack_ensemble parametrů.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Chcete-li změnit výchozí chování souboru, existuje více výchozích argumentů, které lze zadat jako kwargs v objektu AutoMLConfig .
Důležité
Následující parametry nejsou explicitní parametry třídy AutoMLConfig.
ensemble_download_models_timeout_sec: Během generování modelu VotingEnsemble a StackEnsemble se stáhne několik fitovaných modelů z předchozích podřízených spuštění. Pokud dojde k této chybě:AutoMLEnsembleException: Could not find any models for running ensemblingmožná budete muset poskytnout více času, než se modely stáhnou. Výchozí hodnota je 300 sekund pro paralelní stahování těchto modelů a neexistuje maximální limit časového limitu. Pokud potřebujete více času, nakonfigurujte tento parametr s vyšší hodnotou než 300 sekund.Poznámka:
Pokud dojde k dosažení časového limitu a stáhnou se modely, bude přemístit počet stažených modelů. Není nutné, aby se všechny modely musely stáhnout, aby se dokončily v rámci časového limitu. Následující parametry platí pouze pro modely StackEnsemble :
stack_meta_learner_type: metauč je model natrénovaný na výstupu jednotlivých heterogenních modelů. Výchozí metaučující se používajíLogisticRegressionpro úlohy klasifikace (neboLogisticRegressionCVpokud je povolené křížové ověření) aElasticNetpro regresi nebo prognózování úkolů (neboElasticNetCVpokud je povolené křížové ověření). Tento parametr může být jedním z následujících řetězců: , , , , ,ElasticNetCV, , ,LightGBMRegressorneboLinearRegression.ElasticNetLightGBMClassifierLogisticRegressionCVLogisticRegressionstack_meta_learner_train_percentage: určuje poměr trénovací sady (při výběru typu trénování a ověřování trénování) pro trénování metaučovače. Výchozí hodnota je0.2.stack_meta_learner_kwargs: Volitelné parametry pro předání inicializátoru metaučovače. Tyto parametry a typy parametrů zrcadlí parametry a typy parametrů z odpovídajícího konstruktoru modelu a předávají se konstruktoru modelu.
Následující kód ukazuje příklad určení chování vlastního souboru v objektu AutoMLConfig .
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Kritéria ukončení
Existuje několik možností, které můžete definovat v autoMLConfig pro ukončení experimentu.
| Kritéria | description |
|---|---|
| Žádná kritéria | Pokud nedefinujete žádné výstupní parametry, experiment bude pokračovat, dokud nedojde k žádnému dalšímu postupu v primární metrice. |
| Po delší době | V experiment_timeout_minutes nastavení můžete definovat, jak dlouho má experiment běžet v minutách. Abyste se vyhnuli selháním vypršení časového limitu experimentu, existuje minimálně 15 minut nebo 60 minut, pokud řádek podle velikosti sloupce překročí 10 milionů. |
| Bylo dosaženo skóre. | Použití experiment_exit_score dokončí experiment po dosažení zadaného primárního skóre metriky. |
Spuštění experimentu
Upozorňující
Pokud spustíte experiment se stejným nastavením konfigurace a primární metrikou vícekrát, pravděpodobně se v každém experimentu zobrazí konečné skóre metrik a vygenerované modely. Algoritmy automatizovaného strojového učení mají vlastní náhodnost, která může způsobit mírné variace výstupu modelů experimentem a konečné skóre metrik doporučeného modelu, jako je přesnost. Pravděpodobně uvidíte také výsledky se stejným názvem modelu, ale použije se různé hyperparametry.
V případě automatizovaného strojového Experiment učení vytvoříte objekt, což je pojmenovaný objekt v použitém Workspace ke spouštění experimentů.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Odešlete experiment, aby se spustil a vygeneroval model. AutoMLConfig submit Předejte metodě pro vygenerování modelu.
run = experiment.submit(automl_config, show_output=True)
Poznámka:
Závislosti se poprvé nainstalují na nový počítač. Zobrazení výstupu může trvat až 10 minut.
Nastavení show_output pro výsledky zobrazení True výstupu v konzole
Více podřízených spuštění v clusterech
Spuštění podřízeného experimentu automatizovaného strojového učení je možné provést v clusteru, na kterém už běží jiný experiment. Načasování ale závisí na tom, kolik uzlů má cluster a jestli jsou tyto uzly k dispozici ke spuštění jiného experimentu.
Každý uzel v clusteru funguje jako jednotlivý virtuální počítač, který dokáže provést jeden trénovací běh; pro automatizované strojové učení to znamená podřízené spuštění. Pokud jsou všechny uzly zaneprázdněné, nový experiment se zařadí do fronty. Pokud ale existují bezplatné uzly, nový experiment spustí automatizované podřízené běhy ML paralelně v dostupných uzlech nebo virtuálních počítačích.
Pokud chcete pomoct se správou podřízených spuštění a jejich provedením, doporučujeme vytvořit vyhrazený cluster na experiment a shodovat počet experimentů max_concurrent_iterations s počtem uzlů v clusteru. Tímto způsobem použijete všechny uzly clusteru současně s počtem souběžných podřízených spuštění nebo iterací, které chcete.
Nakonfigurujte max_concurrent_iterations v objektu AutoMLConfig . Pokud není nakonfigurovaná, je ve výchozím nastavení povolená pouze jedna souběžná podřízená spuštění nebo iterace pro každý experiment.
V případě výpočetní instance je možné nastavit stejnou max_concurrent_iterations hodnotu jako počet jader na virtuálním počítači výpočetní instance.
Prozkoumání modelů a metrik
Automatizované strojové učení nabízí možnosti, jak monitorovat a vyhodnocovat výsledky trénování.
Výsledky trénování si můžete prohlédnout ve widgetu nebo v textu, pokud jste v poznámkovém bloku. Další podrobnosti najdete v tématu Monitorování spuštění automatizovaného strojového učení .
Definice a příklady výkonnostních grafů a metrik poskytovaných pro každé spuštění najdete v tématu Vyhodnocení výsledků experimentů automatizovaného strojového učení.
Pokud chcete získat souhrn featurizace a pochopit, jaké funkce byly přidány do konkrétního modelu, podívejte se na transparentnost featurizace.
Můžete zobrazit hyperparametry, techniky škálování a normalizace a algoritmus použitý u konkrétního automatizovaného strojového učení s vlastním řešením print_model()kódu.
Tip
Automatizované strojové učení vám také umožní zobrazit vygenerovaný trénovací kód modelu pro vytrénované modely automatického strojového učení. Tato funkce je ve verzi Public Preview a může se kdykoli změnit.
Monitorování spuštění automatizovaného strojového učení
Pokud chcete získat přístup k grafům z předchozího spuštění, v případě automatizovaných spuštění ml nahraďte <<experiment_name>> odpovídajícím názvem experimentu:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
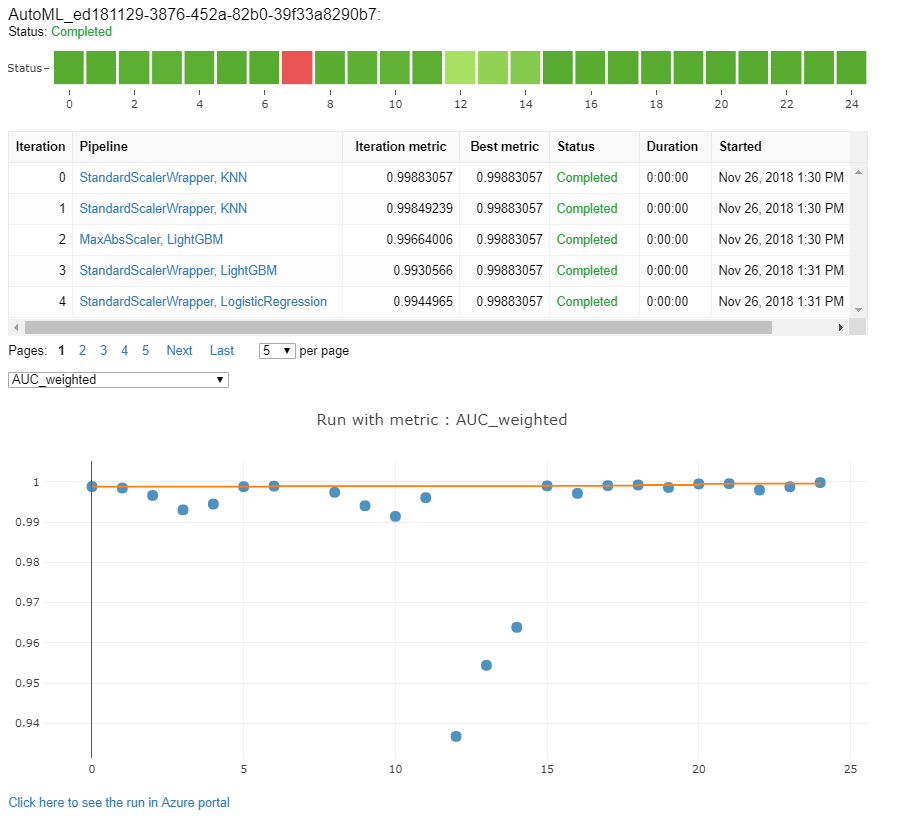
Testovací modely (Preview)
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení automatizovaných modelů generovaných strojového učení je funkce Preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Upozorňující
Tato funkce není k dispozici pro následující scénáře automatizovaného strojového učení.
test_data Předání parametrů test_size do AutoMLConfig, automaticky aktivuje vzdálené testovací spuštění, které používá poskytnutá testovací data k vyhodnocení nejlepšího modelu, který automatizované strojové učení doporučuje po dokončení experimentu. Toto vzdálené testovací spuštění se provádí na konci experimentu, jakmile se určí nejlepší model. Podívejte se, jak předat testovací data do vašeho AutoMLConfigsouboru .
Získání výsledků testovací úlohy
Předpovědi a metriky můžete získat z úlohy vzdáleného testu z studio Azure Machine Learning nebo pomocí následujícího kódu.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
Úloha testu modelu vygeneruje soubor predictions.csv, který je uložený ve výchozím úložišti dat vytvořeném s pracovním prostorem. Toto úložiště dat je viditelné všem uživatelům se stejným předplatným. Testovací úlohy se nedoporučují pro scénáře, pokud některé z informací používaných pro testovací úlohu nebo vytvořené testovací úlohou musí zůstat soukromé.
Testování existujícího automatizovaného modelu ML
Pokud chcete otestovat další existující automatizované modely STROJOVÉho učení vytvořené, nejlepší úlohu nebo podřízenou úlohu, použijte ModelProxy() k otestování modelu po dokončení hlavního spuštění AutoML. ModelProxy() již vrací předpovědi a metriky a nevyžaduje další zpracování pro načtení výstupů.
Poznámka:
ModelProxy je experimentální třída Preview a může se kdykoli změnit.
Následující kód ukazuje, jak otestovat model z libovolného spuštění pomocí metody ModelProxy.test(). V metodě test() máte možnost zadat, pokud chcete zobrazit pouze předpovědi testovacího spuštění s parametrem include_predictions_only .
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Registrace a nasazení modelů
Po otestování modelu a potvrzení, že ho chcete použít v produkčním prostředí, můžete ho zaregistrovat pro pozdější použití a
Pokud chcete zaregistrovat model z automatizovaného spuštění ML, použijte tuto metodu register_model() .
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Podrobnosti o tom, jak vytvořit konfiguraci nasazení a nasadit registrovaný model do webové služby, najdete v tématu o tom, jak a kde nasadit model.
Tip
U registrovaných modelů je nasazení jedním kliknutím dostupné prostřednictvím studio Azure Machine Learning. Podívejte se, jak nasadit registrované modely ze studia.
Interpretovatelnost modelů
Interpretovatelnost modelu umožňuje pochopit, proč vaše modely vytvořily předpovědi a základní hodnoty důležitosti funkcí. Sada SDK obsahuje různé balíčky pro povolení funkcí interpretovatelnosti modelů, a to jak při trénování, tak v době odvozování pro místní a nasazené modely.
Podívejte se, jak povolit funkce interpretovatelnosti speciálně v rámci experimentů automatizovaného strojového učení.
Obecné informace o tom, jak je možné povolit vysvětlení modelů a důležitost funkcí v jiných oblastech sady SDK mimo automatizované strojové učení, najdete v článku o interpretovatelnosti .
Poznámka:
Klient vysvětlení v současné době nepodporuje model ForecastTCN. Tento model nevrátí řídicí panel vysvětlení, pokud se vrátí jako nejlepší model a nepodporuje spuštění vysvětlení na vyžádání.
Další kroky
Přečtěte si další informace o tom, jak a kde nasadit model.
Přečtěte si další informace o tom, jak vytrénovat regresní model pomocí automatizovaného strojového učení.
Řešení potíží s experimenty automatizovaného strojového učení
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro