PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
V tomto článku se naučíte nasadit model do online koncového bodu pro použití při odvozování v reálném čase. Začnete tím, že na místním počítači nasadíte model, abyste mohli ladit případné chyby. Pak model nasadíte a otestujete v Azure, zobrazíte protokoly nasazení a budete monitorovat smlouvu o úrovni služeb (SLA). Na konci tohoto článku máte škálovatelný koncový bod HTTPS/REST, který můžete použít k odvozování v reálném čase.
Online koncové body jsou takové, které se používají pro inference v reálném čase. Existují dva typy online koncových bodů: spravované online koncové body a online koncové body Kubernetes. Další informace o rozdílech najdete v tématu Spravované online koncové body vs. Online koncové body Kubernetes.
Spravované online koncové body pomáhají s nasazováním modelů strojového učení na klíč. Spravované online koncové body pracují s výkonnými procesory a GPU v Azure škálovatelným a plně spravovaným způsobem. Spravované online koncové body se stará o obsluhu, škálování, zabezpečení a monitorování vašich modelů. Tato pomoc vám uvolní režii při nastavování a správě základní infrastruktury.
Hlavní příklad v tomto článku používá spravované online koncové body pro nasazení. Pokud chcete místo toho používat Kubernetes, podívejte se na poznámky v tomto dokumentu, které jsou vložené do diskuze o spravovaném online koncovém bodu.
Požadavky
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Řízení přístupu na základě role v Azure (Azure RBAC) se používá k udělení přístupu k operacím ve službě Azure Machine Learning. Pokud chcete provést kroky v tomto článku, váš uživatelský účet musí mít přiřazenou roli Vlastník nebo Přispěvatel pro pracovní prostor Azure Machine Learning, nebo musí existovat vlastní role, která Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* umožňuje. Pokud k vytváření a správě online koncových bodů nebo nasazení používáte Azure Machine Learning Studio, potřebujete dodatečné oprávnění Microsoft.Resources/deployments/write od vlastníka skupiny prostředků. Další informace najdete v tématu Správa přístupu k pracovním prostorům Azure Machine Learning.
(Volitelné) Pokud chcete nasadit místně, musíte do místního počítače nainstalovat Modul Dockeru .
Důrazně doporučujeme tuto možnost, která usnadňuje odstraňování problémů.
PLATÍ PRO: Python SDK azure-ai-ml v2 (aktuální)
Azure RBAC se používá k udělení přístupu k operacím ve službě Azure Machine Learning. Pokud chcete provést kroky v tomto článku, váš uživatelský účet musí mít přiřazenou roli Vlastník nebo Přispěvatel pro pracovní prostor Azure Machine Learning, nebo musí existovat vlastní role, která Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* umožňuje. Další informace najdete v tématu Správa přístupu k pracovním prostorům Azure Machine Learning.
(Volitelné) Pokud chcete nasadit místně, musíte do místního počítače nainstalovat Modul Dockeru .
Důrazně doporučujeme tuto možnost, která usnadňuje odstraňování problémů.
Než budete postupovat podle kroků v tomto článku, ujistěte se, že máte následující požadavky:
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
- Pracovní prostor Azure Machine Learning a výpočetní instance. Pokud tyto prostředky nemáte, přečtěte si téma Vytvoření prostředků, které potřebujete, abyste mohli začít.
- Azure RBAC se používá k udělení přístupu k operacím ve službě Azure Machine Learning. Pokud chcete provést kroky v tomto článku, váš uživatelský účet musí mít přiřazenou roli Vlastník nebo Přispěvatel pro pracovní prostor Azure Machine Learning, nebo musí existovat vlastní role, která
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* umožňuje. Další informace najdete v tématu Správa přístupu k pracovnímu prostoru Azure Machine Learning.
V těchto krocích se používá Azure CLI a rozšíření rozhraní příkazového řádku pro strojové učení, nejedná se ale o hlavní zaměření. Používají se více jako nástroje pro předávání šablon do Azure a kontrole stavu nasazení šablon.
- Azure RBAC se používá k udělení přístupu k operacím ve službě Azure Machine Learning. Pokud chcete provést kroky v tomto článku, váš uživatelský účet musí mít přiřazenou roli Vlastník nebo Přispěvatel pro pracovní prostor Azure Machine Learning, nebo musí existovat vlastní role, která
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* umožňuje. Další informace najdete v tématu Správa přístupu k pracovnímu prostoru Azure Machine Learning.
Ujistěte se, že máte přidělenou dostatečnou kvótu virtuálního počítače pro nasazení. Azure Machine Learning si vyhrazuje 20% výpočetních prostředků pro provádění upgradů na některých verzích virtuálních počítačů. Pokud například v nasazení požadujete 10 instancí, musíte mít kvótu 12 pro každý počet jader pro verzi virtuálního počítače. Chyba při zohlednění dodatečných výpočetních prostředků způsobí chybu. Některé verze virtuálních počítačů jsou vyjmuty z dodatečné kvóty. Další informace o přidělení kvóty najdete v tématu Přidělení kvóty virtuálních počítačů pro nasazení.
Případně můžete použít kvótu ze sdíleného fondu kvót služby Azure Machine Learning po omezenou dobu. Azure Machine Learning poskytuje fond sdílených kvót, ze kterého mají uživatelé v různých oblastech přístup k kvótě, aby mohli provádět testování po omezenou dobu v závislosti na dostupnosti.
Když pomocí studia nasadíte modely Llama-2, Phi, Nemotron, Mistral, Dolly a Deci-Deci-DeciLM z katalogu modelů do spravovaného online koncového bodu, Azure Machine Learning vám umožní získat přístup k fondu sdílených kvót na krátkou dobu, abyste mohli provést testování. Další informace o sdíleném fondu kvót najdete v tématu Sdílená kvóta služby Azure Machine Learning.
Příprava systému
Nastavení proměnných prostředí
Pokud jste ještě nenastavili výchozí hodnoty pro Azure CLI, uložte výchozí nastavení. Pokud se chcete vyhnout předávání hodnot pro vaše předplatné, pracovní prostor a skupinu prostředků několikrát, spusťte tento kód:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Klonování úložiště příkladů
Pokud chcete postupovat podle tohoto článku, nejprve naklonujte úložiště azureml-examples a pak přejděte do adresáře azureml-examples/cli úložiště:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Pomocí --depth 1 klonujte pouze nejnovější commit do úložiště, což zkracuje dobu potřebnou k dokončení operace.
Příkazy v tomto kurzu jsou umístěny v souborech deploy-local-endpoint.sh a deploy-managed-online-endpoint.sh v adresáři CLI. Konfigurační soubory YAML jsou v endpoints/online/managed/sample/ podadresáři.
Poznámka:
Konfigurační soubory YAML pro online koncové body v Kubernetes se nacházejí v podadresáři endpoints/online/kubernetes/.
Klonování úložiště příkladů
Pokud chcete spustit příklady trénování, nejprve naklonujte úložiště azureml-examples a pak přejděte do azureml-examples/sdk/python/endpoints/online/managed directory:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Pomocí --depth 1 klonujte pouze nejnovější commit do úložiště, což zkracuje dobu potřebnou k dokončení operace.
Informace v tomto článku vycházejí z poznámkového bloku online-endpoints-simple-deployment.ipynb. Obsahuje stejný obsah jako tento článek, i když pořadí kódů se mírně liší.
Připojení k pracovnímu prostoru Azure Machine Learning
Pracovní prostor je prostředek nejvyšší úrovně pro Azure Machine Learning. Poskytuje centralizované místo pro práci se všemi artefakty, které vytvoříte při použití služby Azure Machine Learning. V této části se připojíte k pracovnímu prostoru, ve kterém provádíte úlohy nasazení. Pokud chcete postup sledovat, otevřete poznámkový blok online-endpoints-simple-deployment.ipynb .
Import požadovaných knihoven:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Poznámka:
Pokud používáte online koncový bod Kubernetes, naimportujte třídy KubernetesOnlineEndpoint a KubernetesOnlineDeployment z knihovny azure.ai.ml.entities.
Nakonfigurujte podrobnosti pracovního prostoru a získejte popisovač pracovního prostoru.
Pokud se chcete připojit k pracovnímu prostoru, potřebujete tyto parametry identifikátoru: předplatné, skupinu prostředků a název pracovního prostoru. Pomocí těchto podrobností v MLClient z azure.ai.ml můžete získat přístup k požadovanému pracovnímu prostoru Azure Machine Learning. V tomto příkladu se používá výchozí ověřování Azure.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Pokud máte na místním počítači nainstalovaný Git, můžete podle pokynů naklonovat úložiště příkladů. Jinak postupujte podle pokynů ke stažení souborů z úložiště příkladů.
Klonování úložiště příkladů
Pokud chcete postupovat podle tohoto článku, nejprve naklonujte úložiště azureml-examples a pak přejděte do adresáře azureml-examples/cli/endpoints/online/model-1 .
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Pomocí --depth 1 klonujte pouze nejnovější commit do úložiště, což zkracuje dobu potřebnou k dokončení operace.
Stažení souborů z úložiště příkladů
Pokud jste naklonovali úložiště příkladů, váš místní počítač už má kopie souborů pro tento příklad a můžete přejít k další části. Pokud jste úložiště nenaklonovali, stáhněte si ho do místního počítače.
- Přejděte do úložiště příkladů (azureml-examples).
- Přejděte na <> tlačítko Kód na stránce a pak na kartě Místní vyberte Stáhnout ZIP.
- Vyhledejte složku /cli/endpoints/online/model-1/model a soubor /cli/endpoints/online/model-1/onlinescoring/score.py.
Nastavení proměnných prostředí
Nastavte následující proměnné prostředí, abyste je mohli použít v příkladech v tomto článku. Nahraďte hodnoty ID předplatného Azure, oblast Azure, ve které se nachází váš pracovní prostor, skupinu prostředků, která obsahuje pracovní prostor, a název pracovního prostoru:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Několik příkladů šablon vyžaduje, abyste soubory nahráli do služby Azure Blob Storage pro váš pracovní prostor. Následující kroky se dotazují na pracovní prostor a ukládají tyto informace do proměnných prostředí použitých v příkladech:
Získání přístupového tokenu:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Nastavte verzi rozhraní REST API:
API_VERSION="2022-05-01"
Získejte informace o úložišti:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
Klonování úložiště příkladů
Pokud chcete postupovat podle tohoto článku, nejprve naklonujte úložiště azureml-examples a pak přejděte do adresáře azureml-examples :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Pomocí --depth 1 klonujte pouze nejnovější commit do úložiště, což zkracuje dobu potřebnou k dokončení operace.
Definování koncového bodu
Pokud chcete definovat online koncový bod, zadejte název koncového bodu a režim ověřování. Další informace o spravovaných online koncových bodech najdete v tématu Online koncové body.
Nastavení názvu koncového bodu
Pokud chcete nastavit název koncového bodu, spusťte následující příkaz. Nahraďte <YOUR_ENDPOINT_NAME> jedinečným názvem v oblasti Azure. Další informace o pravidlech pojmenování najdete v tématu Limity koncových bodů.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Následující úryvek ukazuje soubor endpoints/online/managed/sample/endpoint.yml:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Referenční informace pro formát YAML koncového bodu jsou popsány v následující tabulce. Informace o tom, jak tyto atributy zadat, najdete v online referenční příručce pro koncový bod YAML. Informace o omezeních souvisejících se spravovanými koncovými body najdete v tématu Online koncové body služby Azure Machine Learning a dávkové koncové body.
| Klíč |
Popis |
$schema |
(Volitelné) Schéma YAML. Pokud chcete zobrazit všechny dostupné možnosti v souboru YAML, můžete schéma zobrazit v předchozím fragmentu kódu v prohlížeči. |
name |
Název koncového bodu |
auth_mode |
Používá se key pro ověřování založené na klíčích.
Používá se aml_token pro ověřování na základě tokenů služby Azure Machine Learning.
Použijte aad_token pro ověřování založené na tokenech Microsoft Entra (náhled).
Další informace o ověřování najdete v tématu Ověřování klientů pro online koncové body. |
Nejprve definujte název online koncového bodu a pak nakonfigurujte koncový bod.
Nahraďte <YOUR_ENDPOINT_NAME> názvem, který je jedinečný v oblasti Azure, nebo použijte ukázkovou metodu k definování náhodného názvu. Nezapomeňte odstranit metodu, kterou nepoužíváte. Další informace o pravidlech pojmenování najdete v tématu Limity koncových bodů.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
Předchozí kód používá key pro ověřování založené na klíči. Pokud chcete použít ověřování založené na tokenech služby Azure Machine Learning, použijte aml_token. Chcete-li použít ověřování založené na tokenech Microsoft Entra (Preview), použijte aad_token. Další informace o ověřování najdete v tématu Ověřování klientů pro online koncové body.
Když nasadíte do Azure z vývojového prostředí, vytvoříte koncový bod a nasazení, které k němu přidáte. V tuto chvíli se zobrazí výzva k zadání názvů koncového bodu a nasazení.
Nastavení názvu koncového bodu
Pokud chcete nastavit název koncového bodu, spusťte následující příkaz, který vygeneruje náhodný název. Musí být jedinečný v oblasti Azure. Další informace o pravidlech pojmenování najdete v tématu Limity koncových bodů.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
K definování koncového bodu a nasazení se v tomto článku používají šablony Azure Resource Manageru (šablony ARM) online-endpoint.json a online-endpoint-deployment.json. Pokud chcete použít šablony pro definování online koncového bodu a nasazení, přečtěte si část Nasazení do Azure .
Definování nasazení
Nasazení je sada prostředků vyžadovaných pro hostování modelu, který provádí skutečné inferování. V tomto příkladu scikit-learn nasadíte model, který regresi provede, a použijete bodovací skript score.py ke spuštění modelu na konkrétním vstupním požadavku.
Další informace o klíčových atributech nasazení najdete v tématu Online nasazení.
Konfigurace nasazení používá umístění modelu, který chcete nasadit.
Následující úryvek ukazuje soubor endpoints/online/managed/sample/blue-deployment.yml s veškerými potřebnými vstupy pro konfiguraci nasazení.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Soubor blue-deployment.yml určuje následující atributy nasazení:
-
model: Určuje vlastnosti modelu přímo pomocí parametru path (odkud se mají nahrát soubory). Rozhraní příkazového řádku automaticky nahraje soubory modelu a zaregistruje model s automaticky vygenerovaným názvem.
-
environment: Používá vložené definice, které zahrnují, odkud se mají nahrávat soubory. Rozhraní příkazového řádku automaticky nahraje soubor conda.yaml a zaregistruje prostředí. Později pro sestavení prostředí nasazení použije parametr image pro základní obraz. V tomto příkladu je to mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest.
conda_file Závislosti se instalují nad základní image.
-
code_configuration: Nahraje místní soubory, jako je zdroj Pythonu pro model bodování, z vývojového prostředí během nasazování.
Další informace o schématu YAML najdete v online referenčních informacích ke koncovému bodu YAML.
Poznámka:
Použití koncových bodů Kubernetes místo spravovaných online koncových bodů jako cílového výpočetního objektu:
- Vytvořte a připojte cluster Kubernetes jako cílový výpočetní objekt k pracovnímu prostoru Azure Machine Learning pomocí studio Azure Machine Learning.
- Použijte YAML koncového bodu k nastavení cílení na Kubernetes místo YAML koncového bodu spravovaného. Pokud chcete změnit hodnotu na název zaregistrovaného cílového výpočetního
compute objektu, musíte upravit YAML. Můžete použít tento soubor deployment.yaml s dalšími vlastnostmi, které platí pro nasazení Kubernetes.
Všechny příkazy, které se používají v tomto článku pro spravované online koncové body, platí také pro koncové body Kubernetes, s výjimkou následujících funkcí, které se nevztahují na koncové body Kubernetes:
Ke konfiguraci nasazení použijte následující kód:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: Určuje vlastnosti modelu přímo pomocí parametru path (odkud se mají nahrát soubory). Sada SDK automaticky nahraje soubory modelu a zaregistruje model s automaticky vygenerovaným názvem.
-
Environment: Používá vložené definice, které zahrnují, odkud se mají nahrávat soubory. Sada SDK automaticky nahraje soubor conda.yaml a zaregistruje prostředí. Později pro sestavení prostředí nasazení použije parametr image pro základní obraz. V tomto příkladu je to mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest.
conda_file Závislosti se instalují nad základní image.
-
CodeConfiguration: Nahraje místní soubory, jako je zdroj Pythonu pro model bodování, z vývojového prostředí během nasazování.
Pro více informací o definici online nasazení se podívejte na třída OnlineDeployment.
Když nasadíte do Azure, vytvoříte koncový bod a nasazení, které do něj přidáte. V tuto chvíli se zobrazí výzva k zadání názvů koncového bodu a nasazení.
Vysvětlení hodnoticího skriptu
Formát bodovacího skriptu pro online koncové body je stejný formát, který se používá v předchozí verzi rozhraní příkazového řádku a v sadě Python SDK.
Bodovací skript zadaný v code_configuration.scoring_script musí mít init() funkci a run() funkci.
Bodovací skript musí mít init() funkci a run() funkci.
Bodovací skript musí mít init() funkci a run() funkci.
Bodovací skript musí mít init() funkci a run() funkci. Tento článek používá soubor score.py.
Při použití šablony pro nasazení musíte nejprve nahrát soubor bodování do služby Blob Storage a pak ho zaregistrovat:
Následující kód používá příkaz Azure CLI az storage blob upload-batch k nahrání skórovacího souboru.
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
Následující kód používá šablonu k registraci kódu:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
Tento příklad používá soubor score.py z úložiště, které jste naklonovali nebo stáhli dříve:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
Funkce init() se volá při inicializaci nebo spuštění kontejneru. Inicializace se obvykle vyskytuje krátce po vytvoření nebo aktualizaci nasazení. Funkce init je místo pro zápis logiky pro operace globální inicializace, jako je ukládání modelu do mezipaměti v paměti (jak je znázorněno v tomto souboru score.py ).
Funkce run() se volá při každém vyvolání koncového bodu. Provádí skutečné bodování a předpovědi. V tomto funkce extrahuje data ze vstupu JSON, zavolá metodu modelu run() scikit-learn a vrátí výsledek předpovědi.
Provádějte nasazení a ladění lokálně pomocí místního koncového bodu
Důrazně doporučujeme otestovat spuštění koncového bodu místně, abyste před nasazením do Azure ověřili a ladili kód a konfiguraci. Azure CLI a Python SDK podporují místní koncové body a nasazení, ale azure Machine Learning Studio a šablony ARM ne.
Pokud chcete nasadit místně, musí být nainstalován a spuštěn Docker Engine. Modul Dockeru se obvykle spustí při spuštění počítače. Pokud ne, můžete řešit potíže s Docker Enginem.
Balíček Pythonu pro odvozování serveru HTTP pro Azure Machine Learning můžete použít k místnímu ladění hodnoticího skriptu bez Modulu Dockeru. Ladění pomocí serveru odvozování vám pomůže ladit bodovací skript před nasazením do místních koncových bodů, abyste mohli ladit bez ovlivnění konfigurací kontejneru nasazení.
Další informace o místním ladění online koncových bodů před nasazením do Azure najdete v tématu Online ladění koncových bodů.
Místní nasazení modelu
Nejprve vytvořte koncový bod. Volitelně můžete tento krok přeskočit pro místní koncový bod. Nasazení můžete vytvořit přímo (další krok), který pak vytvoří požadovaná metadata. Místní nasazení modelů je užitečné pro účely vývoje a testování.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
Studio nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Šablona nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Teď vytvořte nasazení pojmenované blue pod koncovým bodem.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
Příznak --local nasměruje rozhraní příkazového řádku k nasazení koncového bodu v prostředí Dockeru.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
Příznak local=True nasměruje sadu SDK k nasazení koncového bodu v prostředí Dockeru.
Studio nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Šablona nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Ověření úspěšného místního nasazení
Zkontrolujte stav nasazení a zjistěte, jestli se model nasadil bez chyby:
az ml online-endpoint show -n $ENDPOINT_NAME --local
Výstup by se měl podobat následujícímu formátu JSON. Parametr provisioning_state je Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
Metoda vrátí ManagedOnlineEndpoint entitu. Parametr provisioning_state je Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
Studio nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Šablona nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Následující tabulka obsahuje možné hodnoty pro provisioning_state:
| Hodnota |
Popis |
Creating |
Prostředek se vytváří. |
Updating |
Prostředek se aktualizuje. |
Deleting |
Prostředek se odstraňuje. |
Succeeded |
Operace vytvoření nebo aktualizace byla úspěšná. |
Failed |
Operace vytvoření, aktualizace nebo odstranění selhala. |
Zavolejte místní koncový bod pro ohodnocení dat pomocí vašeho modelu
Pomocí příkazu a předáním parametrů dotazu uložených v souboru JSON vyvolejte koncový bod pro určení skóre modelu invoke :
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Pokud chcete použít klienta REST (například curl), musíte mít scoring URI. Pokud chcete získat identifikátor URI bodování, spusťte az ml online-endpoint show --local -n $ENDPOINT_NAME. Ve vrácených datech vyhledejte scoring_uri atribut.
Pomocí příkazu a předáním parametrů dotazu uložených v souboru JSON vyvolejte koncový bod pro určení skóre modelu invoke .
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Pokud chcete použít klienta REST (například curl), musíte mít scoring URI. Pokud chcete získat identifikátor URI bodování, spusťte následující kód. Ve vrácených datech vyhledejte scoring_uri atribut.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
Studio nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Šablona nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Zkontrolujte protokoly pro výstup z operace vyvolání.
V příkladu score.py souboru run() metoda zaznamená výstup do konzoly.
Tento výstup můžete zobrazit pomocí get-logs příkazu:
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
Tento výstup můžete zobrazit pomocí get_logs metody:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
Studio nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Šablona nepodporuje místní koncové body. Postup místního testování koncového bodu najdete na kartách Azure CLI nebo Pythonu.
Nasazení online koncového bodu do Azure
Dále nasaďte online koncový bod do Azure. Jako osvědčený postup pro produkční prostředí doporučujeme zaregistrovat model a prostředí, které používáte ve svém nasazení.
Registrace modelu a prostředí
Před nasazením do Azure doporučujeme zaregistrovat model a prostředí, abyste mohli během nasazení zadat jejich registrované názvy a verze. Po registraci zdrojů je můžete znovu použít, aniž byste je museli nahrávat při každém nasazení. Tento postup zvyšuje reprodukovatelnost a sledovatelnost.
Na rozdíl od nasazení do Azure místní nasazení nepodporuje používání registrovaných modelů a prostředí. Místo toho místní nasazení používá soubory místního modelu a používá prostředí pouze s místními soubory.
Pro nasazení do Azure můžete použít místní nebo registrované prostředky (modely a prostředí). V této části článku nasazení do Azure používá registrované prostředky, ale místo toho máte možnost používat místní prostředky. Příklad konfigurace nasazení, která nahrává místní soubory, které se mají použít pro místní nasazení, najdete v tématu Konfigurace nasazení.
K registraci modelu a prostředí použijte formulář model: azureml:my-model:1 nebo environment: azureml:my-env:1.
Pro registraci můžete extrahovat definice YAML prvků model a environment do samostatných souborů YAML ve složce koncových bodů/online/spravované/ukázkové a použít příkazy az ml model create a az ml environment create. Další informace o těchto příkazech získáte spuštěním az ml model create -h a az ml environment create -h.
Vytvořte definici YAML pro model. Pojmenujte soubor model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Zaregistrujte model:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Vytvořte definici YAML pro prostředí. Pojmenujte soubor environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Zaregistrujte prostředí:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Další informace o registraci modelu jako prostředku najdete v tématu Registrace modelu pomocí Azure CLI nebo sady Python SDK. Další informace o vytvoření prostředí najdete v tématu Vytvoření vlastního prostředí.
Registrace modelu:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Zaregistrujte prostředí:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Informace o tom, jak model zaregistrovat jako prostředek, abyste mohli během nasazování zadat její registrovaný název a verzi, najdete v tématu Registrace modelu pomocí Azure CLI nebo sady Python SDK.
Další informace o vytvoření prostředí najdete v tématu Vytvoření vlastního prostředí.
Registrace modelu
Registrace modelu je logická entita v pracovním prostoru, která může obsahovat jeden soubor modelu nebo adresář více souborů. Osvědčeným postupem pro produkční prostředí je registrace modelu a prostředí. Před vytvořením koncového bodu a nasazení v tomto článku zaregistrujte složku modelu , která tento model obsahuje.
Pokud chcete ukázkový model zaregistrovat, postupujte takto:
Přejděte na studio Azure Machine Learning.
V levém podokně vyberte stránku Modely .
Vyberte Zaregistrovat a pak zvolte Z místních souborů.
Jako typ modelu vyberte Nezadaný typ.
Vyberte Procházet a zvolte Procházet složku.
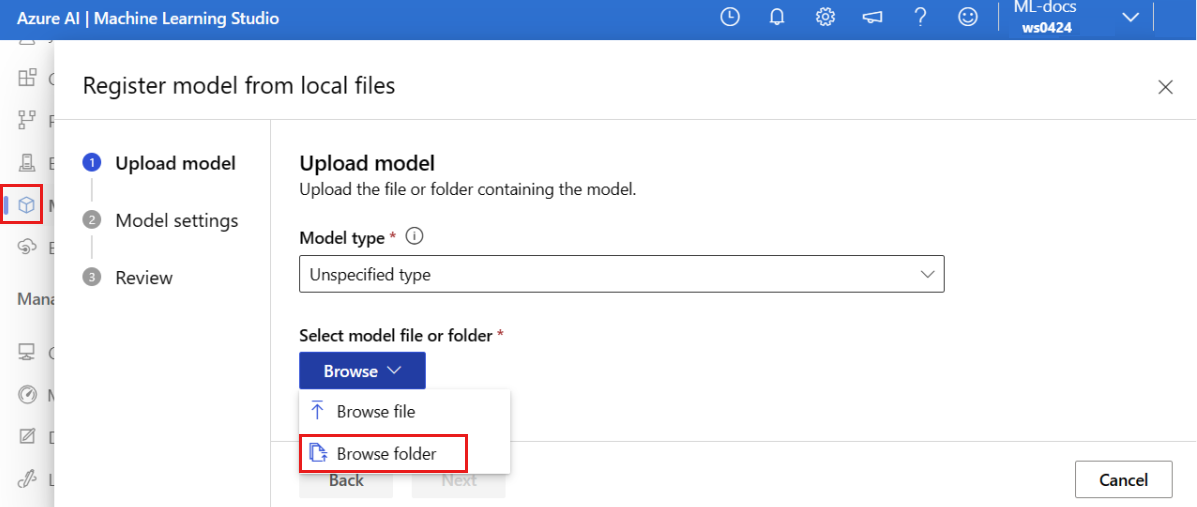
Vyberte složku \azureml-examples\cli\endpoints\online\model-1\model-1 z místní kopie úložiště, které jste naklonovali nebo stáhli dříve. Po zobrazení výzvy vyberte Nahrát a počkejte na dokončení nahrávání.
Vyberte Další.
Zadejte přátelský název modelu. Kroky v tomto článku předpokládají, že model má název model-1.
Vyberte Další a pak výběrem možnosti Zaregistrovat dokončete registraci.
Další informace o tom, jak pracovat s registrovanými modely, najdete v tématu Práce s registrovanými modely.
Vytvoření a registrace prostředí
V levém podokně vyberte stránku Prostředí .
Vyberte kartu Vlastní prostředí a pak zvolte Vytvořit.
Na stránce Nastavení zadejte název, například my-env pro prostředí.
Pro výběr zdroje prostředí zvolte Použít existující image Dockeru s volitelným zdrojem conda.

Výběrem možnosti Další přejděte na stránku Přizpůsobit .
Zkopírujte obsah souboru \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml z úložiště, které jste naklonovali nebo stáhli dříve.
Vložte obsah do textového pole.
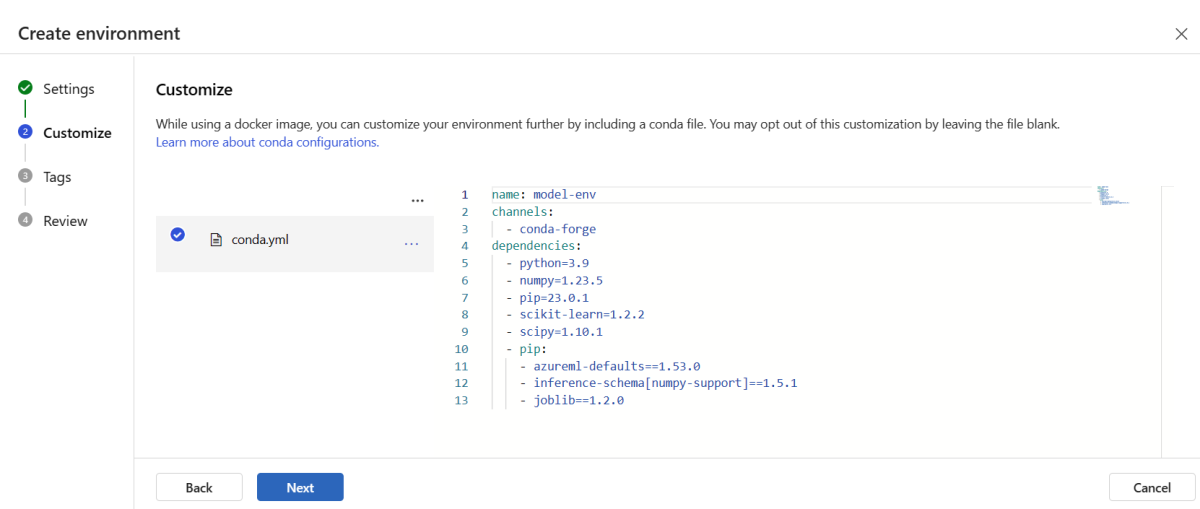
Vyberte Další , dokud se nedostanete na stránku Vytvořit , a pak vyberte Vytvořit.
Další informace o tom, jak vytvořit prostředí v sadě Studio, najdete v tématu Vytvoření prostředí.
Pokud chcete model zaregistrovat pomocí šablony, musíte nejprve nahrát soubor modelu do služby Blob Storage. Následující příklad používá az storage blob upload-batch příkaz k nahrání souboru do výchozího úložiště pro váš pracovní prostor:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
Po nahrání souboru pomocí šablony vytvořte registraci modelu. V následujícím příkladu modelUri obsahuje parametr cestu k modelu:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
Součástí prostředí je soubor conda, který určuje závislosti modelu potřebné k hostování modelu. Následující příklad ukazuje, jak číst obsah souboru conda do proměnných prostředí:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
Následující příklad ukazuje použití šablony k registraci prostředí. Obsah souboru conda z předchozího kroku se předá šabloně pomocí parametru condaFile :
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Důležité
Když pro nasazení definujete vlastní prostředí, ujistěte se, že azureml-inference-server-http je balíček součástí souboru conda. Tento balíček je nezbytný pro správné fungování serveru odvozování. Pokud neznáte způsob vytvoření vlastního prostředí, použijte jedno z našich kurátorovaných prostředí, například minimal-py-inference (pro vlastní modely, které nepoužívají mlflow) nebo mlflow-py-inference (pro modely, které používají mlflow). Tato kurátorovaná prostředí najdete na kartě Prostředí vaší instance nástroje Azure Machine Learning Studio.
Konfigurace nasazení používá registrovaný model, který chcete nasadit, a registrované prostředí.
V definici nasazení použijte registrované prostředky (model a prostředí). Následující úryvek zobrazuje soubor endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml se všemi požadovanými vstupy pro konfiguraci nasazení:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Ke konfiguraci nasazení použijte registrovaný model a prostředí:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Když nasazujete ze studia, vytvoříte koncový bod a k němu přidáte nasazení. V tuto chvíli se zobrazí výzva k zadání názvů koncového bodu a nasazení.
Použijte různé typy instancí procesoru a GPU a různé obrazy.
V definici nasazení můžete určit typy instancí PROCESORu nebo GPU a image pro místní nasazení i nasazení do Azure.
Definice nasazení v souboru blue-deployment-with-registered-assets.yml používala instanci obecného typu Standard_DS3_v2 a Docker image bez GPU mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. U výpočtů GPU zvolte verzi výpočetního typu GPU a Docker obraz pro GPU.
Podporované typy instancí pro všeobecné účely a GPU najdete v seznamu SKU spravovaných online koncových bodů. Seznam základních imagí procesoru a GPU ve službě Azure Machine Learning najdete v základních imagích služby Azure Machine Learning.
V konfiguraci nasazení můžete zadat typy instancí PROCESORu nebo GPU a image pro místní nasazení i nasazení do Azure.
Dříve jste nakonfigurovali nasazení, které používalo instanci typu Standard_DS3_v2 pro obecné účely a Docker image mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest bez GPU. U výpočtů GPU zvolte verzi výpočetního typu GPU a Docker obraz pro GPU.
Podporované typy instancí pro všeobecné účely a GPU najdete v seznamu SKU spravovaných online koncových bodů. Seznam základních imagí procesoru a GPU ve službě Azure Machine Learning najdete v základních imagích služby Azure Machine Learning.
Když k nasazení do Azure použijete studio, zobrazí se výzva k zadání výpočetních vlastností (typ instance a počet instancí) a prostředí, které se mají použít pro vaše nasazení.
Podporované typy instancí pro všeobecné účely a GPU najdete v seznamu SKU spravovaných online koncových bodů. Další informace o prostředích najdete v tématu Správa softwarových prostředí v studio Azure Machine Learning.
Předchozí registrace prostředí specifikuje Docker image bez GPU tím, že předá hodnotu do šablony mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 pomocí parametru . Pro výpočet GPU zadejte do šablony hodnotu obrazu Dockeru pro GPU (použijte dockerImage parametr) a poskytněte verzi typu výpočtu GPU do šablony online-endpoint-deployment.json (použijte skuName parametr).
Podporované typy instancí pro všeobecné účely a GPU najdete v seznamu SKU spravovaných online koncových bodů. Seznam základních imagí procesoru a GPU ve službě Azure Machine Learning najdete v základních imagích služby Azure Machine Learning.
Dále nasaďte online koncový bod do Azure.
Nasazení do Azure
Vytvořte koncový bod v cloudu Azure:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Vytvořte nasazení pojmenované blue pod koncovým bodem:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
Vytvoření nasazení může trvat až 15 minut v závislosti na tom, jestli se podkladové prostředí nebo image sestavují poprvé. Následná nasazení, která používají stejné prostředí, se zpracovávají rychleji.
Pokud nechcete blokovat konzolu rozhraní příkazového řádku, můžete k příkazu přidat příznak --no-wait . Tato možnost ale zastaví interaktivní zobrazení stavu nasazení.
Příznak --all-traffic v kódu az ml online-deployment create , který se používá k vytvoření nasazení, přidělí 100 % provozu koncového bodu nově vytvořenému modrému nasazení. Použití tohoto příznaku je užitečné pro účely vývoje a testování, ale pro produkční prostředí můžete chtít směrovat provoz do nového nasazení prostřednictvím explicitního příkazu. Například použijte az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Vytvořte koncový bod:
Pomocí parametru endpoint , který jste definovali dříve, a parametru MLClient , který jste vytvořili dříve, teď můžete vytvořit koncový bod v pracovním prostoru. Tento příkaz spustí vytvoření koncového bodu a během vytváření koncového bodu vrátí potvrzovací odpověď.
ml_client.online_endpoints.begin_create_or_update(endpoint)
Vytvořte nasazení:
Pomocí parametru blue_deployment_with_registered_assets , který jste definovali dříve, a parametru MLClient , který jste vytvořili dříve, teď můžete vytvořit nasazení v pracovním prostoru. Tento příkaz spustí vytvoření nasazení a během vytváření nasazení vrátí potvrzovací odpověď.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Pokud nechcete blokovat konzolu Pythonu, můžete k parametrům přidat příznak no_wait=True . Tato možnost ale zastaví interaktivní zobrazení stavu nasazení.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Vytvoření spravovaného online koncového bodu a nasazení
Pomocí studia můžete vytvořit spravovaný online koncový bod přímo v prohlížeči. Při vytváření spravovaného online koncového bodu v sadě Studio musíte definovat počáteční nasazení. Nemůžete vytvořit prázdný spravovaný online koncový bod.
Jedním ze způsobů, jak vytvořit spravovaný online koncový bod ve Studiu, je ze stránky Modely. Tato metoda také poskytuje snadný způsob, jak přidat model do existujícího spravovaného online nasazení. Nasazení modelu, model-1 který jste zaregistrovali dříve v části Registrace modelu a prostředí :
Přejděte na studio Azure Machine Learning.
V levém podokně vyberte stránku Modely .
Vyberte model s názvem model-1.
Vyberte Nasadit>koncový bod v reálném čase.
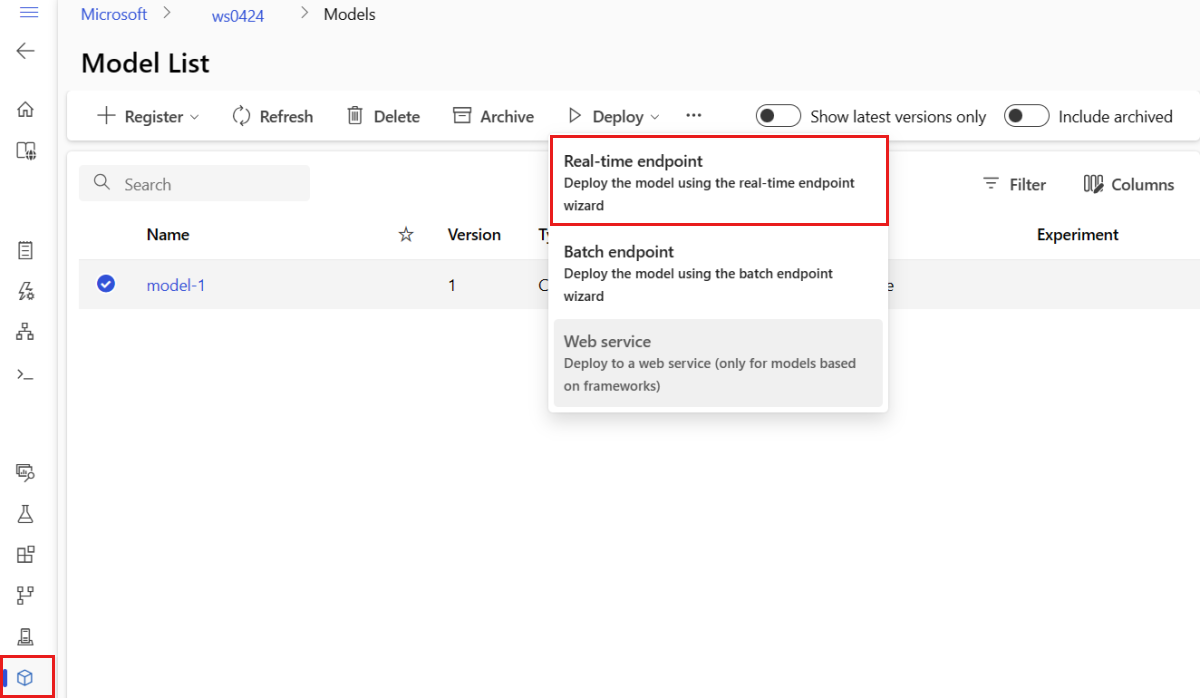
Tato akce otevře okno, ve kterém můžete zadat podrobnosti o koncovém bodu.
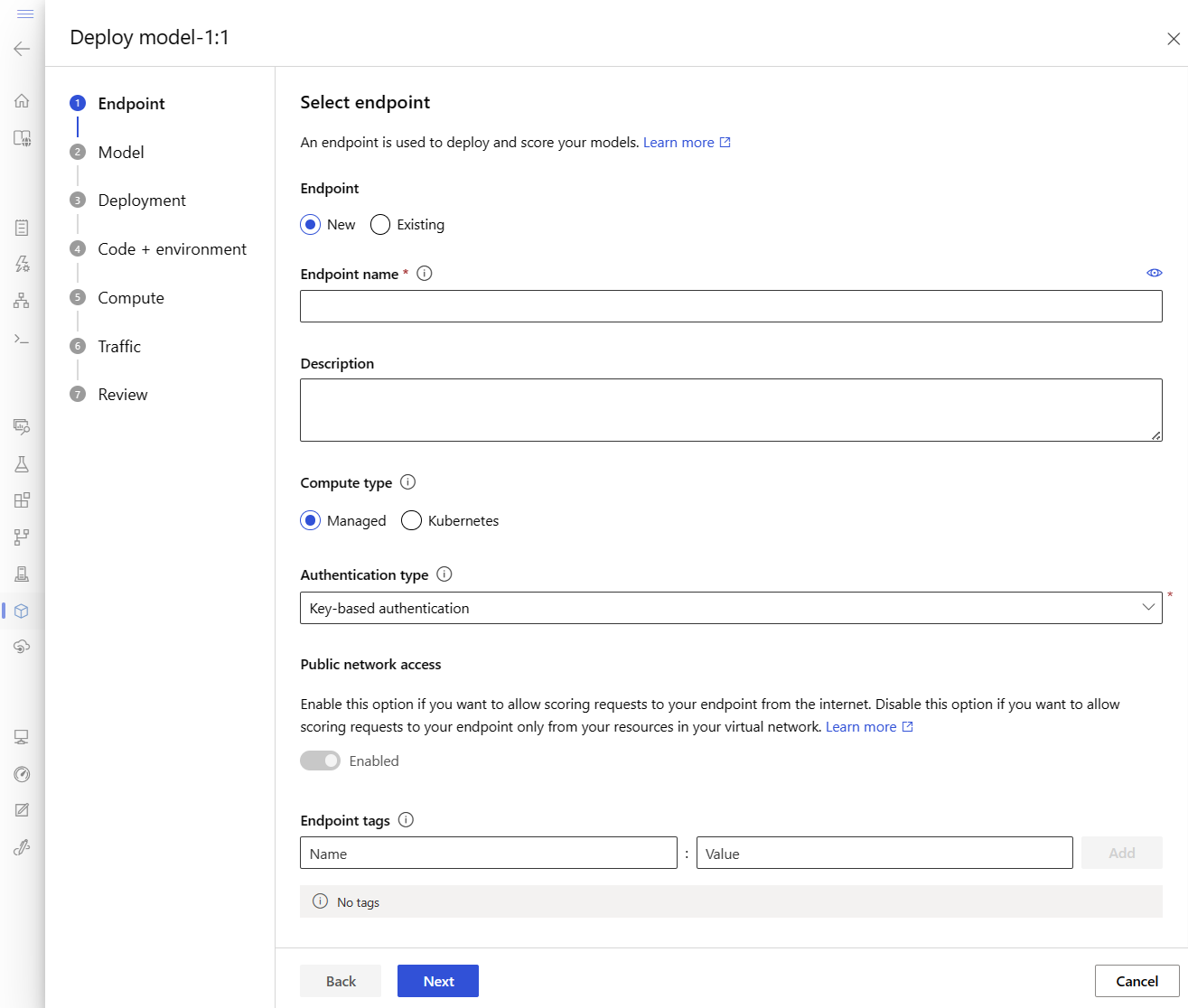
Zadejte název koncového bodu, který je jedinečný v oblasti Azure. Další informace o pravidlech pojmenování najdete v tématu Limity koncových bodů.
Ponechte výchozí výběr: Spravováno pro typ výpočetních prostředků.
Ponechte výchozí výběr: ověřování založené na klíči pro typ ověřování. Další informace o ověřování najdete v tématu Ověřování klientů pro online koncové body.
Vyberte Další , dokud se nedostanete na stránku Nasazení . Přepněte diagnostiku Application Insights na Povoleno , abyste mohli později v nástroji Application Insights zobrazit grafy aktivit koncového bodu a analyzovat metriky a protokoly pomocí Application Insights.
Výběrem možnosti Další přejděte na stránku Kód + prostředí . Vyberte následující možnosti:
-
Vyberte skóringový skript pro inferenci: Projděte a vyberte soubor \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py z repozitáře, který jste naklonovali nebo stáhli dříve.
-
Vyberte oddíl prostředí : Vyberte vlastní prostředí a pak vyberte prostředí my-env:1 , které jste vytvořili dříve.

Vyberte Další a přijměte výchozí hodnoty, dokud se nezobrazí výzva k vytvoření nasazení.
Zkontrolujte nastavení nasazení a vyberte Vytvořit.
Případně můžete vytvořit spravovaný online koncový bod na stránce Koncové body ve Studiu.
Přejděte na studio Azure Machine Learning.
V levém podokně vyberte stránku Koncové body .
Vyberte + Vytvořit.
Tato akce otevře okno pro výběr modelu a zadání podrobností o koncovém bodu a nasazení. Zadejte nastavení pro váš koncový bod a nasazení podle předchozího popisu, a pak vyberte Vytvořit pro vytvoření nasazení.
Pomocí šablony vytvořte online koncový bod:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Po vytvoření koncového bodu nasaďte model do koncového bodu:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Chcete-li ladit chyby ve vašem nasazení, viz Řešení potíží s online nasazením koncových bodů.
Kontrola stavu online koncového bodu
Použijte příkaz show k zobrazení informací v koncovém bodu provisioning_state a nasazení:
az ml online-endpoint show -n $ENDPOINT_NAME
Pomocí příkazu vypište všechny koncové body v pracovním prostoru ve formátu list tabulky:
az ml online-endpoint list --output table
Zkontrolujte stav koncového bodu a zjistěte, jestli se model nasadil bez chyby:
ml_client.online_endpoints.get(name=endpoint_name)
Pomocí metody list vypište všechny koncové body v pracovním prostoru ve formátu tabulky.
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
Metoda vrátí seznam (iterátor) ManagedOnlineEndpoint entit.
Další informace získáte zadáním dalších parametrů. Výstupem je například seznam koncových bodů, jako je tabulka:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Zobrazení spravovaných online koncových bodů
Všechny spravované online koncové body můžete zobrazit na stránce Koncové body . Přejděte na stránku Podrobností koncového bodu a vyhledejte důležité informace, jako je identifikátor URI koncového bodu, stav, testovací nástroje, monitorování aktivit, protokoly nasazení a ukázkový kód spotřeby.
V levém podokně vyberte Koncové body a zobrazte seznam všech koncových bodů v pracovním prostoru.
(Volitelné) Vytvořte filtr pro typ výpočetních prostředků , aby se zobrazily jenom spravované typy výpočetních prostředků.
Výběrem názvu koncového bodu zobrazíte stránku podrobností koncového bodu.

Šablony jsou užitečné pro nasazení prostředků, ale nemůžete je použít k vypsání, zobrazení nebo vyvolání prostředků. K provedení těchto operací použijte Azure CLI, Python SDK nebo studio. Následující kód používá Azure CLI.
show Pomocí příkazu zobrazíte informace v parametru provisioning_state pro koncový bod a nasazení:
az ml online-endpoint show -n $ENDPOINT_NAME
Pomocí příkazu vypište všechny koncové body v pracovním prostoru ve formátu list tabulky:
az ml online-endpoint list --output table
Kontrola stavu online nasazení
V protokolech zkontrolujte, jestli se model nasadil bez chyby.
Pokud chcete zobrazit výstup protokolu z kontejneru, použijte následující příkaz rozhraní příkazového řádku:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Ve výchozím nastavení se protokoly načítají z kontejneru inferenčního serveru. Pokud chcete zobrazit protokoly z kontejneru inicializátoru úložiště, přidejte --container storage-initializer příznak. Další informace o protokolech nasazení najdete v tématu Získání protokolů kontejneru.
Výstup protokolu můžete zobrazit pomocí get_logs metody:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Ve výchozím nastavení se protokoly načítají z kontejneru inferenčního serveru. Pokud chcete zobrazit protokoly z kontejneru inicializátoru úložiště, přidejte možnost container_type="storage-initializer" . Další informace o protokolech nasazení najdete v tématu Získání protokolů kontejneru.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Pokud chcete zobrazit výstup protokolu, vyberte na stránce koncového bodu kartu Protokoly . Pokud máte ve svém koncovém bodu více nasazení, pomocí rozevíracího seznamu vyberte nasazení s protokolem, který chcete zobrazit.
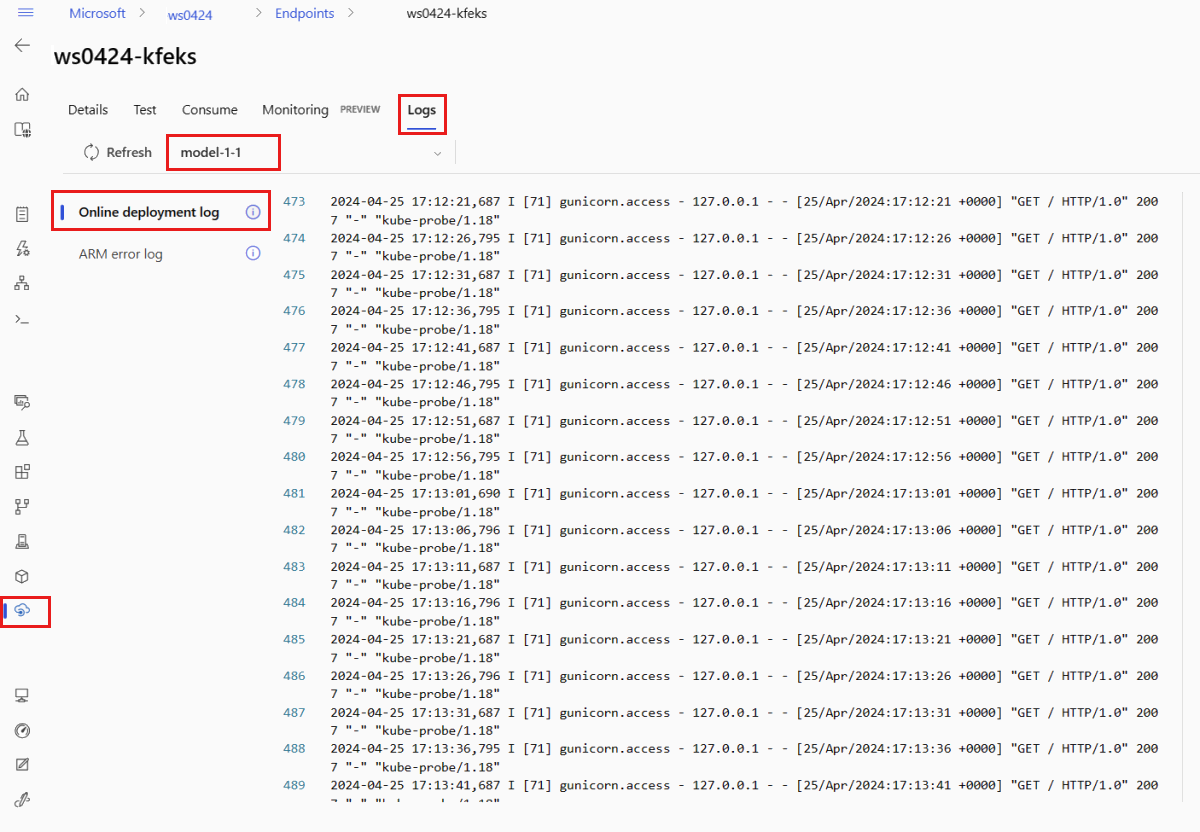
Ve výchozím nastavení se protokoly načítají z inferenčního serveru. Pokud chcete zobrazit protokoly z kontejneru inicializátoru úložiště, použijte Azure CLI nebo Python SDK (podrobnosti najdete na jednotlivých kartách). Protokoly z kontejneru inicializátoru úložiště poskytují informace o tom, jestli se data kódu a modelu úspěšně stáhla do kontejneru. Další informace o protokolech nasazení najdete v tématu Získání protokolů kontejneru.
Šablony jsou užitečné pro nasazení prostředků, ale nemůžete je použít k vypsání, zobrazení nebo vyvolání prostředků. K provedení těchto operací použijte Azure CLI, Python SDK nebo studio. Následující kód používá Azure CLI.
Pokud chcete zobrazit výstup protokolu z kontejneru, použijte následující příkaz rozhraní příkazového řádku:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Ve výchozím nastavení se protokoly načítají z kontejneru inferenčního serveru. Pokud chcete zobrazit protokoly z kontejneru inicializátoru úložiště, přidejte --container storage-initializer příznak. Další informace o protokolech nasazení najdete v tématu Získání protokolů kontejneru.
Vyvolejte koncový bod k ohodnocení dat pomocí vašeho modelu.
invoke K vyvolání koncového bodu a určení skóre některých dat použijte příkaz nebo klienta REST podle vašeho výběru:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Získejte klíč použitý k ověření koncového bodu:
Můžete určit, které objekty zabezpečení Microsoft Entra mohou získat ověřovací klíč tím, že je přiřadíte k vlastní roli, která umožňuje Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action a Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action. Další informace o správě autorizace pro pracovní prostory najdete v tématu Správa přístupu k pracovnímu prostoru Azure Machine Learning.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Data ohodnoťte pomocí curl.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Všimněte si, že k získání přihlašovacích údajů pro ověřování používáte show příkazy a get-credentials příkazy. Všimněte si také, že používáte --query příznak k filtrování pouze potřebných atributů. Pro více informací o příznaku --query, podívejte se na Příkaz Azure CLI pro zobrazení výstupu.
Pokud chcete zobrazit protokoly vyvolání, spusťte get-logs to znovu.
Pomocí parametru MLClient , který jste vytvořili dříve, získáte popisovač koncového bodu. Koncový bod pak můžete vyvolat pomocí invoke příkazu s následujícími parametry:
-
endpoint_name: Název koncového bodu.
-
request_file: Soubor s daty žádosti.
-
deployment_name: Název konkrétního nasazení pro testování v koncovém bodu.
Odešlete ukázkový požadavek pomocí souboru JSON .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
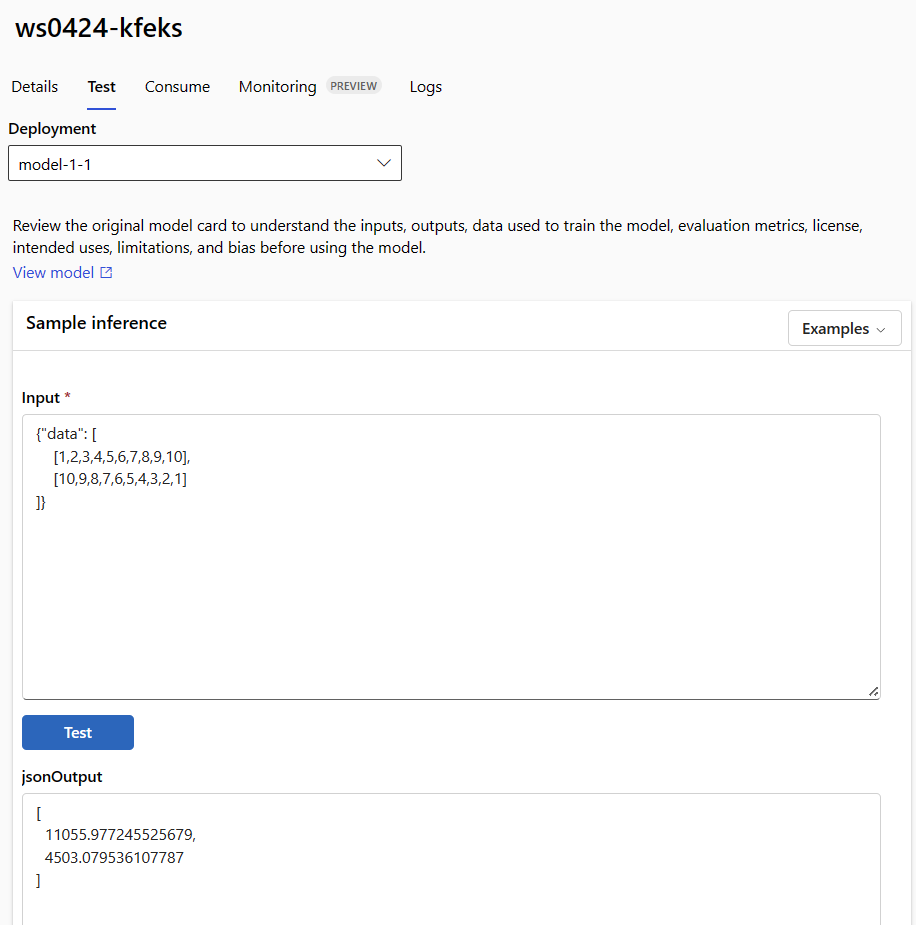
K otestování spravovaného online nasazení použijte kartu Test na stránce podrobností koncového bodu. Zadejte ukázkový vstup a prohlédněte si výsledky.
Na stránce podrobností koncového bodu vyberte kartu Test .
V rozevíracím seznamu vyberte nasazení, které chcete otestovat.
Zadejte ukázkový vstup.
Vyberte Test.
Šablony jsou užitečné pro nasazení prostředků, ale nemůžete je použít k vypsání, zobrazení nebo vyvolání prostředků. K provedení těchto operací použijte Azure CLI, Python SDK nebo studio. Následující kód používá Azure CLI.
invoke K vyvolání koncového bodu a určení skóre některých dat použijte příkaz nebo klienta REST podle vašeho výběru:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Volitelné) Aktualizace nasazení
Pokud chcete aktualizovat kód, model nebo prostředí, aktualizujte soubor YAML. Pak spusťte az ml online-endpoint update příkaz.
Pokud aktualizujete počet instancí (pro škálování nasazení) spolu s dalšími nastaveními modelu (například kód, model nebo prostředí) v jednom update příkazu, provede se nejprve operace škálování. Další aktualizace se použijí. Tyto operace je vhodné provádět samostatně v produkčním prostředí.
Vysvětlení toho, jak update funguje:
Otevřete soubor online/model-1/onlinescoring/score.py.
Změňte poslední řádek init() funkce: Za logging.info("Init complete") přidejte logging.info("Updated successfully").
Uložte soubor.
Spusťte tento příkaz:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
Aktualizace pomocí YAML je deklarativní. To znamená, že změny v YAML se projeví v podkladových prostředcích Resource Manageru (koncových bodech a nasazeních). Deklarativní přístup usnadňuje GitOps: Všechny změny koncových bodů a nasazení (dokonce instance_count) procházejí YAML.
Můžete použít obecné parametry aktualizace, například parametr --set, s příkazem CLI update, abyste přepsali atributy ve vašem YAML nebo nastavili specifické atributy, aniž byste je předali v souboru YAML. Použití --set pro jednotlivé atributy je zvláště cenné ve scénářích vývoje a testování. Pokud například chcete zvýšit hodnotu instance_count pro první nasazení, můžete použít přepínač --set instance_count=2. Protože se ale YAML neaktualizuje, tato technika nepodporuje GitOps.
Zadání souboru YAML není povinné. Pokud například chcete otestovat různá nastavení souběžnosti pro konkrétní nasazení, můžete zkusit něco podobného az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4. Tento přístup zachová veškerou existující konfiguraci, ale aktualizuje pouze zadané parametry.
Protože jste upravili init() funkci, která se spustí při vytvoření nebo aktualizaci koncového bodu, zobrazí se zpráva Updated successfully v protokolech. Načtěte protokoly spuštěním příkazu:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Příkaz update také funguje s místními nasazeními. Použijte stejný az ml online-deployment update příkaz s příznakem --local .
Pokud chcete aktualizovat kód, model nebo prostředí, aktualizujte konfiguraci a spuštěním MLClientonline_deployments.begin_create_or_update metody vytvořte nebo aktualizujte nasazení.
Pokud aktualizujete počet instancí (pro škálování nasazení) spolu s dalšími nastaveními modelu (například kód, model nebo prostředí) v jedné begin_create_or_update metodě, provede se nejprve operace škálování. Pak se použijí další aktualizace. Tyto operace je vhodné provádět samostatně v produkčním prostředí.
Vysvětlení toho, jak begin_create_or_update funguje:
Otevřete soubor online/model-1/onlinescoring/score.py.
Změňte poslední řádek init() funkce: Za logging.info("Init complete") přidejte logging.info("Updated successfully").
Uložte soubor.
Spusťte metodu:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Protože jste upravili init() funkci, která se spustí při vytvoření nebo aktualizaci koncového bodu, zobrazí se zpráva Updated successfully v protokolech. Načtěte protokoly spuštěním příkazu:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Metoda begin_create_or_update také funguje s místními nasazeními. Použijte stejnou metodu s příznakem local=True .
V současné době můžete aktualizovat jen počet instancí nasazení. Pomocí následujících pokynů můžete vertikálně navýšit nebo snížit kapacitu jednotlivých nasazení úpravou počtu instancí:
- Otevřete stránku podrobností koncového bodu a vyhledejte kartu pro nasazení, které chcete aktualizovat.
- Vyberte ikonu pro úpravy (ikonu tužky) vedle názvu nasazení.
- Aktualizujte počet instancí spojených s nasazením. Zvolte mezi výchozímnebo cílovým využitím pro typ škálování nasazení.
- Pokud vyberete Výchozí, můžete také zadat číselnou hodnotu pro počet instancí.
- Pokud vyberete Cílové využití, můžete zadat hodnoty, které se mají použít pro parametry při automatickém škálování nasazení.
- Výběrem možnosti Aktualizovat dokončíte aktualizaci počtu instancí pro vaše nasazení.
V současné době není možné nasazení aktualizovat pomocí šablony ARM.
Poznámka:
Aktualizace nasazení v této části je příkladem postupné aktualizace na místě.
- U spravovaného online koncového bodu se nasazení aktualizuje na novou konfiguraci s 20% uzlů najednou. To znamená, že pokud má nasazení 10 uzlů, aktualizují se současně 2 uzly.
- V případě online koncového bodu Kubernetes systém postupně vytvoří novou nasazovací instanci s novou konfigurací a odstraní původní starou instanci.
- U produkčního využití zvažte modré-zelené nasazení, které nabízí bezpečnější alternativu k aktualizaci webové služby.
Automatické škálování automaticky spustí správné množství prostředků ke zvládnutí zatížení u vaší aplikace. Spravované online koncové body podporují automatické škálování prostřednictvím integrace s funkcí automatického škálování služby Azure Monitor. Informace o konfiguraci automatického škálování najdete v tématu Automatické škálování online koncových bodů.
(Volitelné) Monitorování smlouvy SLA pomocí služby Azure Monitor
Pokud chcete zobrazit metriky a nastavit upozornění na základě vaší smlouvy SLA, postupujte podle kroků popsaných v online koncových bodech monitorování.
(Volitelné) Integrace s Log Analytics
Příkaz get-logs pro rozhraní příkazového řádku nebo metodu get_logs sady SDK poskytuje pouze posledních několik stovek řádků protokolů z automaticky vybrané instance. Log Analytics ale poskytuje způsob, jak trvale ukládat a analyzovat protokoly. Další informace o tom, jak používat protokolování, najdete v tématu Použití protokolů.
Odstranění koncového bodu a nasazení
Pomocí následujícího příkazu odstraňte koncový bod a všechna jeho základní nasazení:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Pomocí následujícího příkazu odstraňte koncový bod a všechna jeho základní nasazení:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Pokud nebudete používat koncový bod a nasazení, odstraňte je. Odstraněním koncového bodu odstraníte také všechna jeho základní nasazení.
- Přejděte na studio Azure Machine Learning.
- V levém podokně vyberte stránku Koncové body .
- Vyberte koncový bod.
- Vyberte Odstranit.
Případně můžete spravovaný online koncový bod odstranit přímo tak, že na stránce podrobností o koncovém bodu vyberete ikonu Odstranit.
Pomocí následujícího příkazu odstraňte koncový bod a všechna jeho základní nasazení:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Související obsah









