Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V této sérii kurzů se naučíte používat spravované úložiště funkcí ke zjišťování, vytváření a zprovoznění funkcí Azure Machine Learning. Funkce bezproblémově integrují fáze vytváření prototypů, trénování a zprovoznění životního cyklu strojového učení.
Důležité
Azure Cache for Redis oznámila časovou osu vyřazení všech skladových položek. Doporučujeme přesunout existující instance Azure Cache for Redis na Azure Managed Redis, jakmile budete moct.
Pokyny k migraci:
- Úrovně Basic, Standard a Premium migrovat do Azure Managed Redis.
- Migrujte podnikovou úroveň do Azure Managed Redis
Další podrobnosti o odchodu do důchodu:
- Ukončení služby Azure Cache pro Redis: Co vědět a jak se připravit
- Nejčastější dotazy k ukončení podpory Azure Cache for Redis
Ve fázi vytváření prototypů experimentujete s různými funkcemi a ve fázi zprovoznění nasadíte modely, které k vyhledání dat funkcí používají kroky odvozování. Funkce slouží jako spojovací tkáně v životním cyklu.
K trénování modelů odvozování pomocí funkcí z úložišť funkcí použijete pracovní prostor projektu Azure Machine Learning. Mnoho pracovních prostorů projektu může sdílet a opakovaně používat stejné úložiště funkcí. Další informace o spravovaném úložišti funkcí najdete v tématu Co je spravované úložiště funkcí a Seznámení s entitami na nejvyšší úrovni ve spravovaném úložišti funkcí.
Požadavky
- Pracovní prostor Azure Machine Learning. Další informace o vytváření pracovních prostorů najdete v tématu Rychlý start: Vytvoření prostředků pracovního prostoru.
- Role vlastníka ve skupině prostředků, ve které je vytvořené úložiště funkcí.
Kurzy k sadě SDK + ROZHRANÍ příkazového řádku nebo sady SDK
Tato série kurzů používá Azure Machine Learning poznámkový blok Sparku pro vývoj. V závislosti na vašich potřebách si můžete vybrat mezi dvěma cestami, jak dokončit sérii tutoriálů.
Trať SDK + CLI používá Python SDK pro vývoj a testování sad funkcí a Azure CLI pro operace vytváření, čtení, aktualizace a mazání (CRUD). Tato stopa je užitečná v kontextu scénářů kontinuální integrace a průběžného doručování (CI/CD) nebo GitOps, které využívají CLI a YAML.
Trať pouze pro SDK používá pouze Python SDK. Tato stopa nabízí čistý vývoj a nasazení založené na Python.
Stopu vyberete tak, že poznámkový blok otevřete v cli_and_sdk nebo ve složce sdk_only naklonovaného poznámkového bloku. Postupujte podle pokynů na odpovídající kartě v návodech.
Sled SDK a CLI používá Azure CLI pro operace CRUD a základní sadu SDK pro úložiště funkcí k vývoji a testování sady funkcí. Tento přístup je užitečný pro scénáře GitOps nebo CI/CD, které používají rozhraní příkazového řádku a YAML. Soubor conda.yml , který nahrajete, tyto prostředky nainstaluje.
- Rozhraní příkazového řádku se používá pro operace CRUD s úložišti funkcí, sadami funkcí a entitami úložiště funkcí.
SDK jádra úložiště funkcí
azureml-featurestoreje určené pro vývoj a využití sad funkcí. Sada SDK provádí následující operace:- Seznamuje nebo získává zaregistrovanou funkční sadu.
- Generuje nebo řeší specifikaci získávání prvku.
- Spustí definici sady funkcí pro vygenerování datového rámce Spark.
- Generuje trénování pomocí spojení k určitému bodu v čase.
Kurz 1: Vývoj a registrace sady funkcí
Tento první kurz vás provede vytvořením specifikace sady funkcí s vlastními transformacemi. Poté tuto množinu vlastností použijete ke generování trénovacích dat, povolení materializace a provedení zpětného doplnění. Naučíte se:
- Vytvořte nový minimální prostředek úložiště funkcí.
- Vývoj a místní testování sady funkcí s možností transformace funkcí
- Zaregistrujte entitu úložiště funkcí v úložišti funkcí.
- Zaregistrujte sadu funkcí, kterou jste vytvořili v úložišti funkcí.
- Vygenerujte ukázkový trénovací datový rámec pomocí funkcí, které jste vytvořili.
- Povolte offline materializaci na sadách atributů a doplňte data atributů.
Klonování poznámkového bloku
V studio Azure Machine Learning vyberte Notebooks v levé navigační nabídce a potom na stránce Notebooks vyberte kartu Samples.
Rozbalte složky SDK v2>sdk>python, klikněte pravým tlačítkem na složku featurestore_sample a vyberte Klonovat.

V podokně Vybrat cílový adresář se ujistěte, že se zobrazí Uživatelé><your_username>>featurestore_sample a vyberte Klonovat. Featurestore_sample se klonuje do uživatelského adresáře vašeho pracovního prostoru.
Přejděte do naklonovaného poznámkového bloku na kartě Soubory na stránce Poznámkový blok a rozbalte položku Uživatelé><your_username>>featurestore_sample>projekt>env.
Klikněte pravým tlačítkem na soubor conda.yml a výběrem možnosti Stáhnout ho stáhněte do počítače, abyste ho mohli později nahrát do serverového prostředí.

Příprava a spuštění poznámkového bloku
V levém podokně na kartě Soubory rozbalte featurestore_sample>notebooks>sdk_and_cli nebo sdk_only podle toho, kterou stopu chcete spustit.
Otevřete první kapitolu kurzu tak, že ji vyberete.
V pravém horním rohu stránky Poznámkový blok vyberte šipku rozevíracího seznamu vedle položky Compute a vyberte Bezserverové výpočetní prostředky Sparku – K dispozici. Připojení výpočetních prostředků může trvat minutu nebo dvě.
Na horní liště nad souborem poznámkového bloku vyberte Konfigurovat relaci.
Na obrazovce Konfigurovat vyberte v levém podokně balíčky Python.
Vyberte Nahrát soubor conda a v části Vybrat soubor conda přejděte a otevřete conda.yml soubor, který jste stáhli.
Volitelně vyberte Nastavení v levém podokně a zvyšte délku časového limitu relace , abyste zabránili vypršení časového limitu bezserverového spuštění Sparku.
Vyberte Použít.


Spusťte poznámkový blok
Posuňte se v poznámkovém bloku dolů, dokud se nedostanete na první buňku, a spusťte ji pro zahájení relace. Spuštění relace může trvat až 15 minut.
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins. print("start spark session")Ve druhé buňce aktualizujte
<your_user_alias>zástupný symbol svým uživatelským jménem. Spuštěním buňky nastavte kořenový adresář pro příklad.import os # Please update <your_user_alias> below (or any custom directory you uploaded the samples to). # You can find the name from the directory structure in the left navigation panel. root_dir = "./Users/<your_user_alias>/featurestore_sample" if os.path.isdir(root_dir): print("The folder exists.") else: print("The folder does not exist. Please create or fix the path")Spuštěním další buňky nainstalujte rozšíření Azure Machine Learning CLI.
# Install AzureML CLI extension !az extension add --name mlSpusťte následující buňku pro autentizaci Azure CLI.
# Authenticate !az loginSpuštěním další buňky nastavte výchozí předplatné Azure.
# Set default subscription import os subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] !az account set -s $subscription_id
Vytvoření minimálního úložiště funkcí
Nastavte parametry úložiště funkcí, včetně názvu, umístění a dalších hodnot. Zadejte
<FEATURESTORE_NAME>a poté spusťte buňku.# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Vytvořte úložiště funkcí.
!az ml feature-store create --subscription $featurestore_subscription_id --resource-group $featurestore_resource_group_name --location $featurestore_location --name $featurestore_nameInicializujte hlavního klienta sady SDK úložiště funkcí pro Azure Machine Learning. Klient se používá k vývoji a využívání funkcí.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Udělte identitě uživatele roli AzureML Datoví vědci v úložišti funkcí. Získejte hodnotu ID objektu Microsoft Entra z portálu Azure, jak je popsáno v tématu Najít ID objektu uživatele.
Spuštěním následující buňky přiřaďte roli AzureML Datoví vědci vaší identitě uživatele, aby bylo možné vytvářet prostředky v pracovním prostoru úložiště funkcí. Zástupný symbol
<USER_AAD_OBJECTID>nahraďte vaším ID objektu Microsoft Entra. Oprávnění může potřebovat nějaký čas na propagaci.your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_idDalší informace o řízení přístupu najdete v tématu Správa řízení přístupu pro spravované úložiště funkcí.
Prototyp a vývoj sady funkcí
Tento poznámkový blok používá ukázková data hostovaná v veřejně přístupném kontejneru objektů blob, která můžete ve Sparku číst prostřednictvím wasbs ovladače. Pokud vytváříte sady funkcí pomocí vlastních zdrojových dat, hostujte je v účtu Azure Data Lake Storage a v cestě k datům použijte ovladač abfss.
Prozkoumání zdrojových dat transakcí
Vytvořte sadu funkcí s názvem transactions, která obsahuje funkce založené na agregaci s využitím klouzavých oken.
# remove the "." in the roor directory path as we need to generate absolute path to read from spark
transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet"
transactions_src_df = spark.read.parquet(transactions_source_data_path)
display(transactions_src_df.head(5))
# Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueMístní vývoj sady funkcí
Specifikace sady funkcí je samostatná definice sady funkcí, kterou můžete místně vyvíjet a testovat. Vytvořte následující agregační funkce s posuvným oknem:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
from azureml.featurestore import create_feature_set_spec
from azureml.featurestore.contracts import (
DateTimeOffset,
TransformationCode,
Column,
ColumnType,
SourceType,
TimestampColumn,
)
from azureml.featurestore.feature_source import ParquetFeatureSource
transactions_featureset_code_path = (
root_dir + "/featurestore/featuresets/transactions/transformation_code"
)
transactions_featureset_spec = create_feature_set_spec(
source=ParquetFeatureSource(
path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet",
timestamp_column=TimestampColumn(name="timestamp"),
source_delay=DateTimeOffset(days=0, hours=0, minutes=20),
),
feature_transformation=TransformationCode(
path=transactions_featureset_code_path,
transformer_class="transaction_transform.TransactionFeatureTransformer",
),
index_columns=[Column(name="accountID", type=ColumnType.string)],
source_lookback=DateTimeOffset(days=7, hours=0, minutes=0),
temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0),
infer_schema=True,
)Projděte si soubor kódu transformace funkcí: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Poznamenejte si průběžnou agregaci definovanou pro funkce. Tento soubor je transformátor Sparku. Další informace o sadě funkcí a transformacích najdete v tématu Co je spravované úložiště funkcí?
Export jako specifikace sady funkcí
Pokud chcete zaregistrovat specifikaci sady funkcí v úložišti funkcí, uložte tuto specifikaci do zadaného umístění a formátu, který podporuje správu zdrojového kódu.
import os
# Create a new folder to dump the feature set specification.
transactions_featureset_spec_folder = (
root_dir + "/featurestore/featuresets/transactions/spec"
)
# Check if the folder exists, create one if it does not exist.
if not os.path.exists(transactions_featureset_spec_folder):
os.makedirs(transactions_featureset_spec_folder)
transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)Pokud chcete zobrazit specifikaci featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml , otevřete vygenerovanou transactions specifikaci sady funkcí ze stromu souborů. Specifikace obsahuje tyto prvky:
-
source: Odkaz na prostředek úložiště. V tomto případě se jedná o soubor parquet v prostředku úložiště objektů blob. -
features: Seznam funkcí a jejich datových typů. Pokud zadáte transformační kód, musí kód vrátit datový rámec, který se mapuje na funkce a datové typy. -
index_columns: Klíče spojení potřebné pro přístup k hodnotám ze sady funkcí.
Registrace entity úložiště funkcí
Entity pomáhají vynucovat osvědčený postup použití stejné definice klíče spojení napříč sadami funkcí, které používají stejné logické entity. Příklady entit zahrnují accounts a customers. Entity se obvykle vytvářejí jednou a pak se znovu používají napříč sadami funkcí. Další informace najdete v tématu Vysvětlení entit nejvyšší úrovně ve spravovaném úložišti funkcí.
Vytvořte entitu account , která má klíč accountID spojení typu string. Zaregistrujte entitu account v úložišti funkcí.
account_entity_path = root_dir + "/featurestore/entities/account.yaml"
!az ml feature-store-entity create --file $account_entity_path --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_nameRegistrace sady funkcí v úložišti funkcí
Následující kód zaregistruje objekt sady funkcí v úložišti funkcí. Tento prostředek pak můžete znovu použít a snadno ho sdílet. Registrace objektu funkční sady nabízí spravované funkce, včetně správy verzí a materializace. Další kurzy v této sérii se týkají spravovaných funkcí.
account_featureset_path = (
root_dir + "/featurestore/featuresets/transactions/featureset_asset.yaml"
)
!az ml feature-set create --file $account_featureset_path --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_nameProzkoumejte uživatelské rozhraní feature store
Vytváření a aktualizace Feature Store aktiv lze provádět pouze prostřednictvím sady SDK a rozhraní příkazového řádku. Uživatelské rozhraní Machine Learning můžete použít k vyhledávání nebo procházení úložiště funkcí.
- Otevřete globální cílovou stránku Azure Machine Learning.
- V levém podokně vyberte Funkční úložiště.
- V seznamu dostupných úložišť funkcí vyberte úložiště funkcí, které jste vytvořili dříve v tomto kurzu.
Přiřazení role Čtenář dat objektů blob služby Storage
Role Čtenář dat objektů blob služby Storage musí být přiřazena k vašemu uživatelskému účtu, aby se zajistilo, že uživatelský účet může číst materializovaná funkční data z offline úložiště materializace.
Získejte informace o offline úložišti materializace ze stránky Přehled uživatelského rozhraní úložiště funkcí. Hodnoty pro účet úložiště <SUBSCRIPTION_ID>, účet úložiště <RESOURCE_GROUP> a offline materializačního úložiště <STORAGE_ACCOUNT_NAME> jsou umístěny na kartě offline úložiště materializace.

Spusťte následující buňku kódu pro přiřazení role. Může nějakou dobu trvat, než se oprávnění plně projeví.
storage_subscription_id = "<SUBSCRIPTION_ID>"
storage_resource_group_name = "<RESOURCE_GROUP>"
storage_account_name = "<STORAGE_ACCOUNT_NAME>"
# Set the ADLS Gen2 storage account ARM ID
gen2_storage_arm_id = "/subscriptions/{sub_id}/resourceGroups/{rg}/providers/Microsoft.Storage/storageAccounts/{account}".format(
sub_id=storage_subscription_id,
rg=storage_resource_group_name,
account=storage_account_name,
)
print(gen2_storage_arm_id)
!az role assignment create --role "Storage Blob Data Reader" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $gen2_storage_arm_idDalší informace o řízení přístupu najdete v tématu Správa řízení přístupu pro spravované úložiště funkcí.
Generování datového rámce trénovacích dat
Vygenerujte datový rámec trénovacích dat pomocí registrační sady vlastností.
Data sledování zatížení zachycená během samotné události.
Data pozorování obvykle zahrnují základní data používaná pro trénování a odvozování, která spojují s daty funkcí k vytvoření úplného trénovacího datového prostředku. Následující data mají základní transakční data, včetně ID transakce, ID účtu a hodnot množství transakcí. Protože data používáte pro trénování, má také připojenou cílovou proměnnou
is_fraud.observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueZískejte zaregistrovanou sadu funkcí a uveďte její funkce.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Vyberte funkce, které se mají stát součástí trénovacích dat, a pomocí sady SDK úložiště funkcí vygenerujte samotná trénovací data. Spojení k určitému bodu v čase připojí funkce k trénovacím datům.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value
Povolení offline materializace
Materializace vypočítá hodnoty funkcí pro okno funkce a uloží tyto hodnoty do materializačního úložiště. Všechny dotazy funkcí mohou pak použít tyto hodnoty z úložiště materializace.
Bez materializace dotaz sady funkcí aplikuje transformace na zdroj za běhu a vypočítá funkce před vrácením hodnot. Tento proces funguje dobře pro fázi vytváření prototypů. Pro trénování a odvozování operací v produkčním prostředí ale materializace funkcí zajišťuje větší spolehlivost a dostupnost.
Výchozí úložiště objektů blob pro úložiště funkcí je kontejner Azure Data Lake Storage (ADLS). Úložiště funkcí je vždy vytvořeno s offline úložištěm materializace a spravovanou identitou přidělenou uživatelem (UAI).
Pokud se vytvoří úložiště funkcí s výchozími hodnotami offline_store=None parametrů a materialization_identity=Nonesystém provede následující nastavení:
- Vytvoří kontejner ADLS jako offline úložiště.
- Vytvoří UAI a přiřadí ho k úložišti funkcí jako materializační identitu.
- Přiřadí uživatelskému rozhraní (UAI) v offline úložišti požadovaná oprávnění řízení přístupu na základě role (RBAC).
Volitelně můžete použít existující kontejner ADLS jako offline úložiště definováním parametru offline_store . Pro offline úložiště materializace jsou podporovány pouze kontejnery ADLS.
Volitelně můžete zadat existující UAI definováním parametru materialization_identity. Požadovaná oprávnění RBAC se při vytváření úložiště funkcí přiřazují k UAI v offline úložišti.
Následující ukázka kódu ukazuje vytvoření úložiště funkcí s uživatelem definovanými offline_store parametry a materialization_identity parametry.
import os
from azure.ai.ml import MLClient
from azure.ai.ml.identity import AzureMLOnBehalfOfCredential
from azure.ai.ml.entities import (
ManagedIdentityConfiguration,
FeatureStore,
MaterializationStore,
)
from azure.mgmt.msi import ManagedServiceIdentityClient
# Get an existing offline store
storage_subscription_id = "<OFFLINE_STORAGE_SUBSCRIPTION_ID>"
storage_resource_group_name = "<OFFLINE_STORAGE_RESOURCE_GROUP>"
storage_account_name = "<OFFLINE_STORAGE_ACCOUNT_NAME>"
storage_file_system_name = "<OFFLINE_STORAGE_CONTAINER_NAME>"
# Get ADLS container ARM ID
gen2_container_arm_id = "/subscriptions/{sub_id}/resourceGroups/{rg}/providers/Microsoft.Storage/storageAccounts/{account}/blobServices/default/containers/{container}".format(
sub_id=storage_subscription_id,
rg=storage_resource_group_name,
account=storage_account_name,
container=storage_file_system_name,
)
offline_store = MaterializationStore(
type="azure_data_lake_gen2",
target=gen2_container_arm_id,
)
# Get an existing UAI
uai_subscription_id = "<UAI_SUBSCRIPTION_ID>"
uai_resource_group_name = "<UAI_RESOURCE_GROUP>"
uai_name = "<FEATURE_STORE_UAI_NAME>"
msi_client = ManagedServiceIdentityClient(
AzureMLOnBehalfOfCredential(), uai_subscription_id
)
managed_identity = msi_client.user_assigned_identities.get(
uai_resource_group_name, uai_name
)
# Get UAI information
uai_principal_id = managed_identity.principal_id
uai_client_id = managed_identity.client_id
uai_arm_id = managed_identity.id
materialization_identity1 = ManagedIdentityConfiguration(
client_id=uai_client_id, principal_id=uai_principal_id, resource_id=uai_arm_id
)
# Create a feature store
featurestore_name = "<FEATURE_STORE_NAME>"
featurestore_location = "<AZURE_REGION>"
featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"]
featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]
ml_client = MLClient(
AzureMLOnBehalfOfCredential(),
subscription_id=featurestore_subscription_id,
resource_group_name=featurestore_resource_group_name,
)
# Use existing ADLS Gen2 container and UAI
fs = FeatureStore(
name=featurestore_name,
location=featurestore_location,
offline_store=offline_store,
materialization_identity=materialization_identity1,
)
fs_poller = ml_client.feature_stores.begin_update(fs)
print(fs_poller.result())
Po povolení materializace sady funkcí v sadě funkcí transakcí můžete provést backfill. Můžete také naplánovat opakující se materializační úlohy. Další informace naleznete v třetím kurzu v této sérii, povolení opakované materializace a spuštění dávkové odvozování.
Nastavení spark.sql.shuffle.partitions v souboru YAML
Konfigurace spark.sql.shuffle.partitions Sparku je volitelný parametr, který může ovlivnit počet souborů Parquet vygenerovaných za den při materializaci sady funkcí do offline úložiště. Výchozí hodnota tohoto parametru je 200.
Osvědčeným postupem je vyhnout se generování mnoha malých souborů Parquet. Pokud se načítání funkcí offline po materializaci sady funkcí zpomalí, otevřete odpovídající složku v offline úložišti. Zkontrolujte, jestli problém zahrnuje příliš mnoho malých souborů Parquet za den, a upravte hodnotu tohoto parametru podle velikosti dat funkce.
Poznámka:
Ukázková data použitá v tomto poznámkovém bloku jsou malá. Proto je parametr spark.sql.shuffle.partitions nastaven na 1 v souboru featureset_asset_offline_enabled.yaml.
transaction_asset_mat_yaml = (
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)
!az ml feature-set update --file $transaction_asset_mat_yaml --resource-group $featurestore_resource_group_name --feature-store-name $featurestore_nameProstředek sady funkcí můžete také uložit jako prostředek YAML.
Doplnění dat pro funkce transakcí
Materializace vypočítá hodnoty funkcí pro okno funkce a uloží tyto vypočítané hodnoty do materializačního úložiště. Materializace funkcí zvyšuje spolehlivost a dostupnost vypočítaných hodnot. Všechny dotazy na funkce teď používají hodnoty z úložiště materializace. Tento krok provede jednorázové doplnění dat pro časové okno funkce o délce 18 měsíců.
Poznámka:
Možná budete muset určit hodnotu okna pro doplnění dat (backfill). Okno se musí shodovat s oknem tréninkových dat. Pokud například chcete pro trénování použít 18 měsíců dat, musíte načíst atributy za posledních 18 měsíců. To znamená, že byste měli znovu vyplňovat 18měsíční interval.
Následující buňka kódu materializuje data podle aktuálního stavu None nebo Incomplete pro definované okno funkce. Lze zadat seznam více než jednoho stavu dat, například ["None", "Incomplete"], v jedné úloze doplnění.
feature_window_start_time = "2022-01-01T00:00.000Z"
feature_window_end_time = "2023-06-30T00:00.000Z"
!az ml feature-set backfill --name transactions --version 1 --by-data-status "['None', 'Incomplete']" --feature-window-start-time $feature_window_start_time --feature-window-end-time $feature_window_end_time --feature-store-name $featurestore_name --resource-group $featurestore_resource_group_nameNávod
- Sloupec
timestampby měl následovat podleyyyy-MM-ddTHH:mm:ss.fffZformátu. - Granularita
feature_window_start_timeafeature_window_end_timeje omezená na sekundy. Milisekundy v objektudatetimejsou ignorovány. - Úloha materializace se odešle pouze v případě, že data v okně funkce odpovídají definovanému
data_statuspři odesílání úlohy.
Vytiskněte ukázková data ze sady funkcí. Výstupní informace ukazují, že data byla načtena z úložiště materializace. Metoda get_offline_features() načte trénovací a odvozená data a ve výchozím nastavení také používá úložiště materializace.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Další prozkoumání materializace funkcí offline
Stav materializace funkcí pro sadu funkcí můžete prozkoumat v uživatelském rozhraní materializačních úloh .
Otevřete globální cílovou stránku Azure Machine Learning.
V levém podokně vyberte Funkční úložiště.
V seznamu dostupných úložišť funkcí vyberte úložiště funkcí, pro které jste provedli obnovení.
Vyberte kartu Materializace úloh .
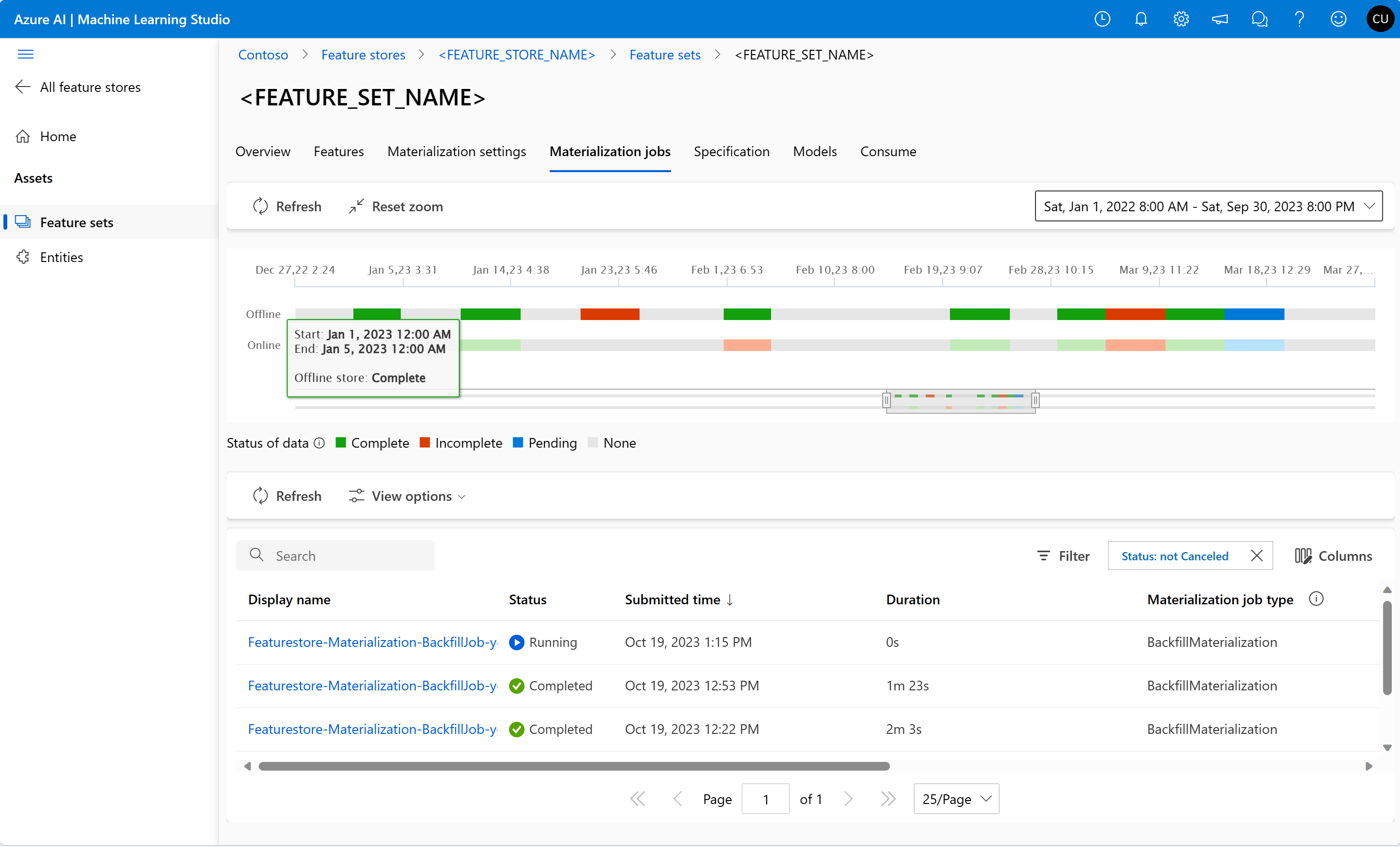

Stav materializace dat může být:
- Dokončeno (zelená)
- Neúplné (červené)
- Čeká na vyřízení (modrá)
- Žádná (šedá)
Interval dat představuje souvislou část dat se stejným stavem materializace dat. Například předchozí snímek má v offline úložišti materializace 16 datových intervalů. Data můžou mít maximálně 2 000 datových intervalů. Pokud data obsahují více než 2 000 datových intervalů, vytvořte novou verzi sady funkcí.
Během doplnění dat se odešle nová úloha materializace pro každý interval dat, který spadá do definovaného okna vlastností. Žádná úloha se neodesílá, pokud už je úloha materializace v čekání nebo spuštěná pro datový interval, který není zpětně vyplněn.
Můžete zopakovat neúspěšnou materializační úlohu.
Poznámka:
Získání ID úlohy neúspěšné materializace:
- Přejděte do uživatelského rozhraní úloh materializace sady funkcí .
- Vyberte zobrazovaný název konkrétní úlohy, která má stavSelhalo.
- V části Název na stránce Přehled úlohy vyhledejte ID úlohy začínající na
Featurestore-Materialization-.
az ml feature-set backfill --by-job-id <JOB_ID_OF_FAILED_MATERIALIZATION_JOB> --name <FEATURE_SET_NAME> --version <VERSION> --feature-store-name <FEATURE_STORE_NAME> --resource-group <RESOURCE_GROUP>
Aktualizace offline úložiště materializovaných dat
Pokud je nutné aktualizovat offline materializační úložiště na úrovni úložiště funkcí, všechny sady funkcí v úložišti funkcí by měly mít vypnutou offline materializaci.
Pokud je offline materializace v sadě funkcí zakázána, stav materializace dat, která jsou již materializována v úložišti offline materializace, se resetuje. Reset učiní již materializovaná data nepoužitelnými. Po povolení offline materializace musíte znovu odeslat úlohy materializace.
Vyčištění
Pátý kurz této série, Vývoj sady funkcí s vlastním zdrojem, popisuje, jak odstranit prostředky.
Další krok
Tento kurz vytvořil trénovací data s funkcemi z úložiště funkcí, povolil materializaci do offline úložiště funkcí a provedl backfill.
Další kurz série Experiment a trénování modelů pomocí funkcí vám ukáže, jak pomocí těchto funkcí spustit trénování modelu.