Nastavení Pacemakeru v Red Hat Enterprise Linuxu v Azure
Tento článek popisuje, jak nakonfigurovat základní cluster Pacemaker na Red Hat Enterprise Serveru (RHEL). Pokyny zahrnují RHEL 7, RHEL 8 a RHEL 9.
Požadavky
Nejprve si přečtěte následující poznámky a články SAP:
Dokumentace k vysoké dostupnosti RHEL (HA)
- Konfigurace a správa clusterů s vysokou dostupností
- Zásady podpory pro clustery s vysokou dostupností RHEL – sbd a fence_sbd.
- Zásady podpory pro clustery s vysokou dostupností RHEL – fence_azure_arm
- Známá omezení watchdogu emulovaného softwaru.
- Prozkoumání komponent vysoké dostupnosti RHEL – sbd a fence_sbd
- Pokyny k návrhu pro clustery s vysokou dostupností RHEL – důležité informace o sbd
- Důležité informace o přijetí RHEL 8 – vysoká dostupnost a clustery
Dokumentace ke službě RHEL specifická pro Azure
Dokumentace RHEL pro nabídky SAP
- Zásady podpory pro clustery s vysokou dostupností RHEL – správa SAP S/4HANA v clusteru
- Konfigurace SAP S/4HANA ASCS/ERS pomocí samostatného enqueue Serveru 2 (ENSA2) v Pacemakeru
- Konfigurace systémové replikace SAP HANA v clusteru Pacemaker
- Řešení vysoké dostupnosti pro Red Hat Enterprise Linux pro škálování na více systémů a replikaci SAP HANA
Přehled
Důležité
Clustery Pacemaker, které zahrnují více virtuálních sítí nebo podsítí, se nevztahují na standardní zásady podpory.
V Azure jsou k dispozici dvě možnosti konfigurace ohraničení v clusteru pacemaker pro RHEL: agent plotu Azure, který restartuje uzel, který selhal přes rozhraní API Azure, nebo můžete použít zařízení SBD.
Důležité
Cluster RHEL s vysokou dostupností v Azure s ohraničením založeným na úložišti (fence_sbd) používá software emulovaný sledovací program. Je důležité zkontrolovat známá omezení a zásady podpory pro clustery s vysokou dostupností RHEL – sbd a fence_sbd při výběru SBD jako mechanismu pro ohraničení.
Použití zařízení SBD
Poznámka:
Mechanismus šermování s SBD je podporován v RHEL 8.8 a vyšší a RHEL 9.0 a vyšší.
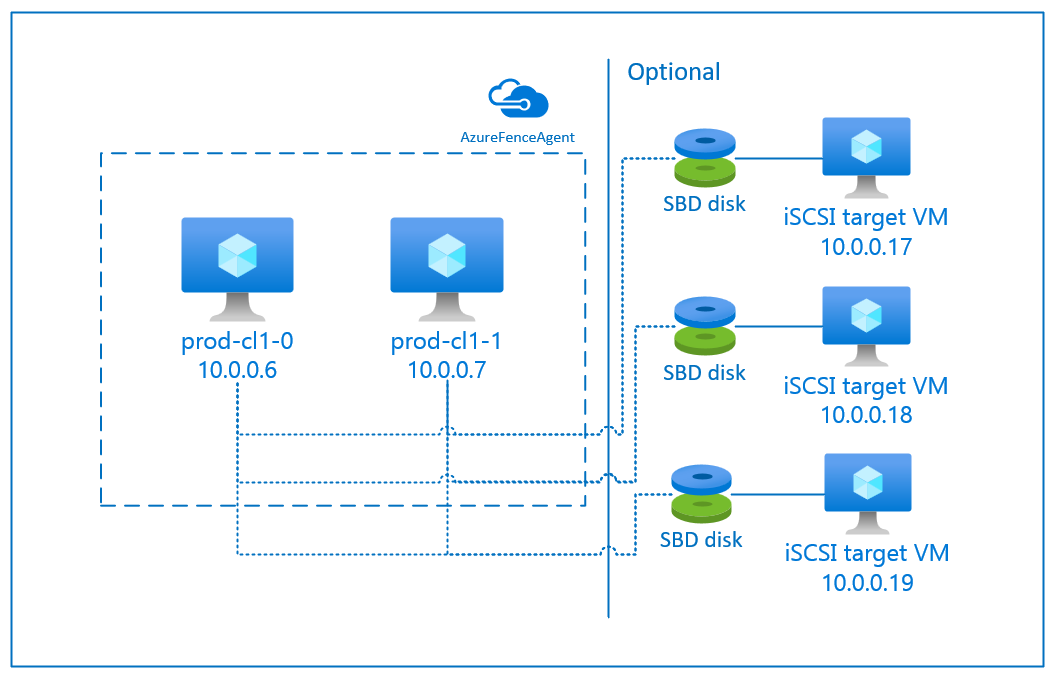
Zařízení SBD můžete nakonfigurovat pomocí jedné ze dvou možností:
SBD s cílovým serverem iSCSI
Zařízení SBD vyžaduje alespoň jeden další virtuální počítač, který funguje jako cílový server iSCSI (Internet Small Compute System Interface) a poskytuje zařízení SBD. Tyto cílové servery iSCSI se ale dají sdílet s jinými clustery pacemakeru. Výhodou použití zařízení SBD je, že pokud už používáte místní zařízení SBD, nevyžadují žádné změny způsobu, jakým pracujete s clusterem pacemaker.
Pro cluster pacemakeru můžete použít až tři zařízení SBD, která umožní, aby zařízení SBD bylo nedostupné (například během opravy operačního systému cílového serveru iSCSI). Pokud chcete použít více než jedno zařízení SBD na pacemaker, nezapomeňte nasadit více cílových serverů iSCSI a připojit jeden SBD z každého cílového serveru iSCSI. Doporučujeme použít jedno nebo tři zařízení SBD. Pacemaker nemůže automaticky ohrazovat uzel clusteru, pokud jsou nakonfigurovaná jenom dvě zařízení SBD a jedna z nich není k dispozici. Pokud chcete být schopni ohrazení, když je jeden cílový server iSCSI, musíte použít tři zařízení SBD, a proto tři cílové servery iSCSI. To je nejodolnější konfigurace při používání sbd.
Důležité
Pokud plánujete nasadit a nakonfigurovat uzly clusteru Pacemaker s Linuxem a zařízení SBD, nepovolujte směrování mezi virtuálními počítači a virtuálními počítači, které hostují zařízení SBD, aby prošla všemi dalšími zařízeními, jako je síťové virtuální zařízení (NVA).
Události údržby a další problémy se síťovým virtuálním zařízením můžou mít negativní dopad na stabilitu a spolehlivost celkové konfigurace clusteru. Další informace najdete v uživatelsky definovaných pravidlech směrování.
SBD se sdíleným diskem Azure
Pokud chcete nakonfigurovat zařízení SBD, musíte ke všem virtuálním počítačům, které jsou součástí clusteru pacemaker, připojit aspoň jeden sdílený disk Azure. Výhodou zařízení SBD, které používá sdílený disk Azure, je, že nemusíte nasazovat a konfigurovat další virtuální počítače.
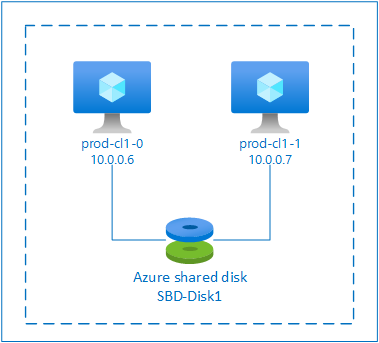
Tady je několik důležitých aspektů zařízení SBD při konfiguraci pomocí sdíleného disku Azure:
- Sdílený disk Azure s SSD úrovně Premium se podporuje jako zařízení SBD.
- Zařízení SBD, která používají sdílený disk Azure, se podporují na RHEL 8.8 a novějších verzích.
- Zařízení SBD, která používají disk sdílené složky Azure Premium, se podporují v místně redundantním úložišti (LRS) a zónově redundantním úložišti (ZRS).
- V závislosti na typu nasazení zvolte jako zařízení SBD odpovídající redundantní úložiště pro sdílený disk Azure.
- Zařízení SBD využívající LRS pro sdílený disk Azure Premium (skuName – Premium_LRS) se podporuje jenom v místním nasazení, jako je skupina dostupnosti.
- Zařízení SBD využívající ZRS pro sdílený disk Azure Premium (skuName – Premium_ZRS) se doporučuje s nasazením zón, jako je zóna dostupnosti nebo škálovací sada s FD=1.
- Zónově redundantní úložiště pro spravovaný disk je aktuálně dostupné v oblastech uvedených v dokumentu regionální dostupnosti .
- Sdílený disk Azure, který používáte pro zařízení SBD, nemusí být velký. Hodnota maxShares určuje, kolik uzlů clusteru může sdílený disk používat. Pro zařízení SBD můžete například použít velikosti disků P1 nebo P2 v clusteru se dvěma uzly, jako je SAP ASCS/ERS nebo vertikální navýšení kapacity SAP HANA.
- Pro horizontální navýšení kapacity HANA pomocí replikace systému HANA (HSR) a pacemakeru můžete použít sdílený disk Azure pro zařízení SBD v clusterech s až pěti uzly na lokalitu replikace kvůli aktuálnímu limitu maximálních sdílených složek.
- Nedoporučujeme připojovat zařízení SBD sdíleného disku Azure napříč clustery pacemakeru.
- Pokud používáte více zařízení SBD sdíleného disku Azure, zkontrolujte limit maximálního počtu datových disků, které je možné připojit k virtuálnímu počítači.
- Další informace o omezeních sdílených disků Azure najdete v dokumentaci ke sdíleným diskům Azure v části Omezení.
Použití agenta azure plotu
Ohraničení můžete nastavit pomocí agenta plotu Azure. Agent plotu Azure vyžaduje spravované identity pro virtuální počítače clusteru nebo instanční objekt nebo identitu spravovaného systému (MSI), která spravuje restartování neúspěšných uzlů prostřednictvím rozhraní API Azure. Agent plotu Azure nevyžaduje nasazení dalších virtuálních počítačů.
SBD s cílovým serverem iSCSI
Chcete-li použít zařízení SBD, které používá cílový server iSCSI pro ohraničení, postupujte podle pokynů v následujících částech.
Nastavení cílového serveru iSCSI
Nejprve musíte vytvořit cílové virtuální počítače iSCSI. Cílové servery iSCSI můžete sdílet s několika clustery pacemaker.
Nasaďte virtuální počítače, které běží na podporované verzi operačního systému RHEL, a připojte se k nim přes SSH. Virtuální počítače nemusí mít velkou velikost. Stačí velikosti virtuálních počítačů, jako jsou Standard_E2s_v3 nebo Standard_D2s_v3. Ujistěte se, že pro disk s operačním systémem používáte Premium Storage.
Pro SAP se službami HA a Update Services není nutné používat RHEL ani image RHEL pro operační systém SAP Apps pro cílový server iSCSI. Místo toho je možné použít standardní image operačního systému RHEL. Mějte ale na paměti, že životní cyklus podpory se liší mezi různými verzemi produktů operačního systému.
Na všech cílových virtuálních počítačích iSCSI spusťte následující příkazy.
Aktualizujte RHEL.
sudo yum -y updatePoznámka:
Po upgradu nebo aktualizaci operačního systému možná budete muset restartovat uzel.
Nainstalujte cílový balíček iSCSI.
sudo yum install targetcliSpusťte a nakonfigurujte cíl tak, aby se spustil při spuštění.
sudo systemctl start target sudo systemctl enable targetOtevření portu
3260v bráně firewallsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Vytvoření zařízení iSCSI na cílovém serveru iSCSI
Pokud chcete vytvořit disky iSCSI pro systémové clustery SAP, spusťte na každém cílovém virtuálním počítači iSCSI následující příkazy. Příklad znázorňuje vytvoření zařízení SBD pro několik clusterů, což demonstruje použití jednoho cílového serveru iSCSI pro více clusterů. Zařízení SBD je nakonfigurované na disku s operačním systémem, proto zajistěte, aby bylo dostatek místa.
- ascsnw1: Představuje cluster ASCS/ERS NW1.
- dbhn1: Představuje databázový cluster HN1.
- sap-cl1 a sap-cl2: Názvy hostitelů uzlů clusteru NW1 ASCS/ERS.
- hn1-db-0 a hn1-db-1: Názvy hostitelů uzlů databázového clusteru.
V následujících pokynech podle potřeby upravte příkaz s konkrétními názvy hostitelů a identifikátory SID.
Vytvořte kořenovou složku pro všechna zařízení SBD.
sudo mkdir /sbdVytvořte zařízení SBD pro servery ASCS/ERS systému NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Vytvořte zařízení SBD pro databázový cluster systému HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Uložte konfiguraci cílového seznamu.
sudo targetcli saveconfigZkontrolujte, jestli je všechno správně nastavené.
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Nastavení zařízení SBD cílového serveru iSCSI
[A]: Platí pro všechny uzly. [1]: Platí pouze pro uzel 1. [2]: Platí pouze pro uzel 2.
Na uzlech clusteru se připojte a zjistěte zařízení iSCSI vytvořené v předchozí části. Na uzlech nového clusteru, který chcete vytvořit, spusťte následující příkazy.
[A] Nainstalujte nebo aktualizujte nástroje iniciátoru iSCSI na všech uzlech clusteru.
sudo yum install -y iscsi-initiator-utils[A] Nainstalujte balíčky clusteru a SBD na všechny uzly clusteru.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Povolte službu iSCSI.
sudo systemctl enable iscsid iscsi[1] Změňte název iniciátoru na prvním uzlu clusteru.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Změňte název iniciátoru na druhém uzlu clusteru.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Restartujte službu iSCSI, aby se změny projevily.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Připojte zařízení iSCSI. V následujícím příkladu je 10.0.0.17 IP adresa cílového serveru iSCSI a 3260 je výchozí port. Cílový název
iqn.2006-04.ascsnw1.local:ascsnw1se zobrazí při spuštění prvního příkazuiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Pokud používáte více zařízení SBD, připojte se také k druhému cílovému serveru iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Pokud používáte více zařízení SBD, připojte se také k třetímu cílovému serveru iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Ujistěte se, že jsou zařízení iSCSI dostupná, a poznamenejte si název zařízení. V následujícím příkladu se zjistí tři zařízení iSCSI připojením uzlu ke třem cílovým serverům iSCSI.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Načtěte ID zařízení iSCSI.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgPříkaz zobrazí seznam tří ID zařízení pro každé zařízení SBD. Doporučujeme použít ID začínající rozhraním scsi-3. V předchozím příkladu jsou ID:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Vytvořte zařízení SBD.
Pomocí ID zařízení iSCSI vytvořte nová zařízení SBD na prvním uzlu clusteru.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createPokud chcete použít více než jedno zařízení, vytvořte také druhá a třetí zařízení SBD.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Přizpůsobení konfigurace SBD
Otevřete konfigurační soubor SBD.
sudo vi /etc/sysconfig/sbdZměňte vlastnost zařízení SBD, povolte integraci pacemakeru a změňte režim spuštění SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Spuštěním následujícího příkazu načtěte
softdogmodul.modprobe softdog[A] Spuštěním následujícího příkazu se ujistěte
softdog, že se po restartování uzlu automaticky načte.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Hodnota časového limitu služby SBD je ve výchozím nastavení nastavená na 90 s. Pokud
SBD_DELAY_STARTje však hodnota nastavena nayes, služba SBD zpozdí její spuštění až po vypršení časového limitumsgwait. Proto by hodnota časového limitu služby SBD měla překročitmsgwaitčasový limit, pokudSBD_DELAY_STARTje povolena.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
SBD se sdíleným diskem Azure
Tato část platí jenom v případě, že chcete použít zařízení SBD se sdíleným diskem Azure.
Konfigurace sdíleného disku Azure pomocí PowerShellu
Pokud chcete vytvořit a připojit sdílený disk Azure pomocí PowerShellu, spusťte následující pokyny. Pokud chcete nasadit prostředky pomocí Azure CLI nebo webu Azure Portal, můžete se také podívat na nasazení disku ZRS.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Nastavení zařízení SBD sdíleného disku Azure
[A] Nainstalujte balíčky clusteru a SBD na všechny uzly clusteru.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Ujistěte se, že je připojený disk dostupný.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Načtěte ID zařízení připojeného sdíleného disku.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaID zařízení se seznamem příkazů připojeného sdíleného disku. Doporučujeme použít ID začínající rozhraním scsi-3. V tomto příkladu je ID /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Vytvoření zařízení SBD
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Přizpůsobení konfigurace SBD
Otevřete konfigurační soubor SBD.
sudo vi /etc/sysconfig/sbdZměna vlastnosti zařízení SBD, povolení integrace pacemakeru a změna režimu spuštění SBD
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Spuštěním následujícího příkazu načtěte
softdogmodul.modprobe softdog[A] Spuštěním následujícího příkazu se ujistěte
softdog, že se po restartování uzlu automaticky načte.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Hodnota časového limitu služby SBD je ve výchozím nastavení nastavená na 90 sekund. Pokud
SBD_DELAY_STARTje však hodnota nastavena nayes, služba SBD zpozdí její spuštění až po vypršení časového limitumsgwait. Proto by hodnota časového limitu služby SBD měla překročitmsgwaitčasový limit, pokudSBD_DELAY_STARTje povolena.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Konfigurace agenta plotu Azure
Zařízení pro dělení používá spravovanou identitu pro prostředek Azure nebo instanční objekt k autorizaci v Azure. V závislosti na metodě správy identit postupujte podle příslušných postupů –
Konfigurace správy identit
Použijte spravovanou identitu nebo instanční objekt.
Pokud chcete vytvořit spravovanou identitu (MSI), vytvořte spravovanou identitu přiřazenou systémem pro každý virtuální počítač v clusteru. Pokud už spravovaná identita přiřazená systémem existuje, použije se. V tuto chvíli nepoužívejte spravované identity přiřazené uživatelem s Pacemakerem. Plotové zařízení založené na spravované identitě je podporováno na RHEL 7.9 a RHEL 8.x/RHEL 9.x.
Vytvoření vlastní role pro agenta plotu
Spravovaná identita i instanční objekt nemají ve výchozím nastavení oprávnění pro přístup k prostředkům Azure. Musíte udělit spravované identitě nebo instančnímu objektu oprávnění ke spuštění a zastavení (vypnutí) všech virtuálních počítačů clusteru. Pokud jste vlastní roli ještě nevytvořili, můžete ji vytvořit pomocí PowerShellu nebo Azure CLI.
Pro vstupní soubor použijte následující obsah. Obsah musíte přizpůsobit svým předplatným, tedy nahradit
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxayyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyyid vašeho předplatného. Pokud máte pouze jedno předplatné, odeberte druhou položku vAssignableScopessouboru .{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Přiřazení vlastní role
Použijte spravovanou identitu nebo instanční objekt.
Přiřaďte vlastní roli
Linux Fence Agent Rolevytvořenou v poslední části ke každé spravované identitě virtuálních počítačů clusteru. Každá spravovaná identita přiřazená systémem virtuálního počítače potřebuje přiřazenou roli pro každý prostředek virtuálního počítače clusteru. Další informace najdete v tématu Přiřazení přístupu ke spravované identitě k prostředku pomocí webu Azure Portal. Ověřte, že přiřazení role spravované identity každého virtuálního počítače obsahuje všechny virtuální počítače clusteru.Důležité
Mějte na paměti, že přiřazení a odebrání autorizace u spravovaných identit může být zpožděné až do účinnosti.
Instalace clusteru
Rozdíly v příkazech nebo konfiguraci mezi RHEL 7 a RHEL 8/RHEL 9 jsou v dokumentu označené.
[A] Nainstalujte doplněk RHEL HA.
sudo yum install -y pcs pacemaker nmap-ncat[A] V RHEL 9.x nainstalujte agenty prostředků pro cloudové nasazení.
sudo yum install -y resource-agents-cloud[A] Nainstalujte balíček plot-agents, pokud používáte zařízení pro ohraničení založené na agentovi plotu Azure.
sudo yum install -y fence-agents-azure-armDůležité
Zákazníkům, kteří chtějí používat spravované identity pro prostředky Azure místo instančních názvů pro agenta plotu, doporučujeme následující verze agenta plotu (nebo novější):
- RHEL 8.4: plot-agent-4.2.1-54.el8.
- RHEL 8.2: plot-agent-4.2.1-41.el8_2.4
- RHEL 8.1: plot-agent-4.2.1-30.el8_1.4
- RHEL 7.9: plot-agent-4.2.1-41.el7_9.4.
Důležité
V RHEL 9 doporučujeme následující verze balíčků (nebo novější), abyste se vyhnuli problémům s agentem plotu Azure:
- plot-agents-4.10.0-20.el9_0.7
- plot-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Zkontrolujte verzi agenta plotu Azure. V případě potřeby ho aktualizujte na minimální požadovanou verzi nebo novější.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armDůležité
Pokud potřebujete aktualizovat agenta plotu Azure a pokud používáte vlastní roli, nezapomeňte aktualizovat vlastní roli tak, aby zahrnovala powerOff akce. Další informace najdete v tématu Vytvoření vlastní role pro plot agenta.
[A] Nastavte překlad názvů hostitelů.
Můžete použít server DNS nebo upravit
/etc/hostssoubor na všech uzlech. Tento příklad ukazuje, jak soubor používat/etc/hosts. V následujících příkazech nahraďte IP adresu a název hostitele.Důležité
Pokud v konfiguraci clusteru používáte názvy hostitelů, je důležité mít spolehlivé překlad názvů hostitelů. Komunikace clusteru selže, pokud nejsou dostupné názvy, což může vést ke zpoždění převzetí služeb při selhání clusteru.
Výhodou použití
/etc/hostsje, že váš cluster je nezávislý na DNS, což může být také kritickým bodem selhání.sudo vi /etc/hostsVložte následující řádky do
/etc/hosts. Změňte IP adresu a název hostitele tak, aby odpovídaly vašemu prostředí.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Změňte
haclusterheslo na stejné heslo.sudo passwd hacluster[A] Přidejte pravidla brány firewall pro Pacemaker.
Přidejte následující pravidla brány firewall do veškeré komunikace clusteru mezi uzly clusteru.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Povolte základní služby clusteru.
Spuštěním následujících příkazů povolte službu Pacemaker a spusťte ji.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Vytvořte cluster Pacemaker.
Spuštěním následujících příkazů ověřte uzly a vytvořte cluster. Nastavte token na 30000, aby se povolila údržba zachování paměti. Další informace najdete v tomto článku pro Linux.
Pokud vytváříte cluster na RHEL 7.x, použijte následující příkazy:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allPokud vytváříte cluster na RHEL 8.x/RHEL 9.x, použijte následující příkazy:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allStav clusteru ověřte spuštěním následujícího příkazu:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Nastavte očekávané hlasy.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Tip
Pokud vytváříte cluster s více uzly, tj. cluster s více než dvěma uzly, nenastavujte hlasy na 2.
[1] Povolit souběžné akce plotu.
sudo pcs property set concurrent-fencing=true
Vytvoření zařízení pro ohraničení v clusteru Pacemaker
Tip
- Abyste se vyhnuli plotovým závodům v clusteru pacemakeru se dvěma uzly, můžete nakonfigurovat vlastnost clusteru
priority-fencing-delay. Tato vlastnost představuje další zpoždění při ohraničení uzlu, který má vyšší celkovou prioritu zdroje, když dojde ke scénáři rozděleného mozku. Další informace najdete v tématu Může Pacemaker ohražovat uzel clusteru s nejmenšími spuštěnými prostředky?. - Vlastnost
priority-fencing-delayse vztahuje na Pacemaker verze 2.0.4-6.el8 nebo vyšší a v clusteru se dvěma uzly. Pokud nakonfigurujete vlastnost clusterupriority-fencing-delay, nemusíte tuto vlastnost nastavovatpcmk_delay_max. Pokud je ale verze Pacemaker menší než 2.0.4-6.el8, musíte vlastnost nastavitpcmk_delay_max. - Pokyny k nastavení vlastnosti clusteru
priority-fencing-delaynajdete v příslušných dokumentech SAP ASCS/ERS a SAP HANA pro vertikální navýšení kapacity.
Na základě vybraného mechanismu šermování postupujte pouze v jedné části pro příslušné pokyny: SBD jako zařízení pro plot nebo agenta plotu Azure jako zařízení pro ploty.
SBD jako zařízení pro šermování
[A] Povolení služby SBD
sudo systemctl enable sbd[1] Pro zařízení SBD nakonfigurované pomocí cílových serverů iSCSI nebo sdíleného disku Azure spusťte následující příkazy.
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Restartujte cluster.
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allPoznámka:
Pokud při spuštění clusteru pacemaker dojde k následující chybě, můžete zprávu ignorovat. Případně můžete cluster spustit pomocí příkazu
pcs cluster start --all --request-timeout 140.Chyba: Nejde spustit všechny uzly node1/node2: Nejde se připojit k uzlu1/node2, zkontrolujte, jestli je v počítači spuštěný počítač, nebo zkuste nastavit vyšší časový limit s
--request-timeoutmožností (Vypršel časový limit operace po 60000 milisekundách s přijatými 0 bajty).
Agent plotu Azure jako zařízení pro ohraničení
[1] Po přiřazení rolí k oběma uzlům clusteru můžete nakonfigurovat zařízení pro ohraničení v clusteru.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] V závislosti na tom, jestli používáte spravovanou identitu nebo instanční objekt pro agenta plotu Azure, spusťte příslušný příkaz.
Poznámka:
Při použití cloudu Azure Government musíte při konfiguraci plot agenta zadat
cloud=možnost. Napříkladcloud=usgovpro cloud Azure PRO státní správu USA. Podrobnosti o podpoře RedHat v cloudu Azure Government najdete v tématu Zásady podpory pro clustery s vysokou dostupností RHEL – Microsoft Azure Virtual Machines jako členové clusteru.Tip
Tato možnost
pcmk_host_mapse vyžaduje jenom v případě, že názvy hostitelů RHEL a názvy virtuálních počítačů Azure nejsou identické. Zadejte mapování ve formátu název hostitele:vm-name. Další informace najdete v tématu Jaký formát mám použít k určení mapování uzlů na zařízení s ohraničením v pcmk_host_map?.Pro RHEL 7.x pomocí následujícího příkazu nakonfigurujte plotové zařízení:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600Pro RHEL 8.x/9.x pomocí následujícího příkazu nakonfigurujte plotové zařízení:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
Pokud používáte zařízení pro ohraničení založené na konfiguraci instančního objektu, přečtěte si informace o změně hlavního názvu služby (SPN) na clustery MSI pro clustery Pacemaker pomocí fencingu Azure a zjistěte, jak převést na konfiguraci spravované identity.
Operace monitorování a šermování jsou deserializovány. V důsledku toho platí, že pokud je spuštěná operace monitorování a souběžná událost ohraničení, nedojde ke zpoždění převzetí služeb při selhání clusteru, protože operace monitorování je již spuštěná.
Tip
Agent plotu Azure vyžaduje odchozí připojení k veřejným koncovým bodům. Další informace spolu s možnými řešeními najdete v tématu Připojení veřejného koncového bodu pro virtuální počítače pomocí standardního nástroje pro vyrovnávání zatížení.
Konfigurace Pacemakeru pro naplánované události Azure
Azure nabízí naplánované události. Naplánované události se odesílají prostřednictvím služby metadat a umožňují aplikaci připravit se na tyto události.
Agent azure-events-az prostředků Pacemaker monitoruje naplánované události Azure. Pokud se zjistí události a agent prostředků určí, že je k dispozici jiný uzel clusteru, nastaví atribut stavu clusteru.
Pokud je atribut stavu clusteru nastavený pro uzel, omezení umístění aktivuje a všechny prostředky s názvy, které nezačínají health- , se migrují mimo uzel s naplánovanou událostí. Jakmile je ovlivněný uzel clusteru bez spuštěných prostředků clusteru, je naplánovaná událost potvrzena a může provést její akci, jako je restartování.
[A] Ujistěte se, že je balíček pro
azure-events-azagenta již nainstalovaný a aktuální.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudMinimální požadavky na verzi:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 a novější:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Nakonfigurujte prostředky v Pacemakeru.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Nastavte strategii stavu clusteru Pacemaker a omezení.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Důležité
Nedefinujte žádné další prostředky v clusteru počínaje
health-prostředky popsanými v dalších krocích.[1] Nastavte počáteční hodnotu atributů clusteru. Spusťte pro každý uzel clusteru a pro prostředí se škálováním na více instancí, včetně virtuálního počítače tvůrce většiny.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Nakonfigurujte prostředky v Pacemakeru. Ujistěte se, že zdroje začínají
health-azurena .sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true failure-timeout=120sVyužít cluster Pacemaker z režimu údržby.
sudo pcs property set maintenance-mode=falseVymažte všechny chyby během povolování a ověřte, že
health-azure-eventsse prostředky úspěšně spustily na všech uzlech clusteru.sudo pcs resource cleanupPrvní spuštění dotazu pro naplánované události může trvat až dvě minuty. Testování Pacemakeru s plánovanými událostmi může pro virtuální počítače clusteru používat akce restartování nebo opětovného nasazení. Další informace naleznete v tématu Naplánované události.
Volitelná konfigurace ohraničení
Tip
Tato část je použitelná pouze v případě, že chcete nakonfigurovat speciální šermovací zařízení fence_kdump.
Pokud potřebujete shromáždit diagnostické informace v rámci virtuálního počítače, může být užitečné nakonfigurovat jiné zařízení pro šermování na základě plotového agenta fence_kdump. Agent fence_kdump může zjistit, že uzel zadal zotavení po havárii kdump a může službě pro zotavení po havárii umožnit dokončení před vyvolání jiných metod dělení. Všimněte si, že fence_kdump při používání virtuálních počítačů Azure se nejedná o náhradu tradičních mechanismů plotu, jako je SBD nebo agent plotu Azure.
Důležité
Mějte na paměti, že pokud fence_kdump je nakonfigurované jako zařízení pro vyrovnávání na první úrovni, představuje zpoždění v operacích ohraničení a zpoždění při převzetí služeb při selhání prostředků aplikace.
Pokud dojde k úspěšnému zjištění výpisu stavu systému, oznamování se zpozdí, dokud se služba zotavení po havárii neskončí. Pokud je uzel, který selhal, nedostupný nebo pokud nereaguje, je ohraničení zpožděno podle času určeného časem, nakonfigurovaného počtu iterací a časového limitu fence_kdump . Další informace najdete v tématu Návody konfigurace fence_kdump v clusteru Red Hat Pacemaker?.
Navrhovaný fence_kdump časový limit může být potřeba přizpůsobit konkrétnímu prostředí.
Doporučujeme nakonfigurovat fence_kdump ohraničení pouze v případě, že je to potřeba ke shromažďování diagnostiky na virtuálním počítači a vždy v kombinaci s tradičními metodami plotu, jako je SBD nebo agent plot Azure.
Následující články znalostní báze Red Hat obsahují důležité informace o konfiguraci fence_kdump šermování:
- Viz Návody konfigurace fence_kdump v clusteru Red Hat Pacemaker?.
- Podívejte se, jak nakonfigurovat nebo spravovat úrovně fencingu v clusteru RHEL pomocí Pacemakeru.
- Viz fence_kdump selže s časovým limitem po X sekundách v clusteru RHEL 6 nebo 7 HA s nástroji kexec-tools staršími než 2.0.14.
- Informace o tom, jak změnit výchozí časový limit, najdete v tématu Návody konfigurace kdump pro použití s doplňkem RHEL 6, 7, 8 HA?.
- Informace o tom, jak snížit zpoždění převzetí služeb při selhání při použití
fence_kdump, najdete v tématu Můžu snížit očekávané zpoždění převzetí služeb při selhání při přidávání fence_kdump konfigurace?.
Spuštěním následujících volitelných kroků přidejte fence_kdump kromě konfigurace agenta plotu Azure konfiguraci jako první úroveň.
[A] Ověřte, zda
kdumpje aktivní a nakonfigurovaná.systemctl is-active kdump # Expected result # active[A] Nainstalujte agenta plotu
fence_kdump.yum install fence-agents-kdump[1] Vytvořte
fence_kdumpv clusteru zařízení pro ohraničení.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Nakonfigurujte úrovně šermování tak, aby se nejprve zapojil mechanismus šermingu
fence_kdump.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Povolte požadované porty pro
fence_kdumpprůchod bránou firewall.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Proveďte konfiguraci
/etc/kdump.conf,fence_kdump_nodesabyste se vyhnulifence_kdumpselhání s vypršením časového limitu pro některékexec-toolsverze. Další informace najdete v tématu fence_kdump vypršení časového limitu v případě, že fence_kdump_nodes není zadaný pomocí nástrojů kexec-tools verze 2.0.15 nebo novější a fence_kdump selže s časovým limitem po X sekundách v clusteru RHEL 6 nebo 7 s vysokou dostupností s verzemi kexec-tools staršími než 2.0.14. Tady je uvedena příklad konfigurace clusteru se dvěma uzly. Po provedení změny musí/etc/kdump.confbýt image kdump znovu vygenerována. Pokud chcete službu znovu vygenerovat, restartujtekdumpji.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Ujistěte se, že soubor obrázku
initramfsobsahujefence_kdumpsoubory ahostssoubory. Další informace najdete v tématu Návody konfigurace fence_kdump v clusteru Red Hat Pacemaker?.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendOtestujte konfiguraci chybovým ukončením uzlu. Další informace najdete v tématu Návody konfigurace fence_kdump v clusteru Red Hat Pacemaker?.
Důležité
Pokud je cluster již produktivní, naplánujte test odpovídajícím způsobem, protože selhání uzlu má vliv na aplikaci.
echo c > /proc/sysrq-trigger
Další kroky
- Viz plánování a implementace virtuálních počítačů Azure pro SAP.
- Viz nasazení virtuálních počítačů Azure pro SAP.
- Viz nasazení DBMS služby Azure Virtual Machines pro SAP.
- Informace o vytvoření vysoké dostupnosti a plánování zotavení po havárii SAP HANA na virtuálních počítačích Azure najdete v tématu Vysoká dostupnost SAP HANA ve službě Azure Virtual Machines.