Indexování dat z knihoven dokumentů SharePointu
Důležité
Podpora indexeru SharePointu Online je ve verzi Public Preview. Nabízí se "tak, jak je", v rámci doplňkových podmínek použití a podporována pouze v rámci maximálního úsilí. Funkce ve verzi Preview se nedoporučují pro produkční úlohy a nejsou zaručené, že budou obecně dostupné.
Než začnete, nezapomeňte navštívit oddíl známých omezení .
Pokud chcete tento náhled použít, vyplňte tento formulář. Nebudete dostávat žádné oznámení o schválení hned po odeslání, protože po odeslání se automaticky přijme jakákoli žádost o přístup. Po povolení přístupu použijte k indexování obsahu rozhraní REST API verze Preview.
Tento článek vysvětluje, jak nakonfigurovat indexer vyhledávání pro indexování dokumentů uložených v knihovnách dokumentů SharePointu pro fulltextové vyhledávání ve službě Azure AI Search. Nejprve jsou kroky konfigurace následované chováním a scénáři.
Funkce
Indexer ve službě Azure AI Search je prohledávací modul, který extrahuje prohledávatelná data a metadata ze zdroje dat. Indexer SharePointu Online se připojí k vašemu webu SharePointu a indexuje dokumenty z jedné nebo více knihoven dokumentů. Indexer poskytuje následující funkce:
- Indexování souborů a metadat z jedné nebo více knihoven dokumentů
- Indexujte postupně a zachytáte pouze nové a změněné soubory a metadata.
- Detekce odstranění je integrovaná. Odstranění v knihovně dokumentů se vyzvedne při dalším spuštění indexeru a dokument se odebere z indexu.
- Text a normalizované obrázky se ve výchozím nastavení extrahují z indexovaných dokumentů. Volitelně můžete přidat sadu dovedností pro hlubší rozšiřování umělé inteligence, jako je OCR nebo překlad textu.
Požadavky
Soubory v knihovně dokumentů
Podporované formáty dokumentů
Indexer SharePointu Online může extrahovat text z následujících formátů dokumentu:
- CSV (viz indexování objektů blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (viz indexování objektů blob JSON)
- KML (XML pro geografické reprezentace)
- formáty systém Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPTM, MSG (e-maily Outlooku), XML (2003 i 2006 WORD XML)
- Formáty otevřených dokumentů: ODT, ODS, ODP
- Soubory ve formátu prostého textu (viz také indexování prostého textu)
- RTF
- XML
- ZIP
Omezení a důležité informace
Tady jsou omezení této funkce:
Indexování seznamů SharePointu se nepodporuje.
Indexování sharepointu . Obsah webu ASPX není podporovaný.
Soubory poznámkového bloku OneNotu nejsou podporované.
Privátní koncový bod není podporovaný.
Přejmenování složky SharePointu neaktivuje přírůstkové indexování. Přejmenovaná složka se považuje za nový obsah.
SharePoint podporuje podrobný model autorizace, který určuje přístup pro jednotlivé uživatele na úrovni dokumentu. Indexer tato oprávnění do indexu nepřetáhne a Azure AI Search nepodporuje autorizaci na úrovni dokumentu. Když je dokument indexován ze SharePointu do vyhledávací služby, je obsah dostupný komukoli, kdo má k indexu přístup pro čtení. Pokud potřebujete oprávnění na úrovni dokumentu, měli byste zvážit filtry zabezpečení, abyste ořízli výsledky a automatizovali kopírování oprávnění na úrovni souboru do pole v indexu.
Indexování souborů zašifrovaných uživatelem, souborů chráněných technologií IRM (Správa přístupových práv k informacím), souborů ZIP s hesly nebo podobným šifrovaným obsahem se nepodporuje. Aby bylo možné zašifrovaný obsah zpracovat, musí uživatel se správnými oprávněními ke konkrétnímu souboru odebrat šifrování, aby bylo možné položku odpovídajícím způsobem indexovat, když indexer spustí další naplánovanou iteraci.
Indexování podřízených webů rekurzivně z konkrétního webu není podporováno.
Indexer SharePointu Online není podporovaný, pokud je povolený podmíněný přístup Microsoft ENTRA ID.
Při používání této funkce je potřeba vzít v úvahu tyto aspekty:
Pokud potřebujete vytvořit vlastní aplikaci Copilot / RAG (Načítání rozšířené generace) pro chatování s daty SharePointu, doporučujeme místo této funkce Preview používat Microsoft Copilot Studio .
Pokud potřebujete řešení indexování obsahu SharePointu v produkčním prostředí, zvažte vytvoření vlastního konektoru se sharepointovými webhooky, volání rozhraní Microsoft Graph API k exportu dat do kontejneru objektů blob Azure a následné použití indexeru objektů blob Azure pro přírůstkové indexování.
- Pokud vaše konfigurace SharePointu umožňuje procesům Microsoftu 365 aktualizovat metadata systému souborů SharePointu, mějte na paměti, že tyto aktualizace můžou aktivovat indexer SharePointu Online, což způsobí, že indexer několikrát ingestuje dokumenty. Protože indexer SharePointu Online je konektor třetí strany do Azure, indexer nemůže přečíst konfiguraci nebo měnit jeho chování. Reaguje na změny v novém a změněném obsahu bez ohledu na to, jak se tyto aktualizace provádějí. Z tohoto důvodu se ujistěte, že testujete nastavení a rozumíte počtu zpracování dokumentů před použitím indexeru a veškerého rozšiřování AI.
Konfigurace indexeru SharePointu Online
K nastavení indexeru SharePointu Online použijte azure Portal i rozhraní REST API verze Preview. Můžete použít verzi 2020-06-30-preview nebo novější. Doporučujeme nejnovější rozhraní API ve verzi Preview.
Tato část obsahuje kroky. Můžete se také podívat na následující video.
Krok 1 (volitelné): Povolení spravované identity přiřazené systémem
Povolte spravovanou identitu přiřazenou systémem, aby automaticky detekovala tenanta, ve které je vyhledávací služba zřízená.
Tento krok proveďte, pokud je sharepointový web ve stejném tenantovi jako vyhledávací služba. Tento krok přeskočte, pokud je sharepointový web v jiném tenantovi. Identita se nepoužívá k indexování, pouze k detekci tenanta. Tento krok můžete také přeskočit, pokud chcete do připojovací řetězec vložit ID tenanta.
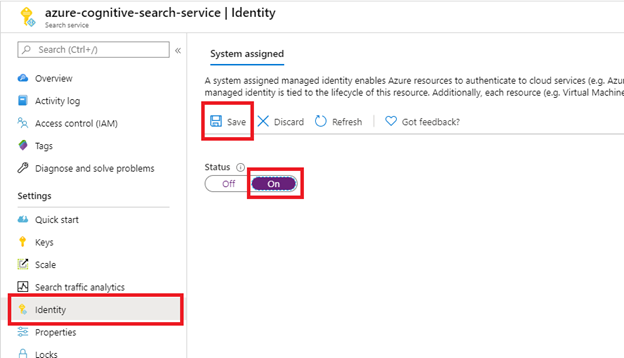
Po výběru možnosti Uložit získáte ID objektu, které bylo přiřazeno k vaší vyhledávací službě.
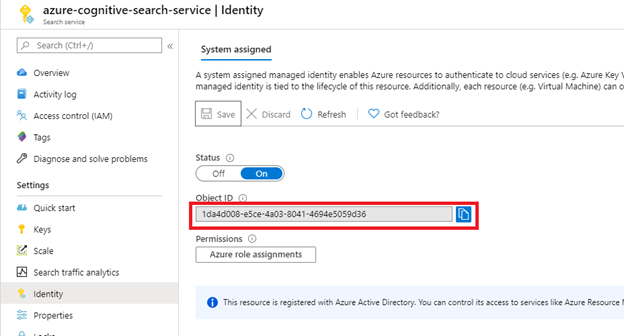
Krok 2: Rozhodnutí, která oprávnění indexer vyžaduje
Indexer SharePointu Online podporuje delegovaná i aplikační oprávnění. Zvolte oprávnění, která chcete použít v závislosti na vašem scénáři.
Doporučujeme oprávnění založená na aplikacích. Podívejte se na omezení známých problémů souvisejících s delegovanými oprávněními.
Oprávnění aplikace (doporučeno), kde indexer běží pod identitou tenanta SharePointu s přístupem ke všem webům a souborům. Indexer vyžaduje tajný klíč klienta. Indexer bude také vyžadovat schválení správce tenanta, aby mohl indexovat jakýkoli obsah.
Delegovaná oprávnění, kde indexer běží pod identitou uživatele nebo aplikace, která žádost odesílá. Přístup k datům je omezený na weby a soubory, ke kterým má volající přístup. Aby indexer podporoval delegovaná oprávnění, vyžaduje , aby se kód zařízení přihlásil jménem uživatele. Uživatelsky delegovaná oprávnění vynucují vypršení platnosti tokenů každých 75 minut podle nejnovějších knihoven zabezpečení používaných k implementaci tohoto typu ověřování. Nejedná se o chování, které lze upravit. Token s vypršenou platností vyžaduje ruční indexování pomocí run Indexeru (Preview). Z tohoto důvodu můžete místo toho chtít oprávnění založená na aplikacích.
Krok 3: Vytvoření registrace aplikace Microsoft Entra
Indexer SharePointu Online používá k ověřování tuto aplikaci Microsoft Entra.
Přihlaste se k portálu Azure.
Vyhledejte nebo přejděte na Microsoft Entra ID a pak vyberte Registrace aplikací.
Vyberte + Nová registrace:
- Zadejte název aplikace.
- Vyberte jednoho tenanta.
- Přeskočte krok označení identifikátoru URI. Není vyžadován identifikátor URI přesměrování.
- Vyberte Zaregistrovat.
Na levé straně vyberte oprávnění rozhraní API a pak přidejte oprávnění a pak Microsoft Graph.
Pokud indexer používá oprávnění rozhraní API aplikace, vyberte Oprávnění aplikace a přidejte následující:
- Aplikace – Files.Read.All
- Aplikace – Sites.Read.All

Použití oprávnění aplikace znamená, že indexer přistupuje k sharepointovém webu v kontextu služby. Když tedy spustíte indexer, bude mít přístup ke všemu obsahu v tenantovi SharePointu, který vyžaduje schválení správce tenanta. Pro ověřování se vyžaduje také tajný klíč klienta. Nastavení tajného klíče klienta je popsáno dále v tomto článku.
Pokud indexer používá delegovaná oprávnění rozhraní API, vyberte Delegovaná oprávnění a přidejte následující:
- Delegovaná – Files.Read.All
- Delegováno – Sites.Read.All
- Delegovaná – User.Read
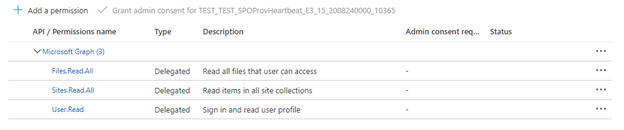
Delegovaná oprávnění umožňují vyhledávacímu klientovi připojit se k SharePointu pod identitou zabezpečení aktuálního uživatele.
Udělení souhlasu správce
Souhlas správce tenanta se vyžaduje při použití oprávnění rozhraní API aplikace. Někteří tenanti jsou uzamčeni takovým způsobem, že pro delegovaná oprávnění rozhraní API se vyžaduje souhlas správce tenanta. Pokud platí některé z těchto podmínek, budete muset před vytvořením indexeru udělit souhlas správce tenanta pro tuto aplikaci Microsoft Entra.
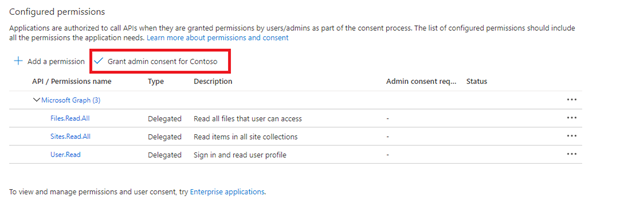
Vyberte kartu Ověřování.
Nastavte Povolit toky veřejného klienta na Ano a pak vyberte Uložit.
Vyberte + Přidat platformu, pak Mobilní a desktopové aplikace a pak zaškrtněte políčko
https://login.microsoftonline.com/common/oauth2/nativeclientKonfigurovat.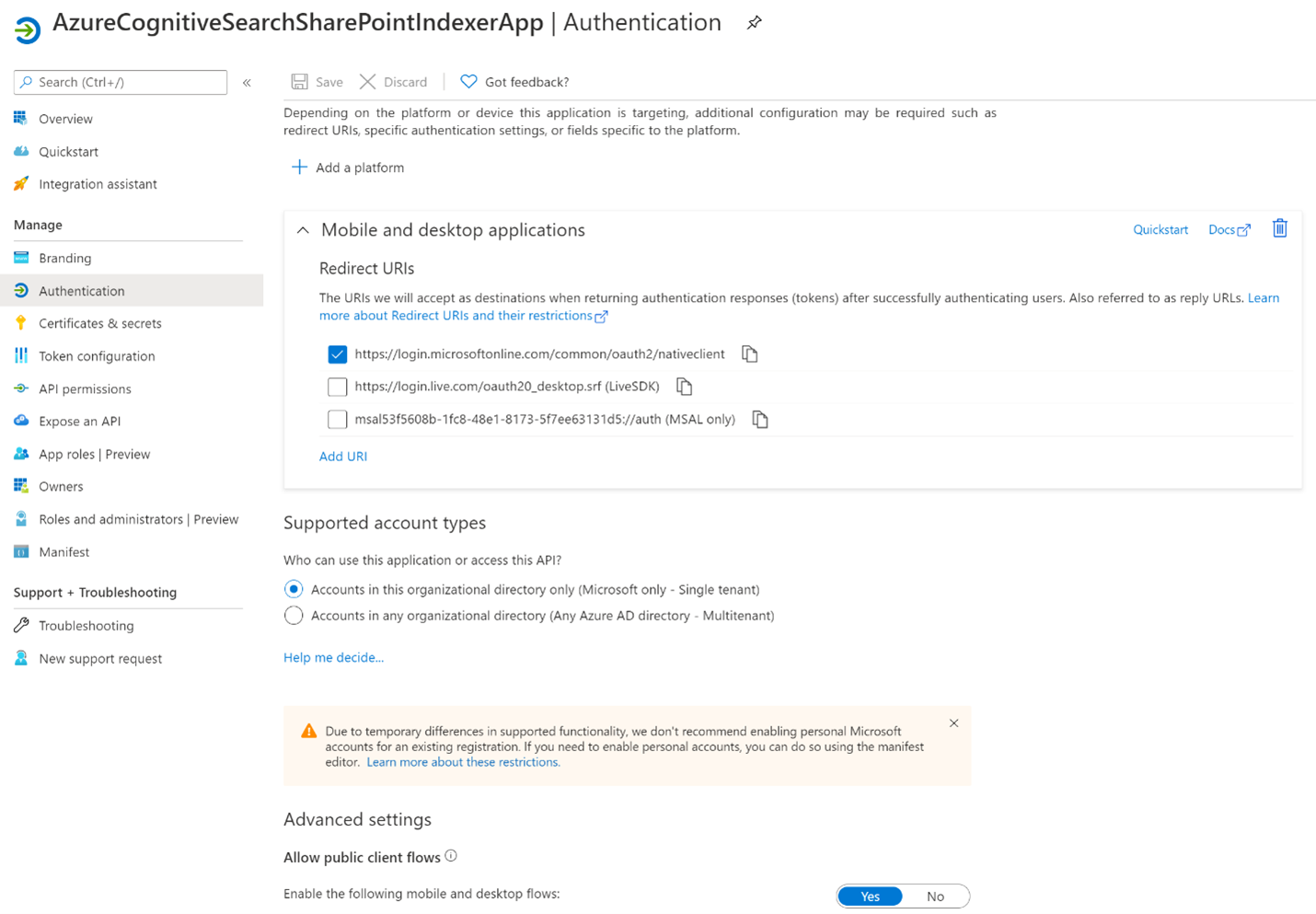
(Pouze oprávnění rozhraní API aplikace) K ověření v aplikaci Microsoft Entra pomocí oprávnění aplikace vyžaduje indexer tajný klíč klienta.
V nabídce vlevo vyberte Certifikáty a tajné kódy a pak Tajné kódy klienta a pak Nový tajný klíč klienta.

V místní nabídce zadejte popis nového tajného klíče klienta. V případě potřeby upravte datum vypršení platnosti. Pokud vyprší platnost tajného kódu, je potřeba ho znovu vytvořit a indexer se musí aktualizovat novým tajným kódem.
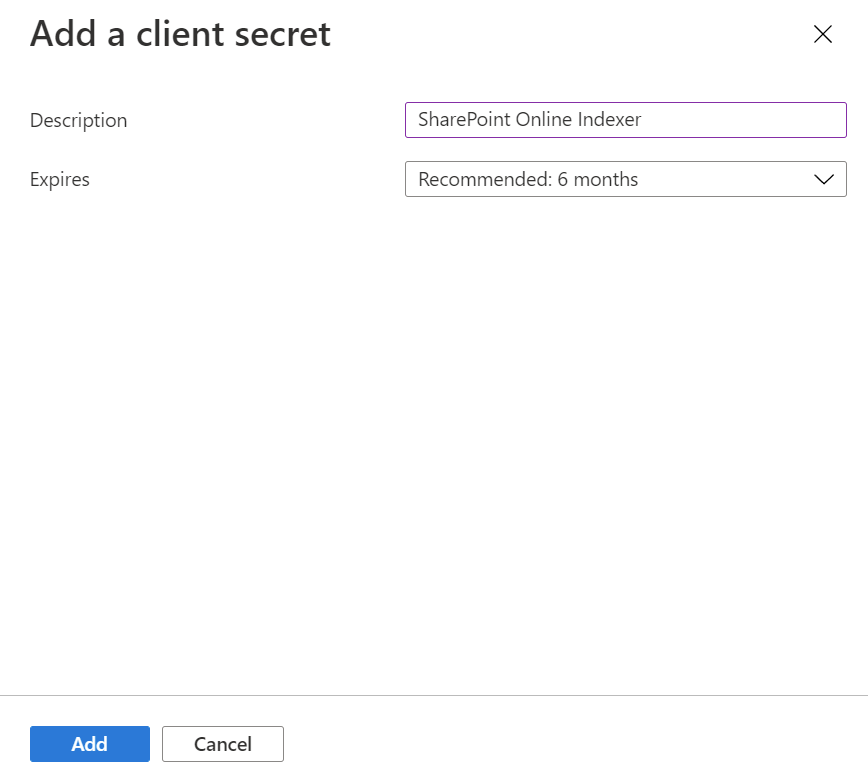
Nový tajný klíč klienta se zobrazí v seznamu tajných kódů. Jakmile přejdete mimo stránku, tajný kód už nebude viditelný, proto ho zkopírujte pomocí tlačítka pro kopírování a uložte ho do zabezpečeného umístění.

Krok 4: Vytvoření zdroje dat
Počínaje touto částí použijte pro zbývající kroky rozhraní REST API ve verzi Preview. Doporučujeme nejnovější rozhraní API ve verzi Preview.
Zdroj dat určuje, která data se mají indexovat, přihlašovací údaje a zásady pro efektivní identifikaci změn v datech (nové, změněné nebo odstraněné řádky). Zdroj dat může používat více indexerů ve stejné vyhledávací službě.
Pro indexování SharePointu musí zdroj dat obsahovat následující požadované vlastnosti:
- name je jedinečný název zdroje dat ve vaší vyhledávací službě.
- typ musí být "sharepoint". U této hodnoty se rozlišují malá a velká písmena.
- přihlašovací údaje poskytují koncový bod SharePointu a ID aplikace Microsoft Entra (klienta). Příkladem koncového bodu SharePointu je
https://microsoft.sharepoint.com/teams/MySharePointSite. Koncový bod můžete získat tak, že přejdete na domovskou stránku sharepointového webu a zkopírujete adresu URL z prohlížeče. - kontejner určuje, která knihovna dokumentů se má indexovat. Vlastnosti určují, které dokumenty jsou indexovány.
Pokud chcete vytvořit zdroj dat, zavolejte vytvořit zdroj dat (Preview).
POST https://[service name].search.windows.net/datasources?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Formát připojovacího řetězce
Formát připojovací řetězec se mění podle toho, jestli indexer používá delegovaná oprávnění rozhraní API nebo oprávnění rozhraní API aplikace.
Delegovaná oprávnění rozhraní API připojovací řetězec formátu
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Formát oprávnění rozhraní API aplikace připojovací řetězec
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Poznámka:
Pokud je sharepointový web ve stejném tenantovi jako vyhledávací služba a spravovaná identita přiřazená systémem, TenantId nemusí být zahrnuta do připojovací řetězec. Pokud je sharepointový web v jiném tenantovi než vyhledávací služba, TenantId musí být zahrnutý.
Krok 5: Vytvoření indexu
Index určuje pole v dokumentu, atributech a dalších konstruktorech, které tvarují vyhledávací prostředí.
Pokud chcete vytvořit index, zavolejte vytvořit index (Preview):<
POST https://[service name].search.windows.net/indexes?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Důležité
Jako pole klíče v indexu naplněném indexem SharePointu Online je možné použít pouze metadata_spo_site_library_item_id pole klíče. Pokud pole klíče ve zdroji dat neexistuje, metadata_spo_site_library_item_id automaticky se mapuje na pole klíče.
Krok 6: Vytvoření indexeru
Indexer propojuje zdroj dat s cílovým vyhledávacím indexem a poskytuje plán pro automatizaci aktualizace dat. Po vytvoření indexu a zdroje dat můžete indexer vytvořit.
Pokud používáte delegovaná oprávnění, během tohoto kroku se zobrazí výzva k přihlášení pomocí přihlašovacích údajů organizace, které mají přístup k webu Služby SharePoint. Pokud je to možné, doporučujeme vytvořit nový uživatelský účet organizace a dát novému uživateli přesná oprávnění, která má indexer mít.
Vytvoření indexeru je několik kroků:
Odeslání žádosti o vytvoření indexeru (Preview):
POST https://[service name].search.windows.net/indexers?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Pokud používáte oprávnění aplikace, je nutné počkat, až se počáteční spuštění dokončí, než začnete dotazovat index. Následující pokyny uvedené v tomto kroku se týkají konkrétně delegovaných oprávnění a nevztahují se na oprávnění aplikace.
Když indexer poprvé vytvoříte, požadavek Create Indexer (Preview) počká, až dokončíte další krok. Pokud chcete získat odkaz, musíte zavolat Get Indexer Status a zadat nový kód zařízení.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Pokud stav Získání indexeru nespustíte do 10 minut, platnost kódu vyprší a budete muset zdroj dat vytvořit znovu.
Zkopírujte přihlašovací kód zařízení z odpovědi Načíst stav indexeru. Přihlášení zařízení najdete v chybové zprávě.
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Zadejte kód, který byl součástí chybové zprávy.
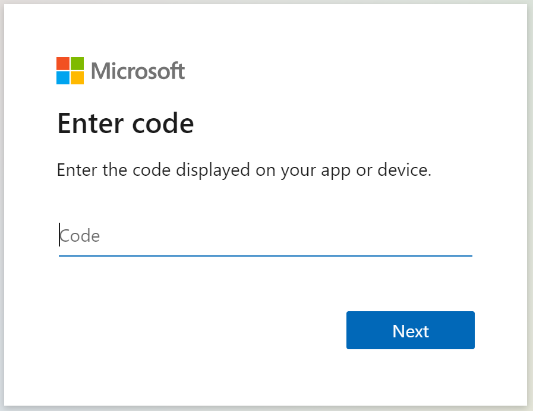
Indexer SharePointu Online bude přistupovat k obsahu SharePointu jako přihlášený uživatel. Uživatel, který se přihlásí během tohoto kroku, bude přihlášený uživatel. Pokud se tedy přihlásíte pomocí uživatelského účtu, který nemá přístup k dokumentu v knihovně dokumentů, kterou chcete indexovat, nebude mít indexer k mu přístup.
Pokud je to možné, doporučujeme vytvořit nový uživatelský účet a dát novému uživateli přesná oprávnění, která má indexer mít.
Schvalte požadovaná oprávnění.
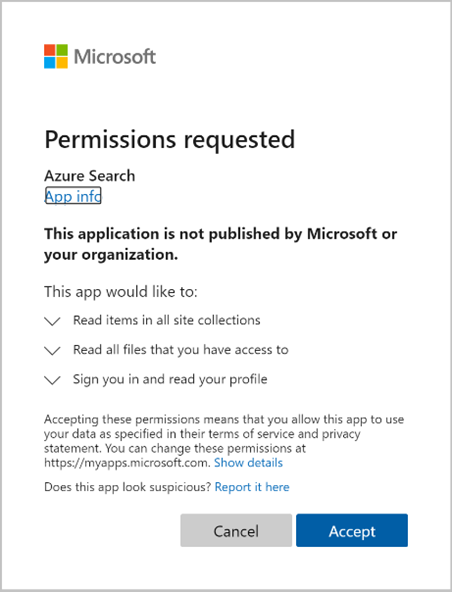
Počáteční požadavek Create Indexer (Preview) se dokončí, pokud jsou všechna výše uvedená oprávnění správná a do 10minutového časového rámce.
Poznámka:
Pokud aplikace Microsoft Entra vyžaduje schválení správcem a nebyla schválena před přihlášením, může se zobrazit následující obrazovka. Aby bylo potřeba pokračovat, je vyžadováno schválení správcem.
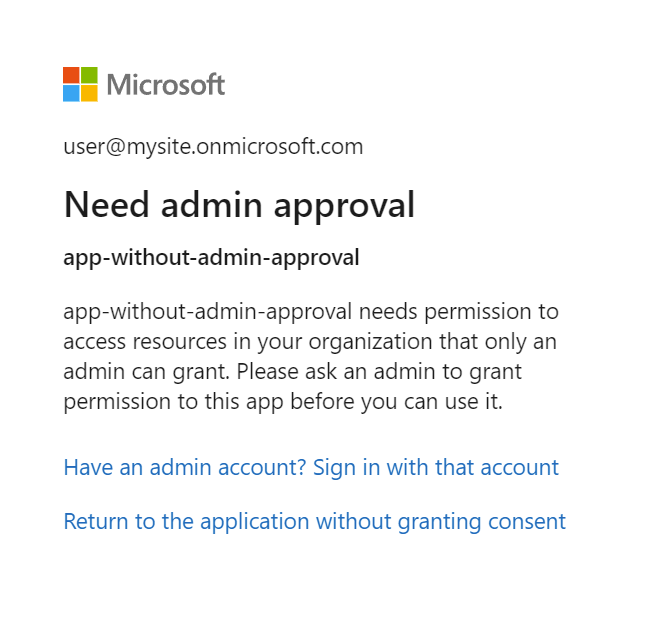
Krok 7: Kontrola stavu indexeru
Po vytvoření indexeru můžete volat Get Indexer Status:
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
Aktualizace zdroje dat
Pokud objekt zdroje dat neobsahuje žádné aktualizace, indexer se spustí podle plánu bez zásahu uživatele.
Pokud však upravíte objekt zdroje dat, když vypršela platnost kódu zařízení, musíte se znovu přihlásit, aby se indexer spustil. Pokud například změníte dotaz zdroje dat, přihlaste se znovu pomocí https://microsoft.com/devicelogin nového kódu zařízení a získejte ho.
Tady je postup aktualizace zdroje dat za předpokladu, že vypršela platnost kódu zařízení:
Voláním spustit indexer (Preview) spusťte spuštění indexeru ručně.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Zkontrolujte stav indexeru.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Pokud se zobrazí chyba s výzvou k návštěvě
https://microsoft.com/devicelogin, otevřete stránku a zkopírujte nový kód.Vložte kód do dialogového okna.
Znovu spusťte indexer ručně a zkontrolujte stav indexeru. Tentokrát by se spuštění indexeru mělo úspěšně spustit.
Indexování metadat dokumentu
Pokud indexujete metadata dokumentu ("dataToExtract": "contentAndMetadata"), budou pro index k dispozici následující metadata.
| Identifikátor | Typ | Popis |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | Kombinace klíče ID webu, ID knihovny a ID položky, která jednoznačně identifikuje položku v knihovně dokumentů pro web. |
| metadata_spo_site_id | Edm.String | ID sharepointového webu. |
| metadata_spo_library_id | Edm.String | ID knihovny dokumentů. |
| metadata_spo_item_id | Edm.String | ID položky (dokumentu) v knihovně. |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | Datum a čas poslední změny (UTC) položky. |
| metadata_spo_item_name | Edm.String | Název položky. |
| metadata_spo_item_size | Edm.Int64 | Velikost položky (v bajtech). |
| metadata_spo_item_content_type | Edm.String | Typ obsahu položky. |
| metadata_spo_item_extension | Edm.String | Rozšíření položky. |
| metadata_spo_item_weburi | Edm.String | Identifikátor URI položky. |
| metadata_spo_item_path | Edm.String | Kombinace nadřazené cesty a názvu položky |
Indexer SharePointu Online podporuje také metadata specifická pro každý typ dokumentu. Další informace najdete ve vlastnostech metadat obsahu používaných ve službě Azure AI Search.
Poznámka:
Pokud chcete indexovat vlastní metadata, musí být v parametru dotazu zdroje dat zadán parametr "additionalColumns".
Zahrnout nebo vyloučit podle typu souboru
To, které soubory se indexují, můžete řídit nastavením kritérií zahrnutí a vyloučení v části Parametry definice indexeru.
Zahrňte konkrétní přípony souborů nastavením "indexedFileNameExtensions" na čárkami oddělený seznam přípon souborů (s úvodní tečkou). Vylučte konkrétní přípony souborů nastavením "excludedFileNameExtensions" na přípony, které by se měly přeskočit. Pokud je stejné rozšíření v obou seznamech, je vyloučené z indexování.
PUT /indexers/[indexer name]?api-version=2024-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Řízení indexovaných dokumentů
Jeden indexer SharePointu Online může indexovat obsah z jedné nebo více knihoven dokumentů. Pomocí parametru "container" v definici zdroje dat označte, ze kterých webů a knihoven dokumentů se mají indexovat.
Oddíl "kontejner" zdroje dat má dvě vlastnosti pro tento úkol: "name" a "query".
Název
Je vyžadována vlastnost "name" a musí být jednou ze tří hodnot:
| Hodnota | Popis |
|---|---|
| defaultSiteLibrary | Indexujte veškerý obsah z výchozí knihovny dokumentů webu. |
| allSiteLibraries | Indexuje veškerý obsah ze všech knihoven dokumentů na webu. Knihovny dokumentů z podřízeného webu jsou mimo rozsah/ Pokud potřebujete obsah z podřízených webů, zvolte useQuery a zadejte includeLibrariesInSite. |
| useQuery | Indexujte pouze obsah definovaný v dotazu. |
Dotaz
Parametr dotazu zdroje dat se skládá z párů klíčových slov a hodnot. Níže jsou uvedena klíčová slova, která lze použít. Tyto hodnoty jsou adresy URL webu nebo adresy URL knihoven dokumentů.
Poznámka:
Pokud chcete získat hodnotu pro konkrétní klíčové slovo, doporučujeme přejít do knihovny dokumentů, kterou se pokoušíte zahrnout nebo vyloučit a zkopírovat identifikátor URI z prohlížeče. Toto je nejjednodušší způsob, jak získat hodnotu, která se má použít s klíčovým slovem v dotazu.
| Klíčové slovo | Popis hodnot a příklady |
|---|---|
| null | Pokud je hodnota null nebo prázdná, indexujte buď výchozí knihovnu dokumentů, nebo všechny knihovny dokumentů v závislosti na názvu kontejneru. Příklad: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indexujte obsah ze všech knihoven v zadaném webu v připojovací řetězec. Hodnota by měla být identifikátor URI lokality nebo podřízeného webu. Příklad 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } Příklad 2 (zahrnout pouze několik podřízených webů): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | Indexuje veškerý obsah z této knihovny. Hodnota je plně kvalifikovaná cesta ke knihovně, kterou můžete zkopírovat z prohlížeče: Příklad 1 (plně kvalifikovaná cesta): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Příklad 2 (identifikátor URI zkopírovaný z prohlížeče): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | Neindexujte obsah z této knihovny. Hodnota je plně kvalifikovaná cesta ke knihovně, kterou můžete zkopírovat z prohlížeče: Příklad 1 (plně kvalifikovaná cesta): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Příklad 2 (identifikátor URI zkopírovaný z prohlížeče): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | Indexujte sloupce z knihovny dokumentů. Hodnota je čárkami oddělený seznam názvů sloupců, které chcete indexovat. Dvojité zpětné lomítko použijte k řídicímu středníku a čárkám v názvech sloupců: Příklad 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Příklad 2 (řídicí znaky používající dvojité zpětné lomítko): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Zpracování chyb
Indexer SharePointu Online se ve výchozím nastavení zastaví, jakmile narazí na dokument s nepodporovaným typem obsahu (například obrázkem). Pomocí parametru excludedFileNameExtensions můžete přeskočit určité typy obsahu. Je však možné, že budete muset indexovat dokumenty, aniž byste předem znali všechny možné typy obsahu. Pokud chcete pokračovat v indexování, pokud je zjištěn nepodporovaný typ obsahu, nastavte failOnUnsupportedContentType parametr konfigurace na hodnotu false:
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
U některých dokumentů azure AI Search nedokáže určit typ obsahu nebo nemůže zpracovat dokument jiného podporovaného typu obsahu. Pokud chcete tento režim selhání ignorovat, nastavte failOnUnprocessableDocument parametr konfigurace na hodnotu false:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure AI Search omezuje velikost dokumentů indexovaných. Tyto limity jsou popsané v omezeních služeb ve službě Azure AI Search. Nadlimitní dokumenty se ve výchozím nastavení považují za chyby. Pokud ale nastavíte indexStorageMetadataOnlyForOversizedDocuments parametr konfigurace na hodnotu true, můžete stále indexovat metadata úložiště nadlimitních dokumentů:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
Můžete také pokračovat v indexování, pokud dojde k chybám v jakémkoli okamžiku zpracování, a to buď při analýze dokumentů, nebo při přidávání dokumentů do indexu. Pokud chcete ignorovat určitý počet chyb, nastavte maxFailedItems parametry konfigurace maxFailedItemsPerBatch na požadované hodnoty. Příklad:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Pokud je na sharepointovém webu povolené šifrování souboru, může se zobrazit chybová zpráva podobná následující:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
Chybová zpráva bude také obsahovat ID webu SharePointu, ID jednotky a ID položky jednotky v následujícím vzoru: <sharepoint site id> :: <drive id> :: <drive item id>. Tyto informace je možné použít k identifikaci položky, která na konci SharePointu selhává. Uživatel pak může odebrat šifrování z položky, aby problém vyřešil.