Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Ve službě Azure AI Search existuje několik způsobů, jak spustit indexer:
- Spusťte okamžitě po vytvoření indexeru. Toto je výchozí nastavení, pokud indexer nevytvoříte ve stavu Zakázáno.
- Spusťte podle plánu pro provádění v pravidelných intervalech.
- Spusťte na vyžádání s resetem nebo bez něj.
Tento článek vysvětluje, jak spouštět indexery na vyžádání s resetováním a bez nich. Popisuje také provádění indexátoru, jeho dobu trvání a souběžnost.
Jak se indexery připojují k prostředkům Azure
Indexery jsou jedním z několika subsystémů, které provádějí zjevná odchozí volání k jiným prostředkům Azure. K ověření připojení můžete použít klíče nebo role.
Z hlediska rolí Azure nemají indexery samostatné identity: připojení z vyhledávacího webu k jinému prostředku Azure se provádí pomocí systému nebo spravované identity přiřazené uživatelem vyhledávací služby a přiřazení role k cílovému prostředku Azure. Pokud se indexer připojí k prostředku Azure ve virtuální síti, měli byste pro toto připojení vytvořit sdílené privátní propojení .
Spuštění indexeru
Vyhledávací služba spouští jednu úlohu indexeru na jednotku vyhledávání. Každá vyhledávací služba začíná s jednou jednotkou pro vyhledávání, ale každý nový oddíl nebo replika zvyšuje počet jednotek vyhledávání vaší služby. Počet jednotek vyhledávání můžete zkontrolovat v části Základy webu Azure Portal na stránce Přehled . Pokud potřebujete souběžné zpracování, ujistěte se, že vaše vyhledávací jednotky obsahují dostatečný počet replik. Indexery se nespouštějí na pozadí, takže pokud je služba pod tlakem, může dojít k většímu omezování dotazů než obvykle.
Následující snímek obrazovky ukazuje počet jednotek hledání, které určují, kolik indexerů může běžet najednou.

Po spuštění indexeru ho nemůžete pozastavit ani zastavit. Provádění indexeru se zastaví, pokud nejsou k dispozici žádné další dokumenty k načtení nebo aktualizaci, nebo při dosažení maximálního časového limitu.
Můžete spustit více indexerů najednou za předpokladu, že je dostatečná kapacita, ale každý samotný indexer je jedna instance. Spuštění nové instance, zatímco indexer je již spuštěn, způsobí tuto chybu: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Spouštěcí prostředí indexeru
Úloha indexeru se spouští ve spravovaném spouštěcím prostředí. V současné době existují dvě prostředí:
Prostředí privátního spouštění běží na vyhledávacích clusterech, které jsou specifické pro vaši vyhledávací službu.
Víceklientských prostředí má procesory obsahu, které spravuje a zabezpečuje Microsoft bez dalších poplatků. Toto prostředí se používá k odlehčení výpočetně náročného zpracování a ponechání prostředků specifických pro službu k dispozici pro rutinní operace. Kdykoli je to možné, většina dovedností se spustí v multitenantním prostředí. Tato možnost je výchozí.
Výpočetní zpracování se týká sad dovedností běžících na procesorech obsahu a úlohách indexeru, které zpracovávají velký objem dokumentů nebo dokumentů velké velikosti. Zpracování sad dovedností na víceklientských procesorech obsahu je určeno heuristikou a systémovými informacemi a není pod kontrolou zákazníků.
Použití víceklientských prostředí ve službách Standard2 nebo vyšších můžete zabránit tak, že připnete indexer a zpracování sady dovedností výhradně do vyhledávacích clusterů.
Nastavte parametr v definici indexeru executionEnvironment tak, aby vždy spustil indexer v privátním spouštěcím prostředí.
Brány firewall protokolu IP blokují víceklientských prostředí, takže pokud máte bránu firewall, vytvořte pravidlo , které umožňuje připojení víceklientských procesorů.
Omezení indexeru se pro každé prostředí liší:
| Pracovní zátěž | Maximální doba trvání | Maximální počet úloh | Spouštěcí prostředí |
|---|---|---|---|
| Privátní spuštění | 24 hodin | Jedna úloha indexeru na jednotkuvyhledávání 1. | Indexování se nespustí na pozadí. Místo toho vyhledávací služba vyrovnává všechny úlohy indexování proti průběžným dotazům a akcím správy objektů (například vytváření nebo aktualizace indexů). Při spouštění indexerů byste měli očekávat určitou latenci dotazů, pokud jsou objemy indexování velké. |
| Víceúrovňový systém | 2 hodiny 2 | Neurčitá 3 | Vzhledem k tomu, že cluster pro zpracování obsahu je víceklientní, přidávají se procesory obsahu, aby splňovaly poptávku. Pokud dojde ke zpoždění při spuštění na vyžádání nebo plánovaném spuštění, důvodem je pravděpodobně to, že systém buď přidává procesory, nebo čeká na to, až bude k dispozici. |
1 Vyhledávací jednotky mohou být flexibilní kombinace oddílů a replik, ale úlohy indexovacího nástroje nejsou svázané s jedním nebo druhým. Jinými slovy, pokud máte 12 jednotek, můžete mít 12 úloh indexeru spuštěných souběžně v privátním spuštění bez ohledu na to, jak se jednotky vyhledávání nasazují.
2 Pokud jsou ke zpracování všech dat potřeba více než dvě hodiny, povolte detekci změn a naplánujte, aby indexer běžel v 5minutových intervalech, aby se indexování rychle obnovilo, pokud se zastaví kvůli vypršení časového limitu. Další strategie najdete v tématu Indexování velké datové sady .
3 "Neurčitá" znamená, že limit není kvantifikován počtem úloh. Některé úlohy, jako je zpracování sady dovedností, se můžou spouštět paralelně, což může vést k mnoha úlohám, i když je zapojen pouze jeden indexer. I když prostředí neukládá omezení, platí omezení indexeru pro vaši vyhledávací službu.
Spustit bez resetování
Operace spuštění Indexeru detekuje a zpracovává pouze to, co je nezbytné k synchronizaci indexu vyhledávání se změnami v podkladovém zdroji dat. Přírůstkové indexování začíná vyhledáním interního vrcholu pro určení naposledy aktualizovaného vyhledávacího dokumentu, který se stane počátečním bodem pro provádění indexace nad novými a aktualizovanými dokumenty v datovém zdroji.
Detekce změn je nezbytná pro určení toho, co je nového nebo aktualizováno ve zdroji dat. Indexery používají možnosti detekce změn podkladového zdroje dat k určení toho, co je nového nebo aktualizováno ve zdroji dat.
Azure Storage má integrovanou detekci změn prostřednictvím vlastnosti LastModified.
Aby indexer mohl číst nové a aktualizované řádky, musí být nakonfigurované jiné zdroje dat, jako je Azure SQL nebo Azure Cosmos DB.
Pokud se podkladový obsah nezmění, operace spuštění nemá žádný vliv. V tomto případě historie spuštění indexeru 0\0 označuje zpracované dokumenty.
Abyste mohli indexer znovu kompletně zpracovat, musíte jej resetovat, jak je vysvětleno v další části.
Resetování indexerů
Po počátečním spuštění indexer sleduje, které vyhledávací dokumenty se indexují prostřednictvím interní horní meze. Značka není nikdy odhalena, ale indexer interně ví, kde se naposledy zastavil.
Pokud potřebujete znovu sestavit celý index nebo jeho část, použijte rozhraní API pro resetování dostupná na nižších úrovních v hierarchii objektů:
- Resetování indexerů vymaže horní značku a provede kompletní přeindexování všech dokumentů.
- Resynchronizace indexerů (Preview) provádí efektivní částečnou reindexaci všech dokumentů.
- Resetování dokumentů (Preview) přeindexuje určitý dokument nebo seznam dokumentů.
- Resetování dovedností (Preview) vyvolá zpracování dovedností pro určitou dovednost.
Po resetování postupujte podle příkazu Spustit a znovu zpracujte nové a existující dokumenty. Sirotčí dokumenty vyhledávání, které nemají žádný protějšek ve zdroji dat, nelze odstranit při resetování nebo spuštění. Pokud potřebujete odstranit dokumenty, přečtěte si místo toho téma Dokumenty – Index .
Poznámka:
Tabulky nemohou být prázdné. Pokud pomocí funkce TRUNCATE TABLE vymažete řádky, resetování a opětovné spuštění indexeru neodebere odpovídající vyhledávací dokumenty. Pokud chcete odebrat osamocené dokumenty, musíte je indexovat s akcí odstranění.
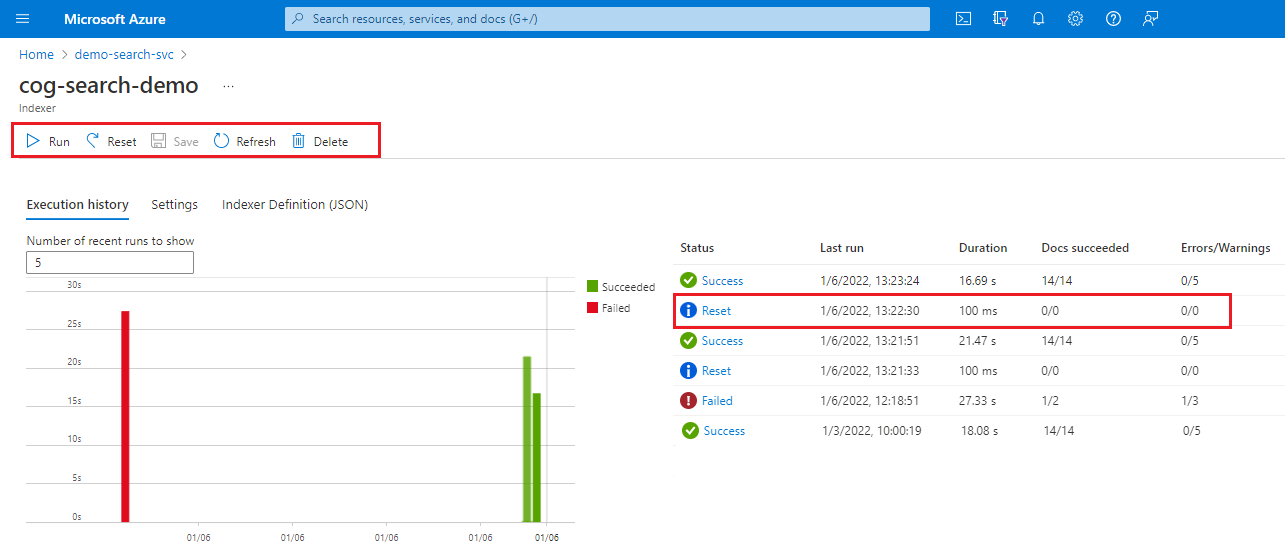
Jak resetovat a spouštět indexery
Obnoví horní mez. Všechny dokumenty v indexu vyhledávání jsou označeny pro úplné přepsání, bez aktualizací či úprav v řádcích nebo sloučení do existujícího obsahu. Pro indexační nástroje s dovednostmi a ukládáním do mezipaměti rozšíření resetování indexu také implicitně resetuje sadu dovedností.
Skutečná práce nastane, když provedete resetování pomocí příkazu Spustit:
- Všechny nové dokumenty nalezené v podkladovém zdroji se přidají do indexu vyhledávání.
- Všechny dokumenty, které existují ve zdroji dat i indexu vyhledávání, se přepíšou v indexu vyhledávání.
- Veškerý obohacený obsah vytvořený ze sad dovedností se znovu sestaví. Mezipaměť rozšiřování, pokud je povolená, se aktualizuje.
Jak už jsme uvedli dříve, resetování je pasivní operace: musíte postupovat s požadavkem Spustit, abyste znovu vytvořili index.
Operace resetování/spuštění se vztahují na index vyhledávání nebo úložiště znalostí, na konkrétní dokumenty nebo projekce a na rozšiřování v mezipaměti, pokud resetování explicitně nebo implicitně zahrnuje dovednosti.
Resetování platí také pro operace vytváření a aktualizace. Neaktivuje odstranění ani nevyčistí osamocené dokumenty v indexu vyhledávání. Další informace o odstraňování dokumentů naleznete v tématu Dokumenty – Index.
Po resetování indexeru nemůžete akci vrátit zpět.
Přihlaste se k webu Azure Portal a otevřete stránku vyhledávací služby.
Na stránce Přehled vyberte kartu Indexery.
Vyberte indexer.
Vyberte příkaz Obnovit a akci potvrďte výběrem možnosti Ano.
Aktualizujte stránku, aby se zobrazil stav. Položku můžete vybrat a zobrazit její podrobnosti.
Vyberte Spustit , chcete-li spustit zpracování indexeru, nebo počkejte na další plánované spuštění.
Resetování dovedností (Preview)
U indexerů, které mají sady dovedností, můžete resetovat jednotlivé dovednosti a vynutit zpracování pouze této dovednosti a všech podřízených dovedností, které závisí na jeho výstupu. Mezipaměť rozšiřování, pokud jste ji povolili, se také aktualizuje.
Resetovat dovednosti je momentálně jenom REST, k dispozici až do verze 2020–06–30 preview nebo novější. Doporučujeme nejnovější rozhraní API ve verzi Preview.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Můžete určit jednotlivé dovednosti, jak je uvedeno v předchozím příkladu, ale pokud některá z těchto dovedností vyžaduje výstup z nezasílaných dovedností (#2 až #4), spustí se nesečtené dovednosti, pokud mezipaměť nemůže poskytnout potřebné informace. Aby to bylo pravda, nesmí mít rozšíření v mezipaměti pro dovednosti č. 2 až #4 závislost na #1 (uvedené pro resetování).
Pokud nejsou zadány žádné dovednosti, spustí se celá sada dovedností a pokud je povolená ukládání do mezipaměti, mezipaměť se také aktualizuje.
Nezapomeňte spustit Run Indexer, abyste vyvolali skutečné zpracování.
Jak resetovat dokumenty (náhled)
Indexery – Reset docs přijímá seznam klíčů dokumentů, abyste mohli aktualizovat konkrétní dokumenty. Pokud je zadáno, parametry resetování se stanou jediným determinantem toho, co se zpracuje, bez ohledu na jiné změny v podkladových datech. Pokud se například od posledního spuštění indexeru přidalo nebo aktualizovalo 20 objektů blob, ale resetujete jenom jeden dokument, zpracuje se jenom tento dokument.
Každé pole v dokumentu vyhledávání se aktualizuje hodnotami a metadaty ze zdroje dat. Nemůžete vybrat a zvolit, která pole se mají aktualizovat.
Pokud je zdrojem dat Azure Data Lake Storage (ADLS) Gen2 a objekty blob jsou přidružené k metadatům oprávnění, tato oprávnění se také znovu ingestují v indexu vyhledávání, pokud se oprávnění v podkladových datech změní. Další informace najdete v tématu Opětovné indexování seznamu ACL a rozsahu RBAC pomocí indexerů ADLS Gen2.
Pokud je dokument rozšířen prostřednictvím sady dovedností a obsahuje data uložená v mezipaměti, vyvolá se sada dovedností pouze pro zadané dokumenty a mezipaměť se aktualizuje pro reprocesované dokumenty.
Při prvním testování tohoto rozhraní API vám následující rozhraní API můžou pomoct ověřit a otestovat chování. Můžete použít rozhraní API verze Preview 2020-06-30-preview a novější. Doporučujeme nejnovější rozhraní API ve verzi Preview.
Volání indexerů – Získání stavu pomocí rozhraní API Preview k ověření stavu resetování a stavu spuštění. Informace o žádosti o resetování najdete na konci odpovědi na stav.
Zavolejte Indexery – Resetování dokumentů pomocí verze API pro náhled, abyste určili, které dokumenty chcete zpracovat.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }Klíče dokumentu zadané v požadavku jsou hodnoty z indexu vyhledávání, které se můžou lišit od odpovídajících polí ve zdroji dat. Pokud si nejste jisti hodnotou klíče, odešlete dotaz , který vrátí hodnotu. Můžete použít
selectk vrácení pouze pole klíče dokumentu.Pro objekty blob, které jsou analyzovány do více vyhledávacích dokumentů (kde parsingMode je nastavena na jsonLines nebo jsonArrays nebo delimitedText), klíč dokumentu je generován indexerem a může být pro vás neznámý. V tomto scénáři se dotaz na klíč dokumentu vrátí správnou hodnotu.
Voláním indexeru spuštění (libovolné verze rozhraní API) zpracujete zadané dokumenty. Indexují se jenom tyto konkrétní dokumenty.
Volejte Run Indexer podruhé ke zpracování od poslední horní meze.
Voláním prohledat dokumenty můžete vyhledat aktualizované hodnoty a také vrátit klíče dokumentu, pokud si nejste jisti hodnotou. Použijte
"select": "<field names>", pokud chcete omezit, která pole se zobrazí v odpovědi.
Přepsání seznamu klíčových slov dokumentu
Načtení rozhraní API pro resetování dokumentů několikrát s různými klíči přidá nové klíče do seznamu klíčů dokumentů, které byly resetovány. Volání rozhraní API s parametrem overwrite nastaveným na true přepíše aktuální seznam novým seznamem:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Postup opětovné synchronizace indexerů (Preview)
Resynchronizace indexerů je nové rozhraní API ve verzi Preview, které provádí částečné přeindexování všech dokumentů. Indexer se považuje za synchronizovaný se zdrojem dat, pokud jsou specifická pole všech dokumentů v cílovém indexu konzistentní s daty ve zdroji dat. Indexer obvykle dosahuje synchronizace po úspěšném počátečním spuštění. Pokud je dokument odstraněn ze zdroje dat, indexer zůstane synchronizovaný podle této definice. Během dalšího spuštění indexeru se ale odpovídající dokument v cílovém indexu odebere, pokud je povolené sledování odstranění.
Pokud se dokument změní ve zdroji dat, indexer se stane nesynchronizovaným. Obecně platí, že mechanismy sledování změn znovu synchronizují indexer během dalšího spuštění. Například ve službě Azure Storage se úprava objektu blob aktualizuje čas poslední změny, což umožňuje jeho opětovné indexování v následném spuštění indexeru, protože aktualizovaný čas překračuje horní mez nastavenou předchozím spuštěním.
Naproti tomu u některých zdrojů dat, jako je ADLS Gen2, změna seznamů řízení přístupu (ACL) objektu blob nemění čas poslední změny, což znamená, že sledování změn je neefektivní, pokud se ingestují seznamy ACL. V důsledku toho nebude upravený objekt blob při následném spuštění znovu indexován, protože se zpracovávají pouze dokumenty upravené po poslední referenční značce.
Při použití buď "obnovení" nebo "reset dokumentů" lze tento problém vyřešit. Obnovení může být časově náročné a neefektivní pro velké datové sady, a reset dokumentů vyžaduje identifikaci klíče dokumentu blobu určeného k aktualizaci.
Resync Indexery nabízejí efektivní a pohodlnou alternativu. Uživatelé jednoduše umístí indexer do režimu resynchronizace a určí obsah, který se má znovu synchronizovat voláním rozhraní API pro resynchronizaci indexerů. V dalším spuštění indexer zkontroluje pouze relevantní část dat ve zdroji a zabrání zbytečnému zpracování, které nesouvisí se zadanými daty. Bude také dotazovat existující dokumenty v cílovém indexu a aktualizovat pouze dokumenty, které zobrazují nesrovnalosti mezi zdrojem dat a cílovým indexem. Po opětovném spuštění se indexer synchronizuje a vrátí do režimu běžného spuštění indexeru pro následné spuštění.
Postup opětovné synchronizace a spuštění indexerů
Indexery - Resynchronizace volání s verzí Preview rozhraní API pro určení, jaký obsah znovu synchronizovat.
POST https://[service name].search.windows.net/indexers/[indexer name]/resync?api-version=2025-05-01-preview { "options" : [ "permissions" ] }- Pole
optionsje povinné. V současné době jepermissionsjedinou podporovanou možností . To znamená, že budou aktualizována pouze pole filtru oprávnění v cílovém indexu.
- Pole
Zavolejte Run Indexer (libovolnou verzi rozhraní API) pro znovu synchronizaci indexeru.
Volejte Run Indexer podruhé ke zpracování od poslední horní meze.
Zkontrolujte stav resetování "currentState"
Pokud chcete zkontrolovat stav resetování a zjistit, které klíče dokumentu se zařadí do fronty ke zpracování, postupujte podle těchto kroků.
Zavolejte Get Indexer Status pomocí rozhraní API ve verzi preview.
Rozhraní API pro náhled vrátí část
currentState, která se nachází na konci odpovědi."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resyncInitialTrackingState": null, "resyncFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Zkontrolujte režim:
V případě resetování dovedností by měl být režim nastaven na
indexingAllDocs(protože se to potenciálně týká všech dokumentů, pokud jde o pole, která jsou naplněná rozšiřováním pomocí umělé inteligence).Pro resynchronní indexery by měl být režim nastaven na
indexingResync. Indexer zkontroluje všechny dokumenty a zaměřuje se na data ve zdroji dat a příslušná pole v cílovém indexu.V případě resetování dokumentů by měl být režim nastaven na
indexingResetDocs. Indexer si tento stav zachová, dokud nebudou zpracovány všechny klíče dokumentu poskytnuté při volání resetování dokumentů, během kterého se nebudou spouštět žádné jiné úlohy indexeru. Vyhledání všech dokumentů v seznamu klíčů dokumentů vyžaduje zpracování každého dokumentu, aby bylo možné vyhledat a porovnat na klíči, a to může chvíli trvat, pokud je datový soubor velký. Pokud kontejner objektů blob obsahuje stovky objektů blob a dokumenty, které chcete resetovat, jsou na konci, indexer nenajde odpovídající objekty blob, dokud se nekontrolují všechny ostatní.Po opětovném zpracování dokumentů znovu spusťte příkaz Získat stav indexeru. Indexer se vrátí do
indexingAllDocsrežimu a zpracuje všechny nové nebo aktualizované dokumenty při dalším spuštění.
Další kroky
Rozhraní API pro resetování se používají k informování rozsahu dalšího spuštění indexeru. Pro skutečné zpracování budete muset vyvolat spuštění indexeru na vyžádání nebo povolit naplánované úloze dokončení práce. Po dokončení spuštění se indexer vrátí k normálnímu zpracování bez ohledu na to, jestli je to v plánu nebo zpracování na vyžádání.
Po resetování a opětovném spuštění úloh indexeru můžete monitorovat stav z vyhledávací služby nebo získat podrobné informace prostřednictvím protokolování prostředků.