Spolehlivost ve službě Azure AI Search
Spolehlivost napříč Azure znamená odolnost a dostupnost, pokud dojde k výpadku nebo snížení výkonu služby. Ve službě Azure AI Search je možné dosáhnout spolehlivosti v rámci jedné služby nebo prostřednictvím několika vyhledávacích služeb v samostatných oblastech.
Nasaďte jednu vyhledávací službu a vertikálně navyšte kapacitu pro zajištění vysoké dostupnosti. Můžete přidat více replik pro zpracování vyššího indexování a dotazování úloh. Pokud vaše vyhledávací služba podporuje zóny dostupnosti, repliky se automaticky zřídí v různých fyzických datových centrech kvůli větší odolnosti.
Nasaďte více vyhledávacích služeb napříč různými geografickými oblastmi. Všechny úlohy vyhledávání jsou plně obsažené v jedné službě, která běží v jedné geografické oblasti, ale ve scénáři s více službami máte možnosti pro synchronizaci obsahu tak, aby byla stejná ve všech službách. Pokud dojde k výpadku služby, můžete také nastavit řešení vyrovnávání zatížení pro redistribuci požadavků nebo převzetí služeb při selhání.
V případě kontinuity podnikových procesů a zotavení po haváriích na regionální úrovni naplánujte multiregionální topologii, která se skládá z více vyhledávacích služeb s identickou konfigurací a obsahem. Váš vlastní skript nebo kód poskytuje mechanismus převzetí služeb při selhání alternativní vyhledávací službě, pokud se náhle stane nedostupným.
Vysoká dostupnost
Ve službě Azure AI Search jsou repliky kopie vašeho indexu. Vyhledávací služba je zprovozněna s alespoň jednou replikou a může mít až 12 replik. Přidání replik umožňuje službě Azure AI Search provádět restartování počítače a údržbu na jedné replice, zatímco spouštění dotazů pokračuje na jiných replikách.
U každé jednotlivé služby Search Microsoft zaručuje minimálně 99,9% dostupnost, pokud konfigurace splňuje tato kritéria:
Dvě repliky pro vysokou dostupnost úloh jen pro čtení (dotazy)
Tři nebo více replik pro vysokou dostupnost úloh pro čtení i zápis (dotazy a indexování)
Systém má interní mechanismy pro monitorování stavu repliky a integrity oddílů. Pokud zřídíte konkrétní kombinaci replik a oddílů, systém zajistí tuto úroveň kapacity pro vaši službu.
Pro úroveň Free není k dispozici žádná smlouva o úrovni služeb (SLA). Další informace najdete ve sla pro Azure AI Search.
Podpora zón dostupnosti
Zóny dostupnosti jsou funkce platformy Azure, která rozděluje datová centra oblasti do různých skupin fyzických umístění, aby poskytovala vysokou dostupnost ve stejné oblasti. Ve službě Azure AI Search jsou jednotlivé repliky jednotkami přiřazení zóny. Vyhledávací služba běží v jedné oblasti; jeho repliky běží v různých fyzických datových centrech (nebo zónách) v dané oblasti.
Zóny dostupnosti se používají při přidávání dvou nebo více replik do vyhledávací služby. Každá replika se umístí do jiné zóny dostupnosti v rámci oblasti. Pokud máte v oblasti vyhledávací služby více replik než dostupné zóny, repliky se distribuují napříč zónami co nejrovnoměrněji. Na vaší straně není žádná konkrétní akce, s výjimkou vytvoření vyhledávací služby v oblasti, která poskytuje zóny dostupnosti, a pak nakonfigurovat službu tak, aby používala více replik.
Požadavky
- Úroveň služby musí být Standard nebo vyšší.
- Oblast služby musí být v oblasti, ve které jsou dostupné zóny (uvedené v následující části).
- Konfigurace musí obsahovat více replik: dvě pro úlohy dotazů jen pro čtení, tři pro úlohy čtení i zápisu, které zahrnují indexování.
Podporované oblasti
Podpora zón dostupnosti závisí na infrastruktuře a úložišti. V současné době má následující zóna nedostatečné úložiště a neposkytuje zónu dostupnosti pro Azure AI Search:
- Japonsko – západ
V opačném případě se zóny dostupnosti pro Azure AI Search podporují v následujících oblastech:
| Oblast | Datum zavedení |
|---|---|
| Austrálie – východ | 30. ledna 2021 nebo novější |
| Brazílie – jih | 2. května 2021 nebo novější |
| Kanada – střed | 30. ledna 2021 nebo novější |
| Indie – střed | 20. ledna 2022 nebo novější |
| USA – střed | 4. prosince 2020 nebo novější |
| Čína – sever 3 | 7. září 2022 nebo novější |
| Východní Asie | 13. ledna 2022 nebo novější |
| USA – východ | 27. ledna 2021 nebo novější |
| USA – východ 2 | 30. ledna 2021 nebo novější |
| Francie – střed | 23. října 2020 nebo novější |
| Německo – středozápad | 3. května 2021 nebo novější |
| Izrael – střed | 1. dubna 2024 nebo novější |
| Itálie – sever | 1. dubna 2024 nebo novější |
| Japonsko – východ | 30. ledna 2021 nebo novější |
| Jižní Korea – střed | 20. ledna 2022 nebo novější |
| Severní Evropa | 28. ledna 2021 nebo novější |
| Norsko – východ | 20. ledna 2022 nebo novější |
| Střední Katar | 25. srpna 2022 nebo novější |
| Jižní Afrika – sever | 7. září 2022 nebo novější |
| Středojižní USA | 30. dubna 2021 nebo novější |
| Jihovýchodní Asie | 31. ledna 2021 nebo novější |
| Švédsko – střed | 21. ledna 2022 nebo novější |
| Švýcarsko – sever | 7. září 2022 nebo novější |
| Spojené arabské emiráty – sever | 9. září 2022 nebo novější |
| Velká Británie – jih | 30. ledna 2021 nebo novější |
| US Gov – Virginie | 30. dubna 2021 nebo novější |
| Západní Evropa | 29. ledna 2021 nebo novější |
| USA – západ 2 | 30. ledna 2021 nebo novější |
| USA – západ 3 | 2. června 2021 nebo novější |
Poznámka:
Zóny dostupnosti nemění podmínky smlouvy SLA. Stále potřebujete tři nebo více replik pro zajištění vysoké dostupnosti dotazů.
Více služeb v samostatných geografických oblastech
Redundance služeb je nezbytná, pokud vaše provozní požadavky zahrnují:
Požadavky na provozní kontinuitu a zotavení po havárii (BCDR). Azure AI Search neposkytuje okamžité převzetí služeb při selhání, pokud dojde k výpadku.
Rychlý výkon pro globálně distribuovanou aplikaci Pokud požadavky na dotazy a indexování pocházejí z celého světa, uživatelé, kteří jsou nejblíže hostitelskému datovému centru, mají rychlejší výkon. Vytváření dalších služeb v oblastech s blízkostí těchto uživatelů může rovnat výkonu pro všechny uživatele.
Pokud potřebujete dvě nebo více vyhledávacích služeb, může jejich vytvoření v různých oblastech splňovat požadavky aplikace na kontinuitu a obnovení a rychlejší doby odezvy globální uživatelské základny.
Azure AI Search neposkytuje automatizovanou metodu replikace indexů vyhledávání napříč geografickými oblastmi, ale existuje několik technik, které tento proces můžou usnadnit implementaci a správu. Tyto techniky jsou popsány v následujících několika částech.
Cílem geograficky distribuované sady vyhledávacích služeb je mít k dispozici dva nebo více indexů ve dvou nebo více oblastech, kde se uživatel přesměruje do azure AI Search, která poskytuje nejnižší latenci:
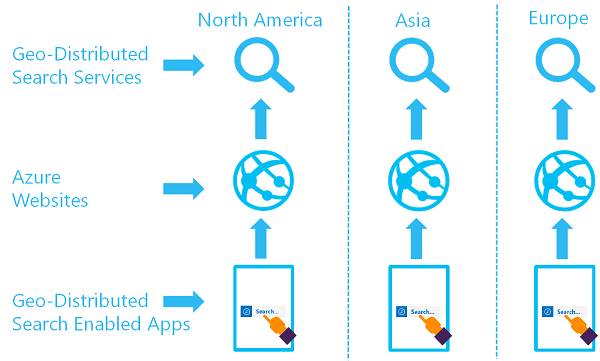
Tuto architekturu můžete implementovat tak, že vytvoříte několik služeb a navrhnete strategii synchronizace dat. Volitelně můžete zahrnout prostředek, jako je Azure Traffic Manager pro žádosti o směrování.
Tip
Nápovědu k nasazení více vyhledávacích služeb napříč několika oblastmi najdete v této ukázce Bicep na GitHubu , která nasadí plně nakonfigurované víceregionální řešení vyhledávání. Ukázka nabízí dvě možnosti synchronizace indexů a přesměrování požadavků pomocí Traffic Manageru.
Synchronizace dat napříč několika službami
Existují dvě možnosti synchronizace dvou nebo více jedinečných vyhledávacích služeb:
- Načtení aktualizací obsahu do indexu vyhledávání pomocí indexeru
- Nasdílejte obsah do indexu pomocí rozhraní REST API pro přidání nebo aktualizaci dokumentů nebo ekvivalentního rozhraní API sady Azure SDK.
Pokud chcete nakonfigurovat některou z možností, doporučujeme použít ukázkový skript Bicep v úložišti azure-search-multiple-region změněný na vaše oblasti a strategie indexování.
Možnost 1: Použití indexerů k aktualizaci obsahu ve více službách
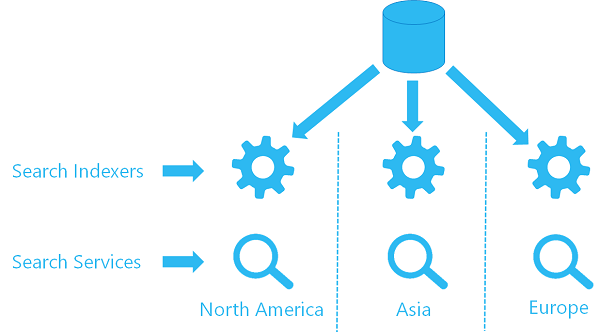
Pokud už indexer používáte v jedné službě, můžete ve druhé službě nakonfigurovat druhý indexer tak, aby používal stejný objekt zdroje dat a načítá data ze stejného umístění. Každá služba v každé oblasti má svůj vlastní indexer a cílový index (index vyhledávání není sdílený, což znamená, že každý index má vlastní kopii dat), ale každý indexer odkazuje na stejný zdroj dat.
Tady je základní vizuál toho, jak by tato architektura vypadala.
Možnost 2: Použití rozhraní REST API pro nabízení aktualizací obsahu ve více službách
Pokud k odesílání obsahu do indexu vyhledávání používáte rozhraní REST API služby Azure AI Search, můžete zajistit synchronizaci různých vyhledávacích služeb tak, že při každé aktualizaci nasdílíte změny do všech vyhledávacích služeb. V kódu nezapomeňte zpracovávat případy, kdy aktualizace jedné vyhledávací služby selže, ale u jiných vyhledávacích služeb bude úspěšná.
Převzetí služeb při selhání nebo přesměrování požadavků na dotazy
Pokud potřebujete redundanci na úrovni požadavku, Azure nabízí několik možností vyrovnávání zatížení:
- Azure Traffic Manager, který se používá ke směrování požadavků na několik geograficky umístěných webů, které pak využívají více vyhledávacích služeb.
- Application Gateway, která se používá k vyrovnávání zatížení mezi servery v oblasti v aplikační vrstvě.
- Azure Front Door, který slouží k optimalizaci globálního směrování webového provozu a zajištění globálního převzetí služeb při selhání.
Při vyhodnocování možností vyrovnávání zatížení je potřeba mít na paměti některé body:
Vyhledávání je back-endová služba, která přijímá požadavky na dotazy a indexování od klienta.
Požadavky z klienta do vyhledávací služby musí být ověřeny. Pro přístup k operacím vyhledávání musí volající mít oprávnění založená na rolích nebo zadat klíč rozhraní API v požadavku.
Koncové body služby jsou ve výchozím nastavení dostupné prostřednictvím veřejného připojení k internetu. Pokud nastavíte privátní koncový bod pro připojení klientů, která pocházejí z virtuální sítě, použijte Application Gateway.
Azure AI Search přijímá požadavky adresované koncovému
<your-search-service-name>.search.windows.netbodu. Pokud se dostanete ke stejnému koncovému bodu pomocí jiného názvu DNS v hlavičce hostitele, například CNAME, požadavek se odmítne.
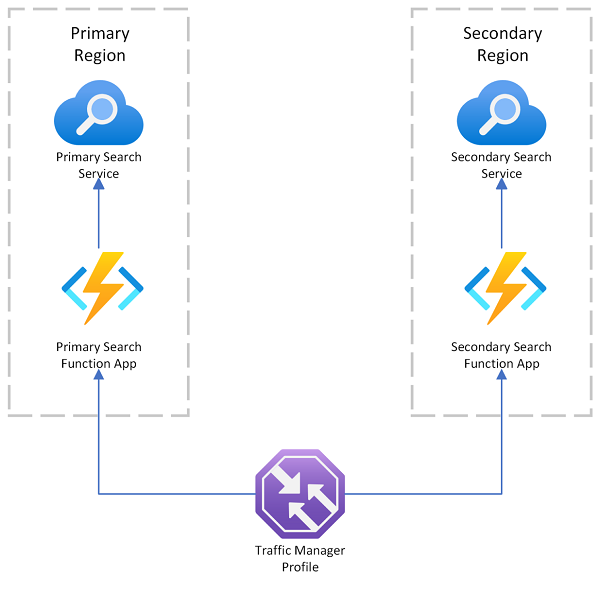
Azure AI Search poskytuje ukázku nasazení ve více oblastech, která pro přesměrování požadavků používá Azure Traffic Manager, pokud primární koncový bod selže. Toto řešení je užitečné při směrování do klienta s podporou vyhledávání, který volá pouze vyhledávací službu ve stejné oblasti.
Azure Traffic Manager se primárně používá ke směrování síťového provozu napříč různými koncovými body na základě konkrétních metod směrování (například priority, výkonu nebo geografického umístění). Funguje na úrovni DNS a směruje příchozí požadavky na příslušný koncový bod. Pokud koncový bod, který služba Traffic Manager obsluhuje, začne odmítat požadavky, provoz se směruje do jiného koncového bodu.
Traffic Manager neposkytuje koncový bod pro přímé připojení ke službě Azure AI Search, což znamená, že vyhledávací službu nemůžete umístit přímo za Traffic Manager. Místo toho se předpokládá, že se vyžaduje tok do Traffic Manageru, pak do webového klienta s podporou vyhledávání a nakonec do vyhledávací služby v back-endu. Klient a služba se nacházejí ve stejné oblasti. Pokud dojde k výpadku jedné vyhledávací služby, spustí se selhání vyhledávacího klienta a Traffic Manager přesměruje na zbývajícího klienta.
Rezidence dat v nasazení ve více oblastech
Když nasadíte více vyhledávacích služeb v různých geografických oblastech, váš obsah se uloží v oblasti, kterou jste zvolili pro každou vyhledávací službu.
Azure AI Search neukládá data mimo zadanou oblast bez vaší autorizace. Autorizace je implicitní, když používáte funkce, které zapisují do prostředku služby Azure Storage: mezipaměť rozšiřování, ladicí relace, úložiště znalostí. Ve všech případech je účet úložiště, který zadáte, v oblasti podle vašeho výběru.
Poznámka:
Pokud je účet úložiště i vyhledávací služba ve stejné oblasti, síťový provoz mezi vyhledáváním a úložištěm používá privátní IP adresu a vyskytuje se přes páteřní síť Microsoftu. Protože se používají privátní IP adresy, nemůžete nakonfigurovat brány firewall protokolu IP ani privátní koncový bod pro zabezpečení sítě. Místo toho jako alternativu použijte výjimku důvěryhodné služby, pokud jsou obě služby ve stejné oblasti.
O výpadkech služeb a katastrofických událostech
Jak je uvedeno ve sla, Microsoft zaručuje vysokou úroveň dostupnosti požadavků na dotazy indexu, když je instance Azure AI Search nakonfigurovaná se dvěma nebo více replikami, a žádosti o aktualizaci indexu, když je instance Azure AI Search nakonfigurovaná se třemi nebo více replikami. Neexistuje však žádný integrovaný mechanismus pro zotavení po havárii. Pokud je v případě závažného selhání mimo kontrolu Microsoftu vyžadována nepřetržitá služba, doporučujeme zřídit druhou službu v jiné oblasti a implementovat strategii geografické replikace, aby se zajistilo, že jsou indexy plně redundantní napříč všemi službami.
Zákazníci, kteří používají indexery k naplnění a aktualizaci indexů, můžou zpracovávat zotavení po havárii prostřednictvím indexerů specifických pro konkrétní geografické oblasti, které načítají data ze stejného zdroje dat. Dvě služby v různých oblastech, z nichž každý spouští indexer, by mohly indexovat stejný zdroj dat, aby bylo možné dosáhnout geografické redundance. Pokud indexujete ze zdrojů dat, které jsou také geograficky redundantní, mějte na paměti, že indexery Azure AI Search můžou provádět přírůstkové indexování (slučování aktualizací z nových, upravených nebo odstraněných dokumentů) z primárních replik. V případě převzetí služeb při selhání nezapomeňte indexer přesměrovat na novou primární repliku.
Pokud indexery nepoužíváte, použijete kód aplikace k paralelnímu nabízení objektů a dat do různých vyhledávacích služeb. Další informace naleznete v tématu Synchronizace dat napříč více službami.
Alternativy zálohování a obnovení
Strategie provozní kontinuity pro datovou vrstvu obvykle zahrnuje krok obnovení ze zálohy. Protože Azure AI Search není primárním řešením úložiště dat, Microsoft neposkytuje formální mechanismus pro samoobslužné zálohování a obnovení. Vzorový kód pro obnovení záloh indexu v tomto ukázkovém úložišti Azure AI Search .NET však můžete použít k zálohování definice a snímku indexu do řady souborů JSON a pak tyto soubory použít k obnovení indexu v případě potřeby. Tento nástroj může také přesouvat indexy mezi úrovněmi služby.
V opačném případě je kód aplikace použitý k vytvoření a naplnění indexu možností de facto obnovení, pokud index odstraníte omylem. Pokud chcete znovu vytvořit index, odstraňte ho (za předpokladu, že existuje), znovu vytvořte index ve službě a znovu načtěte data z primárního úložiště dat.