Kurz: Indexování velkých dat z Apache Sparku pomocí SynapseML a Azure AI Search
V tomto kurzu azure AI Search se dozvíte, jak indexovat a dotazovat velká data načtená z clusteru Spark. Nastavte poznámkový blok Jupyter, který provádí následující akce:
- Načtení různých formulářů (faktur) do datového rámce v relaci Apache Sparku
- Analyzujte je a zjistěte jejich funkce.
- Sestavení výsledného výstupu do tabulkové datové struktury
- Zápis výstupu do indexu vyhledávání hostovaného ve službě Azure AI Search
- Prozkoumání obsahu, který jste vytvořili, a dotazování na obsah, který jste vytvořili
Tento kurz využívá závislost na SynapseML, opensourcové knihovně, která podporuje masivně paralelní strojové učení nad velkými objemy dat. Ve službě SynapseML jsou indexování vyhledávání a strojové učení vystaveny prostřednictvím transformátorů , které provádějí specializované úlohy. Transformátory klepnou na širokou škálu funkcí umělé inteligence. V tomto cvičení použijte rozhraní API AzureSearchWriter k analýze a rozšiřování AI.
Přestože azure AI Search má nativní rozšiřování AI, v tomto kurzu se dozvíte, jak získat přístup k funkcím AI mimo Azure AI Search. Používáním SynapseML místo indexerů nebo dovedností nejste vystaveni omezením dat ani jiným omezením přidruženým k těmto objektům.
Tip
Podívejte se na krátké video této ukázky na adrese https://www.youtube.com/watch?v=iXnBLwp7f88. Video se v tomto kurzu rozšiřuje o další kroky a vizuály.
Požadavky
Potřebujete knihovnu synapseml a několik prostředků Azure. Pokud je to možné, použijte stejné předplatné a oblast pro prostředky Azure a vložte všechno do jedné skupiny prostředků, abyste mohli později provést jednoduché vyčištění. Následující odkazy jsou určené pro instalace portálu. Ukázková data se naimportují z veřejného webu.
- BalíčekSynapseML 1
- Azure AI Search (libovolná úroveň) 2
- Služby Azure AI (libovolná úroveň) 3
- Azure Databricks (libovolná úroveň) 4
1 Tento odkaz řeší kurz načítání balíčku.
2 K indexování ukázkových dat můžete použít bezplatnou vyhledávací vrstvu, ale pokud jsou objemy dat velké, zvolte vyšší úroveň . V případě fakturovatelných úrovní zadejte klíč rozhraní API pro vyhledávání v kroku Nastavení závislostí dále.
3 Tento kurz používá Azure AI Document Intelligence a Azure AI Translator. V následujících pokynech zadejte klíč více služeb a oblast. Stejný klíč funguje pro obě služby.
4 V tomto kurzu poskytuje Azure Databricks výpočetní platformu Spark. K nastavení pracovního prostoru jsme použili pokyny k portálu.
Poznámka:
Všechny výše uvedené prostředky Azure podporují funkce zabezpečení na platformě Microsoft Identity Platform. Pro zjednodušení tento kurz předpokládá ověřování na základě klíčů pomocí koncových bodů a klíčů zkopírovaných ze stránek portálu každé služby. Pokud tento pracovní postup implementujete v produkčním prostředí nebo sdílíte řešení s ostatními, nezapomeňte nahradit pevně zakódované klíče integrovaným zabezpečením nebo šifrovanými klíči.
Krok 1: Vytvoření clusteru Spark a poznámkového bloku
V této části vytvořte cluster, nainstalujte knihovnu synapseml a vytvořte poznámkový blok pro spuštění kódu.
Na webu Azure Portal vyhledejte pracovní prostor Azure Databricks a vyberte Spustit pracovní prostor.
V nabídce vlevo vyberte Compute.
Vyberte Vytvořit výpočetní prostředky.
Přijměte výchozí konfiguraci. Vytvoření clusteru trvá několik minut.
Nainstalujte knihovnu
synapsemlpo vytvoření clusteru:Na kartách v horní části stránky clusteru vyberte Knihovny .
Vyberte Nainstalovat nový.
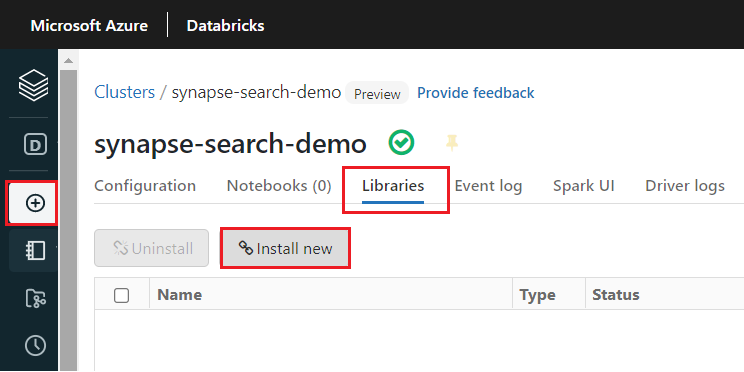
Vyberte Maven.
Do souřadnic zadejte
com.microsoft.azure:synapseml_2.12:1.0.4Vyberte volbu Instalovat.
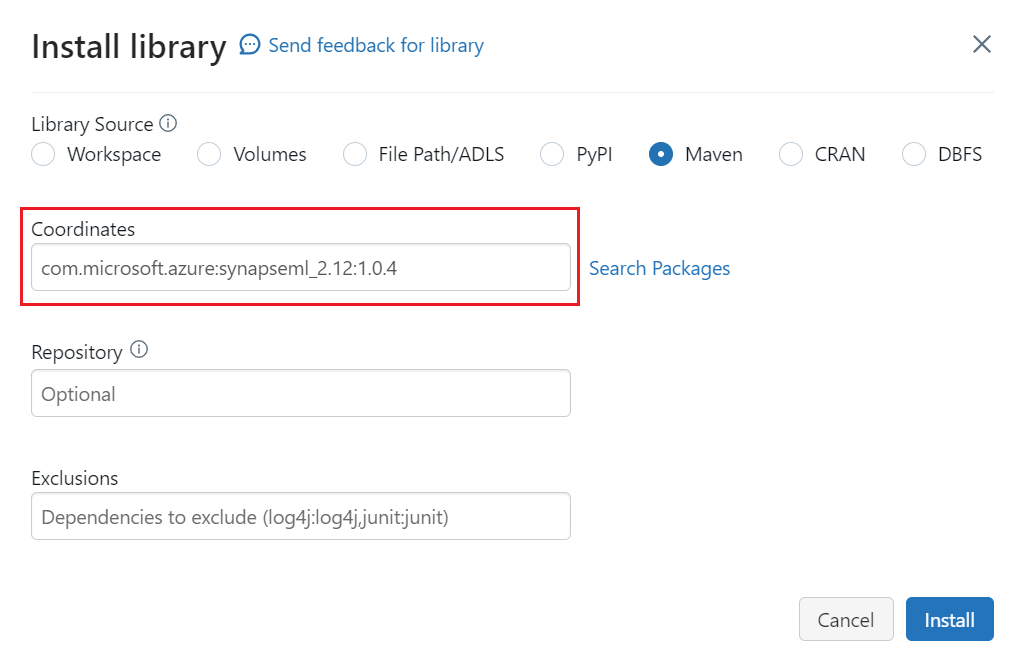
V nabídce vlevo vyberte Vytvořit>poznámkový blok.
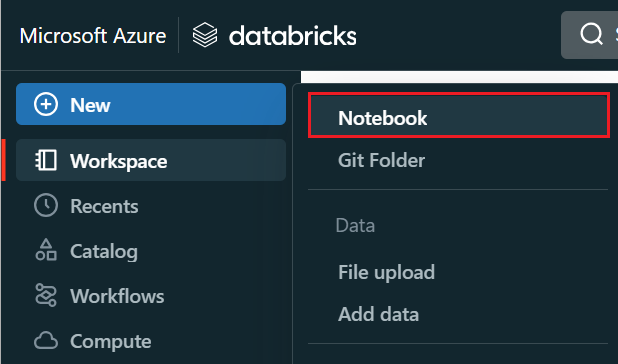
Pojmenujte poznámkový blok, vyberte Python jako výchozí jazyk a vyberte cluster, který má knihovnu
synapseml.Vytvořte sedm po sobě jdoucích buněk. Vložte kód do každého z nich.
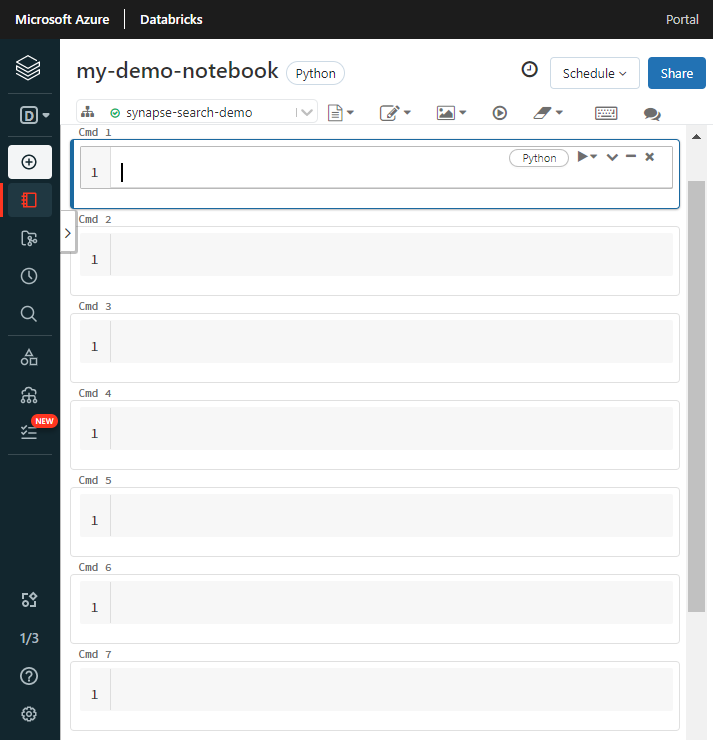
Krok 2: Nastavení závislostí
Do první buňky poznámkového bloku vložte následující kód.
Zástupné symboly nahraďte koncovými body a přístupovými klíči pro každý prostředek. Zadejte název nového indexu vyhledávání. Nejsou vyžadovány žádné další úpravy, takže kód spusťte, až budete připraveni.
Tento kód naimportuje více balíčků a nastaví přístup k prostředkům Azure používaným v tomto pracovním postupu.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Krok 3: Načtení dat do Sparku
Do druhé buňky vložte následující kód. Nevyžadují se žádné úpravy, takže kód spusťte, až budete připraveni.
Tento kód načte několik externích souborů z účtu úložiště Azure. Soubory jsou různé faktury a čtou se do datového rámce.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Krok 4: Přidání inteligentních informací o dokumentech
Do třetí buňky vložte následující kód. Nevyžadují se žádné úpravy, takže kód spusťte, až budete připraveni.
Tento kód načte transformátor AnalyzeInvoices a předá odkaz na datový rámec obsahující faktury. Volá předem vytvořený model faktury služby Azure AI Document Intelligence, který extrahuje informace z faktur.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
Výstup z tohoto kroku by měl vypadat podobně jako na dalším snímku obrazovky. Všimněte si, jak je analýza formulářů zabalená do hustě strukturovaného sloupce, se kterým je obtížné pracovat. Další transformace tento problém vyřeší parsováním sloupce na řádky a sloupce.
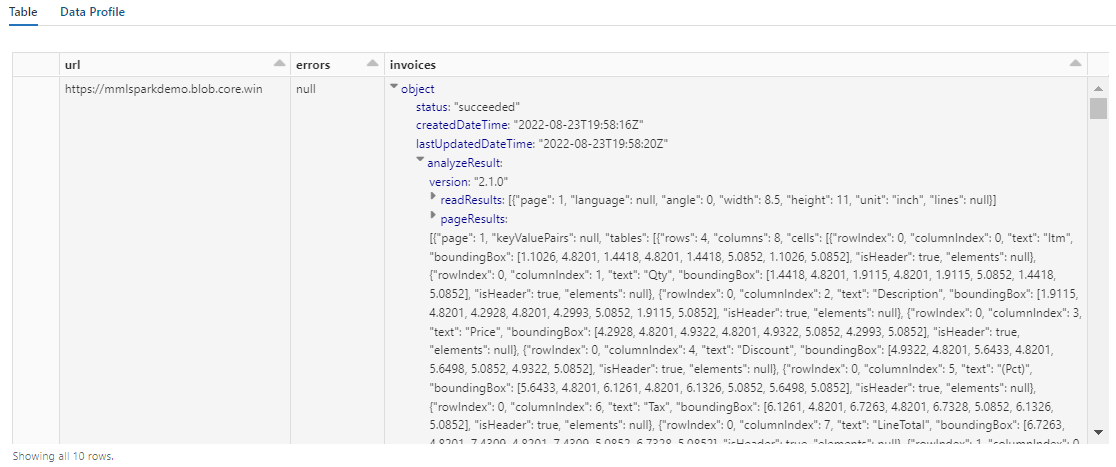
Krok 5: Změna struktury výstupu analýzy dokumentů
Do čtvrté buňky vložte následující kód a spusťte ho. Nejsou vyžadovány žádné změny.
Tento kód načte FormOntologyLearner, transformátor, který analyzuje výstup transformátorů Document Intelligence a odvodí tabulkovou datovou strukturu. Výstup funkce AnalyzeInvoices je dynamický a liší se v závislosti na funkcích zjištěných v obsahu. Transformátor navíc konsoliduje výstup do jednoho sloupce. Vzhledem k tomu, že výstup je dynamický a konsolidovaný, je obtížné ho použít v podřízených transformacích, které vyžadují větší strukturu.
FormOntologyLearner rozšiřuje nástroj AnalyzeInvoices transformer hledáním vzorů, které lze použít k vytvoření tabulkové datové struktury. Uspořádání výstupu do více sloupců a řádků zpřístupňuje obsah v jiných transformátorech, jako je AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Všimněte si, jak tato transformace přepracovává vnořená pole do tabulky, která umožňuje další dvě transformace. Tento snímek obrazovky je oříznut kvůli stručnosti. Pokud sledujete ve vlastním poznámkovém bloku, máte 19 sloupců a 26 řádků.
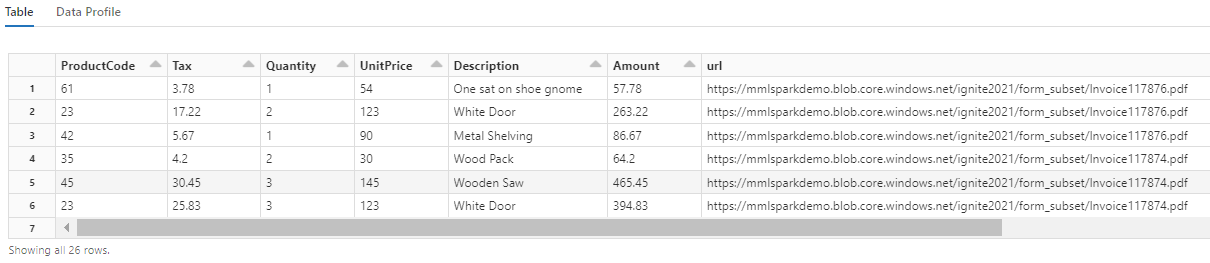
Krok 6: Přidání překladů
Do páté buňky vložte následující kód. Nevyžadují se žádné úpravy, takže kód spusťte, až budete připraveni.
Tento kód načte transformátor, který volá službu Azure AI Translator ve službách Azure AI. Původní text, který je v angličtině ve sloupci Popis, je strojově přeložen do různých jazyků. Veškerý výstup je konsolidovaný do pole output.translations.
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Tip
Pokud chcete zkontrolovat přeložené řetězce, posuňte se na konec řádků.
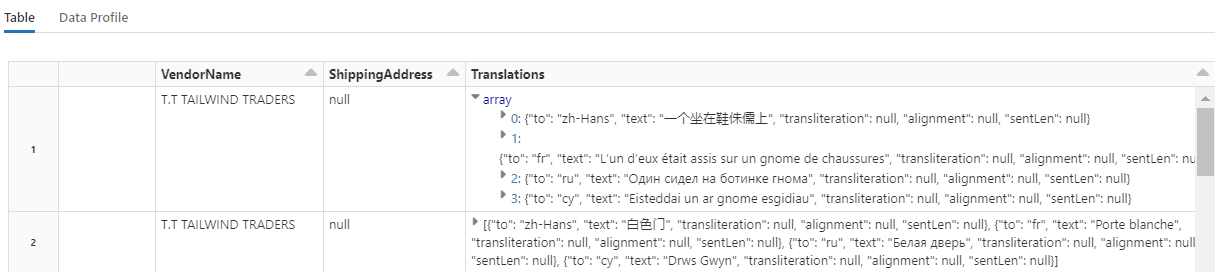
Krok 7: Přidání indexu vyhledávání pomocí AzureSearchWriter
Do šesté buňky vložte následující kód a spusťte ho. Nejsou vyžadovány žádné změny.
Tento kód načte AzureSearchWriter. Využívá tabulkovou datovou sadu a odvodí schéma indexu vyhledávání, které definuje jedno pole pro každý sloupec. Vzhledem k tomu, že struktura překladů je pole, je vyjádřena v indexu jako složitá kolekce s dílčími poli pro každý překlad jazyka. Vygenerovaný index má klíč dokumentu a používá výchozí hodnoty pro pole vytvořená pomocí rozhraní REST API pro vytvoření indexu.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Stránky vyhledávací služby můžete zkontrolovat na webu Azure Portal a prozkoumat definici indexu vytvořenou nástrojem AzureSearchWriter.
Poznámka:
Pokud nemůžete použít výchozí index vyhledávání, můžete zadat externí vlastní definici ve formátu JSON a předat jeho identifikátor URI jako řetězec ve vlastnosti "indexJson". Nejprve vygenerujte výchozí index, abyste věděli, která pole se mají zadat, a pokud potřebujete například konkrétní analyzátory, postupujte podle přizpůsobených vlastností.
Krok 8: Dotazování indexu
Do sedmé buňky vložte následující kód a spusťte ho. Nevyžadují se žádné úpravy, s tím rozdílem, že můžete chtít změnit syntaxi nebo vyzkoušet další příklady pro další prozkoumání obsahu:
Neexistuje žádný transformátor nebo modul, který vydává dotazy. Tato buňka je jednoduché volání rozhraní REST API pro vyhledávání dokumentů.
Tento konkrétní příklad hledá slovo "dveře" ("search": "door"). Vrátí také "počet" počtu odpovídajících dokumentů a pro výsledky vybere jenom obsah polí Popis a Překlady. Pokud chcete zobrazit úplný seznam polí, odeberte parametr "select".
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2020-06-30".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Následující snímek obrazovky ukazuje výstup buňky pro ukázkový skript.
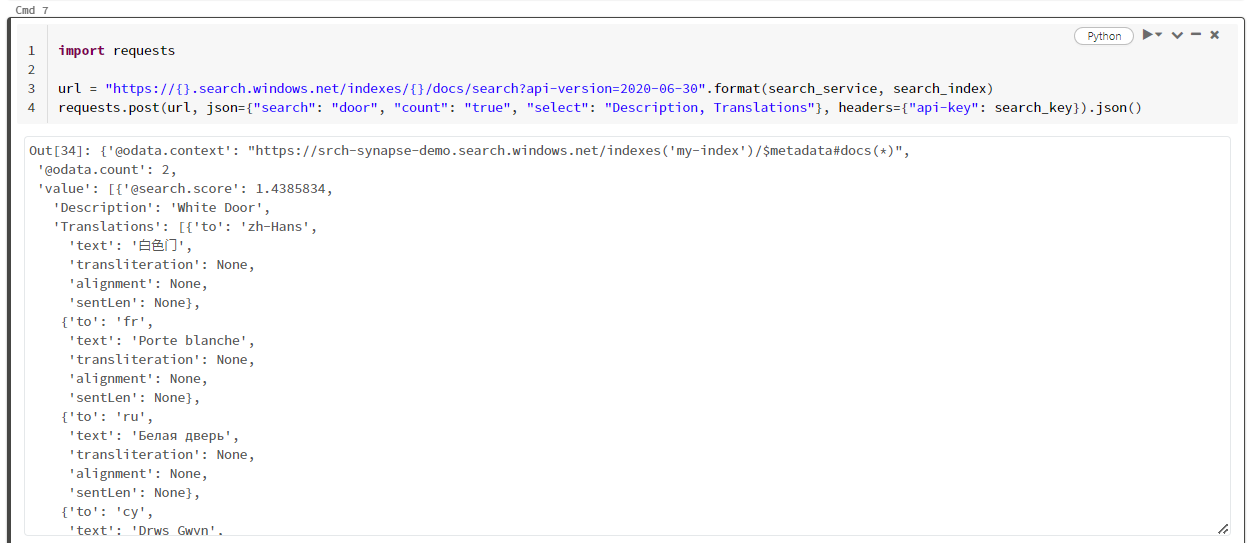
Vyčištění prostředků
Když pracujete ve vlastním předplatném, je na konci projektu vhodné odebrat prostředky, které už nepotřebujete. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na portálu pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Další kroky
V tomto kurzu jste se seznámili s transformátorem AzureSearchWriter v SynapseML, což je nový způsob vytváření a načítání indexů vyhledávání ve službě Azure AI Search. Transformátor přijímá jako vstup strukturovaný JSON. FormOntologyLearner může poskytnout potřebnou strukturu pro výstup vytvořený transformátory Document Intelligence v SynapseML.
V dalším kroku si projděte další kurzy SynapseML, které vytvářejí transformovaný obsah, který můžete prozkoumat prostřednictvím služby Azure AI Search: