Monitorování Azure Service Fabric
Tento článek popisuje:
- Typy dat monitorování, které můžete pro tuto službu shromažďovat.
- Způsoby analýzy dat
Poznámka:
Pokud už tuto službu nebo Azure Monitor znáte a chcete jenom vědět, jak analyzovat data monitorování, přečtěte si část Analyzovat na konci tohoto článku.
Pokud máte důležité aplikace a obchodní procesy, které spoléhají na prostředky Azure, musíte monitorovat a dostávat výstrahy pro váš systém. Služba Azure Monitor shromažďuje a agreguje metriky a protokoly ze všech komponent systému. Azure Monitor poskytuje přehled o dostupnosti, výkonu a odolnosti a upozorní vás na problémy. K nastavení a zobrazení dat monitorování můžete použít Azure Portal, PowerShell, Azure CLI, ROZHRANÍ REST API nebo klientské knihovny.
- Další informace o službě Azure Monitor najdete v přehledu služby Azure Monitor.
- Další informace o tom, jak obecně monitorovat prostředky Azure, najdete v tématu Monitorování prostředků Azure pomocí služby Azure Monitor.
Monitorování Azure Service Fabric
Azure Service Fabric má následující vrstvy, které můžete monitorovat:
- Monitorování aplikací: Aplikace, které běží na uzlech. Aplikace můžete monitorovat pomocí klíče Application Insights nebo sady SDK, EventStore nebo protokolování ASP.NET Core.
- Monitorování platformy (clusteru): Metriky klienta, protokoly a události pro uzly platformy nebo clusteru , včetně metrik kontejnerů. Metriky a protokoly se liší pro uzly Linuxu nebo Windows.
- Monitorování infrastruktury (výkonu): Stav služby a čítače výkonu pro infrastrukturu služeb.
Můžete monitorovat, jak se vaše aplikace používají, akce prováděné platformou Service Fabric, využití prostředků pomocí čítačů výkonu a celkový stav clusteru. Protokoly Azure Monitoru a Application Insights nabízejí integrovanou integraci se Service Fabric.
- Informace o osvědčených postupech najdete v tématu o osvědčených postupech monitorování a diagnostiky pro Azure Service Fabric.
- Kurz, který ukazuje, jak zobrazit události a sestavy stavu Service Fabric, dotazovat se na rozhraní API služby EventStore a monitorovat čítače výkonu, najdete v kurzu : Monitorování clusteru Service Fabric v Azure.
- Informace o konfiguraci protokolů služby Azure Monitor pro monitorování kontejnerů Windows orchestrovaných v Service Fabric najdete v tématu Kurz: Monitorování kontejnerů Windows ve službě Service Fabric pomocí protokolů služby Azure Monitor.
Service Fabric Explorer
Service Fabric Explorer, desktopová aplikace pro Windows, macOS a Linux, je opensourcový nástroj pro kontrolu a správu clusterů Azure Service Fabric. Pokud chcete povolit automatizaci, je možné provést všechny akce, které je možné provádět prostřednictvím Service Fabric Exploreru, také prostřednictvím PowerShellu nebo rozhraní REST API.
Monitorování aplikace
Monitorování aplikací sleduje, jak se používají funkce a součásti vaší aplikace. Chcete monitorovat aplikace, abyste měli jistotu, že se zachytily problémy, které mají dopad na uživatele. Odpovědnost za monitorování aplikací je na uživatelích, kteří vyvíjejí aplikaci a její služby, protože je jedinečná pro obchodní logiku vaší aplikace. Monitorování aplikací může být užitečné v následujících scénářích:
- Kolik provozu má moje aplikace? - Potřebujete škálovat služby tak, aby splňovaly požadavky uživatelů, nebo řešit potenciální kritický bod ve vaší aplikaci?
- Jsou moje volání mezi službami úspěšná a sledována?
- Jaké akce provádějí uživatelé aplikace? – Shromažďování telemetrie může vést k budoucímu vývoji funkcí a lepší diagnostice chyb aplikací.
- Vyvolává moje aplikace neošetřené výjimky?
- Co se děje ve službách spuštěných uvnitř kontejnerů?
Skvělou věcí o monitorování aplikací je, že vývojáři můžou používat libovolné nástroje a architekturu, které by chtěli, protože se nachází v kontextu vaší aplikace. Další informace o řešení Azure pro monitorování aplikací pomocí služby Azure Monitor Application Insights najdete v analýze událostí pomocí Application Insights.
Máme také kurz, jak ho nastavit pro aplikace .NET. V tomto kurzu se dozvíte, jak nainstalovat správné nástroje, příklad zápisu vlastní telemetrie do aplikace a zobrazení diagnostiky a telemetrie aplikací na webu Azure Portal.
Protokolování aplikací
Instrumentace kódu je nejen způsob, jak získat přehledy o uživatelích, ale také jediným způsobem, jak zjistit, jestli se v aplikaci něco nepovedlo, a diagnostikovat, co je potřeba opravit. I když je technicky možné připojit ladicí program k produkční službě, není to běžný postup. Proto je důležité mít podrobná data instrumentace.
Některé produkty váš kód automaticky instrumentuje. I když tato řešení můžou dobře fungovat, ruční instrumentace se téměř vždy vyžaduje, aby byla specifická pro vaši obchodní logiku. Na konci musíte mít dostatek informací pro forenzní ladění aplikace. Aplikace Service Fabric je možné instrumentovat pomocí libovolné architektury protokolování. Tato část popisuje několik různých přístupů k instrumentaci kódu a kdy zvolit jeden přístup přes jiný.
Application Insights SDK: Služba Application Insights nabízí bohatou integraci se Service Fabric. Uživatelé mohou přidat balíčky NuGet AI Service Fabric a přijímat data a protokoly vytvořené a shromážděné zobrazitelné na webu Azure Portal. Uživatelům se navíc doporučuje přidat vlastní telemetrii, aby mohli diagnostikovat a ladit své aplikace a sledovat, které služby a části aplikace se používají nejvíce. Třída TelemetryClient v sadě SDK poskytuje mnoho způsobů sledování telemetrie ve vašich aplikacích. Další informace najdete v tématu Analýza a vizualizace událostí pomocí Application Insights.
Podívejte se na příklad instrumentace a přidání Application Insights do vaší aplikace v našem kurzu pro monitorování a diagnostiku aplikace .NET.
EventSource: Při vytváření řešení Service Fabric ze šablony v sadě Visual Studio se vygeneruje odvozená třída EventSource (ServiceEventSource nebo ActorEventSource). Vytvoří se šablona, ve které můžete přidat události pro vaši aplikaci nebo službu. Název EventSource musí být jedinečný a měl by být přejmenován z výchozího řetězce šablony MyCompany-solution-project<><>. Pokud máte více definic EventSource , které používají stejný název, způsobuje problém za běhu. Každá definovaná událost musí mít jedinečný identifikátor. Pokud identifikátor není jedinečný, dojde k selhání modulu runtime. Některé organizace předem přiřaďte rozsahy hodnot identifikátorů, aby nedocházelo ke konfliktům mezi samostatnými vývojovými týmy. Další informace najdete na blogu společnosti Vance nebo v dokumentaci MSDN.
protokolování ASP.NET Core: Je důležité pečlivě naplánovat, jak budete instrumentovat kód. Správný plán instrumentace vám pomůže vyhnout se potenciálně nestabilitě základu kódu a pak potřebujete kód znovu vytvořit. Pokud chcete snížit riziko, můžete zvolit knihovnu instrumentace, jako je Microsoft.Extensions.Logging, která je součástí Microsoft ASP.NET Core. ASP.NET Core má rozhraní ILogger , které můžete použít s poskytovatelem podle vašeho výběru a zároveň minimalizovat vliv na existující kód. Kód můžete použít v ASP.NET Core ve Windows a Linuxu a v plném rozhraní .NET Framework, takže instrumentační kód je standardizovaný.
Příklady použití těchto návrhů najdete v tématu Přidání protokolování do aplikace Service Fabric.
Monitorování platformy (clusteru)
Uživatel má kontrolu nad tím, jaká telemetrie pochází ze své aplikace, protože uživatel zapíše samotný kód, ale co diagnostika z platformy Service Fabric? Jedním z cílů Service Fabric je zachování odolnosti aplikací vůči selhání hardwaru. Tento cíl se dosahuje schopností systémových služeb platformy zjišťovat problémy s infrastrukturou a rychle při selhání úloh do jiných uzlů v clusteru. Ale v tomto konkrétním případě, co když samotné systémové služby mají problémy? Nebo pokud se pokoušíte nasadit nebo přesunout úlohu, pravidla pro umístění služeb jsou porušena? Service Fabric poskytuje diagnostiku pro tyto a další funkce, abyste měli jistotu, že jste informováni o aktivitě, které probíhají ve vašem clusteru. Mezi ukázkové scénáře monitorování clusteru patří:
Další informace o monitorování platformy (clusteru) najdete v tématu Monitorování clusteru.
Události služby Service Fabric
Service Fabric poskytuje kompletní sadu diagnostických událostí, ke kterým máte přístup prostřednictvím EventStore nebo kanálu provozní události, který platforma zveřejňuje. Tyto události Service Fabric znázorňují akce prováděné platformou na různých entitách, jako jsou uzly, aplikace, služby a oddíly. Stejné události jsou k dispozici v clusterech s Windows i Linuxem.
Kanály událostí Service Fabric: Ve Windows jsou události Service Fabric dostupné od jednoho zprostředkovatele Trasování událostí pro Windows se sadou relevantních
logLevelKeywordFilterspro výběr mezi kanály Provozní a Data &Messaging. Tímto způsobem oddělujeme odchozí události Service Fabric tak, aby se podle potřeby filtrovaly. V Linuxu přicházejí události Service Fabric přes LTTng a umístí se do jedné tabulky Úložiště, odkud je můžete podle potřeby filtrovat. Tyto kanály obsahují kurátorované strukturované události, které je možné použít k lepšímu pochopení stavu clusteru. Diagnostika se ve výchozím nastavení povolí při vytváření clusteru, která vytvoří tabulku Azure Storage, ve které se události z těchto kanálů odesílají, abyste se mohli v budoucnu dotazovat.EventStore je funkce, která zobrazuje události platformy Service Fabric v Service Fabric Exploreru a programově prostřednictvím rozhraní REST API klientské knihovny Service Fabric. Můžete zobrazit zobrazení snímku toho, co se děje v clusteru pro každý uzel, službu a aplikaci, a dotazovat se na základě času události. Rozhraní API EventStore jsou k dispozici pouze pro clustery s Windows spuštěné v Azure. Na počítačích s Windows se tyto události předávají do protokolu událostí, takže se události Service Fabric zobrazí v Prohlížeč událostí.
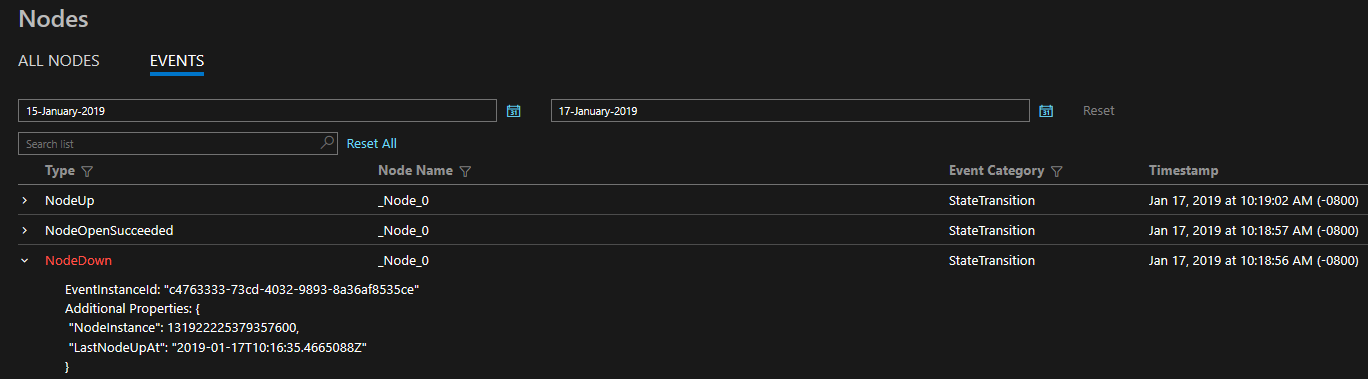
Poskytnutá diagnostika je ve formě komplexní sady událostí, které jsou k dispozici. Tyto události Service Fabric znázorňují akce prováděné platformou na různých entitách, jako jsou uzly, aplikace, služby, oddíly atd. V posledním scénáři výše by platforma vygenerovala NodeDown událost a nástroj pro monitorování by vás mohl informovat okamžitě. Mezi další běžné příklady patří převzetí ApplicationUpgradeRollbackStarted služeb při selhání nebo PartitionReconfigured během převzetí služeb při selhání. Stejné události jsou k dispozici v clusterech s Windows i Linuxem.
Události se odesílají prostřednictvím standardních kanálů ve Windows i Linuxu a mohou je číst jakýkoli monitorovací nástroj, který je podporuje. Řešení Azure Monitor je protokoly služby Azure Monitor. Můžete si přečíst další informace o integraci protokolů služby Azure Monitor, která zahrnuje vlastní provozní řídicí panel pro váš cluster a některé ukázkové dotazy, ze kterých můžete vytvářet upozornění. Další koncepty monitorování clusteru jsou k dispozici na úrovni událostí a generování protokolů na úrovni platformy.
Monitorování stavu
Platforma Service Fabric obsahuje model stavu, který poskytuje rozšiřitelné sestavy stavu pro stav entit v clusteru. Každý uzel, aplikace, služba, oddíl, replika nebo instance má nepřetržitě aktualizovatelný stav. Stav může být "OK", "Upozornění" nebo "Chyba". Události Service Fabric si můžete představit jako příkazy provedené clusterem pro různé entity a stav jako přídavná jména pro každou entitu. Pokaždé, když se stav konkrétní entity změní, událost se také vygeneruje. Tímto způsobem můžete nastavit dotazy a výstrahy pro události stavu ve zvoleném nástroji pro monitorování stejně jako jakoukoli jinou událost.
Kromě toho umožňujeme uživatelům přepsat stav entit. Pokud vaše aplikace prochází upgradem a dochází k selhání ověřovacích testů, můžete napsat do service Fabric Health pomocí rozhraní API pro stav, abyste označili, že vaše aplikace už není v pořádku, a Service Fabric automaticky vrátí upgrade zpět! Další informace o modelu stavu najdete v úvodu k monitorování stavu Service Fabric.
Kukátky
Obecně platí, že sledovací služba je samostatná služba, která sleduje stav a zatížení mezi službami, koncovými body ping a hlásí neočekávané události stavu v clusteru. To může pomoct zabránit chybám, které nemusí být zjištěny pouze na základě výkonu jedné služby. Watchdogs jsou také dobrým místem pro hostování kódu, který provádí nápravné akce, které nevyžadují interakci uživatele, například čištění souborů protokolu v úložišti v určitých časových intervalech. Pokud chcete plně implementovat opensourcovou službu SF watchdog, která zahrnuje snadno použitelný model rozšiřitelnosti watchdogu a který běží v clusterech s Windows i Linuxem, podívejte se na projekt FabricObserver . FabricObserver je software připravený pro produkční prostředí. Doporučujeme nasadit FabricObserver do testovacích a produkčních clusterů a rozšířit ho tak, aby vyhovoval vašim potřebám, a to buď prostřednictvím jeho modelu plug-in, nebo jeho forku a psaní vlastních integrovaných pozorovatelů. Doporučeným přístupem je bývalý (moduly plug-in).
Monitorování infrastruktury (výkonu)
Teď, když jsme probrali diagnostiku ve vaší aplikaci a platformě, jak víme, že hardware funguje podle očekávání? Monitorování základní infrastruktury je klíčovou součástí porozumění stavu clusteru a využití prostředků. Měření výkonu systému závisí na mnoha faktorech, které můžou být subjektivní v závislosti na vašich úlohách. Tyto faktory se obvykle měří prostřednictvím čítačů výkonu. Tyto čítače výkonu můžou pocházet z různých zdrojů, včetně operačního systému, rozhraní .NET Framework nebo samotné platformy Service Fabric. Některé scénáře, ve kterých by byly užitečné, jsou
- Využívám hardware efektivně? Chcete použít hardware na 90 % procesoru nebo 10 % procesoru. To je užitečné při škálování clusteru nebo optimalizaci procesů vaší aplikace.
- Můžu aktivně předpovídat problémy s infrastrukturou? – Mnoha problémům předchází náhlé změny (poklesy) výkonu, takže můžete použít čítače výkonu, jako jsou vstupně-výstupní operace a využití procesoru, k predikci a proaktivní diagnostice problémů.
Seznam čítačů výkonu, které by se měly shromažďovat na úrovni infrastruktury, najdete v metrikách výkonu.
Protokoly služby Azure Monitor se doporučují pro monitorování událostí na úrovni clusteru. Jakmile nakonfigurujete agenta Log Analytics s pracovním prostorem, můžete shromažďovat:
- Metriky výkonu, jako je využití procesoru.
- Čítače výkonu .NET, jako je využití procesoru na úrovni procesu.
- Čítače výkonu Service Fabric, jako je počet výjimek ze spolehlivé služby
- Metriky kontejnerů, jako je využití procesoru.
Typy zdrojů
Azure používá koncept typů prostředků a ID k identifikaci všeho v předplatném. Typy prostředků jsou také součástí ID prostředků pro každý prostředek spuštěný v Azure. Například jeden typ prostředku pro virtuální počítač je Microsoft.Compute/virtualMachines. Seznam služeb a jejich přidružených typů prostředků najdete v tématu Poskytovatelé prostředků.
Azure Monitor podobně organizuje základní data monitorování do metrik a protokolů na základě typů prostředků, označovaných také jako obory názvů. Různé metriky a protokoly jsou k dispozici pro různé typy prostředků. Vaše služba může být přidružená k více než jednomu typu prostředku.
Další informace o typech prostředků pro Azure Service Fabric najdete v referenčních informacích k datům monitorování Service Fabric.
Úložiště dat
Pro Azure Monitor:
- Data metrik se ukládají v databázi metrik služby Azure Monitor.
- Data protokolů se ukládají v úložišti protokolů služby Azure Monitor. Log Analytics je nástroj na webu Azure Portal, který se může dotazovat na toto úložiště.
- Protokol aktivit Azure je samostatné úložiště s vlastním rozhraním na webu Azure Portal.
Volitelně můžete směrovat data metriky a protokolu aktivit do úložiště protokolů služby Azure Monitor. Log Analytics pak můžete použít k dotazování na data a jejich korelaci s jinými daty protokolů.
Mnoho služeb může použít nastavení diagnostiky k odesílání metrik a dat protokolů do jiných umístění úložiště mimo Azure Monitor. Mezi příklady patří Azure Storage, hostované partnerské systémy a partnerské systémy mimo Azure pomocí služby Event Hubs.
Podrobné informace o tom, jak Azure Monitor ukládá data, najdete na datové platformě Azure Monitoru.
Metriky platformy Azure Monitoru
Azure Monitor poskytuje metriky platformy pro mnoho služeb. Seznam všech metrik, které je možné shromáždit pro všechny prostředky ve službě Azure Monitor, najdete v tématu Podporované metriky ve službě Azure Monitor.
Tato služba neshromažďuje metriky platformy.
Metriky založené na službě Azure Monitor
Tato služba poskytuje další metriky, které nejsou zahrnuté v databázi metrik služby Azure Monitor.
Metriky hostovaného operačního systému
Metriky hostovaného operačního systému (OS), který běží na uzlech clusteru Service Fabric, se musí shromažďovat prostřednictvím jednoho nebo více agentů, kteří běží v hostovaném operačním systému. Metriky hostovaného operačního systému zahrnují čítače výkonu, které sledují procento procesoru hosta nebo využití paměti, z nichž obě se často používají pro automatické škálování nebo upozorňování.
Osvědčeným postupem je použít a nakonfigurovat agenta Azure Monitoru tak, aby do databáze metrik Azure Monitoru odesílal metriky hostovaného operačního systému prostřednictvím vlastního rozhraní API metrik. Metriky hostovaného operačního systému můžete odesílat do protokolů služby Azure Monitor pomocí stejného agenta. Pak se na tyto metriky a protokoly můžete dotazovat pomocí Log Analytics.
Poznámka:
Agent Azure Monitor nahrazuje rozšíření Azure Diagnostics a agenta Log Analytics pro směrování hostovaného operačního systému. Další informace najdete v tématu Přehled agentů služby Azure Monitor.
Protokoly prostředků služby Azure Monitor
Protokoly prostředků poskytují přehled o operacích, které provedl prostředek Azure. Protokoly se generují automaticky, ale pokud je chcete uložit nebo dotazovat, musíte je směrovat do protokolů služby Azure Monitor. Protokoly jsou uspořádané do kategorií. Daný obor názvů může mít několik kategorií protokolu prostředků, které můžete shromažďovat.
Tato služba neshromažďuje protokoly prostředků, ale informace o nich najdete v monitorování dat z prostředků Azure.
Protokoly a události Service Fabric
Service Fabric může shromažďovat následující protokoly:
- U clusterů s Windows můžete nastavit monitorování clusteru pomocí diagnostického agenta a protokolů služby Azure Monitor.
- Pro clustery s Linuxem je také doporučeným nástrojem pro monitorování platformy a infrastruktury Azure Protokoly služby Azure Monitor. Diagnostika platformy Linux vyžaduje jinou konfiguraci. Další informace najdete v tématu Události clusteru Service Fabric s Linuxem v Syslogu.
- Agenta Azure Monitoru můžete nakonfigurovat tak, aby odesílal protokoly hostovaného operačního systému do protokolů služby Azure Monitor, kde se na ně můžete dotazovat pomocí Log Analytics.
- Protokoly kontejneru Service Fabric můžete zapisovat do stdoutu nebo stderru , aby byly dostupné v protokolech služby Azure Monitor.
- Můžete nastavit řešení monitorování kontejnerů pro protokoly služby Azure Monitor pro zobrazení událostí kontejneru.
Další řešení protokolování
I když tato dvě řešení doporučujeme, protokoly Azure Monitoru a Application Insights mají integrovanou integraci s Service Fabric, mnoho událostí se zapisuje prostřednictvím poskytovatelů Trasování událostí pro Windows a je rozšiřitelné s jinými řešeními protokolování. Měli byste se také podívat na Elastic Stack (zejména pokud zvažujete spuštění clusteru v offline prostředí), Dynatrace nebo jakoukoli jinou platformu, kterou dáváte přednost. Seznam integrovaných partnerů najdete v tématu Monitorovací partneři Azure Service Fabric.
Mezi klíčové body pro libovolnou platformu, kterou zvolíte, by měly patřit možnosti uživatelského rozhraní, možnosti dotazování, dostupné vlastní vizualizace a řídicí panely a další nástroje, které poskytují k vylepšení prostředí monitorování.
Protokol aktivit Azure
Protokol aktivit obsahuje události na úrovni předplatného, které sledují operace pro každý prostředek Azure, jak je vidět mimo tento prostředek; Například vytvoření nového prostředku nebo spuštění virtuálního počítače.
Shromažďování: Události protokolu aktivit se automaticky generují a shromažďují v samostatném úložišti pro zobrazení na webu Azure Portal.
Směrování: Data protokolu aktivit můžete odesílat do protokolů služby Azure Monitor, abyste je mohli analyzovat společně s dalšími daty protokolů. K dispozici jsou také jiná umístění, jako je Azure Storage, Azure Event Hubs a někteří monitorovací partneři Microsoftu. Další informace o směrování protokolu aktivit najdete v tématu Přehled protokolu aktivit Azure.
Analýza dat monitorování
Existuje mnoho nástrojů pro analýzu dat monitorování.
Nástroje služby Azure Monitor
Azure Monitor podporuje následující základní nástroje:
Průzkumník metrik, nástroj na webu Azure Portal, který umožňuje zobrazit a analyzovat metriky pro prostředky Azure. Další informace najdete v tématu Analýza metrik pomocí Průzkumníka metrik služby Azure Monitor.
Log Analytics, nástroj na webu Azure Portal, který umožňuje dotazovat a analyzovat data protokolů pomocí dotazovacího jazyka Kusto (KQL). Další informace najdete v tématu Začínáme s dotazy na protokoly ve službě Azure Monitor.
Protokol aktivit, který má uživatelské rozhraní na webu Azure Portal pro zobrazení a základní vyhledávání. Pokud chcete provádět podrobnější analýzu, musíte data směrovat do protokolů služby Azure Monitor a spouštět složitější dotazy v Log Analytics.
Mezi nástroje, které umožňují složitější vizualizaci, patří:
- Řídicí panely , které umožňují kombinovat různé druhy dat do jednoho podokna na webu Azure Portal.
- Sešity, přizpůsobitelné sestavy, které můžete vytvořit na webu Azure Portal. Sešity můžou obsahovat dotazy na text, metriky a protokoly.
- Grafana, otevřený nástroj platformy, který exceluje v provozních řídicích panelech Grafana umožňuje vytvářet řídicí panely, které obsahují data z více zdrojů, než je Azure Monitor.
- Power BI, služba obchodní analýzy, která poskytuje interaktivní vizualizace napříč různými zdroji dat. Power BI můžete nakonfigurovat tak, aby automaticky naimportovali data protokolů ze služby Azure Monitor, abyste mohli tyto vizualizace využívat.
Přehled běžných scénářů analýzy monitorování Service Fabric najdete v tématu Diagnostika běžných scénářů pomocí Service Fabric.
Nástroje pro export ve službě Azure Monitor
Data ze služby Azure Monitor můžete získat do jiných nástrojů pomocí následujících metod:
Metriky: Pomocí rozhraní REST API pro metriky extrahujte data metrik z databáze metrik služby Azure Monitor. Rozhraní API podporuje filtrovací výrazy pro upřesnění načtených dat. Další informace najdete v referenčních informacích k rozhraní REST API služby Azure Monitor.
Protokoly: Použijte rozhraní REST API nebo přidružené klientské knihovny.
Další možností je export dat pracovního prostoru.
Pokud chcete začít s rozhraním REST API pro Azure Monitor, přečtěte si průvodce rozhraním REST API pro monitorování Azure.
Dotazy Kusto
Data monitorování můžete analyzovat v protokolech služby Azure Monitor nebo v úložišti Log Analytics pomocí dotazovacího jazyka Kusto (KQL).
Důležité
Když na portálu vyberete protokoly z nabídky služby, otevře se Log Analytics s oborem dotazu nastaveným na aktuální službu. Tento obor znamená, že dotazy protokolu budou obsahovat pouze data z tohoto typu prostředku. Pokud chcete spustit dotaz, který obsahuje data z jiných služeb Azure, vyberte v nabídce Azure Monitor protokoly. Podrobnosti najdete v tématu Rozsah dotazů protokolu a časový rozsah ve službě Azure Monitor Log Analytics .
Seznam běžných dotazů pro libovolnou službu najdete v rozhraní dotazů Log Analytics.
Vzorové dotazy
Následující dotazy vrací události Service Fabric, včetně akcí na uzlech. Další užitečné dotazy najdete v tématu Události Service Fabric.
Vrácení provozních událostí zaznamenaných za poslední hodinu:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Vrácení zpráv o stavu se stavem HealthState == 3 (chyba) a extrahování dalších vlastností z EventMessage pole:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Získání provozních událostí Service Fabric agregovaných s konkrétní službou a uzlem:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Výstrahy
Upozornění služby Azure Monitor vás aktivně upozorňují, když se v datech monitorování nacházejí konkrétní podmínky. Upozornění umožňují identifikovat a řešit problémy ve vašem systému, než si je zákazníci všimnou. Další informace najdete v tématu Upozornění služby Azure Monitor.
Existuje mnoho zdrojů běžných upozornění pro prostředky Azure. Příklady běžných upozornění pro prostředky Azure najdete v tématu Ukázkové dotazy na upozornění protokolu. Web AMBA (Baseline Alerts) služby Azure Monitor poskytuje poloautomatickou metodu implementace důležitých upozornění, řídicích panelů a pokynů pro metriky platformy. Web se vztahuje na neustále se rozšiřující podmnožinu služeb Azure, včetně všech služeb, které jsou součástí cílové zóny Azure (ALZ).
Běžné schéma upozornění standardizuje spotřebu oznámení upozornění služby Azure Monitor. Další informace najdete v tématu Běžné schéma upozornění.
Typy výstrah
Na libovolnou metriku nebo zdroj dat protokolu na datové platformě azure Monitoru můžete upozornit. Existuje mnoho různých typů upozornění v závislosti na službách, které monitorujete, a na datech monitorování, která shromažďujete. Různé typy upozornění mají různé výhody a nevýhody. Další informace naleznete v tématu Volba správného typu upozornění monitorování.
Následující seznam popisuje typy upozornění služby Azure Monitor, které můžete vytvořit:
- Upozornění na metriky vyhodnocují metriky prostředků v pravidelných intervalech. Metriky můžou být metriky platformy, vlastní metriky, protokoly ze služby Azure Monitor převedené na metriky nebo metriky Application Insights. Upozornění na metriky můžou také použít více podmínek a dynamických prahových hodnot.
- Upozornění protokolu umožňují uživatelům použít dotaz Log Analytics k vyhodnocení protokolů prostředků s předdefinovanou frekvencí.
- Upozornění protokolu aktivit se aktivují, když dojde k nové události protokolu aktivit, která odpovídá definovaným podmínkám. Upozornění služby Resource Health a upozornění služby Service Health jsou upozornění protokolu aktivit, která hlásí stav služby a prostředku.
Některé služby Azure také podporují upozornění inteligentního zjišťování, výstrahy Prometheus nebo doporučená pravidla upozornění.
U některých služeb můžete monitorovat škálování použitím stejného pravidla upozornění na metriku u více prostředků stejného typu, které existují ve stejné oblasti Azure. Jednotlivá oznámení se odesílají pro každý monitorovaný prostředek. Podporované služby a cloudy Azure najdete v tématu Monitorování více prostředků pomocí jednoho pravidla upozornění.
Pravidla upozornění Service Fabric
Následující tabulka uvádí některá pravidla upozornění pro Service Fabric. Tyto výstrahy jsou jen příklady. Můžete nastavit upozornění na libovolnou metriku, položku protokolu nebo položku protokolu aktivit uvedenou v odkazu na data monitorování Service Fabric nebo seznam událostí Service Fabric.
| Typ upozornění | Podmínka | Popis |
|---|---|---|
| Událost uzlu | Uzel se zhasne | ServiceFabricOperationalEvent where EventID >= 25622 a EventID <= 25626. Tato ID událostí se nacházejí v referenčních informacích k událostem uzlu. |
| Událost aplikace | Vrácení zpět upgradu aplikace | ServiceFabricOperationalEvent where EventID == 29623 nebo EventID == 29624. Tato ID událostí se nacházejí v referenčních informacích k událostem aplikace. |
| Stav prostředků | Nedostupná nebo nedostupná služba upgradu | Cluster přejde do stavu UpgradeServiceUnreachable. |
Doporučení poradce
U některých služeb, pokud během operací prostředků dojde k kritickým nebo bezprostředním změnám, zobrazí se na stránce Přehled služby na portálu výstraha. Další informace a doporučené opravy výstrahy najdete v doporučeních Advisoru v části Monitorování v nabídce vlevo. Během normálních operací se nezobrazují žádná doporučení poradce.
Další informace o Azure Advisoru najdete v přehledu Azure Advisoru.
Doporučené nastavení
Teď, když jsme prošli jednotlivými oblastmi monitorování a ukázkových scénářů, najdete souhrn monitorovacích nástrojů Azure a nastavení potřebné k monitorování všech výše uvedených oblastí.
- Monitorování aplikací pomocí Application Insights
- Monitorování clusteru s využitím diagnostického agenta a protokolů služby Azure Monitor
- Monitorování infrastruktury pomocí protokolů služby Azure Monitor
Ukázkovou šablonu ARM můžete také použít a upravit, abyste automatizovali nasazení všech potřebných prostředků a agentů.
Související obsah
- Informace o metrikách, protokolech a dalších důležitých hodnotách vytvořených pro Service Fabric najdete v referenčních informacích k datům monitorování Service Fabric.
- Obecné podrobnosti o monitorování prostředků Azure najdete v tématu Monitorování prostředků Azure pomocí služby Azure Monitor .
- Podívejte se na seznam událostí Service Fabric.