Kurz: Monitorování clusteru Service Fabric v Azure
Monitorování a diagnostika jsou důležité pro vývoj, testování a nasazování úloh v jakémkoli cloudovém prostředí. Tento kurz je druhou částí série a ukazuje, jak monitorovat a diagnostikovat cluster Service Fabric pomocí událostí, čítačů výkonu a sestav stavu. Další informace najdete v přehledu monitorování clusteru a monitorování infrastruktury.
V tomto kurzu se naučíte:
- Zobrazení událostí Service Fabric
- Dotazování rozhraní API EventStore pro události clusteru
- Monitorování čítačů výkonu / shromažďování čítačů výkonu
- Zobrazení sestav stavu clusteru
V této sérii kurzů se naučíte:
- Vytvoření zabezpečeného clusteru s Windows v Azure pomocí šablony
- Monitorování clusteru
- Horizontální snížení nebo navýšení kapacity clusteru
- Upgrade modulu runtime clusteru
- Odstranění clusteru
Poznámka:
Při práci s Azure doporučujeme používat modul Azure Az PowerShellu. Pokud chcete začít, přečtěte si téma Instalace Azure PowerShellu. Informace o tom, jak migrovat na modul Az PowerShell, najdete v tématu Migrace Azure PowerShellu z AzureRM na Az.
Požadavky
Než začnete s tímto kurzem:
- Pokud ještě předplatné Azure nemáte, vytvořte si bezplatný účet.
- Nainstalujte Azure PowerShell nebo Azure CLI.
- Vytvoření zabezpečeného clusteru s Windows
- Nastavení diagnostické kolekce pro cluster
- Povolení služby EventStore v clusteru
- Konfigurace protokolů azure Monitoru a agenta Log Analytics pro cluster
Zobrazení událostí Service Fabric pomocí protokolů služby Azure Monitor
Protokoly Azure Monitoru shromažďují a analyzují telemetrická data z aplikací a služeb hostovaných v cloudu a poskytuje analytické nástroje, které vám pomůžou maximalizovat jejich dostupnost a výkon. Dotazy můžete spouštět v protokolech služby Azure Monitor, abyste získali přehledy a mohli řešit potíže s tím, co se děje ve vašem clusteru.
Pokud chcete získat přístup k řešení Service Fabric Analytics, přejděte na web Azure Portal a vyberte skupinu prostředků, ve které jste vytvořili řešení Service Fabric Analytics.
Vyberte prostředek ServiceFabric(mysfomsworkspace).
V přehledu uvidíte dlaždice ve formě grafu pro všechna povolená řešení, včetně těch pro Service Fabric. Kliknutím na graf Service Fabric pokračujte k řešení Service Fabric Analytics.
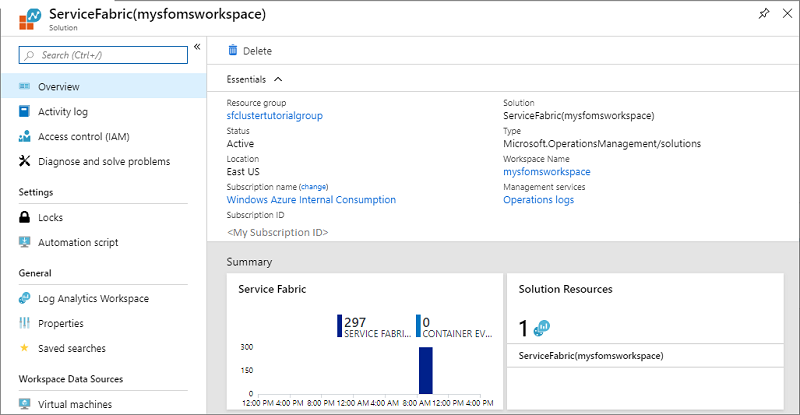
Následující obrázek znázorňuje domovskou stránku řešení Service Fabric Analytics. Tato domovská stránka poskytuje přehled o tom, co se děje v clusteru.
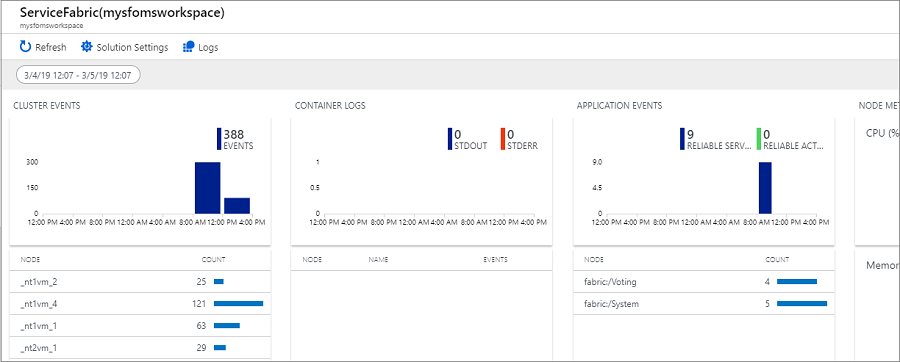
Pokud jste povolili diagnostiku při vytváření clusteru, můžete zobrazit události pro
- Události clusteru Service Fabric
- Události programovacího modelu Reliable Actors
- Události programovacího modelu Reliable Services
Poznámka:
Kromě zastaralých událostí Service Fabric je možné podrobnější systémové události shromažďovat aktualizací konfigurace vašeho rozšíření diagnostiky.
Zobrazení událostí Service Fabric, včetně akcí na uzlech
Na stránce Service Fabric Analytics klikněte na graf událostí clusteru. Zobrazí se protokoly pro všechny shromážděné systémové události. Pro referenci jsou z TABULKY WADServiceFabricSystemEventsTable v účtu Azure Storage a podobně spolehlivé služby a události herců, které vidíte dále, pocházejí z těchto příslušných tabulek.
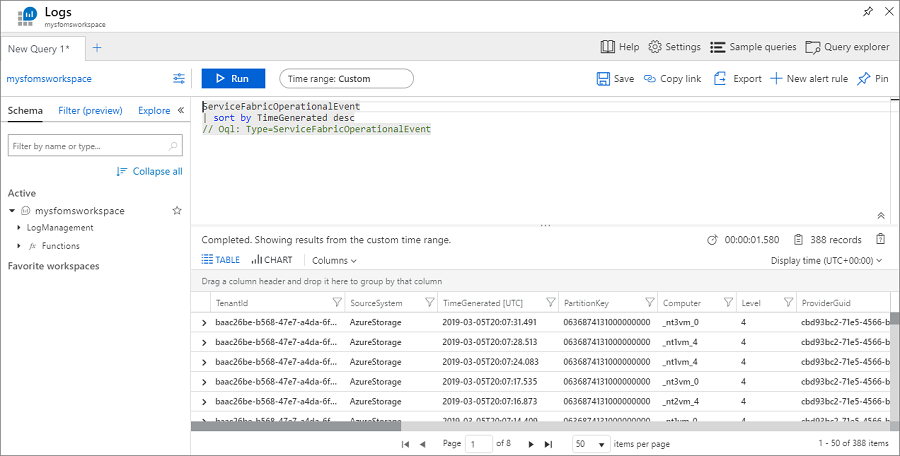
Dotaz používá dotazovací jazyk Kusto, který můžete upravit a upřesnit, co hledáte. Pokud například chcete najít všechny akce prováděné na uzlech v clusteru, můžete použít následující dotaz. ID událostí používaná níže najdete v referenčních informacích k událostem operačního kanálu.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Dotazovací jazyk Kusto je výkonný. Tady jsou některé další užitečné dotazy.
Vytvořte vyhledávací tabulku ServiceFabricEvent jako uživatelem definovanou funkci uložením dotazu jako funkce s aliasem ServiceFabricEvent:
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Vrácení provozních událostí zaznamenaných za poslední hodinu:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Vrácení provozních událostí s ID události == 18604 a EventName == 'NodeDownOperational':
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Vrácení provozních událostí s ID události == 18604 a EventName == 'NodeUpOperational':
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Vrátí zprávy o stavu se stavem HealthState == 3 (Chyba) a extrahuje další vlastnosti z pole EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Vrátí časový graf událostí s ID události != 17523:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Získání provozních událostí Service Fabric agregovaných s konkrétní službou a uzlem:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Vykreslujte počet událostí Service Fabric podle Id události / EventName pomocí dotazu mezi prostředky:
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Zobrazení událostí aplikace Service Fabric
Můžete zobrazit události pro spolehlivé služby a aplikace reliable actors nasazené v clusteru. Na stránce Service Fabric Analytics klikněte na graf událostí aplikace.
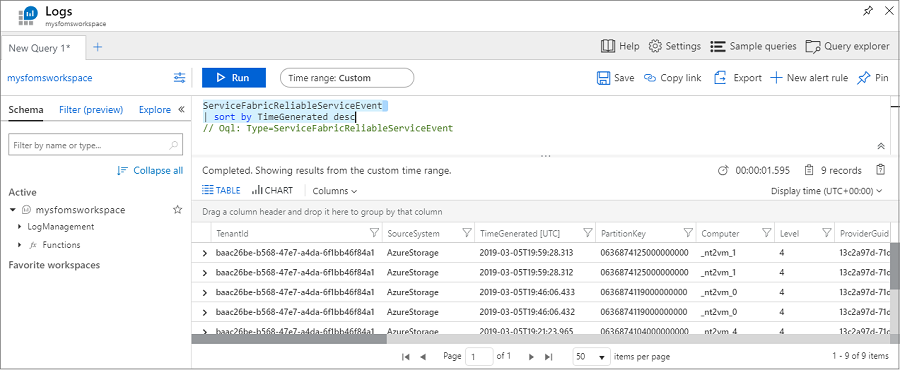
Spuštěním následujícího dotazu zobrazte události z aplikací spolehlivých služeb:
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Můžete vidět různé události, kdy je služba runasync spuštěna a dokončena, což se obvykle děje v nasazeních a upgradech.
Události pro spolehlivou službu můžete najít také pomocí serviceName == "fabric:/Watchdog/WatchdogService":
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Události spolehlivého objektu actor lze zobrazit podobným způsobem:
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Pokud chcete nakonfigurovat podrobnější události pro spolehlivé aktéry, můžete změnit scheduledTransferKeywordFilter konfiguraci rozšíření diagnostiky v šabloně clusteru. Podrobnostioch
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Zobrazení čítačů výkonu pomocí protokolů služby Azure Monitor
Pokud chcete zobrazit čítače výkonu, přejděte na Web Azure Portal a skupinu prostředků, ve které jste vytvořili řešení Service Fabric Analytics.
Vyberte prostředek ServiceFabric(mysfomsworkspace) a pak pracovní prostor služby Log Analytics a pak advanced Nastavení.
Klikněte na Data a potom na čítače výkonu systému Windows. Existuje seznam výchozích čítačů, které můžete povolit, a můžete také nastavit interval pro kolekci. Můžete také přidat další čítače výkonu , které chcete shromáždit. Na správný formát se odkazuje v tomto článku. Klepněte na tlačítko Uložit a klepněte na tlačítko OK.
Zavřete okno Upřesnit Nastavení a pod nadpisem Obecné vyberte Souhrn pracovního prostoru. Pro každé povolené řešení existuje grafická dlaždice, včetně dlaždice pro Service Fabric. Kliknutím na graf Service Fabric pokračujte k řešení Service Fabric Analytics.
K dispozici jsou grafické dlaždice pro provozní kanál a události spolehlivých služeb. Grafické znázornění toku dat pro vybrané čítače se zobrazí v části Metriky uzlu.
Pokud chcete zobrazit další podrobnosti, vyberte graf metriky kontejneru. Můžete také dotazovat na data čítače výkonu podobně jako události clusteru a filtrovat je na uzlech, název čítače výkonu a hodnoty pomocí dotazovacího jazyka Kusto.
Dotazování služby EventStore
Služba EventStore poskytuje způsob, jak porozumět stavu clusteru nebo úloh v daném okamžiku. EventStore je stavová služba Service Fabric, která udržuje události z clusteru. Události se zveřejňují prostřednictvím Service Fabric Exploreru, REST a rozhraní API. EventStore dotazuje cluster přímo na získání diagnostických dat na libovolnou entitu v clusteru. Pokud chcete zobrazit úplný seznam událostí dostupných v EventStore, podívejte se na události Service Fabric.
Rozhraní API EventStore je možné dotazovat programově pomocí klientské knihovny Service Fabric.
Tady je příklad požadavku na všechny události clusteru mezi 2018-04-03T18:00:00Z a 2018-04-04T18:00:00Z prostřednictvím funkce GetClusterEventListAsync.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Tady je další příklad, který se dotazuje na stav clusteru a všechny události uzlů v září 2018 a vytiskne je.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Monitorování stavu clusteru
Service Fabric zavádí model stavu s entitami stavu, na kterých můžou systémové komponenty a watchdogs hlásit místní podmínky, které monitorují. Úložiště stavu agreguje všechna data o stavu a určí, jestli jsou entity v pořádku.
Cluster se automaticky naplní sestavami stavu odesílanými systémovými komponentami. Další informace najdete v článku Použití sestav stavu systému k řešení potíží.
Service Fabric zveřejňuje dotazy na stav pro každý z podporovaných typů entit. K nim lze přistupovat prostřednictvím rozhraní API pomocí metod v Rutinách FabricClient.HealthManager, rutinách PowerShellu a REST. Tyto dotazy vrací úplné informace o stavu entity: agregovaný stav, události stavu entit, podřízené stavy (pokud je k dispozici), vyhodnocení, které není v pořádku, a podřízené statistiky stavu (pokud je to možné).
Získání stavu clusteru
Rutina Get-ServiceFabricClusterHealth vrátí stav entity clusteru a obsahuje stavy aplikací a uzlů (podřízené položky clusteru). Nejprve se připojte ke clusteru pomocí rutiny Připojení-ServiceFabricCluster.
Stav clusteru je 11 uzlů, systémová aplikace a prostředky infrastruktury:/Voting nakonfigurované podle popisu.
Následující příklad získá stav clusteru pomocí výchozích zásad stavu. 11 uzlů je v pořádku, ale agregovaný stav clusteru je Chyba, protože aplikace fabric:/Voting je chybná. Všimněte si, jak vyhodnocení, které není v pořádku, poskytují podrobnosti o podmínkách, které aktivovaly agregovaný stav.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
Následující příklad získá stav clusteru pomocí vlastních zásad aplikace. Filtruje výsledky, aby se při chybě nebo upozornění zobrazily jenom aplikace a uzly. V tomto příkladu se nevrátí žádné uzly, protože jsou všechny v pořádku. Filtr aplikací respektuje pouze aplikace fabric:/Voting. Vzhledem k tomu, že vlastní zásada určuje, že se mají upozornění považovat za chyby pro aplikaci fabric:/Voting, vyhodnotí se aplikace jako chybná, a proto se jedná o cluster.
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Získání stavu uzlu
Rutina Get-ServiceFabricNodeHealth vrátí stav entity uzlu a obsahuje události stavu hlášené na uzlu. Nejprve se připojte ke clusteru pomocí rutiny Připojení-ServiceFabricCluster. Následující příklad získá stav konkrétního uzlu pomocí výchozích zásad stavu:
Get-ServiceFabricNodeHealth _nt1vm_3
Následující příklad získá stav všech uzlů v clusteru:
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Získání stavu systémové služby
Získání agregovaného stavu systémových služeb:
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Další kroky
V tomto kurzu jste se naučili, jak:
- Zobrazení událostí Service Fabric
- Dotazování rozhraní API EventStore pro události clusteru
- Monitorování čítačů výkonu / shromažďování čítačů výkonu
- Zobrazení sestav stavu clusteru
V dalším kurzu se dozvíte, jak škálovat cluster.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro