Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Ověřování vstupu je technika, která slouží k ochraně hlavní logiky dotazu před poškozenými nebo neočekávanými událostmi. Dotaz se upgraduje tak, aby explicitně zpracovával a kontroloval záznamy, aby nemohl přerušit hlavní logiku.
K implementaci ověřování vstupu přidáme do dotazu dva počáteční kroky. Nejprve se ujistěte, že schéma odeslané do základní obchodní logiky odpovídá očekávání. Potom provedeme třídění výjimek a volitelně směrujeme neplatné záznamy do sekundárního výstupu.
Dotaz s ověřováním vstupu bude strukturovaný takto:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Pokud chcete zobrazit komplexní příklad dotazu nastaveného s ověřováním vstupu, přečtěte si část: Příklad dotazu s ověřováním vstupu.
Tento článek ukazuje, jak tuto techniku implementovat.
Kontext
Úlohy Azure Stream Analytics (ASA) zpracovávají data přicházející ze streamů. Toky jsou sekvence nezpracovaných dat přenášených serializovanými daty (CSV, JSON, AVRO...). Ke čtení ze streamu bude aplikace potřebovat znát konkrétní použitý formát serializace. V ASA musí být při konfiguraci vstupu streamování definován formát serializace událostí.
Jakmile jsou data deserializována, je potřeba použít schéma, aby to znamenalo. Podle schématu znamenáme seznam polí v datovém proudu a jejich odpovídající datové typy. U ASA nemusí být schéma příchozích dat nastaveno na úrovni vstupu. ASA místo toho podporuje nativně dynamická vstupní schémata . Očekává, že se změní seznam polí (sloupců) a jejich typů mezi událostmi (řádky). ASA také odvodí datové typy, pokud nejsou explicitně poskytnuty žádné, a v případě potřeby se pokusí implicitně přetypovat typy.
Dynamické zpracování schématu je výkonná funkce, která je klíčem ke zpracování datových proudů. Datové proudy často obsahují data z více zdrojů s více typy událostí, z nichž každý má jedinečné schéma. Aby bylo možné směrovat, filtrovat a zpracovávat události na takových datových proudech, musí ASA ingestovat všechny události bez ohledu na jejich schéma.
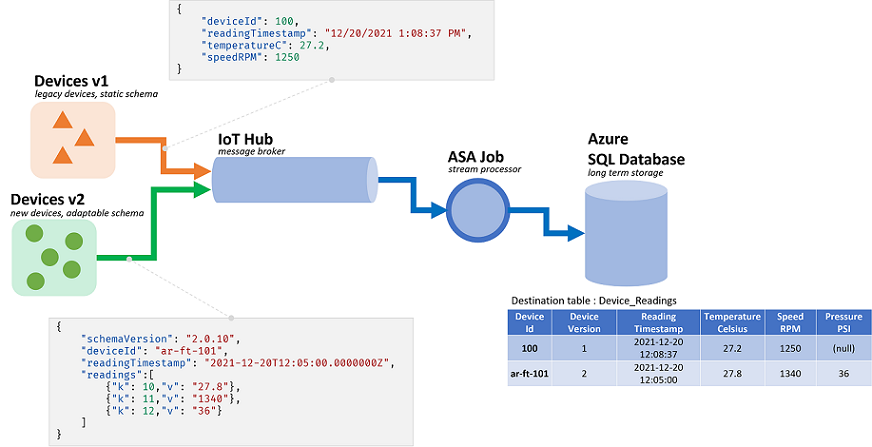
Možnosti nabízené dynamickým zpracováním schémat ale mají potenciální nevýhodu. Neočekávané události můžou protékat logikou hlavního dotazu a narušit je. Jako příklad můžeme použít funkci ROUND u pole typu NVARCHAR(MAX). ASA implicitně přetypuje plovoucí, aby odpovídala podpisu ROUND. Tady očekáváme nebo doufáme, že toto pole bude vždy obsahovat číselné hodnoty. Ale když obdržíme událost s polem nastaveným na "NaN", nebo pokud pole zcela chybí, může úloha selhat.
Při ověřování vstupu přidáme do dotazu předběžné kroky pro zpracování takových poškozených událostí. K implementaci použijeme především WITH a TRY_CAST .
Scénář: Ověřování vstupu pro nespolehlivé producenty událostí
Vytvoříme novou úlohu ASA, která bude ingestovat data z jednoho centra událostí. Jak je tomu nejčastěji, nejsme zodpovědní za producenty dat. Producenti jsou zařízení IoT prodaná několika dodavateli hardwaru.
Se zúčastněnými stranami se shodujeme s formátem serializace a schématem. Všechna zařízení budou tyto zprávy odesílat do společného centra událostí, vstup úlohy ASA.
Kontrakt schématu je definován takto:
| Název pole | Typ pole | Popis pole |
|---|---|---|
deviceId |
Celé číslo | Jedinečný identifikátor zařízení |
readingTimestamp |
Datum a čas | Čas zprávy vygenerovaný centrální bránou |
readingStr |
String | |
readingNum |
Číslo | |
readingArray |
Pole řetězce |
To pak dává následující ukázkovou zprávu v rámci serializace JSON:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Už vidíme nesrovnalosti mezi kontraktem schématu a jeho implementací. Ve formátu JSON neexistuje žádný datový typ data a času. Bude přenášen jako řetězec (viz výše readingTimestamp ). ASA může problém snadno vyřešit, ale ukazuje potřebu ověřovat a explicitně přetypovat typy. Tím více pro data serializovaná ve sdíleném svazku clusteru, protože všechny hodnoty se pak přenesou jako řetězec.
Došlo k dalším nesrovnalostem. ASA používá vlastní systém typů, který neodpovídá příchozímu systému . Pokud má ASA předdefinované typy pro celé číslo (bigint), datetime, řetězec (nvarchar(max)) a pole, podporuje pouze číselnou hodnotu prostřednictvím float. Tato neshoda není problém u většiny aplikací. Ale v některých hraničních případech by to mohlo způsobit mírné odchylky přesnosti. V tomto případě bychom číselnou hodnotu převedli jako řetězec v novém poli. Potom bychom použili systém, který podporuje pevné desetinné číslo, abychom zjistili a opravili potenciální posuny.
Vraťte se k našemu dotazu, tady máme v úmyslu:
- Předání
readingStrdo uživatelem definovaného kódu JavaScriptu - Spočítat počet záznamů v poli
- Zaokrouhlení
readingNumna druhé desetinné místo - Vložení dat do tabulky SQL
Cílová tabulka SQL má následující schéma:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Je vhodné namapovat, co se stane s každým polem při procházení úlohou:
| Pole | Vstup (JSON) | Zděděný typ (ASA) | Výstup (Azure SQL) | Komentář |
|---|---|---|---|---|
deviceId |
Číslo | bigint | integer | |
readingTimestamp |
string | nvarchar(MAX) | datetime2 | |
readingStr |
string | nvarchar(MAX) | nvarchar(200) | používané uživatelem definované uživatelem |
readingNum |
Číslo | float (číslo s plovoucí řádovou čárkou) | decimal(18;2) | zaokrouhlit |
readingArray |
array(řetězec) | pole nvarchar(MAX) | integer | počítáno |
Požadavky
Dotaz budeme vyvíjet v editoru Visual Studio Code pomocí rozšíření ASA Tools . První kroky tohoto kurzu vás provedou instalací požadovaných komponent.
V editoru VS Code použijeme místní spuštění s místním vstupem a výstupem, aby se neúčtovaly žádné náklady, a urychlili jsme ladicí smyčku. Nebudeme muset nastavit centrum událostí ani Azure SQL Database.
Základní dotaz
Začněme základní implementací bez ověření vstupu. Přidáme ho v další části.
Ve VS Code vytvoříme nový projekt ASA.
input Ve složce vytvoříme nový soubor JSON s názvem data_readings.json a přidáme do ní následující záznamy:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Pak nadefinujeme místní vstup s názvem readings, který odkazuje na soubor JSON, který jsme vytvořili výše.
Po nakonfigurování by měl vypadat takto:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Při zobrazení náhledu dat můžeme pozorovat, že se záznamy správně načítají.
Vytvoříme novou uživatelem definovanou uživatelem JavaScriptu , kterou zavoláme udfLen tak, že klikneme pravým tlačítkem myši na Functions složku a vybereme ASA: Add Function. Kód, který použijeme, je:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
V místních spuštěních nemusíme definovat výstupy. Ani nemusíme používat INTO , pokud není více než jeden výstup. .asaql V souboru můžeme existující dotaz nahradit:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Pojďme rychle projít dotaz, který jsme odeslali:
- Abychom mohli spočítat počet záznamů v jednotlivých polích, musíme je napřed rozbalit. Použijeme CROSS APPLY a GetArrayElements() (další ukázky zde).
- Tím v dotazu zobrazíme dvě datové sady: původní vstup a maticové hodnoty. Abychom se ujistili, že pole nekombinujeme, definujeme aliasy (
AS r) a použijeme je všude. - Abychom pak mohli hodnoty pole skutečně
COUNTagregovat pomocí funkce GROUP BY, musíme je agregovat. - Pro to musíme definovat časové období. Vzhledem k tomu, že pro naši logiku ho nepotřebujeme, je okno snímku správnou volbou.
- Tím v dotazu zobrazíme dvě datové sady: původní vstup a maticové hodnoty. Abychom se ujistili, že pole nekombinujeme, definujeme aliasy (
- Musíme také mít všechna pole a promítat
GROUP BYje všechny doSELECT. Explicitní promítání polí je dobrým postupem, protožeSELECT *chyby procházejí ze vstupu do výstupu.- Pokud definujeme časové okno, můžeme definovat časové razítko pomocí timesTAMP BY. Tady není potřeba, aby naše logika fungovala. U místních spuštění se bez
TIMESTAMP BYvšech záznamů načtou do jednoho časového razítka čas spuštění.
- Pokud definujeme časové okno, můžeme definovat časové razítko pomocí timesTAMP BY. Tady není potřeba, aby naše logika fungovala. U místních spuštění se bez
- Funkci definovanou uživatelem používáme k filtrování čtení, u kterých
readingStrje méně než dva znaky. Měli jsme tady použít LEN . K demonstračnímu účelu používáme funkci definovanou uživatelem.
Můžeme spustit spuštění a sledovat zpracovávaná data:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00 | Řetězec | 1.71 | 2 |
| 2 | 2021-12-10T10:01:00 | Jiný řetězec | 2.38 | 1 |
| 3 | 2021-12-10T10:01:20 | Třetí řetězec | -4.85 | 3 |
| 0 | 2021-12-10T10:02:10 | A Forth String | 1.21 | 2 |
Když teď víme, že náš dotaz funguje, otestujeme ho na více datech. Pojďme obsah nahradit data_readings.json následujícími záznamy:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Tady vidíme následující problémy:
- Zařízení č. 1 udělalo všechno správně
- Zařízení č. 2 zapomnělo zahrnout
readingStr - Zařízení č. 3 odesláno
NaNjako číslo - Zařízení č. 4 odeslalo prázdný záznam místo pole.
Spuštění úlohy by teď nemělo končit dobře. Zobrazí se jedna z následujících chybových zpráv:
Zařízení 2 nám poskytne:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
Zařízení 3 nám poskytne:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
Zařízení 4 nám poskytne:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Při každém chybném záznamu bylo povoleno tok ze vstupu do hlavní logiky dotazu bez ověření. Teď si uvědomujeme hodnotu ověření vstupu.
Implementace ověřování vstupu
Pojďme náš dotaz rozšířit, abychom ověřili vstup.
Prvním krokem ověření vstupu je definování očekávání schémat základní obchodní logiky. Když se podíváme na původní požadavek, naší hlavní logikou je:
- Předání
readingStrdo uživatelem definovaného kódu JavaScriptu pro měření jeho délky - Spočítat počet záznamů v poli
- Zaokrouhlení
readingNumna druhé desetinné místo - Vložení dat do tabulky SQL
Pro každý bod můžeme uvést očekávání:
- Funkce definovaná uživatelem vyžaduje argument typu string (nvarchar(max) zde), který nemůže mít hodnotu null.
GetArrayElements()vyžaduje argument typu matice nebo hodnotu null.Roundvyžaduje argument typu bigint nebo float nebo hodnotu null.- Místo toho, abychom se museli spoléhat na implicitní přetypování ASA, měli bychom to udělat sami a zpracovávat konflikty typů v dotazu.
Jedním ze způsobů, jak přejít, je přizpůsobit hlavní logiku pro řešení těchto výjimek. V tomto případě ale věříme, že naše hlavní logika je dokonalá. Pojďme tedy místo toho ověřit příchozí data.
Nejprve pomocí funkce WITH přidáme vstupní ověřovací vrstvu jako první krok dotazu. Pomocí TRY_CAST převedeme pole na očekávaný typ a nastavíme je, NULL pokud převod selže:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
S posledním vstupním souborem, který jsme použili (ten s chybami), tento dotaz vrátí následující sadu:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00 | Řetězec | 1.7145 | ["A","B"] | 0 | 2021-12-10T10:00:00.0000000Z | Řetězec | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Třetí řetězec | Nan | ["D","E","F"] | 3 | 2021-12-10T10:01:20.0000000Z | Třetí řetězec | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | A Forth String | 1.2126 | {} | 4 | 2021-12-10T10:02:10.000000Z | A Forth String | 1.2126 | NULL |
Už vidíme, že se řeší dvě chyby. Změnili NaN jsme a {} do NULL. Teď jsme si jisti, že se tyto záznamy správně vloží do cílové tabulky SQL.
Teď se musíme rozhodnout, jak řešit záznamy s chybějícími nebo neplatnými hodnotami. Po nějaké diskusi se rozhodneme odmítnout záznamy s prázdným nebo neplatným readingArray nebo chybějícím readingStr.
Proto přidáme druhou vrstvu, která bude záznamy pro třídění mezi ověřovací vrstvou a hlavní logikou:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Je vhodné napsat jednu WHERE klauzuli pro oba výstupy a použít NOT (...) ji ve druhém. Tímto způsobem nelze vyloučit žádné záznamy z výstupů i ztrát.
Teď získáme dva výstupy. Debug1 obsahuje záznamy, které se odešlou do hlavní logiky:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00.0000000Z | Řetězec | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Třetí řetězec | NULL | ["D","E","F"] |
Debug2 obsahuje záznamy, které budou odmítnuty:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | A Forth String | 1.2126 | {} | 4 | 2021-12-10T10:02:10.000000Z | A Forth String | 1.2126 | NULL |
Posledním krokem je přidání hlavní logiky zpět. Přidáme také výstup, který shromažďuje zamítnutí. Tady je nejlepší použít výstupní adaptér, který nevynucuje silné psaní, jako je účet úložiště.
Úplný dotaz najdete v poslední části.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
To nám poskytne následující sadu pro SQLOutput bez možné chyby:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00.0000000Z | Řetězec | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Třetí řetězec | NULL | 3 |
Další dva záznamy se posílají do objektu BlobOutput pro lidské zpracování a následné zpracování. Náš dotaz je teď bezpečný.
Příklad dotazu s ověřováním vstupu
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Rozšíření ověřování vstupu
GetType lze použít k explicitní kontrole typu. Funguje dobře s CASE v projekci nebo WHERE na nastavené úrovni. GetType lze také použít k dynamické kontrole příchozího schématu v úložišti metadat. Úložiště lze načíst prostřednictvím referenční datové sady.
Testování jednotek je dobrým postupem, jak zajistit odolnost našeho dotazu. Vytvoříme řadu testů, které se skládají ze vstupních souborů a jejich očekávaného výstupu. Náš dotaz bude muset odpovídat výstupu, který vygeneruje, aby se předal. V ASA se testování jednotek provádí prostřednictvím modulu npm asa-streamanalytics-cicd . Testovací případy s různými poškozenými událostmi by se měly vytvořit a otestovat v kanálu nasazení.
Nakonec můžeme provést testování light integrace ve VS Code. Záznamy můžeme do tabulky SQL vložit prostřednictvím místního spuštění do živého výstupu.
Získání podpory
Pokud potřebujete další pomoc, vyzkoušejte naši stránku pro otázky Microsoftu pro Azure Stream Analytics.
Další kroky
- Nastavení kanálů CI/CD a testování jednotek pomocí balíčku npm
- Přehled místních spuštění Stream Analytics v editoru Visual Studio Code pomocí nástrojů ASA
- Místní testování dotazů Stream Analytics s ukázkovými daty pomocí editoru Visual Studio Code
- Místní testování dotazů Stream Analytics na vstupu živého streamu pomocí editoru Visual Studio Code
- Prozkoumání úloh Azure Stream Analytics pomocí editoru Visual Studio Code (Preview)