Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Apache Spark je architektura pro paralelní zpracování, která podporuje zpracování v paměti pro zvýšení výkonu aplikací pro analýzu velkých objemů dat. Apache Spark ve službě Azure Synapse Analytics je jednou z implementací Apache Sparku v cloudu od Microsoftu. Azure Synapse usnadňuje vytváření a konfiguraci bezserverových fondů úloh Apache Sparku v Azure. Fondy úloh Sparku ve službě Azure Synapse jsou kompatibilní se službami Azure Storage a Azure Data Lake Storage Gen2. Fondy úloh Sparku tak můžete použít ke zpracování dat uložených v Azure.
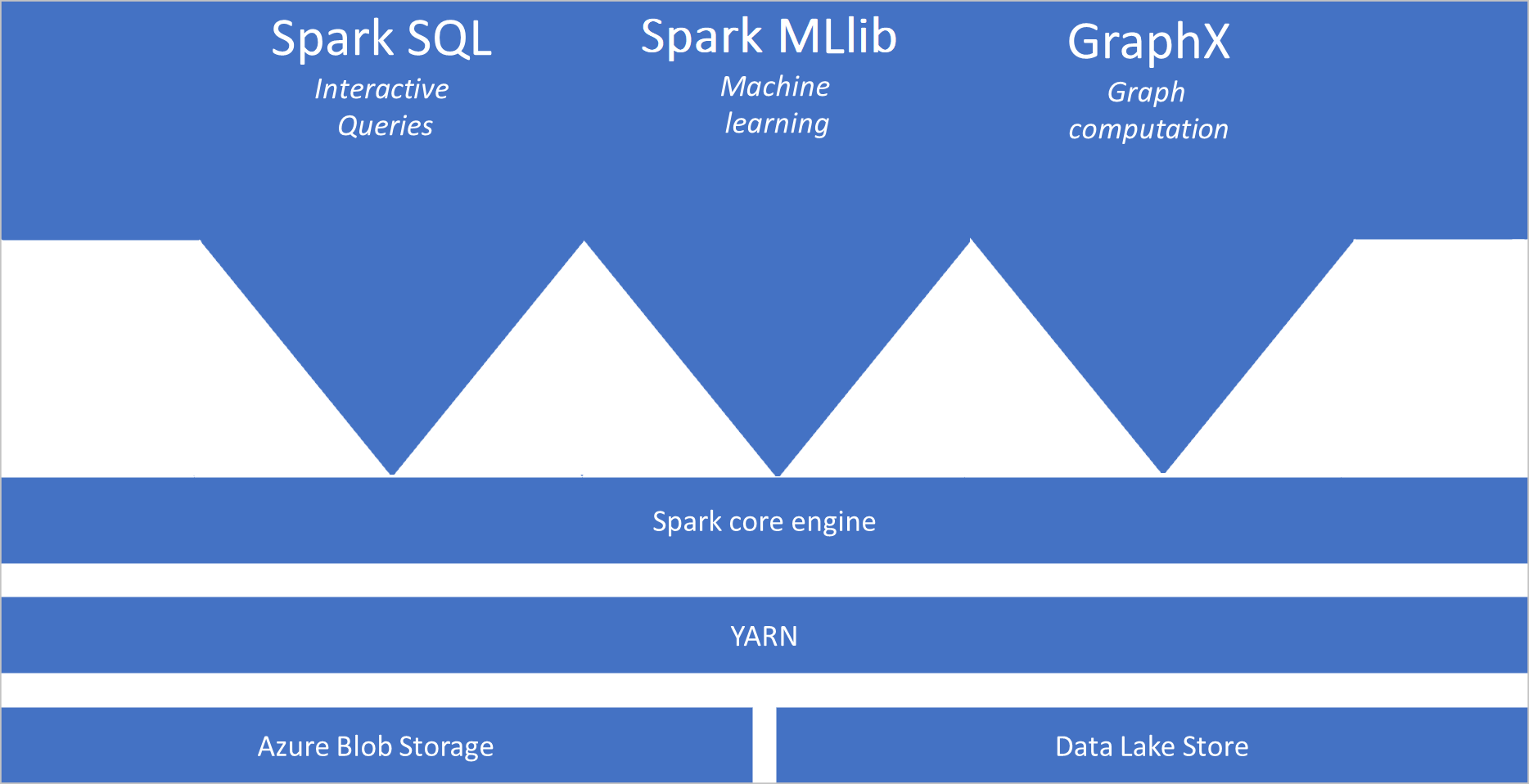
Co je Apache Spark
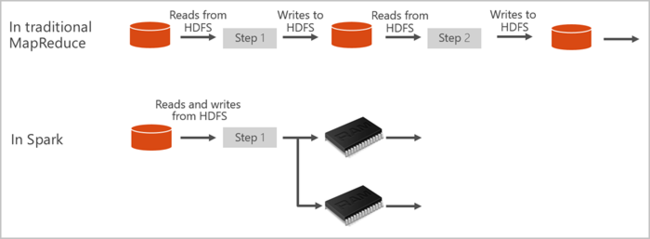
Apache Spark poskytuje primitiva pro clusterové výpočty v paměti. Úloha Sparku dokáže data načíst a uložit je do mezipaměti a opakovaně se na ně dotazovat. Výpočetní prostředí v paměti je rychlejší než aplikace založené na disku. Spark se také integruje s několika programovacími jazyky a díky tomu umožňuje pracovat s distribuovanými datovými sadami stejně jako s místními kolekcemi. Není nutné strukturovat všechno jako mapovací a redukční operace. Další informace najdete ve videu Apache Spark pro Synapse.
Fondy Sparku ve službě Azure Synapse nabízejí plně spravovanou službu Spark. Tady jsou uvedené výhody vytvoření fondu Sparku ve službě Azure Synapse Analytics.
| Funkce | Popis |
|---|---|
| Rychlost a efektivita | Instance Sparku se spouští přibližně za 2 minuty pro méně než 60 uzlů a přibližně 5 minut pro více než 60 uzlů. Instance se ve výchozím nastavení vypne 5 minut po posledním spuštění úlohy, pokud není udržována naživu připojením poznámkového bloku. |
| Snadné vytvoření | Nový fond Sparku v Azure Synapse můžete vytvořit v řádu minut pomocí webu Azure Portal, Azure PowerShellu nebo sady .NET SDK služby Synapse Analytics. Viz Začínáme s fondy Sparku ve službě Azure Synapse Analytics. |
| Jednoduché používání | Synapse Analytics obsahuje vlastní poznámkový blok odvozený z nteractu. Tyto poznámkové bloky můžete použít pro interaktivní zpracování dat a vizualizaci. |
| Rozhraní REST API | Spark ve službě Azure Synapse Analytics zahrnuje Apache Livy, server úloh Spark založený na rozhraní REST API pro vzdálené odesílání a monitorování úloh. |
| Podpora pro Azure Data Lake Storage Generation 2 | Fondy Sparku ve službě Azure Synapse můžou používat Azure Data Lake Storage Generation 2 a BLOB Storage. Další informace o službě Data Lake Storage najdete v tématu Přehled služby Azure Data Lake Storage. |
| Integrace v prostředí IDE třetích stran | Azure Synapse poskytuje modul plug-in IDE pro IntelliJ IDEA JetBrains, který je užitečný k vytváření a odesílání aplikací do fondu Spark. |
| Předem načtené knihovny Anaconda | Fondy Sparku ve službě Azure Synapse jsou předinstalované s knihovnami Anaconda. Anaconda poskytuje téměř 200 knihoven pro strojové učení, analýzu dat, vizualizaci a další technologie. |
| Škálovatelnost | Apache Spark ve fondech Azure Synapse může mít povolené automatické škálování, aby se fondy škálovaly přidáním nebo odebráním uzlů podle potřeby. Fondy Sparku se také dají vypnout bez ztráty dat, protože všechna data jsou uložená v Azure Storage nebo Data Lake Storage. |
Fondy Sparku ve službě Azure Synapse zahrnují následující komponenty, které jsou ve fondech ve výchozím nastavení dostupné:
- Spark Core. Obsahuje Spark Core, Spark SQL, GraphX a MLlib.
- Anaconda
- Apache Livy
- Poznámkový blok nteract
Architektura fondu Sparku
Aplikace Spark běží ve fondu jako nezávislé sady procesů, které jsou koordinované objektem SparkContext v hlavním programu, označované jako program ovladače.
Může SparkContext se připojit ke správci clusteru, který přiděluje prostředky napříč aplikacemi. Správce clusteru je Apache Hadoop YARN. Po připojení Spark získá exekutory na uzlech ve fondu, což jsou procesy, které spouštějí výpočty a ukládají data pro vaši aplikaci. Dále odešle kód aplikace definovaný soubory JAR nebo Pythonu předané SparkContextexekutorům. SparkContext Nakonec odešle úkoly exekutorům, které se mají spustit.
Spustí SparkContext hlavní funkci uživatele a provede různé paralelní operace na uzlech. SparkContext Pak shromáždí výsledky operací. Uzly čtou a zapisují data ze systému souborů a do systému souborů. Uzly také ukládají transformovaná data v paměti jako odolné distribuované datové sady (RDD).
Připojení SparkContext k fondu Sparku a zodpovídá za převod aplikace na směrovaný acyklický graf (DAG). Graf se skládá z jednotlivých úloh, které se spouští v rámci procesu exekutoru na uzlech. Každá aplikace získá vlastní exekutorové procesy, které zůstávají vzhůru během celé aplikace a spouštějí úlohy ve více vláknech.
Případy použití Apache Sparku ve službě Azure Synapse Analytics
Fondy Sparku ve službě Azure Synapse Analytics umožňují následující klíčové scénáře:
- Datoví technici/ příprava dat
Apache Spark obsahuje řadu jazykových funkcí, které podporují přípravu a zpracování velkých objemů dat, aby je mohly být cennější a následně využívané jinými službami v rámci Azure Synapse Analytics. To je povolené prostřednictvím více jazyků (C#, Scala, PySpark, Spark SQL) a dodaných knihoven pro zpracování a připojení.
- Machine Learning
Apache Spark je součástí knihovny strojového učení založené na Sparku, která je založená na sparkovém fondu ve službě Azure Synapse Analytics. Fondy Sparku ve službě Azure Synapse Analytics zahrnují také Anaconda, distribuci Pythonu s různými balíčky pro datové vědy, včetně strojového učení. V kombinaci s integrovanou podporou poznámkových bloků máte prostředí pro vytváření aplikací strojového učení.
- Streamování dat
Synapse Spark podporuje strukturované streamování Sparku, pokud používáte podporovanou verzi modulu runtime Azure Synapse Spark. Všechny úlohy se podporují pro živé 7 dní. To platí pro dávkové i streamované úlohy a obecně zákazníci automatizují proces restartování pomocí Azure Functions.
Související obsah
Další informace o Apache Sparku ve službě Azure Synapse Analytics najdete v následujících článcích:
- Rychlý start: Vytvoření fondu Sparku v Azure Synapse
- Rychlý start: Vytvoření poznámkového bloku Apache Spark
- Kurz: Strojové učení s využitím Apache Sparku
Poznámka:
Některá oficiální dokumentace k Apache Sparku závisí na používání konzoly Spark, která není k dispozici ve Sparku Azure Synapse Sparku. Místo toho použijte prostředí poznámkového bloku nebo IntelliJ.