Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tip
Microsoft Fabric Data Warehouse je relační sklad v podnikovém měřítku na základu datového jezera s architekturou připravenou pro budoucnost, integrovanou AI a novými funkcemi. Pokud s datovými sklady začínáte, začněte pracovat s Fabric Data Warehouse. Stávající úlohy fondu dedikované SQL můžou upgradovat na Fabric a získat tak přístup k novým funkcím napříč datovou vědou, analýzou v reálném čase a reportováním.
Tato příručka obsahuje užitečné tipy a osvědčené postupy pro vytváření řešení vyhrazeného SQL fondu (dříve SQL DW).
Následující obrázek znázorňuje proces návrhu datového skladu s vyhrazeným fondem SQL (dříve SQL DW):
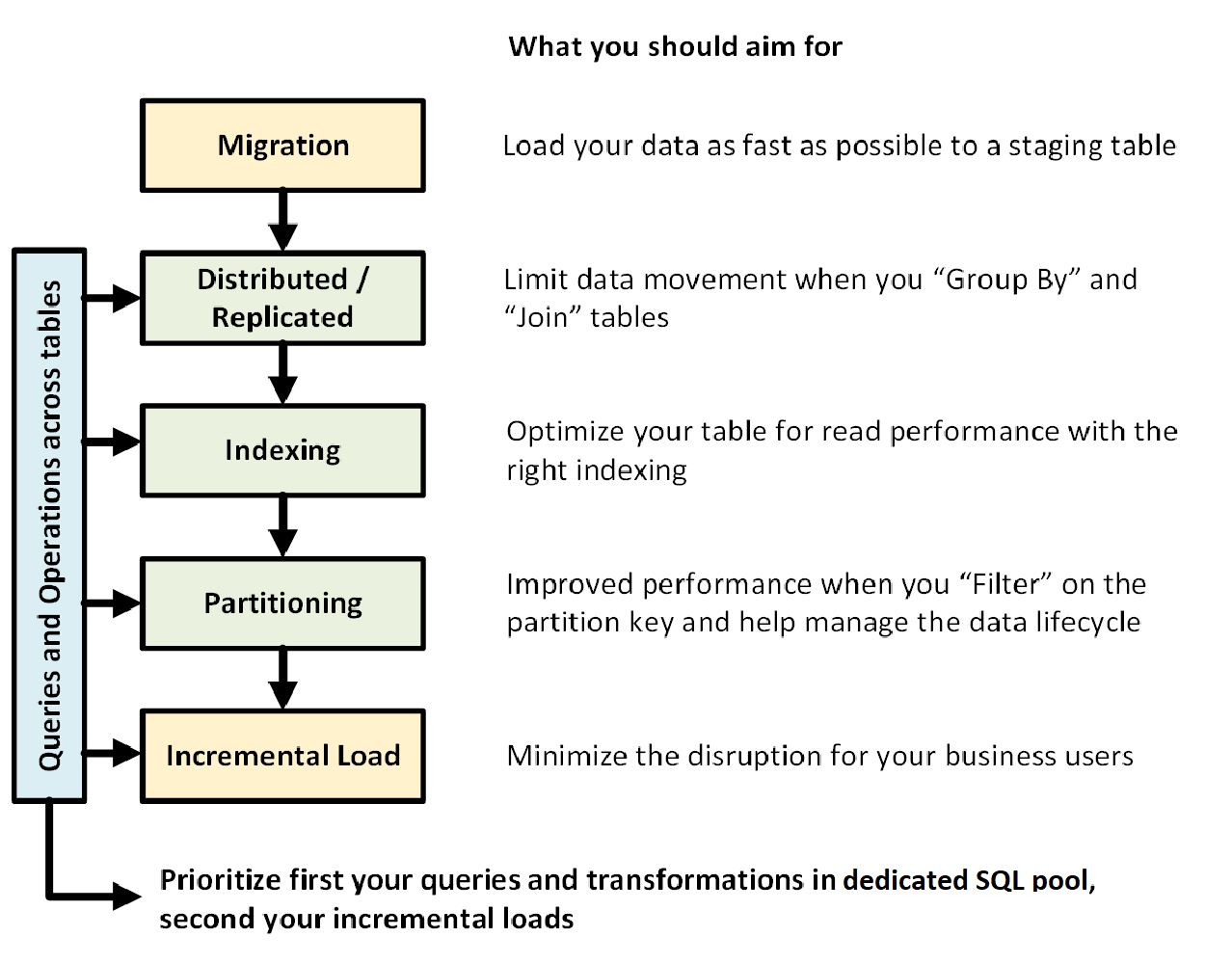
Dotazy a operace napříč tabulkami
Když předem víte, jaké primární operace a dotazy se mají v datovém skladu spouštět, můžete u těchto operací určit prioritu architektury datového skladu. Mezi tyto dotazy a operace patří:
- Spojování jedné nebo dvou tabulek faktů s tabulkami dimenzí, filtrování kombinované tabulky a následné připojení výsledků k datovému tržiště
- Provádění velkých nebo malých aktualizací prodejních údajů.
- Připojení pouze dat k tabulkám
Znalost typů operací předem vám pomůže optimalizovat návrh tabulek.
Migrace dat
Nejprve načtěte data do Azure Data Lake Storage nebo Azure Blob Storage. Dále pomocí příkazu COPY načtěte data do pracovních tabulek. Použijte následující konfiguraci:
| Design/Návrh | Doporučení |
|---|---|
| Distribution | Kruhové přidělování |
| Indexování | Heap |
| dělení na části | Žádné |
| Třída zdrojů | větší nebo xlargerc |
Přečtěte si další informace o migraci dat, načítání dat a procesu extrakce, načtení a transformace (ELT).
Distribuované nebo replikované tabulky
V závislosti na vlastnostech tabulky použijte následující strategie:
| Typ | Vhodné pro... | Dávejte pozor, pokud... |
|---|---|---|
| Replikován | * Malé tabulky dimenzí ve hvězdicovém schématu s méně než 2 GB úložiště po kompresi (přibližně 5x komprese) | * Mnoho transakcí zápisu se provádí v tabulce (například vložení, upsert, odstranění, aktualizace) * Často měníte zřizování jednotek Data Warehouse (DWU). * Používáte pouze 2 až 3 sloupce, ale tabulka obsahuje mnoho sloupců. * Indexujete replikovanou tabulku. |
| Round Robin (výchozí) | * Dočasná/přechodná tabulka * Žádný zřejmý spojovací klíč ani dobrý kandidátní sloupec |
* Výkon je pomalý kvůli přesunu dat |
| Hash | * Tabulky faktů * Velké tabulky dimenzí |
* Distribuční klíč nejde aktualizovat. |
Tips:
- Začněte s cyklickým rozdělením, ale usilujte o strategii rozložení pomocí hashovací funkce pro využití výhod masivně paralelní architektury.
- Ujistěte se, že běžné klíče hash mají stejný datový formát.
- Nedistribuujte ve formátu varchar.
- Tabulky dimenzí, které mají společný hash klíč s tabulkou faktů, kde jsou časté operace spojení, mohou být distribuovány podle hash klíče.
- Pomocí sys.dm_pdw_nodes_db_partition_stats můžete analyzovat jakoukoli nerovnoměrnou distribuci dat.
- Pomocí sys.dm_pdw_request_steps můžete analyzovat pohyby dat za dotazy, monitorovat dobu vysílání a provádět operace míchání. To je užitečné při kontrole strategie distribuce.
Přečtěte si další informace o replikovaných tabulkách a distribuovaných tabulkách.
Indexování tabulky
Indexování je užitečné pro rychlé čtení tabulek. Existuje jedinečná sada technologií, které můžete použít na základě svých potřeb:
| Typ | Vhodné pro... | Dávejte pozor, pokud... |
|---|---|---|
| Heap | * Pracovní/dočasná tabulka * Malé tabulky s malými vyhledáváními |
* Jakékoli vyhledávání prohledá celou tabulku. |
| Clusterovaný index | * Tabulky s až 100 miliony řádků * Velké tabulky (více než 100 milionů řádků) s pouze 1–2 sloupci silně využívanými |
* Používá se v replikované tabulce. * Máte složité dotazy zahrnující více operací spojení a seskupení podle * Provedete aktualizace indexovaných sloupců: zabírá paměť. |
| Clusterovaný index columnstore (CCI) (výchozí) | * Velké tabulky (více než 100 milionů řádků) | * Používá se v replikované tabulce. * V tabulce provedete rozsáhlé operace aktualizací. * Nadměrně členíte tabulku: Skupiny řádků nepřesahují různé distribuční uzly a oddíly. |
Tips:
- Nad clusterovaným indexem můžete chtít přidat neclusterovaný index do sloupce, který se často používá k filtrování.
- Dávejte pozor, jak spravovat paměť v tabulce pomocí nástroje CCI. Při načítání dat chcete, aby uživatel (nebo dotaz) využíval širokou třídu prostředků. Nezapomeňte se vyhnout zmenšení a vytváření menších skupin komprimovaných řádků.
- V Gen2 se tabulky CCI ukládají místně do mezipaměti na výpočetních uzlech, aby se maximalizoval výkon.
- U CCI může dojít k pomalému výkonu kvůli špatné kompresi skupin řádků. Pokud k tomu dojde, znovu sestavte nebo přeuspořádejte vaše CCI. Chcete alespoň 100 000 řádků pro komprimované skupiny řádků. Ideální je 1 milion řádků ve skupině řádků.
- Na základě četnosti a velikosti přírůstkového zatížení chcete automatizovat při opětovném uspořádání nebo opětovném sestavení indexů. Jarní čištění je vždy užitečné.
- Buďte strategičtí, když chcete upravit skupinu řádků. Jak velké jsou otevřené skupiny řádků? Kolik dat očekáváte v nadcházejících dnech?
Přečtěte si další informace o indexech.
dělení na části
Tabulku můžete rozdělit, pokud máte velkou tabulku faktů (větší než 1 miliardu řádků). Ve 99 procentech případů by měl klíč oddílu vycházet z data.
S pracovními tabulkami, které vyžadují ELT, můžete využít dělení. Usnadňuje správu životního cyklu dat. Dejte pozor, abyste nepřerozdělili faktovou nebo přípravnou tabulku, zejména u clusterovaného columnstore indexu.
Přečtěte si další informace o oddílech.
Přírůstkové načítání
Pokud budete data postupně načítat, nejprve se ujistěte, že pro načítání dat přidělíte větší kategorie zdrojů. To je zvlášť důležité při načítání do tabulek s clusterovanými indexy columnstore. Další podrobnosti najdete v třídách prostředků .
Pro automatizaci kanálů ELT do datového skladu doporučujeme používat PolyBase a ADF V2.
U velké dávky aktualizací v historických datech zvažte použití CTAS k zápisu dat, která chcete zachovat v tabulce, a ne pomocí insert, UPDATE a DELETE.
Udržujte statistiky
Je důležité aktualizovat statistiky, protože se s vašimi daty dějí významné změny. Pokud chcete zjistit, jestli došlo k významným změnám, podívejte se na statistiky aktualizací. Aktualizované statistiky optimalizují plány dotazů. Pokud zjistíte, že zachování všech vašich statistik trvá příliš dlouho, vyberte si, které sloupce mají statistiky.
Můžete také definovat frekvenci aktualizací. Například můžete chtít aktualizovat sloupce kalendářních dat, kde se můžou přidávat nové hodnoty každý den. Největší výhodu získáte díky tomu, že máte statistiky o sloupcích zahrnutých ve spojeních, sloupcích používaných v klauzuli WHERE a sloupcích nalezených ve skupině GROUP BY.
Přečtěte si další informace o statistikách.
Třída prostředků
Skupiny prostředků se používají jako způsob přidělování paměti dotazům. Pokud potřebujete více paměti ke zlepšení rychlosti dotazování nebo načítání, měli byste přidělit vyšší třídy prostředků. Na druhé straně použití větších tříd prostředků má vliv na souběžnost. Před přesunem všech uživatelů do velké třídy prostředků byste měli tuto skutečnost vzít v úvahu.
Pokud si všimnete, že dotazy trvají příliš dlouho, zkontrolujte, že se uživatelé nespouštějí ve velkých třídách prostředků. Velké třídy zdrojů spotřebovávají mnoho míst pro souběžnost. Můžou způsobit, že se ostatní dotazy zařadí do fronty.
Nakonec pomocí Gen2 vyhrazeného fondu SQL (dříve SQL DW) získá každá třída prostředků 2,5krát více paměti než Gen1.
Přečtěte si další informace o tom, jak pracovat s třídami prostředků a souběžností.
Snížení nákladů
Klíčovou funkcí Azure Synapse je schopnost spravovat výpočetní prostředky. Vyhrazený fond SQL (dříve SQL DW) můžete pozastavit, když ho nepoužíváte, což zastaví fakturaci výpočetních prostředků. Prostředky můžete škálovat tak, aby splňovaly vaše požadavky na výkon. K pozastavení použijte portál Azure nebo PowerShell. Ke škálování použijte portál Azure, PowerShell, T-SQL nebo REST API.
Automatické škálování teď v okamžiku, kdy chcete použít Azure Functions:

Optimalizace architektury pro výkon
Doporučujeme zvážit SQL Database a Azure Analysis Services v hub-and-spoke architektuře. Toto řešení může poskytovat izolaci úloh mezi různými skupinami uživatelů a zároveň využívat pokročilé funkce zabezpečení ze služby SQL Database a Azure Analysis Services. To je také způsob, jak uživatelům poskytnout neomezenou souběžnost.
Přečtěte si další informace o typických architekturách, které využívají vyhrazený fond SQL (dříve SQL DW) v Azure Synapse Analytics.
Implementujte komponenty ve SQL databázích z vyhrazeného fondu SQL (dříve SQL DW):