Doporučení pro reakci na incidenty zabezpečení
Platí pro doporučení kontrolního seznamu zabezpečení architektury Azure Well-Architected Framework:
| SE:12 | Definujte a otestujte efektivní postupy reakce na incidenty, které pokrývají spektrum incidentů, od lokalizovaných problémů po zotavení po havárii. Jasně definujte, který tým nebo jednotlivec provádí postup. |
|---|
Tato příručka popisuje doporučení pro implementaci reakce na incidenty zabezpečení pro úlohu. Pokud dojde k ohrožení zabezpečení systému, systémový přístup k reakcím na incidenty pomáhá zkrátit dobu potřebnou k identifikaci, správě a zmírnění bezpečnostních incidentů. Tyto incidenty můžou ohrozit důvěrnost, integritu a dostupnost softwarových systémů a dat.
Většina podniků má centrální provozní tým zabezpečení (označovaný také jako Security Operations Center (SOC) nebo SecOps. Odpovědností provozního týmu zabezpečení je rychle zjišťovat, určovat prioritu a určit prioritu potenciálních útoků. Tým také monitoruje telemetrická data související se zabezpečením a zkoumá porušení zabezpečení.
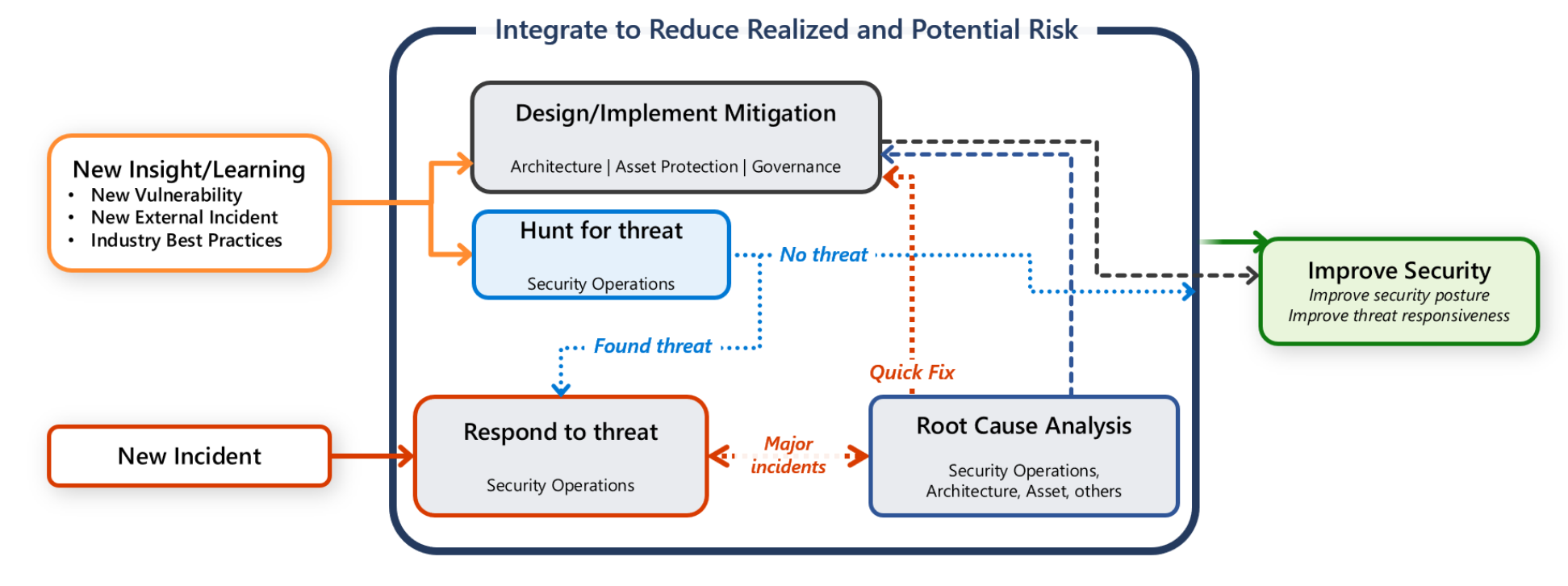
Máte ale také zodpovědnost za ochranu vašich úloh. Je důležité, aby všechny aktivity komunikace, vyšetřování a proaktivního vyhledávání byly úsilím o spolupráci mezi týmem úloh a týmem SecOps.
Tato příručka poskytuje doporučení pro vás a váš tým úloh, která vám pomůžou rychle detekovat, určit prioritu a prozkoumat útoky.
Definice
| Pojem | definice |
|---|---|
| Výstrahy | Oznámení, které obsahuje informace o incidentu. |
| Věrnost upozornění | Přesnost dat, která určují výstrahu. Výstrahy s vysokou věrností obsahují kontext zabezpečení, který je potřeba k provedení okamžitých akcí. Upozornění s nízkou věrností neobsahují informace nebo obsahují šum. |
| Falešně pozitivní výsledek | Výstraha, která indikuje incident, který se nestal. |
| Incident | Událost, která označuje neoprávněný přístup k systému. |
| Reakce na incidenty | Proces, který detekuje, reaguje na ně a zmírní rizika spojená s incidentem. |
| Posouzení | Operace reakce na incidenty, která analyzuje problémy se zabezpečením a upřednostňuje jejich zmírnění. |
Klíčové strategie návrhu
Vy a váš tým provádíte operace reakce na incidenty, pokud existuje signál nebo výstraha pro potenciální ohrožení. Výstrahy s vysokou věrností obsahují velký kontext zabezpečení, který analytikům usnadňuje rozhodování. Upozornění s vysokou věrností vedou k nízkému počtu falešně pozitivních výsledků. V této příručce se předpokládá, že systém upozornění filtruje signály s nízkou věrností a zaměřuje se na výstrahy s vysokou věrností, které by mohly znamenat skutečný incident.
Určení kontaktů pro oznámení incidentů
Výstrahy zabezpečení musí kontaktovat příslušné osoby ve vašem týmu a ve vaší organizaci. Vytvořte pro svůj tým úloh určený kontaktní bod pro příjem oznámení incidentů. Tato oznámení by měla obsahovat co nejvíce informací o ohrožených prostředcích a systému. Výstraha musí obsahovat další kroky, aby váš tým mohl urychlit akce.
Doporučujeme protokolovat a spravovat oznámení a akce incidentů pomocí specializovaných nástrojů, které udržují záznam auditu. Pomocí standardních nástrojů můžete zachovat důkazy, které by mohly být vyžadovány pro případná právní šetření. Hledejte příležitosti k implementaci automatizace, která může odesílat oznámení na základě odpovědností zodpovědných stran. Udržujte jasný řetězec komunikace a hlášení během incidentu.
Využijte výhod řešení pro správu událostí zabezpečení (SIEM) a řešení automatické orchestrace zabezpečení (SOAR), která vaše organizace poskytuje. Alternativně můžete získat nástroje pro správu incidentů a povzbuzovat organizaci, aby je standardizovala pro všechny týmy úloh.
Zkoumání pomocí týmu pro třídění
Člen týmu, který obdrží oznámení o incidentu, zodpovídá za nastavení procesu třídění, který zahrnuje příslušné osoby na základě dostupných dat. Tým pro třídění, často označovaný jako tým mostu, musí souhlasit s režimem a procesem komunikace. Vyžaduje tento incident asynchronní diskuze nebo volání mostu? Jak by měl tým sledovat průběh vyšetřování a informovat ho? Kde může tým získat přístup k prostředkům incidentů?
Reakce na incidenty je zásadní důvod, proč udržovat dokumentaci v aktualizovaném stavu, jako je rozložení architektury systému, informace na úrovni komponent, klasifikace ochrany osobních údajů nebo zabezpečení, vlastníci a klíčové body kontaktu. Pokud jsou informace nepřesné nebo zastaralé, tým mostu ztrácí cenný čas a snaží se pochopit, jak systém funguje, kdo zodpovídá za každou oblast a jaký může být účinek události.
Pro další šetření se zapojte do příslušných lidí. Můžete zahrnout vedoucího incidentu, pracovníka zabezpečení nebo potenciální zákazníky zaměřené na úlohy. Chcete-li zachovat prioritu třídění, vylučte osoby, které jsou mimo rozsah problému. Někdy incident prošetří samostatné týmy. Může existovat tým, který nejprve problém prošetří a pokusí se zmírnit incident, a další specializovaný tým, který může provést forenzní účely pro hloubkové šetření, aby bylo možné zjistit rozsáhlé problémy. Prostředí úloh můžete umístit do karantény, aby forenzní tým mohl provádět šetření. V některýchpřípadechch
V počáteční fázi je tým pro třídění zodpovědný za určení potenciálního vektoru a jeho vlivu na důvěrnost, integritu a dostupnost systému (označovanou také jako CIA).
V kategoriích CIA přiřaďte počáteční úroveň závažnosti, která indikuje hloubku poškození a naléhavost nápravy. Očekává se, že se tato úroveň v průběhu času změní, protože se v úrovních třídění zjistí více informací.
Ve fázi zjišťování je důležité určit okamžitý průběh akčních a komunikačních plánů. Došlo k nějakým změnám spuštěného stavu systému? Jak může být útok obsažen, aby se zastavilo další zneužití? Potřebuje tým rozesílat interní nebo externí komunikaci, jako je zodpovědné zveřejnění? Zvažte detekci a dobu odezvy. Můžete být právně povinni nahlásit některé typy porušení předpisů regulačnímu orgánu během určitého časového období, což je často hodiny nebo dny.
Pokud se rozhodnete systém vypnout, další kroky vedou k procesu zotavení po havárii (DR) úlohy.
Pokud systém nevypnete, určete, jak incident napravit, aniž by to mělo vliv na funkčnost systému.
Zotavení z incidentu
Zacházejte s incidentem zabezpečení jako s havárií. Pokud náprava vyžaduje úplné obnovení, použijte správné mechanismy zotavení po havárii z hlediska zabezpečení. Proces obnovení musí zabránit pravděpodobnosti opakování. V opačném případě obnovení z poškozené zálohy znovu vytvoří problém. Opětovné nasazení systému se stejnou chybou zabezpečení vede ke stejnému incidentu. Ověřte kroky a procesy převzetí služeb při selhání a navrácení služeb po obnovení.
Pokud systém zůstane funkční, vyhodnoťte vliv na spuštěné části systému. Pokračujte v monitorování systému a ujistěte se, že implementace správných procesů snížení výkonu splňuje nebo čte další cíle spolehlivosti a výkonu. Neohrožujte ochranu osobních údajů kvůli zmírnění rizik.
Diagnostika je interaktivní proces, dokud není identifikován vektor a potenciální oprava a náhradní. Po diagnostice tým pracuje na nápravě, která identifikuje a použije požadovanou opravu v přijatelném období.
Metriky obnovení měří, jak dlouho trvá oprava problému. V případě vypnutí může dojít k naléhavosti v souvislosti s dobou nápravy. Pokud chcete systém stabilizovat, trvá to nějakou dobu, než použijete opravy, opravy a testy a nasadíte aktualizace. Určete strategie zahrnutí, které zabrání dalšímu poškození a šíření incidentu. Rozvíjet eradikační postupy, které zcela odstraní hrozbu z prostředí.
Kompromis: Došlo k kompromisu mezi cíli spolehlivosti a nápravnou dobou. Během incidentu pravděpodobně nesplňujete jiné nefunkční nebo funkční požadavky. Během vyšetřování incidentu budete například muset zakázat části systému nebo dokonce budete muset celý systém převést do offline režimu, dokud nezjisíte rozsah incidentu. Podnikoví pracovníci s rozhodovací pravomocí musí explicitně rozhodnout, jaké jsou přijatelné cíle během incidentu. Jasně určete osobu, která je za toto rozhodnutí zodpovědná.
Informace o incidentu
Incident odhalí mezery nebo zranitelné body v návrhu nebo implementaci. Je to příležitost ke zlepšení, která je řízena lekcemi v technických aspektech návrhu, automatizaci, procesy vývoje produktů, které zahrnují testování a efektivitu procesu reakce na incidenty. Udržujte podrobné záznamy incidentů, včetně akcí provedených, časových os a zjištění.
Důrazně doporučujeme provádět strukturované závěrečné vyhodnocení incidentů, jako je analýza původní příčiny a retrospektivní analýza. Sledujte a upřednostňování výsledků těchto kontrol a zvažte použití toho, co se naučíte v budoucích návrzích úloh.
Plány vylepšení by měly zahrnovat aktualizace postupů a testování zabezpečení, jako jsou postupy provozní kontinuity a zotavení po havárii (BCDR). Při provádění podrobného postupu BCDR používejte ohrožení zabezpečení. Podrobné postupy můžou ověřit, jak fungují zdokumentované procesy. Playbooky reakce na incidenty by neměly být více. Použijte jeden zdroj, který můžete upravit na základě velikosti incidentu a toho, jak je efekt široce rozšířený nebo lokalizovaný. Podrobné postupy jsou založeny na hypotetických situacích. Provádění podrobných postupů v prostředí s nízkým rizikem a zahrnutí fáze výuky do podrobností
Proveďte závěrečné vyhodnocení incidentů nebo postmortemy za účelem identifikace slabých míst v procesu reakce a oblastech pro zlepšení. Na základě poznatků, které se z incidentu naučíte, aktualizujte plán reakce na incidenty (IRP) a kontrolní mechanismy zabezpečení.
Definování komunikačního plánu
Implementujte komunikační plán, který uživatelům oznámí přerušení a informuje interní zúčastněné strany o nápravě a vylepšeních. Ostatní uživatelé ve vaší organizaci musí být upozorněni na všechny změny standardních hodnot zabezpečení úlohy, aby se zabránilo budoucím incidentům.
Vygenerujte sestavy incidentů pro interní použití a v případě potřeby pro dodržování právních předpisů nebo pro právní účely. Můžete také přijmout standardní sestavu formátu (šablonu dokumentu s definovanými oddíly), kterou tým SOC používá pro všechny incidenty. Před uzavřením šetření se ujistěte, že má každý incident přidruženou sestavu.
Usnadnění azure
Microsoft Sentinel je řešení SIEM a SOAR. Jedná se o jediné řešení pro detekci výstrah, viditelnost hrozeb, proaktivní proaktivní proaktivní vyhledávání a reakci na hrozby. Další informace najdete v tématu Co je Microsoft Sentinel?
Ujistěte se, že portál pro registraci Azure obsahuje kontaktní informace správce, aby bylo možné o operacích zabezpečení informovat přímo prostřednictvím interního procesu. Další informace najdete v tématu Aktualizace nastavení oznámení.
Další informace o vytvoření určeného kontaktního bodu, který přijímá oznámení incidentů Azure z Microsoft Defenderu pro cloud, najdete v tématu Konfigurace e-mailových oznámení pro výstrahy zabezpečení.
Sladění organizace
Architektura přechodu na cloud pro Azure poskytuje pokyny k plánování reakcí na incidenty a operacím zabezpečení. Další informace najdete v tématu Operace zabezpečení.
Související odkazy
- Automatické vytváření incidentů z výstrah zabezpečení Microsoftu
- Provádění komplexního proaktivního vyhledávání hrozeb pomocí funkce proaktivní vyhledávání
- Konfigurace e-mailových oznámení pro upozornění zabezpečení
- Přehled reakce na incidenty
- Připravenost na incidenty Microsoft Azure
- Navigace a vyšetřování incidentů v Microsoft Sentinelu
- Řízení zabezpečení: Reakce na incidenty
- Řešení SOAR v Microsoft Sentinelu
- Školení: Úvod do připravenosti na incidenty Azure
- Aktualizace nastavení oznámení na webu Azure Portal
- Co je SOC?
- Co je Microsoft Sentinel?
Kontrolní seznam zabezpečení
Projděte si kompletní sadu doporučení.