Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje mapování zobrazení dat a popisuje, jak se role dat používají k vytváření různých typů vizuálů. Vysvětluje, jak určit podmíněné požadavky pro role dat a různé dataMappings typy.
Každé platné mapování vytvoří zobrazení dat. Za určitých podmínek můžete zadat více mapování dat. Podporované možnosti mapování:
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
Power BI vytvoří mapování na zobrazení dat pouze v případě, že je platné mapování také definováno v dataViewMappings.
Jinými slovy, categorical může být definována v dataViewMappings jiných mapováních, například table nebo single, nemusí být. V takovém případě Power BI vytvoří zobrazení dat s jedním categorical mapováním, zatímco table jiná mapování zůstanou nedefinovaná. Příklad:
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Podmínky
Oddíl conditions stanoví pravidla pro konkrétní mapování dat. Pokud data odpovídají některé z popsaných sad podmínek, vizuál přijme data jako platná.
Pro každé pole můžete zadat minimální a maximální hodnotu. Hodnota představuje počet polí, která mohou být svázána s danou rolí dat.
Poznámka:
Pokud je v podmínce vynechána role dat, může mít libovolný počet polí.
V následujícím příkladu category je omezeno na jedno datové pole a measure je omezeno na dvě datová pole.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Pro roli dat můžete také nastavit více podmínek. V takovém případě jsou data platná, pokud je splněna některá z podmínek.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
V předchozím příkladu je vyžadována jedna z následujících dvou podmínek:
- Přesně jedno pole kategorie a přesně dvě míry
- Přesně dvě kategorie a přesně jedna míra
Jedno mapování dat
Jedno mapování dat je nejjednodušší formou mapování dat. Přijme jedno pole míry a vrátí součet. Pokud je pole číselné, vrátí součet. V opačném případě vrátí počet jedinečných hodnot.
Pokud chcete použít jedno mapování dat, definujte název role dat, kterou chcete namapovat. Toto mapování funguje pouze s jedním polem míry. Pokud je přiřazené druhé pole, nevygeneruje se žádné zobrazení dat, takže je vhodné zahrnout podmínku, která omezuje data na jedno pole.
Poznámka:
Toto mapování dat nelze použít ve spojení s žádným jiným mapováním dat. Účelem je snížit data na jednu číselnou hodnotu.
Příklad:
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
Výsledné zobrazení dat může stále obsahovat jiné typy mapování, jako je tabulka nebo kategorie, ale každé mapování obsahuje pouze jednu hodnotu. Osvědčeným postupem je přístup k hodnotě pouze v jednom mapování.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
Následující vzorový kód zpracovává jednoduché mapování zobrazení dat:
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
Výsledkem předchozího ukázkového kódu je zobrazení jedné hodnoty z Power BI:
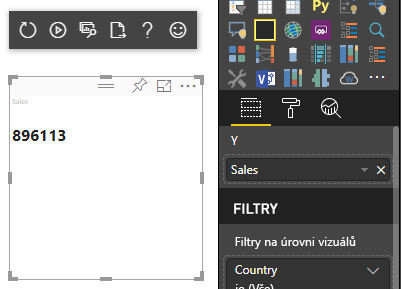
Kategorické mapování dat
Kategorické mapování dat slouží k získání nezávislých seskupení nebo kategorií dat. Kategorie lze také seskupit pomocí "seskupit podle" v mapování dat.
Základní mapování dat kategorií
Zvažte následující role a mapování dat:
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
Předchozí příklad načte "Mapovat moji category datovou roli tak, aby pro každé pole, které přetáhnem do category, jsou jeho data mapována na categorical.categories. Také namapovat moji measure roli dat na categorical.values."
- pro... in: Zahrnuje všechny položky v této roli dat v datovém dotazu.
- vázat... to: Vytvoří stejný výsledek jako pro... očekává ale, že role dat bude mít podmínku, která ji omezuje na jedno pole.
Data kategorií skupin
V dalším příkladu se používají stejné dvě role dat jako v předchozím příkladu a přidají dvě další datové role s názvem grouping a measure2.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
Rozdíl mezi tímto mapováním a základním mapováním je způsob categorical.values mapování. Když namapujete measure role dat a measure2 role dat na roli groupingdat, je možné odpovídajícím způsobem škálovat osu x a osu y.
Hierarchická data skupin
V dalším příkladu se kategorická data používají k vytvoření hierarchie, která se dá použít k podpoře akcí přechodu k podrobnostem .
Následující příklad ukazuje role a mapování dat:
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
Zvažte následující kategorická data:
| Země/oblast | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| USA | linka | linka | 650 | 350 |
| Kanada | linka | 630 | 490 | linka |
| Mexiko | 645 | linka | x | linka |
| Velká Británie | linka | linka | 831 | linka |
Power BI vytvoří zobrazení dat kategorií s následující sadou kategorií.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Každá category mapa se mapuje na sadu .values Každý z nich values je seskupený podle series, který je vyjádřen jako roky.
Například každé values pole představuje jeden rok.
Každé values pole má také čtyři hodnoty: Kanada, USA, Spojené království a Mexiko.
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
Následující ukázka kódu slouží ke zpracování mapování zobrazení dat kategorií. Tato ukázka vytvoří hierarchickou strukturu Country/Region > Year > Value.
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
Tady je výsledný vizuál:
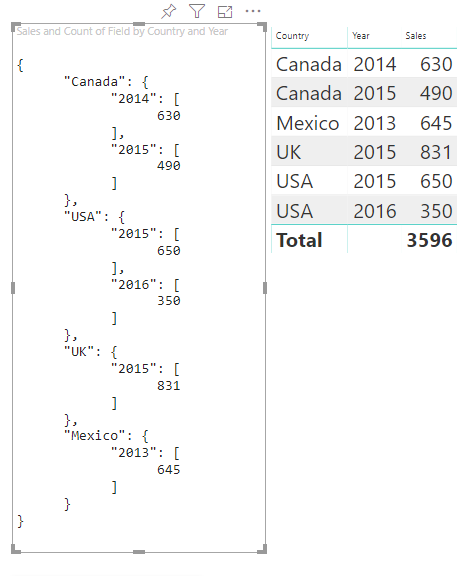
Mapování tabulek
Zobrazení dat tabulky je v podstatě seznam datových bodů, kde lze agregovat číselné datové body.
Použijte například stejná data v předchozí části, ale s následujícími funkcemi:
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
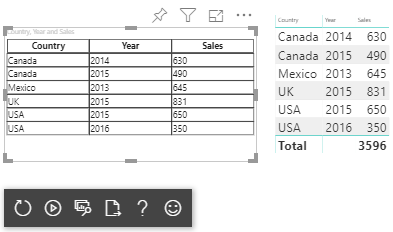
Vizualizujte zobrazení dat tabulky jako v tomto příkladu:
| Země/oblast | Year (Rok) | Prodej |
|---|---|---|
| USA | 2016 | 100 |
| USA | 2015 | 50 |
| Kanada | 2015 | 200 |
| Kanada | 2015 | 50 |
| Mexiko | 2013 | 300 |
| Velká Británie | 2014 | 150 |
| USA | 2015 | 75 |
Datová vazba:
Power BI zobrazí vaše data jako zobrazení dat tabulky. Nepředpokládáme, že jsou data seřazená.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
Pokud chcete data agregovat, vyberte požadované pole a pak zvolte Součet.
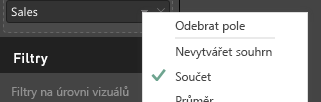
Ukázka kódu pro zpracování mapování zobrazení dat tabulky
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
Soubor style/visual.less stylů vizuálů obsahuje rozložení tabulky:
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
Výsledný vizuál vypadá takto:
Mapování dat matice
Mapování maticových dat je podobné mapování dat tabulky, ale řádky se zobrazují hierarchicky. Libovolnou z hodnot role dat lze použít jako hodnotu záhlaví sloupce.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
Hierarchická struktura maticových dat
Power BI vytvoří hierarchickou datovou strukturu. Kořen stromové hierarchie obsahuje data ze sloupce Category Nadřazené role dat s podřízenými položkami ze sloupce Podřízené položky v tabulce role dat.
Sémantický model:
| Rodiče | Podřízené prvky | Vnoučata | Sloupce | Hodnoty |
|---|---|---|---|---|
| Nadřazený 1 | Podřízený 1 | Velké podřízené 1 | Sloupec 1 | 5 |
| Nadřazený 1 | Podřízený 1 | Velké podřízené 1 | Sloupec 2 | 6 |
| Nadřazený 1 | Podřízený 1 | Podřízený prvek Grand2 | Sloupec 1 | 7 |
| Nadřazený 1 | Podřízený 1 | Podřízený prvek Grand2 | Sloupec 2 | 8 |
| Nadřazený 1 | Podřízené 2 | Velké podřízené 3 | Sloupec 1 | 5 |
| Nadřazený 1 | Podřízené 2 | Velké podřízené 3 | Sloupec 2 | 3 |
| Nadřazený 1 | Podřízené 2 | Velké podřízené 4 | Sloupec 1 | 4 |
| Nadřazený 1 | Podřízené 2 | Velké podřízené 4 | Sloupec 2 | 9 |
| Nadřazený 1 | Podřízené 2 | Velké podřízené 5 | Sloupec 1 | 3 |
| Nadřazený 1 | Podřízené 2 | Velké podřízené 5 | Sloupec 2 | 5 |
| Nadřazená 2 | Podřízená položka 3 | Velké podřízené 6 | Sloupec 1 | 0 |
| Nadřazená 2 | Podřízená položka 3 | Velké podřízené 6 | Sloupec 2 | 2 |
| Nadřazená 2 | Podřízená položka 3 | Podřízený prvek Grand7 | Sloupec 1 | 7 |
| Nadřazená 2 | Podřízená položka 3 | Podřízený prvek Grand7 | Sloupec 2 | 0 |
| Nadřazená 2 | Podřízená položka 3 | Velké podřízené 8 | Sloupec 1 | 10 |
| Nadřazená 2 | Podřízená položka 3 | Velké podřízené 8 | Sloupec 2 | 13 |
Základní maticový vizuál Power BI vykresluje data jako tabulku.
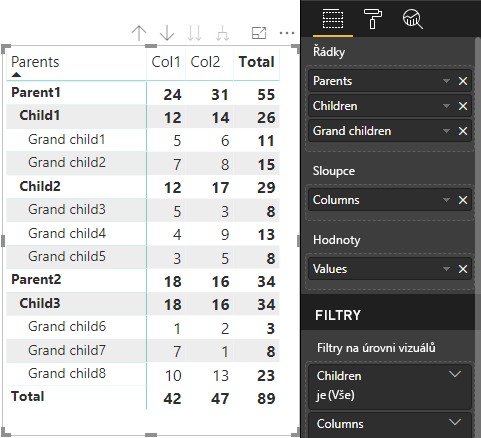
Vizuál získá datovou strukturu, jak je popsáno v následujícím kódu (tady jsou zobrazeny pouze první dva řádky tabulky):
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Rozbalení a sbalení záhlaví řádků
Pro rozhraní API 4.1.0 nebo novější maticová data podporují rozbalení a sbalení záhlaví řádků. Z rozhraní API 4.2 můžete programově rozbalit nebo sbalit celou úroveň. Funkce rozbalení a sbalení optimalizuje načítání dat do dataView tím, že uživateli umožní rozbalit nebo sbalit řádek bez načtení všech dat pro další úroveň. Načte pouze data pro vybraný řádek. Stav rozšíření záhlaví řádku zůstává konzistentní napříč záložkami a dokonce i mezi uloženými sestavami. Není specifický pro každý vizuál.
Příkazy rozbalení a sbalení lze přidat do místní nabídky zadáním dataRoles parametru metodě showContextMenu .
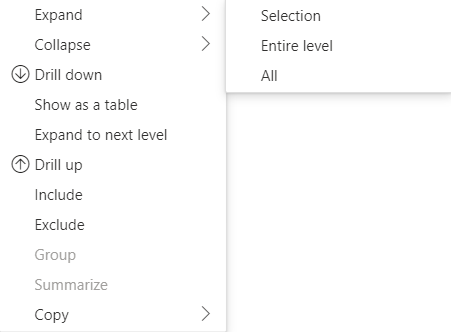
Pokud chcete rozšířit velký počet datových bodů, použijte rozhraní API pro načtení dalších dat s rozhraním API pro rozbalení nebo sbalení.
Funkce rozhraní API
Do rozhraní API verze 4.1.0 byly přidány následující prvky, které umožňují rozbalení a sbalení záhlaví řádků:
Příznak
isCollapsedv :DataViewTreeNodeinterface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }Metoda
toggleExpandCollapsevISelectionMangerrozhraní:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }Příznak
canBeExpandedv prvku DataViewHierarchyLevel:interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Vizuální požadavky
Povolení funkce rozbalení sbalování ve vizuálu pomocí zobrazení maticových dat:
Do souboru capabilities.json přidejte následující kód:
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Ověřte, že role jsou dostupné k podrobnostem:
"drilldown": { "roles": ["Rows"] },Pro každý uzel vytvořte instanci tvůrce výběrů voláním
withMatrixNodemetody ve vybrané úrovni hierarchie uzlů a vytvořenímselectionId. Příklad:let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Vytvořte instanci správce výběru a použijte metodu
selectionManager.toggleExpandCollapse()s parametremselectionId, který jste vytvořili pro vybraný uzel. Příklad:// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Poznámka:
- Pokud vybraný uzel není uzel řádku, PowerBI ignoruje rozbalení a sbalení volání a příkazy rozbalení a sbalení se odeberou z místní nabídky.
- Parametr
dataRolesje vyžadován pro metodushowContextMenupouze v případě, že vizuál podporujedrilldownneboexpandCollapsefunkce. Pokud vizuál tyto funkce podporuje, ale objekty dataRoles nebyly zadány, při použití vizuálu vývojáře se do konzoly zobrazí chyba nebo ladění veřejného vizuálu s povoleným režimem ladění.
Úvahy a omezení
- Po rozbalení uzlu se na DataView použijí nová omezení dat. Nové zobrazení DataView nemusí obsahovat některé uzly zobrazené v předchozím objektu DataView.
- Při použití rozbalení nebo sbalení se přidají součty i v případě, že vizuál o ně nepožádal.
- Rozbalení a sbalení sloupců se nepodporuje.
Zachovat všechny sloupce metadat
Pro rozhraní API 5.1.0 nebo novější se podporují všechny sloupce metadat. Tato funkce umožňuje vizuálu přijímat metadata pro všechny sloupce bez ohledu na to, co jsou jejich aktivní projekce.
Do souboru capabilities.json přidejte následující řádky:
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
Nastavením této vlastnosti se true budou přijímat všechna metadata, včetně z sbalovaných sloupců. Když ho false nastavíte nebo necháte nedefinovaný, bude příjem metadat pouze u sloupců s aktivními projekcemi (například rozbalené).
Algoritmus redukce dat
Algoritmus redukce dat řídí, která data a kolik dat se přijímají v zobrazení dat.
Počet je nastaven na maximální počet hodnot, které může zobrazení dat přijmout. Pokud existuje více hodnot než počet , algoritmus redukce dat určuje, které hodnoty se mají přijímat.
Typy algoritmů redukce dat
Existují čtyři typy nastavení algoritmu redukce dat:
top: První hodnoty počtu jsou převzaty ze sémantického modelu.bottom: Poslední hodnoty počtu jsou převzaty ze sémantického modelu.sample: První a poslední položky jsou zahrnuty a počet položek se stejnými intervaly mezi nimi. Pokud máte například sémantický model [0, 1, 2, ... 100] a počet 9, obdržíte hodnoty [0, 10, 20 ... 100].window: Načte jedno okno datových bodů najednou obsahující prvky počtu .topV současné době jsouwindowekvivalentní. V budoucnu bude plně podporováno nastavení oken.
Ve výchozím nastavení mají všechny vizuály Power BI použitý algoritmus redukce dat s počtem nastaveným na 1 000 datových bodů. Toto výchozí nastavení odpovídá nastavení následujících vlastností v souboru capabilities.json :
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Hodnotu počtu můžete upravit na libovolnou celočíselnou hodnotu až do 3 0000. Vizuály Power BI založené na jazyce R můžou podporovat až 15 0000 řádků.
Využití algoritmu redukce dat
Algoritmus redukce dat se dá použít v mapování zobrazení dat kategorií, tabulek nebo matic.
V mapování kategorických dat můžete přidat algoritmus do části values "categories" a/nebo "group" pro mapování dat kategorií.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
V mapování zobrazení dat tabulky použijte algoritmus redukce dat v rows části tabulky mapování zobrazení dat.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Algoritmus redukce dat můžete použít v rows matici mapování zobrazení dat a columns v oddílech.