Použití relací M:N v Power BI Desktopu
S relacemi s kardinalitou M:N v Power BI Desktopu můžete spojit tabulky, které používají kardinalitu M:N. Můžete snadněji a intuitivněji vytvářet datové modely, které obsahují dva nebo více zdrojů dat. Relace s kardinalitou M:N jsou součástí větších možností složených modelů v Power BI Desktopu. Další informace o složených modelech najdete v tématu Použití složených modelů v Power BI Desktopu.
Co řeší relace s kardinalitou M:N
Před zpřístupněním relací s kardinalitou M:N byla v Power BI definována relace mezi dvěma tabulkami. Nejméně jeden ze sloupců tabulky zahrnutých v relaci musel obsahovat jedinečné hodnoty. Často ale žádné sloupce neobsály jedinečné hodnoty.
Například dvě tabulky můžou mít sloupec označený jako Země. Hodnoty Země ale nebyly v tabulce jedinečné. Pokud chcete takové tabulky spojit, museli jste vytvořit alternativní řešení. Jedním z alternativních řešení může být zavedení dalších tabulek s potřebnými jedinečnými hodnotami. Pokud používáte relaci s kardinalitou M:N, můžete tyto tabulky spojit přímo, pokud použijete relaci s kardinalitou M:N.
Použití relací s kardinalitou M:N
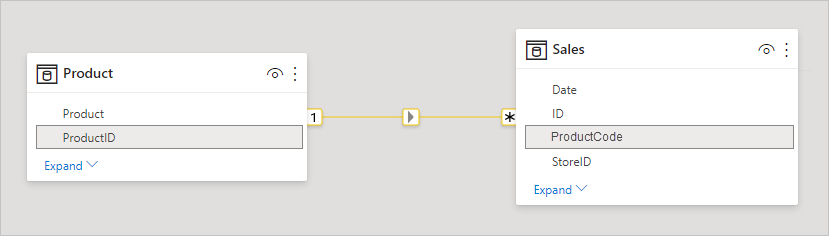
Když definujete relaci mezi dvěma tabulkami v Power BI, musíte definovat kardinalitu relace. Například vztah mezi produkty ProductSales a Product – pomocí sloupců ProductSales[ProductCode] a Product[ProductCode], by byl definován jako M:1. Relaci definujeme tímto způsobem, protože každý produkt má mnoho prodejů a sloupec v tabulce Product (ProductCode) je jedinečný. Když definujete kardinalitu relace jako M:1, 1:N nebo 1-1, Power BI ji ověří, takže kardinalita, kterou vyberete, odpovídá skutečným datům.
Podívejte se například na jednoduchý model na tomto obrázku:
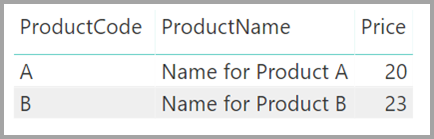
Teď si představte, že tabulka Product zobrazuje jenom dva řádky, jak je znázorněno na obrázku:
Představte si také, že tabulka Sales má jenom čtyři řádky, včetně řádku pro produkt C. Kvůli chybě referenční integrity řádek produktu C v tabulce Product neexistuje.
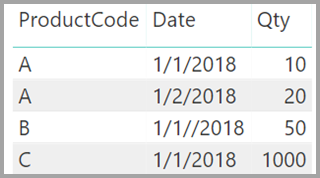
Hodnoty ProductName a Price (z tabulky Product ) spolu s celkovým počtem Qty pro každý produkt (z tabulky ProductSales) by se zobrazily takto:
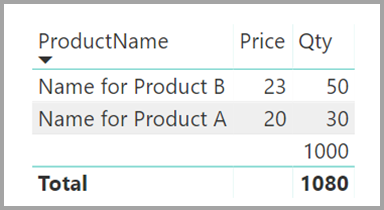
Jak vidíte na předchozím obrázku, prázdný řádek ProductName je přidružený k prodeji produktu C. Tento prázdný řádek odpovídá následujícím aspektům:
Všechny řádky v tabulce ProductSales, pro které v tabulce Product neexistuje žádný odpovídající řádek. Existuje problém s referenční integritou, jak vidíme u produktu C v tomto příkladu.
Všechny řádky v tabulce ProductSales , pro které má sloupec cizího klíče hodnotu null.
Z těchto důvodů prázdný řádek v obou případech představuje prodej, kde productName a Price jsou neznámé.
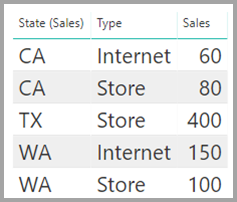
Někdy jsou tabulky spojené dvěma sloupci, ale ani jeden sloupec není jedinečný. Představte si například tyto dvě tabulky:
V tabulce Sales (Prodej) se zobrazují data o prodeji podle státu a každý řádek obsahuje částku prodeje pro typ prodeje v daném státě. Mezi stavy patří CA, WA a TX.
Tabulka CityData zobrazuje data o městech, včetně populace a státu (například CA, WA a New York).
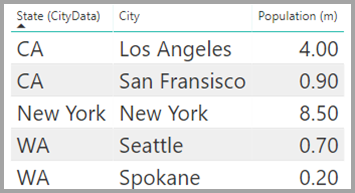
Sloupec pro Stát je teď v obou tabulkách. Je vhodné hlásit celkové prodeje podle státu i celkového počtu obyvatel každého státu. Problém ale existuje: Sloupec State není v tabulce jedinečný.
Předchozí alternativní řešení
Před verzí Power BI Desktopu z července 2018 jste mezi těmito tabulkami nemohli vytvořit přímou relaci. Běžným alternativním řešením bylo:
Vytvořte třetí tabulku, která obsahuje pouze jedinečná ID států. Tabulka může být libovolná nebo všechna:
- Počítaná tabulka (definovaná pomocí výrazů analýzy dat [DAX]).
- Tabulka založená na dotazu definovaném v Editor Power Query, který by mohl zobrazit jedinečná ID nakreslená z jedné z tabulek.
- Kombinovaná úplná sada.
Tyto dvě původní tabulky pak propojovat s novou tabulkou pomocí běžných relací M:1 .
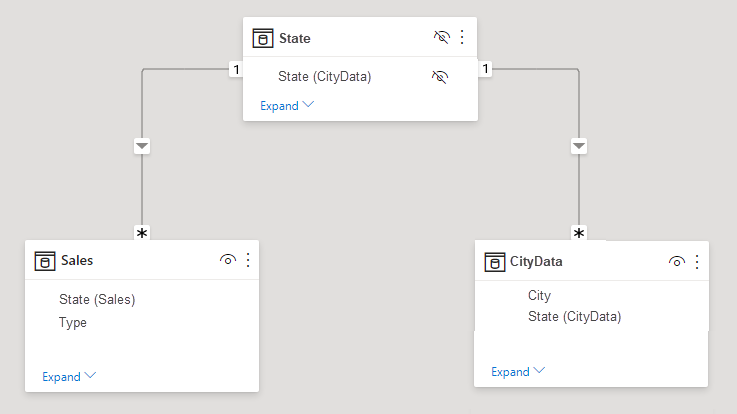
Tabulku alternativního řešení můžete nechat viditelnou. Nebo můžete tabulku alternativního řešení skrýt, takže se nezobrazí v seznamu Pole . Pokud tabulku skryjete, relace M:1 by se obvykle nastavily tak, aby filtrovaly v obou směrech a mohli byste použít pole Stát z obou tabulek. Druhé křížové filtrování by se rozšířilo do druhé tabulky. Tento přístup je znázorněn na následujícím obrázku:
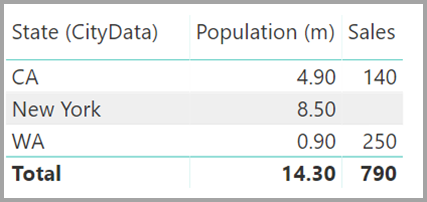
Vizuál zobrazující state (z tabulky CityData) spolu s celkovým počtem obyvatel a celkovým prodejem by se pak zobrazil takto:
Poznámka:
Vzhledem k tomu, že se v tomto alternativním řešení používá stav z tabulky CityData , jsou uvedené pouze stavy v této tabulce, takže TX je vyloučený. Na rozdíl od relací M:1 platí, že zatímco řádek souhrnu zahrnuje všechny prodeje (včetně těch z TX), podrobnosti neobsahují prázdný řádek pokrývající takové neshodované řádky. Podobně by žádný prázdný řádek nepokrývala prodej , pro který je hodnota null pro Stát.
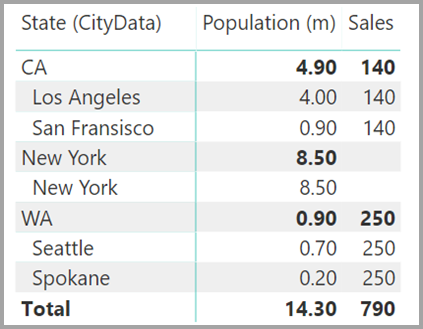
Předpokládejme, že do daného vizuálu přidáte také Město. I když je počet obyvatel na město známý, prodej zobrazený pro Město jednoduše opakuje prodeje pro odpovídající stát. K tomuto scénáři obvykle dochází v případě, že seskupení sloupců nesouvisí s určitou agregační mírou, jak je znázorněno tady:
Řekněme, že definujete novou tabulku Sales (Prodej) jako kombinaci všech států zde a my ji zpřístupníme v seznamu Pole . Stejný vizuál by zobrazoval stav (v nové tabulce), celkový počet obyvatel a celkový prodej:
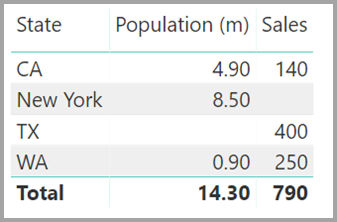
Jak vidíte, TX – s prodejními daty, ale neznámými daty populace – a New Yorkem – se známými údaji o populaci, ale bez prodejních dat, by byla zahrnuta. Toto alternativní řešení není optimální a má mnoho problémů. U relací s kardinalitou M:N se výsledné problémy řeší, jak je popsáno v další části.
Další informace o implementaci tohoto alternativního řešení najdete v pokynech k relacím M:N.
Použití relace s kardinalitou M:N místo alternativního řešení
Tabulky, které jsme popsali dříve, můžete přímo propojit, aniž byste se museli chytnout k podobným alternativním řešením. Teď je možné nastavit kardinalitu relace na M:N. Toto nastavení označuje, že žádná tabulka neobsahuje jedinečné hodnoty. U takových relací můžete i nadále určovat, která tabulka filtruje druhou tabulku. Nebo můžete použít obousměrné filtrování, kde každá tabulka filtruje druhou.
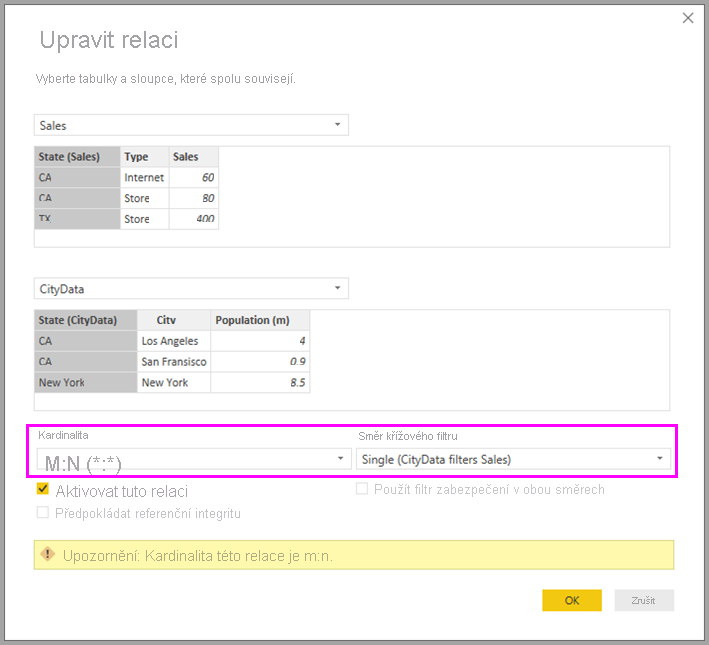
V Power BI Desktopu se kardinalita standardně nastaví na M:N , když určí, že žádná tabulka neobsahuje jedinečné hodnoty sloupců relací. V takových případech zpráva s upozorněním potvrzuje, že chcete nastavit relaci a že změna není nežádoucím účinkem problému s daty.
Když například vytvoříte relaci přímo mezi CityData a Sales – kde by filtry měly proudit z CityData do Sales – Power BI Desktop zobrazí dialogové okno Upravit relaci :
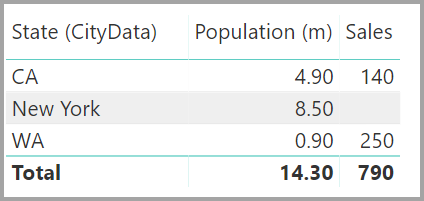
Výsledné zobrazení relace by pak zobrazilo přímou relaci M:N mezi dvěma tabulkami. Vzhled tabulek v seznamu Pole a jejich pozdější chování při vytváření vizuálů se podobá použití alternativního řešení. V alternativním řešení se nezobrazují další tabulka, která zobrazuje jedinečná data o stavu. Jak je popsáno výše, zobrazí se vizuál zobrazující data o státu, populaci a prodeji :
Hlavní rozdíly mezi relacemi s kardinalitou M:N a typickými relacemi M:1 jsou následující:
Zobrazené hodnoty nezahrnují prázdný řádek, který odpovídá neshodným řádkům v druhé tabulce. Hodnoty také nepočítá s řádky, ve kterých sloupec použitý v relaci v druhé tabulce má hodnotu null.
Funkci nemůžete použít
RELATED(), protože může souviset více než jeden řádek.ALL()Použití funkce v tabulce neodebere filtry použité u jiných souvisejících tabulek relací M:N. V předchozím příkladu by míra definovaná tady, neodebíla filtry sloupců v související tabulce CityData:![Screenshot of a script example. The example is, Sales total = Calculate(Sum('Sales'[Sales]), All('Sales')).](media/desktop-many-to-many-relationships/many-to-many-relationships_13.png)
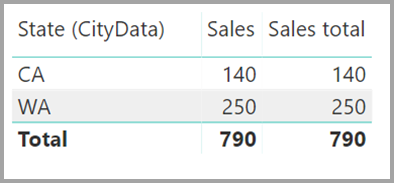
Vizuál zobrazující celkové údaje o stavu, prodeji a prodeji by výsledkem tohoto obrázku:
S ohledem na předchozí rozdíly se ujistěte, že výpočty, které používají ALL(<Table>)( například % celkového součtu), vrací zamýšlené výsledky.
Úvahy a omezení
Tato verze relací s kardinalitou M:N a složenými modely má několik omezení.
S složenými modely se nedají použít následující zdroje live Připojení (multidimenzionální):
- SAP HANA
- SAP Business Warehouse
- SQL Server Analysis Services
- Sémantické modely Power BI
- Azure Analysis Services
Když se k těmto multidimenzionálním zdrojům připojíte pomocí DirectQuery, nemůžete se připojit k jinému zdroji DirectQuery ani ho kombinovat s importovanými daty.
Stávající omezení použití DirectQuery se stále vztahují, pokud používáte relace s kardinalitou M:N. V závislosti na režimu úložiště tabulky je teď pro každou tabulku mnoho omezení. Počítaný sloupec v importované tabulce může například odkazovat na jiné tabulky, ale počítaný sloupec v tabulce DirectQuery může odkazovat pouze na sloupce ve stejné tabulce. Další omezení platí pro celý model, pokud jsou jakékoli tabulky v modelu DirectQuery. Funkce Rychlé Přehledy a Q&A například nejsou v modelu dostupné, pokud má některá tabulka v něm režim úložiště DirectQuery.
Související obsah
Další informace o složených modelech a DirectQuery najdete v následujících článcích:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro