Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Machine Learning Studio (Klasické)
Machine Learning Studio (Klasické)  Azure Machine Learning
Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Do tohoto data doporučujeme přejít na Azure Machine Learning .
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Přečtěte si informace o přesunu projektů strojového učení ze sady ML Studio (classic) do služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
V tomto článku se dozvíte o metrikách, které můžete použít k monitorování výkonu modelu v nástroji Machine Learning Studio (classic). Vyhodnocení výkonu modelu je jednou ze základních fází procesu datových věd. Označuje, jak úspěšné bodování (předpovědi) datové sady proběhlo vytrénovaným modelem. Machine Learning Studio (classic) podporuje vyhodnocování modelů prostřednictvím dvou hlavních modulů strojového učení:
Tyto moduly umožňují zjistit, jak model funguje z hlediska řady metrik, které se běžně používají ve strojovém učení a statistikách.
Hodnocení modelů by mělo být zvažováno společně s následujícími:
Jsou uvedeny tři běžné scénáře učení pod dohledem:
- regrese do dřívějšího stavu
- binární klasifikace
- vícetřídová klasifikace
Vyhodnocení vs. Křížové ověření
Vyhodnocení a křížové ověřování jsou standardní způsoby měření výkonu modelu. Oba generují metriky vyhodnocení, které můžete zkontrolovat nebo porovnat s metrikami jiných modelů.
Vyhodnocení modelu očekává jako vstup vyhodnocenou datovou sadu (nebo dva v případě, že byste chtěli porovnat výkon dvou různých modelů). Proto potřebujete vytrénovat model pomocí modulu Trénování modelu a před vyhodnocením výsledků provést předpovědi u některé datové sady pomocí modulu Určení skóre modelu . Vyhodnocení vychází z skóre popisků a pravděpodobností spolu s skutečnými popisky, z nichž všechny jsou výstupem modulu Score Model .
Případně můžete použít křížové ověření k automatickému provádění několika operací trénování-hodnocení (10 dílčích) na různých podmnožinách vstupních dat. Vstupní data jsou rozdělena na 10 částí, kde je jedna vyhrazena pro testování a druhá 9 pro trénování. Tento proces se opakuje 10krát a metriky vyhodnocení se zprůměrují. To pomáhá při určování, jak dobře by model generalizoval nové datové sady. Modul Cross-Validate Model přebírá netrénovaný model a některé označené datové sady a výstupem jsou výsledky vyhodnocení každého z 10 složených záhybů kromě průměrných výsledků.
V následujících částech vytvoříme jednoduché regrese a klasifikační modely a vyhodnotíme jejich výkon pomocí modulů Vyhodnotit model i Model křížového ověření .
Vyhodnocení regresního modelu
Předpokládejme, že chceme předpovědět cenu auta pomocí funkcí, jako jsou rozměry, koňská síla, specifikace motoru atd. Jedná se o typický problém regrese, kdy cílová proměnná (cena) je souvislá číselná hodnota. Můžeme přizpůsobit model lineární regrese, který s ohledem na hodnoty vlastností určitého auta dokáže předpovědět cenu tohoto auta. Tento regresní model lze použít k určení skóre stejné datové sady, na které jsme natrénovali. Jakmile budeme mít predikované ceny aut, můžeme výkon modelu vyhodnotit tak, že se podíváme na to, kolik predikcí se v průměru odchyluje od skutečných cen. K ilustraci použijeme datovou sadu Automobile Price Data (Raw) dostupnou v části Uložené datové sady v nástroji Machine Learning Studio (classic).
Vytvoření experimentu
Do pracovního prostoru v nástroji Machine Learning Studio (classic) přidejte následující moduly:
- Údaje o cenách automobilů (Surová)
- Lineární regrese
- Trénink modelu
- Určení skóre modelu
- Vyhodnocení modelu
Připojte porty, jak je znázorněno na obrázku 1, a nastavte sloupec Label modulu Trénovat Model na cenu.
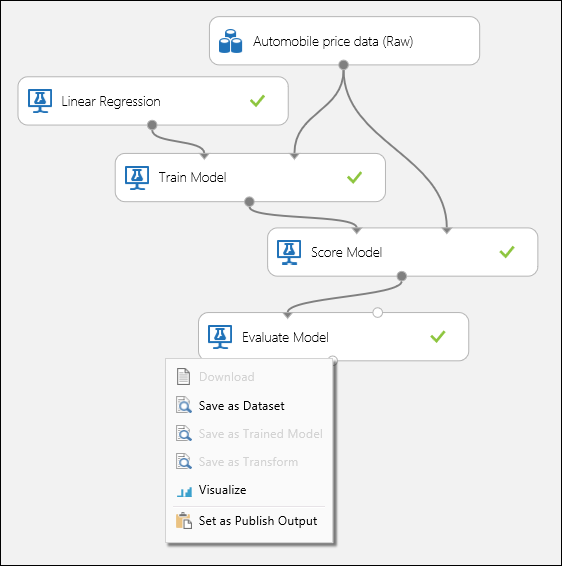
Obrázek č. 1. Vyhodnocení regresního modelu
Kontrola výsledků vyhodnocení
Po spuštění experimentu můžete kliknout na výstupní port modulu Vyhodnotit model a vybrat Vizualizovat a zobrazit výsledky vyhodnocení. Metriky vyhodnocení dostupné pro regresní modely jsou: střední absolutní chyba, absolutní chyba kořene, relativní absolutní chyba, relativní kvadratická chyba a koeficient určení.
Výraz "error" zde představuje rozdíl mezi predikovanou hodnotou a skutečnou hodnotou. Absolutní hodnota nebo druhou mocninu tohoto rozdílu se obvykle vypočítá za účelem zachycení celkové velikosti chyby ve všech instancích, protože rozdíl mezi predikovanou a skutečnou hodnotou může být v některých případech záporný. Metriky chyb měří prediktivní výkon regresního modelu z hlediska střední odchylky jejích předpovědí od skutečných hodnot. Nižší chybové hodnoty znamenají, že model je přesnější při vytváření předpovědí. Celková metrika chyby nuly znamená, že model dokonale odpovídá datům.
Koeficient určení, který se také označuje jako R squared, je také standardní způsob měření, jak dobře model vyhovuje datům. Dá se interpretovat jako poměr variant, který model vysvětluje. Vyšší podíl je v tomto případě lepší, kde 1 označuje perfektní fit.
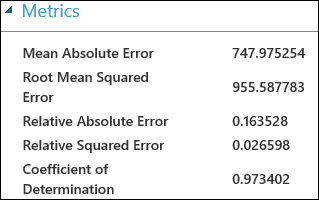
Obrázek č. 2. Metriky vyhodnocení lineární regrese
Použití křížového ověřování
Jak už bylo zmíněno dříve, můžete provádět opakované trénování, bodování a hodnocení automaticky pomocí modulu Křížové ověření modelu . V tomto případě stačí datová sada, nenatrénovaný model a modul křížového ověření ( viz obrázek níže). Ve vlastnostech modulu Cross-Validate Model je potřeba nastavit sloupec popisku na cenu.
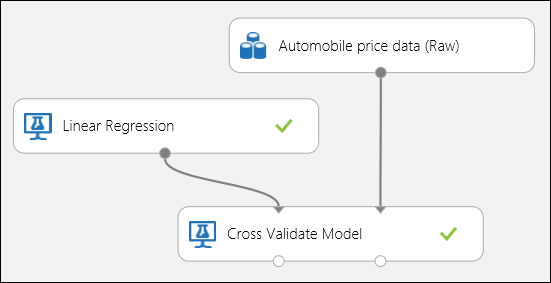
Obrázek č. 3. Křížové ověřování regresního modelu
Po spuštění experimentu můžete výsledky vyhodnocení zkontrolovat kliknutím na správný výstupní port modulu Křížové ověření modelu . Zobrazí se podrobné zobrazení metrik pro každou iteraci (složené) a průměrné výsledky jednotlivých metrik (obrázek 4).
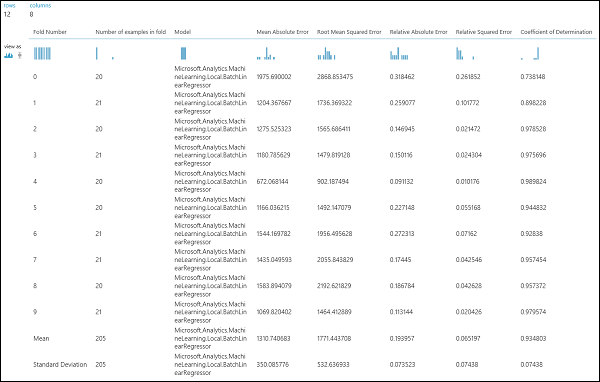
Obrázek č. 4. Výsledky křížového ověření regresního modelu
Vyhodnocení binárního klasifikačního modelu
Ve scénáři binární klasifikace má cílová proměnná pouze dva možné výsledky, například: {0, 1} nebo {false, true}, {negative, positive}. Předpokládejme, že máte datovou sadu zaměstnanců pro dospělé s některými demografickými proměnnými a proměnnými zaměstnání a že jste požádáni o predikci úrovně příjmů, binární proměnnou s hodnotami {"<=50 K", ">50 K"}. Jinými slovy, záporná třída představuje zaměstnance, kteří mají příjem menší nebo roven 50 tisícům ročně, a kladná třída představuje všechny ostatní zaměstnance. Stejně jako ve scénáři regrese bychom vytrénovali model, skórovali některá data a vyhodnotili výsledky. Hlavním rozdílem je výběr metrik, které Machine Learning Studio (classic) vypočítá a výstupy. K ilustraci scénáře predikce úrovně příjmu použijeme datovou sadu Adult k vytvoření experimentu ve Studio (classic) a vyhodnocení výkonu logistického regresního modelu pro dvě třídy, běžně používaného binárního klasifikátoru.
Vytvoření experimentu
Do pracovního prostoru v nástroji Machine Learning Studio (classic) přidejte následující moduly:
- Datová sada pro binární klasifikaci příjmů dospělých
- Two-Class Logistická regrese
- Trénování modelu
- Určení skóre modelu
- Vyhodnocení modelu
Připojte porty, jak je znázorněno níže na obrázku 5, a nastavte sloupec Popisek modulu Trénování modelu na příjem.
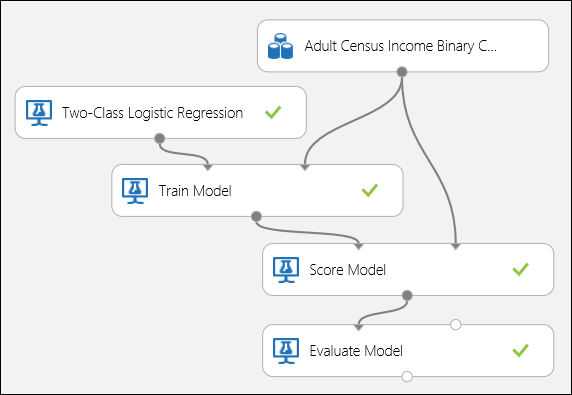
Obrázek č. 5. Vyhodnocení binárního klasifikačního modelu
Kontrola výsledků vyhodnocení
Po spuštění experimentu můžete kliknout na výstupní port modulu Vyhodnotit model a vybrat Vizualizovat a zobrazit výsledky vyhodnocení (obrázek 7). Metriky vyhodnocení dostupné pro binární klasifikační modely jsou: přesnost, preciznost, úplnost, skóre F1 a AUC. Modul navíc vypíše konfuzní matici zobrazující počet skutečných pozitivních, falešně negativních, falešně pozitivních a skutečných negativních hodnot a také ROC, přesnost/úplnost a křivky Lift.
Přesnost je jednoduše poměr správně klasifikovaných instancí. Obvykle se jedná o první metriku, na kterou se podíváte při vyhodnocování klasifikátoru. Pokud jsou však testovací data nevyvážená (kde většina instancí patří do jedné z tříd), nebo vás zajímá výkon jedné z tříd, přesnost ve skutečnosti nezachytí účinnost klasifikátoru. Ve scénáři klasifikace na úrovni příjmu předpokládejme, že testujete některá data, ve kterých 99 % instancí představuje osoby, které vydělají méně než 50 tisíc ročně. Přesnost 0,99 je možné dosáhnout predikcí třídy =<50K pro všechny instance. Klasifikátor v tomto případě vypadá, že dělá dobrou práci celkově, ale ve skutečnosti nedokáže klasifikovat žádnou z osob s vysokým příjmem (1 %) správně.
Z tohoto důvodu je užitečné vypočítat další metriky, které zachycují konkrétnější aspekty vyhodnocení. Než začnete s podrobnostmi o těchto metrikách, je důležité pochopit konfuzní matici vyhodnocení binární klasifikace. Třídní popisky v datové sadě mohou nabývat pouze dvou možných hodnot, které obvykle označujeme jako kladné nebo záporné. Kladné a záporné instance, které klasifikátor predikuje správně, se nazývají pravdivě pozitivní (TP) a pravdivě negativní (TN). Podobně se nesprávně klasifikované instance označují jako falešně pozitivní (FP) a falešně negativní (FN). Matice záměn je jednoduše tabulka, která ukazuje počet instancí spadajících do každé z těchto čtyř kategorií. Machine Learning Studio (classic) automaticky rozhodne, které ze dvou tříd v datové sadě je kladná třída. Pokud jsou popisky tříd typu Boolean nebo celá čísla, instance označené jako "true" nebo "1" jsou přiřazeny do kladné třídy. Pokud jsou popisky řetězce, například s datovou sadou příjmů, popisky se seřadí abecedně a první úroveň se zvolí jako záporná třída, zatímco druhá úroveň je kladná třída.
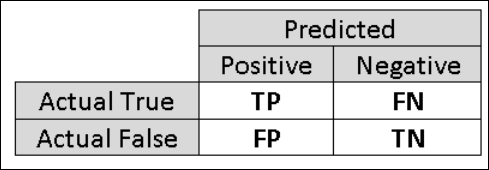
Obrázek č. 6. Konfuzní matice pro binární klasifikaci.
Když se vrátíme k problému klasifikace příjmů, chtěli bychom položit několik otázek vyhodnocení, které nám pomůžou pochopit výkon použitého klasifikátoru. Přirozenou otázkou je: "Mimo jednotlivce, kterým model předpověděl, že získá >50 K (TP+FP), kolik bylo klasifikováno správně (TP)?" Na tuto otázku můžete odpovědět tak, že se podíváte na přesnost modelu, což je poměr kladných hodnot, které jsou klasifikovány správně: TP/(TP+FP). Další běžnou otázkou je "Kolik z těch, kteří patří mezi zaměstnance s vysokým příjmem s příjmem >50 tisíc (TP+FN), klasifikátor klasifikoval správně (TP)". Ve skutečnosti se jedná o úplnost nebo skutečnou kladnou rychlost: TP/(TP+FN) klasifikátoru. Můžete si všimnout, že mezi přesností a úplností je zřejmý kompromis. Například vzhledem k relativně vyvážené datové sadě by klasifikátor, který předpovídá převážně pozitivní instance, měl vysokou úplnost, ale spíše nízkou přesnost, protože mnoho negativních instancí by bylo chybně klasifikováno, což by vedlo k velkému počtu falešně pozitivních případů. Pokud chcete zobrazit graf toho, jak se tyto dvě metriky liší, můžete kliknout na křivku PRECISION/RECALL na stránce výstupu vyhodnocení (levá horní část obrázku 7).
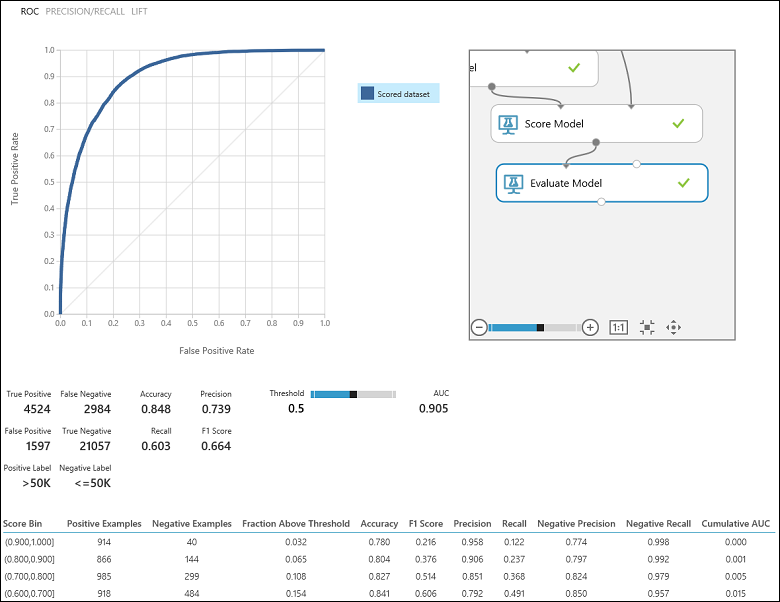
Obrázek 7. Výsledky vyhodnocení binární klasifikace
Dalším související metrikou , která se často používá, je skóre F1, které bere v úvahu přesnost i úplnost. Jedná se o harmonický průměr těchto dvou metrik a vypočítá se například: F1 = 2 (přesnost x úplnost) / (přesnost + úplnost). Skóre F1 je dobrým způsobem, jak shrnout hodnocení do jednoho čísla, ale vždy je vhodné podívat se jak na přesnost, tak na senzitivitu, abyste lépe pochopili, jak se klasifikátor chová.
Kromě toho můžete zkontrolovat skutečnou kladnou rychlost vs. falešně pozitivní rychlost v křivkě ROC (Receiver Operating Characteristic) a odpovídající oblast pod křivkou (AUC). Čím je tato křivka blíže levému hornímu rohu, tím lepší je výkon klasifikátoru (to znamená maximalizaci skutečné kladné míry a minimalizaci falešně pozitivní míry). Křivky, které jsou blízko úhlopříčky grafu, jsou výsledkem klasifikátorů, které mají tendenci vytvářet předpovědi, které jsou blízko náhodnému odhadování.
Použití křížového ověřování
Stejně jako v příkladu regrese můžeme provést křížové ověření, které bude opakovaně trénovat, skórovat a vyhodnocovat různé podmnožiny dat automaticky. Podobně můžeme použít modul Cross-Validate Model , nenatrénovaný logistický regresní model a datovou sadu. Sloupec popisku musí být nastaven na příjem ve vlastnostech modulu Křížové ověření modelu. Po spuštění experimentu a kliknutí na správný výstupní port modulu Cross-Validate Model uvidíme hodnoty metrik binární klasifikace pro každý sklád, kromě střední hodnoty a směrodatné odchylky každého z nich.
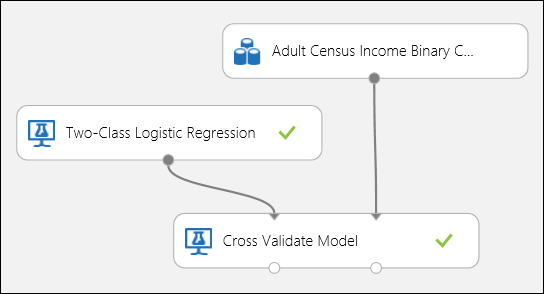
Obrázek 8. Křížové ověřování binárního klasifikačního modelu
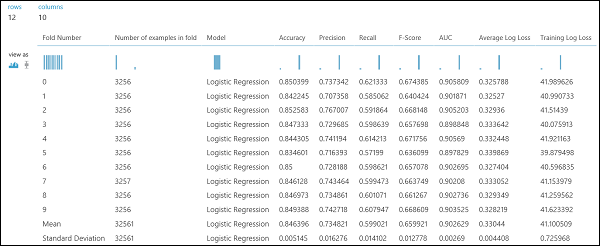
Obrázek 9. Výsledky křížového ověření binárního klasifikátoru
Vyhodnocení klasifikačního modelu s více třídami
V tomto experimentu použijeme oblíbenou datovou sadu Iris, která obsahuje instance tří různých typů (tříd) kosatce. Pro každý případ jsou k dispozici čtyři hodnoty vlastností (délka/šířka kališního lístku a délka/šířka korunního plátku). V předchozích experimentech jsme natrénovali a otestovali modely pomocí stejných datových sad. Zde použijeme modul Rozdělit data k vytvoření dvou podmnožin dat, trénování na prvním a vyhodnocení druhého. Datová sada Iris je veřejně dostupná v úložišti strojového učení UCI a můžete ji stáhnout pomocí modulu Import dat .
Vytvoření experimentu
Do pracovního prostoru v nástroji Machine Learning Studio (classic) přidejte následující moduly:
Připojte porty, jak je znázorněno níže na obrázku 10.
Nastavte index sloupce Popisek modulu Trénování modelu na hodnotu 5. Datová sada nemá žádný řádek záhlaví, ale víme, že popisky tříd jsou v pátém sloupci.
Klikněte na modul Importovat data a nastavte vlastnost Zdroj dat na webovou adresu URL prostřednictvím protokolu HTTP a adresu URL na http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Nastavte zlomek instancí, které mají být použity pro trénování v modulu Split Data (například 0,7).
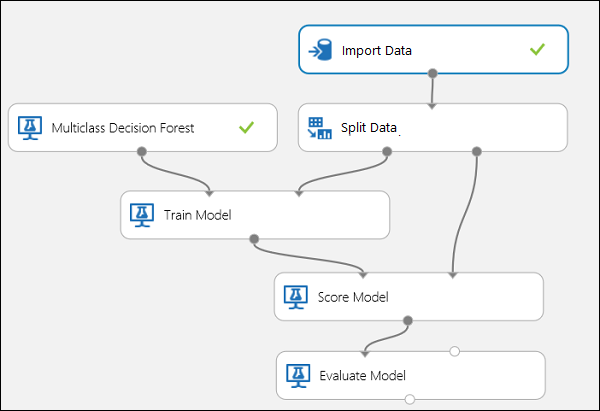
Obrázek 10. Vyhodnocení klasifikátoru s více třídami
Kontrola výsledků vyhodnocení
Spusťte experiment a klikněte na výstupní port vyhodnocení modelu. Výsledky vyhodnocení jsou prezentovány ve formě konfuzní matice, v tomto případě. Matice zobrazuje skutečné a předpovězené instance pro všechny tři třídy.
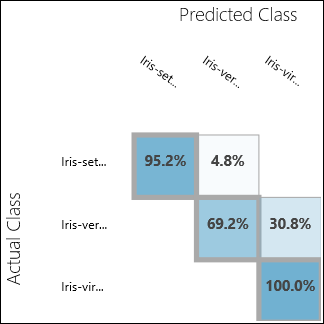
Obrázek 11. Výsledky vyhodnocení klasifikace s více třídami
Použití křížového ověřování
Jak už bylo zmíněno dříve, můžete provádět opakované trénování, bodování a hodnocení automaticky pomocí modulu Křížové ověření modelu . Potřebujete datovou sadu, netrénovaný model a modul Modelu křížového ověření (viz obrázek níže). Znovu je potřeba nastavit sloupec popisku modulu Cross-Validate Model (index sloupce 5 v tomto případě). Po spuštění experimentu a kliknutí na pravý výstupní port křížového ověření modelu můžete zkontrolovat hodnoty metrik pro každé záhyby a střední a směrodatnou odchylku. Zobrazené metriky jsou podobné metrikám, které jsou popsány v binárním klasifikačním případu. Ve vícetřídové klasifikaci je však výpočet pravdivě pozitivních/negativních výsledků a falešně pozitivních/negativních výsledků proveden počítáním na základě jednotlivých tříd, protože neexistuje žádná celková kladná nebo záporná třída. Například při výpočtu přesnosti nebo míry záchytu třídy Iris-setosa se předpokládá, že se jedná o kladnou třídu, zatímco všechny ostatní jsou považovány za záporné.
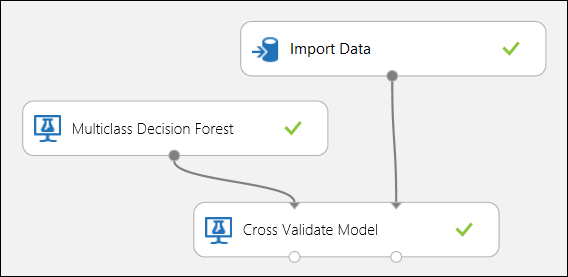
Obrázek 12 Křížové ověřování klasifikačního modelu s více třídami
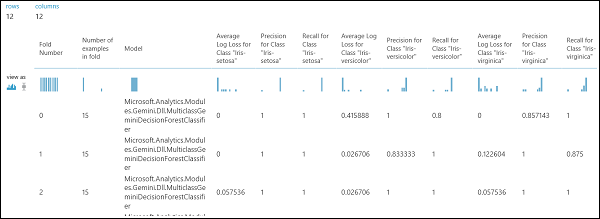
Obrázek 13 Výsledky křížového ověření klasifikačního modelu s více třídami