Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Přečtěte si informace o přesunu projektů strojového učení ze sady ML Studio (classic) do služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
Toto téma vysvětluje, jak vizualizovat a interpretovat výsledky předpovědi v nástroji Machine Learning Studio (classic). Po vytrénování modelu a provedení předpovědí pomocí něj ("vyhodnocení modelu"), je třeba pochopit a interpretovat výsledek předpovědi.
V nástroji Machine Learning Studio (classic) existují čtyři hlavní druhy modelů strojového učení:
- Klasifikace
- Klastrování
- Regrese
- Doporučené systémy
Moduly používané pro predikci nad těmito modely jsou:
- Modul skórovacího modelu pro klasifikaci a regresi
- Přiřazení ke Clusters modulu pro shlukování
- Score Matchbox Recommender pro systémy doporučení
Zjistěte, jak zvolit parametry pro optimalizaci algoritmů v nástroji ML Studio (classic).
Pokud chcete zjistit, jak vyhodnotit modely, přečtěte si, jak vyhodnotit výkon modelu.
Pokud s ML Studio (classic) začínáte, přečtěte si, jak vytvořit jednoduchý experiment.
Klasifikace
Existují dvě podkategorie problémů klasifikace:
- Problémy pouze se dvěma třídami (dvoutřídní nebo binární klasifikace)
- Problémy s více než dvěma třídami (klasifikace s více třídami)
Machine Learning Studio (classic) má různé moduly pro každou z těchto typů klasifikace, ale metody interpretace výsledků predikce jsou podobné.
Dvoutřídní klasifikace
Příklad experimentu
Příkladem problému klasifikace se dvěma třídami je klasifikace květů duhovky. Úkolem je klasifikovat iris květiny na základě jejich vlastností. Datová sada Iris poskytovaná v nástroji Machine Learning Studio (classic) je podmnožinou oblíbené datové sady Iris obsahující instance pouze dvou druhů květin (třídy 0 a 1). Pro každou květinu jsou čtyři funkce (délka sepalu, šířka sepalu, délka okvětního lístku a okvětní šířka).
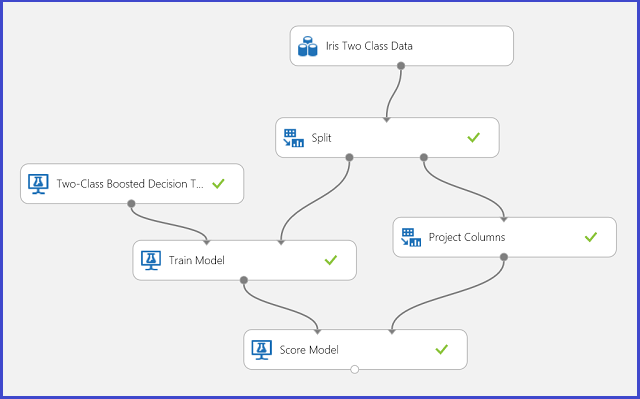
Obrázek č. 1. Experiment se dvěma třídami klasifikace Iris
K vyřešení tohoto problému došlo k experimentu, jak je znázorněno na obrázku 1. Model zesíleného rozhodovacího stromu se dvěma třídami byl natrénován a vyhodnocen. Teď můžete vizualizovat výsledky předpovědi z modulu Určení skóre modelu kliknutím na výstupní port modulu Určení skóre modelu a následným kliknutím na Vizualizovat.
Tím se zobrazí výsledky vyhodnocování, jak je znázorněno na obrázku 2.
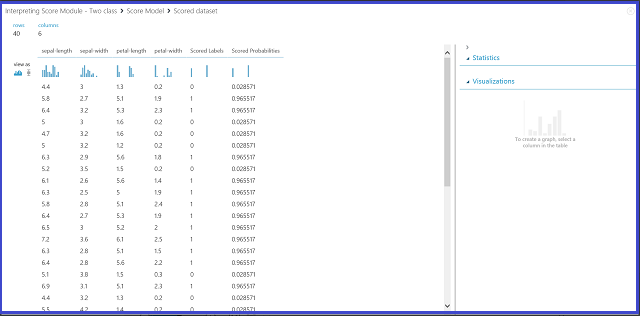
Obrázek č. 2. Vizualizace výsledku skórovacího modelu v klasifikaci se dvěma třídami
Interpretace výsledků
V tabulce výsledků je šest sloupců. Levé čtyři sloupce jsou čtyři funkce. Dva pravé sloupce, Scored Labels a Scored Probabilities, jsou výsledky předpovědi. Sloupec Scored Probabilities (Skóre pravděpodobností) zobrazuje pravděpodobnost, že květina patří do kladné třídy (třída 1). Například první číslo ve sloupci (0,028571) znamená, že existuje pravděpodobnost 0,028571, že první květina patří do třídy 1. Sloupec Označení skóre zobrazuje predikovanou třídu pro každou květinu. Toto je založeno na sloupci nazvaném "Pravděpodobnosti skóre". Pokud je vyhodnocená pravděpodobnost květiny větší jak 0,5, je zařazena jako Třída 1. Jinak se predikuje jako třída 0.
Publikování webové služby
Po pochopení a posouzení výsledků predikce je možné experiment publikovat jako webovou službu, abyste ji mohli nasadit v různých aplikacích a volat ji k získání predikcí tříd na jakékoli nové kosatce iris. Informace o tom, jak změnit trénovací experiment na hodnoticí experiment a publikovat ho jako webovou službu, najdete v kurzu 3: Nasazení modelu úvěrového rizika. Tento postup poskytuje hodnoticí experiment, jak je znázorněno na obrázku 3.
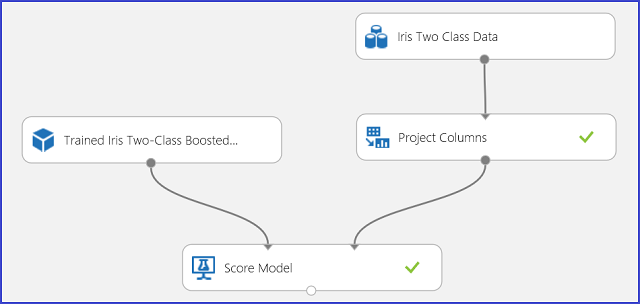
Obrázek č. 3. Hodnocení experimentu s problémem s klasifikací Iris do dvou tříd
Teď potřebujete nastavit vstup a výstup webové služby. Vstup je správný vstupní port Score Modelu, což je vstup s charakteristikami květin Iris. Volba výstupu závisí na tom, jestli vás zajímá predikovaná třída (označená třída), pravděpodobnost přiřazeného skóre, nebo obojí. V tomto příkladu se předpokládá, že vás zajímá obojí. K výběru požadovaných výstupních sloupců použijte modul Vybrat sloupce v sadě dat. Klikněte na Vybrat sloupce v datové sadě, klikněte na Spustit selektor sloupců a vyberte Ohodnocené štítky a Ohodnocené pravděpodobnosti. Po nastavení výstupního portu Vybrat sloupce v datové sadě a jeho opětovném spuštění byste měli být připraveni publikovat experiment vyhodnocování jako webovou službu kliknutím na Publikovat webovou službu. Konečný experiment vypadá jako obrázek 4.
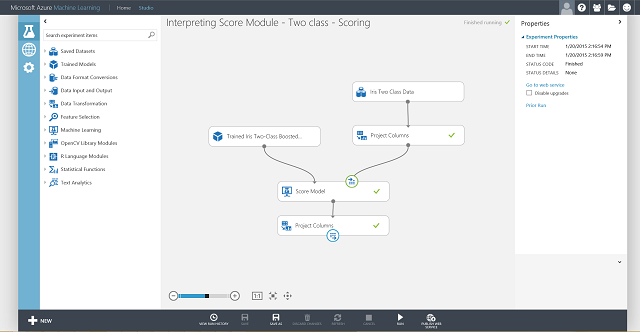
Obrázek č. 4. Konečný experiment s bodováním problému klasifikace iris se dvěma třídami
Po spuštění webové služby a zadání některých hodnot funkcí testovací instance vrátí výsledek dvě čísla. První číslo je označení podle skóre a druhé je pravděpodobnost podle skóre. Tato květina je předpovězena jako třída 1 s pravděpodobností 0,9655.
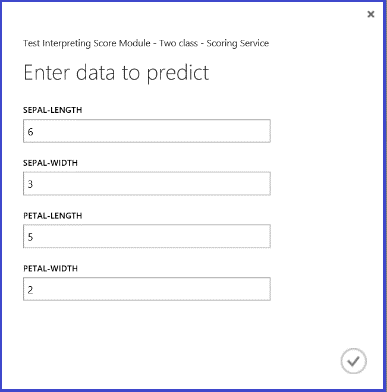

Obrázek č. 5. Výsledek webové služby dvoutřídní klasifikace Iris
Klasifikace s více třídami
Příklad experimentu
V tomto experimentu provedete úlohu rozpoznávání písmen jako příklad klasifikace s více třídami. Klasifikátor se pokusí předpovědět určité písmeno %28class%29 na základě některých ručně psaných hodnot atributů extrahovaných z ručně psaných obrázků.
V trénovacích datech je 16 příznaků extrahovaných z obrázků ručně psaných písmen. 26 písmen tvoří naše 26 tříd. Obrázek 6 ukazuje experiment, který bude trénovat klasifikační model s více třídami pro rozpoznávání písmen a predikovat na stejné sadě funkcí v testovací sadě dat.
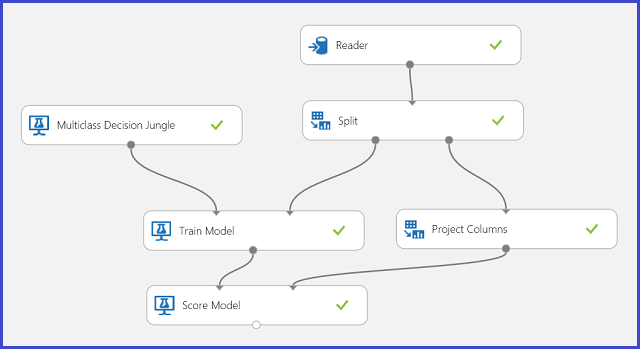
Obrázek č. 6. Experiment s problémem více tříd klasifikace pro rozpoznávání písmen.
Vizualizace výsledků z modulu Určení skóre modelu kliknutím na výstupní port modulu Určení skóre modelu a následným kliknutím na Vizualizovat by se měl zobrazit obsah, jak je znázorněno na obrázku 7.
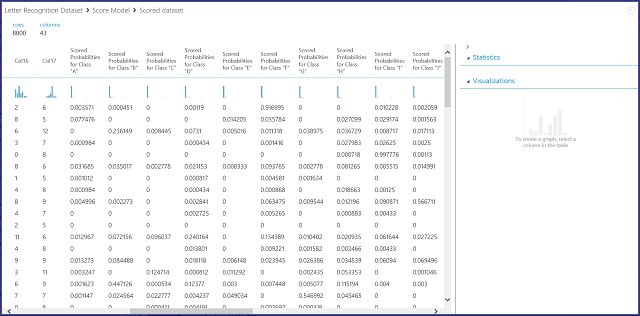
Obrázek 7. Vizualizace výsledků modelu skóre v klasifikaci s více třídami
Interpretace výsledků
Levé 16 sloupců představuje hodnoty funkcí testovací sady. Sloupce s názvy, jako je například Scored Probabilities pro třídu „XX“, jsou stejné jako sloupec Scored Probabilities v případě dvou tříd. Ukazují pravděpodobnost, že odpovídající položka spadá do určité třídy. Například pro první položku existuje pravděpodobnost 0,003571, že se jedná o pravděpodobnost "A", 0,000451, že je to "B", a tak dále. Poslední sloupec (Scored Labels) je stejný jako Scored Labels v dvoutřídním případě. Vybere třídu s největší pravděpodobností skóre jako předpovězenou třídu odpovídající položky. Například pro první položku je označení skóre "F", protože má největší pravděpodobnost být "F" (0,916995).
Publikování webové služby
Můžete také získat označení s hodnocením pro každou položku a pravděpodobnost tohoto označení. Základní logika spočívá v nalezení největší pravděpodobnosti ze všech vyhodnocených pravděpodobností. K tomu je potřeba použít modul Spustit skript jazyka R. Kód R se zobrazuje na obrázku 8 a výsledek experimentu je znázorněn na obrázku 9.

Obrázek 8. Kód R pro extrakci ohodnocených popisků a jejich přidružených pravděpodobností
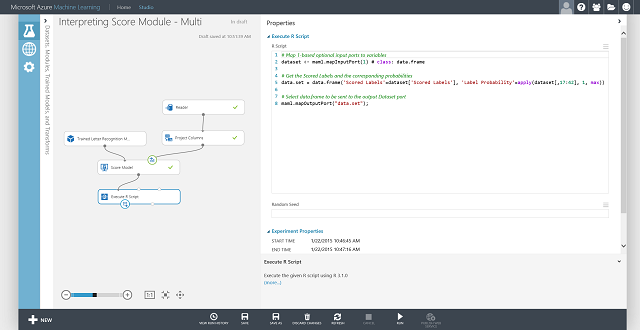
Obrázek 9. Konečný experiment s hodnocením problému vícetřídní klasifikace při rozpoznávání písmen
Po publikování a spuštění webové služby a zadání některých vstupních hodnot funkcí bude vrácený výsledek vypadat jako obrázek 10. Tento rukou psaný dopis, s extrahovanými 16 vlastnostmi, je předpovězen jako "T" s pravděpodobností 0,9715.
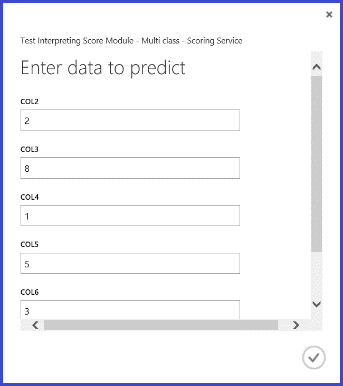

Obrázek 10. Výsledek vícetřídové klasifikace webové služby
Regrese
Regresní problémy se liší od problémů klasifikace. Při klasifikačním problému se snažíte předpovědět diskrétní třídy, například do které třídy patří květina kosatce. Jak ale vidíte v následujícím příkladu problému s regresí, snažíte se předpovědět souvislou proměnnou, například cenu auta.
Příklad experimentu
Jako příklad pro regresi použijte predikci cen automobilů. Snažíte se předpovědět cenu auta na základě jeho funkcí, včetně make, typu paliva, typu těla a hnacího kola. Experiment se zobrazí na obrázku 11.
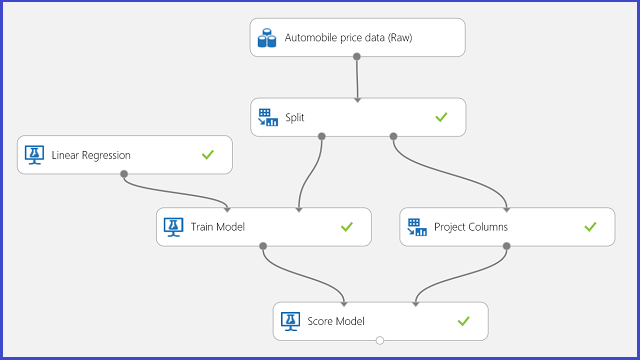
Obrázek 11. Experiment s problémem regresní analýzy cen automobilů
Vizualizace modulu Skóre modelu, výsledek vypadá jako na obrázku 12.
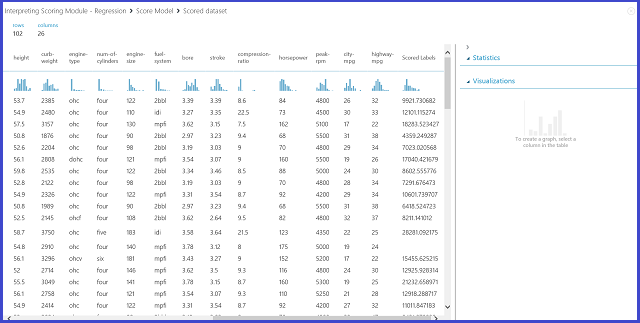
Obrázek 12 Výsledek bodování pro problém predikce cen automobilů
Interpretace výsledků
Skórované popisky jsou výsledným sloupcem ve výsledcích hodnocení. Čísla představují predikovanou cenu pro každé auto.
Publikování webové služby
Regresní experiment můžete publikovat do webové služby a použít jej pro predikci cen automobilů stejným způsobem jako v případu dvoutřídní klasifikace.
Obrázek 13 Vyhodnocení skórovacího experimentu pro regresi cen automobilů
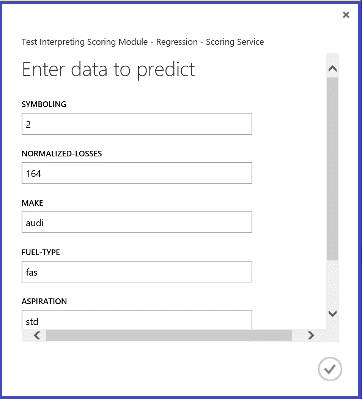
Při spuštění webové služby vypadá vrácený výsledek jako na obrázku 14. Predikovaná cena tohoto auta je 15 085,52 Kč.

Obrázek 14 Výsledek služby webu k analýze regresí cen automobilů
Klastrování
Příklad experimentu
Pojďme znovu použít sadu dat Iris k vytvoření experimentu clusteringu. Tady můžete vyfiltrovat popisky tříd v sadě dat, aby měly jenom funkce a bylo možné je použít pro clustering. V případě použití duhovky zadejte počet shluků na dva během trénovacího procesu, což znamená, že květiny shluknete do dvou tříd. Experiment se zobrazí na obrázku 15.
Experiment s klasifikací Iris
Obrázek 15 Experiment s clusteringem Iris
Clustering se liší od klasifikace v tom, že trénovací datová sada sama o sobě neobsahuje popisky základní pravdy. Clustering seskupí instance trénovacích datových sad do různých clusterů. Během procesu trénování model označí položky tím, že se naučí rozdíly mezi jejich funkcemi. Potom lze natrénovaný model použít k další klasifikaci budoucích položek. V rámci problému s clusteringem máme zájem o dvě části výsledku. První část označuje trénovací datovou sadu a druhá klasifikuje novou datovou sadu pomocí natrénovaného modelu.
Pro vizualizaci první části výsledku je třeba kliknout na levý výstupní port Trénování clusteringového modelu a poté kliknutím na Vizualizovat. Vizualizace je znázorněna na obrázku 16.
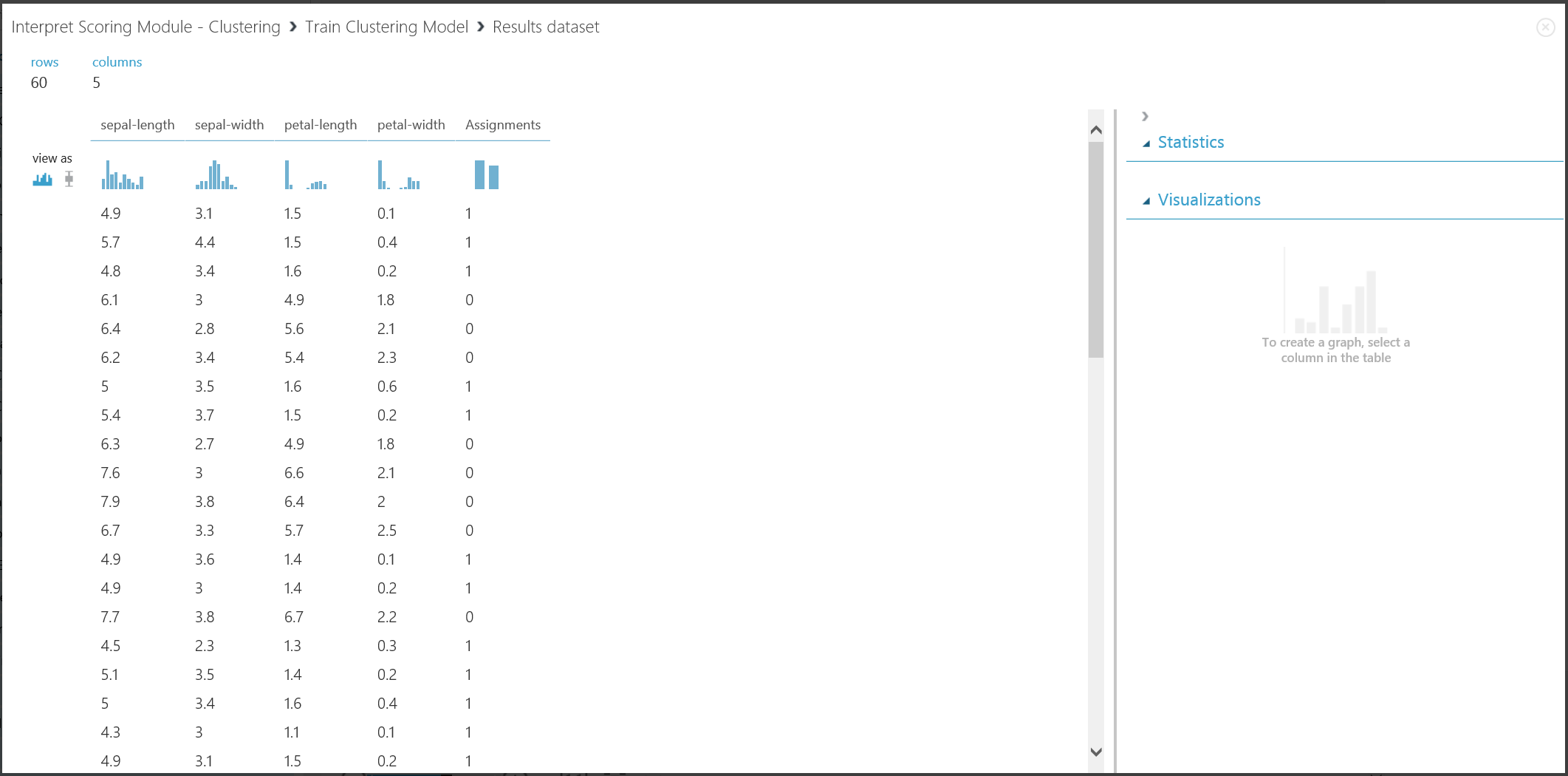
Obrázek 16 Vizualizace výsledku clusteringu pro trénovací sadu dat
Výsledek druhé části, seskupování nových položek s natrénovaným modelem clusteringu, je znázorněno na obrázku 17.
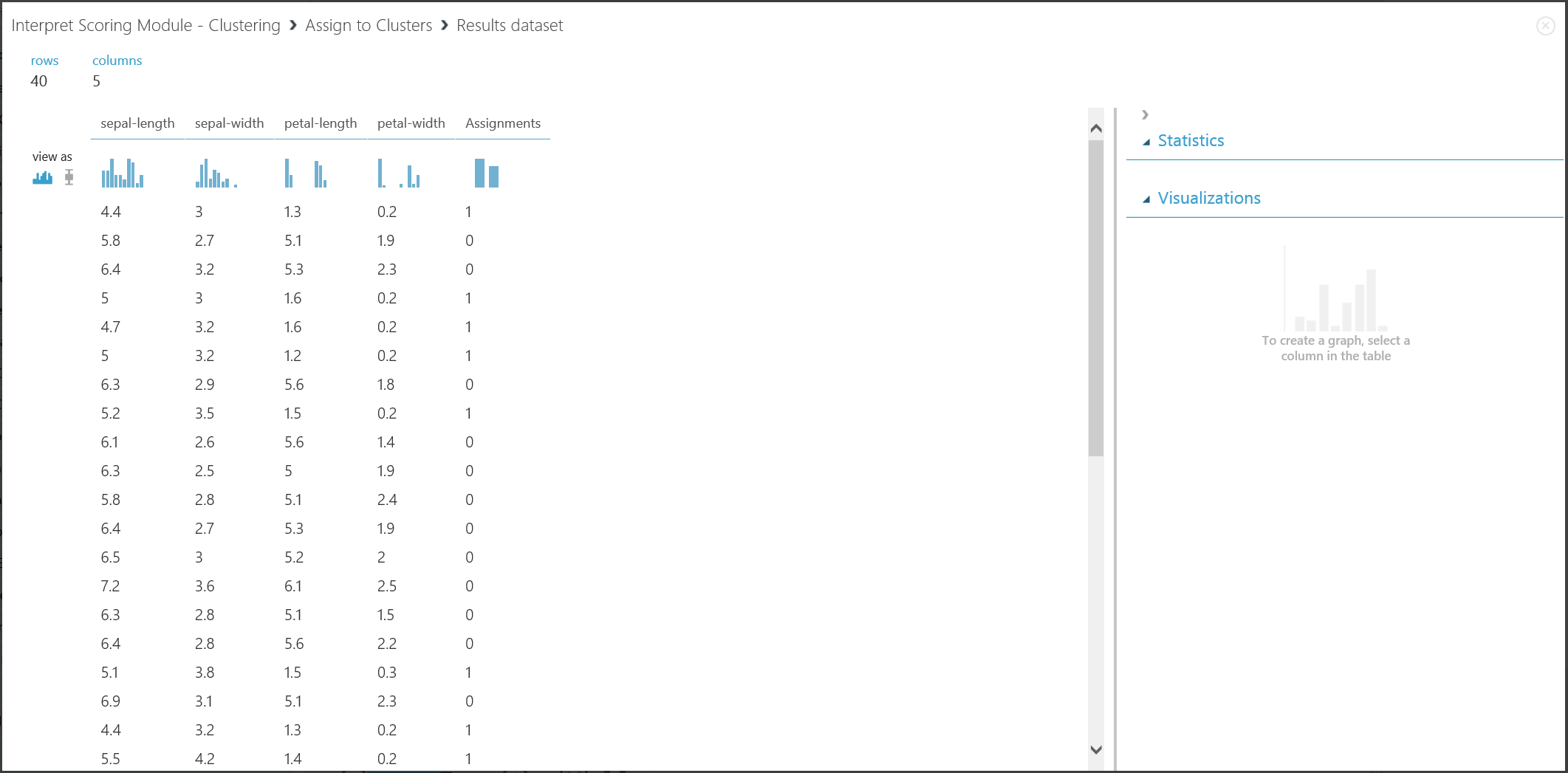
Obrázek 17 Vizualizace výsledku clusteringu v nové sadě dat
Interpretace výsledků
I když výsledky těchto dvou částí pocházejí z různých fází experimentu, vypadají stejně a interpretují se stejným způsobem. První čtyři sloupce jsou vlastnosti. Poslední sloupec, přiřazení, je výsledek předpovědi. Položky přiřazené stejnému číslu se predikují tak, že jsou ve stejném clusteru, to znamená, že sdílejí podobnosti nějakým způsobem (tento experiment používá výchozí metriku vzdálenosti Euklidovské vzdálenosti). Vzhledem k tomu, že jste zadali počet clusterů, které mají být 2, jsou položky v přiřazení označeny buď 0, nebo 1.
Publikování webové služby
Experiment shlukování můžete publikovat do webové služby a používat jej pro předpovědi shlukování stejným způsobem, jakým používáte klasifikaci do dvou tříd.
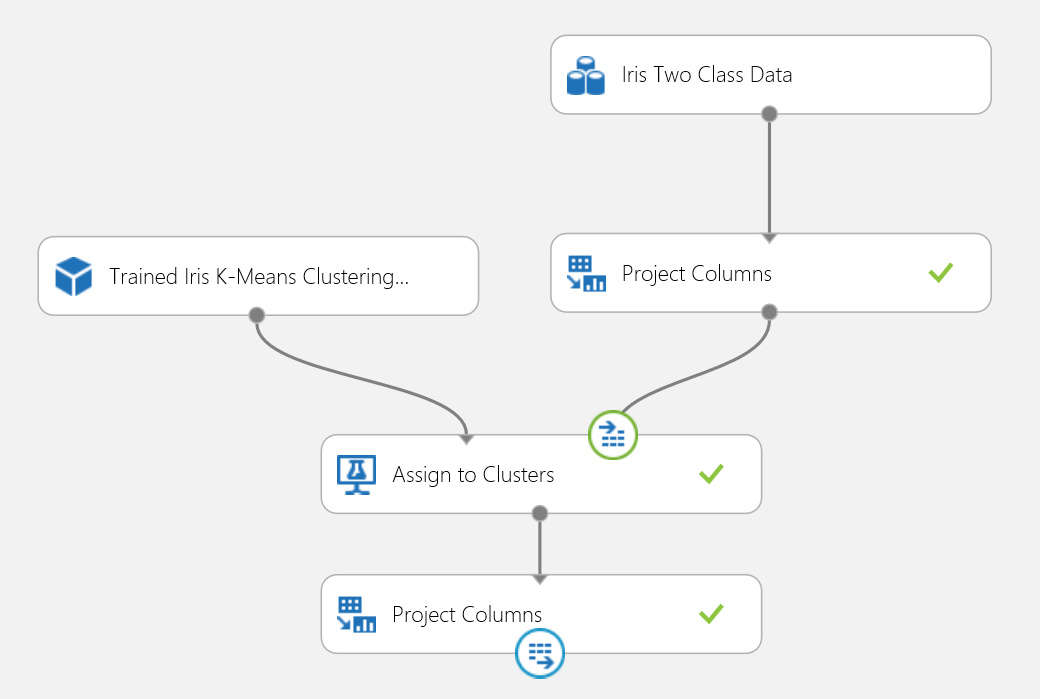
Obrázek 18 Vyhodnocení experimentu s problémem shlukování duhovky
Po spuštění webové služby bude vrácený výsledek vypadat jako obrázek 19. Tato květina je předpovězena, že je v clusteru 0.
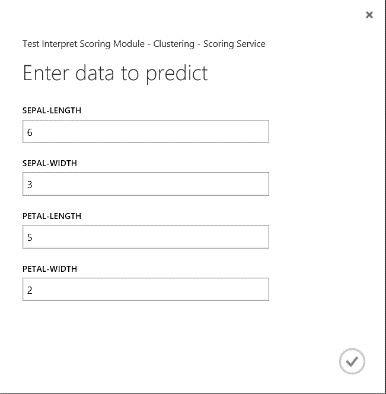

Obrázek 19 Výsledek webové služby dvoutřídní klasifikace Iris
Doporučovací systém
Příklad experimentu
V případě doporučených systémů můžete jako příklad použít problém s doporučením restaurace: můžete zákazníkům doporučit restaurace na základě historie jejich hodnocení. Vstupní data se skládají ze tří částí:
- Hodnocení restaurací od zákazníků
- Data o funkcích zákazníků
- Údaje o jednotlivých prvcích restaurace
S modulem Train Matchbox Recommender v nástroji Machine Learning Studio (classic) můžeme udělat několik věcí:
- Predikce hodnocení pro daného uživatele a položku
- Doporučte položky danému uživateli.
- Vyhledání uživatelů souvisejících s daným uživatelem
- Vyhledání položek souvisejících s danou položkou
Můžete si vybrat, co chcete udělat, výběrem ze čtyř možností v nabídce druhu predikce doporučování. Tady si můžete projít všechny čtyři scénáře.
Typický experiment nástroje Machine Learning Studio (klasický) pro doporučovací systém vypadá jako obrázek 20. Informace o tom, jak tyto moduly doporučovacího systému používat, najdete v tématu Train matchbox recommender and Score matchbox recommender.
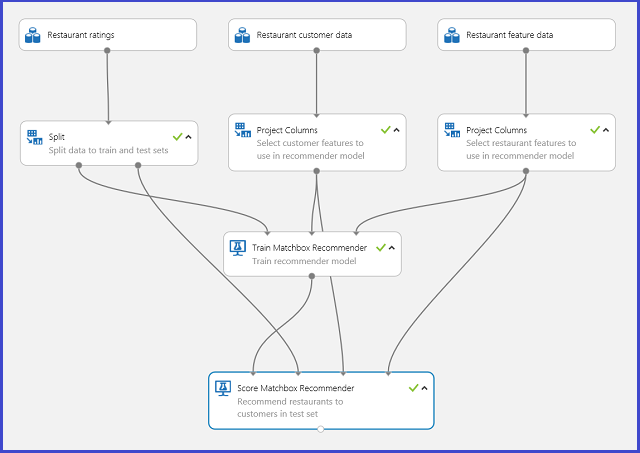
Obrázek 20 Experiment doporučeného systému
Interpretace výsledků
Predikce hodnocení pro daného uživatele a položku
Výběrem možnosti Predikce hodnocení v části Druh predikce doporučovacího nástroje žádáte doporučovací systém, aby předpověděl hodnocení pro daného uživatele a položku. Vizualizace výstupu nástroje Score Matchbox Recommender vypadá jako Obrázek 21.
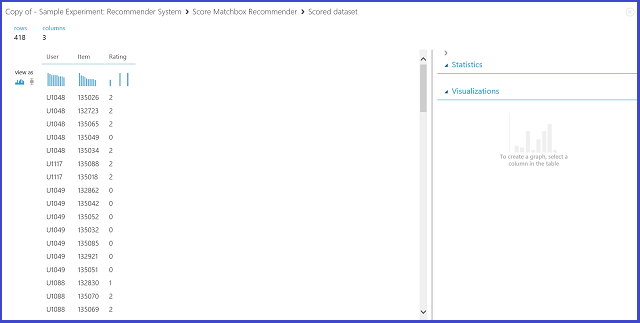
Obrázek 21 Vizualizace výsledku skóre doporučeného systému – předpověď hodnocení
První dva sloupce jsou páry položek uživatele poskytnuté vstupními daty. Třetí sloupec je predikované hodnocení uživatele pro určitou položku. Například v prvním řádku se u zákazníka U1048 předpovídá hodnocení restaurace 135026 jako 2.
Doporučte položky danému uživateli.
Výběrem Doporučení položek pod Typ predikce doporučení žádáte doporučovací systém, aby doporučoval položky konkrétnímu uživateli. Posledním parametrem, který chcete zvolit v tomto scénáři, je doporučený výběr položky. Možnost Z hodnocených položek (pro vyhodnocení modelu) je primárně určená pro vyhodnocení modelu během procesu trénování. Pro tuto fázi předpovědi zvolíme Ze všech položek. Vizualizace výstupu doporučovacího modulu Score Matchbox vypadá jako obrázek 22.
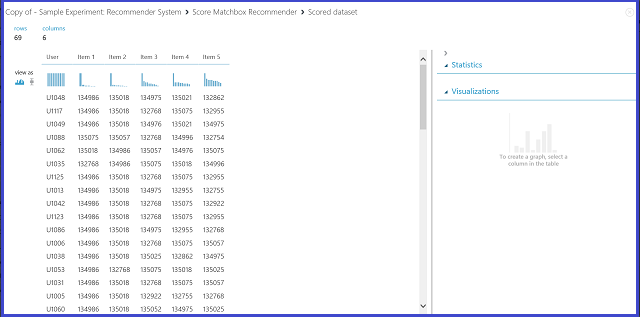
Obrázek 22 Vizualizace výsledku skóre doporučovacího systému – doporučení položky
První ze šesti sloupců představuje daná ID uživatelů, která doporučí položky, jak jsou poskytována vstupními daty. Ostatních pět sloupců představuje položky doporučené uživateli v sestupném pořadí relevance. Například v prvním řádku je doporučená restaurace pro zákazníka U1048 134986 následovaná 135018, 134975, 135021 a 132862.
Vyhledání uživatelů souvisejících s daným uživatelem
Výběrem možnosti Související uživatelé v části Druh predikce Doporučeného uživatele žádáte doporučovací systém, aby našel související uživatele s daným uživatelem. Související uživatelé jsou uživatelé, kteří mají podobné preference. Posledním parametrem, který chcete zvolit v tomto scénáři, je Výběr souvisejícího uživatele. Možnost Od uživatelů, kteří hodnotili položky (pro hodnocení modelu) je primárně určená pro hodnocení modelu v průběhu trénování. Pro tuto fázi predikce zvolte Ze všech uživatelů. Vizualizace výstupu doporučovacího modulu Score Matchbox vypadá jako obrázek 23.
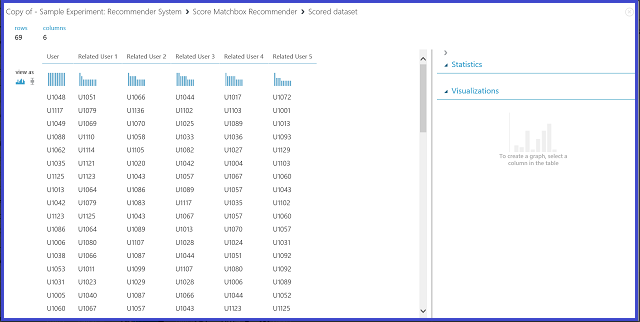
Obrázek 23 Vizualizujte výsledky skóre uživatelů souvisejících s doporučovacím systémem
První ze šesti sloupců zobrazuje daná ID uživatelů potřebná k vyhledání souvisejících uživatelů, jak jsou poskytována vstupními daty. Ostatní pět sloupců ukládají predikované související uživatele uživatele v sestupném pořadí podle relevance. Například v prvním řádku je nejrelevavantnější zákazník pro zákazníka U1048 U1051, následovaný U1066, U1044, U1017 a U1072.
Vyhledání položek souvisejících s danou položkou
Výběrem možnosti Související položky v části Druh predikce doporučujícího se žádáte, aby systém doporučovačů našel související položky s danou položkou. Související položky jsou položky, které se s největší pravděpodobností líbí stejnému uživateli. Posledním parametrem, který chcete zvolit v tomto scénáři, je výběr související položky. Možnost Z hodnocených položek (pro vyhodnocení modelu) je primárně určená pro vyhodnocení modelu během procesu trénování. Pro tuto fázi predikce zvolíme Ze všech položek. Vizualizace výstupu doporučovacího modulu Score Matchbox vypadá jako obrázek 24.
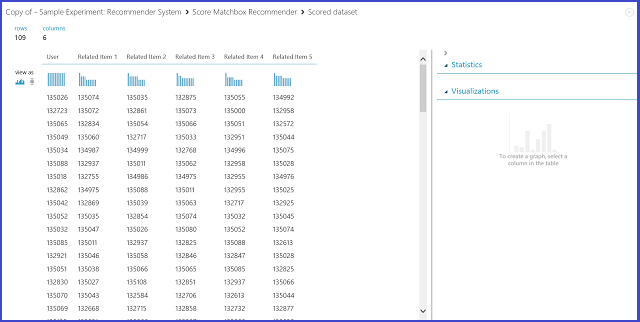
Obrázek 24 Vizualizace výsledků skóre doporučovacího systému - související položky
První ze šesti sloupců představuje daná ID položek potřebná k vyhledání souvisejících položek, jak jsou poskytována vstupními daty. Ostatních pět sloupců ukládá předpovězené související položky v sestupném pořadí podle relevance. Například v prvním řádku je nejrelevavantnější položka pro položku 135026 135074, za kterou následuje 135035, 132875, 135055 a 134992.
Publikování webové služby
Proces publikování těchto experimentů jako webových služeb pro získání předpovědí je podobný pro každý ze čtyř scénářů. Tady jako příklad vezmeme druhý scénář (doporučíme položky danému uživateli). Můžete postupovat stejným postupem s ostatními třemi.
Uložte natrénovaný doporučovací systém jako model a filtrujte vstupní data na jeden sloupec s ID uživatele podle požadavku. Experiment můžete připojit jako na obrázku 25 a publikovat ho jako webovou službu.
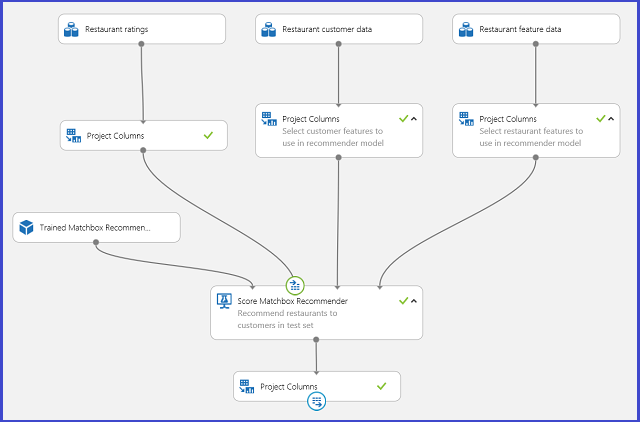
Obrázek 25 Hodnocení experimentu s problémem doporučení restaurace
Při spuštění webové služby vypadá vrácený výsledek jako na obrázku 26. Pět doporučených restaurací pro uživatele U1048 je 134986, 135018, 134975, 135021 a 132862.
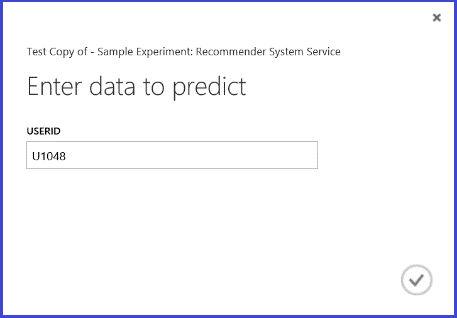

Obrázek 26 Výsledek problému s doporučením restaurace z webové služby