Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Spravovaná instance
Spravovaná instance![]() Azure SQLDatabáze SQL v Microsoft Fabric
Azure SQLDatabáze SQL v Microsoft Fabric
Návrh efektivních indexů je klíčem k dosažení dobrého výkonu databáze a aplikace. Nedostatek indexů, nadměrné indexování nebo špatně navržené indexy jsou hlavními zdroji problémů s výkonem databáze.
Tato příručka popisuje architekturu indexů a základy a poskytuje osvědčené postupy, které vám pomůžou navrhnout efektivní indexy tak, aby vyhovovaly potřebám vašich aplikací.
Další informace o dostupných typech indexů naleznete v tématu Indexy.
Tato příručka popisuje následující typy indexů:
| Formát primárního úložiště | Typ indexu |
|---|---|
| Úložiště řádků založené na disku | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Seskupený sloupcový úložiště | |
| Neclustered columnstore | |
| Memory-optimized | |
| Hash | |
| Optimalizované pro paměť neclusterované |
Informace o indexech XML naleznete v tématu INDEXY XML (SQL Server) a selektivní indexy XML (SXI).
Informace o prostorových indexech naleznete v tématu Přehled prostorových indexů.
Pro informace o fulltextových indexech viz Naplnění indexů Full-Text.
Základy indexu
Zamyslete se nad běžnou knihou: na konci knihy je rejstřík, který pomáhá rychle najít informace v knize. Index je seřazený seznam klíčových slov a vedle každého klíčového slova je sada čísel stránek odkazující na stránky, kde lze najít jednotlivá klíčová slova.
Index rowstore je podobný: jedná se o uspořádaný seznam hodnot a pro každou hodnotu jsou ukazatele na datové stránky , kde se tyto hodnoty nacházejí. Samotný index se také ukládá na stránkách, které se označují jako indexové stránky. Pokud index v běžné knize zahrnuje více stránek a musíte najít ukazatele na všechny stránky, které obsahují slovo SQL , například byste museli listovat od začátku indexu, dokud nenajdete indexovou stránku, která obsahuje klíčové slovo SQL. Odtud budete postupovat podle ukazatelů na všechny stránky knihy. To by mohlo být optimalizováno dále, pokud na začátku indexu vytvoříte jednu stránku, která obsahuje abecední seznam, kde lze najít každé písmeno. Příklad: "A až D - strana 121", "E až G - strana 122" atd. Tato extra stránka by eliminovala krok procházení indexu, aby se zjistilo počáteční místo. Taková stránka v pravidelných knihách neexistuje, ale existuje v indexu rowstore. Tato jedna stránka se označuje jako kořenová stránka indexu. Kořenová stránka je počáteční stránkou struktury stromu, kterou používá index. Po analogii stromu se koncové stránky, které obsahují ukazatele na skutečná data, označují jako "listové stránky" stromu.
Index je struktura na disku nebo v paměti přidružená k tabulce nebo zobrazení, která urychluje načítání řádků z tabulky nebo zobrazení. Index rowstore obsahuje klíče vytvořené z hodnot v jednom nebo více sloupcích v tabulce nebo zobrazení. U indexů rowstore jsou tyto klíče uložené ve stromové struktuře (strom B+), která databázovému stroji umožňuje rychle a efektivně najít řádky přidružené k hodnotám klíče.
Index rowstore ukládá data logicky uspořádaná jako tabulka s řádky a sloupci a fyzicky uložená v datovém formátu, který se nazývá rowstore1. Existuje alternativní způsob, jak ukládat sloupce dat, označované jako columnstore.
Návrh správných indexů pro databázi a její úlohy je složitým vyrovnáváním mezi rychlostí dotazů, náklady na aktualizaci indexu a náklady na úložiště. Úzké indexy úložiště řádků založené na disku nebo indexy s několika sloupci v klíči indexu vyžadují méně místa úložiště a menší režijní náklady na aktualizaci. Široké indexy na druhou stranu můžou zlepšit více dotazů. Před nalezením nejúčinnější sady indexů možná budete muset experimentovat s několika různými návrhy. S vývojem aplikace se indexy můžou muset změnit, aby se zachoval optimální výkon. Indexy je možné přidávat, upravovat a odebírat, aniž by to mělo vliv na návrh schématu databáze nebo aplikace. Proto byste neměli váhat experimentovat s různými indexy.
Optimalizátor dotazů v databázovém stroji obvykle zvolí nejúčinnější indexy pro spuštění dotazu. Pokud chcete zjistit, které indexy optimalizátor dotazů používá pro konkrétní dotaz, v aplikaci SQL Server Management Studio v nabídce Dotaz vyberte Zobrazit odhadovaný plán provádění nebo zahrnout skutečný plán provádění.
Nepoužívejte vždy rovnaní využití indexů s dobrým výkonem a dobrým výkonem s efektivním využitím indexu. Pokud by použití indexu vždy pomohlo dosáhnout nejlepšího výkonu, úloha optimalizátoru dotazů by byla jednoduchá. Ve skutečnosti může nesprávná volba indexu způsobit méně než optimální výkon. Proto je úkolem optimalizátoru dotazů vybrat index nebo kombinaci indexů, pouze pokud zlepšuje výkon, a vyhnout se indexovaným načítáním, pokud brání výkonu.
Běžnou chybou návrhu je vytvoření mnoha indexů spekulativním způsobem, aby se "optimalizátoru daly volby". Výsledné přeindexování zpomalí úpravy dat a může způsobit problémy s souběžností.
Úložiště řádků 1 bylo tradičním způsobem ukládání dat relační tabulky. Úložiště řádků odkazuje na tabulku, ve které je podkladovým formátem úložiště dat halda, strom B+ (clusterovaný index) nebo tabulka optimalizovaná pro paměť. Úložiště řádků založené na disku vylučuje tabulky optimalizované pro paměť.
Úlohy návrhu indexu
Následující úlohy tvoří naši doporučenou strategii návrhu indexů:
Seznamte se s charakteristikami databáze a aplikace.
Například v databázi online zpracování transakcí (OLTP) s častými úpravami dat, které musí udržovat vysokou propustnost, několik úzkých indexů rowstore cílených na nejdůležitější dotazy by bylo dobrým počátečním návrhem indexu. Pro extrémně vysokou propustnost zvažte tabulky a indexy optimalizované pro paměť, které poskytují návrh bez zámků a západek. Další informace naleznete v tématu Pokyny pro návrh neclusterovaného indexu optimalizované pro paměť a pokyny k návrhu indexu hash v této příručce.
Naopak pro databázi analýz nebo datových skladů (OLAP), která musí rychle zpracovávat velmi velké datové sady, by bylo obzvláště vhodné použít clusterované indexy columnstore. Další informace najdete v tématu Indexy Columnstore: přehled nebo architektura indexu Columnstore v této příručce.
Seznamte se s charakteristikami nejčastěji používaných dotazů.
Když například víte, že často používaný dotaz spojuje dvě nebo více tabulek, pomůže vám určit sadu indexů pro tyto tabulky.
Seznamte se s distribucí dat ve sloupcích použitých v predikátech dotazu.
Například index může být užitečný pro sloupce s mnoha odlišnými datovými hodnotami, ale méně tak pro sloupce s mnoha duplicitními hodnotami. Pro sloupce s mnoha seznamy NUL nebo pro sloupce s dobře definovanými podmnožinami dat můžete použít filtrovaný index. Další informace naleznete v tématu Filtrované pokyny k návrhu indexu v této příručce.
Určete, které možnosti indexu můžou zvýšit výkon.
Například vytvoření clusterovaného indexu u existující velké tabulky může těžit z možnosti indexu
ONLINE. TatoONLINEmožnost umožňuje, aby souběžná aktivita na podkladových datech pokračovala, zatímco se index vytváří nebo znovu sestavuje. Použití komprese dat řádků nebo stránek může zvýšit výkon snížením vstupně-výstupních operací a paměti indexu. Další informace naleznete v tématu CREATE INDEX.Prozkoumejte existující indexy v tabulce, abyste zabránili vytváření duplicitních nebo velmi podobných indexů.
Často je lepší upravit existující index než vytvořit nový, ale většinou duplicitní index. Zvažte například přidání jednoho nebo dvou sloupců navíc do existujícího indexu místo vytvoření nového indexu s těmito sloupci. To je zvlášť důležité, pokud ladíte neclusterované indexy s chybějícími návrhy indexů, nebo pokud používáte Poradce pro ladění databázového stroje, kde můžete být nabízeny podobné varianty indexů ve stejné tabulce a sloupcích.
Obecné pokyny pro návrh indexu
Pochopení charakteristik databáze, dotazů a sloupců tabulek vám může pomoct při počátečním návrhu optimálních indexů a úpravě návrhu při vývoji vašich aplikací.
Důležité informace o databázi
Při návrhu indexu zvažte následující pokyny k databázi:
Velký počet indexů v tabulce ovlivňuje výkon
INSERT,UPDATE,DELETEaMERGEpříkazy, protože data v indexech se můžou muset změnit, protože data v tabulce se mění. Pokud je například sloupec použit v několika indexech a spustíteUPDATEpříkaz, který upraví data daného sloupce, musí být také aktualizován každý index obsahující tento sloupec.Vyhněte se příliš indexování silně aktualizovaných tabulek a udržujte indexy úzké, to znamená s co nejnižším množstvím sloupců.
Na tabulkách, které mají málo úprav dat, ale velké objemy dat, můžete mít více indexů. U takových tabulek může široká škála indexů zlepšit výkon dotazů, zatímco náklady na aktualizaci indexu zůstávají přijatelné. Nevytvávejte indexy spekulativním způsobem. Monitorujte využití indexů a v průběhu času odeberte nepoužívané indexy.
Indexování malých tabulek nemusí být optimální, protože databázovému stroji může trvat delší dobu, než bude procházet index vyhledáváním dat, než provést prohledávání základní tabulky. Proto se indexy u malých tabulek nemusí používat, ale musí se aktualizovat, protože se aktualizují data v tabulce.
Indexy v zobrazení můžou poskytovat významné zvýšení výkonu, když zobrazení obsahuje agregace nebo spojení. Další informace najdete v tématu Vytvoření indexovaných zobrazení.
Databáze na primárních replikách ve službě Azure SQL Database automaticky generují doporučení výkonu od poradce pro indexy. Volitelně můžete povolit automatické ladění indexu.
Úložiště dotazů pomáhá identifikovat dotazy s neoptimálním výkonem a poskytuje historii plánů spouštění dotazů , které umožňují zobrazit indexy vybrané optimalizátorem. Pomocí těchto dat můžete provádět změny optimalizace indexu nejvýrazněji tím, že se zaměříte na nejčastější dotazy a dotazy využívající prostředky.
Úvahy o dotazech
Při návrhu indexu zvažte následující pokyny pro dotazy:
Vytvořte neclusterované indexy ve sloupcích, které se často používají v predikátech a spojují výrazy v dotazech. Jedná se o SARGable sloupce. Neměli byste ale přidávat nepotřebné sloupce do indexů. Přidání příliš velkého počtu sloupců indexu může nepříznivě ovlivnit výkon místa na disku a aktualizace indexu.
Termín SARGable v relačních databázích odkazuje na predikát Search ARGschopný predikát, který může použít index ke zrychlení provádění dotazu. Další informace najdete v průvodci návrhem a architekturou indexu SQL SQL a SQL.
Tip
Vždy se ujistěte, že úlohy dotazu skutečně používají indexy, které vytvoříte. Zahoďte nepoužité indexy.
Statistiky využití indexů jsou k dispozici v sys.dm_db_index_usage_stats a sys.dm_db_index_operational_stats.
Pokrytí indexů může zlepšit výkon dotazů, protože všechna data potřebná ke splnění požadavků dotazu existují v rámci samotného indexu. To znamená, že k načtení požadovaných dat jsou vyžadovány pouze indexové stránky, nikoli datové stránky tabulky nebo clusterovaného indexu; tím snižuje celkový počet vstupně-výstupních operací disku. Například dotaz na sloupce
AaBna tabulku, která má složený index vytvořený ve sloupcíchA,BaCmůže načíst zadaná data z samotného indexu.Note
Krytýindex je neclusterovaný index, který splňuje veškerý přístup k datům dotazem přímo bez přístupu k základní tabulce.
Tyto indexy mají všechny potřebné sloupce SARGable v klíči indexu a sloupce bez SARGable jako zahrnuté sloupce. To znamená, že všechny sloupce, které dotaz potřebuje, buď v
WHEREklauzulích ,JOINaGROUP BYklauzulích, nebo vSELECTUPDATEklauzulích, jsou přítomné v indexu.To může znamenat podstatně menší vstupně-výstupní operace při provedení dotazu, pokud je index omezený ve srovnání s řádky a sloupci v samotné tabulce, tedy že zahrnuje pouze malou část všech sloupců.
Zvažte pokrytí indexů při načítání malé části velké tabulky a tam, kde je tato malá část definovaná pevným predikátem.
Vyhněte se vytváření krytého indexu s příliš mnoha sloupci, protože snižuje jeho výhodu při nafouknutí úložiště databáze, vstupně-výstupních operací a paměti.
Pište dotazy, které v jednom příkazu vkládají nebo upravují co nejvíce řádků, místo použití více dotazů k aktualizaci stejných řádků. Tím se sníží režijní náklady na aktualizace indexu.
Úvahy o sloupcích
Při návrhu indexu zvažte následující pokyny pro sloupce:
Udržujte délku klíče indexu krátkou, zejména pro clusterové indexy.
Sloupce, které jsou typu ntext, text, obrázek, varchar(max), nvarchar(max), varbinary(max), json a vektorové datové typy nelze zadat jako sloupce klíče indexu. Sloupce s těmito datovými typy se ale dají přidat do neclusterovaného indexu jako sloupce indexu bez klíče (zahrnuté). Další informace najdete v části Použití zahrnutých sloupců v neclusterovaných indexech v této příručce.
Prozkoumejte jedinečnost sloupce. Jedinečný index místo neunique indexu ve stejných klíčových sloupcích poskytuje další informace pro optimalizátor dotazů, díky kterému je index užitečnější. Další informace naleznete v tématu Jedinečné pokyny k návrhu indexu v tomto průvodci.
Prozkoumejte distribuci dat ve sloupci. Vytvoření indexu ve sloupci s mnoha řádky, ale málo jedinečných hodnot nemusí zvýšit výkon dotazů, i když je index používán optimalizátorem dotazů. Jako příklad, fyzický telefonní seznam seřazený abecedně podle příjmení neurychlí nalezení osoby, pokud se všichni lidé ve městě jmenují Smith nebo Jones. Další informace o distribuci dat naleznete v tématu Statistika.
Zvažte použití filtrovaných indexů u sloupců, které mají dobře definované podmnožina, například sloupce s mnoha hodnotami NUL, sloupce s kategoriemi hodnot a sloupce s odlišnými rozsahy hodnot. Dobře navržený filtrovaný index může zlepšit výkon dotazů, snížit náklady na aktualizace indexu a snížit náklady na úložiště tím, že uloží malou podmnožinu všech řádků v tabulce, pokud je tato podmnožina relevantní pro mnoho dotazů.
Pokud klíč obsahuje více sloupců, zvažte pořadí sloupců klíče indexu. Sloupec, který je použit v predikátu dotazu v rovném (
=), nerovném (>,>=,<,<=) neboBETWEENvýrazu, nebo se účastní spojení, by měl být umístěn jako první. Další sloupce by se měly řadit na základě jejich úrovně jedinečnosti, tj. od těch nejvýraznějších po nejméně odlišné.Pokud je například index definován jako
LastName,FirstName, je index užitečný, pokud je predikát dotazu v klauzuliWHEREWHERE LastName = 'Smith'neboWHERE LastName = Smith AND FirstName LIKE 'J%'. Optimalizátor dotazů by ale index nepoužil pro dotaz, který prohledál pouzeWHERE FirstName = 'Jane'dotaz, nebo by index nezlepšil výkon takového dotazu.Pokud jsou zahrnuté do predikátů dotazů, zvažte indexování počítaných sloupců. Další informace najdete v tématu Indexy ve vypočítaných sloupcích.
Charakteristiky indexu
Jakmile zjistíte, že je index vhodný pro dotaz, můžete vybrat typ indexu, který nejlépe vyhovuje vaší situaci. Mezi charakteristiky indexu patří:
- Clusterované nebo neclusterované
- Jedinečné nebo neunique
- Jeden sloupec nebo vícesloupcový
- Vzestupné nebo sestupné pořadí pro klíčové sloupce v indexu
- Všechny řádky nebo filtrované pro neclusterované indexy
- Columnstore nebo rowstore (úložiště sloupců nebo úložiště řádků)
- Hodnota hash nebo neclusterovaná pro tabulky optimalizované pro paměť
Umístění indexu u skupin souborů nebo schémat oddílů
Při vývoji strategie návrhu indexu byste měli zvážit umístění indexů do skupin souborů přidružených k databázi.
Ve výchozím nastavení jsou indexy uložené ve stejné skupině souborů jako základní tabulka (clusterovaný index nebo halda), na které se index vytvoří. Jsou možné i další konfigurace, mezi které patří:
Vytvořte neclusterované indexy v jiné skupině souborů, než je skupina souborů základní tabulky.
Rozdělte clusterované a neclusterované indexy tak, aby přesahovaly více skupin souborů.
U tabulek, které nejsou rozděleny na oddíly, je nejjednodušší přístup obvykle nejlepší: vytvořit všechny tabulky na stejném filegroupu a přidat do filegroupu tolik datových souborů, kolik je potřeba k využití veškerého dostupného fyzického úložiště.
Pokročilejší přístupy k umístění indexů je možné zvážit, když je k dispozici vrstvené úložiště. Můžete například vytvořit skupinu souborů pro často používané tabulky se soubory na rychlejších discích a skupinu souborů pro archivační tabulky na pomalejších discích.
Tabulku s clusterovaným indexem můžete přesunout z jedné skupiny souborů do druhé přetažením clusterovaného indexu a zadáním nového schématu skupiny souborů nebo oddílu v MOVE TO klauzuli DROP INDEX příkazu nebo pomocí CREATE INDEX příkazu s DROP_EXISTING klauzulí.
Dělené indexy
Můžete také zvážit dělení diskových hald, clusterovaných a neclusterovaných indexů napříč několika skupinami souborů. Rozdělené indexy jsou rozdělené vodorovně (podle řádků) na základě funkce pro rozdělení. Funkce oddílu definuje, jak se každý řádek mapuje na oddíl na základě hodnot určitého sloupce, který určíte, označovaného jako sloupec dělení. Schéma oddílů určuje mapování sady oddílů na skupinu souborů.
Rozdělení indexu může přinést následující výhody:
Zjednodušit správu velkých databází. Systémy OLAP mohou například implementovat ETL pracující s oddíly, které výrazně zjednodušují hromadné přidávání a odebírání dat.
Urychlte spouštění určitých typů dotazů, jako jsou dlouhotrvající analytické dotazy. Když dotazy používají dělený index, databázový stroj může zpracovat více oddílů najednou a přeskočit (eliminovat) oddíly, které dotaz nepotřebuje.
Výstraha
Dělení zřídka zvyšuje výkon dotazů v systémech OLTP, ale může představovat významnou režii, pokud transakční dotaz musí přistupovat k mnoha oddílům.
Další informace najdete v tématu Dělené tabulky a indexy.
Pokyny pro návrh pořadí řazení indexu
Při definování indexů zvažte, jestli má být každý sloupec klíče indexu uložen ve vzestupném nebo sestupném pořadí. Výchozí nastavení je vzestupně. Syntaxe CREATE INDEX, CREATE TABLEa ALTER TABLE příkazy podporuje klíčová slova ASC (vzestupně) a DESC (sestupně) u jednotlivých sloupců v indexech a omezeních.
Určení pořadí, ve kterém jsou hodnoty klíčů uloženy v indexu, je užitečné, když dotazy odkazující na tabulku obsahují ORDER BY klauzule, které určují různé směry pro klíčový sloupec nebo sloupce v daném indexu. V těchto případech může index odebrat potřebu operátoruřazení v plánu dotazu.
Například kupující v nákupním oddělení Adventure Works Cycles musí vyhodnotit kvalitu produktů, které nakupují od dodavatelů. Kupující se nejvíce zajímají o hledání produktů odeslaných dodavateli s vysokou sazbou zamítnutí.
Jak je znázorněno v následujícím dotazu na ukázkovou databázi AdventureWorks, načtení dat tak, aby splňovala tato kritéria, vyžaduje RejectedQty řazení sloupce v Purchasing.PurchaseOrderDetail tabulce sestupně (velké až malé) a ProductID sloupec, který se má seřadit vzestupně (malé až velké).
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Následující plán provádění pro tento dotaz ukazuje, že optimalizátor dotazu použil operátor Sort k vrácení sady výsledků v pořadí určeném ORDER BY klauzulí.

Pokud se vytvoří index rowstore založený na disku s klíčovými sloupci, které odpovídají sloupcům v ORDER BY klauzuli v dotazu, operátor Sort v plánu dotazu se eliminuje a tím se plán dotazu zefektivňuje.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Po opětovném spuštění dotazu následující plán spuštění ukazuje, že operátor Sort již neexistuje a nově vytvořený neclusterovaný index se použije.
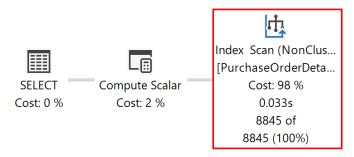
Databázový stroj může prohledávat index v obou směrech. Index definovaný jako RejectedQty DESC, ProductID ASC lze stále použít pro dotaz, ve kterém jsou směry řazení sloupců v ORDER BY klauzuli obráceny. Například dotaz s ORDER BY klauzulí ORDER BY RejectedQty ASC, ProductID DESC může použít stejný index.
Pořadí řazení lze zadat pouze pro klíčové sloupce v indexu. Katalogové zobrazení sys.index_columns uvádí, zda je indexový sloupec uložen ve vzestupném nebo sestupném pořadí.
Pokyny pro návrh clusterovaného indexu
Clusterovaný index ukládá všechny řádky a všechny sloupce tabulky. Řádky jsou seřazené v pořadí hodnot klíče indexu. Pro každou tabulku může existovat pouze jeden clusterovaný index.
Base table může odkazovat buď na uspořádaný index, nebo na haldu. Halda je neseřazená datová struktura na disku, která obsahuje všechny řádky a všechny sloupce tabulky.
S několika výjimkami by každá tabulka měla mít clusterovaný index. Žádoucí vlastnosti clusterovaného indexu jsou:
| Vlastnictví | Description |
|---|---|
| Úzký | Clusterovaný indexový klíč je součástí jakéhokoli neclusterovaného indexu ve stejné základní tabulce. Úzký klíč nebo klíč, kde je celková délka sloupců klíčů malá, snižuje velikost úložiště, vstupně-výstupních operací a režijních nákladů na paměť všech indexů v tabulce. Pokud chcete vypočítat délku klíče, přidejte velikosti úložiště pro datové typy používané klíčovými sloupci. Další informace naleznete v tématu Kategorie datových typů. |
| Jedinečný | Pokud clusterovaný index není jedinečný, automaticky se do klíče indexu přidá 4 bajtový interní jedinečný sloupec, aby se zajistila jedinečnost. Přidáním existujícího jedinečného sloupce do clusterovaného indexového klíče se vyhnete režii úložiště, paměti a vstupně-výstupních operací sloupce 'uniqueifier' ve všech indexech v tabulce. Optimalizátor dotazů navíc může vygenerovat efektivnější plány dotazů, pokud je index jedinečný. |
| Stále rostoucí | V neustále se zvyšujícím indexu se data vždy přidávají na poslední stránce indexu. Tím se zabrání rozdělení stránek uprostřed indexu, což snižuje hustotu stránky a snižuje výkon. |
| Neměnný | Clusterovaný indexový klíč je součástí jakéhokoli neclusterovaného indexu. Když dojde ke změně klíčového sloupce clusterovaného indexu, je potřeba provést změnu také ve všech neclusterovaných indexech, které přidávají režijní náklady na procesor, protokolování, vstupně-výstupní operace a paměť. Režijní náklady se vyhnete, pokud jsou klíčové sloupce clusterovaného indexu neměnné. |
| Obsahuje pouze sloupce, které nemohou být null. | Pokud má řádek sloupce s možnou hodnotou null, musí obsahovat interní strukturu nazvanou blok NULL, který přidá 3–4 bajty úložiště na řádek v indexu. Pokud uděláte všechny sloupce clusterovaného indexu nenulové, vyhnete se této režii. |
| Má pouze sloupce s pevnou šířkou. | Sloupce využívající datové typy s proměnlivou šířkou, jako je varchar nebo nvarchar , používají další 2 bajty na hodnotu v porovnání s datovými typy s pevnou šířkou. Použití datových typů s pevnou šířkou, jako je například int , zabrání této režii ve všech indexech v tabulce. |
Při návrhu clusterovaného indexu je splnění co největšího počtu těchto vlastností efektivnější nejen pro clusterovaný index, ale také pro všechny neclusterované indexy ve stejné tabulce. Výkon se zlepšuje tím, že se vyhnete režijním nákladům na úložiště, vstupně-výstupní operace a paměť.
Například clusterovaný indexový klíč s jedním int nebo bigint, který není nulový, má všechny tyto vlastnosti, pokud je naplněn IDENTITY klauzulí nebo výchozím omezením pomocí sekvence a po vložení řádku se neaktualizuje.
Naopak clusterovaný indexový klíč s jedním sloupcem uniqueidentifier je širší, protože používá 16 bajtů úložiště místo 4 bajtů pro int a 8 bajtů pro bigint a nesplňuje neustále rostoucí vlastnost, pokud se hodnoty nevygenerují postupně.
Tip
Při vytváření PRIMARY KEY omezení se automaticky vytvoří jedinečný index podporující omezení. Ve výchozím nastavení je tento index clusterovaný; Pokud však tento index nevyhovuje požadovaným vlastnostem clusterovaného indexu, můžete vytvořit omezení jako neclusterované a vytvořit jiný clusterovaný index.
Pokud nevytvoříte seskupený index, tabulka se uloží jako hromada, která není obecně doporučována.
Architektura clusterovaného indexu
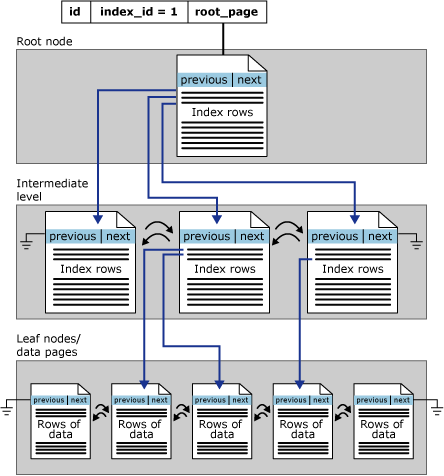
Indexy řádkového úložiště jsou uspořádané jako stromy B+. Každá stránka ve stromu indexu B+ se nazývá uzel indexu. Horní uzel stromu B+ se nazývá kořenový uzel. Dolní uzly v indexu se nazývají uzly typu list. Všechny úrovně indexu mezi kořenovým a listovými uzly se souhrnně označují jako přechodné úrovně. V clusterovém indexu listové uzly obsahují datové stránky podkladové tabulky. Kořenové a přechodné uzly obsahují indexové stránky, které obsahují řádky indexu. Každý řádek indexu obsahuje hodnotu klíče a ukazatel na stránku střední úrovně ve stromu B+ nebo datový řádek na úrovni listu indexu. Stránky v každé úrovni indexu jsou propojeny v doubly propojeném seznamu.
Clusterované indexy mají jeden řádek v sys.partitions pro každý oddíl používaný indexem, s index_id = 1. Clusterovaný index má ve výchozím nastavení jeden oddíl. Pokud má clusterovaný index více oddílů, každý oddíl má samostatnou strukturu stromu B+, která obsahuje data pro daný oddíl. Pokud například clusterovaný index obsahuje čtyři oddíly, existují čtyři stromové struktury B+ v každém oddílu.
V závislosti na datových typech v clusterovém indexu má každá struktura clusterovaného indexu jednu nebo více alokačních jednotek, ve kterých se mají ukládat a spravovat data pro určitý oddíl. Každý clusterovaný index má minimálně jednu IN_ROW_DATA alokační jednotku na oddíl. Clusterovaný index má také jednu LOB_DATA alokační jednotku na oddíl, pokud obsahuje velké sloupce objektu (LOB), jako je nvarchar(max). Má také jednu ROW_OVERFLOW_DATA alokační jednotku na oddíl, pokud obsahuje sloupce s proměnlivou délkou, které překračují limit velikosti řádku o velikosti 8 060 bajtů.
Stránky ve struktuře stromu B+ jsou seřazené podle hodnoty clusterovaného indexového klíče. Všechny vložení se vytvoří na stránce, kde se hodnota klíče v vloženého řádku vejde do pořadí mezi existujícími stránkami. Na stránce nejsou řádky nutně uložené v žádném fyzickém pořadí. Stránka však udržuje logické řazení řádků pomocí interní struktury označované jako pole slotu. Položky v poli slotů se uchovávají v pořadí podle klíče indexu.
Tento obrázek znázorňuje strukturu clusterovaného indexu v jednom oddílu.
Pokyny pro návrh neclusterovaného indexu
Hlavní rozdíl mezi clusterovaným a neclusterovaným indexem spočívá v tom, že neclusterovaný index obsahuje podmnožinu sloupců v tabulce, obvykle seřazených jinak než clusterovaný index. Volitelně lze filtrovat neclusterovaný index, což znamená, že obsahuje podmnožinu všech řádků v tabulce.
Neclusterovaný index úložiště řádků na disku obsahuje lokátory řádků, které odkazují na umístění úložiště řádku v základní tabulce. V tabulce nebo indexovém zobrazení můžete vytvořit více neclusterovaných indexů. Obecně platí, že neclusterované indexy by měly být navrženy tak, aby zlepšily výkon často používaných dotazů, které by jinak potřebovaly prohledat základní tabulku.
Podobně jako při použití indexu v knize hledá optimalizátor dotazů hodnotu dat vyhledáním neclusterovaného indexu a vyhledá umístění hodnoty dat v tabulce a pak načte data přímo z tohoto umístění. Díky tomu jsou neclusterované indexy optimální volbou pro přesné shody dotazů, protože index obsahuje položky popisující přesné umístění v tabulce hodnot dat, které se v dotazech hledají.
Pokud chcete například zadat dotaz na HumanResources.Employee tabulku pro všechny zaměstnance, kteří hlásí určitému manažeru, může optimalizátor dotazů použít neclusterovaný index IX_Employee_ManagerID, který má ManagerID jako první klíčový sloupec. Vzhledem k tomu, že ManagerID hodnoty jsou seřazené v neclusterovaném indexu, může optimalizátor dotazů rychle najít všechny položky v indexu, které odpovídají zadané ManagerID hodnotě. Každá položka indexu odkazuje na přesnou stránku a řádek v základní tabulce, kde lze načíst odpovídající data ze všech ostatních sloupců. Jakmile optimalizátor dotazů najde všechny položky v indexu, může přejít přímo na přesnou stránku a řádek a načíst data místo prohledávání celé základní tabulky.
Architektura neclusterovaného indexu
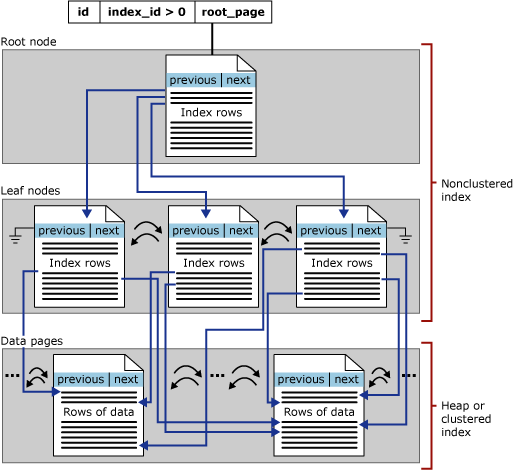
Neclusterované indexy úložiště řádků založené na disku mají stejnou strukturu stromu B+ jako clusterované indexy s výjimkou následujících rozdílů:
Neclusterovaný index nemusí nutně obsahovat všechny sloupce a řádky tabulky.
Úroveň listu neclusterovaného indexu se skládá z indexových stránek místo datových stránek. Indexové stránky na úrovni listu neclusterovaného indexu obsahují klíčové sloupce. Volitelně mohou také obsahovat podmnožinu dalších sloupců v tabulce jako zahrnuté sloupce, aby se zabránilo jejich načtení ze základní tabulky.
Lokátory řádků v neclusterovaných řádcích indexu jsou ukazatel na řádek nebo jsou clusterovaným indexovým klíčem pro řádek, jak je popsáno takto:
Pokud má tabulka seskupený index nebo je index v indexovaném zobrazení, je ukazatel řádku klíč seskupeného indexu pro řádek.
Pokud je tabulka haldou, což znamená, že nemá clusterovaný index, je lokátor řádku ukazatelem na řádek. Ukazatel je sestaven z identifikátoru souboru (ID), čísla stránky a čísla řádku na stránce. Celý ukazatel se označuje jako ID řádku (RID).
Lokátory řádků také zajišťují jedinečnost pro neclusterované řádky indexu. Následující tabulka popisuje, jak databázový stroj přidává lokátory řádků do neclusterovaných indexů:
| Základní typ tabulky | Neclusterovaný typ indexu | Lokátor řádků |
|---|---|---|
| Heap | ||
| Nonunique | Identifikátor RID přidaný do klíčových sloupců | |
| Unique | Identifikátor RID přidaný do zahrnutých sloupců | |
| Jedinečný clusterovaný index | ||
| Nonunique | Clusterované indexové klíče přidané do klíčových sloupců | |
| Unique | Clusterované indexové klíče přidané do zahrnutých sloupců | |
| Ne jedinečný clusterovaný index | ||
| Nonunique | Klíče clusterovaných indexů a jedinečník (pokud je přítomen) přidány do klíčových sloupců. | |
| Unique | Clusterované indexové klíče a uniqueifier (pokud jsou k dispozici) přidané do zahrnutých sloupců |
Databázový stroj nikdy neuchová do neclusterovaného indexu daný sloupec více než jednou. Pořadí klíčů indexu určené uživatelem při vytváření neclusterovaného indexu je vždy dodrženo: všechny sloupce lokátoru řádků, které je potřeba přidat do klíče neclusterovaného indexu, se přidají na konec klíče za sloupci zadanými v definici indexu. Lokátory řádků clusterovaného indexového klíče v neclusterovaném indexu lze použít při zpracování dotazů bez ohledu na to, jestli jsou explicitně zadány v definici indexu nebo implicitně přidány.
Následující příklady ukazují, jak jsou lokátory řádků implementovány v neclusterovaných indexech:
| Clusterovaný index | Definice neclusterovaného indexu | Definice neclusterovaného indexu s lokátory řádků | Explanation |
|---|---|---|---|
Jedinečný skupinový index s klíčovými sloupci (A, B, C) |
Nevýznamný neclusterovaný index s klíčovými sloupci (B, A) a zahrnutými sloupci (E, G) |
Klíčové sloupce (B, A, C) a zahrnuté sloupce (E, G) |
Neclusterovaný index není jedinečný, takže lokátor řádku musí být v klíčích indexu. Sloupce B a A z lokátoru řádků jsou už k dispozici, takže se přidá jenom sloupec C . Sloupec C se přidá na konec seznamu klíčových sloupců. |
Jedinečný skupinový index s klíčovým sloupcem (A) |
Neunikátní neklastrový index s klíčovými sloupci (B, C) a zahrnutým sloupcem (A) |
Klíčové sloupce (B, C, A) |
Neklusterovaný index je neunikátní, takže se k klíči přidá lokátor řádku. Sloupec A ještě není zadaný jako klíčový sloupec, takže se přidá na konec seznamu klíčových sloupců. Sloupec A je teď v klíči, takže ho nemusíte ukládat jako zahrnutý sloupec. |
Jedinečný skupinový index s klíčovým sloupcem (A, B) |
Jedinečný neclusterovaný index s klíčovým sloupcem (C) |
Klíčový sloupec (C) a zahrnuté sloupce (A, B) |
Neclusterovaný index je jedinečný, takže lokátor řádku se přidá do zahrnutých sloupců. |
Neclusterované indexy mají jeden řádek v sys.partitions pro každý oddíl používaný indexem, s index_id > 1. Ve výchozím nastavení má neclusterovaný index jeden oddíl. Pokud má neclusterovaný index více oddílů, každý oddíl má strukturu stromu B+ obsahující řádky indexu pro daný oddíl. Pokud má například neclusterovaný index čtyři oddíly, existují čtyři struktury stromu B+ v každém oddílu.
V závislosti na datových typech v neclusterovém indexu má každá neclusterovaná struktura indexu jednu nebo více jednotek přidělení, ve kterých se mají ukládat a spravovat data pro určitý oddíl. Každý neclusterovaný index má minimálně jednu IN_ROW_DATA alokační jednotku na oddíl, který ukládá stránky stromové struktury B+ indexu. Neclusterovaný index má také jednu LOB_DATA alokační jednotku na oddíl, pokud obsahuje velké sloupce objektu (LOB), jako je nvarchar(max). Kromě toho má jednu ROW_OVERFLOW_DATA alokační jednotku na oddíl, pokud obsahuje sloupce s proměnlivou délkou, které překračují limit velikosti řádků 8 060 bajtů.
Následující obrázek znázorňuje strukturu neclusterovaného indexu v jednom oddílu.
Použití zahrnutých sloupců v neclusterovaných indexech
Kromě klíčových sloupců může mít neclusterovaný index také neklíčové sloupce uložené na úrovni listu. Tyto sloupce bez klíče se nazývají zahrnuté sloupce a jsou zadány v INCLUDE klauzuli CREATE INDEX příkazu.
Index se zahrnutými neklíčovými sloupci může výrazně zlepšit výkon dotazů, pokud se týká dotazu, tj. když jsou všechny sloupce použité v dotazu v indexu buď jako klíčové, nebo neklíčové sloupce. Zvýšení výkonu se dosahuje, protože databázový stroj může vyhledat všechny hodnoty sloupců v indexu; Základní tabulka není přístupná, což vede k menšímu počtu vstupně-výstupních operací disku.
Pokud se sloupec musí načíst dotazem, ale nepoužívá se v predikátech, agregacích a řazení dotazu, přidejte ho jako zahrnutý sloupec, ne jako klíčový sloupec. To má následující výhody:
Zahrnuté sloupce můžou používat datové typy, které nejsou povolené jako sloupce s klíčem indexu.
Zahrnuté sloupce nejsou při výpočtu počtu sloupců klíče indexu nebo velikosti klíče indexu zohledňovány databázovým stroj. U zahrnutých sloupců nejste omezeni maximální velikostí klíče o velikosti 900 bajtů. Můžete vytvořit širší indexy, které pokrývají více dotazů.
Když přesunete sloupec z indexového klíče na zahrnuté sloupce, sestavení indexu bude trvat kratší dobu, protože operace řazení indexu bude rychlejší.
Pokud tabulka obsahuje skupinový index, sloupec nebo sloupce definované v clusterovém indexovém klíči se automaticky přidají do každého nevýznamného neclusterovaného indexu v tabulce. Není nutné je zadávat v neklasifikovaném indexovém klíči ani jako zahrnuté sloupce.
Pokyny pro indexy se zahrnutými sloupci
Při návrhu neclusterovaných indexů s zahrnutými sloupci zvažte následující pokyny:
Zahrnuté sloupce lze definovat pouze v neclusterovaných indexech v tabulkách nebo indexovaných zobrazeních.
Všechny datové typy jsou povoleny s výjimkou textové, textu a obrázku.
Počítané sloupce, které jsou deterministické a přesné nebo nepřesné, můžou být zahrnuté sloupce. Další informace najdete v tématu Indexy ve vypočítaných sloupcích.
Stejně jako u klíčových sloupců mohou být počítané sloupce odvozené z datových typů image, ntext a text zahrnuty jako sloupce, pokud je datový typ počítaného sloupce povolen pro zahrnutí.
Názvy sloupců nelze zadat jak v
INCLUDEseznamu, tak v seznamu klíčových sloupců.Názvy sloupců se v seznamu nedají opakovat
INCLUDE.Nejméně jeden klíčový sloupec musí být definován v indexu. Maximální počet zahrnutých sloupců je 1 023. Toto je maximální počet sloupců tabulky minus 1.
Bez ohledu na přítomnost zahrnutých sloupců musí sloupce klíče indexu dodržovat omezení stávající velikosti indexu 16 klíčových sloupců maximálně a celkovou velikost klíče indexu 900 bajtů.
Návrh doporučení pro indexy se zahrnutými sloupci
Zvažte přepracování neclusterovaných indexů s velkou velikostí klíče tak, aby pouze sloupce použité v predikátech dotazů, agregacích a řazeních byly klíčovými sloupci. Nastavte všechny ostatní sloupce, které pokrývají dotaz, včetně neklíčových sloupců. Tímto způsobem máte všechny sloupce potřebné k pokrytí dotazu, ale samotný klíč indexu je malý a efektivní.
Předpokládejme například, že chcete navrhnout index tak, aby pokrývala následující dotaz.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Aby bylo možné dotaz pokrýt, musí být každý sloupec definován v indexu. I když byste mohli definovat všechny sloupce jako klíčové sloupce, velikost klíče by byla 334 bajtů. Vzhledem k tomu, že jediný sloupec použitý jako kritéria hledání je PostalCode sloupec, který má délku 30 bajtů, bude lepší návrh indexu definovat PostalCode jako klíčový sloupec a zahrnout všechny ostatní sloupce jako neklíčové sloupce.
Následující příkaz vytvoří index se zahrnutými sloupci pro pokrytí dotazu.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Pokud chcete ověřit, že index pokrývá dotaz, vytvořte index a zobrazte odhadovaný plán provádění. Pokud plán provádění zobrazuje operátor Index Seek pro IX_Address_PostalCode index, dotaz je pokryt indexem.
Důležité informace o výkonu indexů s zahrnutými sloupci
Vyhněte se vytváření indexů s velkým počtem zahrnutých sloupců. I když index možná pokrývá více dotazů, jeho výhoda výkonu se sníží, protože:
Méně řádků indexu se vejde na stránku. Tím se zvýší vstupně-výstupní operace disku a sníží se efektivita mezipaměti.
K uložení indexu je potřeba více místa na disku. Přidání varchar(max), nvarchar(max), varbinary(max) nebo datových typů XML v zahrnutých sloupcích může výrazně zvýšit požadavky na místo na disku. Důvodem je to, že hodnoty sloupců se zkopírují do úrovně listu indexu. Proto se nacházejí v indexu i základní tabulce.
Výkon úprav dat se snižuje, protože mnoho sloupců musí být změněno jak v tabulce založené, tak v neclusterovém indexu.
Musíte určit, jestli zvýšení výkonu dotazů převáží snížení výkonu úprav dat a zvýšení požadavků na místo na disku.
Pokyny pro návrh jedinečného indexu
Jedinečný index zaručuje, že klíč indexu neobsahuje žádné duplicitní hodnoty. Vytvoření jedinečného indexu je možné pouze v případech, kdy je jedinečnost charakteristická pro samotná data. Pokud například chcete zajistit, aby hodnoty ve NationalIDNumber sloupci v HumanResources.Employee tabulce byly jedinečné, když je EmployeeIDprimární klíč , vytvořte UNIQUE omezení NationalIDNumber sloupce. Omezení odmítne všechny pokusy o zavedení řádků s duplicitními národními identifikačními čísly.
U vícesloupcových jedinečných indexů index zaručuje, že každá kombinace hodnot v klíči indexu je jedinečná. Pokud je například vytvořen jedinečný index v kombinaci LastNameFirstName, a MiddleName sloupců, žádné dva řádky v tabulce by mohly mít stejné hodnoty pro tyto sloupce.
Clusterované i neclusterované indexy můžou být jedinečné. Ve stejné tabulce můžete vytvořit jedinečný clusterovaný index a několik jedinečných neclusterovaných indexů.
Mezi výhody jedinečných indexů patří:
- Vynucují se obchodní pravidla, která vyžadují jedinečnost dat.
- K dispozici jsou další informace užitečné pro optimalizátor dotazů.
Vytvoření omezení PRIMARY KEY nebo UNIQUE automaticky vytvoří jedinečný index pro zadané sloupce. Neexistují žádné významné rozdíly mezi vytvořením UNIQUE omezení a vytvořením jedinečného indexu nezávisle na omezení. Ověření dat probíhá stejným způsobem a optimalizátor dotazů nerozlišuje mezi jedinečným indexem vytvořeným omezením nebo ručně vytvořeným. Pokud je cílem vynucování obchodních pravidel, měli byste na sloupec vytvořit omezení UNIQUE nebo PRIMARY KEY. Tímto způsobem je cíl indexu jasný.
Důležité informace o jedinečném indexu
Jedinečný index,
UNIQUEomezení neboPRIMARY KEYomezení nelze vytvořit, pokud v datech existují duplicitní hodnoty klíče.Pokud jsou data jedinečná a chcete vynutit jedinečnost, vytvoření jedinečného indexu místo neunique indexu ve stejné kombinaci sloupců poskytuje další informace pro optimalizátor dotazů, který může vytvářet efektivnější plány provádění. V tomto případě se doporučuje vytvořit
UNIQUEomezení nebo jedinečný index.Jedinečný neclusterovaný index může obsahovat zahrnuté sloupce bez klíče. Další informace naleznete v tématu Použití zahrnutých sloupců v neclusterovaných indexech.
Na rozdíl od omezení typu
PRIMARY KEYlze vytvořit omezení typuUNIQUEnebo jedinečný index se sloupcem, který může obsahovat hodnotu null v klíči indexu. Pro účely vynucení jedinečnosti jsou dvě hodnoty NULL považovány za stejné. To například znamená, že v jedinečném indexu s jedním sloupcem může mít sloupec hodnotu NULL pouze pro jeden řádek v tabulce.
Pokyny k návrhu filtrovaného indexu
Filtrovaný index je optimalizovaný neclusterovaný index, zejména pro dotazy, které vyžadují malou podmnožinu dat v tabulce. Používá predikát filtru v definici indexu k indexování části řádků v tabulce. Dobře navržený filtrovaný index může zlepšit výkon dotazů, snížit náklady na aktualizace indexu a snížit náklady na úložiště indexů v porovnání s indexem full-table.
Filtrované indexy můžou poskytovat následující výhody oproti indexům full-table:
Vylepšený výkon dotazů a kvalita plánu
Dobře navržený filtrovaný index zlepšuje výkon dotazů a kvalitu plánu provádění, protože je menší než neclusterovaný index celé tabulky. Filtrovaný index má filtrované statistiky, které jsou přesnější než statistiky úplné tabulky, protože pokrývají pouze řádky ve filtrovaného indexu.
Snížené náklady na aktualizaci indexu
Index se aktualizuje jenom v případech, kdy příkazy jazyka DML (Data Manipulat Language) ovlivňují data v indexu. Filtrovaný index snižuje náklady na aktualizace indexu v porovnání s neclusterovaným indexem celé tabulky, protože je menší a aktualizuje se pouze v případech, kdy jsou ovlivněna data v indexu. Je možné mít velký počet filtrovaných indexů, zejména pokud obsahují data, která jsou ovlivněna zřídka. Podobně platí, že pokud filtrovaný index obsahuje pouze často ovlivněná data, menší velikost indexu snižuje náklady na aktualizaci statistik.
Snížení nákladů na úložiště indexů
Vytvoření filtrovaného indexu může snížit diskové úložiště pro neclusterované indexy, pokud není nutný úplný index tabulky. Můžete být schopni nahradit neclusterovaný index celé tabulky několika filtrovanými indexy, aniž byste výrazně zvýšili požadavky na úložiště.
Filtrované indexy jsou užitečné, když sloupce obsahují dobře definované podmnožina dat. Příklady:
Sloupce, které obsahují mnoho NULL hodnot.
Heterogenní sloupce, které obsahují kategorie dat.
Sloupce obsahující rozsahy hodnot, jako jsou množství, čas a kalendářní data.
Nižší náklady na aktualizaci pro filtrované indexy jsou nejvýraznější, když je počet řádků v indexu malý v porovnání s indexem celé tabulky. Pokud filtrovaný index obsahuje většinu řádků v tabulce, může jeho údržba stát více než údržba celotabulkového indexu. V tomto případě byste měli místo filtrovaného indexu použít úplný index tabulky.
Filtrované indexy jsou definovány v jedné tabulce a podporují pouze jednoduché relační operátory. Pokud potřebujete výraz filtru, který obsahuje složitou logiku nebo odkazuje na více tabulek, měli byste vytvořit indexovaný počítaný sloupec nebo indexované zobrazení.
Aspekty návrhu filtrovaného indexu
Aby bylo možné navrhnout efektivní filtrované indexy, je důležité pochopit, jaké dotazy vaše aplikace používá a jak souvisí s podmnožinami dat. Mezi příklady dat s dobře definovanými podmnožinami patří sloupce s mnoha hodnotami NULL, sloupce s heterogenními kategoriemi hodnot a sloupců s odlišnými rozsahy hodnot.
Následující aspekty návrhu poskytují několik scénářů, kdy filtrovaný index může poskytovat výhody oproti indexům full-table.
Filtrované indexy pro podmnožinu dat
Pokud sloupec obsahuje jenom několik relevantních hodnot pro dotazy, můžete pro podmnožinu hodnot vytvořit filtrovaný index. Pokud je například sloupec převážně NULL a dotaz vyžaduje pouze hodnoty, které nemají hodnotu NULL, můžete vytvořit filtrovaný index obsahující řádky, které nejsou null.
Ukázková databáze Production.BillOfMaterials má například tabulku s 2 679 řádky. Sloupec EndDate obsahuje pouze 199 řádků, které obsahují jinou hodnotu než NULL a ostatní řádky 2480 obsahují hodnotu NULL. Následující filtrovaný index se zabývá dotazy, které vracejí sloupce definované v indexu a které vyžadují pouze řádky s hodnotou, která není null pro EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
Filtrovaný index FIBillOfMaterialsWithEndDate je platný pro následující dotaz.
Zobrazte plán odhadovaného spuštění , abyste zjistili, jestli optimalizátor dotazů použil filtrovaný index.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Další informace o tom, jak vytvořit filtrované indexy a jak definovat filtrovaný výraz predikátu indexu, naleznete v tématu Vytvoření filtrovaných indexů.
Filtrované indexy pro heterogenní data
Pokud tabulka obsahuje heterogenní datové řádky, můžete vytvořit filtrovaný index pro jednu nebo více kategorií dat.
Například produkty uvedené v Production.Product tabulce jsou každý přiřazen ke ProductSubcategoryID, které jsou zase přidružené k produktovým kategoriím Kola, Součásti, Oděvy nebo Příslušenství. Tyto kategorie jsou heterogenní, protože jejich hodnoty sloupců v Production.Product tabulce nejsou úzce korelovány. Například sloupce Color, , ReorderPoint, ListPriceWeight, Classa Style mají jedinečné vlastnosti pro každou kategorii produktu. Předpokládejme, že existují časté dotazy na příslušenství, které mají podkategorie mezi 27 a 36 včetně. Výkon dotazů na příslušenství můžete zlepšit vytvořením filtrovaného indexu v podkategoriích příslušenství, jak je znázorněno v následujícím příkladu.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
Filtrovaný index FIProductAccessories pokrývá následující dotaz, protože výsledky dotazu jsou obsaženy v indexu a plán dotazu nevyžaduje přístup k základní tabulce. Například, výraz predikátu dotazu ProductSubcategoryID = 33 je podmnožinou filtrovaného predikátu indexu ProductSubcategoryID >= 27 a ProductSubcategoryID <= 36; sloupce ProductSubcategoryID a ListPrice v predikátu dotazu jsou oba klíčovými sloupci v indexu a název je uložen na úrovni listu indexu jako zahrnutý sloupec.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Klíčové a zahrnuté sloupce ve filtrovaných indexech
Osvědčeným postupem je přidat malý počet sloupců do filtrované definice indexu, pouze pokud je to nutné, aby optimalizátor dotazů zvolil filtrovaný index pro plán provádění dotazu. Optimalizátor dotazů může zvolit filtrovaný index pro dotaz bez ohledu na to, jestli index dotaz pokrývá nebo ne. Optimalizátor dotazů ale pravděpodobně zvolí filtrovaný index, pokud dotaz pokrývá.
V některých případech filtrovaný index pokrývá dotaz, aniž by zahrnoval sloupce ve výrazu filtrovaného indexu jako klíčové nebo zahrnuté sloupce v definici filtrovaného indexu. Následující pokyny vysvětlují, kdy sloupec ve filtrovaném výrazu indexu by měl být klíčem nebo zahrnutým sloupcem v definici filtrovaného indexu. Příklady odkazují na filtrovaný index, FIBillOfMaterialsWithEndDate který byl vytvořen dříve.
Sloupec ve výrazu filtrovaného indexu nemusí být klíčem ani zahrnutým sloupcem v definici filtrovaného indexu, pokud výraz filtrovaného indexu odpovídá predikátu dotazu a dotaz nevrací sloupec výrazu filtrovaného indexu ve výsledcích dotazu. Pokryje například následující dotaz, protože predikát dotazu je ekvivalentní výrazu filtru, a FIBillOfMaterialsWithEndDate není vrácen s výsledky dotazu. Index FIBillOfMaterialsWithEndDate nepotřebuje EndDate jako klíč ani zahrnutý sloupec ve filtrované definici indexu.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Sloupec ve filtrovaném výrazu indexu by měl být klíčem nebo zahrnutým sloupcem v definici filtrovaného indexu, pokud predikát dotazu používá sloupec v porovnávání, které není ekvivalentní filtrovanému výrazu indexu. Například platí pro následující dotaz, FIBillOfMaterialsWithEndDate protože vybere podmnožinu řádků z filtrovaného indexu. Nepokrývá ale následující dotaz, protože EndDate se používá ve srovnání EndDate > '20040101', což není ekvivalentem filtrovaného výrazu indexu. Procesor dotazů nemůže tento dotaz spustit, aniž by prozkoumal hodnoty EndDate.
EndDate Proto by měl být klíčem nebo zahrnutým sloupcem v definici filtrovaného indexu.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Sloupec ve filtrovaném výrazu indexu by měl být klíčovým nebo zahrnutým sloupcem v definici filtrovaného indexu, pokud se sloupec nachází v sadě výsledků dotazu. Například FIBillOfMaterialsWithEndDate vynechává následující dotaz, protože obsahuje sloupec EndDate ve výsledcích dotazu.
EndDate Proto by měl být klíčem nebo zahrnutým sloupcem v definici filtrovaného indexu.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Clusterovaný indexový klíč tabulky nemusí být klíčem ani zahrnutým sloupcem v definici filtrovaného indexu. Clusterovaný indexový klíč se automaticky zahrne do všech neclusterovaných indexů, včetně filtrovaných indexů.
Operátory převodu dat v predikátu filtru
Pokud relační operátor zadaný ve filtrovaném indexovém výrazu filtrovaného indexu vede k implicitnímu nebo explicitnímu převodu dat, dojde k chybě, pokud dojde k převodu na levé straně relačního operátoru. Řešením je napsat filtrovaný indexový výraz s operátorem převodu dat (CAST nebo CONVERT) na pravé straně relačního operátoru.
Následující příklad vytvoří tabulku se sloupci různých datových typů.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
V následující filtrované definici indexu je sloupec b implicitně převeden na celočíselné datové typy pro porovnání s konstantou 1. Tím se vygeneruje chybová zpráva 10611, protože převod probíhá na levé straně operátoru ve filtrovaném predikátu.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
Řešením je převést konstantu na pravé straně tak, aby byla stejného typu jako sloupec b, jak je vidět v následujícím příkladu:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Přesunutí převodu dat z levé strany na pravou stranu porovnávacího operátoru může změnit význam převodu. V předchozím příkladu se při přidání operátoru CONVERT na pravou stranu porovnání změnilo z porovnání typu int na varbinární porovnání.
Architektura indexu Columnstore
Index columnstore je technologie pro ukládání, načítání a správu dat pomocí sloupcového formátu dat označovaného jako columnstore. Další informace najdete v článku Indexy columnstore: přehled.
Informace o verzi a nové funkce najdete v sekci Co je nového v indexech columnstore.
Znalost těchto základů usnadňuje pochopení dalších článků columnstore, které vysvětlují, jak tuto technologii efektivně používat.
Úložiště dat používá columnstore a rowstore.
Při diskuzi o indexech columnstore používáme termíny rowstore a columnstore ke zdůraznění formátu úložiště dat. Indexy columnstore používají oba typy úložiště.

Columnstore je data, která jsou logicky uspořádaná jako tabulka s řádky a sloupci a fyzicky uložená ve sloupcovém datovém formátu.
Index columnstore fyzicky ukládá většinu dat ve formátu columnstore. Ve formátu columnstore se data komprimují a dekomprimují po sloupcích. Není nutné nekomprimovat jiné hodnoty v každém řádku, které dotaz nevyžaduje. Díky tomu můžete rychle zkontrolovat celý sloupec velké tabulky.
Úložiště řádků je data, která jsou logicky uspořádaná jako tabulka s řádky a sloupci, a poté fyzicky uložená ve formátu dat po řádcích. Jedná se o tradiční způsob ukládání dat v relačních tabulkách, jako je clusterovaný index stromu B+ nebo strukturovaná halda.
Index columnstore také fyzicky ukládá některé řádky ve formátu rowstore nazývaném deltastore. Deltastore, také nazývaný delta rowgroups, je místo pro řádky, které jsou příliš málo na to, aby se kvalifikovaly k sloučení a kompresi do columnstore. Každá delta skupina řádků je implementována jako clusterovaný index B+ stromu, který funguje jako úložiště řádků.
Operace se provádějí se skupinami řádků a segmenty sloupců.
Index columnstore seskupuje řádky do spravovatelných jednotek. Každá z těchto jednotek se nazývá skupina řádků. Pro zajištění nejlepšího výkonu je počet řádků ve skupině řádků dostatečně velký, aby se zlepšil poměr komprese a dostatečně malý, aby byl přínosem při operacích s pamětí.
Index columnstore například provádí tyto operace se skupinami řádků:
Zkomprimuje skupiny řádků do sloupcového úložiště. Komprese se provádí u každého segmentu sloupce v rámci skupiny řádků.
Sloučí skupiny řádků během
ALTER INDEX ... REORGANIZEoperace, včetně odebrání odstraněných dat.Během operace znovu vytvoří všechna seskupení
ALTER INDEX ... REBUILDřádků.Sestavy o stavu skupiny řádků a fragmentaci ve zobrazeních dynamické správy (DMVs).
Deltastore se skládá z jedné nebo více skupin řádků, které se nazývají delta rowgroups. Každá rozdílová skupina řádků je shlukový index B+ stromu, který ukládá malé hromadné zatížení a vkládání, dokud skupina řádků neobsahuje 1 048 576 řádků. V tomto okamžiku proces nazvaný tuple-mover automaticky komprimuje uzavřenou skupinu řádků do columnstore.
Další informace o stavech skupiny řádků najdete v tématu sys.dm_db_column_store_row_group_physical_stats.
Tip
Příliš mnoho malých skupin řádků snižuje kvalitu indexu columnstore. Operace reorganizace slučuje menší skupiny řádků podle zásad interní prahové hodnoty, která určuje, jak odebrat odstraněné řádky a zkombinovat komprimované skupiny řádků. Po sloučení se zlepší kvalita indexu.
V SQL Serveru 2019 (15.x) a novějších verzích pomáhá tuple-moveru slučovací úloha na pozadí, která automaticky komprimuje menší otevřené delta skupiny řádků, které existovaly po určitou dobu podle interní prahové hodnoty, nebo sloučí komprimované skupiny řádků, ze kterých byl odstraněn velký počet řádků.
Každý sloupec má v každé skupině řádků několik hodnot. Tyto hodnoty se nazývají segmenty sloupců. Každá skupina řádků obsahuje jeden segment sloupce pro každý sloupec v tabulce. Každý sloupec má v každé skupině řádků jeden segment sloupce.
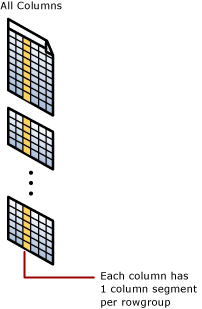
Když index columnstore komprimuje skupinu řádků, zkomprimuje každý segment sloupce samostatně. Pokud chcete dekomprimovat celý sloupec, index columnstore potřebuje odkomprimovat pouze jeden segment sloupce z každé skupiny řádků.
Malé náklady a vložky se přesunou do deltastoru.
Index columnstore zlepšuje kompresi a výkon columnstore tím, že do indexu columnstore komprimuje alespoň 102 400 řádků najednou. Aby se řádky mohly hromadně zkomprimovat, index columnstore shromažďuje malé objemy a vkládá je do deltastore. Operace deltastore se zpracovávají na pozadí. Pokud chcete vrátit výsledky dotazu, clusterovaný index columnstore kombinuje výsledky dotazu z columnstore i deltastore.
Řádky přejdou do rozdílového úložiště, když jsou:
Vloženo pomocí
INSERT INTO ... VALUESpříkazu.Na konci hromadného nahrávání a jejich počet je menší než 102 400.
Updated. Každá aktualizace se implementuje jako odstranění a vložení.
Deltastore také ukládá seznam ID odstraněných řádků, které byly označeny jako odstraněné, ale ještě nejsou fyzicky odstraněny ze columnstore.
Když jsou skupiny rozdílových řádků plné, jsou zkomprimovány do sloupcového úložiště.
Clusterované columnstore indexy shromažďují až 1 048 576 řádků v každé řádkové skupině delta před její kompresí do columnstore. Tím se zlepší komprese indexu columnstore. Když rozdílová skupina řádků dosáhne maximálního počtu řádků, přejde ze stavu OPEN do stavu CLOSED. Proces běžící na pozadí s názvem tuple-mover kontroluje uzavřené skupiny řádků. Pokud proces najde uzavřenou skupinu řádků, zkomprimuje skupinu řádků a uloží ji do columnstore.
Když je delta skupina řádků zkomprimovaná, stávající delta skupina řádků přejde do stavu TOMBSTONE, který bude později odebrán nástrojem tuple-mover, jakmile na ni není žádný odkaz, a nová komprimovaná skupina řádků se označí jako COMPRESSED.
Další informace o stavech skupiny řádků najdete v tématu sys.dm_db_column_store_row_group_physical_stats.
Delta rowgroups můžete vynutit do columnstore pomocí alter INDEX k opětovnému sestavení nebo změně uspořádání indexu. Pokud při kompresi dojde k zatížení paměti, index columnstore může snížit počet řádků v komprimované skupině řádků.
Každý oddíl tabulky má vlastní skupiny řádků a rozdílové skupiny řádků.
Koncept dělení je stejný v clusterovaném indexu, haldě a sloupcovém indexu. Dělení tabulky rozdělí tabulku na menší skupiny řádků podle rozsahu hodnot sloupců. Často se používá ke správě dat. Můžete například vytvořit oddíl pro každý rok dat a pak pomocí přepínání oddílů archivovat stará data do levnějšího úložiště.
Skupiny řádků se vždy definují v rámci partitionu tabulky. Když je index columnstore rozdělen, má každý oddíl vlastní komprimované skupiny řádků a delta skupiny řádků. Tabulka, která není rozdělena na oddíly, obsahuje jeden oddíl.
Tip
Zvažte použití dělení tabulky, pokud je potřeba odebrat data z columnstore. Přepínání a zkracování oddílů, které už nejsou potřeba, je efektivní strategií, jak odstranit data, aniž by došlo k fragmentaci ve sloupcovém úložišti.
Každý oddíl může mít více delta skupin řádků.
Každá partition může obsahovat více než jednu delta skupinu řádků. Když index columnstore potřebuje přidat data do rozdílové skupiny řádků a rozdílová skupina řádků je uzamčena jinou transakcí, index columnstore se pokusí získat zámek v jiné rozdílové skupině řádků. Pokud nejsou k dispozici žádné rozdílové skupiny řádků, index columnstore vytvoří novou rozdílovou skupinu řádků. Například tabulka s 10 partice může mít snadno 20 nebo více delta skupin řádků.
Kombinování indexů columnstore a rowstore ve stejné tabulce
Neclusterovaný index obsahuje kopii části nebo všech řádků a sloupců v podkladové tabulce. Index je definován jako jeden nebo více sloupců tabulky a má volitelnou podmínku, která filtruje řádky.
V tabulce rowstore můžete vytvořit aktualizovatelný neclusterovaný index columnstore. Index columnstore ukládá kopii dat, takže potřebujete další úložiště. Data v indexu columnstore se ale komprimuje na mnohem menší velikost, než vyžaduje tabulka rowstore. Tímto způsobem můžete spustit analýzy indexu columnstore a úloh OLTP na indexu rowstore najednou. Columnstore se aktualizuje, když se data změní v tabulce rowstore, takže oba indexy pracují se stejnými daty.
Tabulka typu rowstore může mít jeden neklastrovaný index columnstore. Další informace najdete v tématu Indexy Columnstore – pokyny k návrhu.
V clusterované tabulce columnstore můžete mít jeden nebo více neclusterovaných indexů rowstore. Tímto způsobem můžete provádět efektivní hledání tabulek v podkladovém columnstore. K dispozici jsou i další možnosti. Jedinečnost můžete například vynutit pomocí UNIQUE omezení v tabulce rowstore. Pokud se neunikátní hodnotu nelze vložit do tabulky rowstore, Databázový stroj tuto hodnotu nevloží ani do columnstore.
Aspekty výkonu neclusterovaného columnstore
Definice indexu columnstore bez clusteru podporuje použití filtrované podmínky. Aby se minimalizoval dopad na výkon při přidání indexu columnstore, použijte výraz filtru k vytvoření neklastrovaného indexu columnstore pouze u podmnožiny dat požadovaných pro analýzu.
Tabulka optimalizovaná pro paměť může mít jeden columnstore index. Můžete ji vytvořit při vytvoření tabulky nebo ji později přidat pomocí příkazu ALTER TABLE.
Další informace najdete v tématu Indexy Columnstore – výkon dotazů.
Pokyny k návrhu indexu hash optimalizovaného pro paměť
Při použití In-Memory OLTP musí mít všechny tabulky optimalizované pro paměť alespoň jeden index. Pro tabulku optimalizovanou pro paměť je každý index také optimalizován pro paměť. Indexy hash jsou jedním z možných typů indexů v tabulce optimalizované pro paměť. Další informace najdete v tématu Indexy v tabulkách Memory-Optimized.
Architektura indexu hash optimalizovaná pro paměť
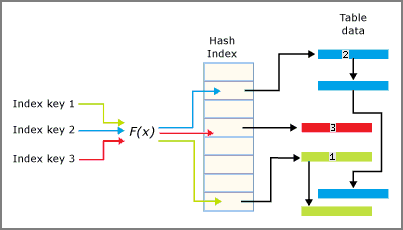
Index hash se skládá z pole ukazatelů a každý prvek pole se nazývá kontejner hash.
- Každý slot má 8 bajtů, které se používají k uložení adresy paměti spojového seznamu klíčových záznamů.
- Každá položka je hodnota pro klíč indexu a adresa odpovídajícího řádku v podkladové tabulce optimalizované pro paměť.
- Každá položka odkazuje na další položku ve spojovém seznamu položek, které jsou zřetězené do aktuálního kbelíku.
Počet kbelíků musí být zadán při vytváření indexu:
- Čím nižší je poměr kontejnerů k řádkům tabulky nebo k jedinečným hodnotám, tím delší je průměrný seznam propojení kontejnerů.
- Seznamy krátkých odkazů fungují rychleji než dlouhé seznamy odkazů.
- Maximální počet kbelíků v hashových indexech je 1 073 741 824.
Tip
Pokud chcete určit to správné BUCKET_COUNT pro vaše data, přečtěte si téma Konfigurace počtu kontejnerů indexu hash.
Funkce hash se použije na sloupce klíče indexu a výsledek funkce určuje, do jakého kontejneru klíč spadá. Každý kontejner má ukazatel na řádky, jejichž hodnoty hashovaného klíče se mapují na tento kontejner.
Funkce hash použitá pro indexy hash má následující vlastnosti:
- Databázový stroj má jednu funkci hash, která se používá pro všechny indexy hash.
- Funkce hash je deterministická. Stejná hodnota vstupního klíče se vždy mapuje na stejný kontejner v indexu hash.
- Více indexových klíčů může být namapováno do stejného kontejneru hash.
- Funkce hash je vyvážená, což znamená, že rozdělení hodnot klíče indexu v kontejnerech hash se obvykle řídí rozdělením poissonovy nebo zvonové křivky, nikoli plochým lineárním rozdělením.
- Poissonovo rozdělení není rovnoměrné rozdělení. Hodnoty klíče indexu nejsou rovnoměrně distribuovány v kontejnerech hash.
- Pokud jsou dva indexové klíče namapované do stejného kontejneru hash, dojde ke kolizi hash. Velký počet kolizí hash může mít vliv na výkon operací čtení. Realistickým cílem je 30 procent kbelíků, aby obsahovaly dvě různé klíčové hodnoty.
Souhra hašovacího indexu a věder je shrnuta na následujícím obrázku.
Konfigurace počtu kontejnerů indexu hash
Počet kbelíků indexu hash se zadává při vytváření indexu ALTER TABLE...ALTER INDEX REBUILD a dá se změnit pomocí syntaxe.
Ve většině případů by počet kbelíků měl být mezi 1 a 2násobky počtu jedinečných hodnot v klíči indexu.
Nemusí být vždy možné předpovědět, kolik hodnot má konkrétní klíč indexu. Výkon je obvykle stále dobrý, pokud hodnota BUCKET_COUNT je do 10násobku skutečného počtu klíčových hodnot, a přeceňování je obecně lepší než podcenění.
Příliš málo kbelíků může mít následující nevýhody:
- Více kolizí hash pro různé hodnoty klíčů.
- Každá jedinečná hodnota je nucena sdílet stejný kbelík s jinou odlišnou hodnotou.
- Průměrná délka řetězce na jeden kbelík roste.
- Čím delší je řetěz kbelíků, tím pomalejší bude hledání shody v indexu.
Příliš mnoho kontejnerů může mít následující nevýhody:
- Příliš vysoký počet kbelíků může vést k více prázdným kontejnerům.
- Prázdné kontejnery ovlivňují výkon kontrol úplného indexu. Pokud se kontroly provádějí pravidelně, zvažte výběr počtu kontejnerů blízko počtu jedinečných hodnot klíče indexu.
- Prázdné kontejnery používají paměť, i když každý kbelík používá pouze 8 bajtů.
Note
Přidání dalších kbelíků nijak nezmenšuje řetězení položek, které sdílejí duplicitní hodnotu. Míra duplikace hodnot se používá k rozhodování, jestli je index hash nebo neclusterovaný index vhodným typem indexu, nikoli k výpočtu počtu kbelíků.
Důležité informace o výkonu pro indexy hash
Výkon indexu hash je následující:
- Vynikající, když predikát v
WHEREklauzuli určuje přesnou hodnotu pro každý sloupec v klíči indexu hash. Hash index se vrátí ke skenování při použití podmínky nerovnosti. - Špatné, když predikát v
WHEREklauzuli hledá rozsah hodnot v klíči indexu. - Špatné, když predikát v
WHEREklauzuli stanoví jednu specifickou hodnotu pro první sloupec klíče indexu hash se dvěma sloupci, ale nezadá hodnotu pro ostatní sloupce klíče.
Tip
Predikát musí obsahovat všechny sloupce v klíči indexu hash. Hash index vyžaduje pro vyhledání v indexu použití celého klíče.
Pokud se použije hash index a počet jedinečných klíčů indexu je více než 100krát menší než počet řádků, zvažte zvýšení počtu bucketů, abyste se vyhnuli velkým řetězcům řádků, nebo místo toho použijte neklastrovaný index.
Vytvoření indexu hash
Při vytváření indexu hash zvažte následující:
- Index hash může existovat pouze v tabulce optimalizované pro paměť. V tabulce na bázi disku nemůže existovat.
- Index hash je ve výchozím nastavení neunique, ale může být deklarován jako jedinečný.
Následující příklad vytvoří jedinečný index hash:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Verze řádků a správa paměti v tabulkách optimalizovaných pro paměť
Pokud je v tabulce optimalizované pro paměť ovlivněný příkazem UPDATE řádek, vytvoří tabulka aktualizovanou verzi řádku. Během transakce aktualizace mohou ostatní sezení být schopny přečíst starší verzi řádku a tak se vyhnout zpomalení výkonu způsobeného zámkem řádku.
Index hash může mít také různé verze svých položek, aby se přizpůsobily aktualizaci.
Pokud už starší verze nejsou potřeba, vlákno uvolňování paměti (GC) prochází kontejnery a jejich seznamy odkazů, aby se vyčistily staré položky. Vlákno GC funguje lépe, pokud jsou délky řetězu seznamu odkazů krátké. Pro více informací se podívejte na In-Memory OLTP Garbage Collection.
Pokyny k návrhu neklastrového indexu optimalizovaného pro paměť
Kromě indexů hash jsou neclusterované indexy další možné typy indexů v tabulce optimalizované pro paměť. Další informace najdete v tématu Indexy v tabulkách Memory-Optimized.
Architektura neclusterovaného indexu optimalizovaná pro paměť
Neclusterované indexy v tabulkách optimalizovaných pro paměť jsou implementovány pomocí datové struktury označované jako Bw-tree, původně vizualizované a popsané microsoft Research v roce 2011. Bw-strom je varianta B-stromu bez zámků a západek. Další informace naleznete v tématu Bw-tree: A B-tree for New Hardware Platforms.
Na vysoké úrovni lze Bw-tree pochopit jako mapu stránek uspořádaných podle ID stránky (PidMap), zařízení pro přidělení a opakované použití ID stránek (PidAlloc) a sady stránek propojených v mapě stránky a k sobě navzájem. Tyto tři dílčí podkomponenty vysoké úrovně tvoří základní vnitřní strukturu Bw-tree.
Struktura se podobá normálnímu stromu B v tom smyslu, že každá stránka má sadu hodnot klíčů, které jsou seřazené a v indexu jsou úrovně, které odkazují na nižší úroveň a úrovně listu odkazují na řádek dat. Existuje však několik rozdílů.
Stejně jako u indexů hash je možné propojit více datových řádků za účelem podpory správy verzí. Ukazatele na stránku mezi úrovněmi jsou logická ID stránek, které se odkazují na tabulku mapování stránek, jež obsahuje fyzickou adresu pro každou stránku.
Nejsou k dispozici žádné místní aktualizace indexových stránek. Pro tento účel jsou zavedeny nové rozdílové stránky.
- Aktualizace stránek nevyžadují zajištění ani uzamykání.
- Indexové stránky nejsou pevnou velikostí.
Hodnota klíče na každé úrovni ne-listových stránek je nejvyšší hodnota, kterou obsahuje dítě, na které stránka ukazuje, a každý řádek také obsahuje ID logické stránky. Na stránkách na úrovni listu obsahuje spolu s klíčovou hodnotou fyzickou adresu datového řádku.
Vyhledávání bodových hodnot je podobné B-stromům, s tím rozdílem, že stránky jsou propojeny pouze jedním směrem, a databázový stroj sleduje pravé ukazatele stránky, kde každá ne-listová stránka má nejvyšší hodnotu svého podřízeného, na rozdíl od nejnižší hodnoty jako v B-stromu.
Pokud se stránka na úrovni listu musí změnit, databázový stroj nezmění samotnou stránku. Databázový stroj vytvoří rozdílový záznam, který popisuje změnu, a připojí ho na předchozí stránku. Pak také aktualizuje adresu tabulky stránkovací mapy pro předchozí stránku na adresu rozdílového záznamu, který se nyní stává fyzickou adresou této stránky.
Ke správě struktury stromu Bw mohou být požadovány tři různé operace: konsolidace, rozdělení a sloučení.
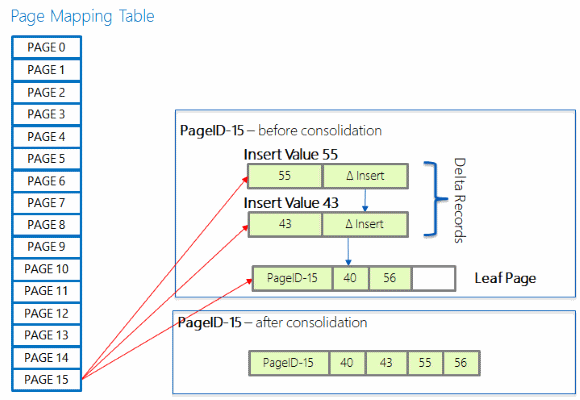
Rozdílová konsolidace
Dlouhý řetězec delta záznamů může vést k poklesu výkonu hledání, protože při hledání v indexu může vyžadovat dlouhé procházení řetězce. Pokud je nový rozdílový záznam přidán do řetězu, který již má 16 prvků, změny v rozdílových záznamech jsou sloučeny do odkazované indexové stránky a stránka se pak znovu sestaví, včetně změn označených novým rozdílovým záznamem, který aktivoval sloučení. Nově znovu sestavená stránka má stejné ID stránky, ale novou adresu paměti.
Rozdělená stránka
Indexová stránka ve stromu Bw roste podle potřeby, počínaje uložením jednoho řádku až po uložení maximálně 8 kB. Jakmile indexová stránka roste na 8 kB, nové vložení jednoho řádku způsobí rozdělení indexové stránky. Pokud jde o interní stránku, znamená to, že není k dispozici dostatek prostoru pro přidání další hodnoty klíče a ukazatele. U listové stránky to znamená, že řádek by byl příliš velký na to, aby se vešel na stránku, jakmile se začlení všechny rozdílové záznamy. Informace o statistikách v záhlaví listové stránky sledují, kolik místa je potřeba pro sloučení rozdílových záznamů. Tyto informace se upraví, jakmile je přidán každý nový rozdílový záznam.
Operace rozdělení se provádí ve dvou atomických krocích. V následujícím diagramu předpokládejme, že listová stránka vynutí rozdělení, protože se vkládá klíč s hodnotou 5, a existuje ne-listová stránka, která odkazuje na konec aktuální listové stránky (hodnota klíče 4).

Krok 1: Přidělte dvě nové stránky P1 a P2rozdělte řádky ze staré P1 stránky na tyto nové stránky, včetně nově vloženého řádku. Nový slot v tabulce mapování stránek se používá k uložení fyzické adresy stránky P2. Stránky P1 a P2 zatím nejsou přístupné pro žádné souběžné operace. Kromě toho je nastavený logický ukazatel z P1 na P2 . Potom v jednom atomickém kroku aktualizujte tabulku mapování stránky tak, aby se ukazatel změnil ze starého P1 na nový P1.
Krok 2: Ne-listová stránka odkazuje na P1, ale neexistuje žádný přímý ukazatel z ne-listové stránky na P2.
P2 je dosažitelná pouze prostřednictvím P1. Pokud chcete vytvořit ukazatel z neleaf stránky na P2, přidělte novou neleaf stránku (interní indexovou stránku), zkopírujte všechny řádky ze staré neleaf stránky a přidejte nový řádek, na který chcete odkazovat P2. Jakmile to uděláte, aktualizujte v jednom atomickém kroku tabulku mapování stránek tak, aby změnila ukazatel ze staré neleaf stránky na novou neleaf stránku.
Stránka sloučit
DELETE Pokud má operace za následek, že stránka má méně než 10 procent maximální velikosti stránky (8 kB) nebo s jedním řádkem, tato stránka se sloučí s souvislou stránkou.
Při odstranění řádku ze stránky se přidá rozdílový záznam pro odstranění. Kromě toho se provede kontrola, která určí, zda indexová stránka (neleafová stránka) splňuje kritéria pro sloučení. Tato kontrola ověří, jestli je zbývající místo po odstranění řádku menší než 10 procent maximální velikosti stránky. Pokud splňuje podmínky, sloučení se provádí ve třech "atomických" krocích.
Na následujícím obrázku předpokládejme, že DELETE operace odstraní hodnotu klíče 10.

Krok 1: Vytvoří se rozdílová stránka představující klíčovou hodnotu 10 (modrý trojúhelník) a její ukazatel v nelistové stránce Pp1 je nastaven na novou rozdílovou stránku. Vytvoří se také speciální stránka merge-delta (zelený trojúhelník), která je propojena tak, aby ukazovala na rozdílovou stránku. V této fázi nejsou obě stránky (delta page a merge-delta page) viditelné pro žádnou souběžnou transakci. V jednom atomickém kroku se ukazatel na stránku na úrovni listu P1 v tabulce mapování stránky aktualizuje tak, aby odkazoval na stránku merge-delta. Po tomto kroku nyní položka pro hodnotu klíče 10 v Pp1 odkazuje na stránku merge-delta.
Krok 2: Řádek představující hodnotu klíče 7 na neleafové stránce Pp1 je potřeba odebrat a položku pro klíčovou hodnotu 10 aktualizovat tak, aby odkazovala na P1. Chcete-li to provést, je přidělena nová ne-listová stránka Pp2 a všechny řádky z Pp1 jsou zkopírovány, s výjimkou řádku představujícího hodnotu 7 klíče; poté se řádek pro hodnotu 10 klíče aktualizuje tak, že bude odkazovat na stránku P1. V jednom atomovém kroku se po dokončení aktualizuje položka tabulky mapování stránky, která ukazuje na Pp1, aby nyní odkazovala na Pp2.
Pp1 už není dostupný.
Krok 3: Stránky na úrovni listu P2 a P1 jsou sloučeny a rozdílové stránky se odeberou. Za tímto účelem se přidělí nová stránka P3 a řádky z P2 a P1 budou sloučeny a rozdílové změny stránky jsou zahrnuty v nové P3. Pak se v jednom atomovém kroku aktualizuje položka tabulky mapování stránky odkazující na stránku P1, aby odkazovala na stránku P3.
Důležité informace o výkonu pro neclusterované indexy optimalizované pro paměť
Výkon neclusterovaného indexu je lepší než u indexů hash při dotazování tabulky optimalizované pro paměť s predikáty nerovnosti.
Sloupec v tabulce optimalizované pro paměť může být součástí indexu hash i neclusterovaného indexu.
Pokud má klíčový sloupec v neklastrovaném indexu mnoho duplicitních hodnot, může se zhoršit výkon u aktualizací, vkládání a odstraňování. Jedním ze způsobů, jak v této situaci zlepšit výkon, je přidat sloupec, který má lepší selektivitu v klíči indexu.
Metadata indexu
Pokud chcete prozkoumat metadata indexu, jako jsou definice indexu, vlastnosti a statistiky dat, použijte následující systémová zobrazení:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Předchozí zobrazení platí pro všechny typy indexů. Pro indexy columnstore navíc použijte následující zobrazení:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
U indexů columnstore jsou všechny sloupce uloženy v metadatech jako zahrnuté sloupce. Index columnstore nemá klíčové sloupce.
Pro indexy v tabulkách optimalizovaných pro paměť navíc použijte následující zobrazení:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Související obsah
- VYTVOŘTE INDEX (Transact-SQL)
- Optimalizace údržby indexů za účelem zlepšení výkonu dotazů a snížení spotřeby prostředků
- dělené tabulky a indexy
- Indexy v tabulkách Memory-Optimized
- Indexy columnstore: Přehled
- Indexy ve vypočítaných sloupcích
- Ladění neclusterovaných indexů s využitím návrhů týkajících se chybějících indexů