Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Toto téma vysvětluje, jak nainstalovat Odstranění duplicitních dat, vyhodnotit úlohy pro odstranění duplicitních dat a povolit Odstranění duplicitních dat na konkrétních svazcích.
Note
Pokud plánujete spustit Odstranění duplicitních dat v clusteru s podporou převzetí služeb při selhání, musí mít každý uzel v clusteru nainstalovanou roli serveru Odstranění duplicitních dat.
Instalace odstranění duplicitních dat
Important
KB4025334 obsahuje opravy odstranění duplicitních dat, včetně důležitých oprav spolehlivosti, a důrazně doporučujeme ji nainstalovat při použití Odstranění duplicitních dat s Windows Serverem 2016.
Instalace odstranění duplicitních dat pomocí Správce serveru
- V průvodci přidáním rolí a funkcí vyberte Role serveru a pak vyberte Odstranění duplicitních dat.
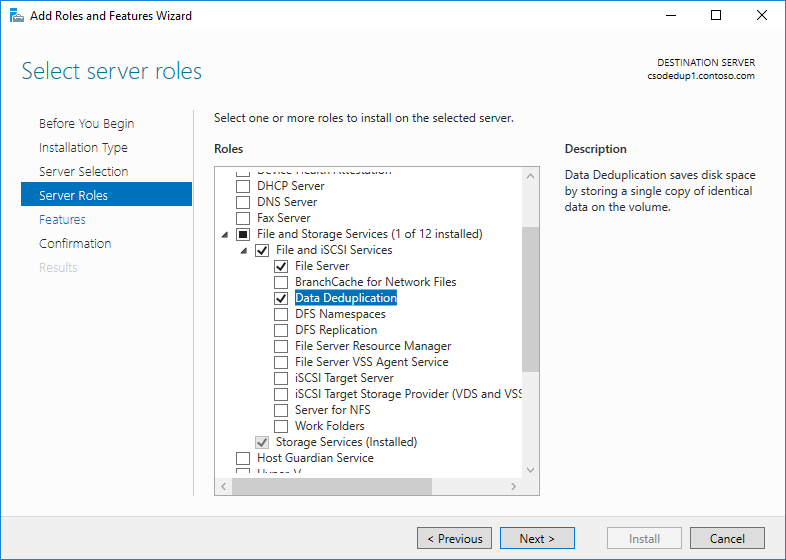
- Klepněte na tlačítko Další , dokud není tlačítko Instalovat aktivní, a potom klepněte na tlačítko Nainstalovat.
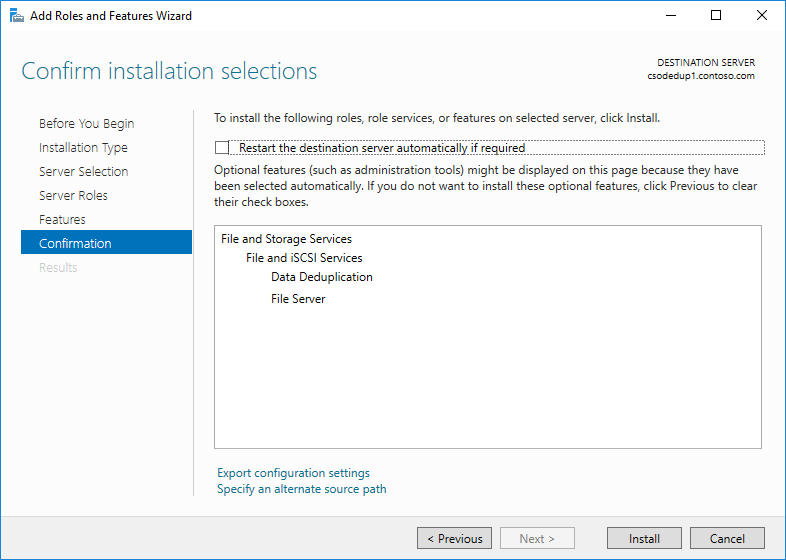
Instalace odstranění duplicitních dat pomocí PowerShellu
Odstranění duplicitních dat nainstalujete spuštěním následujícího příkazu PowerShellu jako správce: Install-WindowsFeature -Name FS-Data-Deduplication
Postup instalace deduplikace dat:
Ze serveru s Windows Serverem 2016 nebo novějším nebo z počítače s Windows s nainstalovanými nástroji pro vzdálenou správu serveru nainstalujte Odstranění duplicitních dat s explicitním odkazem na název serveru (nahraďte MyServer skutečným názvem instance serveru):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOr
Připojte se vzdáleně k instanci serveru pomocí vzdáleného přístupu PowerShellu a nainstalujte datovou deduplikaci pomocí DISM.
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Povolení odstranění duplicitních dat
Určení úloh, které jsou kandidáty pro odstranění duplicitních dat
Odstranění duplicitních dat může efektivně minimalizovat náklady na spotřebu dat serverové aplikace snížením místa na disku spotřebovaném redundantními daty. Před povolením odstranění duplicitních dat je důležité porozumět charakteristikám úlohy, abyste měli jistotu, že z úložiště získáte maximální výkon. Existují dvě třídy úloh, které je potřeba vzít v úvahu:
-
Doporučené úlohy , u kterých bylo prokázáno, že mají obě datové sady, které mají vysokou výhodu odstranění duplicitních dat, a mají vzory spotřeby prostředků, které jsou kompatibilní s modelem následného zpracování Odstranění duplicitních dat. U těchto úloh doporučujeme vždy povolit odstranění duplicitních dat :
- Souborové servery pro obecné účely (GPFS) obsluhující sdílené složky, jako jsou sdílené složky týmu, domovské složky uživatelů, pracovní složky a sdílené složky pro vývoj softwaru.
- Servery virtualizované desktopové infrastruktury (VDI).
- Virtualizované zálohovací aplikace, jako je Microsoft Data Protection Manager (DPM).
- Úlohy, které by mohly mít prospěch z deduplikace, ale nejsou vždy dobrými kandidáty pro deduplikaci. Například následující úlohy můžou s odstraněním duplicitních dat dobře fungovat, ale nejprve byste měli vyhodnotit výhody odstranění duplicit:
- Hostitelé pro obecné účely Hyper-V
- SERVERY SQL
- Servery pro klíčové podnikové aplikace
Vyhodnocení úloh pro odstranění duplicitních dat
Important
Pokud spouštíte doporučenou úlohu, můžete tuto část přeskočit a přejít na Povolení odstranění duplicitních dat pro vaši úlohu.
Pokud chcete zjistit, jestli úloha funguje dobře s odstraněním duplicitních dat, odpovězte na následující otázky. Pokud si nejste jisti úlohou, zvažte pilotní nasazení Odstranění duplicitních dat na testovací datové sadě pro vaši úlohu a podívejte se, jak funguje.
Má datová sada úlohy dostatek duplicit, aby bylo možné povolit odstranění duplicitních dat? Před povolením Odstranění duplicitních dat pro úlohu prozkoumejte, kolik duplicit má datová sada vaší úlohy, pomocí nástroje pro vyhodnocení úspor odstranění duplicitních dat nebo DDPEval. Po instalaci Odstranění duplicitních dat najdete tento nástroj na adrese
C:\Windows\System32\DDPEval.exe. Nástroj DDPEval může vyhodnotit potenciál optimalizace přímo připojených svazků (včetně místních jednotek nebo sdílených svazků clusteru) a mapovaných nebo nenamapovaných síťových sdílených složek.Spuštění DDPEval.exe vrátí výstup podobný následujícímu:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Jak vypadají vzorce vstupně-výstupních operací mé zátěže na její datovou sadu? Jaký výkon mám pro svou úlohu? Odstranění duplicitních dat optimalizuje soubory jako pravidelnou úlohu, a ne při zápisu souboru na disk. V důsledku toho je důležité prozkoumat očekávané vzory čtení úloh na deduplikovaném svazku. Vzhledem k tomu, že Odstranění duplicitních dat přesune obsah souboru do úložiště bloků dat a pokusí se co nejvíce uspořádat úložiště bloků dat podle souboru, operace čtení fungují nejlépe, když se použijí na sekvenční rozsahy souboru.
Databázové úlohy obvykle mají více vzorů náhodného čtení než vzory sekvenčního čtení, protože databáze obvykle nezaručují, že rozložení databáze bude optimální pro všechny možné dotazy, které mohou být spuštěny. Vzhledem k tomu, že oddíly úložiště bloků dat můžou existovat po celém svazku, může přístup k rozsahům dat v úložišti bloků dat pro databázové dotazy zavádět další latenci. Úlohy s vysokým výkonem jsou zvláště citlivé na tuto dodatečnou latenci, ale jiné úlohy podobné databázovým nemusí být.
Note
Tyto obavy platí hlavně pro úlohy úložiště na svazcích tvořených tradičními rotačními úložnými médium (označované také jako pevné disky nebo pevné disky). Infrastruktura úložiště typu All-Flash (označovaná také jako disky SSD nebo Solid State Disk) je méně ovlivněná náhodnými vstupně-výstupními vzory, protože jedna z vlastností flashového média je stejná jako doba přístupu ke všem umístěním na médiu. Odstranění duplicitních dat proto nebude mít stejnou latenci čtení do datových sad úloh uložených na all-flash médiu, jako by to bylo u tradičních rotačních úložných médií.
Jaké jsou požadavky na prostředky úlohy na serveru? Vzhledem k tomu, že Odstranění duplicitních dat používá model následného zpracování, odstranění duplicitních dat pravidelně potřebuje k dokončení optimalizace a dalších úloh dostatek systémových prostředků. To znamená, že úlohy, které mají čas nečinnosti, například večer nebo o víkendech, jsou vynikajícími kandidáty na deduplikaci, zatímco úlohy, které běží celý den každý den, nemusejí být. Úlohy, které nemají dobu nečinnosti, mohou být stále vhodnými kandidáty na odstranění duplicitních dat, pokud úloha nemá na serveru vysoké požadavky na prostředky.
Povolení odstranění duplicitních dat
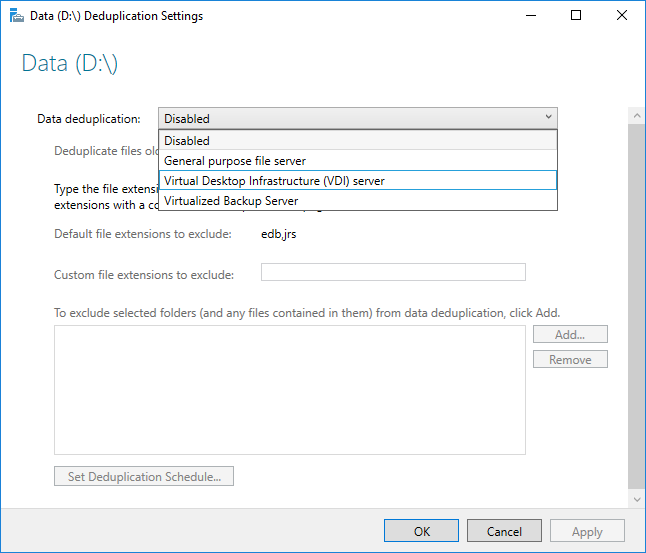
Před povolením Odstranění duplicitních dat musíte zvolit typ použití , který se nejvíce podobá vaší úloze. Odstranění duplicitních dat zahrnuje tři typy použití.
- Výchozí – vyladěno speciálně pro souborové servery pro obecné účely
- Hyper-V – vyladěno speciálně pro servery VDI
- Zálohování – vyladěné speciálně pro virtualizované zálohovací aplikace, jako je Například Microsoft DPM
Povolení odstranění duplicitních dat pomocí Správce serveru
- Ve Správci serveru vyberte Souborová služba a služba úložiště .
- Vyberte svazky ze souborových služeb a služeb úložiště.
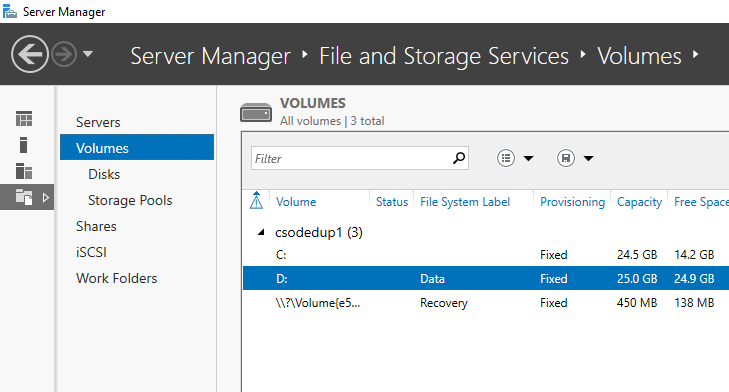
- Klikněte pravým tlačítkem na požadovaný svazek a vyberte Konfigurovat odstranění duplicitních dat.
- V rozevíracím seznamu vyberte požadovaný typ použití a vyberte OK.
- Pokud spouštíte doporučenou úlohu, jste hotovi. Informace o jiných úlohách najdete v tématu Další důležité informace.
Note
Další informace o vyloučení přípon souborů nebo složek a výběr plánu odstranění duplicitních dat, včetně důvodů, proč byste to chtěli udělat, najdete v konfiguraci odstranění duplicitních dat.
Povolení odstranění duplicitních dat pomocí PowerShellu
V kontextu správce spusťte následující příkaz PowerShellu:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Pokud spouštíte doporučenou úlohu, jste hotovi. Informace o jiných úlohách najdete v tématu Další důležité informace.
Note
Rutiny PowerShellu pro deduplikaci dat, včetně Enable-DedupVolume, je možné spouštět vzdáleně pomocí připojení parametru -CimSession k relaci CIM. To je zvlášť užitečné pro vzdálené spuštění rutin PowerShellu pro odstranění duplicitních dat v instanci serveru. Pro vytvoření nové relace CIM spusťte New-CimSession.
Ostatní úvahy
Important
Pokud spouštíte doporučenou úlohu, můžete tuto část přeskočit.
- Typy použití Odstranění duplicitních dat poskytují rozumné výchozí hodnoty pro doporučené úlohy, ale poskytují také dobrý výchozí bod pro všechny úlohy. U jiných úloh než doporučených úloh je možné upravit upřesňující nastavení Odstranění duplicitních dat, aby se zlepšil výkon odstranění duplicitních dat.
- Pokud má vaše úloha na vašem serveru vysoké požadavky na prostředky, měly by být úlohy odstranění duplicitních dat naplánované tak, aby běžely během očekávaných nečinných časů pro danou úlohu. To je obzvlášť důležité při spuštění deduplikace dat na hyperkonvergovaném hostiteli, protože spuštění deduplikace dat během běžné pracovní doby může vést k nedostatku zdrojů pro virtuální počítače.
- Pokud vaše úloha nemá vysoké požadavky na prostředky nebo je důležitější, aby úlohy optimalizace byly dokončeny než požadavky na úlohy, je možné upravit paměť, procesor a prioritu úloh Odstranění duplicitních dat.
Nejčastější dotazy
Chci spustit Odstranění duplicitních dat v datové sadě pro úlohu X. Je to podporované? Kromě úloh, o kterých víme, že nepracují s odstraněním duplicitních dat, plně podporujeme integritu dat při používání odstranění duplicitních dat s jakoukoli úlohou. Microsoft podporuje také doporučené úlohy pro zvýšení výkonu. Výkon jiných úloh výrazně závisí na tom, co dělají na vašem serveru. Musíte zjistit, jaký dopad na výkon má Data Deduplication na vaši úlohu a zda je to pro tuto úlohu přijatelné.
Jaké jsou požadavky na objem deduplikovaných svazků? Ve Windows Serveru 2012 a Windows Serveru 2012 R2 musely být svazky pečlivě dimenzovány, aby se zajistilo, že odstranění duplicitních dat může vyrovnávat se změnami na svazku. To obvykle znamenalo, že průměrná maximální velikost svazku s odstraněním duplicitních dat pro úlohu s vysokou četností změn byla 1–2 TB a absolutní doporučená velikost byla 10 TB. Ve Windows Serveru 2016 se tato omezení odebrala. Další informace najdete v tématu Co je nového v Odstranění duplicitních dat.
Potřebuji upravit plán nebo jiné nastavení odstranění duplicitních dat pro doporučené úlohy? Ne, zadané typy použití byly vytvořeny tak, aby poskytovaly rozumné výchozí hodnoty pro doporučené úlohy.
Jaké jsou požadavky na paměť pro odstranění duplicitních dat?
Odstranění duplicitních dat musí mít minimálně 300 MB + 50 MB pro každou TB logických dat. Pokud například optimalizujete svazek o velikosti 10 TB, potřebujete minimálně 800 MB paměti přidělené pro odstranění duplicitních dat (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Odstranění duplicitních dat sice může optimalizovat svazek s tímto nízkým množstvím paměti, ale takové omezené prostředky zpomalí úlohy Odstranění duplicitních dat.
V optimálním případě by odstranění duplicitních dat mělo mít 1 GB paměti pro každou 1 TB logických dat. Pokud například optimalizujete svazek o velikosti 10 TB, budete optimálně potřebovat 10 GB paměti přidělené pro odstranění duplicitních dat (1 GB * 10). Tento poměr zajistí maximální výkon úloh odstranění duplicitních dat.
Jaké jsou požadavky na úložiště pro odstranění duplicitních dat? Ve Windows Serveru 2016 může Odstranění duplicitních dat podporovat velikosti svazků až 64 TB. Další informace najdete v tématu Co je nového v Odstranění duplicitních dat.