Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento dokument popisuje, jak odstranění duplicitních dat funguje.
Jak funguje Odstranění duplicitních dat?
Odstranění duplicitních dat ve Windows Serveru bylo vytvořeno s následujícími dvěma principy:
Optimalizace by se neměla dostat do způsobu zápisu na disk . Odstranění duplicitních dat optimalizuje data pomocí modelu následného zpracování. Všechna data se zapisují neoptimalizovaný na disk a poté se optimalizují později odstraněním duplicitních dat.
Optimalizace by neměla měnit sémantiku přístupu Uživatelé a aplikace, které přistupují k datům na optimalizovaném svazku, si úplně neuvědomují, že soubory, ke kterým přistupují, byly odstraněny duplicity.
Při povolení pro svazek se deduplikace dat spustí na pozadí, aby:
- Identifikace opakovaných vzorů napříč soubory na daném svazku
- Bez problémů přesuňte tyto bloky nebo části pomocí speciálních ukazatelů označovaných jako reparse body, které směřují na jedinečnou kopii tohoto bloku.
K tomu dochází v následujících čtyřech krocích:
- Zkontrolujte v systému souborů soubory, které splňují zásady optimalizace.

- Rozdělte soubory do bloků s proměnlivou velikostí.

- Identifikace jedinečných bloků dat
- Umístěte bloky dat do úložiště bloků dat a volitelně je zkomprimujte.
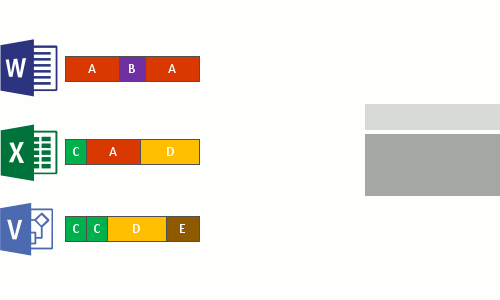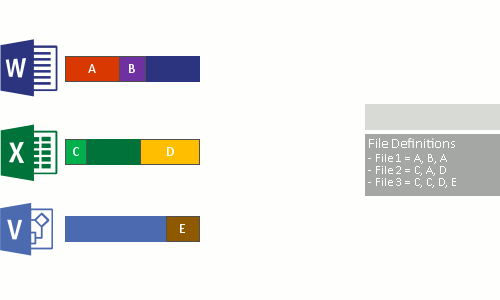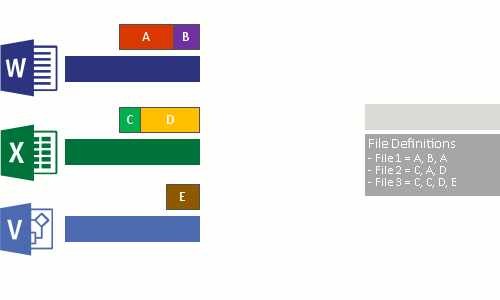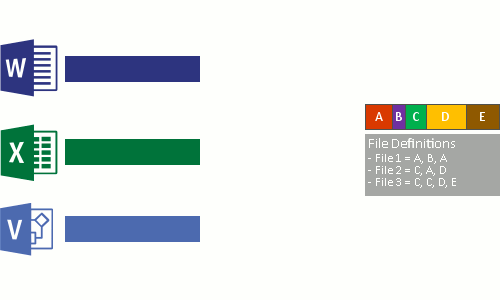
- Nahraďte původní datový proud souboru nyní optimalizovaných souborů spojovacím bodem do úložiště bloků dat.
Při čtení optimalizovaných souborů systém souborů odesílá soubory s převodním bodem do filtru systému souborů pro deduplikaci dat (Dedup.sys). Filtr přesměruje operaci čtení na příslušné bloky dat, které tvoří datový proud pro daný soubor v úložišti bloků dat. Změny rozsahů souborů s odstraněnými duplicitními daty se bez optimalizace zapíšou na disk a optimalizují se při příštím spuštění optimalizační úlohou.
Typy použití
Následující typy použití poskytují přiměřenou konfiguraci odstranění duplicitních dat pro běžné úlohy:
| Typ použití | Ideální zátěže | Co se liší |
|---|---|---|
| Výchozí | Souborový server pro obecné účely:
|
|
| Hyper-V | Servery virtualizované desktopové infrastruktury (VDI) |
|
| Zálohování | Virtualizované zálohovací aplikace, jako je Microsoft Data Protection Manager (DPM) |
|
Jobs
Deduplikace dat používá strategii následného zpracování k optimalizaci a údržbě prostorové efektivity svazku.
| Název úlohy | Popisy úloh | Výchozí plán |
|---|---|---|
| Optimalizace | Úloha optimalizace deduplikuje data na svazku podle nastavení zásad svazku, (volitelně) komprimuje tyto bloky a ukládá je jedinečně v úložišti bloků. Proces optimalizace, který odstranění duplicitních dat používá, je podrobně popsán v části Jak funguje Odstranění duplicitních dat?. | Jednou za hodinu |
| Automatické uvolňování paměti | Úloha odstraňování nepotřebných dat uvolňuje místo na disku odebráním zbytečných částí, na které již neodkazují soubory, které byly nedávno změněny nebo odstraněny. | Každou sobotu v 2:35 |
| Kontrola integrity | Úloha integrity scrub identifikuje poškození v úložišti bloků z důvodu selhání disku nebo chybných sektorů. Pokud je to možné, odstranění duplicitních dat může automaticky používat funkce svazku (například zrcadlení nebo paritu na svazku Prostorů úložiště) k rekonstrukci poškozených dat. Odstranění duplicitních dat navíc uchovává záložní kopie oblíbených bloků dat, když se na tyto bloky odkazuje více než 100krát v oblasti označované jako hotspot. | Každou sobotu v 3:35 |
| Neoptimalizace | Úloha neoptimalizace, což je speciální úloha, která by měla být spuštěna pouze ručně, vrátí optimalizaci provedenou deduplikací a zakáže Data Deduplication pro tento svazek. | Pouze na vyžádání |
Terminologie odstranění duplicitních dat
| Term | Definition |
|---|---|
| Blok | Část souboru je segment, který byl vybrán algoritmem deduplikace dat, protože se pravděpodobně vyskytuje i v jiných, podobných souborech. |
| úložiště bloků dat | Úložiště bloků dat je uspořádaná řada souborů kontejneru ve složce Systémové informace o svazku, kterou Odstranění duplicitních dat používá k jedinečnému ukládání bloků dat. |
| Odstranění duplicitních dat | Zkratka pro Odstranění duplicitních dat, která se běžně používá v PowerShellu, rozhraních API a komponentách Windows Serveru a komunitě Windows Serveru. |
| metadata souboru | Každý soubor obsahuje metadata, která popisují zajímavé vlastnosti souboru, které nesouvisejí s hlavním obsahem souboru. Například datum vytvoření, datum posledního čtení, autor atd. |
| stream souborů | Stream souboru je hlavním obsahem souboru. Toto je část souboru, kterou odstranění duplicitních dat optimalizuje. |
| systém souborů | Systém souborů je softwarová a disková datová struktura, kterou operační systém používá k ukládání souborů na médiu úložiště. Odstranění duplicitních dat se podporuje u svazků formátovaných systémem souborů NTFS. |
| Filtr systému souborů | Filtr systému souborů je modul plug-in, který upravuje výchozí chování systému souborů. K zachování sémantiky přístupu používá Odstranění duplicitních dat filtr systému souborů (Dedup.sys) k přesměrování čtení na optimalizovaný obsah zcela transparentně na uživatele nebo aplikaci, která provádí požadavek na čtení. |
| Optimalizace | Soubor se považuje za optimalizovaný (nebo deduplikovaný) systémem Řešení deduplikace dat, pokud byl rozdělen na části a jeho jedinečné části byly uloženy v úložišti částí. |
| Optimalizační politika | Zásady optimalizace určují soubory, které se mají považovat za odstranění duplicitních dat. Například soubory mohou být považovány za mimo politiku, pokud jsou zcela nové, otevřené, nacházejí se na určité cestě na svazku nebo mají určitý typ souboru. |
| spojovací bod | Spojovací bod je speciální značka, která systému souborů oznámí předání vstupně-výstupních operací do zadaného filtru systému souborů. Pokud je datový proud souboru optimalizován, Datová deduplikace nahradí datový proud reparse bodem, což umožňuje Datové deduplikaci zachovat přístupovou sémantiku pro tento soubor. |
| Hlasitost | Svazek je prvek Windows pro logické úložiště, které může zahrnovat více fyzických úložných zařízení na jednom či více serverech. Odstranění duplicitních dat je povolené na bázi svazku po svazku. |
| Pracovní zátěž | Úloha je aplikace, která běží na Windows Serveru. Mezi ukázkové úlohy patří souborový server pro obecné účely, Hyper-V a SQL Server. |
Warning
Pokud nemáte pokyn autorizovaným pracovníkem podpory Společnosti Microsoft, nepokoušejte se ručně upravit úložiště bloků dat. To může vést k poškození nebo ztrátě dat.
Nejčastější dotazy
Jak se Odstranění duplicitních dat liší od jiných optimalizačních produktů? Mezi odstraněním duplicitních dat a dalšími běžnými produkty pro optimalizaci úložiště existuje několik důležitých rozdílů:
Jak se odstranění duplicitních dat liší od úložiště jedné instance? Jednoúčelové úložiště nebo SIS je technologie, která předchází odstranění duplicitních dat a byla poprvé představena ve Windows Storage Serveru 2008 R2. Pro optimalizaci svazku jednoúčelové úložiště identifikovalo soubory, které byly zcela identické a nahradily je logickými odkazy na jednu kopii souboru uloženého v běžném úložišti SIS. Deduplikace dat, na rozdíl od úložiště s jednou instancí, může dosáhnout úspory místa u souborů, které nejsou identické, ale sdílejí mnoho běžných vzorů, a také u souborů, které samy obsahují mnoho opakujících se vzorů. Úložiště jednotlivých instancí bylo zrušeno ve Windows Serveru 2012 R2 a ve Windows Serveru 2016 bylo odebráno ve prospěch deduplikace dat.
Jak se odstranění duplicitních dat liší od komprese NTFS? Komprese NTFS je funkce NTFS, kterou můžete aktivovat volitelně a to na úrovni svazku. Při kompresi NTFS je každý soubor optimalizovaný jednotlivě prostřednictvím komprese v době zápisu. Na rozdíl od komprese NTFS může odstranění duplicitních dat dosáhnout úspory mezer mezi všemi soubory na svazku. To je lepší než komprese NTFS, protože soubory mohou mít jak interní duplicitu (což je vyřešeno kompresí NTFS), tak podobnosti s jinými soubory na svazku (které komprese NTFS neřeší). Odstranění duplicitních dat má navíc model následného zpracování, což znamená, že se nové nebo upravené soubory zapíšou na disk neoptimalizovaný a budou optimalizovány později odstraněním duplicitních dat.
Jak se Odstranění duplicitních dat liší od formátů souborů archivu, jako jsou zip, rar, 7z, cab atd.? Formáty souborů archivu, jako je zip, rar, 7z, cab atd., provádějí kompresi přes zadanou sadu souborů. Podobně jako odstranění duplicitních dat jsou duplikované vzory v souborech a duplicitní vzory napříč soubory optimalizované. Musíte ale zvolit soubory, které chcete zahrnout do archivu. Sémantika přístupu se také liší. Pokud chcete získat přístup ke konkrétnímu souboru v archivu, musíte otevřít archiv, vybrat konkrétní soubor a dekomprimovat ho, abyste ho mohli použít. Odstranění duplicitních dat funguje transparentně uživatelům a správcům a nevyžaduje ruční zahájení. Odstranění duplicitních dat navíc zachovává sémantiku přístupu: optimalizované soubory se po optimalizaci zobrazují beze změny.
Můžu u vybraného typu použití změnit nastavení Odstranění duplicitních dat? Yes. Odstranění duplicitních dat sice poskytuje rozumné výchozí hodnoty pro doporučené úlohy, ale přesto můžete chtít upravit nastavení Odstranění duplicitních dat, aby bylo úložiště co nejvíce dostupné. Kromě toho budou další úlohy vyžadovat určité úpravy, aby se zajistilo, že Odstranění duplicitních dat nenaruší úlohu.
Můžu ručně spustit úlohu Odstranění duplicitních dat? Ano, všechny úlohy odstranění duplicitních dat se můžou spouštět ručně. To může být žádoucí, pokud se naplánované úlohy nespustí kvůli nedostatečným systémovým prostředkům nebo kvůli chybě. Kromě toho lze úlohu neoptimalizace spustit pouze ručně.
Můžu monitorovat historické výsledky úloh odstranění duplicitních dat? Ano, všechny úlohy odstranění duplicitních dat tvoří položky v protokolu událostí systému Windows.
Můžu v systému změnit výchozí plány úloh odstranění duplicitních dat? Ano, všechny plány jsou konfigurovatelné. Úprava výchozích plánů deduplikace dat je zvlášť žádoucí, aby úlohy deduplikace měly čas na dokončení a nekonkurovaly o prostředky se zátěží.