Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V předchozí fázi tohoto kurzu jsme nainstalovali na váš počítač PyTorch. Teď ho použijeme k nastavení kódu s daty, která použijeme k vytvoření modelu.
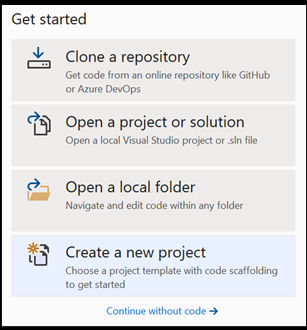
Otevřete nový projekt v aplikaci Visual Studio.
- Otevřete Visual Studio a zvolte
create a new project.
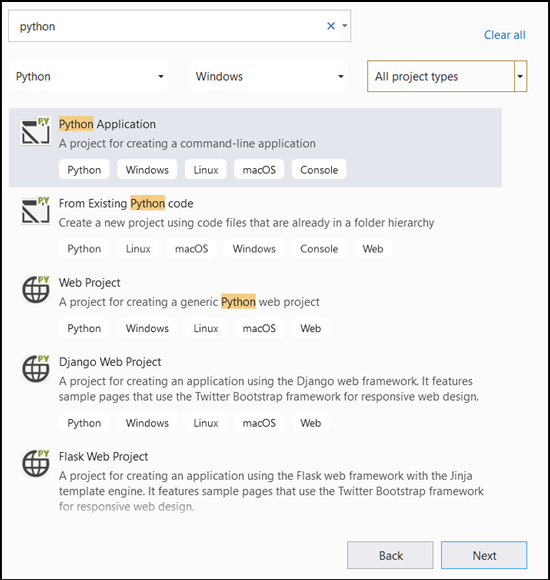
- Na panelu hledání zadejte
Pythona vybertePython Applicationjako šablonu projektu.
- V okně konfigurace:
- Pojmenujte projekt. Tady ji nazýváme DataClassifier.
- Zvolte umístění projektu.
- Pokud používáte VS2019, zkontrolujte, jestli
Create directory for solutionje zaškrtnuté. - Pokud používáte VS2017, ujistěte se, že
Place solution and project in the same directorynení zaškrtnuto.
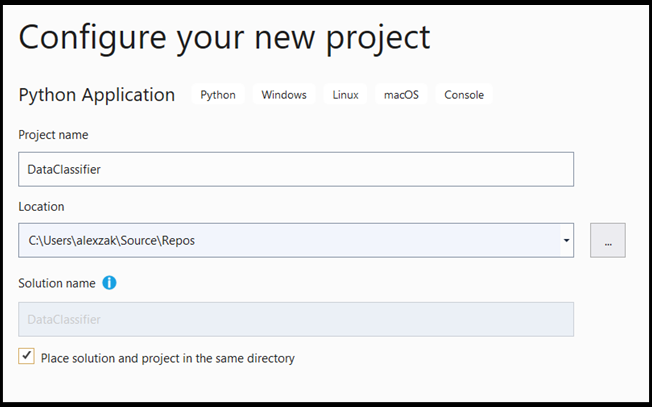
Stisknutím create vytvoříte projekt.
Vytvoření interpreta Pythonu
Teď musíte definovat nový interpret Pythonu. To musí zahrnovat balíček PyTorch, který jste nedávno nainstalovali.
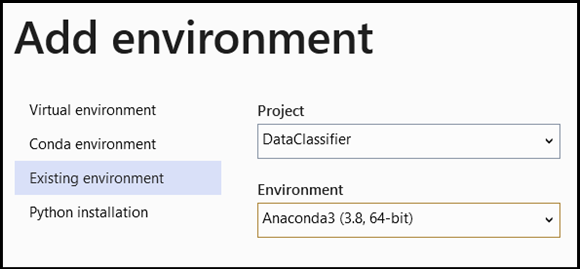
- Přejděte na výběr interpreta a vyberte
Add Environment:

- V okně
Add EnvironmentvyberteExisting environmenta zvolteAnaconda3 (3.6, 64-bit). To zahrnuje balíček PyTorch.
Pokud chcete otestovat nový interpret Pythonu a balíček PyTorch, zadejte do DataClassifier.py souboru následující kód:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
Výstup by měl být náhodný tensor 5x3 podobný následujícímu.
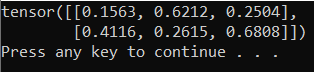
Poznámka:
Zajímá vás další informace? Navštivte oficiální stránky PyTorch.
Pochopení dat
Model vytrénujeme na datové sadě Iris Společnosti Fisher. Tato známá datová sada obsahuje 50 záznamů pro každý ze tří druhů Iris: Iris setosa, Iris virginica a Iris versicolor.
Bylo publikováno několik verzí datové sady. Datovou sadu Iris najdete v úložišti strojového učení UCI, naimportujete datovou sadu přímo z knihovny Python Scikit-learn nebo použijete jakoukoli jinou publikovanou verzi. Informace o datové sadě Iris flower najdete na jeho stránce Wikipedie.
V tomto kurzu předvedete, jak vytrénovat model pomocí tabulkového typu vstupu, použijete datovou sadu Iris exportovanou do excelového souboru.
Každý řádek excelové tabulky bude zobrazovat čtyři vlastnosti kosatců: délku listů v cm, šířku listů v cm, délku okvětního lístku v cm a šířku okvětního lístku v cm. Tyto vlastnosti budou sloužit jako vstup. Poslední sloupec obsahuje typ Iris související s těmito parametry a bude představovat regresní výstup. Datová sada celkem zahrnuje 150 vstupů čtyř funkcí, z nichž každý odpovídá příslušnému typu Iris.
Regresní analýza zkoumá vztah mezi vstupními proměnnými a výsledkem. Na základě vstupu se model naučí predikovat správný typ výstupu – jeden ze tří typů Iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Důležité
Pokud se rozhodnete k vytvoření vlastního modelu použít jakoukoli jinou datovou sadu, budete muset zadat vstupní proměnné modelu a výstup podle vašeho scénáře.
Načtěte datovou sadu.
Stáhněte datovou sadu Iris ve formátu Excelu. Najdete ho tady.
DataClassifier.pyDo souboru ve složce Soubory Průzkumníka řešení přidejte následující příkaz importu, abyste získali přístup ke všem balíčkům, které budeme potřebovat.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Jak vidíte, budete k načítání a manipulaci s daty a balíčku torch.nn, který obsahuje moduly a rozšiřitelné třídy pro vytváření neurálních sítí, používat balíček pandas (Analýza dat Pythonu).
- Načtěte data do paměti a ověřte počet tříd. Očekáváme, že uvidíme 50 položek každého typu Iris. Nezapomeňte zadat umístění datové sady na počítači.
Do souboru DataClassifier.py přidejte následující kód.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
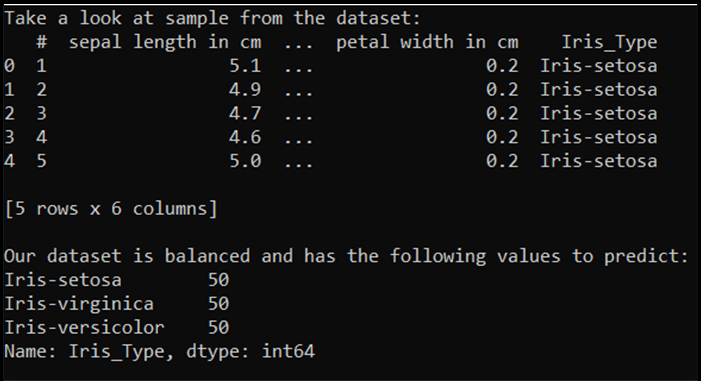
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Při spuštění tohoto kódu je očekávaný výstup následující:
Abychom mohli datovou sadu používat a vytrénovat model, musíme definovat vstup a výstup. Vstup zahrnuje 150 řádků funkcí a výstupem je sloupec typu Iris. Neurální síť, kterou použijeme, vyžaduje číselné proměnné, takže výstupní proměnnou převedete na číselný formát.
- V datové sadě vytvořte nový sloupec, který bude představovat výstup v číselném formátu a definuje regresní vstup a výstup.
Do souboru DataClassifier.py přidejte následující kód.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
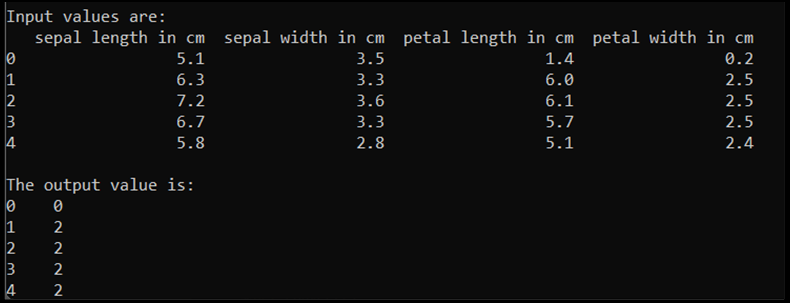
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Při spuštění tohoto kódu je očekávaný výstup následující:
K trénování modelu potřebujeme převést vstup a výstup modelu do formátu Tensor:
- Převést na Tensor:
Do souboru DataClassifier.py přidejte následující kód.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Pokud kód spustíme, očekávaný výstup zobrazí vstupní a výstupní formát následujícím způsobem:

Vstupní hodnoty jsou 150. Přibližně 60% bude trénovacími daty modelu. Budete uchovávat 20% pro ověření a 30% pro test.
V tomto kurzu je velikost dávky pro trénovací datovou sadu definovaná jako 10. V trénovací sadě je 95 položek, což znamená, že v průměru je zde 9 celých dávek k iteraci přes trénovací sadu jednou za jednu epochu. Velikost dávky ověřovací a testovací sady zachováte jako 1.
- Rozdělte data pro trénování, ověřování a testování sad:
Do souboru DataClassifier.py přidejte následující kód.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Další kroky
Když jsou data připravena, je čas vytrénovat náš model PyTorch.