Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I denne vejledning forklares det, hvordan du opretter en Spark Job Definition, der indeholder Python-kode med Spark Structured Streaming til at lande data i et lakehouse og derefter betjene dem via et SQL Analytics-slutpunkt. Når du har fuldført denne hurtige introduktion, har du en Spark-jobdefinition, der kører løbende, og SQL Analytics-slutpunktet kan få vist de indgående data.
Opret et Python-script
Brug følgende Python-script til at oprette en deltastreamingtabel i et lakehouse ved hjælp af Apache Spark. Scriptet læser en stream af genererede data (én række pr. sekund) og skriver dem i tilføjelsestilstand til en Delta-tabel med navnet streamingtable. Oplysningerne om data og kontrolpunkt gemmes i det angivne lakehouse.
Brug følgende Python-kode, der bruger Spark-struktureret streaming til at hente data i en lakehouse-tabel.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Gem dit script som Python-fil (.py) på din lokale computer.
Opret et lakehouse
Brug følgende trin til at oprette et lakehouse:
Log på Microsoft Fabric-portalen.
Gå til det ønskede arbejdsområde, eller opret et nyt, hvis det er nødvendigt.
Hvis du vil oprette et søhus, skal du vælge Nyt element i arbejdsrummet og derefter vælge Søhus i det panel, der åbnes.
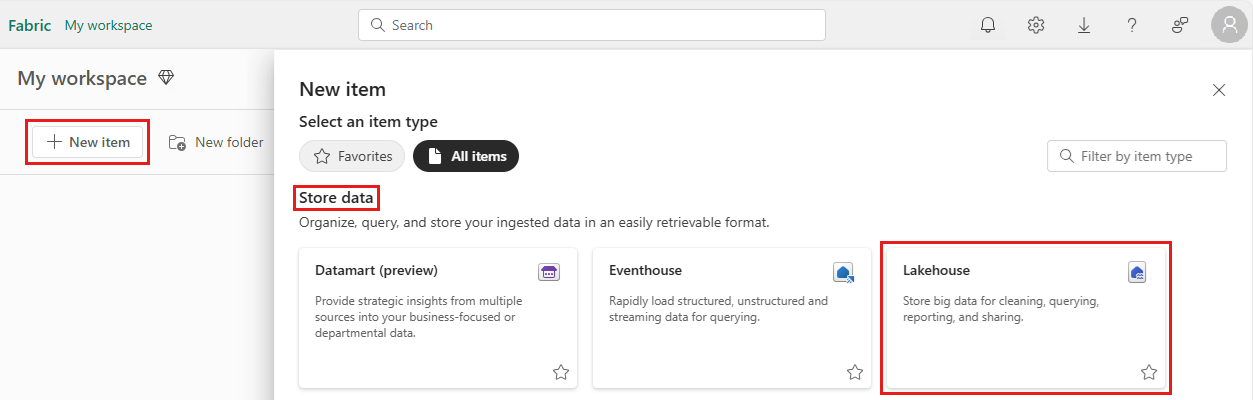
Indtast navnet på dit søhus, og vælg Opret.

Opret en Spark-jobdefinition
Brug følgende trin til at oprette en Spark-jobdefinition:
Fra det samme arbejdsområde, hvor du oprettede et søhus, skal du vælge Nyt element.
I det panel, der åbnes, skal du under Hent data vælge Definition af Spark-job.
Angiv navnet på din Spark-jobdefinition, og vælg Opret.
Vælg Upload , og vælg den Python-fil, du oprettede i det forrige trin.
Under Søhusreference skal du vælge det søhus, du har oprettet.
Angiv forsøgspolitik for Spark-jobdefinition
Brug følgende trin til at angive politikken for forsøg for definitionen af dit Spark-job:
Fra topmenuen skal du vælge ikonet Indstilling .
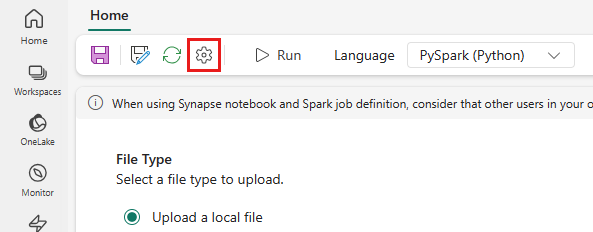
Åbn fanen Optimering, og angiv Udløser for politik for genforsøgTil.
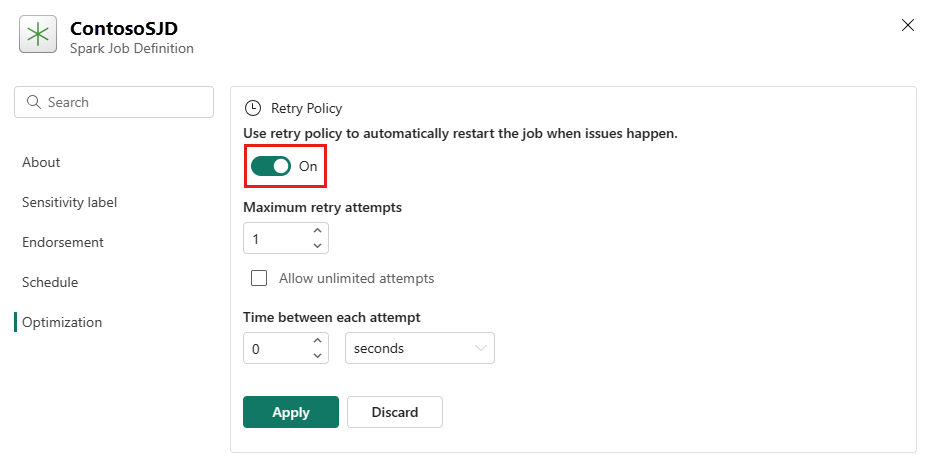
Definer det maksimale antal forsøg, eller markér Tillad ubegrænsede forsøg.
Angiv tiden mellem hvert forsøg igen, og vælg Anvend.


Note
Der er en levetidsgrænse på 90 dage for konfiguration af politik for nye forsøg. Når forsøgspolitikken er aktiveret, genstartes jobbet i henhold til politikken inden for 90 dage. Efter denne periode ophører forsøgspolitikken automatisk med at fungere, og jobbet afsluttes. Brugerne skal derefter genstarte jobbet manuelt, hvilket igen vil genaktivere politikken for forsøg.
Udfør og overvåg Definitionen af Spark-job
Fra topmenuen skal du vælge ikonet Kør .
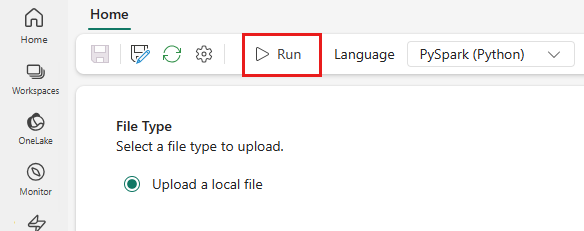
Kontrollér, om Spark-jobdefinitionen blev sendt korrekt, og om den kører.

Få vist data ved hjælp af et SQL Analytics-slutpunkt
Når scriptet kører, oprettes der en tabel med navnet streamingtable med tidsstempel og værdikolonner i lakehouse. Du kan få vist dataene ved hjælp af SQL Analytics-slutpunktet:
Åbn dit Lakehouse fra arbejdsområdet.
Skift til SQL Analytics-slutpunktet fra øverste højre hjørne.
Udvid Skemaer > dbo-tabeller >i navigationsruden til venstre, og vælg streamingtabel for at få vist dataene.