Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Fabric User datafunktioner-programmeringsmodellen definerer mønstre og koncepter for at forfatte funktioner i Fabric.
SDK'en fabric-user-data-functions implementerer denne programmeringsmodel og leverer den nødvendige funktionalitet til at udarbejde og udgive kørbare funktioner. SDK'et giver dig også mulighed for problemfrit at integrere med andre elementer i Fabric-økosystemet, f.eks. Fabric-datakilder.
Dette bibliotek er offentligt tilgængeligt i PyPI og er forudinstalleret i dine brugerdatafunktioner.
Denne artikel forklarer, hvordan man bruger SDK'en til at bygge funktioner, der kan kaldes fra Fabric-portalen, andre Fabric-elementer eller eksterne applikationer ved brug af REST API'en. Du lærer programmeringsmodellen og nøglebegreber med praktiske eksempler.
Tips
For fuldstændige detaljer om alle klasser, metoder og parametre, se SDK-referencedokumentationen.
Getting started med SDK'et
Dette afsnit introducerer kernekomponenterne i User Data Functions SDK og forklarer, hvordan du strukturerer dine funktioner. Du lærer om de nødvendige import, dekoratorer og hvilke typer input- og outputdata, dine funktioner kan håndtere.
SDK til brugerdatafunktioner
SDK'et fabric-user-data-functions leverer de kernekomponenter, du har brug for til at oprette brugerdatafunktioner i Python.
Påkrævede import og initialisering
Hver user data functions-fil skal importere modulet fabric.functions og initialisere eksekveringskonteksten:
import datetime
import fabric.functions as fn
import logging
udf = fn.UserDataFunctions()
Dekoratøren @udf.function()
Funktioner markeret med decoratoren @udf.function() kan aktiveres fra Fabric-portalen, et andet Fabric-element eller en ekstern applikation. Funktioner med denne decorator skal angive en returtype.
Eksempel:
@udf.function()
def hello_fabric(name: str) -> str:
logging.info('Python UDF trigger function processed a request.')
logging.info('Executing hello fabric function.')
return f"Welcome to Fabric Functions, {name}, at {datetime.datetime.now()}!"
Hjælper-funktioner
Python-metoder uden @udf.function() decorator kan ikke aktiveres direkte. De kan kun kaldes fra dekorerede funktioner og fungerer som hjælpefunktioner.
Eksempel:
def uppercase_name(name: str) -> str:
return name.upper()
Understøttede inputtyper
Du kan definere inputparametre for funktionen, f.eks. primitive datatyper som str, int, float osv. De understøttede inputdatatyper er:
| JSON-type | Python-datatype |
|---|---|
| Streng | Str |
| datetime-streng | datetime |
| Boolesk | Bool |
| tal | int, flyde |
| Array | list[], eksempelliste[int] |
| objekt | Dict |
| objekt | pandaer DataFrame |
| Objekt eller matrix af objekter | pandas-serien |
Notat
For at bruge pandas DataFrame- og Series-typer, gå til Fabric-portalen, find dit arbejdsområde og åbn dit user data functions-element. Vælg Biblioteksadministration, søg efter fabric-user-data-functions pakken, og opdater den til version 1.0.0 eller nyere.
Eksempel på anmodningsbrødtekst for understøttede inputtyper:
{
"name": "Alice", // String (str)
"signup_date": "2025-11-08T13:44:40Z", // Datetime string (datetime)
"is_active": true, // Boolean (bool)
"age": 30, // Number (int)
"height": 5.6, // Number (float)
"favorite_numbers": [3, 7, 42], // Array (list[int])
"profile": { // Object (dict)
"email": "alice@example.com",
"location": "Sammamish"
},
"sales_data": { // Object (pandas DataFrame)
"2025-11-01": {"product": "A", "units": 10},
"2025-11-02": {"product": "B", "units": 15}
},
"weekly_scores": [ // Object or Array of Objects (pandas Series)
{"week": 1, "score": 88},
{"week": 2, "score": 92},
{"week": 3, "score": 85}
]
}
Understøttede outputtyper
De understøttede outputdatatyper er:
| Python-datatype |
|---|
| Str |
| datetime |
| Bool |
| int, flyde |
| list[data-type], f.eks. list[int] |
| Dict |
| Ingen |
| pandas-serien |
| pandaer DataFrame |
Skrivefunktioner
Syntakskrav og begrænsninger
Når du skriver User Data Functions, skal du følge specifikke syntaksregler for at sikre, at dine funktioner fungerer korrekt.
Parameternavngivning
-
Brug camelCase: Parameternavne skal bruge camelCase-navngivningskonventionen og må ikke indeholde understrøg. For eksempel kan i stedet for
productNamebrugesproduct_name. -
Reserverede nøgleord: Du kan ikke bruge reserverede Python-nøgleord eller følgende Fabric-specifikke nøgleord som parameter- eller funktionsnavne:
req,context, ogreqInvocationId.
Parameterkrav
Typeannotationer kræves: Alle parametre skal inkludere typeannotationer (for eksempel,
name: str).Standardværdier: Standardparameterværdier understøttes. Du kan definere standardargumenter i Fabric-brugerdatafunktioner for at gøre din kode lettere at kalde og vedligeholde. Parametre med standardværdier er valgfrie ved påkaldelse; parametre uden standardværdier er påkrævet. Følgende typer understøttes som standardværdier:
Standardtype Notes String Enhver JSON-serialiserbar streng. Dato-tid-streng Angiv som en streng i funktionssignaturen. Kørselstiden parser strengen til ved datetimepåkaldelsestidspunktet. Brug ISO 8601-formatet (for eksempel2025-12-31T23:59:59Z) for konsistent, entydig parsing.Boolean TrueellerFalse.Integer Enhver heltalsværdi. Float Enhver flydende kommatal-værdi. Liste Skal være JSON-serialiserbar. Foretrukk Nonei signaturen og tildel den reelle standard inde i funktionen for at undgå delte foranderlige standardindstillinger.Ordbog Skal være JSON-serialiserbar. Foretræk Nonei signaturen og tildel den reelle standard i funktionen.pandaer DataFrame Leveres som et JSON-objekt, som SDK'en konverterer til en pandas-type. Kræver fabric-user-data-functionsversion 1.0.0 eller nyere.pandas-serien Leveres som et JSON-array af objekter, som SDK'en konverterer til en pandas-type. Kræver fabric-user-data-functionsversion 1.0.0 eller nyere.syntaks
@udf.function() def function_name( requiredParam: str, optionalStr: str = "hello", optionalDate: datetime.datetime = "2025-01-01T00:00:00Z", # specify as a string; the runtime parses it to datetime at invocation time optionalBool: bool = True, optionalInt: int = 10, optionalFloat: float = 1.5, optionalList: list | None = None, # assign real default inside the function optionalDict: dict | None = None, # assign real default inside the function ) -> dict: optionalList = optionalList or [1, 2, 3] optionalDict = optionalDict or {"key": "value"} return {"param": requiredParam}Standardindstillinger skal være JSON-serialiserbare (sæt og tupler understøttes ikke). For liste- eller ordbogsdefaults, brug
Nonei signaturen og tildel den rigtige standard inde i funktionen for at undgå delte foranderlige defaults. Brug ISO 8601-formatet (for eksempel,2025-12-31T23:59:59Z) til standardindstillinger for datotid. At bruge pandas DataFrame eller Series som standard kræverfabric-user-data-functionsversion 1.0.0 eller nyere.
Funktionskrav
-
Return type krævet: Funktioner med decoratoren
@udf.function()skal specificere en return type-annotation (for eksempel,-> str). -
Nødvendige imports: Sætningen
import fabric.functions as fnogudf = fn.UserDataFunctions()initialiseringen er nødvendige for, at dine funktioner kan fungere.
Eksempel på korrekt syntaks
@udf.function()
def process_order(orderNumber: int, customerName: str, orderDate: str) -> dict:
return {
"order_id": orderNumber,
"customer": customerName,
"date": orderDate,
"status": "processed"
}
Sådan skriver du en asynkron funktion
Tilføj asynkron dekoratør med din funktionsdefinition i din kode. Med en async funktion kan du forbedre svartid og effektivitet i dit program ved at håndtere flere opgaver på én gang. De er ideelle til styring af store mængder I/O-bundne operationer. Denne eksempelfunktion læser en CSV-fil fra et lakehouse ved hjælp af pandas. Funktionen bruger filnavnet som inputparameter.
import pandas as pd
# Replace the alias "<My Lakehouse alias>" with your connection alias.
@udf.connection(argName="myLakehouse", alias="<My Lakehouse alias>")
@udf.function()
async def read_csv_from_lakehouse(myLakehouse: fn.FabricLakehouseClient, csvFileName: str) -> str:
# Connect to the Lakehouse
connection = myLakehouse.connectToFilesAsync()
# Download the CSV file from the Lakehouse
csvFile = connection.get_file_client(csvFileName)
downloadFile = await csvFile.download_file()
csvData = await downloadFile.readall()
# Read the CSV data into a pandas DataFrame
from io import StringIO
df = pd.read_csv(StringIO(csvData.decode('utf-8')))
# Display the DataFrame
result=""
for index, row in df.iterrows():
result=result + "["+ (",".join([str(item) for item in row]))+"]"
# Close the connection
csvFile.close()
connection.close()
return f"CSV file read successfully.{result}"
Arbejde med data
Dataforbindelser til Fabric-datakilder
SDK'et giver dig mulighed for at referere dataforbindelser uden behov for at skrive forbindelsesstrenge i din kode. Biblioteket fabric.functions indeholder to måder at håndtere dataforbindelser på:
- fabric.functions.FabricSqlConnection: Giver dig mulighed for at arbejde med SQL-databaser i Fabric, herunder SQL Analytics-slutpunkter og Fabric warehouses.
- fabric.functions.FabricLakehouseClient: Giver dig mulighed for at arbejde med Lakehouses, så du kan oprette forbindelse til både Lakehouse-tabeller og Lakehouse-filer.
Hvis du vil referere til en forbindelse til en datakilde, skal du bruge @udf.connection dekoratør. Du kan anvende den i et af følgende formater:
@udf.connection(alias="<alias for data connection>", argName="sqlDB")@udf.connection("<alias for data connection>", "<argName>")@udf.connection("<alias for data connection>")
Argumenterne for @udf.connection er:
-
argName, navnet på den variabel, som forbindelsen bruger i din funktion. -
alias, aliasset for den forbindelse, du har tilføjet med menuen Administrer forbindelser. - Hvis
argNameogaliashar samme værdi, kan du bruge@udf.connection("<alias and argName for the data connection>").
Eksempel
# Where demosqldatabase is the argument name and the alias for my data connection used for this function
@udf.connection("demosqldatabase")
@udf.function()
def read_from_sql_db(demosqldatabase: fn.FabricSqlConnection)-> list:
# Connect to the SQL database
connection = demosqldatabase.connect()
cursor = connection.cursor()
# Replace with the query you want to run
query = "SELECT * FROM (VALUES ('John Smith', 31), ('Kayla Jones', 33)) AS Employee(EmpName, DepID);"
# Execute the query
cursor.execute(query)
# Fetch all results
results = cursor.fetchall()
# Close the cursor and connection
cursor.close()
connection.close()
return results
Generiske forbindelser for Fabric-items eller Azure-ressourcer
SDK'et understøtter generiske forbindelser, der gør det muligt at oprette forbindelser til Fabric-elementer eller Azure-ressourcer ved hjælp af din User Data Functions-item owner-identitet. Denne funktion genererer et Microsoft Entra ID-token med vareejerens identitet og en angivet målgruppetype. Dette token bruges til at autentificere med Fabric-elementer eller Azure-ressourcer, der understøtter den pågældende målgruppetype. Denne tilgang giver en lignende programmeringsoplevelse som brugen af managed connections-objekter fra funktionen Manage Connections , men kun for den angivne målgruppetype i forbindelsen.
Denne funktion bruger dekoratøren @udf.generic_connection() med følgende parametre:
| Parameter | Beskrivelse | Værdi |
|---|---|---|
argName |
Navnet på den variabel, der overføres til funktionen. Brugeren skal angive denne variabel i argumenterne for deres funktion og bruge typen af fn.FabricItem for den |
Hvis funktionen f.eks. argName=CosmosDbskal indeholde dette argument cosmosDb: fn.FabricItem |
audienceType |
Den type målgruppe, som forbindelsen er oprettet til. Denne parameter er knyttet til typen af Fabric-item eller Azure-tjeneste og bestemmer den klient, der bruges til forbindelsen. | De tilladte værdier for denne parameter er CosmosDb eller KeyVault. |
Opret forbindelse til Fabric Cosmos DB-objektbeholder ved hjælp af en generisk forbindelse
Generiske forbindelser understøtter oprindelige Fabric Cosmos DB-elementer ved hjælp af målgruppetypen CosmosDB . Det medfølgende User Data Functions SDK indeholder en hjælpemetode, der kaldes get_cosmos_client , der henter en singleton Cosmos DB-klient for hvert kald.
Du kan oprette forbindelse til et Fabric Cosmos DB-element ved hjælp af en generisk forbindelse ved at følge disse trin:
Gå til Fabric-portalen, find dit arbejdsområde, og åbn dit element for brugerdatafunktioner. Vælg Library Management, søg efter biblioteket
azure-cosmos, og installer det. For mere information, se Administrer biblioteker.Gå til dine Fabric Cosmos DB-elementindstillinger .
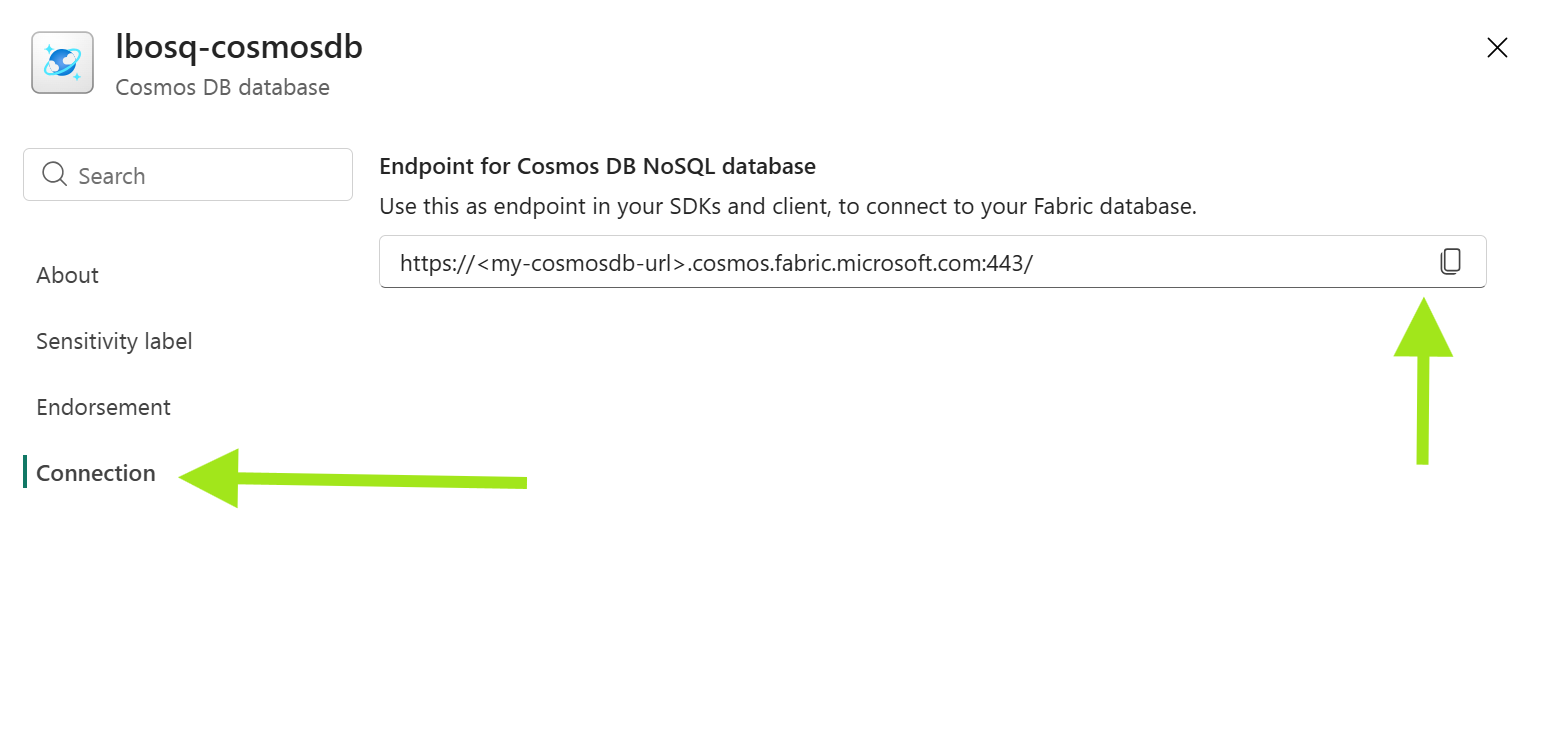
Hent URL-adressen til dit Fabric Cosmos DB-slutpunkt.
Gå til dit element Brugerdatafunktioner. Brug følgende eksempelkode til at oprette forbindelse til din Fabric Cosmos DB-objektbeholder og køre en læseforespørgsel ved hjælp af Cosmos DB-eksempeldatasættet. Erstat værdierne for følgende variabler:
-
COSMOS_DB_URImed dit Fabric Cosmos DB-slutpunkt. -
DB_NAMEmed navnet på din Fabric Cosmos DB-vare.
from fabric.functions.cosmosdb import get_cosmos_client import json @udf.generic_connection(argName="cosmosDb", audienceType="CosmosDB") @udf.function() def get_product_by_category(cosmosDb: fn.FabricItem, category: str) -> list: COSMOS_DB_URI = "YOUR_COSMOS_DB_URL" DB_NAME = "YOUR_COSMOS_DB_NAME" # Note: This is the Fabric item name CONTAINER_NAME = "SampleData" # Note: This is your container name. In this example, we are using the SampleData container. cosmosClient = get_cosmos_client(cosmosDb, COSMOS_DB_URI) # Get the database and container database = cosmosClient.get_database_client(DB_NAME) container = database.get_container_client(CONTAINER_NAME) query = 'select * from c WHERE c.category=@category' #"select * from c where c.category=@category" parameters = [ { "name": "@category", "value": category } ] results = container.query_items(query=query, parameters=parameters) items = [item for item in results] logging.info(f"Found {len(items)} products in {category}") return json.dumps(items)-
Test eller kør denne funktion ved at angive et kategorinavn, f.eks
Accessory. i aktiveringsparametrene.


Notat
Du kan også bruge disse trin til at forbinde til en Azure Cosmos DB-database ved hjælp af kontoens URL og databasenavne. User Data Functions-ejerkontoen skal have access tilladelser til den Azure Cosmos DB-konto.
Forbind til Azure Key Vault ved hjælp af en generisk forbindelse
Generiske forbindelser understøtter forbindelse til en Azure Key Vault ved at bruge KeyVault målgruppetypen. Denne type forbindelse kræver, at ejeren af Fabric User Data Functions har tilladelser til at oprette forbindelse til Azure Key Vault. Du kan bruge denne forbindelse til at hente nøgler, hemmeligheder eller certifikater efter navn.
Du kan forbinde til Azure Key Vault for at hente en klienthemmelighed og kalde et API ved hjælp af en generisk forbindelse ved at følge disse trin:
Gå til Fabric-portalen, find dit arbejdsområde, og åbn dit element for brugerdatafunktioner. Vælg Library Management, søg derefter efter og installer bibliotekerne
requestsogazure-keyvault-secrets. For mere information, se Administrer biblioteker.Gå til din Azure Key Vault ressource i Azure portal og hent
Vault URIog navnet på din nøgle, hemmelighed eller certifikat.
Go back til dit Fabric User Data Functions-element og brug dette eksempel. I dette eksempel henter vi en hemmelighed fra Azure Key Vault for at forbinde til et offentligt API. Erstat værdien af følgende variabler:
-
KEY_VAULT_URLmed detVault URIdu hentede i det forrige trin. -
KEY_VAULT_SECRET_NAMEmed navnet på din hemmelighed. -
API_URLvariabel med webadressen på den API, du vil oprette forbindelse til. I dette eksempel antages det, at du opretter forbindelse til en offentlig API, der accepterer GET-anmodninger og tager følgende parametreapi-keyogrequest-body.
from azure.keyvault.secrets import SecretClient from azure.identity import DefaultAzureCredential import requests @udf.generic_connection(argName="keyVaultClient", audienceType="KeyVault") @udf.function() def retrieveNews(keyVaultClient: fn.FabricItem, requestBody:str) -> str: KEY_VAULT_URL = 'YOUR_KEY_VAULT_URL' KEY_VAULT_SECRET_NAME= 'YOUR_SECRET' API_URL = 'YOUR_API_URL' credential = keyVaultClient.get_access_token() client = SecretClient(vault_url=KEY_VAULT_URL, credential=credential) api_key = client.get_secret(KEY_VAULT_SECRET_NAME).value api_url = API_URL params = { "api-key": api_key, "request-body": requestBody } response = requests.get(api_url, params=params) data = "" if response.status_code == 200: data = response.json() else: print(f"Error {response.status_code}: {response.text}") return f"Response: {data}"-
Test eller kør denne funktion ved at angive en anmodningstekst i din kode.

Avancerede funktioner
Programmeringsmodellen definerer avancerede mønstre, der giver dig større kontrol over dine funktioner. SDK'en implementerer disse mønstre gennem klasser og metoder, der gør det muligt at:
- Access invocation-metadata om, hvem der kaldte din funktion, og hvordan
- Håndter brugerdefinerede fejlscenarier med strukturerede fejlsvar
- Integrér med Fabric-variabelbiblioteker til centraliseret konfigurationsstyring
Notat
User Data Functions har servicebegrænsninger for anmodningsstørrelse, eksekveringstimeout og svarstørrelse. For detaljer om disse begrænsninger og hvordan de håndhæves, se Servicedetaljer og begrænsninger.
Hent aktiveringsegenskaber ved hjælp af UserDataFunctionContext
SDK'en indeholder objektet UserDataFunctionContext . Dette objekt indeholder funktionskald-metadata og kan bruges til at skabe specifik app-logik for forskellige kaldemekanismer (såsom portalkald versus REST API-kald).
I følgende tabel vises egenskaberne for det UserDataFunctionContext objekt:
| Egenskabsnavn | Datatype | Beskrivelse |
|---|---|---|
| invocation_id | streng | Det entydige GUID, der er knyttet til aktiveringen af elementet med brugerdatafunktioner. |
| executing_user | objekt | Metadata for brugerens oplysninger, der bruges til at godkende aktiveringen. |
Objektet executing_user indeholder følgende oplysninger:
| Egenskabsnavn | Datatype | Beskrivelse |
|---|---|---|
| Oid | streng (GUID) | Brugerens objekt-ID, som er en uforanderlig identifikator for anmodningspersonen. Dette er den bekræftede identitet for den bruger eller tjenesteprincipal, der bruges til at aktivere denne funktion på tværs af programmer. |
| TenantId | streng (GUID) | Id'et for den lejer, som brugeren er logget på. |
| PreferredUsername | streng | Det foretrukne brugernavn for den bruger, der aktiverer, som angivet af brugeren. Denne værdi kan slås fra. |
For at access parameteren UserDataFunctionContext skal du bruge følgende dekorator øverst i funktionsdefinitionen: @udf.context(argName="<parameter name>")
Eksempel
@udf.context(argName="myContext")
@udf.function()
def getContext(myContext: fabric.functions.UserDataFunctionContext)-> str:
logging.info('Python UDF trigger function processed a request.')
return f"Hello oid = {myContext.executing_user['Oid']}, TenantId = {myContext.executing_user['TenantId']}, PreferredUsername = {myContext.executing_user['PreferredUsername']}, InvocationId = {myContext.invocation_id}"
Kast en håndteret fejl med UserThrownError
Når du udvikler din funktion, kan du kaste et forventet fejlsvar ved at bruge den UserThrownError klasse, der er tilgængelig i SDK'et. En anvendelse af denne klasse er håndtering af tilfælde, hvor brugerindtastede input ikke består forretningsvalideringsreglerne.
Eksempel
import datetime
@udf.function()
def raise_userthrownerror(age: int)-> str:
if age < 18:
raise fn.UserThrownError("You must be 18 years or older to use this service.", {"age": age})
return f"Welcome to Fabric Functions at {datetime.datetime.now()}!"
Klassekonstruktøren UserThrownError tager to parametre:
-
Message: Denne streng returneres som fejlmeddelelse til det program, der aktiverer denne funktion. - En ordbog med egenskaber returneres til det program, der kalder denne funktion.
Hent variabler fra Fabric-variabelbiblioteker
Et Fabric variabelbibliotek i Microsoft Fabric er et centraliseret repository til håndtering af variabler, der kan bruges på tværs af forskellige elementer i et arbejdsområde. Det giver udviklere mulighed for at tilpasse og dele varekonfigurationer effektivt. Hvis du endnu ikke har et variabelbibliotek, se Opret og administrer variabelbiblioteker.
For at bruge et variabelbibliotek i dine funktioner tilføjer du en forbindelse til det fra dit user data functions-element. Variabelbiblioteker optræder i OneLake-kataloget sammen med datakilder som SQL-databaser og lakehouses.
Følg disse trin for at bruge variabelbiblioteker i dine funktioner:
- I dit element for brugerdatafunktioner skal du tilføje en forbindelse til dit variabelbibliotek. I OneLake-kataloget finder og vælger du dit variabelbibliotek, og vælg derefter Connect. Bemærk det alias, som Fabric genererer for forbindelsen.
- Tilføj en forbindelsesdekorator til det variable bibliotekselement. Du kan f.eks.
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")erstatte alias til den nyligt tilføjede forbindelse til det variable bibliotekselement. - I funktionsdefinitionen skal du medtage et argument med typen
fn.FabricVariablesClient. Denne klient indeholder de metoder, du skal bruge til at arbejde med variables library item. - Brug
getVariables()metoden til at hente alle variablerne fra variabelbiblioteket. - For at læse værdierne for variablerne skal du bruge enten
["variable-name"]eller.get("variable-name").
Eksempel
I dette eksempel simulerer vi et konfigurationsscenarie for et produktions- og et udviklingsmiljø. Denne funktion sætter en storage-sti afhængigt af det valgte miljø ved hjælp af en værdi hentet fra Variable Library. Variabelbiblioteket indeholder en variabel, der hedder ENV , hvor brugere kan angive en værdi på dev eller prod.
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")
@udf.function()
def get_storage_path(dataset: str, varLib: fn.FabricVariablesClient) -> str:
"""
Description: Determine storage path for a dataset based on environment configuration from Variable Library.
Args:
dataset_name (str): Name of the dataset to store.
varLib (fn.FabricVariablesClient): Fabric Variable Library connection.
Returns:
str: Full storage path for the dataset.
"""
# Retrieve variables from Variable Library
variables = varLib.getVariables()
# Get environment and base paths
env = variables.get("ENV")
dev_path = variables.get("DEV_FILE_PATH")
prod_path = variables.get("PROD_FILE_PATH")
# Apply environment-specific logic
if env.lower() == "dev":
return f"{dev_path}{dataset}/"
elif env.lower() == "prod":
return f"{prod_path}{dataset}/"
else:
return f"incorrect settings define for ENV variable"
Relateret indhold
- Reference-API-dokumentation
- opret et element til fabric-brugerdatafunktioner
- Brugerdata-funktioner samples