Forklaringstyper i Microsoft Syntex
Gælder for: ✓ Ustruktureret dokumentbehandling
Forklaringer bruges som en hjælp til at definere de oplysninger, du vil mærke og udtrække i dine ustrukturerede dokumentbehandlingsmodeller i Microsoft Syntex. Når du opretter en forklaring, skal du vælge en forklaringstype. Denne artikel hjælper dig med at forstå de forskellige forklaringstyper, og hvordan de bruges.
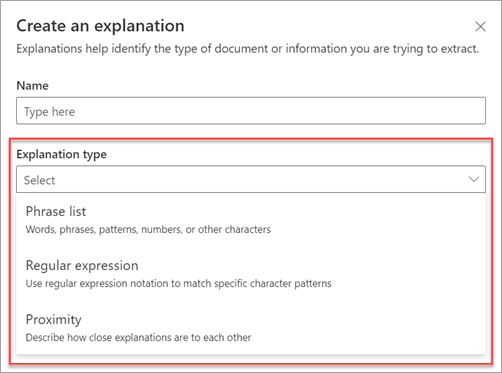
Disse forklaringstyper er tilgængelige:
Udtryksliste: Liste over ord, udtryk, tal eller andre tegn, du kan bruge i det dokument eller de oplysninger, du uddrager. Tekststrengens henvisende læge findes f.eks. i alle de referencedokumenter, du identificerer. Eller telefonnummeret på den henvisende læge fra alle dokumenter om henvisning til læge, som du identificerer.
Regulært udtryk: Bruger en notation, der matcher et mønster, til at finde bestemte tegnmønstre. Du kan f.eks. bruge et regulært udtryk til at finde alle forekomster af et mailadressemønster i et sæt dokumenter.
Nærhed: Beskriver, hvor tætte forklaringer er på hinanden. En liste med gadenummerudtryk går f.eks. lige før listen over gadenavneudtryk uden tokens imellem (du får mere at vide om tokens senere i denne artikel). Brug af nærhedstypen kræver, at du har mindst to forklaringer i din model, ellers deaktiveres indstillingen.
Udtryksliste
En forklaringstype for sætningslisten bruges typisk til at identificere og klassificere et dokument via din model. Som beskrevet i eksemplet med henvisningslægemærkaten er det en streng af ord, sætninger, tal eller tegn, der konsekvent findes i de dokumenter, du identificerer.
Selvom det ikke er et krav, kan du opnå bedre succes med din forklaring, hvis det udtryk, du registrerer, er placeret på en ensartet placering i dit dokument. Mærkaten for den henvisende læge kan f.eks. være placeret konsekvent i dokumentets første afsnit. Du kan også bruge indstillingen Konfigurer, hvor udtryk forekommer i dokumentets avancerede indstilling til at vælge bestemte områder, hvor udtrykket er placeret, især hvis der er risiko for, at udtrykket kan forekomme flere steder i dokumentet.
Hvis forskel på store og små bogstaver er et krav til identifikation af mærkaten, kan du bruge udtrykslistetypen til at angive det i forklaringen ved at markere afkrydsningsfeltet Kun nøjagtig brug af store og små bogstaver .

En udtrykstype er især nyttig, når du opretter en forklaring, der identificerer og udtrækker oplysninger i forskellige formater, f.eks. datoer, telefonnumre og kreditkortnumre. En dato kan f.eks. vises i mange forskellige formater (1/1/2020, 1-1-2020, 01/01/20, 01/01/2020 eller 1. januar 2020). Hvis du definerer en udtryksliste, bliver din forklaring mere effektiv ved at registrere eventuelle variationer i de data, du forsøger at identificere og udtrække.
I eksemplet med telefonnummeret udtrækker du telefonnummeret til hver henvisende læge fra alle dokumenter om henvisning til læge, som modellen identificerer. Når du opretter forklaringen, skal du skrive de forskellige formater, som et telefonnummer kan vise i dokumentet, så du kan registrere mulige variationer.
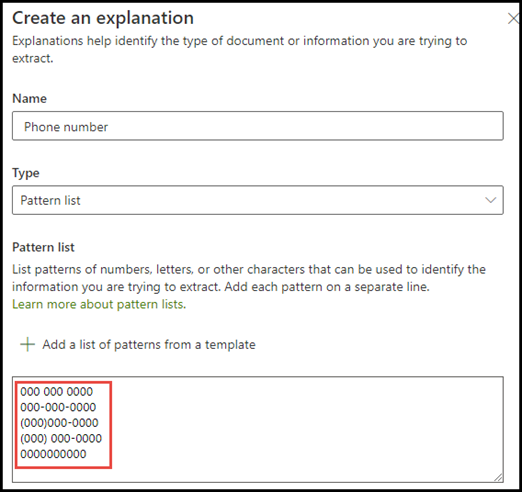
I dette eksempel skal du i Avancerede indstillinger markere afkrydsningsfeltet Et vilkårligt ciffer fra 0-9 for at genkende hver "0"-værdi, der bruges på udtrykslisten, til at være et vilkårligt ciffer fra 0 til og med 9.

Hvis du på samme måde opretter en udtryksliste, der indeholder teksttegn, skal du markere afkrydsningsfeltet Ethvert bogstav fra a-z for at genkende hvert "a"-tegn, der bruges på udtrykslisten, til et vilkårligt tegn fra "a" til "z".
Hvis du f.eks. opretter en liste med datoudtryk , og du vil sikre dig, at et datoformat som f.eks. den 1. januar 2020 genkendes, skal du gøre følgende:
- Føj aaa 0, 0000 og aaa 00, 0000 til din udtryksliste.
- Sørg for, at Alle bogstaver fra a-z også er markeret.

Hvis du har krav til store bogstaver på udtrykslisten, kan du markere afkrydsningsfeltet Kun nøjagtig brug af store bogstaver . Hvis du i datoeksepelet kræver, at det første bogstav i måneden angives med stort, skal du:
- Føj Aaa 0, 0000 og Aaa 00, 0000 til din udtryksliste.
- Sørg for, at kun nøjagtig brug af store bogstaver også er valgt.

Bemærk!
I stedet for at oprette en forklaring på en udtryksliste manuelt kan du bruge forklaringsbiblioteket til at bruge skabeloner til udtrykslister til en almindelig udtryksliste, f.eks. dato, telefonnummer eller kreditkortnummer.
Regulært udtryk
En forklaringstype for regulære udtryk giver dig mulighed for at oprette mønstre, der hjælper med at finde og identificere visse tekststrenge i dokumenter. Du kan bruge regulære udtryk til hurtigt at fortolke store mængder tekst til:
- Find specifikke tegnmønstre.
- Valider tekst for at sikre, at den svarer til et foruddefineret mønster (f.eks. en mailadresse).
- Udtræk, rediger, erstat eller slet tekstunderstrenge.
En type regulært udtryk er især nyttig, når du opretter en forklaring, der identificerer og udtrækker oplysninger i lignende formater, f.eks. mailadresser, bankkontonumre eller URL-adresser. En mailadresse, f.eks megan@contoso.com. , vises f.eks. i et bestemt mønster ("Megan" er den første del, og "com" er den sidste del).
Det regulære udtryk for en mailadresse er: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[ A-Za-z]{2,6}.
Dette udtryk består af fem dele i denne rækkefølge:
En vilkårlig mængde af følgende tegn:
a. Bogstaver fra a til z
b. Tal fra 0-9
c. Periode, understregningstegn, procent eller streg
Symbolet @
En vilkårlig mængde af de samme tegn som den første del af mailadressen
Et punktum
To til seks bogstaver
Sådan tilføjer du en forklaringstype for regulært udtryk:
Vælg Regulært udtryk i panelet Opret en forklaring under Forklaringstype.
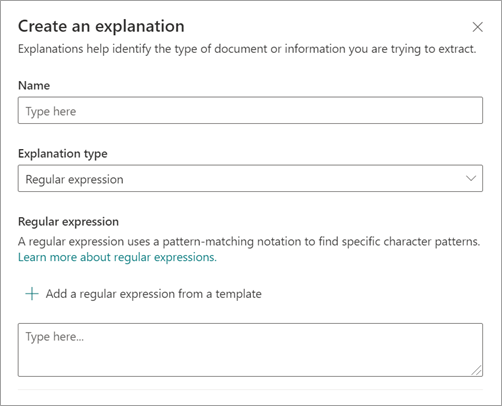
Du kan enten skrive et udtryk i tekstfeltet Regulært udtryk eller vælge Tilføj et regulært udtryk fra en skabelon.
Når du tilføjer et regulært udtryk ved hjælp af en skabelon, føjes navnet og det regulære udtryk automatisk til tekstfeltet. Hvis du f.eks. vælger skabelonen Mailadresse , udfyldes panelet Opret en forklaring .

Begrænsninger
I følgende tabel vises indbyggede tegnindstillinger, der i øjeblikket ikke er tilgængelige til brug i regulære udtryksmønstre.
| Valgmulighed | Stat | Aktuel funktionalitet |
|---|---|---|
| Forskel på små og små bogstaver | Understøttes ikke i øjeblikket. | Der skelnes ikke mellem store og små bogstaver i alle de udførte matches. |
| Stregankre | Understøttes ikke i øjeblikket. | Det er ikke muligt at angive en bestemt placering i en streng, hvor der skal være et match. |
Nærhed
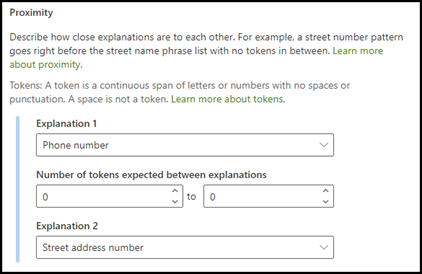
Forklaringstypen for nærhed hjælper din model med at identificere data ved at definere, hvor tæt en anden datadel er på dem. I din model kan du f.eks. sige, at du har defineret to forklaringer, der angiver både kundens gadeadressenummer og telefonnummer.
Bemærk, at kundetelefonnumre altid vises før adressenummeret.
Alex Wilburn
555-555-5555
One Microsoft Way
Redmond, WA 98034
Brug nærhedsforklaringen til at definere, hvor langt væk forklaringen på telefonnummeret er, for bedre at identificere adressenummeret i dine dokumenter.
Bemærk!
Regulære udtryk kan i øjeblikket ikke bruges med forklaringstypen nærhed.
Hvad er tokens?
Hvis du vil bruge forklaringstypen nærhed, skal du forstå, hvad et token er. Antallet af tokens er, hvordan nærhedsforklaringen måler afstanden fra én forklaring til en anden. Et token er et fortløbende mellemrum (uden mellemrum eller tegnsætning) af bogstaver og tal.
I følgende tabel vises eksempler på, hvordan du bestemmer antallet af tokens i et udtryk.
| Frase | Antal tokens | Forklaring |
|---|---|---|
Dog |
1 | Et enkelt ord uden tegnsætning eller mellemrum. |
RMT33W |
1 | Et nummer til postsøger. Det kan indeholde tal og bogstaver, men ikke tegnsætning. |
425-555-5555 |
5 | Et telefonnummer. Hvert tegnsætningstegn er et enkelt token, så 425-555-5555 det er 5 tokens:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Konfigurer forklaringstypen for nærhed
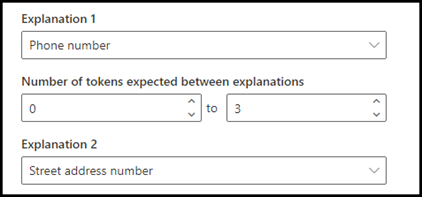
I eksemplet skal du konfigurere nærhedsindstillingen for at definere intervallet for antallet af tokens i forklaringen til telefonnummeret fra forklaringen til adressenummeret . Bemærk, at minimumintervallet er "0", fordi der ikke er nogen tokens mellem telefonnummer og adressenummer.
Men nogle telefonnumre i eksempeldokumenterne tilføjes med (mobil).
Nestor Wilke
111-111-1111 (mobil)
One Microsoft Way
Redmond, WA 98034
Der er tre tokens i (mobil):
| Frase | Antal tokens |
|---|---|
| ( | 1 |
| mobil | 2 |
| ) | 3 |
Konfigurer nærhedsindstillingen, så den har et interval mellem 0 og 3.
Konfigurer, hvor udtryk forekommer i dokumentet
Når du opretter en forklaring, søges der som standard i hele dokumentet efter det udtryk, du forsøger at udtrække. Du kan dog bruge indstillingen Hvor disse udtryk forekommer avanceret til at hjælpe med at isolere en bestemt placering i dokumentet, som et udtryk forekommer. Denne indstilling er nyttig i situationer, hvor lignende forekomster af et udtryk kan blive vist et andet sted i dokumentet, og du vil sikre dig, at den korrekte er valgt.
Den henvisende læge nævnes altid i dokumentets første afsnit med henvisningseksempel. Med indstillingen Hvor disse udtryk forekommer kan du i dette eksempel konfigurere din forklaring til kun at søge efter denne mærkat i starten af dokumentet eller en anden placering, hvor det kan forekomme.
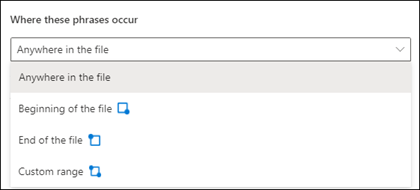
Du kan vælge følgende indstillinger for denne indstilling:
Hvor som helst i filen: Hele dokumentet søges efter udtrykket.
Starten af filen: Der søges i dokumentet fra starten til sætningsplaceringen.
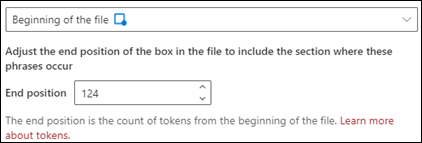
I fremviseren kan du manuelt justere markeringsfeltet for at inkludere den placering, hvor fasen forekommer. Værdien for slutpositionen opdateres for at vise antallet af tokens, som dit valgte område indeholder. Du kan også opdatere værdien for slutplaceringen for at justere det valgte område.
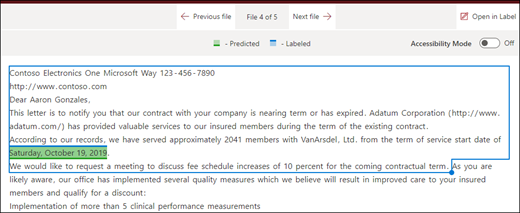
Slutningen af filen: Der søges i dokumentet fra slutningen til sætningsplaceringen.
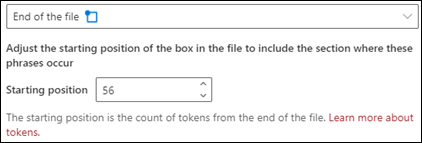
I fremviseren kan du manuelt justere markeringsfeltet for at inkludere den placering, hvor fasen forekommer. Startpositionsværdien opdateres for at vise antallet af tokens, som dit valgte område indeholder. Du kan også opdatere startplaceringsværdien for at justere det valgte område.

Brugerdefineret område: Der søges i dokumentet inden for et angivet område for sætningsplaceringen.
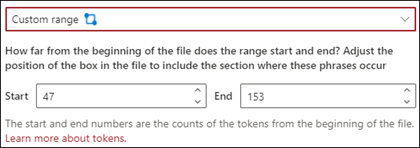
I fremviseren kan du manuelt justere markeringsfeltet for at inkludere den placering, hvor fasen forekommer. Til denne indstilling skal du vælge en start- og slutposition . Disse værdier repræsenterer antallet af tokens fra starten af dokumentet. Selvom du manuelt kan angive disse værdier, er det nemmere at justere markeringsfeltet manuelt i fremviseren.
Overvejelser i forbindelse med konfiguration af forklaringer
Når du oplærer en klassificering, er der et par ting, du skal være opmærksom på, som vil give mere forudsigelige resultater:
Jo flere dokumenter du oplærer med, jo mere præcis bliver klassificeringen. Når det er muligt, skal du bruge mere end fem gode dokumenter og bruge mere end ét ugyldigt dokument. Hvis de biblioteker, du arbejder med, har flere forskellige dokumenttyper, medfører flere af hver type mere forudsigelige resultater.
Mærkning af dokumentet spiller en vigtig rolle i oplæringsprocessen. De bruges sammen med forklaringer til at oplære modellen. Du kan muligvis se nogle uregelmæssigheder, når du oplærer en klassificering med dokumenter, der ikke har meget indhold i dem. Forklaringen stemmer muligvis ikke overens med noget i dokumentet, men da den er mærket som et "godt" dokument, kan det være et match under oplæringen.
Når du opretter forklaringer, bruges OR-logik i kombination med mærkaten til at afgøre, om det er et match. Regulært udtryk, der bruger AND-logik, kan være mere forudsigeligt. Her er et eksempel på regulært udtryk, der kan bruges på rigtige dokumenter, når du oplærer dem. Bemærk, at den tekst, der er fremhævet med rødt, er det eller de udtryk, du leder efter.
(?=.*network provider)(?=.*participating providers).*
Etiketter og forklaringer arbejder sammen og bruges til oplæring af modellen. Det er ikke en række regler, der kan afkobles og præcise vægte eller forudsigelse anvendes på hver variabel, der er konfigureret. Jo større variationen af dokumenter, der bruges i oplæringen, giver mere nøjagtighed i modellen.