Konfigurer arbejdsbelastninger i en Premium-kapacitet
I denne artikel vises arbejdsbelastningerne for Power BI Premium, og deres kapaciteter beskrives.
Bemærk
Arbejdsbelastninger kan aktiveres og tildeles til en kapacitet ved hjælp af REST API'er for kapaciteter .
Understøttede arbejdsbelastninger
Forespørgselsarbejdsbelastninger er optimeret til og begrænset af ressourcer, der bestemmes af din Premium-kapacitets-SKU. Premium-kapaciteter understøtter også yderligere arbejdsbelastninger, der kan bruge din kapacitets ressourcer.
Listen over arbejdsbelastninger nedenfor beskriver, hvilke Premium-SKU'er der understøtter hver arbejdsbelastning:
AI – Alle SKU'er understøttes bortset fra EM1/A1-SKU'erne
Semantiske modeller – alle SKU'er understøttes
Dataflow – alle SKU'er understøttes
Sideinddelte rapporter – alle SKU'er understøttes
Konfigurer arbejdsbelastninger
Du kan justere funktionsmåden for arbejdsbelastningerne ved at konfigurere arbejdsbelastningsindstillinger for din kapacitet.
Vigtigt
Alle arbejdsbelastninger er altid aktiveret og kan ikke deaktiveres. Dine kapacitetsressourcer administreres af Power BI i henhold til dit kapacitetsforbrug.
Sådan konfigurerer du arbejdsbelastninger på Power BI-administrationsportalen
Log på Power BI ved hjælp af legitimationsoplysningerne for din administratorkonto.
I sidehovedet skal du vælge ...>Indstillingsadministrationsportal>.
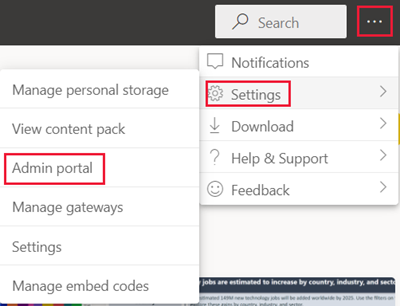
Gå til Kapacitetsindstillinger , og vælg en kapacitet under fanen Power BI Premium .
Udvid Arbejdsbelastninger.
Angiv værdierne for hver arbejdsbelastning i henhold til dine specifikationer.
Vælg Anvend.
Overvåg arbejdsbelastninger
Brug appen Microsoft Fabric Capacity Metrics til at overvåge din kapacitets aktivitet.
Vigtigt
Hvis din Power BI Premium-kapacitet oplever et højt ressourceforbrug, hvilket medfører problemer med ydeevnen eller pålideligheden, kan du modtage beskedmails for at identificere og løse problemet. Dette kan være en strømlinet måde at foretage fejlfinding af overbelastede kapaciteter på. Du kan få flere oplysninger under Meddelelser.
AI (prøveversion)
Ai-arbejdsbelastningen giver dig mulighed for at bruge kognitive tjenester og automatiseret maskinel indlæring i Power BI. Brug følgende indstillinger til at styre funktionsmåden for arbejdsbelastningen.
| Indstillingsnavn | Beskrivelse |
|---|---|
| Maks. hukommelse (%)1 | Den maksimale procentdel af tilgængelig hukommelse, som AI-processer kan bruge i en kapacitet. |
| Tillad brug fra Power BI Desktop | Denne indstilling er reserveret til fremtidig brug og vises ikke i alle lejere. |
| Tillad oprettelse af modeller til maskinel indlæring | Angiver, om forretningsanalytikere kan oplære, validere og aktivere modeller til maskinel indlæring direkte i Power BI. Du kan få flere oplysninger under Automatiseret maskinel indlæring i Power BI (prøveversion). |
| Aktivér parallelitet for AI-anmodninger | Angiver, om AI-anmodninger kan køre parallelt. |
1 Premium kræver ikke, at hukommelsesindstillingerne ændres. Hukommelse i Premium administreres automatisk af det underliggende system.
Semantiske modeller
I dette afsnit beskrives følgende indstillinger for arbejdsbelastning for semantiske modeller:
Power BI-indstillinger
Brug indstillingerne i tabellen nedenfor til at styre funktionsmåden for arbejdsbelastningen. Indstillinger med et link indeholder flere oplysninger, som du kan gennemse i de angivne afsnit under tabellen.
| Indstillingsnavn | Beskrivelse |
|---|---|
| Maks. hukommelse (%)1 | Den maksimale procentdel af tilgængelig hukommelse, som semantiske modeller kan bruge i en kapacitet. |
| XMLA-slutpunkt | Angiver, at forbindelser fra klientprogrammer overholder det medlemskab af sikkerhedsgrupper, der er angivet på arbejdsområde- og appniveauerne. Du kan få flere oplysninger under Opret forbindelse til semantiske modeller med klientprogrammer og -værktøjer. |
| Maks. antal mellemliggende rækkesæt | Det maksimale antal mellemliggende rækker, der returneres af DirectQuery. Standardværdien er 1000000, og det tilladte interval er mellem 100000 og 2147483646. Den øvre grænse skal muligvis begrænses yderligere, afhængigt af hvad datakilden understøtter. |
| Maks. størrelse på semantisk offlinemodel (GB) | Den maksimale størrelse af den semantiske offlinemodel i hukommelsen. Dette er den komprimerede størrelse på disken. Standardværdien er 0, hvilket er den højeste grænse, der er defineret af SKU. Det tilladte interval er mellem 0 og grænsen for kapacitetsstørrelse. |
| Maksimalt antal resultatrækker | Det maksimale antal rækker, der returneres i en DAX-forespørgsel. Standardværdien er 2147483647, og det tilladte interval er mellem 10000 og 2147483647. |
| Grænse for forespørgselshukommelse (%) | Den maksimale procentdel af tilgængelig hukommelse i arbejdsbelastningen, der kan bruges til at udføre en MDX- eller DAX-forespørgsel. Standardværdien er 0, hvilket medfører, at der anvendes SKU-specifik automatisk hukommelsesgrænse for forespørgsler. |
| Timeout for forespørgsel (sekunder) | Den maksimale mængde tid, før en forespørgsel udløber. Standarden er 3600 sekunder (1 time). En værdi på 0 angiver, at forespørgsler ikke får timeout. |
| Automatisk sideopdatering | Slå til/fra for at give Premium-arbejdsområder mulighed for at have rapporter med automatisk sideopdatering baseret på faste intervaller. |
| Minimuminterval for opdatering | Hvis automatisk sideopdatering er slået til, er det minimuminterval, der er tilladt for sideopdateringsintervallet. Standardværdien er fem minutter, og den tilladte minimumværdi er ét sekund. |
| Ændringsregistreringsmåling | Slå til/fra for at tillade premiumarbejdsområder at have rapporter med automatisk sideopdatering baseret på registrering af ændringer. |
| Minimuminterval for udførelse | Hvis målingen ændre registrering er slået til, er det mindste udførelsesinterval, der er tilladt for forespørgsler om dataændringer. Standardværdien er fem sekunder, og den tilladte minimumværdi er ét sekund. |
1 Premium kræver ikke, at hukommelsesindstillingerne ændres. Hukommelse i Premium administreres automatisk af det underliggende system.
Maks. antal mellemliggende rækkesæt
Brug denne indstilling til at styre virkningen af ressourcetunge eller dårligt designede rapporter. Når en forespørgsel til en semantisk DirectQuery-model resulterer i et meget stort resultat fra kildedatabasen, kan det medføre en stigning i hukommelsesforbruget og behandlingsomkostningerne. Denne situation kan medføre, at andre brugere og rapporter løber tør for ressourcer. Denne indstilling gør det muligt for kapacitetsadministratoren at justere, hvor mange rækker en individuel forespørgsel kan hente fra datakilden.
Hvis kapaciteten kan understøtte mere end standarden på én million rækker, og du har en stor semantisk model, kan du også øge denne indstilling for at hente flere rækker.
Denne indstilling påvirker kun DirectQuery-forespørgsler, mens Maks. antal resultatrækkesæt påvirker DAX-forespørgsler.
Maks. størrelse på semantisk offlinemodel
Brug denne indstilling til at forhindre rapportoprettere i at publicere en stor semantisk model, der kan påvirke kapaciteten negativt. Power BI kan ikke bestemme den faktiske størrelse i hukommelsen, før den semantiske model indlæses i hukommelsen. Det er muligt, at en semantisk model med en mindre offlinestørrelse kan have et større hukommelsesforbrug end en semantisk model med en større offlinestørrelse.
Hvis du har en eksisterende semantisk model, der er større end den størrelse, du angiver for denne indstilling, indlæses den semantiske model ikke, når en bruger forsøger at få adgang til den. Den semantiske model kan også ikke indlæses, hvis den er større end den maksimale hukommelse, der er konfigureret til arbejdsbelastningen for semantiske modeller.
Denne indstilling gælder for modeller i både lille semantisk modellagerformat (ABF-format) og stort semantisk modellagerformat (PremiumFiles), selvom offlinestørrelsen for den samme model kan variere, når den gemmes i ét format i forhold til et andet. Du kan få flere oplysninger under Store modeller i Power BI Premium.
For at beskytte systemets ydeevne anvendes der et ekstra SKU-specifikt fast loft for den maksimale semantiske offlinemodelstørrelse, uanset hvilken værdi der er konfigureret. Det ekstra SKU-specifikke faste loft i nedenstående tabel gælder ikke for semantiske Power BI-modeller, der er gemt i store semantiske modellagerformater.
| SKU | Grænse1 |
|---|---|
| F2 | 1 GB |
| F4 | 2 GB |
| F8/EM1/A1 | 3 GB |
| F16/EM2/A2 | 5 GB |
| F32/EM3/A3 | 6 GB |
| F64/P1/A4 | 10 GB |
| F128/P2/A5 | 10 GB |
| F256/P3/A6 | 10 GB |
| F512/P4/A7 | 10 GB |
| F1024/P5/A8 | 10 GB |
| F2048 | 10 GB |
1Fast loft for Max Offline semantisk modelstørrelse (lille lagerformat).
Maks. antal resultatrækkesæt
Brug denne indstilling til at styre virkningen af ressourcetunge eller dårligt designede rapporter. Hvis denne grænse nås i en DAX-forespørgsel, får en rapportbruger vist følgende fejl. De skal kopiere oplysningerne om fejlen og kontakte en administrator.
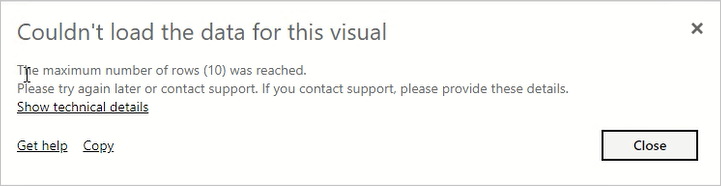
Denne indstilling påvirker kun DAX-forespørgsler, mens Maks. antal mellemliggende rækkesæt påvirker DirectQuery-forespørgsler.
Grænse for forespørgselshukommelse
Brug denne indstilling til at styre virkningen af ressourcetunge eller dårligt designede rapporter. Nogle forespørgsler og beregninger kan resultere i mellemliggende resultater, der bruger meget hukommelse på kapaciteten. Denne situation kan medføre, at andre forespørgsler udføres meget langsomt, at andre semantiske modeller fjernes fra kapaciteten, og at der opstår hukommelsesfejl for andre brugere af kapaciteten.
Denne indstilling gælder for alle DAX- og MDX-forespørgsler, der udføres af Power BI-rapporter, Analysér i Excel-rapporter samt andre værktøjer, der kan oprette forbindelse via XMLA-slutpunktet.
Dataopdateringshandlinger kan også udføre DAX-forespørgsler som en del af opdateringen af dashboardfelterne og visualiseringscacherne, når dataene i den semantiske model er blevet opdateret. Sådanne forespørgsler kan også mislykkes på grund af denne indstilling, og det kan medføre, at dataopdateringshandlingen vises i en mislykket tilstand, selvom dataene i den semantiske model blev opdateret.
Standardindstillingen er 0, hvilket medfører, at følgende SKU-specifikke automatiske forespørgselshukommelsesgrænse anvendes.
| SKU | Automatisk hukommelsesgrænse for forespørgsel |
|---|---|
| F2 | 1 GB |
| F4 | 1 GB |
| F8/EM1/A1 | 1 GB |
| F16/EM2/A2 | 2 GB |
| F32/EM3/A3 | 5 GB |
| F64/P1/A4 | 10 GB |
| F128/P2/A5 | 10 GB |
| F256/P3/A6 | 10 GB |
| F512/P4/A7 | 20 GB |
| F1024/P5/A8 | 40 GB |
| F2048 | 40 GB |
Forespørgselsgrænsen for et arbejdsområde, der ikke er tildelt en Premium-kapacitet, er 1 GB.
Timeout for forespørgsel
Brug denne indstilling til at bevare bedre kontrol over langvarige forespørgsler, hvilket kan medføre, at rapporter indlæses langsomt for brugerne.
Denne indstilling gælder for alle DAX- og MDX-forespørgsler, der udføres af Power BI-rapporter, Analysér i Excel-rapporter samt andre værktøjer, der kan oprette forbindelse via XMLA-slutpunktet.
Dataopdateringshandlinger kan også udføre DAX-forespørgsler som en del af opdateringen af dashboardfelterne og visualiseringscacherne, når dataene i den semantiske model er blevet opdateret. Sådanne forespørgsler kan også mislykkes på grund af denne indstilling, og det kan medføre, at dataopdateringshandlingen vises i en mislykket tilstand, selvom dataene i den semantiske model blev opdateret.
Denne indstilling gælder for en enkelt forespørgsel og ikke den tid, det tager at køre alle de forespørgsler, der er knyttet til opdatering af en semantisk model eller rapport. Se følgende eksempel:
- Indstillingen For forespørgselstimeout er 1200 (20 minutter).
- Der er fem forespørgsler at udføre, og hver kører 15 minutter.
Den kombinerede tid for alle forespørgsler er 75 minutter, men indstillingsgrænsen nås ikke, fordi alle de enkelte forespørgsler kører i mindre end 20 minutter.
Bemærk, at Power BI-rapporter tilsidesætter denne standard med en meget mindre timeout for hver forespørgsel til kapaciteten. Timeout for hver forespørgsel er typisk ca. tre minutter.
Automatisk sideopdatering
Når indstillingen er aktiveret, giver automatisk sideopdatering brugere i din Premium-kapacitet mulighed for at opdatere sider i deres rapport med et defineret interval for DirectQuery-kilder. Som kapacitetsadministrator kan du gøre følgende:
- Slå automatisk sideopdatering til og fra
- Definer et minimuminterval for opdatering
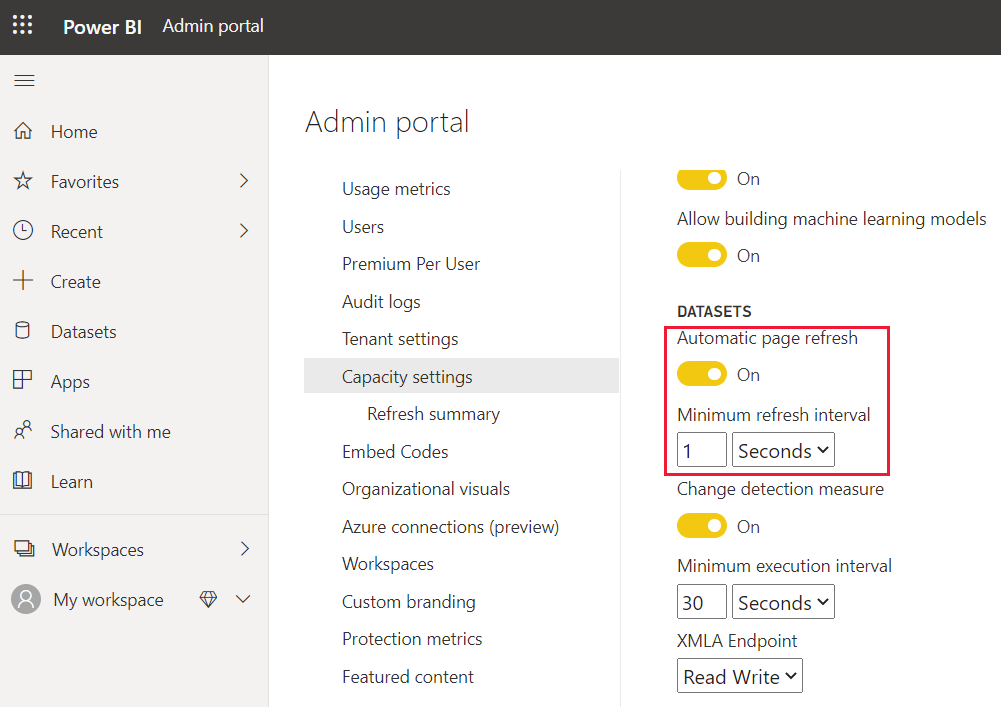
Sådan finder du indstillingen for automatisk sideopdatering:
Vælg Kapacitetsindstillinger på Power BI-administrationsportalen.
Vælg din kapacitet, og rul derefter ned, og udvid menuen Arbejdsbelastninger .
Rul ned til afsnittet Semantiske modeller .
Forespørgsler, der oprettes ved automatisk sideopdatering, går direkte til datakilden, så det er vigtigt at overveje pålidelighed og belastning på disse kilder, når du tillader automatisk sideopdatering i din organisation.
Egenskaber for Analysis Services-server
Power BI Premium understøtter yderligere Analysis Services-serveregenskaber. Hvis du vil gennemse disse egenskaber, skal du se Serveregenskaber i Analysis Services.
Skift til administrationsportal
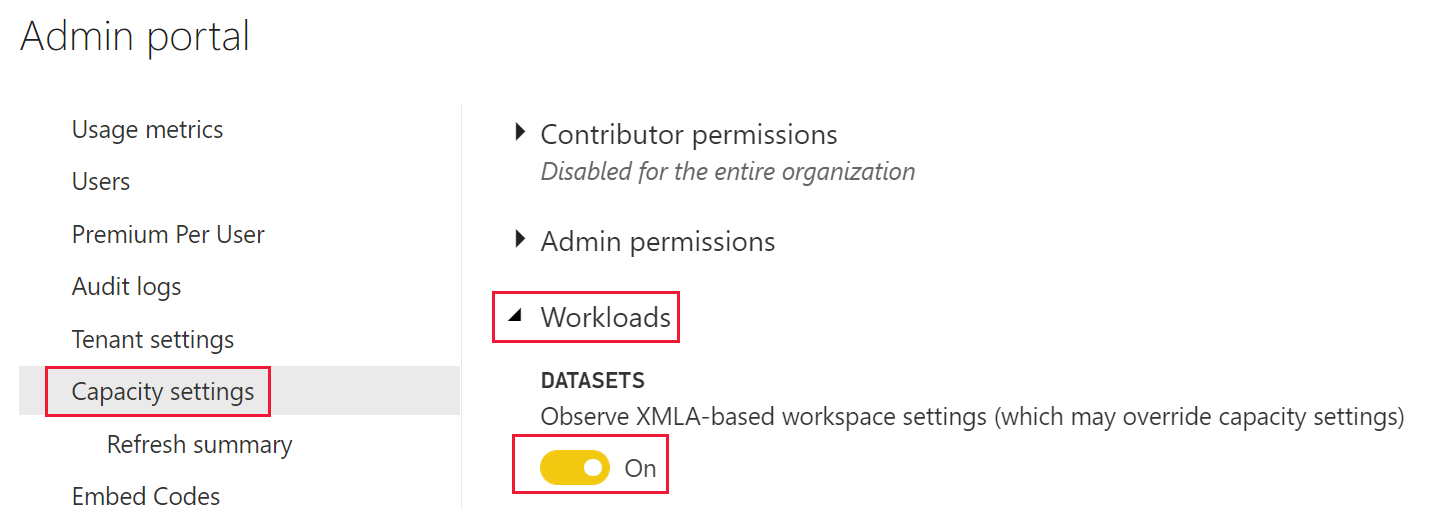
Indstillingen for Analysis Services XMLA-baserede serveregenskaber er aktiveret som standard. Når indstillingen er aktiveret, kan arbejdsområdeadministratorer ændre funktionsmåder for et individuelt arbejdsområde. Ændrede egenskaber gælder kun for det pågældende arbejdsområde. Hvis du vil slå indstillingen for Analysis Services-serveregenskaber til eller fra, skal du følge nedenstående trin.
Gå til dine kapacitetsindstillinger.
Vælg den kapacitet, du vil deaktivere egenskaberne for Analysis Services-serveren i.
Udvid Arbejdsbelastninger.
Under semantiske modeller skal du vælge den ønskede indstilling for indstillingen Overhold XMLA-baserede arbejdsområdeindstillinger (som kan tilsidesætte kapacitetsindstillinger).
Dataflows
Med dataflowarbejdsbelastningen kan du bruge selvbetjent dataforberedelse af dataflows til at indtage, transformere, integrere og forbedre data. Brug følgende indstillinger til at styre funktionsmåden for arbejdsbelastninger i Premium. Power BI Premium kræver ikke, at hukommelsesindstillingerne ændres. Hukommelse i Premium administreres automatisk af det underliggende system.
Forbedret beregningsprogram til dataflow
Hvis du vil drage fordel af det nye beregningsprogram, skal du opdele dataindtagelse i separate dataflow og placere transformationslogik i beregnede enheder i forskellige dataflow. Denne fremgangsmåde anbefales, fordi beregningsprogrammet fungerer på dataflow, der refererer til et eksisterende dataflow. Det fungerer ikke på dataflow for indtagelse. Hvis du følger denne vejledning, sikrer du, at det nye beregningsprogram håndterer transformationstrin, f.eks. joinforbindelser og fletninger, for at opnå optimal ydeevne.
Sideinddelte rapporter
Arbejdsbelastningen for sideinddelte rapporter giver dig mulighed for at køre sideinddelte rapporter på basis af SQL Server Reporting Services-standardformatet i Power BI-tjeneste.
Sideinddelte rapporter tilbyder de samme funktioner som SSRS-rapporter (SQL Server Reporting Services) i dag, herunder muligheden for, at rapportforfattere kan tilføje brugerdefineret kode. Dette gør det muligt for forfattere at ændre rapporter dynamisk, f.eks. ændre tekstfarver baseret på kodeudtryk.
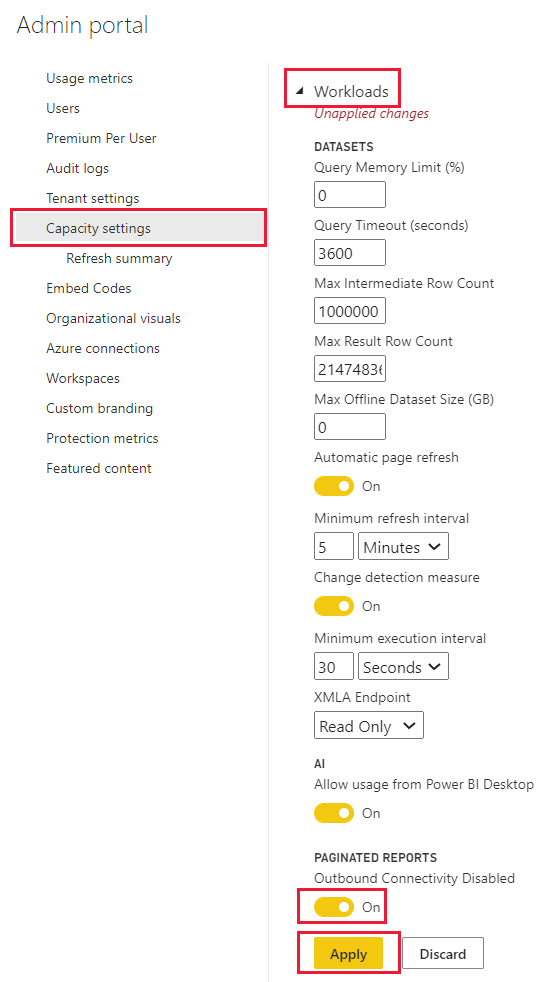
Udgående forbindelse
Udgående forbindelse er som standard slået til. Det gør det muligt for sideinddelte rapporter at foretage anmodninger om hentning af eksterne ressourcer, f.eks. billeder, og kalde eksterne API'er og Azure-funktioner, der er defineret ved hjælp af brugerdefineret kode i sideinddelte rapporter. En Fabric-administrator kan deaktivere denne indstilling på Power BI-administrationsportalen.
Følg disse trin for at få vist indstillingerne for udgående forbindelser:
I Power BI-tjeneste skal du gå til administrationsportalen.
Under fanen Power BI Premium skal du vælge den kapacitet, du vil deaktivere udgående anmodninger om sideinddelte rapporter for.
Udvid Arbejdsbelastninger.
Den udgående forbindelseskontakt findes i afsnittet sideinddelte rapporter .
Når deaktivering af udgående forbindelse er slået fra, aktiveres udgående forbindelse.
Når deaktivering af udgående forbindelse er slået til, er udgående forbindelse deaktiveret.
Når du har foretaget en ændring, skal du vælge Anvend.
Arbejdsbelastningen for sideinddelte rapporter aktiveres automatisk og er altid aktiveret.