Begivenhed
14. feb., 16 - 31. mar., 16
Med 4 chancer for at komme ind, kan du vinde en konference pakke og gøre det til LIVE Grand Finale i Las Vegas
Flere oplysningerDenne browser understøttes ikke længere.
Opgrader til Microsoft Edge for at drage fordel af de nyeste funktioner, sikkerhedsopdateringer og teknisk support.
Sammenlægninger i Power BI kan forbedre forespørgselsydeevnen i forbindelse med store semantiske DirectQuery-modeller. Ved hjælp af sammenlægninger cachelagrer du data på det aggregerede niveau i hukommelsen. Sammenlægninger i Power BI kan konfigureres manuelt i datamodellen, som beskrevet i denne artikel. For Premium-abonnementer automatisk ved at aktivere funktionen Automatiske sammenlægninger i model Indstillinger.
Afhængigt af datakildetypen kan der oprettes en sammenlægningstabel i datakilden som en tabel eller visning, oprindelig forespørgsel. For at opnå den bedste ydeevne skal du oprette en sammenlægningstabel som en importtabel, der er oprettet i Power Query. Du kan derefter bruge dialogboksen Administrer sammenlægninger i Power BI Desktop til at definere sammenlægninger for sammenlægningskolonner med egenskaber for opsummering, detaljetabel og detaljekolonne.
Dimensionelle datakilder, f.eks. data warehouses og data marts, kan bruge relationsbaserede sammenlægninger. Hadoop-baserede big data-kilder baserer ofte sammenlægninger på GroupBy-kolonner. I denne artikel beskrives typiske forskelle i Power BI-datamodellering for hver type datakilde.
Højreklik på sammenlægningstabellen i ruden Data i en power BI Desktop-visning, og vælg derefter Administrer sammenlægninger.
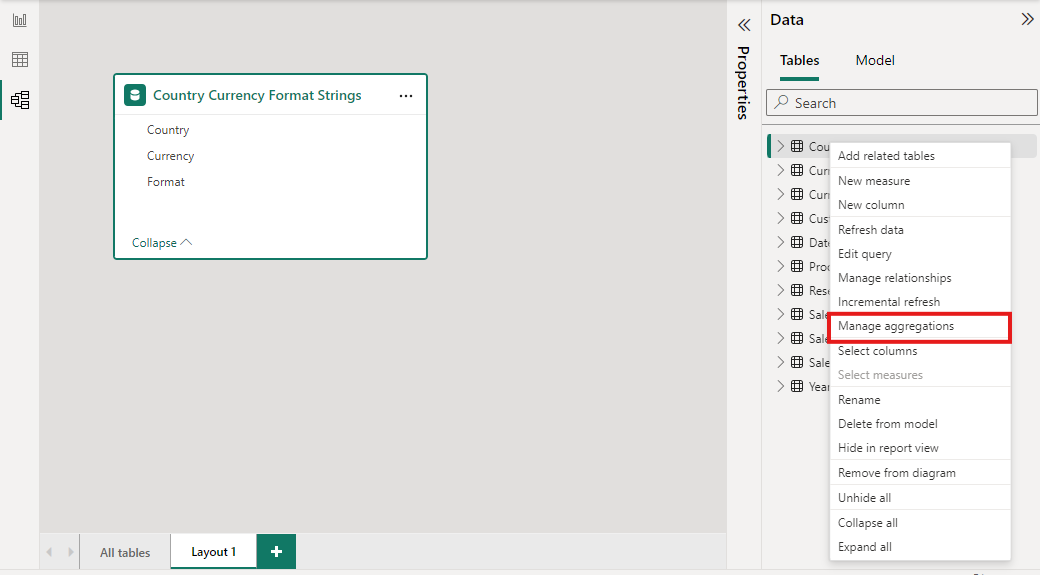
I dialogboksen Administrer sammenlægninger vises der en række for hver kolonne i tabellen, hvor du kan angive funktionsmåden for sammenlægning. I følgende eksempel omdirigeres forespørgsler til detaljetabellen Sales internt til sammenlægningstabellen Sales Agg .
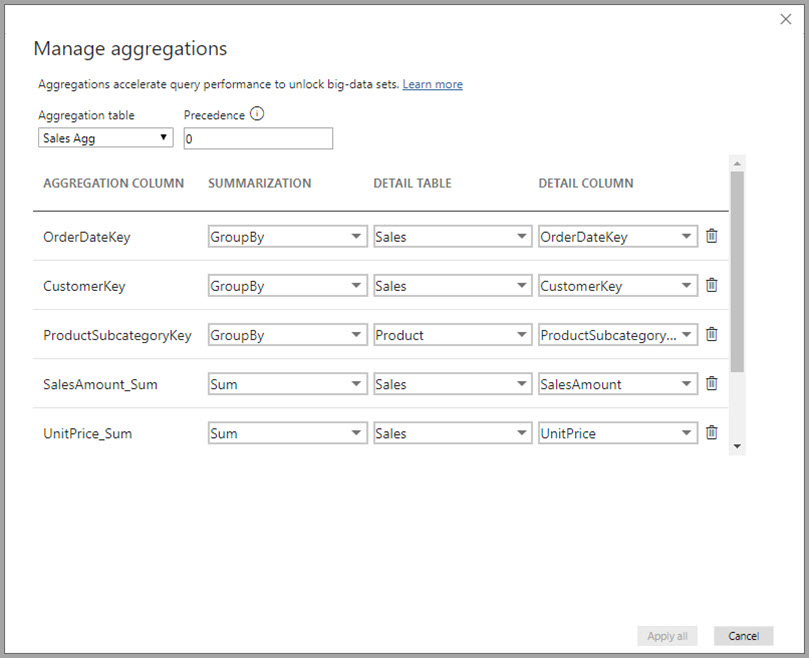
I dette relationsbaserede sammenlægningseksempel er GroupBy-posterne valgfrie. Med undtagelse af DISTINCTCOUNT påvirker de ikke funktionsmåden for sammenlægning og er primært af hensyn til læsbarheden. Uden GroupBy-posterne vil sammenlægningerne stadig blive vist på baggrund af relationerne. Dette adskiller sig fra eksemplet med big data senere i denne artikel, hvor GroupBy-posterne er påkrævet.
Dialogboksen Administrer sammenlægninger gennemtvinger valideringer:
De fleste valideringer gennemtvinges ved at deaktivere rullelisteværdier og vise forklarende tekst i værktøjstippet.
Brugere med skrivebeskyttet adgang til modellen kan ikke forespørge sammenlægningstabeller. Skrivebeskyttet adgang undgår sikkerhedsproblemer, når den bruges sammen med sikkerhed på rækkeniveau. Forbrugere og forespørgsler refererer til detaljetabellen, ikke sammenlægningstabellen, og de behøver ikke at vide noget om sammenlægningstabellen.
Derfor er sammenlægningstabeller skjult i visningen Rapport . Hvis tabellen ikke allerede er skjult, angiver dialogboksen Administrer sammenlægninger den til skjult, når du vælger Anvend alle.
Sammenlægningsfunktionen interagerer med lagringstilstande på tabelniveau. Power BI-tabeller kan bruge DirectQuery-, Import- eller Dual-lagringstilstande . DirectQuery forespørger backend direkte, mens Import cachelagrer data i hukommelsen og sender forespørgsler til de cachelagrede data. Alle Power BI-import- og ikke-flerdimensionelle DirectQuery-datakilder kan arbejde med sammenlægninger.
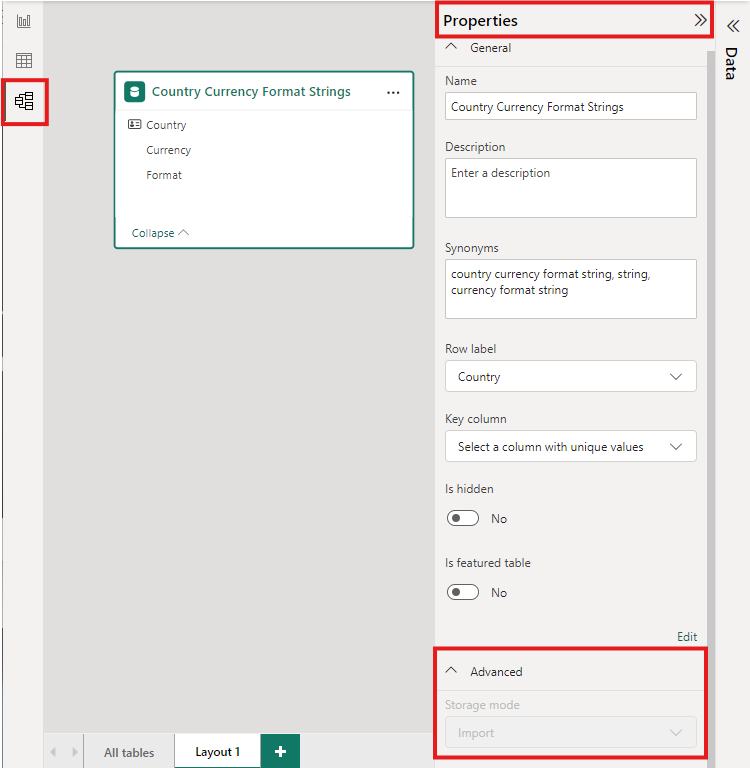
Hvis du vil angive lagringstilstanden for en aggregeret tabel til Import for at fremskynde forespørgsler, skal du vælge den aggregerede tabel i Modelvisning i Power BI Desktop. I ruden Egenskaber skal du udvide Avanceret, rulle ned i markeringen under Lagringstilstand og vælge Importér. Ændring af import kan ikke fortrydes.
Du kan få mere at vide om tabellagringstilstande under Administrer lagringstilstand i Power BI Desktop.
Hvis RLS-udtryk skal fungere korrekt for sammenlægninger, skal de filtrere sammenlægningstabellen og detaljetabellen.
I følgende eksempel fungerer RLS-udtrykket i tabellen Geography til sammenlægninger, fordi Geography er på filtreringssiden af relationer til tabellen Sales og tabellen Sales Agg. Forespørgsler, der ramte sammenlægningstabellen, og forespørgsler, der ikke har RLS anvendt korrekt.
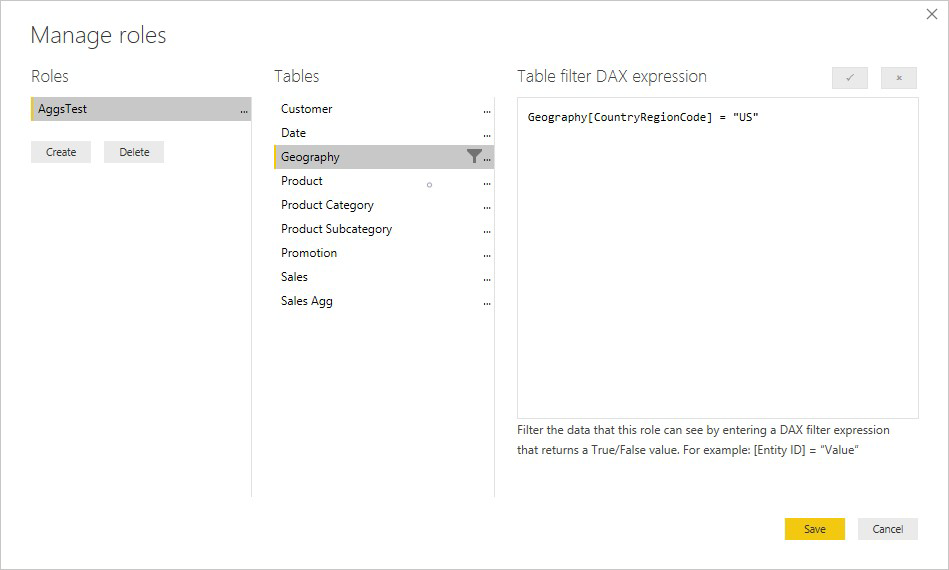
Et RLS-udtryk i tabellen Product filtrerer kun detaljetabellen Sales og ikke den aggregerede tabel Sales Agg . Da sammenlægningstabellen er en anden repræsentation af dataene i detaljetabellen, vil det være usikkert at besvare forespørgsler fra sammenlægningstabellen, hvis RLS-filteret ikke kan anvendes. Det anbefales ikke kun at filtrere detaljetabellen, fordi brugerforespørgsler fra denne rolle ikke kan drage fordel af sammenlægningsforekomster.
Et RLS-udtryk, der kun filtrerer sammenlægningstabellen Sales Agg og ikke detaljetabellen Sales , er ikke tilladt.
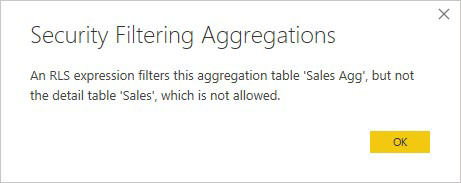
For sammenlægninger, der er baseret på GroupBy-kolonner, kan et RLS-udtryk, der anvendes på detaljetabellen, bruges til at filtrere sammenlægningstabellen, fordi alle GroupBy-kolonnerne i sammenlægningstabellen dækkes af detaljetabellen. På den anden side kan et RLS-filter på sammenlægningstabellen ikke anvendes på detaljetabellen, så det er ikke tilladt.
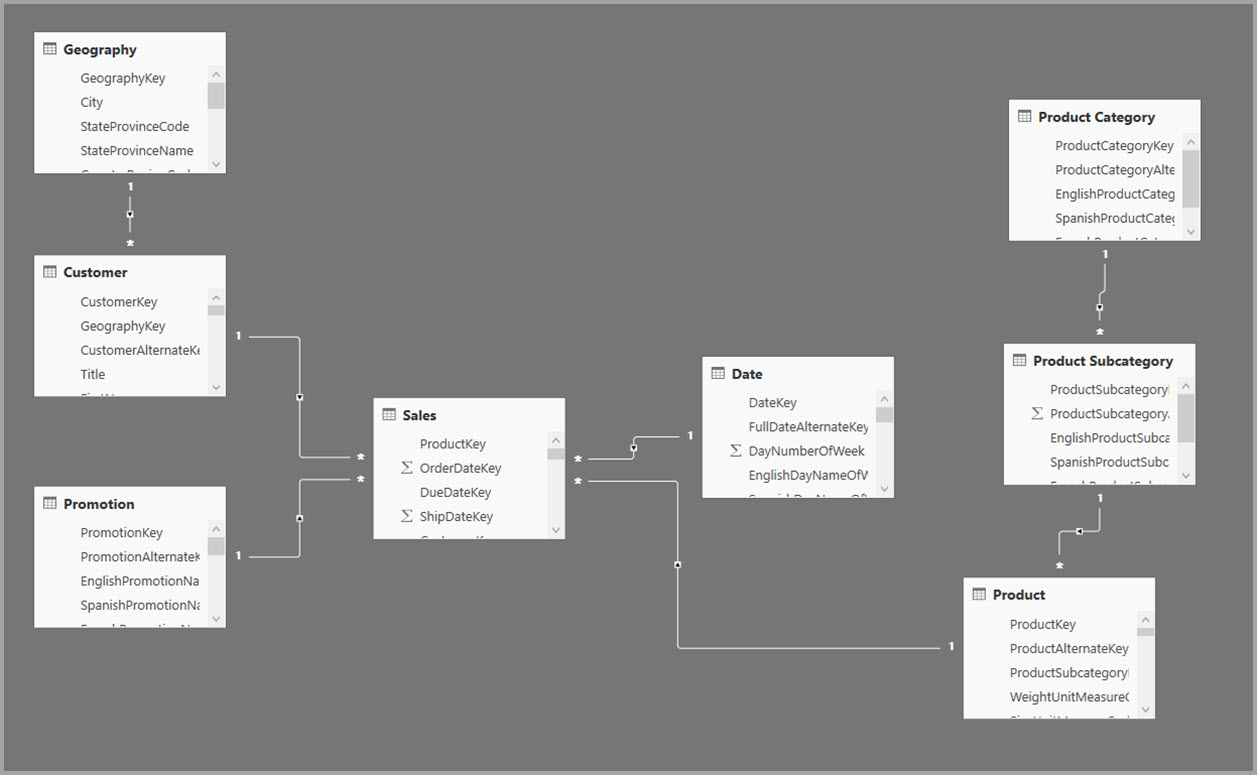
Dimensionelle modeller bruger typisk sammenlægninger baseret på relationer. Power BI-modeller fra data warehouses og datacentre ligner stjerne-/snowflake-skemaer med relationer mellem dimensionstabeller og faktatabeller.
I følgende eksempel henter modellen data fra en enkelt datakilde. Tabeller bruger DirectQuery-lagringstilstand. Faktatabellen Sales indeholder milliarder af rækker. Hvis du angiver lagringstilstanden for Sales til Import til cachelagring, vil det forbruge betydelige hukommelses- og ressourceomkostninger.
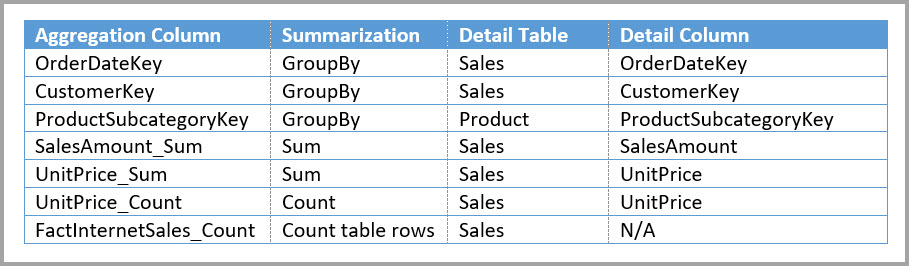
Opret i stedet sammenlægningstabellen Sales Agg . I tabellen Sales Agg er antallet af rækker lig med summen af SalesAmount grupperet efter CustomerKey, DateKey og ProductSubcategoryKey. Tabellen Sales Agg har en højere granularitet end Sales, så i stedet for milliarder kan den indeholde millioner af rækker, hvilket er nemmere at administrere.
Hvis følgende dimensionstabeller bruges oftest til forespørgsler med høj forretningsværdi, kan de filtrere Sales Agg ved hjælp af en til mange- eller mange til en-relationer.
På følgende billede vises denne model.
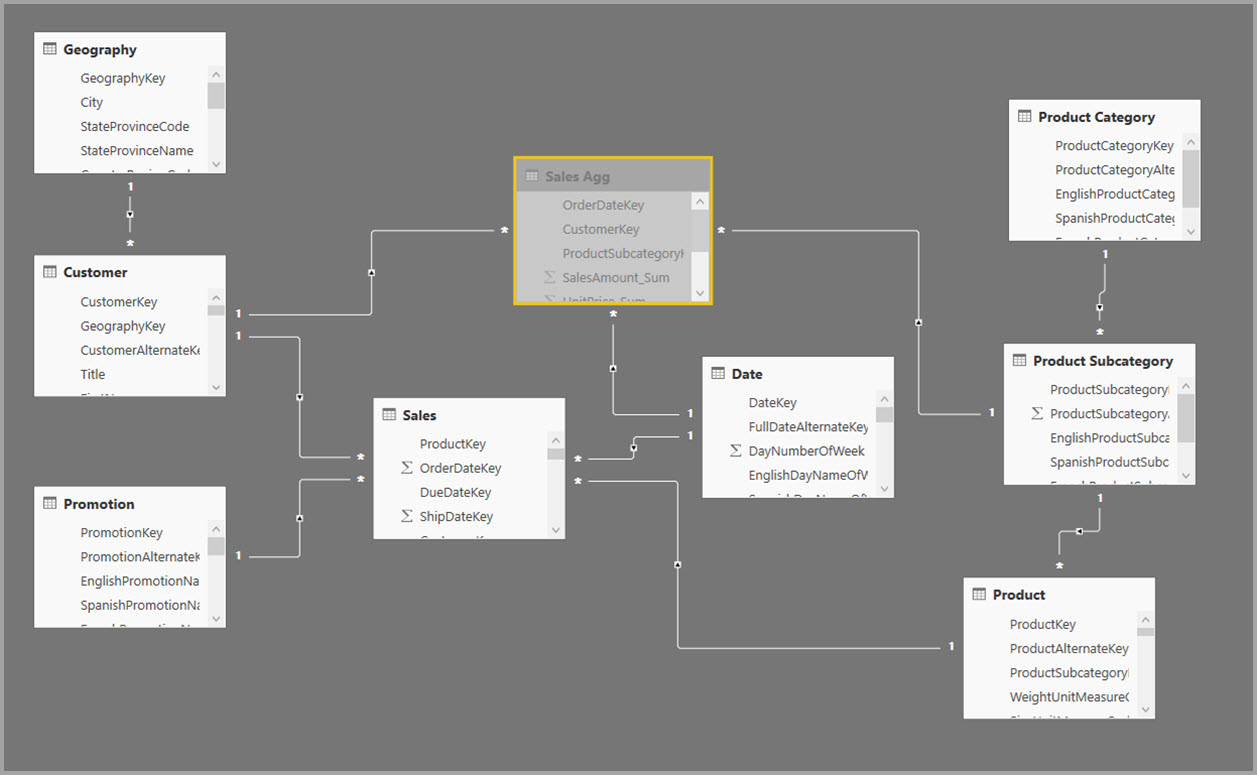
I følgende tabel vises sammenlægningerne for tabellen Sales Agg .
Bemærk
Tabellen Sales Agg har som enhver anden tabel fleksibiliteten ved at blive indlæst på mange forskellige måder. Sammenlægningen kan udføres i kildedatabasen ved hjælp af ETL/ELT-processer eller af M-udtrykket for tabellen. Den aggregerede tabel kan bruge lagringstilstanden Import med eller uden trinvis opdatering for semantiske modeller, eller den kan bruge DirectQuery og optimeres til hurtige forespørgsler ved hjælp af columnstore-indekser. Denne fleksibilitet muliggør balancerede arkitekturer, der kan sprede forespørgselsbelastningen for at undgå flaskehalse.
Hvis du ændrer lagringstilstanden for den samlede tabel Sales Agg til Import, åbnes en dialogboks, hvor der står, at de relaterede dimensionstabeller kan indstilles til lagringstilstanden Dual.
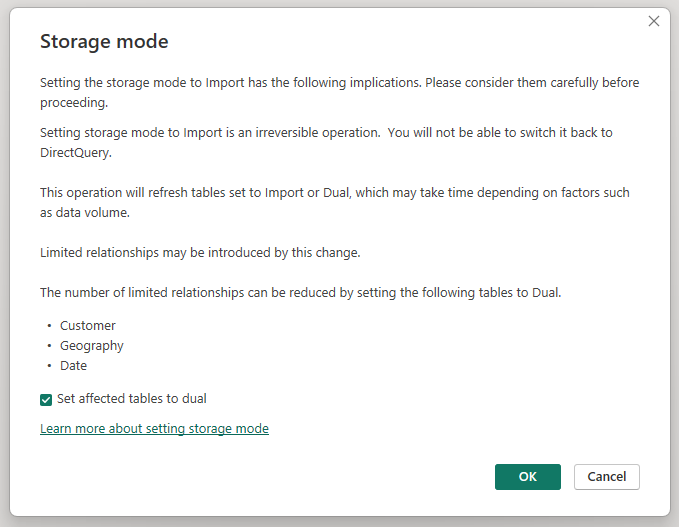
Hvis du angiver de relaterede dimensionstabeller til Dual, kan de fungere som enten Import eller DirectQuery, afhængigt af underforespørgslen. I eksemplet:
Du kan få flere oplysninger om Dobbelt lagringstilstand under Administrer lagringstilstand i Power BI Desktop.
Sammenlægningsforekomster baseret på relationer kræver almindelige relationer.
Almindelige relationer omfatter følgende kombinationer af lagringstilstand, hvor begge tabeller er fra en enkelt kilde:
| Tabel på mange sider | Tabel på 1-siden |
|---|---|
| Dobbelt | Dobbelt |
| Importér | Import eller Dual |
| DirectQuery | DirectQuery eller Dual |
Det eneste tilfælde, hvor en relation på tværs af kilder anses for at være almindelig, er, hvis begge tabeller er angivet til Import. Mange til mange-relationer anses altid for at være begrænsede.
Hvis du vil se forekomster på tværs af kilder , der ikke er afhængige af relationer, skal du se Sammenlægninger baseret på GroupBy-kolonner.
Følgende forespørgsel giver forekomster ved sammenlægningen, fordi kolonnerne i tabellen Date har den granularitet, der kan ramme sammenlægningen. Kolonnen SalesAmount bruger sammenlægningen Sum .

Følgende forespørgsel giver ikke forekomster ved sammenlægningen. På trods af at der anmodes om summen af SalesAmount, udfører forespørgslen en GroupBy-handling på en kolonne i tabellen Product , som ikke har den granularitet, der kan udløse sammenlægningen. Hvis du holder øje med relationerne i modellen, kan en produktunderkategori have flere produktrækker . Forespørgslen kan ikke bestemme, hvilket produkt der skal aggregeres til. I dette tilfælde vender forespørgslen tilbage til DirectQuery og sender en SQL-forespørgsel til datakilden.

Sammenlægninger er ikke kun til simple beregninger, der udfører en simpel sum. Komplekse beregninger kan også være en fordel. Konceptuelt opdeles en kompleks beregning i underforespørgsler for hver SUM, MIN, MAX og COUNT. Hver underforespørgsel evalueres for at afgøre, om den kan give forekomster ved sammenlægningen. Denne logik gælder ikke i alle tilfælde på grund af optimering af forespørgselsplan, men den bør generelt anvendes. I følgende eksempel vises sammenlægningen:

Funktionen COUNTROWS kan drage fordel af sammenlægninger. Følgende forespørgsel giver forekomster ved sammenlægningen, fordi der er defineret en sammenlægning af antal tabelrækker for tabellen Sales .

Funktionen AVERAGE kan drage fordel af sammenlægninger. Følgende forespørgsel giver forekomster ved sammenlægningen, fordi AVERAGE foldes internt til en SUM divideret med et COUNT. Da kolonnen UnitPrice har sammenlægninger defineret for både SUM og COUNT, er sammenlægningen nået.

I nogle tilfælde kan funktionen DISTINCTCOUNT drage fordel af sammenlægninger. Følgende forespørgsel giver forekomster ved sammenlægningen, fordi der er en GroupBy-post for CustomerKey, som bevarer distinktionen af CustomerKey i sammenlægningstabellen. Denne teknik kan stadig nå grænsen for ydeevne, hvor mere end to til fem millioner forskellige værdier kan påvirke forespørgslens ydeevne. Det kan dog være nyttigt i scenarier, hvor der er milliarder af rækker i detaljetabellen, men to til fem millioner forskellige værdier i kolonnen. I dette tilfælde kan DISTINCTCOUNT udføre hurtigere end at scanne tabellen med milliarder af rækker, selvom den blev cachelagret i hukommelsen.

DAX-funktioner (Data Analysis Expressions) er aggregeringsorienterede. Følgende forespørgsel giver sammenlægningen forekomster, fordi funktionen DATESYTD genererer en tabel med CalendarDay-værdier , og sammenlægningstabellen har en granularitet, der er dækket for gruppér efter-kolonner i tabellen Date . Dette er et eksempel på et tabelbaseret filter til funktionen CALCULATE, som kan arbejde med sammenlægninger.

Hadoop-baserede big data-modeller har andre egenskaber end dimensionelle modeller. For at undgå joinforbindelser mellem store tabeller bruger big data-modeller ofte ikke relationer, men deormaliserer dimensionsattributter til faktatabeller. Du kan låse op for sådanne big data-modeller til interaktiv analyse ved hjælp af sammenlægninger, der er baseret på GroupBy-kolonner.
Følgende tabel indeholder den numeriske kolonne Bevægelse , der skal aggregeres. Alle de andre kolonner er attributter, der skal grupperes efter. Tabellen indeholder IoT-data og et massivt antal rækker. Lagringstilstanden er DirectQuery. Forespørgsler på datakilden, der aggregeres på tværs af hele modellen, er langsomme på grund af den store mængde.
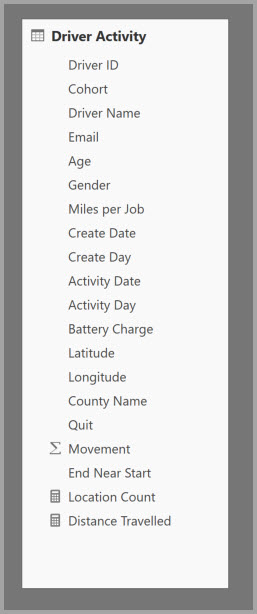
Hvis du vil aktivere interaktiv analyse af denne model, kan du tilføje en sammenlægningstabel, der grupperer efter de fleste af attributterne, men udelukker attributter med høj kardinalitet, f.eks. længdegrad og breddegrad. Dette reducerer antallet af rækker drastisk og er lille nok til at passe komfortabelt ind i en cache i hukommelsen.
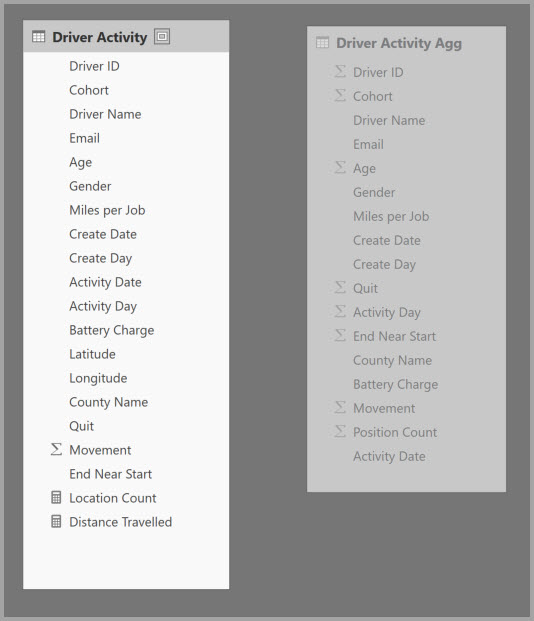
Du definerer sammenlægningstilknytningerne for tabellen Driver Activity Agg i dialogboksen Administrer sammenlægninger .
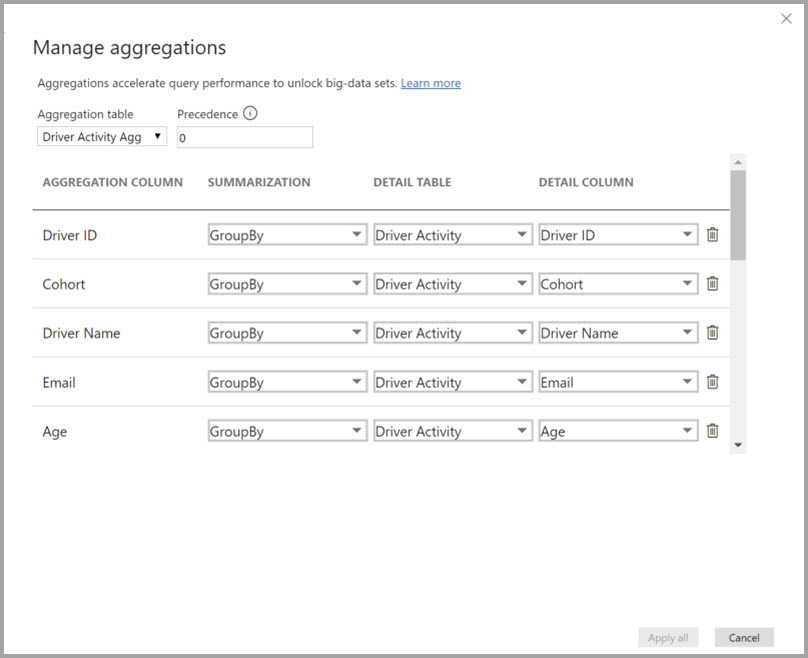
I sammenlægninger, der er baseret på GroupBy-kolonner, er GroupBy-posterne ikke valgfrie. Uden dem bliver sammenlægningerne ikke ramt. Dette adskiller sig fra at bruge sammenlægninger baseret på relationer, hvor GroupBy-posterne er valgfrie.
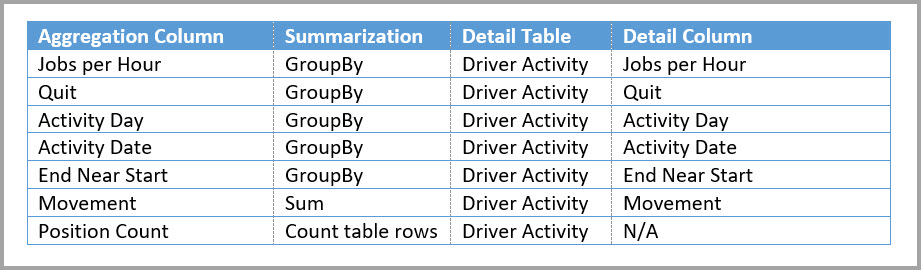
I følgende tabel vises sammenlægningerne for tabellen Driver Activity Agg .
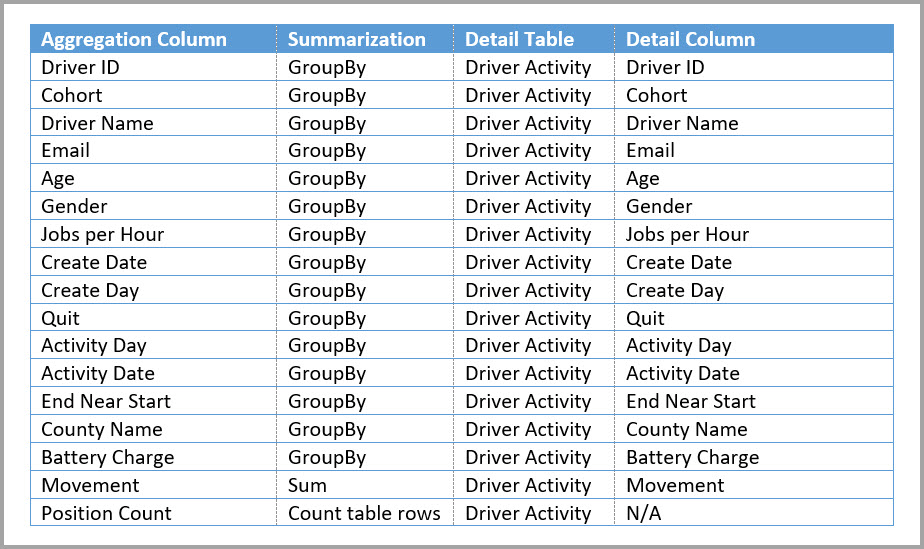
Du kan angive lagringstilstanden for den samlede tabel Driver Activity Agg til Import.
Følgende forespørgsel giver forekomster ved sammenlægningen, fordi kolonnen Activity Date er dækket af sammenlægningstabellen. Funktionen COUNTROWS bruger sammenlægningen Antal tabelrækker .

Især for modeller, der indeholder filterattributter i faktatabeller, er det en god idé at bruge Sammenlægninger af antal tabelrækker . Power BI kan sende forespørgsler til modellen ved hjælp af COUNTROWS i de tilfælde, hvor brugeren ikke udtrykkeligt anmoder om det. Filterdialogboksen viser f.eks. antallet af rækker for hver værdi.
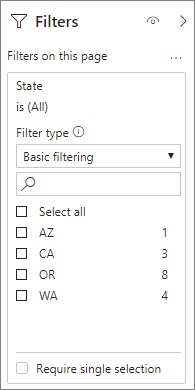
Du kan kombinere teknikkerne relationer og GroupBy-kolonner til sammenlægninger. Sammenlægninger baseret på relationer kan kræve, at de denormaliserede dimensionstabeller opdeles i flere tabeller. Hvis det er dyrt eller upraktisk for visse dimensionstabeller, kan du replikere de nødvendige attributter i sammenlægningstabellen for disse dimensioner og bruge relationer for andre.
Følgende model replikerer f.eks. Måned, Kvartal, Semester og År i tabellen Sales Agg . Der er ingen relation mellem Sales Agg og tabellen Date , men der er relationer til Kunde og Produktunderkategori. Lagringstilstanden for Sales Agg er Import.
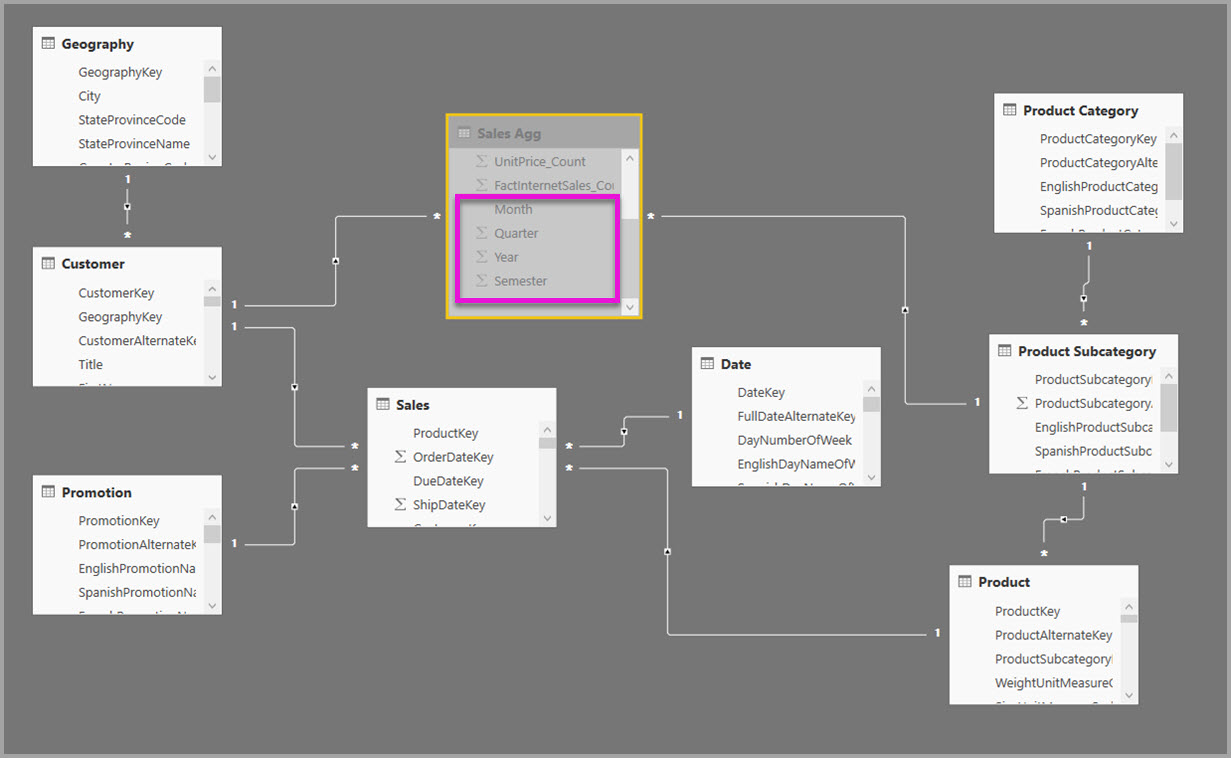
I følgende tabel vises de poster, der er angivet i dialogboksen Administrer sammenlægninger for tabellen Sales Agg . GroupBy-posterne, hvor Date er detaljetabellen, er obligatoriske for at give forekomster af sammenlægninger for forespørgsler, der grupperes efter datoattributterne. Som i det forrige eksempel påvirker GroupBy-posterne for CustomerKey og ProductSubcategoryKey ikke sammenlægningsforekomster undtagen DISTINCTCOUNT på grund af tilstedeværelsen af relationer.
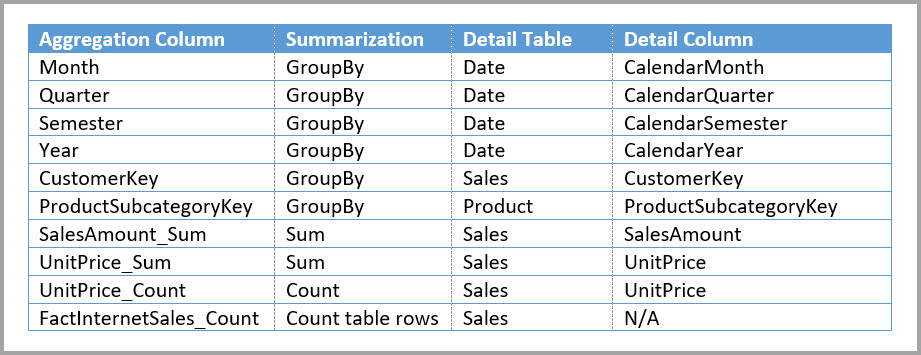
Følgende forespørgsel giver forekomster ved sammenlægningen, fordi sammenlægningstabellen dækker CalendarMonth, og CategoryName er tilgængelig via en til mange-relationer. SalesAmount bruger SUM-sammenlægningen.

Følgende forespørgsel giver ikke forekomster ved sammenlægningen, fordi sammenlægningstabellen ikke dækker CalendarDay.

Følgende time intelligence-forespørgsel giver ikke forekomster ved sammenlægningen, fordi funktionen DATESYTD genererer en tabel med CalendarDay-værdier , og sammenlægningstabellen dækker ikke CalendarDay.

Sammenlægningsrækkefølge gør det muligt for flere sammenlægningstabeller at blive taget i betragtning af en enkelt underforespørgsel.
Følgende eksempel er en sammensat model , der indeholder flere kilder:
Bemærk
DirectQuery-sammenlægningstabeller, der bruger en anden datakilde fra detaljetabellen, understøttes kun, hvis sammenlægningstabellen er fra en SQL Server-, Azure SQL- eller Azure Synapse Analytics-kilde (tidligere SQL Data Warehouse).
Hukommelsesfodaftrykket for denne model er relativt lille, men det låser op for en enorm model. Den repræsenterer en balanceret arkitektur, fordi den fordeler forespørgselsbelastningen på tværs af komponenterne i arkitekturen og udnytter dem på baggrund af deres styrker.
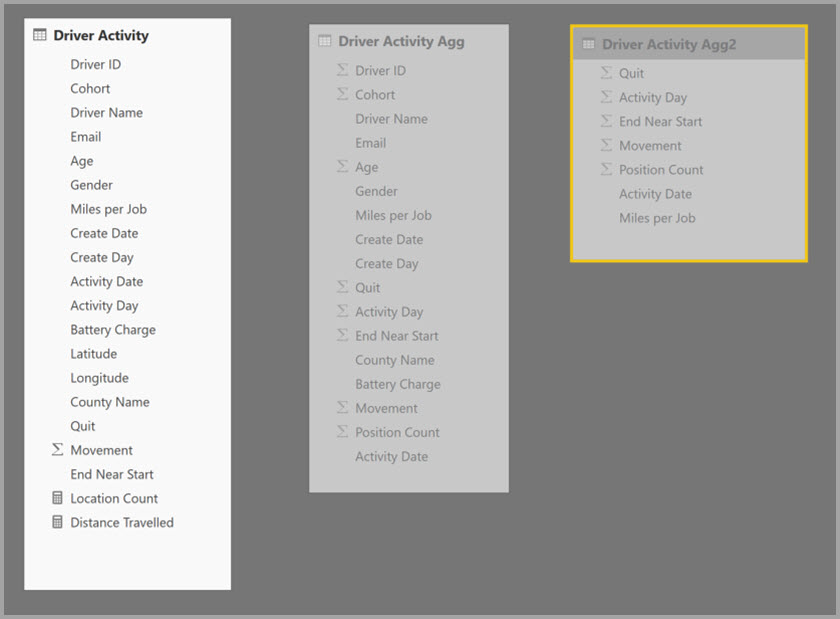
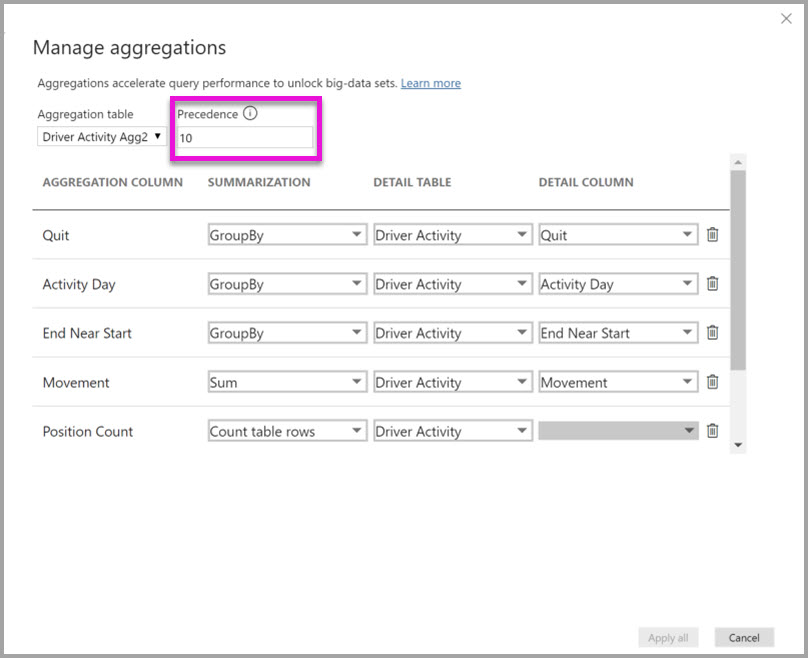
Dialogboksen Administrerede sammenlægninger for Driver Activity Agg2 angiver feltet Rangplacering til 10, hvilket er højere end for Driver Activity Agg. Indstillingen for højere prioritet betyder, at forespørgsler, der bruger sammenlægninger, først overvejer Driver Activity Agg2 . Underforespørgsler, der ikke har den granularitet, der kan besvares af Driver Activity Agg2 , kan overveje Driver Activity Agg i stedet for. Detaljeforespørgsler, der ikke kan besvares af nogen af sammenlægningstabellen, kan henvise til Driver Activity.
Den tabel, der er angivet i kolonnen Detail Table , er Driver Activity, ikke Driver Activity Agg, fordi sammenkædede sammenlægninger ikke er tilladt.
I følgende tabel vises sammenlægningerne for tabellen Driver Activity Agg2 .
SQL Profiler kan registrere, om forespørgsler returneres fra cachelagerprogrammet i hukommelsen eller pushes til datakilden af DirectQuery. Du kan bruge den samme proces til at registrere, om sammenlægninger rammes. Du kan få flere oplysninger under Forespørgsler, der rammer eller savner cachen.
SQL Profiler leverer også den Query Processing\Aggregate Table Rewrite Query udvidede hændelse.
Følgende JSON-kodestykke viser et eksempel på outputtet af hændelsen, når der bruges en sammenlægning.

Sammenlægninger, der kombinerer DirectQuery-, Import- og/eller Dual-lagringstilstande, kan returnere forskellige data, medmindre cachen i hukommelsen holdes synkroniseret med kildedataene. Udførelse af forespørgsler forsøger f.eks. ikke at maskere dataproblemer ved at filtrere DirectQuery-resultater, så de stemmer overens med cachelagrede værdier. Der er etableret teknikker til at håndtere sådanne problemer ved kilden, hvis det er nødvendigt. Optimeringer af ydeevnen bør kun bruges på måder, der ikke kompromitterer din evne til at opfylde forretningsmæssige krav. Det er dit ansvar at kende dine dataflow og designe i overensstemmelse hermed.
Sammenlægninger understøtter ikke dynamiske M-forespørgselsparametre.
Fra og med august 2022 ignorerer Power BI på grund af ændringer i funktionaliteten sammenlægningstabeller i importtilstand med SSO-aktiverede datakilder (Single Sign-on) på grund af potentielle sikkerhedsrisici. For at sikre optimal forespørgselsydeevne med sammenlægninger anbefales det, at du deaktiverer SSO for disse datakilder.
Power BI har et levende community, hvor MVP'er, BI-teknikere og peers deler ekspertise inden for diskussionsgrupper, videoer, blogs og meget mere. Når du lærer om sammenlægninger, skal du tjekke disse yderligere ressourcer ud:
Begivenhed
14. feb., 16 - 31. mar., 16
Med 4 chancer for at komme ind, kan du vinde en konference pakke og gøre det til LIVE Grand Finale i Las Vegas
Flere oplysningerTræning
Læringsforløb
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Certificering
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Demonstrer metoder og bedste fremgangsmåder, der er i overensstemmelse med forretningsmæssige og tekniske krav til modellering, visualisering og analyse af data med Microsoft Power BI.
Dokumentation
Antag indstillingen Referentiel integritet i Power BI Desktop - Power BI
Få mere at vide om, hvordan Power BI Desktop antager referentiel integritet, hvilket gør det muligt for forespørgsler at bruge INNER JOIN-sætninger.
Bruge sammensatte modeller i Power BI Desktop - Power BI
Få mere at vide om, hvordan du opretter datamodeller med flere dataforbindelser og mange til mange-relationer i Power BI Desktop.
Oversigt over automatiske sammenlægninger - Power BI
Få mere at vide om, hvordan du bruger automatiske sammenlægninger til at optimere forespørgselsydeevnen for Semantiske DirectQuery-modeller.