Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Power BI semantiske modeller kan inkludere tabeller fra en eller flere datakilder ved at bruge en hvilken som helst af de understøttede tabellagringstilstande. Når tabeller bruger forskellige lagringstilstande, er modellen en sammensat semantisk model. For DirectQuery-tabellagringstilstand er modellen sammensat, når DirectQuery-tabellerne bruger forskellige datakilder.
For eksempel, hvis du forbinder til en anden Power BI semantisk model ved at bruge DirectQuery (som tilføjer tabeller i DirectQuery-lagringstilstand) og også har lokale tabeller i Import-tilstand, bliver din model en sammensat model, fordi den indeholder tabeller med forskellige lagringstilstande.
Bemærk
Importtabeller fra en eller flere datakilder er ikke sammensatte modeller, før du blander dem med ikke-importerede tabeller. Den samme regel gælder for semantiske modeller med Direct Lake-tabeller fra en eller flere datakilder.
Bemærk
For sammensatte modeller antages Direct Lake-tabellagringstilstanden at være Direct Lake på OneLake. Direct Lake på SQL-tabellagringstilstand er kun en enkelt kilde og kan ikke føjes til nogen sammensat model. For mere information om forskellene i Direct Lake-tabellagringstilstand, se aka.ms/DirectLake.
Typer af sammensatte modeller
Der findes forskellige typer af sammensatte modeller afhængigt af kombinationen af tabellagringstilstande i den semantiske model. Hver type har sine egne overvejelser for funktionalitet og værktøj.
| Sammensat modeltype | Værktøj til rådighed | Notes |
|---|---|---|
| DirectQuery til en anden semantisk Power BI-model med eller uden yderligere tabeller i import- eller DirectQuery-lagringstilstand | Kun Power BI Desktop | Forbind til en Power BI semantisk model, vælg derefter Foretag ændringer i denne model eller forbind efter at have tilføjet en tabel i import- eller DirectQuery-lagringstilstand. |
| DirectQuery-tabeller, der kommer fra forskellige datakilder | Kun Power BI Desktop | Tabel A kommer f.eks. fra SQL-database A, og tabel B kommer fra SQL-database B |
| Import- og DirectQuery-tabeller i den samme semantiske model | Kun Power BI Desktop | |
| Import- og Direct Lake-tabeller i samme semantiske model | Kun Power BI-webmodellering | Import- eller Direct Lake-tabeller kan tilføjes i Desktop, men kun kombineres i webmodellering. |
| DirectQuery- og Direct Lake-tabeller i samme semantiske model | Kun XMLA | Kombiner ved hjælp af et XMLA-script eller XMLA-community-baserede værktøjer. Kan kun åbnes i webmodellering for redigering af semantiske modeller uden indstillinger for opdatering eller ændring af tabeller. |
Opret sammensatte modeller i Power BI Desktop
I Power BI Desktop kan du oprette semantiske modeller med import- eller DirectQuery-tabeller lokalt. Du kan derefter tilføje flere tabeller fra Get data-båndknappen i den anden lagringstilstand for at skabe en sammensat model.
Bemærk
Hvis import- og DirectQuery-tabeller begge er i en semantisk model og kommer fra samme datakilde, er dual storage mode tilgængelig. Dobbelttilstand, der bruges i stedet for DirectQuery, kan undgå begrænsede relationer med importtabeller. For mere information, se dual storage mode.
Tilføjelse af DirectQuery-tabeller fra en anden Power BI semantisk model har et par forskellige oprettelsesstier.
I en tom Power BI-fil skal du først oprette forbindelse til den semantiske Power BI-model. Når du er tilsluttet, har du mulighed for at foretage ændringer i denne model. Ved at vælge 'Foretag ændringer i denne model ' fra båndet eller footeren konverteres den levende forbindelse til en DirectQuery-forbindelse. DirectQuery-forbindelsen opretter en ny lokal semantisk model med tabellerne i DirectQuery-lagringstilstand. Du kan tilføje nye tabeller i enten import- eller DirectQuery-lagringstilstand samt give dig mulighed for at tilsidesætte nogle kolonneegenskaber på den semantiske kildemodel.
I en semantisk model med import- eller DirectQuery-tabeller allerede, forbind til en Power BI-semantisk model, og de tabeller, du vælger, tilføjes som DirectQuery.
Semantiske modeller, der er oprettet med Direct Lake-tabeller, redigeres direkte i Power BI Desktop. Du kan tilføje flere Direct Lake-borde. For at tilføje importtabeller skal du åbne den semantiske model i Power BI web modeling. For at tilføje DirectQuery-tabeller, brug XMLA.
Du kan live redigere en Direct Lake og importere semantisk model i Desktop, men du kan ikke tilføje flere tabeller. Du kan kun tilføje tabeller fra Power BI web modeling til Direct Lake og importere kompositmodeller.
Oprette sammensatte modeller i webmodellering
I Power BI webmodellering kan du oprette semantiske modeller med import- eller Direct Lake-tabeller. Du kan ikke tilføje DirectQuery-tabeller. Du kan tilføje flere tabeller i den anden lagringstilstand for at skabe en sammensat model.
Brug sammensatte modeller
Med sammensatte modeller kan du oprette forbindelse til forskellige typer datakilder, når du bruger Power BI Desktop eller Power BI-tjeneste. Du kan oprette disse dataforbindelser på flere måder:
- Ved at importere data til Power BI, som er den mest almindelige måde at hente data på.
- Ved at oprette direkte forbindelse til data i det oprindelige kildelager ved hjælp af DirectQuery. Du kan få mere at vide om DirectQuery under DirectQuery i Power BI.
Når du bruger DirectQuery, gør sammensatte modeller det muligt at oprette en Power BI-model, f.eks. en enkelt .pbix Power BI Desktop-fil, der udfører en eller begge af følgende handlinger:
- Kombinerer data fra en eller flere DirectQuery-kilder.
- Kombinerer data fra DirectQuery-kilder og importerer data.
Ved hjælp af sammensatte modeller kan du f.eks. oprette en model, der kombinerer følgende datatyper:
- Salgsdata fra et virksomhedsdata warehouse.
- Salgsmåldata fra en afdelings SQL Server-database.
- Data, der er importeret fra et regneark.
En semantisk model, der kombinerer tabeller fra mere end én DirectQuery-kilde, eller kombinerer DirectQuery, Direct Lake og importtabeller, er en sammensat semantisk model.
Du kan oprette relationer mellem tabeller, som du altid har gjort, selvom disse tabeller kommer fra forskellige kilder. Alle relationer, der er på tværs af kilder, oprettes med en kardinalitet på mange til mange, uanset deres faktiske kardinalitet. Du kan ændre dem til en til mange, mange til en eller en til en. Uanset hvilken kardinalitet du angiver, har relationer på tværs af kilder forskellige funktionsmåder. Du kan ikke bruge DAX-funktioner (Data Analysis Expressions) til at hente værdier på one siden fra many siden. Du kan også se en indvirkning på ydeevnen i forhold til mange til mange-relationer i den samme kilde.
Bemærk
I forbindelse med sammensatte modeller er alle importerede tabeller reelt en enkelt kilde, uanset de faktiske underliggende datakilder.
Eksempel på en sammensat model
I et eksempel på en sammensat model kan du overveje en rapport, der opretter forbindelse til et firmadata warehouse i SQL Server ved hjælp af DirectQuery. I dette tilfælde indeholder data warehouse'et Sales by Country, Quarter og Bike (Product) som vist på følgende billede:
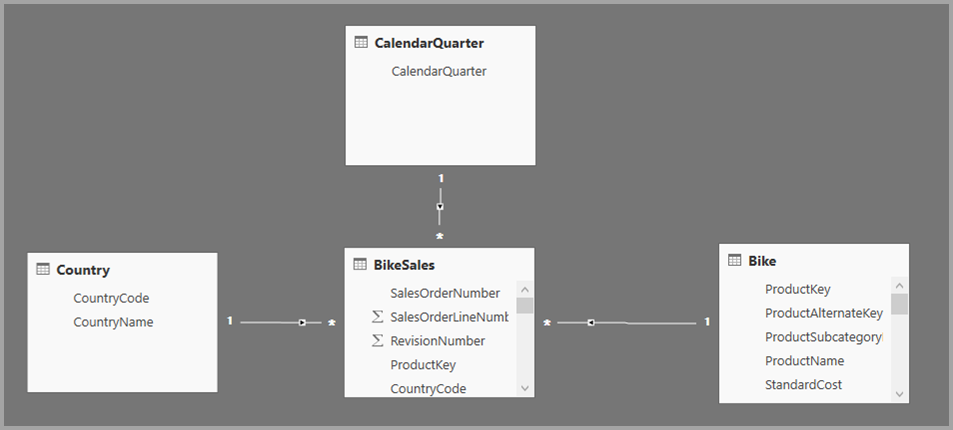
På dette tidspunkt kan du oprette simple visualiseringer ved hjælp af felter fra denne kilde. På følgende billede vises det samlede salg efter ProductName for et valgt kvartal.
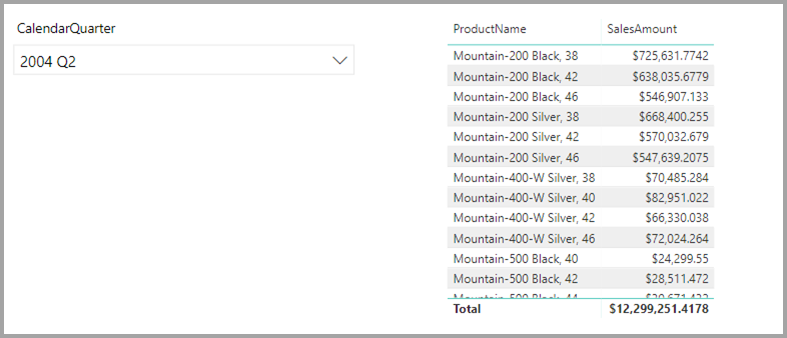
Men hvad nu, hvis du har data i et Excel-regneark om den produktchef, der er tildelt hvert produkt, sammen med marketingprioriteten? Hvis du vil have vist Salgsbeløb efter Produktchef, er det muligvis ikke muligt at føje disse lokale data til virksomhedens data warehouse. Eller det kan tage måneder i bedste fald.
Det kan være muligt at importere disse salgsdata fra data warehouse'et i stedet for at bruge DirectQuery. Og salgsdataene kan derefter kombineres med de data, du har importeret fra regnearket. Denne fremgangsmåde er dog urimelig af de grunde, der i første omgang førte til brugen af DirectQuery. Årsagerne kan omfatte:
- En kombination af de sikkerhedsregler, der gennemtvinges i den underliggende kilde.
- Behovet for at kunne få vist de nyeste data.
- Den store skala af dataene.
Her kommer sammensatte modeller ind i det. Sammensatte modeller giver dig mulighed for at oprette forbindelse til data warehouse'et ved hjælp af DirectQuery og derefter bruge Hent data til flere kilder. I dette eksempel opretter vi først DirectQuery-forbindelsen til virksomhedens data warehouse. Vi bruger Hent data, vælger Excel og navigerer derefter til det regneark, der indeholder vores lokale data. Endelig importerer vi det regneark, der indeholder produktnavnene, den tildelte salgschef og prioriteten.
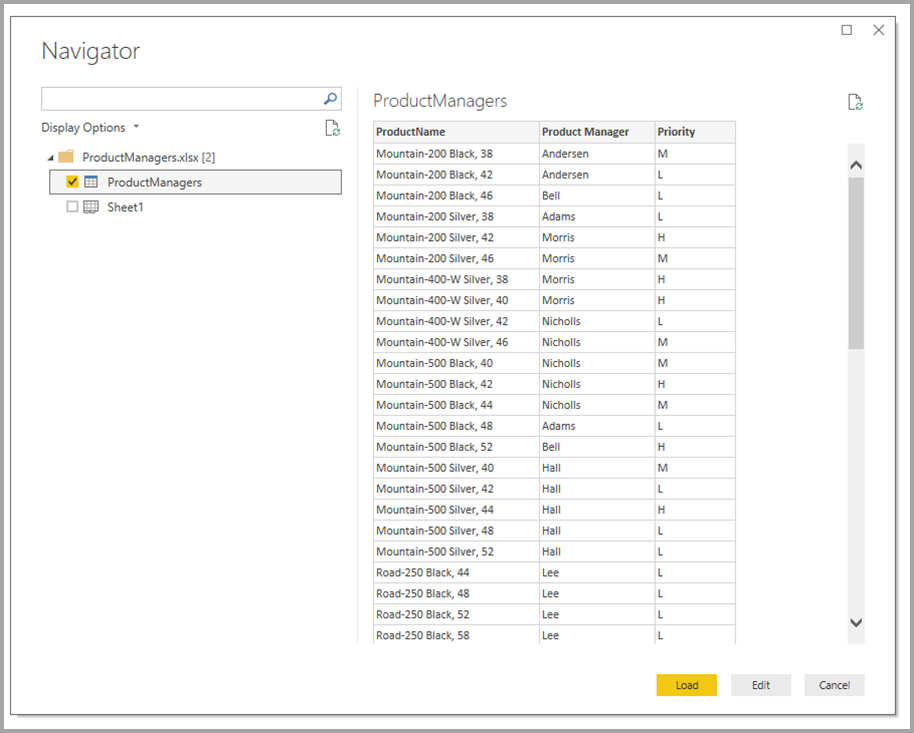
På listen Felter kan du se to tabeller: den oprindelige cykeltabel fra SQL Server og en ny ProductManagers-tabel. Den nye tabel indeholder de data, der er importeret fra Excel.
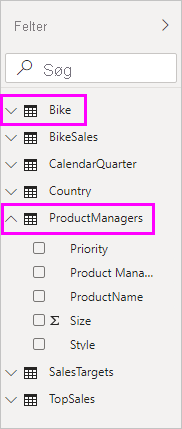
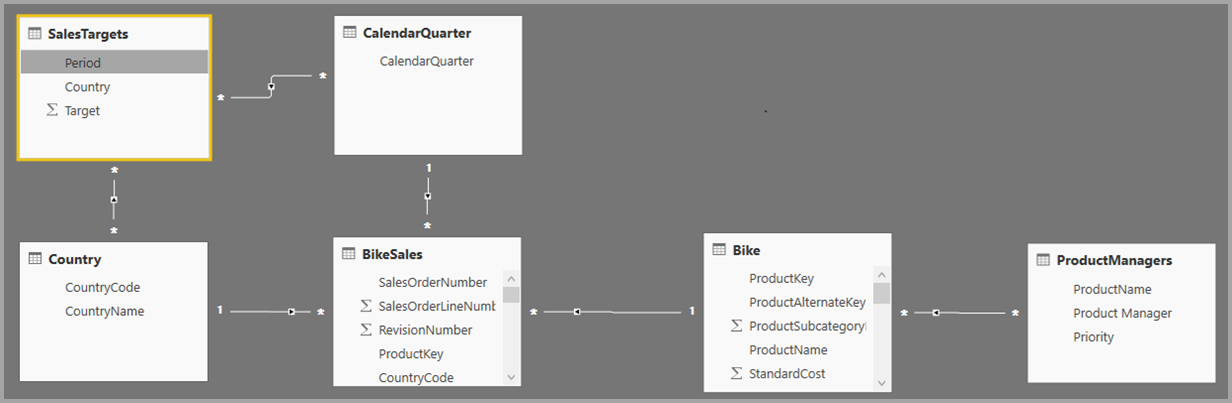
På samme måde kan vi i relationsvisningen i Power BI Desktop nu se en anden tabel med navnet ProductManagers.
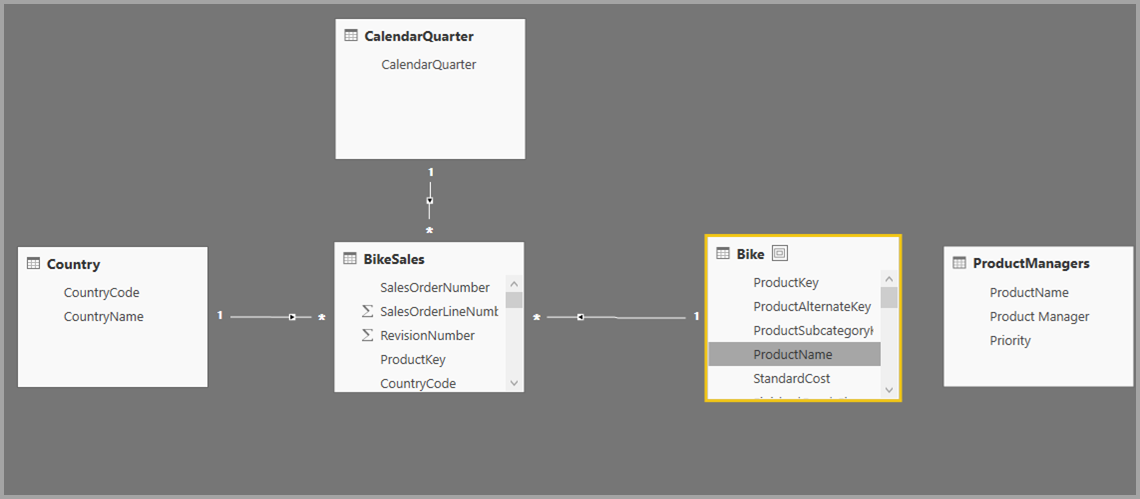
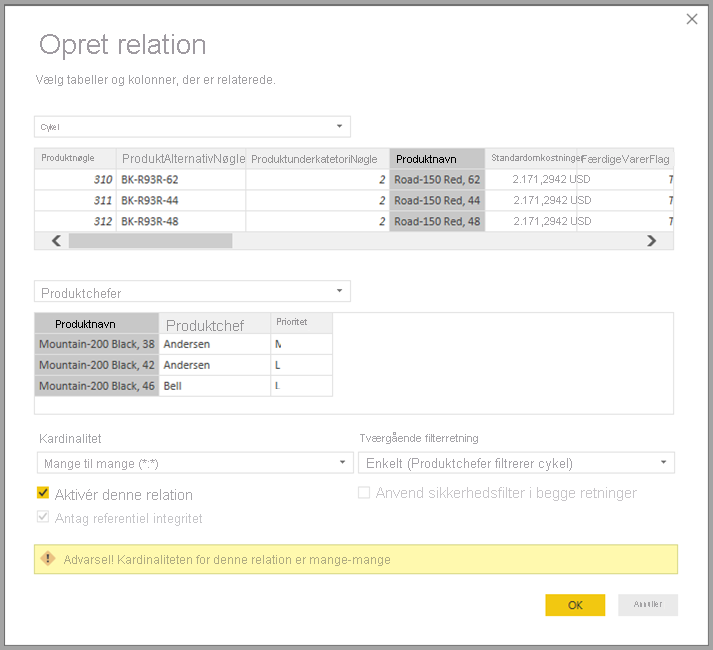
Vi skal nu relatere disse tabeller til de andre tabeller i modellen. Som altid opretter vi en relation mellem tabellen Bike fra SQL Server og den importerede ProductManagers-tabel . Det vil altså være relationen mellem Bike[ProductName] og ProductManagers[ProductName]. Som beskrevet tidligere er alle relationer, der går på tværs af kilden, som standard mange til mange-kardinalitet.
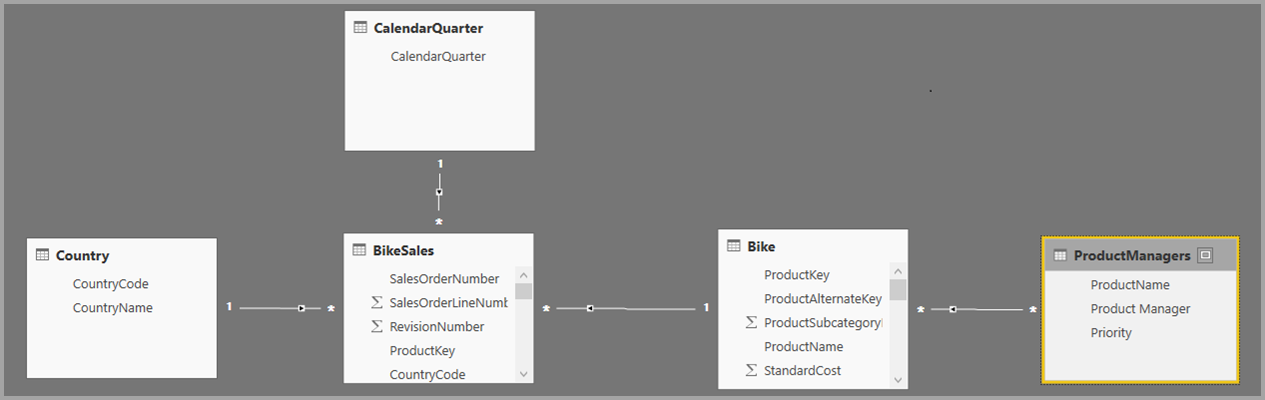
Nu, hvor vi har oprettet denne relation, vises den i relationsvisningen i Power BI Desktop, som vi ville forvente.
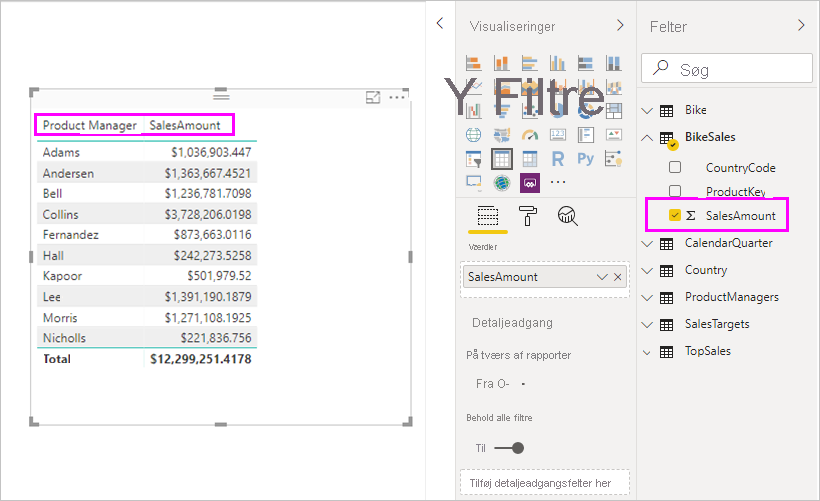
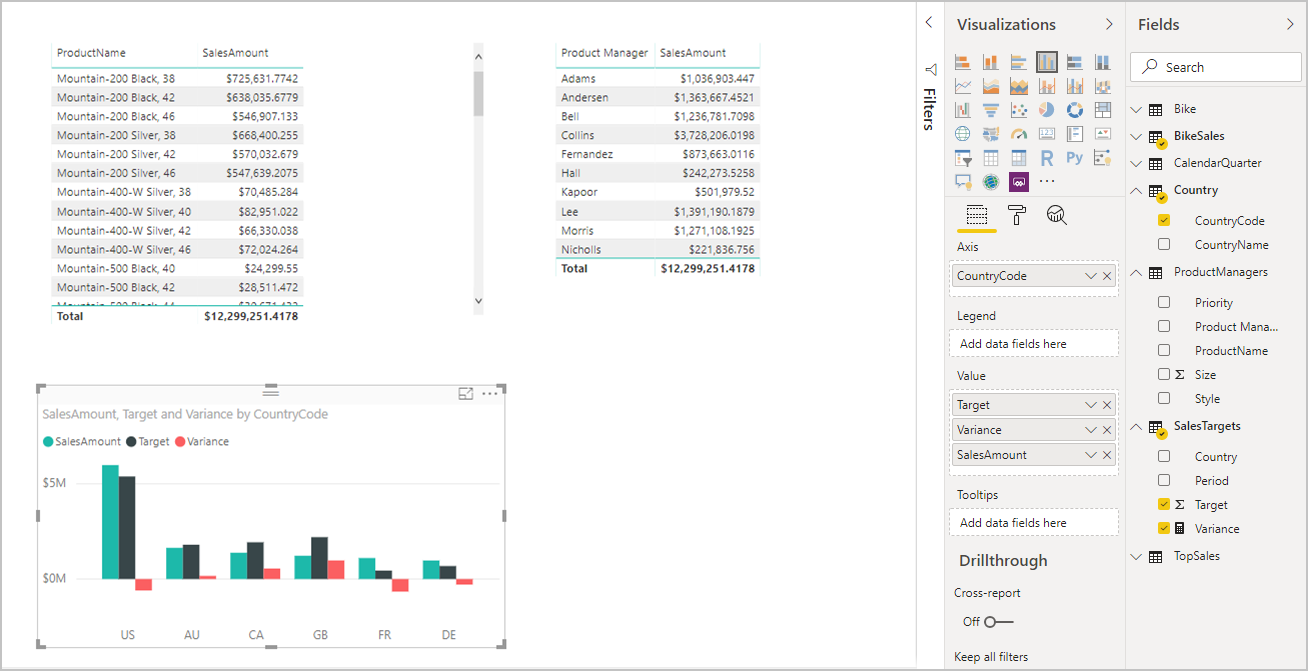
Vi kan nu oprette visualiseringer ved hjælp af et af felterne på listen Felter . Denne fremgangsmåde blander problemfrit data fra flere kilder. Det samlede SalesAmount for hver Produktchef vises f.eks. på følgende billede:
I følgende eksempel vises et almindeligt tilfælde af en dimensionstabel , f.eks . Product eller Customer, der er udvidet med nogle ekstra data, der er importeret et andet sted fra. Det er også muligt at få tabeller til at bruge DirectQuery til at oprette forbindelse til forskellige kilder. For at fortsætte med vores eksempel kan du forestille dig, at salgsmål pr. land og periode er gemt i en separat afdelingsdatabase. Som sædvanlig kan du bruge Hent data til at oprette forbindelse til disse data, som vist på følgende billede:
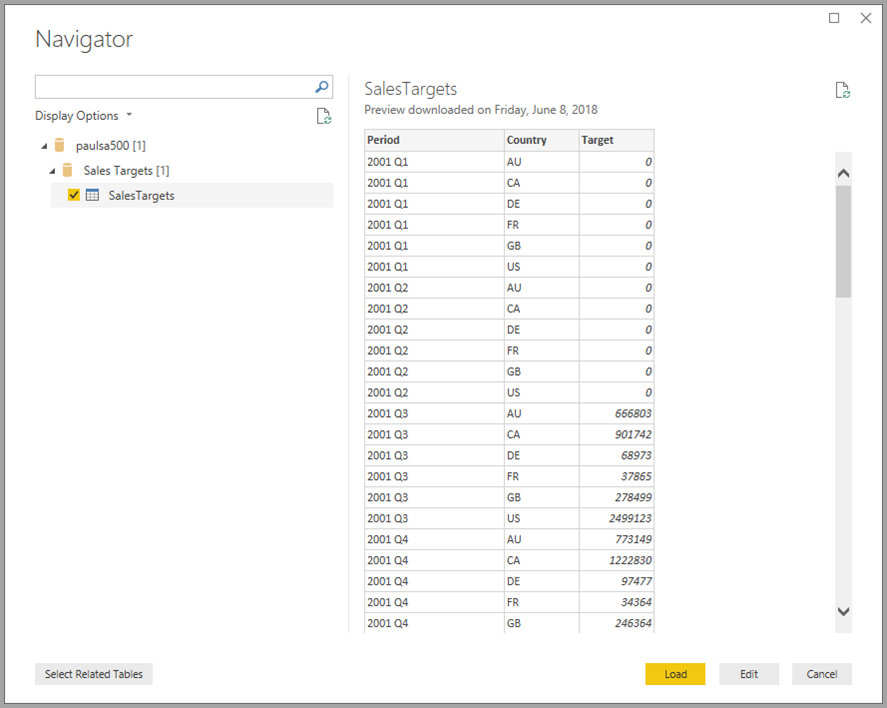
Som vi gjorde tidligere, kan vi oprette relationer mellem den nye tabel og andre tabeller i modellen. Derefter kan vi oprette visualiseringer, der kombinerer tabeldataene. Lad os se på visningen Relationer igen, hvor vi har oprettet de nye relationer:
Det næste billede er baseret på de nye data og relationer, vi har oprettet. Visualiseringen nederst til venstre viser det samlede salgsbeløb i forhold til Mål, og variansberegningen viser forskellen. Dataene Sales Amount og Target stammer fra to forskellige SQL Server-databaser.
Angiv lagringstilstanden
Hver tabel i en sammensat model har en lagringstilstand, der angiver, om tabellen er baseret på DirectQuery eller import. Du kan se og ændre lagringstilstanden i Egenskaber-panelet . For at se lagringstilstanden:
- Vælg tabellen i modelvisning .
- I Egenskaber-panelet udvid du Avancerede sektion, og udvid derefter listen over Opbevaringstilstand .
Du kan også se lagringstilstanden i tooltip'en for hver tabel, når du holder musen over den i Data-panelet.
For alle Power BI Desktop-filer (en .pbix-fil ), der indeholder nogle tabeller fra DirectQuery og nogle importtabeller, viser statuslinjen en lagringstilstand med navnet Blandet. Du kan vælge dette ord på statuslinjen og nemt skifte alle tabeller til import.
Du kan få flere oplysninger om lagringstilstand under Administrer lagringstilstand i Power BI Desktop.
Bemærk
Du kan bruge blandet lagringstilstand i Power BI Desktop og i Power BI-tjeneste.
Beregnede tabeller
Du kan føje beregnede tabeller til en model i Power BI Desktop, der bruger DirectQuery. DAX (Data Analysis Expressions), der definerer den beregnede tabel, kan referere til enten importerede eller DirectQuery-tabeller eller en kombination af de to.
Beregnede tabeller importeres altid, og deres data opdateres, når du opdaterer tabellerne. Hvis en beregnet tabel refererer til en DirectQuery-tabel, viser visualiseringer, der refererer til DirectQuery-tabellen, altid de nyeste værdier i den underliggende kilde. Alternativt kan visualiseringer, der refererer til den beregnede tabel, vise værdierne på det tidspunkt, hvor den beregnede tabel sidst blev opdateret.
Vigtigt
Beregnede tabeller understøttes ikke i Power BI-tjenesten ved at bruge denne funktion, medmindre du opfylder specifikke krav. For mere information, se afsnittet Arbejde med en sammensat model baseret på en semantisk model i denne artikel.
Sikkerhedsmæssige konsekvenser
Sammensatte modeller har nogle sikkerhedsmæssige konsekvenser. En forespørgsel sendt til én datakilde kan indeholde dataværdier, der hentes fra en anden kilde. I det tidligere eksempel sender den visualisering, der viser (Salgsbeløb) af Produktchef , en SQL-forespørgsel til relationsdatabasen Salg. Denne SQL-forespørgsel kan indeholde navnene på produktchefer og deres tilknyttede produkter.

Så de oplysninger, der er gemt i regnearket, er nu inkluderet i en forespørgsel, der sendes til relationsdatabasen. Hvis disse oplysninger er fortrolige, bør du overveje de sikkerhedsmæssige konsekvenser. Overvej især følgende punkter:
Enhver administrator af databasen, som kan se spor eller revisionslogfiler, kan se disse oplysninger, selv uden tilladelser til dataene i deres oprindelige kilde. I dette eksempel har administratoren brug for tilladelser til Excel-filen.
Krypteringsindstillingerne for hver kilde. Du vil undgå at hente oplysninger fra én kilde via en krypteret forbindelse og derefter utilsigtet inkludere dem i en forespørgsel, der sendes til en anden kilde af en ukrypteret forbindelse.
For at bekræfte, at du har taget hensyn til eventuelle sikkerhedsmæssige implikationer, viser Power BI Desktop en advarselsmeddelelse, når du opretter en sammensat model.
Derudover, hvis en forfatter tilføjer Table1 fra Model A til en sammensat model (lad os kalde den Model C til reference), kan en bruger, der ser en rapport bygget på Model C , forespørge enhver tabel i Model A , der ikke er beskyttet af row-level security (RLS).
Af lignende årsager skal du være forsigtig, når du åbner en Power BI Desktop-fil, der er sendt fra en kilde, der ikke er tillid til. Hvis filen indeholder sammensatte modeller, sendes information, som nogen henter fra én kilde ved at bruge brugerens legitimationsoplysninger, til en anden datakilde som en del af forespørgslen. Den ondsindede forfatter af Power BI Desktop-filen kunne se informationen. Når du åbner en Power BI Desktop-fil, der indeholder flere kilder, viser Power BI Desktop en advarsel. Advarslen svarer til den, der vises, når du åbner en fil, der indeholder oprindelige SQL-forespørgsler.
Konsekvenser for ydeevnen
Når du bruger DirectQuery, skal du altid tage hensyn til ydeevnen. Sørg for, at backend-kilden har nok ressourcer til at give brugerne en god oplevelse. En god oplevelse betyder, at visualiseringerne opdateres på fem sekunder eller mindre. Du kan finde flere råd om ydeevnen i DirectQuery i Power BI.
Brug af sammensatte modeller tilføjer andre overvejelser i forbindelse med ydeevnen. En enkelt visuel kan sende forespørgsler til flere kilder. Ofte sender én forespørgsel sine resultater videre til en anden kilde. Denne situation kan resultere i følgende former for udførelse:
En kildeforespørgsel, der indeholder et stort antal bogstavelige værdier: For eksempel vil en visuel person, der anmoder om det samlede salgsbeløb for et sæt udvalgte produktchefer , først skulle finde ud af, hvilke produkter disse produktchefer administrerer. Denne sekvens skal ske, før visualiseringen sender en SQL-forespørgsel, der indeholder alle produkt-id'erne i en
WHEREdelsætning.En kildeforespørgsel, der forespørger på et lavere granularitetsniveau, hvor dataene senere aggregeres lokalt: Da antallet af produkter , der opfylder filterkriterierne i Product Manager , bliver stort, kan det blive ineffektivt eller umuligt at inkludere alle produkter i en
WHEREdelsætning. Du kan i stedet forespørge relationskilden på det lavere niveau af Produkter og derefter samle resultaterne lokalt. Hvis kardinaliteten for Produkter overskrider en grænse på 1 million, mislykkes forespørgslen.Flere kildeforespørgsler, én per gruppe efter værdi: Når aggregeringen bruger DistinctCount og grupperes af en kolonne fra en anden kilde, og hvis den eksterne kilde ikke understøtter effektiv overførsel af mange literalværdier, der definerer grupperingen, skal du sende én SQL-forespørgsel per gruppe efter værdi.
Et visuelt system, der anmoder om en særskilt optælling af CustomerAccountNumber fra SQL Server-tabellen af Product Managers , som er importeret fra regnearket, skal sende detaljerne fra Product Manager-tabellen i forespørgslen sendt til SQL Server. I forhold til andre kilder, f.eks. Redshift, er denne handling ikke mulig. I stedet sendes der én SQL-forespørgsel pr. salgschef op til en praktisk grænse, hvorefter forespørgslen mislykkes.
Hver af disse sager har sine egne konsekvenser for ydeevnen, og de nøjagtige oplysninger varierer for hver datakilde. Selvom kardinaliteten af kolonnerne, der bruges i relationen, der forbinder de to kilder, forbliver lav (et par tusinde), bør ydeevnen ikke blive påvirket. Efterhånden som denne kardinalitet vokser, bør du være mere opmærksom på effekten på den resulterende præstation.
Desuden betyder brugen af mange til mange-relationer, at der skal sendes separate forespørgsler til den underliggende kilde for hvert total- eller subtotalniveau i stedet for at aggregere de detaljerede værdier lokalt. En simpel tabel-visuel med totaler sender to kildeforespørgsler i stedet for én.
Kildegrupper
En kildegruppe er en samling elementer, f.eks. tabeller og relationer, fra en DirectQuery-kilde eller alle importkilder, der er involveret i en datamodel. En sammensat model er lavet af en eller flere kildegrupper. Overvej følgende eksempler:
- En sammensat model, der opretter forbindelse til en semantisk Power BI-model med navnet Sales og forbedrer den semantiske model ved at tilføje en Sales YTD-måling , som ikke er tilgængelig i den oprindelige semantiske model. Denne model består af én kildegruppe.
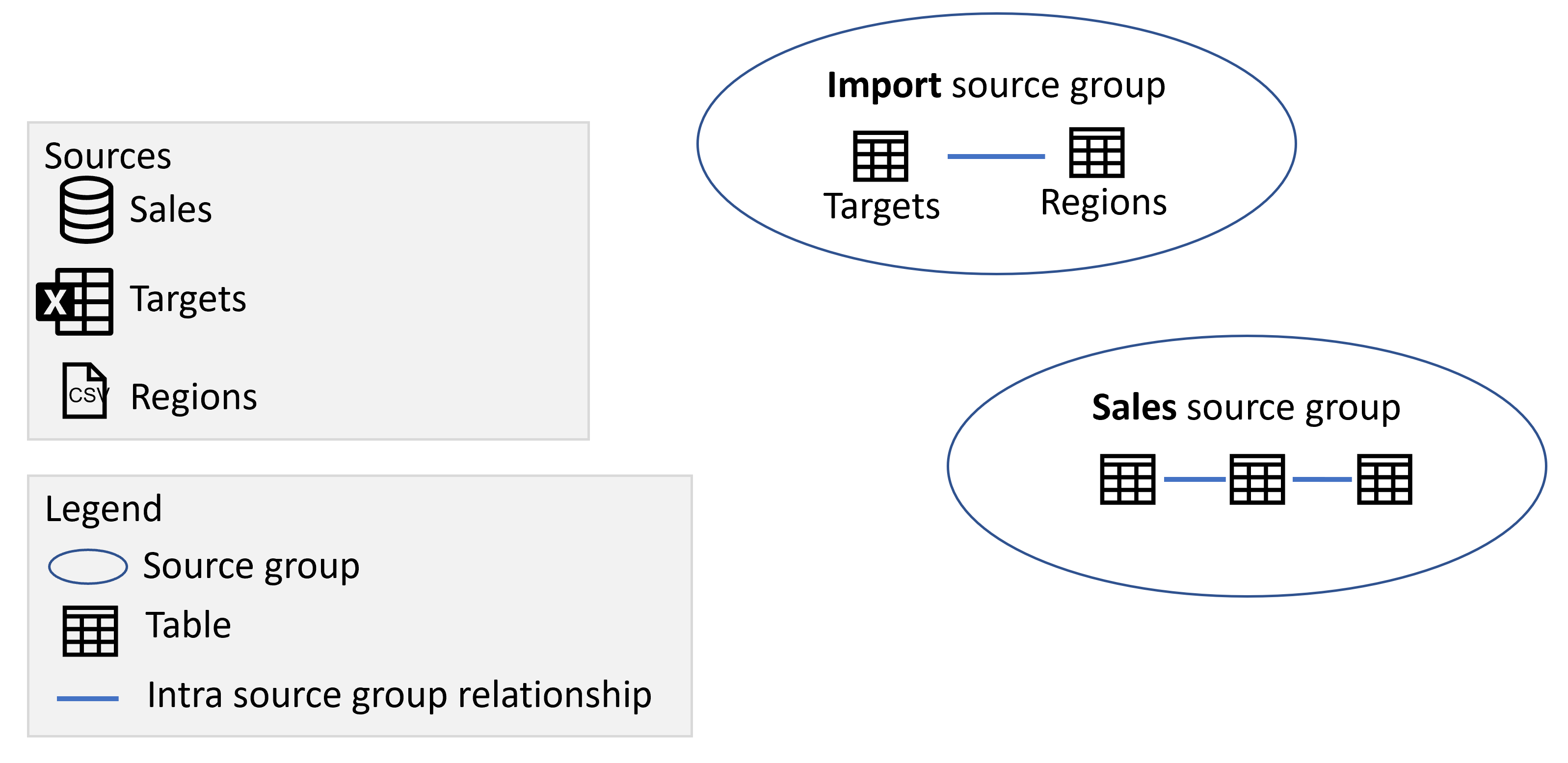
- En sammensat model, der kombinerer data ved at importere en tabel fra et Excel-ark med navnet Targets og en CSV-fil med navnet Områder og oprette en DirectQuery-forbindelse til en semantisk Power BI-model med navnet Salg. I dette tilfælde er der to kildegrupper som vist på følgende billede:
- Den første kildegruppe indeholder tabellerne fra Excel-arket Targets og CSV-filen Område .
- Den anden kildegruppe indeholder elementerne fra semantikmodellen Sales Power BI.
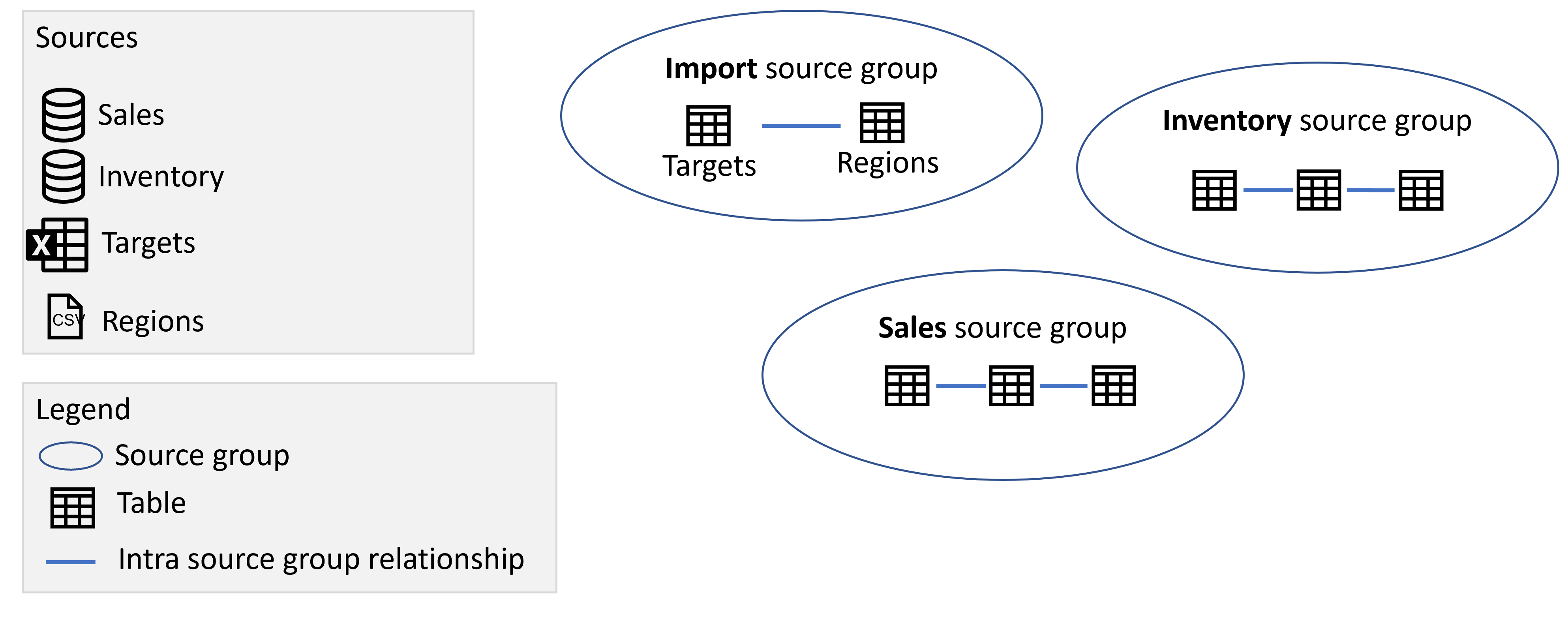
Hvis du tilføjer en anden DirectQuery-forbindelse til en anden kilde, såsom en DirectQuery-forbindelse til en SQL Server-database kaldet Inventory, tilføjes elementerne fra den kilde som en anden kildegruppe:
Bemærk
Import af data fra en anden kilde tilføjer ikke en ny kildegruppe, fordi alle elementer fra alle importerede kilder er i én kildegruppe. Direct Lake- og importtabeller betragtes også som den samme kildegruppe.
Kildegrupper og -relationer
En sammensat model har to typer relationer:
- Relationer for intern kildegruppe. Disse relationer forbinder elementer inden for en kildegruppe. Disse relationer er altid almindelige relationer, medmindre de er mange til mange, i hvilket tilfælde de er begrænset.
- Relationer på tværs af kildegrupper. Disse relationer starter i én kildegruppe og ender i en anden kildegruppe. Disse relationer er altid begrænsede relationer.
Læs mere om forskellen mellem almindelige og begrænsede relationer og deres indvirkning.
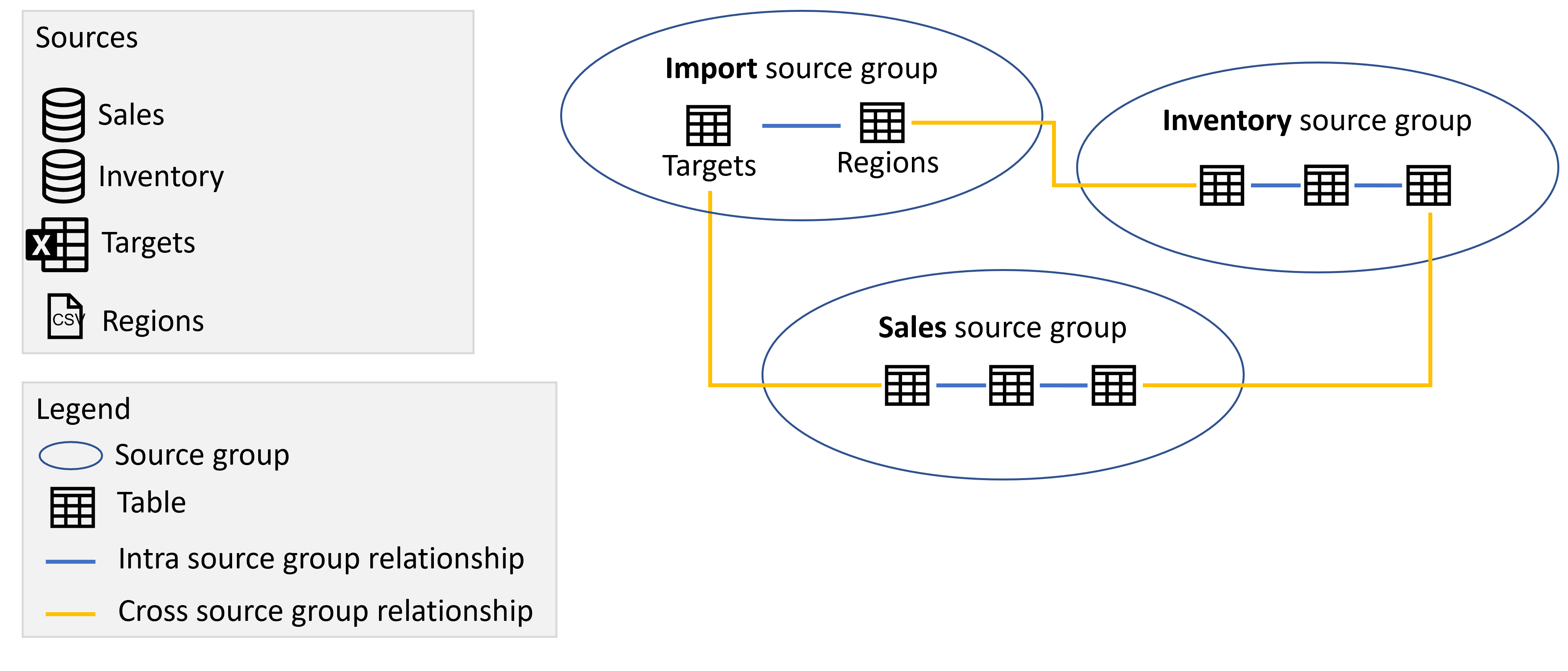
For eksempel tilføjede vi i det følgende billede tre krydskildegrupperelationer, der relaterer tabeller på tværs af de forskellige kildegrupper sammen:
Lokal og ekstern
Ethvert element i en kildegruppe, der er en DirectQuery-kildegruppe, er fjernt, medmindre du definerer elementet lokalt som en del af en udvidelse eller berigelse til DirectQuery-kilden, og det ikke er en del af den fjernkilde, såsom et mål eller en beregnet tabel. En beregnet tabel baseret på en tabel fra DirectQuery-kildegruppen tilhører "Import"-kildegruppen og er lokal. Ethvert element i kildegruppen "Import" er lokalt. For eksempel, hvis du definerer følgende mål i en sammensat model, der bruger en DirectQuery-forbindelse til Inventory-kilden, er målet lokalt:
[Average Inventory Count] = Average(Inventory[Inventory Count])
Beregningsgrupper, forespørgsel og målingsevaluering
Beregningsgrupper hjælper dig med at reducere antallet af redundante mål og gruppere fælles måludtryk sammen. Typiske anvendelsestilfælde er tidsintelligensberegninger, hvor du vil skifte fra faktiske til måned-til-dato, kvartal-til-dato eller år-til-dato beregninger. Når du arbejder med sammensatte modeller, er det vigtigt at være opmærksom på interaktionen mellem beregningsgrupper, og om en måling kun refererer til elementer fra en enkelt fjernkildegruppe. Hvis et mål kun refererer til elementer fra en enkelt fjernkildegruppe, og fjernmodellen definerer en beregningsgruppe, der påvirker målet, anvendes beregningsgruppen, selvom du definerer målet i fjernmodellen eller i den lokale model. Hvis et mål dog ikke udelukkende refererer til elementer fra en enkelt fjernkildegruppe, men henviser til elementer fra en fjernkildegruppe, hvor en fjernberegningsgruppe anvendes, kan målingsresultatet stadig blive påvirket af den fjernberegningsgruppe. Se følgende eksempel:
- Reseller Sales er en måling, der er defineret i fjernmodellen.
- Den fjernbaserede model indeholder en beregningsgruppe, der ændrer resultatet af Reseller Sales.
- Internet Sales er en måling, der er defineret i den lokale model.
- Total Sales er en måling, der er defineret i den lokale model, og har følgende definition:
[Total Sales] = [Internet Sales] + [Reseller Sales]
I dette scenarie påvirkes Internet Sales-målet ikke af den beregningsgruppe, der er defineret i fjernmodellen, fordi de ikke er en del af samme model. Dog kan beregningsgruppen ændre resultatet af Reseller Sales-målingen , fordi de er i samme model. Dette betyder, at de resultater, der returneres af målingen Total Sales , skal evalueres omhyggeligt. Forestil dig, at du bruger beregningsgruppen i fjernmodellen til at returnere resultater fra år til dato. Det resultat, der returneres af Reseller Sales , er nu en år-til-dato-værdi, mens resultatet, der returneres af Internet Sales , stadig er en faktisk værdi. Resultatet af Samlet salg er nu sandsynligvis uventet, da det føjer en faktisk værdi til et års-til-dato-resultat.
Sammensatte modeller på semantiske Power BI-modeller og Analysis Services
Ved at bruge sammensatte modeller med Power BI semantiske modeller og Analysis Services kan du bygge en sammensat model ved at bruge en DirectQuery-forbindelse til at forbinde til Power BI semantiske modeller, Azure Analysis Services (AAS) og SQL Server 2022 Analysis Services. Med en sammensat model kan du kombinere dataene i disse kilder med andre DirectQuery- og importerede data. Rapportforfattere, der ønsker at kombinere data fra deres virksomhedssemantiske model med andre data, de ejer, såsom et Excel-regneark, eller ønsker at personliggøre eller berige metadataene fra deres virksomhedssemantiske model, finder denne funktionalitet særligt nyttig.
Administration af sammensatte modeller på semantiske Power BI-modeller
For at oprette og bruge sammensatte modeller på Power BI semantiske modeller skal din lejer have følgende switches aktiveret:
- Tillad XMLA-slutpunkter og analysér i Excel med semantiske modeller i det lokale miljø. Hvis du deaktiverer denne switch, kan du ikke oprette en DirectQuery-forbindelse til en Power BI semantisk model.
- Brugerne kan arbejde med semantiske Power BI-modeller i Excel ved hjælp af en direkte forbindelse. Hvis du deaktiverer denne switch, kan brugerne ikke lave live-forbindelser til Power BI semantiske modeller, så knappen 'Lav ændringer i denne model ' er ikke tilgængelig.
- Tillad DirectQuery-forbindelse til semantiske Power BI-modeller. Se følgende afsnit for at få flere oplysninger om denne parameter og effekten af at deaktivere den.
Lejeradministratorer kan aktivere eller deaktivere DirectQuery-forbindelser til semantiske Power BI-modeller på administrationsportalen. Selvom denne indstilling er aktiveret som standard, forhindrer deaktivering af den brugere i at publicere nye sammensatte modeller på Power BI semantiske modeller til tjenesten.
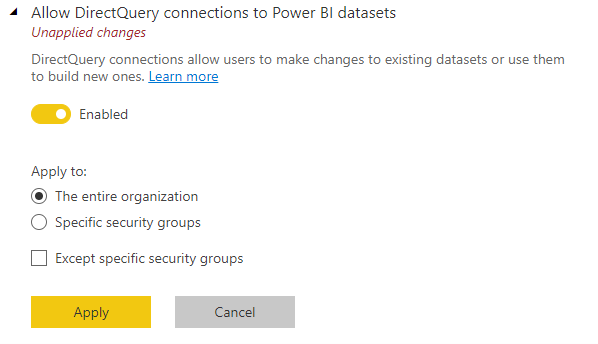
Eksisterende rapporter, der bruger en sammensat model på en Power BI semantisk model, fortsætter med at fungere. Brugere kan stadig oprette den sammensatte model i Power BI Desktop, men kan ikke publicere den til tjenesten. I stedet, når du opretter en DirectQuery-forbindelse til Power BI's semantiske model ved at vælge Foretag ændringer i denne model, ser du følgende advarselsmeddelelse:
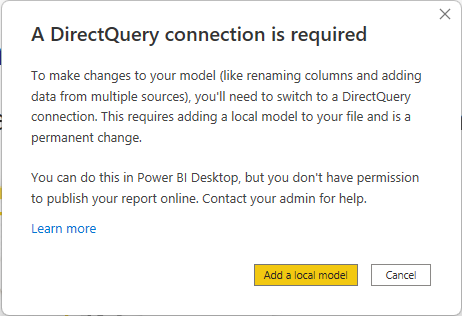
På denne måde kan du stadig udforske den semantiske model i dit lokale Power BI Desktop-miljø og oprette den sammensatte model. Du kan dog ikke offentliggøre rapporten til tjenesten. Når du offentliggør rapporten og modellen, ser du følgende fejlmeddelelse, og publiceringen blokeres:
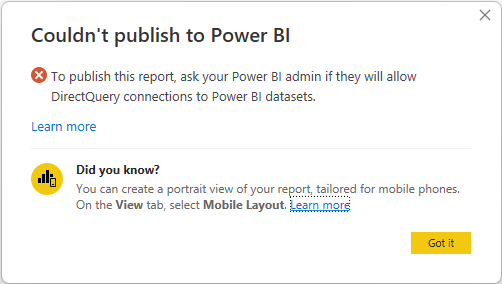
Direkte forbindelser til semantiske Power BI-modeller påvirkes ikke af kontakten, og det er heller ikke direkte eller DirectQuery-forbindelser til Analysis Services. Disse forbindelser fortsætter med at fungere uanset switch-indstillingen. Desuden fortsætter alle publicerede rapporter, der bruger en sammensat model på en Power BI semantisk model, med at fungere, selvom kontakten er slukket efter udgivelsen.
Oprettelse af en sammensat model på en semantisk model eller model
For at bygge en sammensat model på en Power BI semantisk model eller Analysis Services-model har din rapport brug for en lokal model. Du kan starte fra en direkte forbindelse og føje eller opgradere til en lokal model eller starte med en DirectQuery-forbindelse eller importerede data, hvilket automatisk opretter en lokal model i din rapport.
For at se, hvilke forbindelser der bruges i din model, tjek statuslinjen i nederste højre hjørne af Power BI Desktop. Hvis du kun har forbindelse til en Analysis Services-kilde, får du vist en meddelelse som følgende billede:

Hvis du er forbundet til en Power BI semantisk model, ser du en besked, der fortæller dig, hvilken Power BI semantisk model du er forbundet til:

Hvis du vil tilpasse metadataene for felter i din semantiske model med direkte forbindelse, skal du vælge Foretag ændringer af denne model på statuslinjen. Du kan også vælge knappen Foretag ændringer af denne model på båndet, som vist på følgende billede. I Rapportvisning findes knappen 'Foretag ændringer til denne model' under fanen Modellering. I Model View er knappen i Home-fanen.

Når du vælger knappen, vises en dialog, der bekræfter tilføjelsen af en lokal model. Vælg Tilføj en lokal model for at muliggøre oprettelse af nye kolonner eller ændring af metadata for felter fra Power BI semantiske modeller eller Analysis Services. Følgende billede viser dialogen.
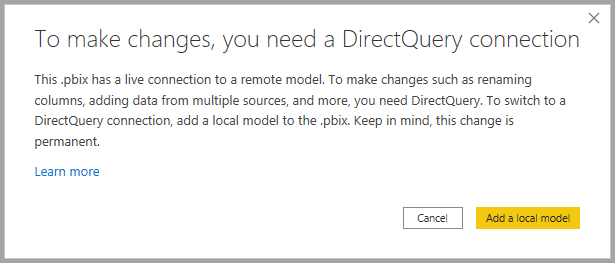
Når du har direkte forbindelse til en Analysis Services-kilde, er der ingen lokal model. Hvis du vil bruge DirectQuery til direkte forbundne kilder, f.eks. semantiske Power BI-modeller og Analysis Services, skal du føje en lokal model til din rapport. Når du publicerer en rapport med en lokal model til Power BI-tjeneste, publiceres der også en semantisk model for den pågældende lokale model.
Kæde
Semantiske modeller og de semantiske modeller, de er baseret på, danner en kæde. Denne proces, der kaldes sammenkædning, giver dig mulighed for at publicere en rapport og semantisk model baseret på andre semantiske Power BI-modeller.
Forestil dig f.eks., at din kollega publicerer en semantisk Power BI-model med navnet Salg og Budget baseret på en Analysis Services-model kaldet Salg og kombinerer den med et Excel-ark kaldet Budget. Derefter opretter og publicerer du en sammensat semantisk model og rapport, kaldet Sales and Budget Europe, ved hjælp af Sales and Budget Power BI semantic model med dine egne ændringer. Denne semantiske model er den tredje i kæden.
- Den første kæde er Sales Analysis Services-modellen.
- Den anden kæde er den sammensatte Power BI-model for salg og budget .
- Den tredje kæde er din sammensatte Power BI-model for salg og budget.
Følgende billede visualiserer denne sammenkædningsproces.
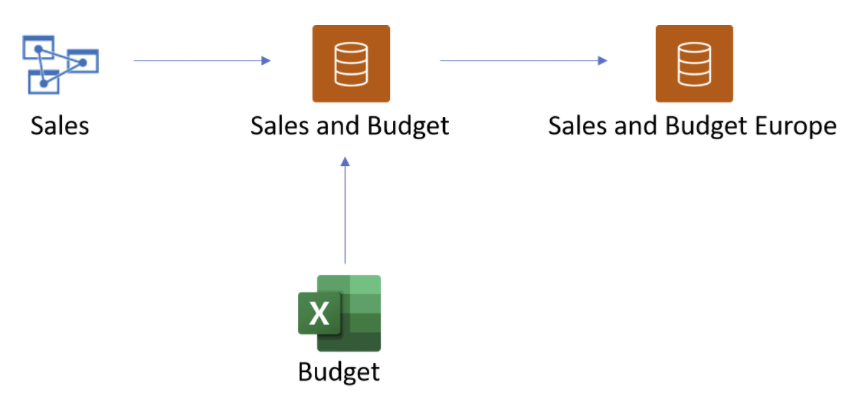
Længden af kæden på det foregående billede er tre, hvilket er den maksimale længde. Udvidelse ud over en kædelængde på tre understøttes ikke og resulterer i fejl.
Tilladelser og licenser
Brugere, der tilgår rapporter ved hjælp af en sammensat model, skal have korrekte tilladelser til alle semantiske modeller og modeller i kæden.
Ejeren af den sammensatte model har brug for byggetilladelse til de semantiske modeller, der bruges som kilder, så andre brugere kan få adgang til disse modeller på vegne af ejeren. Som følge heraf kræver oprettelse af forbindelsen til den sammensatte model i Power BI Desktop eller udarbejdelse af rapporten i Power BI Build tilladelser på de semantiske modeller, der bruges som kilder.
Brugere, der ser rapporter ved hjælp af den sammensatte model, har generelt brug for læsetilladelser på selve den sammensatte model og de semantiske modeller, der bruges som kilder. Oprettelsestilladelser kan være påkrævet, hvis rapporterne er i et Pro-arbejdsområde. Disse lejerparametre skal aktiveres for brugeren.
Følgende eksempel illustrerer de nødvendige tilladelser:
Sammensat model A (ejet af ejer A)
- Datakilde A1: Semantisk model B.
Ejer A skal have byggetilladelse på Semantisk Model B, for at brugerne kan se rapporten, der bruger Composite Model A.
- Datakilde A1: Semantisk model B.
Sammensat model C (ejet af ejer C)
- Datakilde C1: Semantisk model D
Ejer C skal have byggetilladelse på Semantisk Model D for at brugerne kan se rapporten, der bruger Composite Model C. - Datakilde C2: Sammensat model A
Ejer C skal have tilladelsen Opret for sammensat model A og læsetilladelse til semantisk model B.
- Datakilde C1: Semantisk model D
En bruger, der ser rapporter, der bruger Composite Model A , skal have læserettigheder til både Composite Model A og Semantic Model B, mens en bruger, der ser rapporter, der bruger Composite Model C , skal have læsetilladelser på Composite Model C, Semantic Model D, Composite Model A og Semantic Model B.
Bemærk
For mere information, se tilladelser krævet for sammensatte modeller på Power BI semantiske modeller og Analysis Services-modeller.
Hvis en semantisk model i kæden er i et Premium Per User-arbejdsområde, skal brugeren, der tilgår det, have en Premium Per User-licens. Hvis en semantisk model i kæden er i et Pro-arbejdsområde, skal brugeren, der tilgår det, have en Pro-licens. Hvis alle de semantiske modeller i kæden er på Premium-kapaciteter eller Fabric F64 eller større, kan en bruger få adgang til det ved at bruge en Gratis-licens.
Sikkerhedsadvarsel
Når du bruger Composite models på Power BI semantic models og Analysis Services models-funktionen , ser du en sikkerhedsadvarselsdialog, vist på det følgende billede.
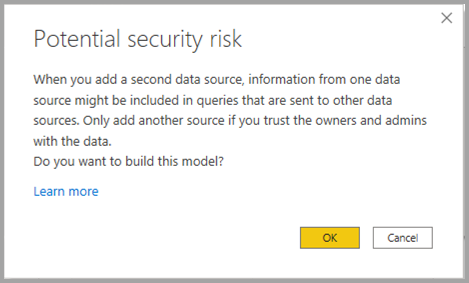
Data kan blive sendt fra én datakilde til en anden. Denne sikkerhedsadvarsel gælder for at kombinere DirectQuery- og importkilder i en datamodel. For mere information om denne adfærd, se brug af sammensatte modeller i Power BI Desktop.
Understøttede scenarier
Du kan bygge sammensatte modeller ved at bruge data fra Power BI semantiske modeller eller Analysis Services-modeller til at håndtere følgende scenarier:
- Forbind til data fra forskellige kilder: Import (såsom filer), Power BI semantiske modeller, Analysis Services-modeller
- Skab relationer mellem forskellige datakilder
- Skriv målinger, der bruger felter fra forskellige datakilder
- Opret nye kolonner til tabeller fra Power BI semantiske modeller eller Analysis Services-modeller
- Lav visuelle fremstillinger, der bruger kolonner fra forskellige datakilder
- Fjern en tabel fra din model ved at bruge feltlisten for at holde modellerne så præcise og slanke som muligt (hvis du forbinder til et perspektiv, kan du ikke fjerne tabeller fra modellen)
- Angiv, hvilke tabeller der skal indlæses, i stedet for at skulle indlæse alle, når du kun vil have et bestemt delmængde af tabeller. Se Indlæsning af et undersæt af tabeller senere i dette dokument.
- Specificér, om du skal tilføje tabeller, som du senere tilføjer til den semantiske model, efter du har lavet forbindelsen i din model.
Arbejde med en sammensat model, der er baseret på en semantisk model
Når du arbejder med DirectQuery til semantiske Power BI-modeller og Analysis Services, skal du overveje følgende oplysninger:
Hvis du opdaterer dine datakilder, og der er fejl med modstridende felt- eller tabelnavne, løser Power BI fejlene for dig.
Du kan ikke redigere, slette eller oprette nye relationer i den samme semantiske Power BI-model eller Analysis Services-kilde. Hvis du har redigeringsadgang til disse kilder, kan du i stedet foretage ændringerne direkte i datakilden.
Du kan ikke ændre datatyper for kolonner, der indlæses fra en semantisk Power BI-model eller Analysis Services-kilde. Hvis du har brug for at ændre datatypen, skal du enten ændre den i kilden eller bruge en beregnet kolonne.
For at bygge rapporter i Power BI-tjenesten på en sammensat model baseret på en anden semantisk model, skal du sætte alle legitimationsoplysninger.
Forbindelser til en SQL Server 2022 og nyere Analysis Services-server i det lokale miljø eller IAAS kræver en datagateway i det lokale miljø (standardtilstand).
Alle forbindelser til fjern Power BI semantiske modeller bruger single sign-on. Godkendelse med en tjenesteprincipal understøttes ikke i øjeblikket.
RLS-regler gælder for kilden, de er defineret på, men gælder ikke for andre semantiske modeller i modellen. RLS defineret i rapporten gælder ikke for fjernkilder, og RLS sat på fjernkilder gælder ikke for andre datakilder. Du kan heller ikke definere sikkerhed på rækkeniveau på en tabel, der er indlæst fra en fjernkilde, og sikkerhed på rækkeniveau, der er defineret på lokale tabeller, filtrerer ikke tabeller, der er indlæst fra en fjernkilde.
KPI'er, sikkerhed på rækkeniveau og oversættelser importeres ikke fra kilden.
Du får muligvis vist en uventet funktionsmåde, når du bruger et datohierarki. Du kan løse problemet ved at bruge en datokolonne i stedet. Efter at have tilføjet et datohierarki til et visuelt billede, kan du skifte til en datokolonne ved at vælge pilen nedad i feltnavnet og derefter vælge navnet på det felt i stedet for at bruge Datohierarki:
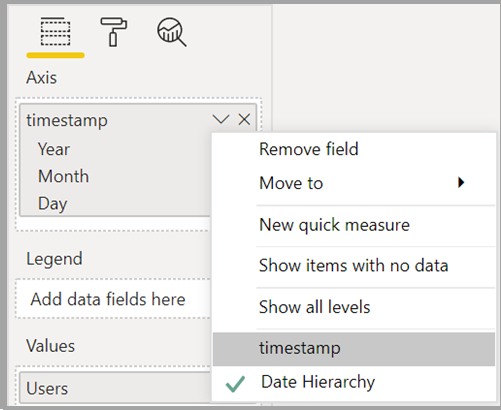
Du kan finde flere oplysninger om brug af datokolonner i forhold til datohierarkier under Anvend automatisk dato eller klokkeslæt i Power BI Desktop.
Den maksimale længde på en kæde af modeller er tre. Udvidelse ud over kædelængden på tre understøttes ikke og resulterer i fejl.
Du kan sætte et afskrækkelses-kædeflag på en model for at forhindre, at en kæde bliver oprettet eller udvidet. Du kan finde flere oplysninger under Administrer DirectQuery-forbindelser til en publiceret semantisk model.
Power Query viser ikke forbindelsen til en Power BI semantisk model eller Analysis Services-model.
Følgende begrænsninger gælder, når du arbejder med DirectQuery til semantiske Power BI-modeller og Analysis Services:
- Parametre for database- og servernavne er deaktiveret i øjeblikket.
- Definition af sikkerhed på rækkeniveau for tabeller fra en ekstern kilde understøttes ikke.
- Brug af en af følgende kilder som DirectQuery-kilde understøttes ikke:
- SSAS-tabelmodeller (SQL Server Analysis Services) før version 2022
- SSAS Flerdimensionelle modeller
- SAP HANA
- SAP Business Warehouse
- Semantiske modeller i realtid
- Semantiske eksempelmodeller
- Opdatering af Excel Online
- Data, der er importeret fra Excel- eller CSV-filer i tjenesten
- Forbrugsdata
- Semantiske modeller, der er gemt i "Mit arbejdsområde"
- Brug af Power BI Embedded med semantiske modeller, der indeholder en DirectQuery-forbindelse til en ekstern Analysis Services-model (Azure Analysis Services/SQL Server Analysis Services), understøttes ikke i øjeblikket.
- Publicering af en rapport på nettet ved at bruge funktionen 'publicer til web' understøttes ikke.
- Beregningsgrupper på eksterne kilder understøttes ikke med udefinerede forespørgselsresultater.
- Beregnede tabeller og beregnede kolonner, der refererer til en DirectQuery-tabel fra en datakilde med enkeltlogongodkendelse (SSO), understøttes i Power BI-tjeneste med en tildelt cloudforbindelse, der kan deles, og/eller detaljeret adgangskontrol.
- Hvis du omdøber et arbejdsområde efter at have sat DirectQuery-forbindelsen op, skal du opdatere datakilden i Power BI Desktop, for at rapporten kan fortsætte med at fungere.
- Automatisk sideopdatering understøttes kun i nogle scenarier, afhængigt af datakildetypen. Du kan få flere oplysninger under Automatisk sideopdatering i Power BI.
- At overtage en semantisk model, der bruger funktionen DirectQuery til andre semantiske modeller , understøttes ikke i øjeblikket.
- Som med enhver DirectQuery-datakilde vises hierarkier defineret i en Analysis Services-model eller Power BI-semantisk model ikke, når man forbinder til modellen eller den semantiske model i DirectQuery-tilstand ved brug af Excel.
Når du arbejder med DirectQuery til Power BI semantiske modeller og analysetjenester, bør du overveje følgende vejledning:
- Brug kolonner med lav kardinalitet i relationer på tværs af kildegrupper: Når du opretter en relation på tværs af to forskellige kildegrupper, skal de kolonner, der deltager i relationen (også kaldet joinkolonnerne), have lav kardinalitet, ideelt set 50.000 eller mindre. Denne overvejelse gælder for ikke-strengnøglekolonner. for kolonner med strengnøgler skal du se følgende overvejelse.
- Undgå at bruge store strengenøglekolonner i relationer på tværs af kildegrupper: Når du opretter en relation på tværs af kildegrupper, skal du undgå at bruge store strengkolonner som relationskolonner, især for kolonner med større kardinalitet. Når du skal bruge strengkolonner som relationskolonne, skal du beregne den forventede strenglængde for filteret ved at multiplicere kardinaliteten (C) med den gennemsnitlige længde af strengkolonnen (A). Sørg for, at den forventede strenglængde er under 250.000, så A ∗ C < 250.000.
Du kan finde flere overvejelser og vejledning i vejledning til sammensatte modeller.
Overvejelser i forbindelse med lejer
Du skal offentliggøre enhver model med en DirectQuery-forbindelse til en Power BI semantisk model eller til Analysis Services i samme lejere. Dette krav er især vigtigt, når man får adgang til en Power BI semantisk model eller en Analysis Services-model ved brug af B2B-gæsteidentiteter, som vist i det følgende diagram.
Overvej følgende diagram. De nummererede trin i diagrammet beskrives i følgende afsnit.
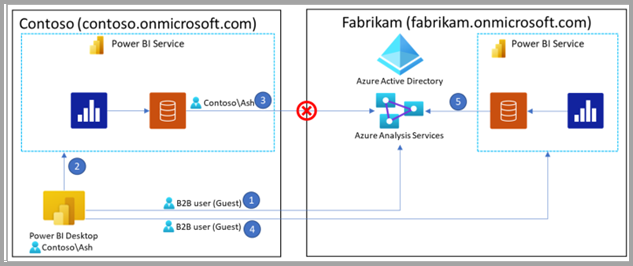
I diagrammet arbejder Ash sammen med Contoso og får adgang til data leveret af Fabrikam. Med Power BI Desktop opretter Ash en DirectQuery-forbindelse til en Analysis Services-model, som Fabrikam hoster.
For at autentificere bruger Ash en B2B gæstebrugeridentitet (trin 1 i diagrammet).
Hvis Ash publicerer rapporten til Contosos Power BI-tjeneste (trin 2), kan den semantiske model, der er offentliggjort i Contoso-lejeren, ikke godkende korrekt mod Fabrikams Analysis Services-model (trin 3). Derfor fungerer rapporten ikke.
I dette scenarie, da Fabrikam huser Analysis Services-modellen, skal du også offentliggøre rapporten i Fabrikams lejere. Efter en vellykket publikation i Fabrikams lejer (trin 4) kan den semantiske model få adgang til Analysis Services-modellen (trin 5), og rapporten fungerer korrekt.
Arbejde med sikkerhed på objektniveau
Når en sammensat model henter data fra en semantisk Power BI-model eller Analysis Services via DirectQuery, og denne kildemodel er sikret af sikkerhed på objektniveau, kan forbrugere af den sammensatte model opleve uventede resultater. I følgende afsnit forklares det, hvordan disse resultater kan opstå.
Objektniveau-sikkerhed (OLS) gør det muligt for modelforfattere at skjule objekter, der udgør modelskemaet (dvs. tabeller, kolonner, metadata osv.) for modelforbrugere (for eksempel en rapportbygger eller en sammensat modelforfatter). Når modelforfatteren konfigurerer OLS for et objekt, opretter den en rolle og fjerner derefter adgangen til objektet for brugere, der er tildelt den pågældende rolle. Set fra disse brugeres synspunkt findes det skjulte objekt ganske enkelt ikke.
OLS er defineret for og anvendt på kildemodellen. Du kan ikke definere det for en sammensat model bygget på kildemodellen.
Når du bygger en sammensat model oven på en OLS-beskyttet Power BI semantisk model eller Analysis Services-model via DirectQuery-forbindelse, kopierer du modelskemaet fra kildemodellen til den sammensatte model. Hvad du kopierer afhænger af, hvad du må se i kildemodellen ifølge OLS-reglerne, der gælder der. Du kopierer ikke dataene til den sammensatte model – du henter dem altid via DirectQuery fra kildemodellen, når det er nødvendigt. Med andre ord kommer datahentning altid tilbage til kildemodellen, hvor OLS-regler gælder.
Da den sammensatte model ikke er sikret af OLS-regler, er de objekter, som forbrugerne af den sammensatte model ser, dem, du kunne se i kildemodellen, snarere end dem, de selv måtte have adgang til. Denne situation kan resultere i følgende udfald:
- En person, der kigger på den sammensatte model, kan se objekter, der er skjult for dem i kildemodellen af OLS.
- Omvendt kan de muligvis IKKE se et objekt i den sammensatte model, som de kan se i kildemodellen, fordi dette objekt blev skjult for forfatteren af den sammensatte model af OLS-reglerne, der styrer adgangen til kildemodellen.
Et vigtigt punkt er, at på trods af det tilfælde, der er beskrevet i det første punkttegn, kan forbrugere af den sammensatte model aldrig se faktiske data, de ikke skal se, fordi dataene ikke er placeret i den sammensatte model. På grund af DirectQuery hentes den i stedet efter behov fra den semantiske kildemodel, hvor OLS blokerer uautoriseret adgang.
Med denne baggrund i tankerne skal du overveje følgende scenarie:
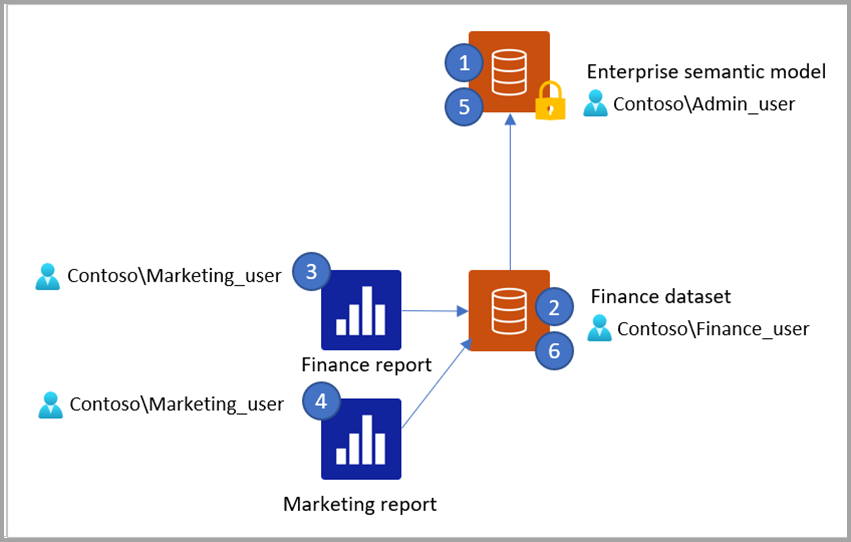
Admin_user offentliggør en virksomhedssemantisk model ved brug af en Power BI-semantisk model eller en Analysis Services-model, der har en Customer-tabel og en Territory-tabel. Admin_user publicerer den semantiske model til Power BI-tjeneste og angiver OLS-regler, der har følgende virkning:
- Økonomibrugere kan ikke se tabellen Kunde
- Marketingbrugere kan ikke se tabellen Territory
Finance_user publicerer en semantisk model kaldet "Finance semantisk model" og en rapport med navnet "Finance report", der opretter forbindelse via DirectQuery til den semantiske virksomhedsmodel, der er publiceret i trin 1. Økonomirapporten indeholder en visualisering, der bruger en kolonne fra tabellen Territory.
Marketing_user åbner finansrapporten. Den visualisering, der bruger tabellen Territory, vises, men returnerer en fejl, fordi DirectQuery forsøger at hente dataene fra kildemodellen ved hjælp af legitimationsoplysningerne for Marketing_user, som er blokeret fra at få vist tabellen Territory i henhold til de OLS-regler, der er angivet i den semantiske virksomhedsmodel.
Marketing_user opretter en ny rapport med navnet "Marketingrapport", der bruger den semantiske økonomimodel som kilde. Feltlisten viser de tabeller og kolonner, som Finance_user har adgang til. Derfor vises tabellen Territory på listen felter, men det er tabellen Customer ikke. Men når Marketing_user forsøger at oprette en visualisering, der bruger en kolonne fra tabellen Territory, returneres der en fejl, fordi DirectQuery på det tidspunkt forsøger at hente data fra kildemodellen ved hjælp af Marketing_user legitimationsoplysninger, og OLS-regler sparker og blokerer adgang igen. Det samme sker, når Marketing_user opretter en ny semantisk model og rapport, der opretter forbindelse til den semantiske økonomimodel med en DirectQuery-forbindelse – de får vist tabellen Territory på listen felter, da det er det, Finance_user kunne se, men når de forsøger at oprette en visualisering, der bruger tabellen, blokeres de af OLS-reglerne for den semantiske virksomhedsmodel.
Lad os nu sige, at Admin_user opdaterer OLS-reglerne for den semantiske virksomhedsmodel for at forhindre Finance i at se tabellen Territory.
De opdaterede OLS-regler afspejles kun i den semantiske økonomimodel, når den opdateres. Når Finance_user opdaterer den semantiske økonomimodel, vises tabellen Territory derfor ikke længere på listen felter, og den visualisering i økonomirapporten, der bruger en kolonne fra tabellen Territory, returnerer en fejl for Finance_user, fordi de nu ikke har adgang til tabellen Territory.
Sådan opsummerer du:
- Forbrugere af en sammensat model kan se resultaterne af de OLS-regler, der var gældende for forfatteren af den sammensatte model, da de oprettede modellen. Når der oprettes en ny rapport baseret på den sammensatte model, viser feltlisten de tabeller, som forfatteren af den sammensatte model havde adgang til, da modellen blev oprettet, uanset hvad den aktuelle bruger har adgang til i kildemodellen.
- Du kan ikke definere OLS-regler på selve den sammensatte model.
- En forbruger af en sammensat model ser aldrig faktiske data, de ikke burde se, fordi relevante OLS-regler på kildemodellen blokerer dem, når DirectQuery forsøger at hente dataene ved hjælp af deres legitimationsoplysninger.
- Hvis kildemodellen opdaterer sine OLS-regler, påvirker disse ændringer kun den sammensatte model, når den opdateres.
Indlæser et undersæt af tabeller fra en semantisk Power BI-model eller Analysis Services-model
Når du forbinder til en Power BI semantisk model eller Analysis Services-model ved hjælp af en DirectQuery-forbindelse, vælger du, hvilke tabeller du vil forbinde til. Du kan også vælge automatisk at tilføje en tabel, der kan blive føjet til den semantiske model eller model, når du har oprettet forbindelse til din model. Når du opretter forbindelse til et perspektiv, indeholder din model alle tabeller i den semantiske model, og alle tabeller, der ikke er inkluderet i perspektivet, skjules. Desuden tilføjes alle tabeller, der kan blive føjet til perspektivet, automatisk. I menuen Indstillinger kan du vælge automatisk at oprette forbindelse til tabeller, der føjes til den semantiske model, når du først har konfigureret forbindelsen.
Denne dialogboks vises ikke for direkte forbindelser.
Bemærk
Denne dialog vises kun, hvis du tilføjer en DirectQuery-forbindelse til en Power BI semantisk model eller Analysis Services-model til en eksisterende model. Du kan også åbne denne dialog ved at ændre DirectQuery-forbindelsen til Power BI semantic model eller Analysis Services-modellen i Data source-indstillingerne, efter du har oprettet den.
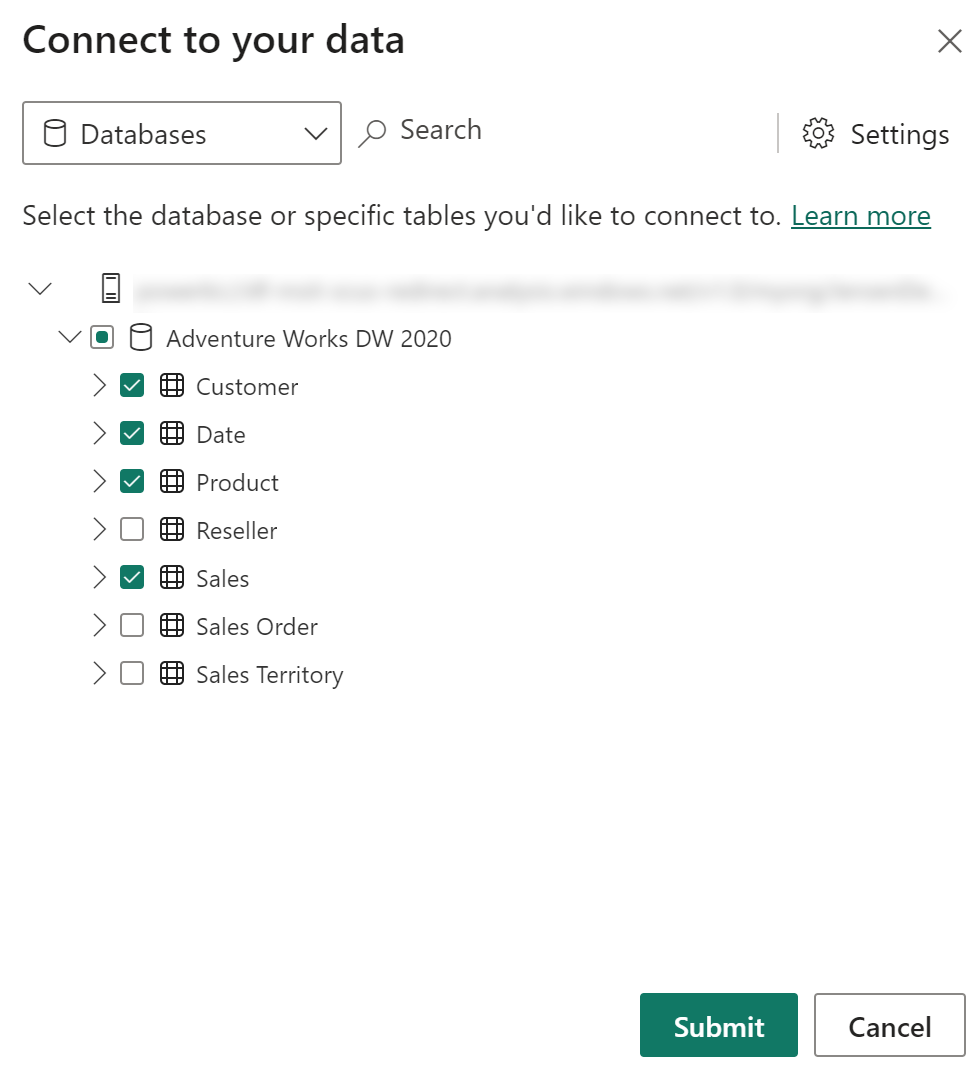
Konfiguration af deduplikeringsregler
Du kan angive deduplikeringsregler for at holde målings- og tabelnavne entydige i en sammensat model ved hjælp af indstillingen Indstillinger i den dialogboks, der blev vist tidligere:
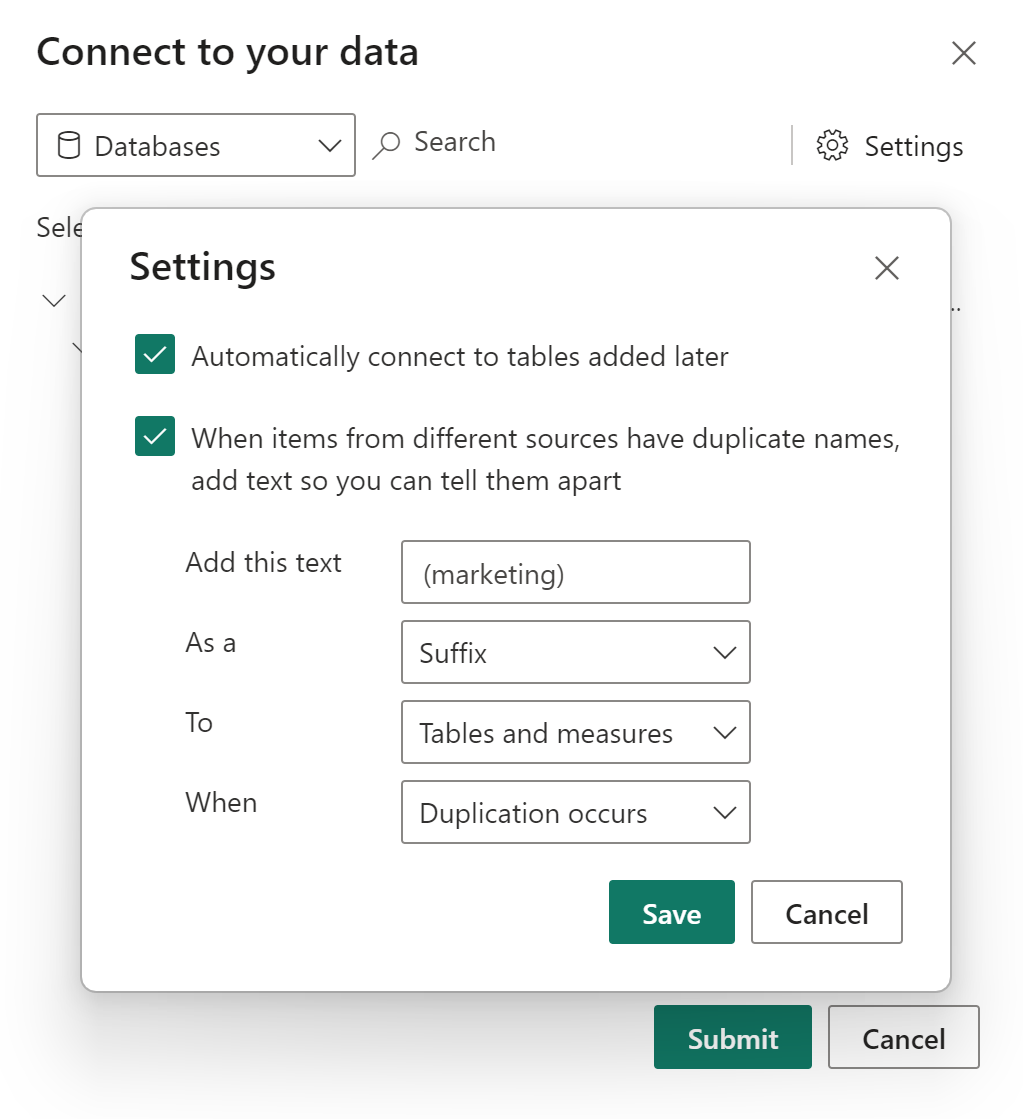
I det forrige eksempel tilføjede vi '(marketing)' som suffiks til enhver tabel eller målnavn, der er i konflikt med en anden kilde i den sammensatte model. Du kan:
- Indtast en tekst for at tilføje til navnet på modstridende tabeller eller mål.
- Angiv, om du ønsker, at teksten skal tilføjes til tabellen eller målnavnet som præfiks eller suffiks.
- Anvend deduplikeringsreglen på tabeller, målinger eller begge dele.
- Vælg kun at anvende deduplikeringsreglen, når der opstår en navnekonflikt, eller anvend den hele tiden. Standarden er kun at anvende reglen, når der sker duplikering. I vores eksempel får enhver tabel eller måling fra marketingkilden, der ikke har en dublet i salgskilden, ikke navneændring.
Efter du har lavet forbindelserne og sat deduplikationsreglen op, viser din feltliste både 'Kunde' og 'Kunde (marketing)' i henhold til deduplikeringsreglen i vores eksempel:
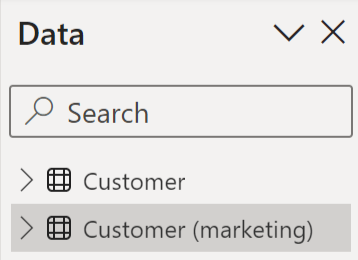
Hvis du ikke specificerer en deduplikeringsregel, eller de deduplikeringsregler, du angiver, ikke løser navnekonflikten, anvendes de standard deduplikeringsregler stadig. Standardafduplikeringsreglerne føjer et tal til navnet på det modstridende element. Hvis der er en navnekonflikt i 'Customer'-tabellen, omdøbes en af 'Customer'-tabellerne til 'Customer 2'.
ÆNDRINGER I XMLA og sammensatte modeller
Når du ændrer en semantisk model ved hjælp af XMLA, skal du opdatere ChangedProperties og PBI_RemovedChildren samlinger for det ændrede objekt, så de inkluderer eventuelle ændrede eller fjernede egenskaber. Hvis du ikke opdaterer disse samlinger, kan Power BI-modelleringsværktøjer overskrive dine ændringer næste gang skemaet synkroniseres med datakilden.
For mere information om semantiske modelobjekt-lineage-tags, se lineage tags for Power BI semantiske modeller.
Overvejelser og begrænsninger
Sammensatte modeller præsenterer et par overvejelser og begrænsninger:
Mixed-mode forbindelser – Når du bruger en mixed mode-forbindelse, der indeholder online data (såsom en Power BI semantisk model) og en on-premises semantisk model (såsom en Excel-arbejdsbog), skal du etablere gateway mapping for at visualiseringer kan vises korrekt.
I øjeblikket understøttes trinvis opdatering kun for sammensatte modeller, der opretter forbindelse til sql-, Oracle- og Teradata-datakilder.
Følgende Live Connect-tabelkilder kan ikke bruges sammen med sammensatte modeller:
- SAP HANA
- SAP Business Warehouse
- SQL Server Analysis Services tidligere end version 2022
- Forbrugsdata (Mit arbejdsområde)
Brug af semantiske streamingmodeller i sammensatte modeller understøttes ikke.
De eksisterende begrænsninger for DirectQuery gælder stadig, når du bruger sammensatte modeller. Mange af disse begrænsninger er nu pr. tabel, afhængigt af tabellens lagringstilstand. En beregnet kolonne i en importtabel kan f.eks. referere til andre tabeller, der ikke er i DirectQuery, men en beregnet kolonne i en DirectQuery-tabel kan stadig kun referere til kolonner i den samme tabel. Der gælder andre begrænsninger for modellen som helhed, hvis nogen af tabellerne i modellen er DirectQuery. Funktionen QuickInsights er f.eks. ikke tilgængelig for en model, hvis nogen af tabellerne i den har lagringstilstanden DirectQuery.
Hvis du bruger række-niveau sikkerhed i en sammensat model med nogle af tabellerne i DirectQuery-tilstand, skal du opdatere modellen for at anvende nye opdateringer fra DirectQuery-tabellerne. For eksempel, hvis en Bruger-tabel i DirectQuery-tilstand har nye brugerposter ved kilden, inkluderes de nye poster først efter næste modelopdatering. Power BI-tjenesten cachelagrer forespørgslen Brugere for at forbedre ydeevnen og genindlæser ikke dataene fra kilden før den næste manuelle eller planlagte opdatering.
Relateret indhold
Du kan finde flere oplysninger om sammensatte modeller og DirectQuery i følgende artikler: