Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Klyngeværdier opretter automatisk grupper med lignende værdier ved hjælp af en fuzzy matching-algoritme og kortlægger derefter hver kolonnes værdi til den bedst matchede gruppe. Denne transformation er nyttig, når du arbejder med data, der har mange forskellige variationer af samme værdi, og du skal kombinere værdier i konsistente grupper.
Overvej en eksempeltabel med en id-kolonne , der indeholder et sæt ID'er, og en Person-kolonne , der indeholder forskellige stavede og store bogstavede versioner af navnene Miguel, Mike, William og Bill.
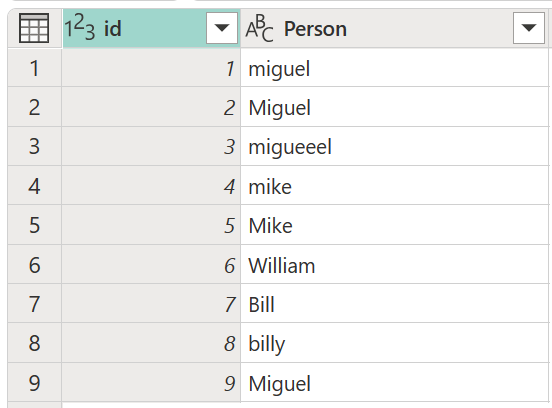
I dette eksempel leder du efter et resultat med en ny kolonne, der viser de rigtige grupper af værdier fra Person-kolonnen og ikke alle de forskellige variationer af de samme ord.
Notat
Funktionen Cluster values er kun tilgængelig for Power Query Online.
Opret en Klynge-kolonne
For at klynge værdier skal du først vælge kolonnen Person , gå til fanen Tilføj kolonne i båndet, og derefter vælge Klyngeværdier-muligheden .
![]()
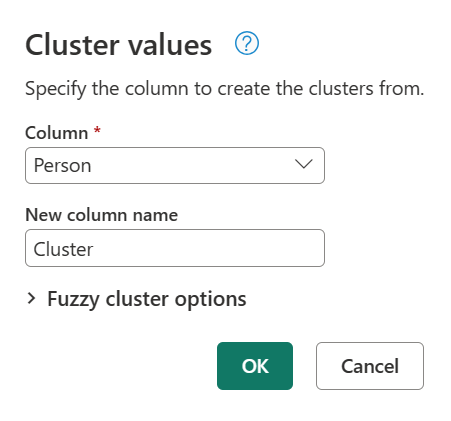
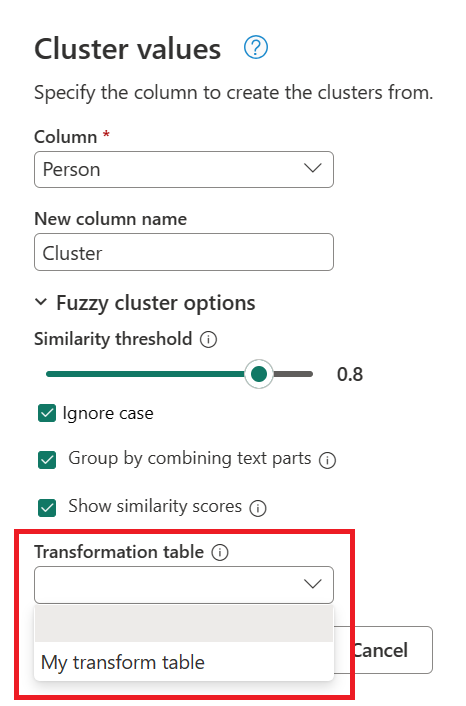
I dialogboksen Klyngeværdier bekræft den kolonne, du vil bruge til at oprette klyngerne fra, og indtast det nye navn på kolonnen. I dette tilfælde skal denne nye kolonne navngives Klynge.
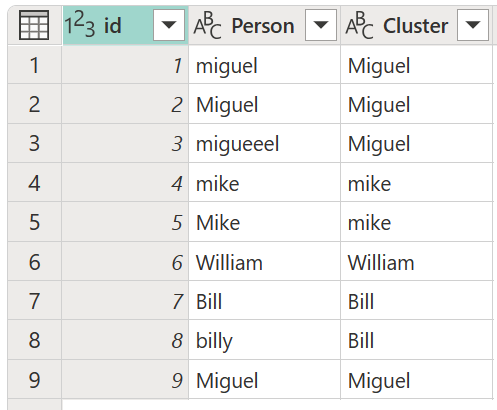
Resultatet af denne operation vises i det følgende billede.
Notat
For hver klynge af værdier vælger Power Query den hyppigste instans fra den valgte kolonne som den "kanoniske" instans. Hvis flere tilfælde forekommer med samme hyppighed, vælger Power Query den første.
Brug af fuzzy cluster-indstillingerne
Følgende muligheder er tilgængelige for at samle værdier i en ny kolonne:
- Lighedstærskel (valgfrit): Denne mulighed angiver, hvor ens to værdier skal være for at blive grupperet sammen. Minimumsindstillingen nul (0) får alle værdier til at blive grupperet sammen. Maksimumsindstillingen 1 tillader kun, at værdier, der matcher præcist, kan grupperes sammen. Standardindstillingen er 0,8.
- Ignorer sag: Når tekststrenge sammenlignes, ignoreres kasus. Denne mulighed er aktiveret som standard.
- Gruppering ved at kombinere tekstdele: Algoritmen forsøger at kombinere tekstdele (såsom at kombinere Micro og soft i Microsoft) for at gruppere værdier.
- Vis lighedsscorer: Viser lighedsscorer mellem inputværdierne og de beregnede repræsentative værdier efter fuzzy clustering.
- Transformationstabel (valgfrit): Du kan vælge en transformationstabel, der mapper værdier (såsom mapping MSFT til Microsoft) for at gruppere dem.
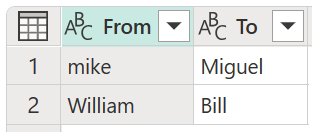
I dette eksempel bruges en ny transformationstabel med navnet My transformtabel til at demonstrere, hvordan værdier kan mappes. Denne transformationstabel har to kolonner:
- Fra: Tekststrengen, du skal kigge efter i din tabel.
- Til: Tekststrengen, der skal bruges til at erstatte tekststrengen i From-kolonnen .
Vigtigt!
Det er vigtigt, at transformationstabellen har de samme kolonner og kolonnenavne som vist på det forrige billede (de skal hedde "From" og "To"), ellers vil Power Query ikke genkende denne tabel som en transformationstabel, og der vil ikke finde nogen transformation.
Ved at bruge den tidligere oprettede forespørgsel dobbeltklikker du på trinnet Clustered values, og udvider derefter Fuzzy cluster-indstillingerne i dialogboksen Cluster values. Under Fuzzy cluster-indstillinger kan du aktivere muligheden Vis lighedsscores . For transformationstabellen (valgfri) vælges den forespørgsel, der har transformationstabellen.
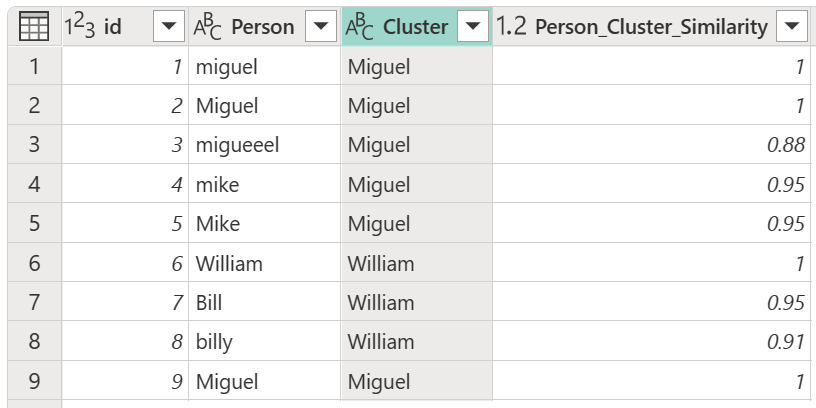
Efter at have valgt din transformationstabel og aktiveret muligheden Vis lighedsscorer, vælg OK. Resultatet af denne operation giver dig en tabel, der indeholder samme id- og Person-kolonner som den oprindelige tabel, men også indeholder to nye kolonner kaldet Cluster og Person_Cluster_Similarity. Kolonnen Cluster indeholder de korrekt stavede og store versioner af navnene Miguel for versioner af Miguel og Mike, og William for versioner af Bill, Billy og William. Kolonnen Person_Cluster_Similarity indeholder lighedsscorerne for hvert af navnene.
Transformationstabellens principper
Du vil måske bemærke, at transformationstabellen i det forrige afsnit syntes at indikere, at instanser af Mike er ændret til Miguel, og instanser af William er ændret til Bill. Men i den resulterende tabel blev forekomsterne af Bill og "billy" i stedet ændret til William. I transformationstabellen er transformationstabellen ikke en direkte Fra til Til-sti , men symmetrisk under klyngedannelse, hvilket betyder, at "mike" svarer til "Miguel" og omvendt. Resultatet af ækvivalenterne givet i transformationstabellen afhænger af følgende regler:
- Hvis der er flertal af identiske værdier, har disse værdier forrang frem for ikke-identiske værdier.
- Hvis der ikke er flertal af værdier, har den værdi, der vises først, forrang.
For eksempel udgør versioner af Miguel (både "miguel" og Miguel) i kolonnen Person størstedelen af forekomsterne af navnene Miguel og Mike i den oprindelige tabel, der bruges i denne artikel. Derudover udgør navnet Miguel med initialer hovedhoveder størstedelen af navnet Miguel. Så ved at associere Miguel og dets afledte og Mike og dets afledte i transformationstabellen bruges navnet Miguel i Cluster-kolonnen .
Men for navnene William, Bill og "billy" er der ikke flertal af værdier, da alle tre er unikke. Da William optræder først, bruges William i klyngekolonnen . Hvis "billy" først var optrådt i tabellen, ville "billy" blive brugt i kolonnen Cluster . Desuden, fordi der ikke er flertal af værdier, bruges kasuset brugt af de enkelte navne. Det vil sige, hvis William er først, bruges William med stort "W" som resultatværdi; Hvis "Billy" er først, bruges "Billy" med lille "B".