Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Power Query-funktioner som fuzzy-fletning, klyngeværdier og fuzzy-gruppering bruger de samme mekanismer til at fungere som fuzzy-matchning.
Denne artikel gennemgår mange scenarier, der viser, hvordan du kan drage fordel af de muligheder, som fuzzy matching har, med det formål at gøre "fuzzy" tydeligt.
Notat
Selvom indstillingen klyngeværdier kun er tilgængelig i Power Query Online, gælder de mekanismer, der vises i dette afsnit, også for fuzzy-fletning og fuzzy-gruppering.
Juster lighedsgrænsen
Det bedste scenarie til anvendelse af fuzzy match-algoritmen er, når alle tekststrenge i en kolonne kun indeholder de strenge, der skal sammenlignes, og ingen ekstra komponenter. For eksempel giver sammenligning Apples med 4ppl3s højere lighedsscore end at sammenligne Apples med My favorite fruit, by far, is Apples. I simply love them!.
Fordi ordet Apples i den anden streng kun er en lille del af hele tekststrengen, giver denne sammenligning en lavere lighedsscore.
Følgende datasæt består f.eks. af svar fra en undersøgelse, der kun havde ét spørgsmål – "Hvad er din yndlingsfrugt?"
| Frugt |
|---|
| Blåbær |
| Blå bær er simpelthen de bedste |
| Jordbær |
| Jordbær = <3 |
| Æbler |
| »Sples |
| 4ppl3s |
| Bananer |
| Yndlingsfrugt er bananer |
| Banas |
| Min yndlingsfrugt er langt æbler. Jeg elsker dem simpelthen! |
Undersøgelsen gav en enkelt tekstboks til at indtaste værdien og havde ingen validering.
Nu har du til opgave at gruppere værdierne. Hvis du vil udføre denne opgave, skal du indlæse den forrige tabel med frugter i Power-forespørgsel, vælge kolonnen og derefter vælge indstillingen Klyngeværdier under fanen Tilføj kolonne på båndet.
![]()
Dialogboksen Klyngeværdier vises, hvor du kan angive navnet på den nye kolonne. Navngiv denne nye kolonne Klynge, og vælg OK.
Som standard bruger Power Query en lighedsgrænse på 0,8 (eller 80%). Minimumsværdien på 0,00 får alle værdier med et hvilket som helst lighedsniveau til at matche hinanden, og maksimumværdien på 1,00 tillader kun nøjagtige matches. Et uklart "eksakt match" kan ignorere forskelle som store og små bogstaver, ordstilling og tegnsætning. Resultatet af den forrige handling giver følgende tabel med en ny kolonne Cluster .
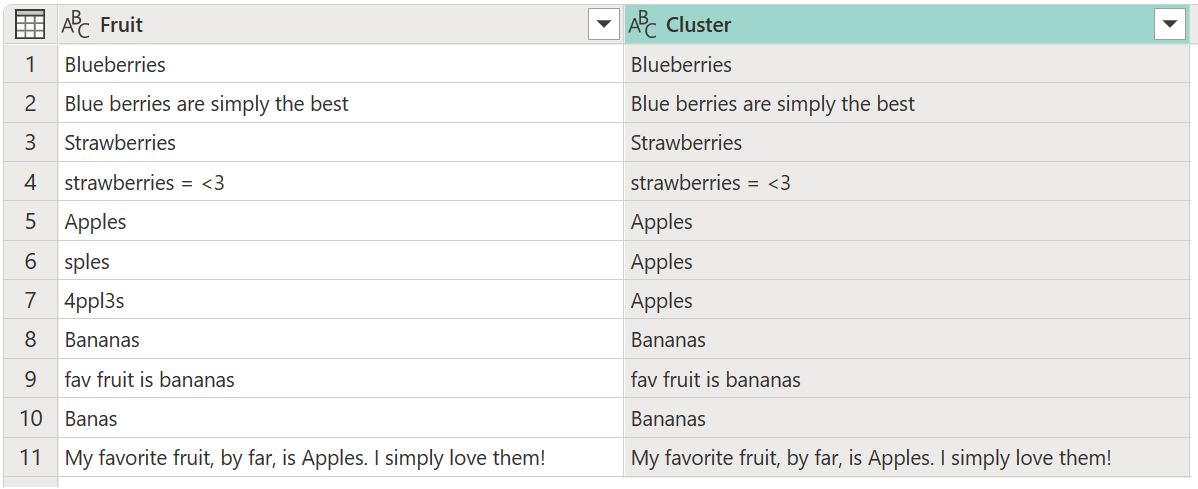
Mens klyngedannelsen er udført, giver den dig ikke de forventede resultater for alle rækkerne. Række nummer to (2) har stadig værdien Blue berries are simply the best, men den skal grupperes til Blueberries, og der sker noget lignende med tekststrengene Strawberries = <3, fav fruit is bananas, og My favorite fruit, by far, is Apples. I simply love them!.
Hvis du vil finde ud af, hvad der forårsager denne klyngedannelse, skal du dobbeltklikke på Klyngeværdier i panelet Anvendte trin for at få dialogboksen Klyngeværdier tilbage. I denne dialog skal du udvide Fuzzy-klyngeindstillinger. Aktivér indstillingen Vis lighedsscorer, og vælg derefter OK.
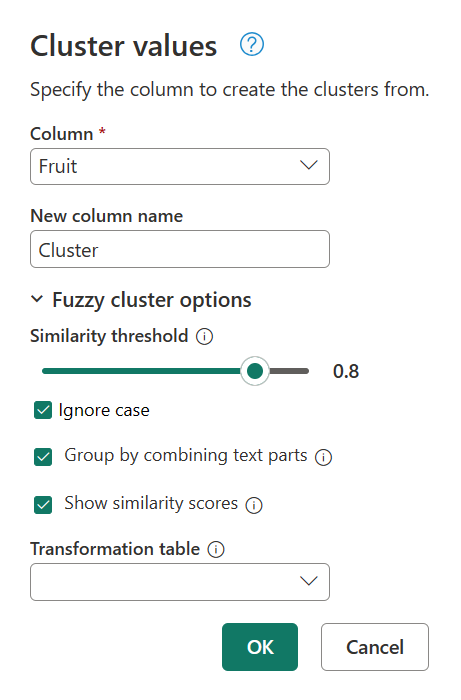
Hvis du aktiverer indstillingen Vis lighedsscorer , oprettes der en ny kolonne i tabellen. Denne kolonne viser dig den nøjagtige lighedsscore mellem den definerede klynge og den oprindelige værdi.

Ved nærmere eftersyn kunne Power Query ikke finde andre værdier i lighedsgrænsen for tekststrengene Blue berries are simply the best,Strawberries = <3, fav fruit is bananas, og My favorite fruit, by far, is Apples. I simply love them!.
Gå tilbage til dialogboksen Klyngeværdier en gang til ved at dobbeltklikke på Klyngeværdier i panelet Anvendte trin . Rediger lighedsgrænsen fra 0,8 til 0,6, og vælg derefter OK.
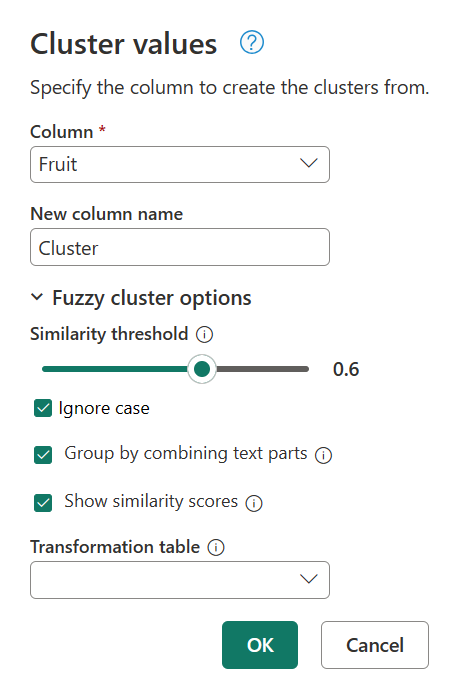
Denne ændring bringer dig tættere på det resultat, du leder efter, bortset fra tekststrengen My favorite fruit, by far, is Apples. I simply love them!. Da du ændrede værdien for lighedstærsklen fra 0,8 til 0,6, kunne Power Query nu bruge værdierne med en lighedsscore, der starter fra 0,6 helt op til 1.

Notat
Power Query bruger altid den værdi, der er tættest på tærsklen, til at definere klyngerne. Tærsklen definerer den nedre grænse for den lighedsscore, der er acceptabel for at tildele værdien til en klynge.
Du kan prøve igen ved at ændre lighedsscoren fra 0,6 til et lavere tal, indtil du får de resultater, du leder efter. I dette tilfælde skal du ændre lighedsscoren til 0,5. Denne ændring giver det nøjagtige resultat, du forventer, med den tekststreng My favorite fruit, by far, is Apples. I simply love them! , der nu er tildelt klyngen Apples.

Notat
I øjeblikket er det kun funktionen Klyngeværdier i Power Query Online, der indeholder en ny kolonne med lighedsscoren.
Særlige overvejelser i forbindelse med transformationstabel
Transformationstabellen hjælper dig med at knytte værdier fra kolonnen til nye værdier, før du udfører algoritmen til fuzzy-matchning.
Nogle eksempler på, hvordan transformationstabellen kan bruges:
- Transformationstabel i klyngeværdier
- Transformationstabel i fuzzy-fletforespørgsler
- Transformationstabel i gruppe efter
Vigtigt!
Når transformationstabellen bruges, er den maksimale lighedsscore for værdierne fra transformationstabellen 0,95. Denne bevidste straf på 0,05 er på plads for at skelne, at den oprindelige værdi fra en sådan kolonne ikke er lig med de værdier, den blev sammenlignet med, siden en transformation fandt sted.
I scenarier, hvor du først vil tilknytte dine værdier og derefter udføre fuzzy-matchningen uden sanktionen 0,05, anbefaler vi, at du erstatter værdierne fra kolonnen og derefter udfører fuzzy-matchningen.