Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie ein benutzerdefiniertes Deep Learning-Modell mit Transferlernen, einem vortrainierten TensorFlow-Modell und der ML.NET Bildklassifizierungs-API trainieren, um Bilder konkreter Oberflächen als zerbrochen oder ungecrackt zu klassifizieren.
In diesem Tutorial erfahren Sie, wie:
- Verstehen des Problems
- Informationen zur ML.NET Bildklassifizierungs-API
- Grundlegendes zum vortrainierten Modell
- Verwenden von Transferlernen zum Trainieren eines benutzerdefinierten TensorFlow-Bildklassifizierungsmodells
- Klassifizieren von Bildern mit dem benutzerdefinierten Modell
Voraussetzungen
Verstehen des Problems
Die Bildklassifizierung ist ein Computervisionsproblem. Die Bildklassifizierung verwendet ein Bild als Eingabe und kategorisiert es in eine vorgeschriebene Klasse. Bildklassifizierungsmodelle werden häufig mithilfe von Deep Learning und neuralen Netzwerken trainiert. Weitere Informationen finden Sie unter Deep Learning im Vergleich zum maschinellen Lernen.
Einige Szenarien, in denen die Bildklassifizierung nützlich ist, umfassen:
- Gesichtserkennung
- Emotionserkennung
- Medizinische Diagnose
- Orientierungspunkterkennung
In diesem Lernprogramm wird ein benutzerdefiniertes Bildklassifizierungsmodell trainiert, um automatisierte visuelle Inspektionen von Brückendecks durchzuführen, um Strukturen zu identifizieren, die durch Risse beschädigt sind.
ML.NET Bildklassifizierungs-API
ML.NET bietet verschiedene Möglichkeiten zum Ausführen der Bildklassifizierung. In diesem Tutorial wird Transfer-Lernen mithilfe der Bildklassifizierungs-API verwendet. Die Bildklassifizierungs-API verwendet TensorFlow.NET, einer Bibliothek mit niedriger Ebene, die C#-Bindungen für die TensorFlow-C++-API bereitstellt.
Was ist Übertragungslernen?
Transfer Learning wendet Wissen an, das von der Lösung eines Problems auf ein anderes verwandtes Problem gewonnen wurde.
Für das Training eines deep Learning-Modells von Grund auf müssen mehrere Parameter, eine große Menge bezeichneter Schulungsdaten und eine große Menge an Rechenressourcen (Hunderte von GPU-Stunden) festgelegt werden. Die Verwendung eines vortrainierten Modells und von Transferlernen ermöglicht es Ihnen, den Schulungsprozess abzukürzen.
Schulungsprozess
Die Bildklassifizierungs-API startet den Schulungsprozess, indem ein vortrainiertes TensorFlow-Modell geladen wird. Der Schulungsvorgang besteht aus zwei Schritten:
- Engpassphase.
- Schulungsphase.
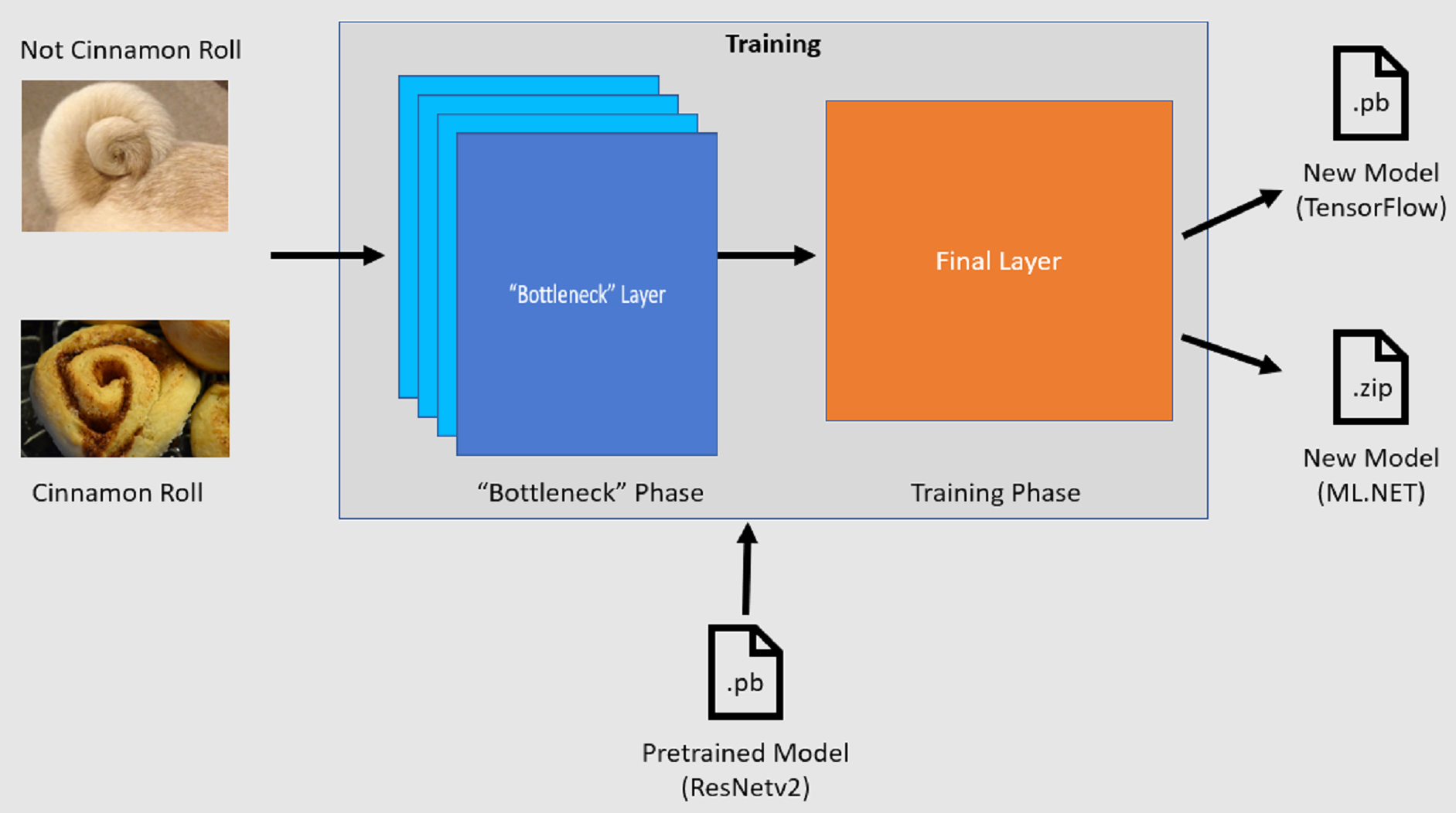
Engpassphase
Während der Engpassphase wird der Satz von Trainingsbildern geladen, und die Pixelwerte werden als Eingabe oder Merkmale für die eingefrorenen Schichten des vortrainierten Modells verwendet. Die fixierten Schichten enthalten alle Schichten im neuralen Netzwerk bis zur vorletzten Ebene, die informell als Engpassebene bezeichnet wird. Diese Schichten werden als "eingefroren" bezeichnet, da kein Training in diesen Schichten stattfindet und Vorgänge durchgeschleust werden. Auf diesen eingefrorenen Ebenen werden die Muster auf niedrigerer Ebene berechnet, die einem Modell helfen, zwischen den verschiedenen Klassen zu unterscheiden. Je größer die Anzahl der Ebenen ist, desto rechenintensiver ist dieser Schritt. Da dies eine einmalige Berechnung ist, können die Ergebnisse glücklicherweise zwischengespeichert und später beim Experimentieren mit verschiedenen Parametern verwendet werden.
Schulungsphase
Sobald die Ausgabewerte aus der Engpassphase berechnet wurden, werden sie als Eingabe verwendet, um die endgültige Ebene des Modells neu zu trainieren. Dieser Prozess ist iterativ und wird für die Anzahl der durch Modellparameter angegebenen Male ausgeführt. Während jeder Ausführung werden der Verlust und die Genauigkeit ausgewertet. Anschließend werden die entsprechenden Anpassungen vorgenommen, um das Modell mit dem Ziel zu verbessern, den Verlust zu minimieren und die Genauigkeit zu maximieren. Nach Abschluss der Schulung werden zwei Modellformate ausgegeben. Eine davon ist die .pb Version des Modells, und die andere ist die .zip ML.NET serialisierte Version des Modells. Wenn Sie in Umgebungen arbeiten, die von ML.NET unterstützt werden, empfiehlt es sich, die .zip Version des Modells zu verwenden. In Umgebungen, in denen ML.NET nicht unterstützt wird, haben Sie jedoch die Möglichkeit, die .pb Version zu verwenden.
Grundlegendes zum vortrainierten Modell
Das in diesem Lernprogramm verwendete vortrainierte Modell ist die 101-Layer-Variante des Restnetzwerkmodells (ResNet) v2. Das ursprüngliche Modell wird trainiert, Bilder in tausend Kategorien zu klassifizieren. Das Modell verwendet als Eingabe ein Bild der Größe 224 x 224 und gibt die Klassenwahrscheinlichkeiten für jede der Klassen aus, auf die es trainiert wird. Teil dieses Modells wird verwendet, um ein neues Modell mithilfe von benutzerdefinierten Bildern zu trainieren, um Vorhersagen zwischen zwei Klassen zu erstellen.
Erstellen einer Konsolenanwendung
Nachdem Sie nun ein allgemeines Verständnis für das Übertragen des Lernens und der Imageklassifizierungs-API haben, ist es an der Zeit, die Anwendung zu erstellen.
Erstellen Sie eine C# -Konsolenanwendung namens "DeepLearning_ImageClassification_Binary". Klicken Sie auf die Schaltfläche Weiter .
Wählen Sie .NET 8 als zu verwendende Framework und dann "Erstellen" aus.
Installieren Sie das Microsoft.ML NuGet-Paket:
Hinweis
In diesem Beispiel wird die neueste stabile Version der erwähnten NuGet-Pakete verwendet, sofern nichts anderes angegeben ist.
- Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf Ihr Projekt, und wählen Sie "NuGet-Pakete verwalten" aus.
- Wählen Sie "nuget.org" als Paketquelle aus.
- Wählen Sie die Registerkarte Durchsuchen aus.
- Aktivieren Sie das Kontrollkästchen "Vorabversionen einschließen ".
- Suchen Sie nach Microsoft.ML.
- Wählen Sie die Schaltfläche Installieren aus.
- Wählen Sie im Dialogfeld "Lizenzakzeptanz" die Schaltfläche "Ich stimme zu", wenn Sie den Lizenzbedingungen für die aufgeführten Pakete zustimmen.
- Wiederholen Sie diese Schritte für die Pakete Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (Version 2.3.1) und Microsoft.ML.ImageAnalytics NuGet.
Vorbereiten und Verstehen der Daten
Hinweis
Die Datasets für dieses Lernprogramm stammen aus Maguire, Marc; Dorafshan, Sattar; und Thomas, Robert J., "SDNET2018: Ein konkretes Rissbild-Dataset für Machine Learning-Anwendungen" (2018). Durchsuchen Sie alle Datasets. Papier 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 ist ein Bild-Dataset, das Anmerkungen für rissige und nicht rissige Betonstrukturen (Brückendecks, Wände und Gehsteige) enthält.

Die Daten sind in drei Unterverzeichnissen angeordnet:
- D enthält Bilder des Brückendecks
- P enthält Pflasterbilder
- W enthält Wandbilder
Jedes dieser Unterverzeichnisse enthält zwei zusätzliche Unterverzeichnisse mit Präfix:
- C ist das Präfix, das für rissige Oberflächen verwendet wird.
- U ist das Präfix, das für uncracked Surfaces verwendet wird.
In diesem Lernprogramm werden nur Bilder des Brückendecks verwendet.
- Laden Sie das Dataset herunter, und entpacken Sie es.
- Erstellen Sie ein Verzeichnis mit dem Namen "Assets" in Ihrem Projekt, um Ihre Datasetdateien zu speichern.
- Kopieren Sie die CD- und UD-Unterverzeichnisse aus dem kürzlich extrahierten Verzeichnis in das Assets-Verzeichnis.
Erstellen von Eingabe- und Ausgabeklassen
Öffnen Sie die Program.cs Datei, und ersetzen Sie den vorhandenen Inhalt durch die folgenden
usingDirektiven:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Erstellen Sie eine Klasse namens
ImageData. Diese Klasse wird verwendet, um die anfänglich geladenen Daten darzustellen.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDataenthält die folgenden Eigenschaften:-
ImagePathist der vollqualifizierte Pfad, in dem das Bild gespeichert ist. -
Labelist die Kategorie, zu der das Bild gehört. Dies ist der wert, der vorhergesagt werden soll.
-
Erstellen Sie Klassen für Ihre Eingabe- und Ausgabedaten.
Definieren Sie unter der
ImageDataKlasse das Schema Ihrer Eingabedaten in einer neuen Klasse namensModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputenthält die folgenden Eigenschaften:-
Imageist diebyte[]Darstellung des Bilds. Das Modell erwartet, dass Bilddaten dieser Art für die Schulung vorliegen. -
LabelAsKeyist die numerische Darstellung derLabel. -
ImagePathist der vollqualifizierte Pfad, in dem das Bild gespeichert ist. -
Labelist die Kategorie, zu der das Bild gehört. Dies ist der wert, der vorhergesagt werden soll.
Nur
ImageundLabelAsKeywerden verwendet, um das Modell zu trainieren und Vorhersagen zu machen. Die EigenschaftenImagePathundLabelwerden beibehalten, um den Zugriff auf den ursprünglichen Bilddateinamen und die ursprüngliche Kategorie zu erleichtern.-
Definieren Sie dann unter der
ModelInputKlasse das Schema Ihrer Ausgabedaten in einer neuen Klasse namensModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputenthält die folgenden Eigenschaften:-
ImagePathist der vollqualifizierte Pfad, in dem das Bild gespeichert ist. -
Labelist die ursprüngliche Kategorie, zu der das Bild gehört. Dies ist der wert, der vorhergesagt werden soll. -
PredictedLabelist der vom Modell vorhergesagte Wert.
Ähnlich wie
ModelInput, nur diePredictedLabelist erforderlich, um Vorhersagen zu machen, da sie die vom Modell vorgenommene Vorhersage enthält. DieImagePath- undLabel-Eigenschaften werden zur Vereinfachung des Zugriffs auf den ursprünglichen Bilddateinamen und die ursprüngliche Kategorie beibehalten.-
Definieren von Pfaden und Initialisieren von Variablen
Fügen Sie unter den
usingDirektiven den folgenden Code hinzu:Definieren Sie den Speicherort der Objekte.
Initialisieren Sie die
mlContextVariable mit einer neuen Instanz von MLContext.Die MLContext-Klasse ist ein Ausgangspunkt für alle ML.NET Vorgänge, und die Initialisierung von mlContext erstellt eine neue ML.NET Umgebung, die für die Workflowobjekte der Modellerstellung freigegeben werden kann. Es ist konzeptionell ähnlich wie
DbContextim Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Laden der Daten
Erstellen einer Hilfsprogrammmethode für das Laden von Daten
Die Bilder werden in zwei Unterverzeichnissen gespeichert. Vor dem Laden der Daten muss sie in eine Liste von ImageData Objekten formatiert werden. Erstellen Sie dazu die LoadImagesFromDirectory Methode:
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
Die LoadImagesFromDirectory-Methode:
- Ruft alle Dateipfade aus den Unterverzeichnissen ab.
- Durchlaufen Sie jede einzelne Datei mithilfe einer
foreachAnweisung und überprüfen Sie, ob die Dateierweiterungen unterstützt werden. Die Bildklassifizierungs-API unterstützt JPEG- und PNG-Formate. - Ruft die Bezeichnung für die Datei ab. Wenn der
useFolderNameAsLabelParameter auftruefestgelegt ist, wird das übergeordnete Verzeichnis, in dem die Datei gespeichert wird, als Bezeichnung verwendet. Andernfalls erwartet sie, dass die Bezeichnung ein Präfix des Dateinamens oder des Dateinamens selbst ist. - Erstellt eine neue Instanz von
ModelInput.
Vorbereiten der Daten
Fügen Sie den folgenden Code nach der Zeile hinzu, in der Sie eine neue Instanz von MLContext erstellen.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
Der vorherige Code:
Ruft die
LoadImagesFromDirectoryHilfsmethode auf, um die Liste der Bilder abzurufen, die nach der Initialisierung dermlContextVariablen für die Schulung verwendet werden.Lädt die Bilder in eine
IDataViewmithilfe derLoadFromEnumerableMethode.Löscht die Daten mithilfe der
ShuffleRowsMethode. Die Daten werden in der Reihenfolge geladen, in der sie aus den Verzeichnissen gelesen wurde. Der Shuffle wird ausgeführt, um es auszugleichen.Führt vor der Schulung einige Vorverarbeitungen der Daten durch. Dies geschieht, weil Machine Learning-Modelle erwarten, dass eingaben im numerischen Format vorliegen. Der Vorverarbeitungscode erstellt eine
EstimatorChainMischung aus denMapValueToKeyUndLoadRawImageBytesTransformationen. DieMapValueToKey-Transformation nimmt den kategorischen Wert in derLabel-Spalte, konvertiert ihn in einen numerischenKeyType-Wert und speichert ihn in einer neuen Spalte namensLabelAsKey. Die Werte aus derImagePathSpalte werden zusammen mit demimageFolderParameter verwendet, um Bilder für das Training zu laden.Verwendet die
FitMethode, um die Daten auf diepreprocessingPipelineEstimatorChainTransformgefolgte Methode anzuwenden, die eineIDataViewmit den vorverarbeiteten Daten zurückgibt.Teilt die Daten in Schulungs-, Validierungs- und Testsätze auf.
Um ein Modell zu trainieren, ist es wichtig, über ein Schulungsdatenset sowie ein Validierungsdatenset zu verfügen. Das Modell wird auf dem Trainingssatz trainiert. Wie gut es Vorhersagen für nicht angezeigte Daten macht, wird durch die Leistung anhand des Überprüfungssatzes gemessen. Basierend auf den Ergebnissen dieser Leistung nimmt das Modell Anpassungen an das, was es gelernt hat, um dies zu verbessern. Der Überprüfungssatz kann entweder aus dem Teilen Ihres ursprünglichen Datasets oder aus einer anderen Quelle stammen, die bereits für diesen Zweck reserviert wurde.
Im Codebeispiel werden zwei Aufteilungen durchgeführt. Zunächst werden die vorverarbeiteten Daten aufgeteilt und 70% für schulungen verwendet, während die verbleibenden 30% zur Überprüfung verwendet werden. Anschließend wird der 30% Validierungssatz weiter in Validierungs- und Testsätze aufgeteilt, bei denen 90% für die Validierung verwendet werden und 10% für Tests verwendet wird.
Eine Möglichkeit, über den Zweck dieser Datenpartitionen nachzudenken, besteht darin, eine Prüfung zu absolvieren. Beim Lernen für eine Prüfung überprüfen Sie Ihre Notizen, Bücher oder andere Ressourcen, um die Konzepte zu verstehen, die in der Prüfung vorkommen. Dies ist das Eisenbahnset. Dann können Sie eine Pseudoprüfung durchführen, um Ihr Wissen zu überprüfen. Hier kommt der Validierungssatz ins Spiel. Sie möchten prüfen, ob Sie die Konzepte gut verstanden haben, bevor Sie die eigentliche Prüfung absolvieren. Basierend auf diesen Ergebnissen notieren Sie sich, was Sie falsch gemacht haben oder nicht gut verstanden haben, und integrieren Sie Ihre Änderungen, während Sie die eigentliche Prüfung überprüfen. Schließlich nehmen Sie die Prüfung ab. Dies ist der Zweck des Testsatzes. Sie haben die Fragen, die im Examen vorkommen, noch nie gesehen und wenden jetzt an, was Sie aus der Schulung und Validierung gelernt haben, um Ihr Wissen auf die Aufgabe, die vor Ihnen liegt, anzuwenden.
Den Partitionen werden ihre jeweiligen Werte für die Trainings-, Validierungs- und Testdaten zugewiesen.
Definieren der Schulungspipeline
Die Modellschulung besteht aus zwei Schritten. Zunächst wird die Bildklassifizierungs-API verwendet, um das Modell zu trainieren. Anschließend werden die codierten Beschriftungen in der PredictedLabel-Spalte mithilfe der MapKeyToValue-Transformation wieder in ihren ursprünglichen kategorialen Wert konvertiert.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Der vorherige Code:
Erstellt eine neue Variable zum Speichern einer Reihe von erforderlichen und optionalen Parametern für ein ImageClassificationTrainer. Eine ImageClassificationTrainer akzeptiert mehrere optionale Parameter:
-
FeatureColumnNameist die Spalte, die als Eingabe für das Modell verwendet wird. -
LabelColumnNameist die Spalte für den zu prognostizierenden Wert. -
ValidationSetenthält dieIDataViewÜberprüfungsdaten. -
Archdefiniert, welche der vortrainierten Modellarchitekturen verwendet werden sollen. In diesem Lernprogramm wird die 101-Layer-Variante des ResNetv2-Modells verwendet. -
MetricsCallbackbindet eine Funktion, um den Fortschritt während der Schulung nachzuverfolgen. -
TestOnTrainSetweist das Modell an, die Leistung anhand des Trainingssatzes zu messen, wenn kein Validierungssatz vorhanden ist. -
ReuseTrainSetBottleneckCachedValuesteilt dem Modell mit, ob die zwischengespeicherten Werte aus der Engpassphase in nachfolgenden Ausführungen verwendet werden sollen. Die Engpassphase ist eine einmalige Pass-Through-Berechnung, die rechenintensiv ist, wenn sie zum ersten Mal ausgeführt wird. Wenn sich die Schulungsdaten nicht ändern und sie mit einer anderen Anzahl von Epochen oder Batchgrößen experimentieren möchten, reduziert die Verwendung der zwischengespeicherten Werte erheblich die Zeit, die zum Trainieren eines Modells erforderlich ist. -
ReuseValidationSetBottleneckCachedValuesistReuseTrainSetBottleneckCachedValuesähnlich, nur dass es sich in diesem Fall um den Validierungsdatensatz handelt.
-
Definiert die
EstimatorChain-Schulungspipeline, die sich sowohl aus demmapLabelEstimatorals auch aus dem ImageClassificationTrainer zusammensetzt.Verwendet die
FitMethode, um das Modell zu trainieren.
Verwenden Sie das Modell
Nachdem Sie das Modell trainiert haben, ist es an der Zeit, es zum Klassifizieren von Bildern zu verwenden.
Erstellen Sie eine neue Hilfsmethode, die aufgerufen wird OutputPrediction , um Vorhersageinformationen in der Konsole anzuzeigen.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Klassifizieren eines einzelnen Bilds
Erstellen Sie eine Methode, die aufgerufen wird
ClassifySingleImage, um eine einzelne Bildvorhersage zu erstellen und auszugeben.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }Die
ClassifySingleImage-Methode:- Erstellt eine
PredictionEngineinnerhalb derClassifySingleImageMethode. DiesPredictionEngineist eine Komfort-API, mit der Sie eine Vorhersage für eine einzelne Dateninstanz durchführen können. - Wenn Sie auf eine einzelne
ModelInputInstanz zugreifen möchten, konvertiert siedataIDataViewin eineIEnumerablemithilfe derCreateEnumerableMethode und ruft dann die erste Beobachtung ab. - Verwendet die
PredictMethode zum Klassifizieren des Bilds. - Gibt die Vorhersage mit der
OutputPredictionMethode an die Konsole aus.
- Erstellt eine
Rufen Sie
ClassifySingleImageauf, nachdem Sie dieFit-Methode mit dem Testsatz von Bildern aufgerufen haben.ClassifySingleImage(mlContext, testSet, trainedModel);
Klassifizieren mehrerer Bilder
Erstellen Sie eine Methode, die aufgerufen wird
ClassifyImages, um mehrere Bildvorhersagen zu erstellen und auszugeben.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }Die
ClassifyImages-Methode:- Erstellt eine
IDataViewmit der Methode enthaltendeTransformVorhersage. - Um über die Vorhersagen zu iterieren, werden
predictionDataIDataViewmittels der MethodeCreateEnumerablein einIEnumerableumgewandelt und die ersten 10 Beobachtungen abgerufen. - Durchläuft und gibt die ursprünglichen und vorhergesagten Labels für die Prognosen aus.
- Erstellt eine
Rufen Sie
ClassifyImagesauf, nachdem Sie dieClassifySingleImage()-Methode mit dem Testsatz von Bildern aufgerufen haben.ClassifyImages(mlContext, testSet, trainedModel);
Ausführen der Anwendung
Führen Sie Ihre Konsolen-App aus. Die Ausgabe sollte der folgenden Ausgabe ähneln.
Hinweis
Möglicherweise werden Warnungen oder die Verarbeitung von Nachrichten angezeigt; Diese Nachrichten wurden aus den folgenden Ergebnissen aus Gründen der Übersichtlichkeit entfernt. Aus Platzgründen wurde die Ausgabe kondensiert.
Engpassphase
Für den Bildnamen wird kein Wert ausgegeben, da die Bilder als byte[] geladen werden und es aus diesem Grund keinen Bildnamen gibt, der angezeigt werden kann.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Schulungsphase
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Klassifizieren der Bildausgabe
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Bei der Überprüfung des 7001-220.jpg Bildes können Sie feststellen, dass es nicht rissig ist, wie das Modell vorhergesagt hat.

Glückwunsch! Sie haben nun erfolgreich ein Deep Learning-Modell für die Klassifizierung von Bildern erstellt.
Verbessern des Modells
Wenn Sie mit den Ergebnissen des Modells nicht zufrieden sind, können Sie versuchen, die Leistung zu verbessern, indem Sie einige der folgenden Ansätze ausprobieren:
- Weitere Daten: Je mehr Beispiele ein Modell lernt, desto besser ist es. Laden Sie das vollständige SDNET2018 Dataset herunter, und verwenden Sie es zum Trainieren.
- Erweitern Sie die Daten: Eine gängige Technik zum Hinzufügen von Vielfalt zu den Daten besteht darin, die Daten zu erweitern, indem sie ein Bild aufnehmen und verschiedene Transformationen anwenden (Drehen, Kippen, Umschalten, Zuschneiden). Dadurch werden vielfältigere Beispiele für das Modell hinzugefügt, aus dem sie lernen können.
- Trainieren Sie länger: Je länger Sie trainieren, desto besser wird das Modell abgestimmt. Durch die Erhöhung der Anzahl von Epochen kann die Leistung Ihres Modells verbessert werden.
- Experimentieren Sie mit den Hyperparametern: Zusätzlich zu den in diesem Lernprogramm verwendeten Parametern können andere Parameter optimiert werden, um die Leistung potenziell zu verbessern. Eine Änderung der Lernrate, die die Größe der Aktualisierungen an dem Modell nach jeder Epoche bestimmt, kann die Leistung verbessern.
- Verwenden Sie eine andere Modellarchitektur: Je nachdem, wie Ihre Daten aussehen, kann sich das Modell, das seine Features am besten erlernen kann, unterscheiden. Wenn Sie mit der Leistung Ihres Modells nicht zufrieden sind, versuchen Sie, die Architektur zu ändern.
Nächste Schritte
In diesem Lernprogramm haben Sie gelernt, wie Sie ein benutzerdefiniertes Deep Learning-Modell mit Transferlernen, ein vortrainiertes TensorFlow-Modell und die ML.NET Bildklassifizierungs-API erstellen, um Bilder konkreter Oberflächen als zerbrochen oder ungecrackt zu klassifizieren.
Wechseln Sie zum nächsten Lernprogramm, um mehr zu erfahren.
Siehe auch
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.