Power BI-Modellierungsleitfaden für Power Platform
Microsoft Dataverse ist die Standarddatenplattform für viele Microsoft-Geschäftsanwendungsprodukte, einschließlich Dynamics 365 Customer Engagement und Power Apps-Canvas-Apps, sowie Dynamics 365 Customer Voice (früher Microsoft Forms Pro), Power Automate-Genehmigungen, Power Apps-Portale und mehr.
Dieser Artikel enthält Anleitungen zum Erstellen eines Power BI-Datenmodells, das eine Verbindung mit Dataverse herstellt. Es werden die Unterschiede zwischen einem Dataverse-Schema und einem optimierten Power BI-Schema beschrieben, und es werden Anleitungen zur Erweiterung der Sichtbarkeit Ihrer Geschäftsanwendungsdaten in Power BI geboten.
Aufgrund der einfachen Einrichtung, der schnellen Bereitstellung und der weiten Verbreitung speichert und verwaltet Dataverse immer größere Datenmengen in organisationsübergreifenden Umgebungen. Das bedeutet, dass es einen noch größeren Bedarf – und eine noch größere Chance – gibt, Analysen in diese Prozesse zu integrieren. Zu den Chancen gehören:
- Erstellen von Berichten zu allen Dataverse-Daten, die über die Einschränkungen der integrierten Diagramme hinausgehen
- Einfacher Zugang zu relevanten, kontextuell gefilterten Berichten innerhalb eines bestimmten Datensatzes
- Verbesserung des Werts von Dataverse-Daten durch Integration mit externen Daten
- Die Nutzung der in Power BI integrierten künstlichen Intelligenz (KI) ohne die Notwendigkeit, komplexen Code zu schreiben
- Steigerung der Akzeptanz von Power Platform-Lösungen durch Erhöhung ihres Nutzens und Wertes
- Verdeutlichung des Werts der Daten in Ihrer App für Entscheidungsträger*innen im Unternehmen
Verbinden von Power BI mit Dataverse
Beim Verbinden von Power BI mit Dataverse wird ein Power BI-Datenmodell erstellt. Sie können aus drei Methoden wählen, um ein Power BI-Modell zu erstellen.
- Importieren von Dataverse-Daten mithilfe des Dataverse-Connectors: Mit dieser Methode werden Dataverse-Daten in einem Power BI-Modell zwischengespeichert (gespeichert). Dieser Modus bietet dank der Ausführung der Abfragen im Arbeitsspeicher eine hohe Leistung. Er bietet auch Entwurfsflexibilität für Modellierer*innen, sodass sie Daten aus anderen Quellen integrieren können. Aufgrund dieser Stärken ist das Importieren von Daten der Standardmodus beim Erstellen eines Modells in Power BI Desktop.
- Importieren von Dataverse-Daten mithilfe von Azure Synapse Link: Diese Methode ist eine Variante der Importmethode, da sie auch Daten im Power BI-Modell zwischenspeichert, aber dazu eine Verbindung mit Azure Synapse Analytics herstellt. Mithilfe von Azure Synapse Link für Dataverse werden Dataverse-Tabellen kontinuierlich in Azure Synapse oder Azure Data Lake Storage Gen2 (ADLS) repliziert. Dieser Ansatz wird für die Berichterstattung über Hunderttausende oder sogar Millionen von Datensätzen in Dataverse-Umgebungen verwendet.
- Erstellen einer DirectQuery-Verbindung mithilfe des Dataverse-Connectors: Diese Methode ist eine Alternative zum Importieren von Daten. Ein DirectQuery-Modell besteht nur aus Metadaten, die die Modellstruktur definieren. Wenn Benutzer*innen einen Bericht öffnen, sendet Power BI native Abfragen an Dataverse, um Daten abzurufen. Erwägen Sie die Erstellung eines DirectQuery-Modells, wenn Berichte Dataverse-Daten nahezu in Echtzeit anzeigen müssen oder wenn Dataverse rollenbasierte Sicherheit erzwingen muss, damit Benutzer*innen nur die Daten sehen können, auf die sie zugreifen können.
Wichtig
Obwohl ein DirectQuery-Modell eine gute Alternative sein kann, wenn Sie eine Berichterstellung nahezu in Echtzeit oder die Erzwingung der Dataverse-Sicherheit in einem Bericht benötigen, kann dies zu einer langsamen Leistung für diesen Bericht führen.
Weitere Informationen zu den Überlegungen zu DirectQuery finden Sie weiter unten in diesem Artikel.
Um die richtige Methode für Ihr Power BI-Modell zu ermitteln, sollten Sie Folgendes in Betracht ziehen:
- Abfrageleistung
- Datenmenge
- Datenlatenz
- Rollenbasierte Sicherheit
- Die Einrichtungskomplexität
Tipp
Eine ausführliche Erläuterung zu Modellframeworks (Import-, DirectQuery- oder Verbundmodelle), deren Vorteilen und Einschränkungen sowie Features zur Optimierung von Power BI-Datenmodellen finden Sie unter Auswählen eines Power BI-Modellframeworks.
Abfrageleistung
Abfragen, die an Importmodelle gesendet werden, sind schneller als native Abfragen, die an DirectQuery-Datenquellen gesendet werden. Das liegt daran, dass importierte Daten im Arbeitsspeicher zwischengespeichert werden und für Analyseabfragen (Filter-, Gruppierungs- und Zusammenfassungsvorgänge) optimiert sind.
Umgekehrt rufen DirectQuery-Modelle Daten aus der Quelle erst ab, nachdem die Benutzer*innen einen Bericht geöffnet haben, was zu einer sekundenlangen Verzögerung beim Rendern des Berichts führt. Darüber hinaus erfordern Benutzerinteraktionen im Bericht, dass Power BI die Quelle erneut abfragen muss, was die Reaktionsfähigkeit weiter reduziert.
Datenmenge
Beim Entwickeln eines Importmodells sollten Sie darauf achten, die Daten, die in das Modell geladen werden, zu minimieren. Dies gilt insbesondere für große Modelle und Modelle, die im Laufe der Zeit voraussichtlich größer werden. Weitere Informationen finden Sie unter Verfahren zur Datenreduktion für die Importmodellierung.
Eine DirectQuery-Verbindung mit Dataverse ist eine gute Wahl, wenn das Abfrageergebnis des Berichts nicht groß ist. Ein großes Abfrageergebnis enthält mehr als 20.000 Zeilen in den Quelltabellen des Berichts, oder das an den Bericht zurückgegebene Ergebnis beträgt nach Anwendung von Filtern mehr als 20.000 Zeilen. In diesem Fall können Sie mithilfe des Dataverse-Connectors einen Power BI-Bericht erstellen.
Hinweis
Die Zeilengröße von 20.000 ist keine feste Grenze. Jede Datenquellenabfrage muss jedoch innerhalb von zehn Minuten ein Ergebnis zurückgeben. Später in diesem Artikel erfahren Sie, wie Sie innerhalb dieser Beschränkungen arbeiten können, und es werden weitere Überlegungen zum Entwurf von Dataverse DirectQuery erläutert.
Sie können die Leistung größerer semantischer Modelle (zuvor als Datasets bezeichnet) verbessern, indem Sie den Dataverse Connector verwenden, um die Daten in das Datenmodell zu importieren.
Auch größere semantische Modelle (mit mehreren Hunderttausend oder sogar Millionen von Zeilen) können von der Verwendung von Azure Synapse Link für Dataverse profitieren. Bei diesem Ansatz wird eine fortlaufende verwaltete Pipeline eingerichtet, die Dataverse-Daten als CSV- oder Parquet-Dateien in ADLS Gen2 kopiert. Power BI kann dann einen serverlosen Azure Synapse SQL-Pool abfragen, um ein Importmodell zu laden.
Datenlatenz
Wenn sich die Dataverse-Daten schnell ändern und Berichtsbenutzer*innen aktuelle Daten anzeigen müssen, kann ein DirectQuery-Modell Abfrageergebnisse in Quasi-Echtzeit liefern.
Tipp
Sie können einen Power BI-Bericht erstellen, der die automatische Seitenaktualisierung verwendet, um Echtzeitupdates anzuzeigen, aber nur, wenn der Bericht eine Verbindung mit einem DirectQuery-Modell herstellt.
Importdatenmodelle müssen eine Datenaktualisierung durchführen, um die Berichterstellung über aktuelle Datenänderungen zu ermöglichen. Beachten Sie, dass die Anzahl der täglichen geplanten Datenaktualisierungsvorgänge eingeschränkt ist. Sie können bis zu acht Aktualisierungen pro Tag für eine freigegebene Kapazität planen. Bei einer Premium-Kapazität oder Microsoft Fabric-Kapazität können Sie bis zu 48 Aktualisierungen pro Tag planen, wodurch eine Aktualisierungsfrequenz von 15 Minuten erreicht werden kann.
Wichtig
Manchmal bezieht sich dieser Artikel auf Power BI Premium oder seine Kapazitätsabonnements (P-SKUs). Beachten Sie, dass Microsoft derzeit Kaufoptionen konsolidiert und die SKUs von Power BI Premium pro Kapazität einstellt. Neue und vorhandene Kunden sollten stattdessen den Kauf von Fabric-Kapazitätsabonnements (F-SKUs) in Betracht ziehen.
Weitere Informationen finden Sie unter Wichtige Updates zur Power BI Premium-Lizenzierung und Häufig gestellte Fragen zu Power BI Premium.
Sie können auch die Verwendung der inkrementellen Aktualisierung in Betracht ziehen, um schnellere Aktualisierungen und Leistung in Quasi-Echtzeit zu erzielen (nur mit Premium oder Fabric verfügbar).
Rollenbasierte Sicherheit
Wenn rollenbasierte Sicherheit erzwungen werden muss, kann dies die Wahl des Power BI-Modellframeworks direkt beeinflussen.
Dataverse kann komplexe rollenbasierte Sicherheit erzwingen, um den Zugriff auf bestimmte Datensätze für bestimmte Benutzer*innen zu steuern. Beispielsweise können Vertriebsmitarbeiter nur ihre Verkaufschancen sehen, während Vertriebsleiter alle Verkaufschancen für alle Vertriebsmitarbeiter anzeigen können. Sie können den Komplexitätsgrad basierend auf den Anforderungen Ihrer Organisation anpassen.
Ein DirectQuery-Modell, das auf Dataverse basiert, kann mithilfe des Sicherheitskontexts der Berichtsbenutzer*innen eine Verbindung herstellen. Auf diese Weise werden den Berichtsbenutzer*innen nur die Daten angezeigt, auf die sie zugreifen dürfen. Dieser Ansatz kann den Berichtsentwurf vereinfachen, sofern die Leistung akzeptabel ist.
Um die Leistung zu verbessern, können Sie stattdessen ein Importmodell erstellen, das eine Verbindung mit Dataverse herstellt. In diesem Fall können Sie dem Modell bei Bedarf die Sicherheit auf Zeilenebene (Row-Level Security, RLS) hinzufügen.
Hinweis
Es kann eine Herausforderung sein, einige rollenbasierte Sicherheitsfunktionen von Dataverse in der Sicherheit auf Zeilenebene von Power BI zu replizieren, insbesondere wenn Dataverse komplexe Berechtigungen erzwingt. Darüber hinaus ist möglicherweise eine laufende Verwaltung erforderlich, um die Power BI-Berechtigungen mit den Dataverse-Berechtigungen synchron zu halten.
Weitere Informationen zur Sicherheit auf Zeilenebene in Power BI finden Sie unter Leitfaden zu Sicherheit auf Zeilenebene (Row-Level Security, RLS) in Power BI Desktop.
Die Einrichtungskomplexität
Die Verwendung des Dataverse-Connectors in Power BI – sei es für Import- oder DirectQuery-Modelle – ist unkompliziert und erfordert keine spezielle Software oder erhöhte Dataverse-Berechtigungen. Das ist ein Vorteil für Organisationen oder Abteilungen, die gerade ihre Arbeit aufnehmen.
Die Option „Azure Synapse Link“ erfordert Systemadministratorzugriff auf Dataverse und bestimmte Azure-Berechtigungen. Diese Azure-Berechtigungen sind erforderlich, um das Speicherkonto und einen Synapse-Arbeitsbereich einzurichten.
Empfohlene Vorgehensweisen
In diesem Abschnitt werden Entwurfsmuster (und Antimuster) beschrieben, die Sie beim Erstellen eines Power BI-Modells berücksichtigen sollten, das eine Verbindung mit Dataverse herstellt. Nur wenige dieser Muster sind für Dataverse spezifisch, aber sie stellen für Dataverse-Entwickler*innen häufig eine Herausforderung dar, wenn sie Power BI-Berichte erstellen möchten.
Fokus auf einen bestimmten Anwendungsfall
Konzentrieren Sie sich auf einen bestimmten Anwendungsfall, anstatt zu versuchen, alle Probleme zu lösen.
Dies ist wahrscheinlich das häufigste und am schwierigsten zu vermeidende Antimuster. Ein einziges Modell zu entwickeln, das alle Anforderungen an die Self-Service-Berichterstellung erfüllt, ist eine Herausforderung. Erfolgreiche Modelle sind darauf ausgerichtet, Fragen im Zusammenhang mit einer zentralen Sammlung von Fakten zu einem bestimmten Thema zu beantworten. Auch wenn dies auf den ersten Blick eine Einschränkung des Modells zu sein scheint, ist es in Wirklichkeit eine Verbesserung, da Sie das Modell auf die Beantwortung von Fragen zu diesem Thema abstimmen und optimieren können.
Stellen Sie sich die folgenden Fragen, um sicherzustellen, dass Sie den Zweck des Modells genau verstanden haben.
- Welchen Themenbereich behandelt dieses Modell?
- Wer ist das Zielpublikum des Berichts?
- Welche Fragen sollen durch die Berichte beantwortet werden?
- Was ist das mindestfähige semantische Modell?
Vermeiden Sie es, mehrere Themenbereiche in einem einzelnen Modell zu behandeln, weil die Berichtsbenutzer*innen Fragen zu mehreren Themenbereichen haben, die in einem einzigen Bericht behandelt werden sollen. Wenn Sie diesen Bericht in mehrere Berichte aufteilen, von denen jeder ein anderes Thema (oder eine Faktentabelle) behandelt, können Sie sehr viel effizientere, skalierbare und besser verwaltbare Modelle erstellen.
Entwerfen eines Sternschemas
Dataverse-Entwickler und Administratoren, die mit dem Dataverse-Schema vertraut sind, versuchen möglicherweise, dasselbe Schema in Power BI zu reproduzieren. Dieser Ansatz ist ein Antimuster, und er ist wahrscheinlich am schwierigsten zu überwinden, weil es sich einfach richtig anfühlt, die Konsistenz zu wahren.
Dataverse eignet sich als relationales Modell gut für seinen Zweck. Es ist jedoch nicht als Analysemodell konzipiert, das für analytische Berichte optimiert ist. Das häufigste Muster für die Modellierung von Analysedaten ist ein Sternschemaentwurf. Das Sternschema ist ein ausgereifter Modellierungsansatz, der von relationalen Data Warehouse weitgehend übernommen wird. Hierzu müssen Modellierer ihre Modelltabellen entweder als Dimension oder Fakt klassifizieren. Berichte können anhand von Dimensionstabellenspalten filtern oder gruppieren und Faktentabellenspalten zusammenfassen.
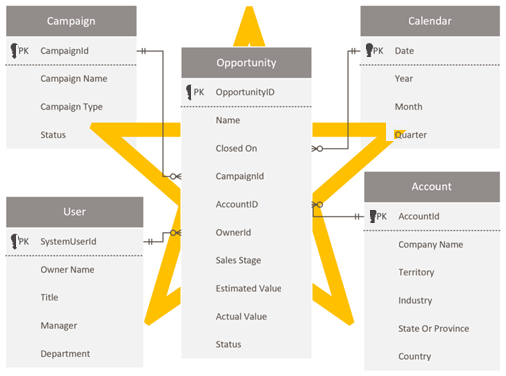
Weitere Informationen finden Sie im Artikel Informationen zum Sternschema und der Wichtigkeit für Power BI.
Optimieren Power Query Abfragen
Die Power Query Mashup-Engine strebt aus Effizienzgründen nach Möglichkeit das Query Folding an. Nach dem Query Folding delegiert eine Abfrage die Abfrageverarbeitung an das Quellsystem.
Das Quellsystem, in diesem Fall Dataverse, muss dann nur noch gefilterte oder zusammengefasste Ergebnisse an Power BI übermitteln. Eine Abfrage ist nach dem Query Folding oft deutlich schneller und effizienter als davor.
Weitere Informationen zum Erreichen des Query Folding finden Sie unter Query Folding in Power Query.
Hinweis
Das Optimieren von Power Query ist ein umfangreiches Thema. Um besser zu verstehen, was Power Query bei der Dokumenterstellung und bei der Modellaktualisierung in Power BI Desktop tut, lesen Sie Abfragediagnose.
Minimieren der Anzahl von Abfragespalten
Wenn Sie Power Query zum Laden einer Dataverse-Tabelle verwenden, werden standardmäßig alle Zeilen und alle Spalten abgerufen. Wenn Sie beispielsweise eine Systembenutzertabelle abfragen, kann diese mehr als 1.000 Spalten enthalten. Die Spalten in den Metadaten enthalten Beziehungen zu anderen Entitäten und Lookups für Optionsbezeichnungen, weshalb die Gesamtzahl der Spalten mit der Komplexität der Dataverse-Tabelle wächst.
Der Versuch, Daten aus allen Spalten abzurufen, ist ein Antimuster. Dieser führt häufig zu längeren Datenaktualisierungsvorgängen und bewirkt, dass die Abfrage fehlschlägt, wenn die für die Rückgabe der Daten erforderliche Zeit zehn Minuten überschreitet.
Es wird empfohlen, nur Spalten abzurufen, die für Berichte erforderlich sind. Häufig empfiehlt es sich, Abfragen nach Abschluss der Berichtsentwicklung neu zu bewerten und umzugestalten, damit Sie nicht verwendete Spalten identifizieren und entfernen können. Weitere Informationen finden Sie unter Verfahren zur Datenreduktion für die Importmodellierung (Entfernen von unnötigen Spalten).
Stellen Sie außerdem sicher, dass Sie den Power Query-Schritt Spalten entfernen frühzeitig einführen, damit ein Backfolding mit der Quelle möglich ist. Auf diese Weise kann Power Query die unnötige Arbeit vermeiden, Quelldaten zu extrahieren, um sie später (in einem Schritt ohne Folding) zu verwerfen.
Wenn Sie über eine Tabelle verfügen, die viele Spalten enthält, ist es möglicherweise nicht praktikabel, den interaktiven Abfrage-Generator von Power Query zu verwenden. In diesem Fall können Sie zunächst eine leere Abfrage erstellen. Anschließend können Sie Erweiterter Editor verwenden, um eine minimale Abfrage einzufügen, die einen Startpunkt erstellt.
Betrachten Sie die folgende Abfrage, die Daten aus nur zwei Spalten der Kontotabelle abruft.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Schreiben nativer Abfragen
Wenn Sie bestimmte Transformationsanforderungen haben, erreichen Sie möglicherweise eine bessere Leistung, wenn Sie eine native Abfrage verwenden, die in Dataverse SQL geschrieben ist, einer Teilmenge von Transact-SQL. Sie können eine native Abfrage für folgende Zwecke schreiben:
- Reduzieren der Anzahl von Zeilen (mithilfe einer
WHERE-Klausel) - Aggregieren von Daten (mithilfe der
GROUP BY- undHAVING-Klauseln) - Verknüpfen von Tabellen auf eine bestimmte Weise (mithilfe der
JOIN- oderAPPLY-Syntax) - Verwenden von unterstützten SQL-Funktionen
Weitere Informationen findest du unter:
Ausführen nativer Abfragen mit der Option „EnableFolding“
Power Query führt mithilfe der Value.NativeQuery-Funktion eine native Abfrage aus.
Wenn Sie diese Funktion verwenden, ist es wichtig, die EnableFolding=true-Option hinzuzufügen, um sicherzustellen, dass ein Backfolding der Abfragen zum Dataverse-Dienst erfolgt. Für eine native Abfrage wird nur dann ein Folding ausgeführt, wenn diese Option hinzugefügt wird. Die Aktivierung dieser Option kann zu erheblichen Leistungsverbesserungen führen – in einigen Fällen bis zu 97 Prozent.
Betrachten Sie die folgende Abfrage, die eine native Abfrage verwendet, um ausgewählte Spalten aus der Kontotabelle abzurufen. Für die native Abfrage wird ein Folding ausgeführt, da die EnableFolding=true-Option festgelegt ist.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Die größten Leistungsverbesserungen können Sie erwarten, wenn Sie eine Teilmenge von Daten aus einem großen Datenvolumen abrufen.
Tipp
Leistungsverbesserungen können auch davon abhängen, wie Power BI die Quelldatenbank abfragt. Beispielsweise zeigte ein Measure, das die COUNTDISTINCT-DAX-Funktion verwendet, mit oder ohne den Hinweis auf das Folding fast keine Verbesserung. Als die Measureformel so umgeschrieben wurde, dass sie die SUMX-DAX-Funktion verwendet, konnte die Abfrage um 97 Prozent gegenüber der gleichen Abfrage ohne den Hinweis verbessert werden.
Weitere Informationen finden Sie unter Value.NativeQuery. (Für die EnableFolding-Option ist keine Dokumentation vorhanden, da sie nur für bestimmte Datenquellen spezifisch ist.)
Beschleunigen der Auswertungsphase
Wenn Sie den Dataverse-Connector (früher als Common Data Service bezeichnet) verwenden, können Sie die CreateNavigationProperties=false-Option hinzufügen, um die Auswertungsphase eines Datenimports zu beschleunigen.
In der Auswertungsphase eines Datenimports werden die Metadaten der Quelle durchlaufen, um alle möglichen Tabellenbeziehungen zu bestimmen. Diese Metadaten können umfangreich sein, insbesondere für Dataverse. Indem Sie diese Option zur Abfrage hinzufügen, lassen Sie Power Query wissen, dass Sie diese Beziehungen nicht verwenden möchten. Dank dieser Option kann Power BI Desktop diese Phase der Aktualisierung überspringen und mit dem Abrufen der Daten fortfahren.
Hinweis
Verwenden Sie diese Option nicht, wenn die Abfrage von erweiterten Beziehungsspalten abhängig ist.
Betrachten Sie ein Beispiel, bei dem Daten aus der Kontotabelle abgerufen werden. Sie enthält drei Spalten im Zusammenhang mit „territory“: territory, territoryid und territoryidname.
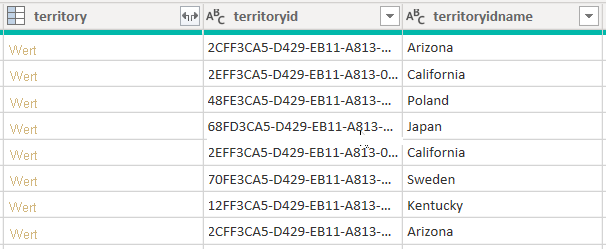
Wenn Sie die CreateNavigationProperties=false-Option festlegen, bleiben die territoryid- und territoryidname-Spalten erhalten, aber die territory-Spalte, die eine Beziehungsspalte ist (sie zeigt Value-Links) wird ausgeschlossen. Es ist wichtig zu verstehen, dass Power Query-Beziehungsspalten ein anderes Konzept als Modellbeziehungen sind, die Filter zwischen Modelltabellen weitergeben.
Betrachten Sie die folgende Abfrage, die die CreateNavigationProperties=false-Option (im Schritt Quelle) verwendet, um die Auswertungsphase eines Datenimports zu beschleunigen.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Wenn Sie diese Option verwenden, werden Sie wahrscheinlich eine erhebliche Leistungsverbesserung feststellen, wenn eine Dataverse-Tabelle viele Beziehungen zu anderen Tabellen aufweist. Da die SystemUser-Tabelle beispielsweise mit jeder anderen Tabelle in der Datenbank verknüpft ist, würde sich die Aktualisierungsleistung dieser Tabelle durch die Festlegung der Option CreateNavigationProperties=false verbessern.
Hinweis
Diese Option kann die Leistung der Datenaktualisierung von Importtabellen oder Tabellen im dualen Speichermodus verbessern, einschließlich des Prozesses der Anwendung von Änderungen im Power Query-Editor-Fenster. Die Leistung der interaktiven Kreuzfilterung von DirectQuery-Tabellen im Speichermodus wird dadurch nicht verbessert.
Auflösen leerer Auswahlbezeichnungen
Wenn Sie feststellen, dass Dataverse-Auswahlbezeichnungen in Power BI leer sind, kann dies daran liegen, dass die Bezeichnungen nicht auf dem TDS-Endpunkt (Tabular Data Stream) veröffentlicht wurden.
Öffnen Sie in diesem Fall das Dataverse Maker-Portal, navigieren Sie zum Bereich Lösungen, und wählen Sie dann Alle Anpassungen veröffentlichen aus. Der Veröffentlichungsprozess aktualisiert den TDS-Endpunkt mit den neuesten Metadaten, sodass die Optionsbezeichnungen für Power BI verfügbar sind.
Größere semantische Modelle mit Azure Synapse Link
Dataverse bietet die Möglichkeit, Tabellen mit Azure Data Lake Storage (ADLS) zu synchronisieren und dann über einen Azure Synapse-Arbeitsbereich eine Verbindung mit diesen Daten herzustellen. Sie können Azure Synapse Link mit minimalem Aufwand einrichten, um Dataverse-Daten in Azure Synapse aufzufüllen und Datenteams zu ermöglichen, tiefere Erkenntnisse zu gewinnen.
Azure Synapse Link ermöglicht eine kontinuierliche Replikation der Daten und Metadaten aus Dataverse in den Data Lake. Außerdem bietet der Dienst einen integrierten serverlosen SQL-Pool als praktische Datenquelle für Power BI-Abfragen.
Die Vorteile dieses Ansatzes sind erheblich. Kunden erhalten die Möglichkeit, Analyse-, Business Intelligence- und Machine Learning-Workloads für Dataverse-Daten auszuführen, indem sie verschiedene erweiterte Dienste verwenden. Zu den erweiterten Diensten gehören Apache Spark, Power BI, Azure Data Factory, Azure Databricks und Azure Machine Learning.
Herstellen einer Azure Synapse Link-Verbindung für Dataverse
Um eine Azure Synapse Link-Verbindung für Dataverse herzustellen, müssen die folgenden Voraussetzungen erfüllt sein:
- Systemadministratorzugriff auf die Dataverse-Umgebung
- Voraussetzungen für den Azure Data Lake Storage-Dienst:
- Sie müssen über ein Speicherkonto verfügen, das Sie mit ADLS Gen2 verwenden können.
- Sie müssen die Rollen Besitzer von Speicherblobdaten und Mitwirkender an Storage-Blobdaten innehaben, um auf das Speicherkonto zuzugreifen. Weitere Informationen finden Sie unter Rollenbasierte Zugriffssteuerung (Azure RBAC).
- Das Speicherkonto muss den hierarchischen Namespace aktivieren.
- Es wird empfohlen, dass das Speicherkonto georedundanten Speicher mit Lesezugriff (RA-GRS) verwendet.
- Voraussetzungen für den Synapse-Arbeitsbereich:
- Sie müssen Zugriff auf einen Synapse-Arbeitsbereich haben und über den Synapse-Administratorzugriff verfügen. Weitere Informationen finden Sie unter Integrierte Synapse RBAC-Rollen und -Bereiche.
- Der Arbeitsbereich muss sich in derselben Region wie das ADLS Gen2-Speicherkonto befinden.
Die Einrichtung umfasst die Anmeldung bei Power Apps und das Verbinden von Dataverse mit dem Azure Synapse-Arbeitsbereich. Über eine assistentenähnliche Oberfläche können Sie einen neuen Link erstellen, indem Sie das Speicherkonto und die zu exportierenden Tabellen auswählen. Azure Synapse Link kopiert dann Daten in den ADLS Gen2-Speicher und erstellt automatisch Ansichten im integrierten serverlosen Azure Synapse SQL-Pool. Sie können dann eine Verbindung mit diesen Ansichten herstellen, um ein Power BI-Modell zu erstellen.
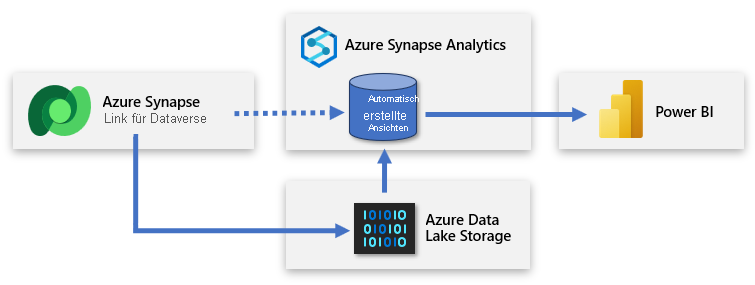
Tipp
Eine vollständige Dokumentation zum Erstellen, Verwalten und Überwachen von Azure Synapse Link finden Sie unter Erstellen einer Azure Synapse Link-Verbindung für Dataverse mit Ihrem Azure Synapse-Arbeitsbereich.
Erstellen einer zweiten serverlosen SQL-Datenbank
Sie können eine zweite serverlose SQL-Datenbank erstellen und sie verwenden, um benutzerdefinierte Berichtsansichten hinzuzufügen. Auf diese Weise können Sie den Power BI-Ersteller*innen einen vereinfachten Datensatz präsentieren, mit dem sie ein Modell auf der Grundlage nützlicher und relevanter Daten erstellen können. Die neue serverlose SQL-Datenbank wird zur primären Quellverbindung des Erstellers und zu einer benutzerfreundlichen Darstellung der Daten, die aus dem Data Lake stammen.
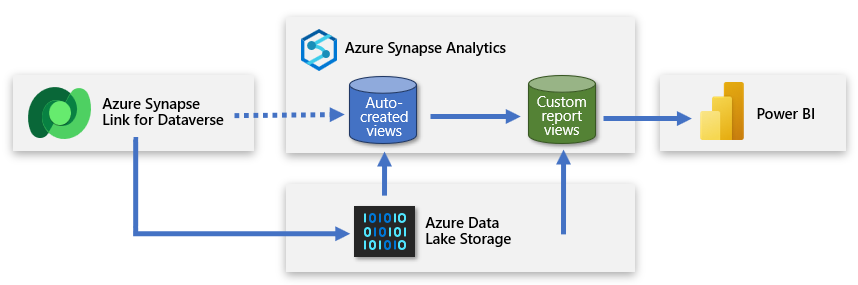
Dieser Ansatz liefert Daten an Power BI, die präzise, angereichert und gefiltert sind.
Sie können eine serverlose SQL-Datenbank mit Azure Synapse Studio im Azure Synapse-Arbeitsbereich erstellen. Wählen Sie serverlos als SQL-Datenbanktyp aus und geben Sie einen Datenbanknamen ein. Power Query kann eine Verbindung mit dieser Datenbank herstellen, indem eine Verbindung mit dem SQL-Endpunkt des Arbeitsbereichs hergestellt wird.
Erstellen benutzerdefinierter Ansichten
Sie können benutzerdefinierte Ansichten erstellen, die serverlose SQL-Poolabfragen einschließen. Diese Ansichten dienen als unkomplizierte, saubere Datenquellen, mit denen Power BI eine Verbindung herstellt. Die Ansichten sollten folgende Anforderungen erfüllen:
- Sie sollten die Bezeichnungen einschließen, die den Auswahlfeldern zugeordnet sind.
- Sie sollten die Komplexität reduzieren, indem Sie nur die Spalten einschließen, die für die Datenmodellierung erforderlich sind.
- Sie sollten unnötige Zeilen herausfiltern, z. B. inaktive Datensätze.
Betrachten Sie die folgende Ansicht, die Kampagnendaten abruft.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Beachten Sie, dass die Ansicht nur vier Spalten enthält, die jeweils einen Alias mit einem Anzeigenamen aufweisen. Es gibt auch eine WHERE-Klausel, um nur erforderliche Zeilen zurückzugeben, in diesem Fall aktive Kampagnen. Außerdem fragt die Ansicht die Kampagnentabelle ab, die mit den Tabellen OptionsetMetadata und StatusMetadata verknüpft ist, die die Auswahlbezeichnungen abrufen.
Tipp
Weitere Informationen zum Abrufen von Metadaten finden Sie unter Zugreifen auf Auswahlbezeichnungen direkt aus Azure Synapse Link für Dataverse.
Abfragen geeigneter Tabellen
Azure Synapse Link für Dataverse stellt sicher, dass Daten kontinuierlich mit den Daten im Data Lake synchronisiert werden. Bei Aktivitäten mit hoher Auslastung können gleichzeitige Schreib- und Lesevorgänge zu Sperren führen, die Abfragen zum Scheitern bringen. Um die Zuverlässigkeit beim Abrufen von Daten zu gewährleisten, werden zwei Versionen der Tabellendaten in Azure Synapse synchronisiert.
- Daten in Quasi-Echtzeit: Liefert auf effiziente Weise eine Kopie der von Dataverse über Synapse Link synchronisierten Daten, indem festgestellt wird, welche Daten sich seit der ersten Extraktion oder der letzten Synchronisierung geändert haben.
- Momentaufnahmedaten: Stellt eine schreibgeschützte Kopie der Daten in Quasi-Echtzeit bereit, die in regelmäßigen Abständen (in diesem Fall stündlich) aktualisiert wird. Namen von Momentaufnahme-Datentabellen werden _partitioned an ihren Namen angefügt.
Wenn Sie erwarten, dass viele Lese- und Schreibvorgänge gleichzeitig ausgeführt werden, sollten Sie die Daten aus den Momentaufnahmetabellen abrufen, um Abfragefehler zu vermeiden.
Weitere Informationen finden Sie unter Zugreifen auf Daten in Quasi-Echtzeit und schreibgeschützte Momentaufnahmedaten.
Herstellen einer Verbindung mit Synapse Analytics
Um einen serverlosen Azure Synapse SQL-Pool abzufragen, benötigen Sie dessen Arbeitsbereich-SQL-Endpunkt. Sie können den Endpunkt aus Synapse Studio abrufen, indem Sie die Eigenschaften des serverlosen SQL-Pools öffnen.
In Power BI Desktop können Sie mithilfe des SQL-Connectors für Azure Synapse Analytics eine Verbindung mit Azure Synapse herstellen. Wenn Sie zur Eingabe des Servers aufgefordert werden, geben Sie den SQL-Endpunkt des Arbeitsbereichs ein.
Überlegungen zu DirectQuery
Es gibt viele Anwendungsfälle, in denen die Verwendung des DirectQuery-Speichermodus Ihre Anforderungen erfüllen kann. Die Verwendung von DirectQuery kann sich jedoch negativ auf die Leistung von Power BI-Berichten auswirken. Ein Bericht, der eine DirectQuery-Verbindung mit Dataverse verwendet, ist nicht so schnell wie ein Bericht, der ein Importmodell verwendet. Im Allgemeinen sollten Sie Daten nach Möglichkeit in Power BI importieren.
Es wird empfohlen, die Themen in diesem Abschnitt bei der Arbeit mit DirectQuery zu berücksichtigen.
Weitere Informationen darüber, wann Sie mit dem DirectQuery-Speichermodus arbeiten sollten, finden Sie unter Auswählen eines Power BI-Modellframeworks.
Verwenden von Dimensionstabellen im dualen Speichermodus
Eine Tabelle mit Speichermodus „Dual“ ist auf die Verwendung von Import- und DirectQuery-Speichermodi festgelegt. Zur Abfragezeit bestimmt Power BI den effizientesten Modus, der verwendet werden soll. Wann immer möglich, versucht Power BI, Abfragen mit importierten Daten zu beantworten, da dies schneller ist.
Sie sollten gegebenenfalls Dimensionstabellen auf den dualen Speichermodus festlegen. Auf diese Weise werden Slicervisuals und Filterkartenlisten, die häufig auf Dimensionstabellenspalten basieren, schneller gerendert, da sie aus importierten Daten abgefragt werden.
Wichtig
Wenn eine Dimensionstabelle das Dataverse-Sicherheitsmodell erben muss, sollten Sie den dualen Speichermodus nicht verwenden.
Faktentabellen, die in der Regel große Datenmengen speichern, sollten als DirectQuery-Speichertabellen beibehalten werden. Sie werden nach den Dimensionstabellen im dualen Speichermodus gefiltert, die mit der Faktentabelle verbunden werden können, um eine effiziente Filterung und Gruppierung zu erreichen.
Sehen Sie sich den folgenden Datenmodellentwurf an. Drei Dimensionstabellen(Besitzer, Konto und Kampagne) verfügen über einen gestreiften oberen Rahmen, was bedeutet, dass sie auf den dualen Speichermodus festgelegt sind.
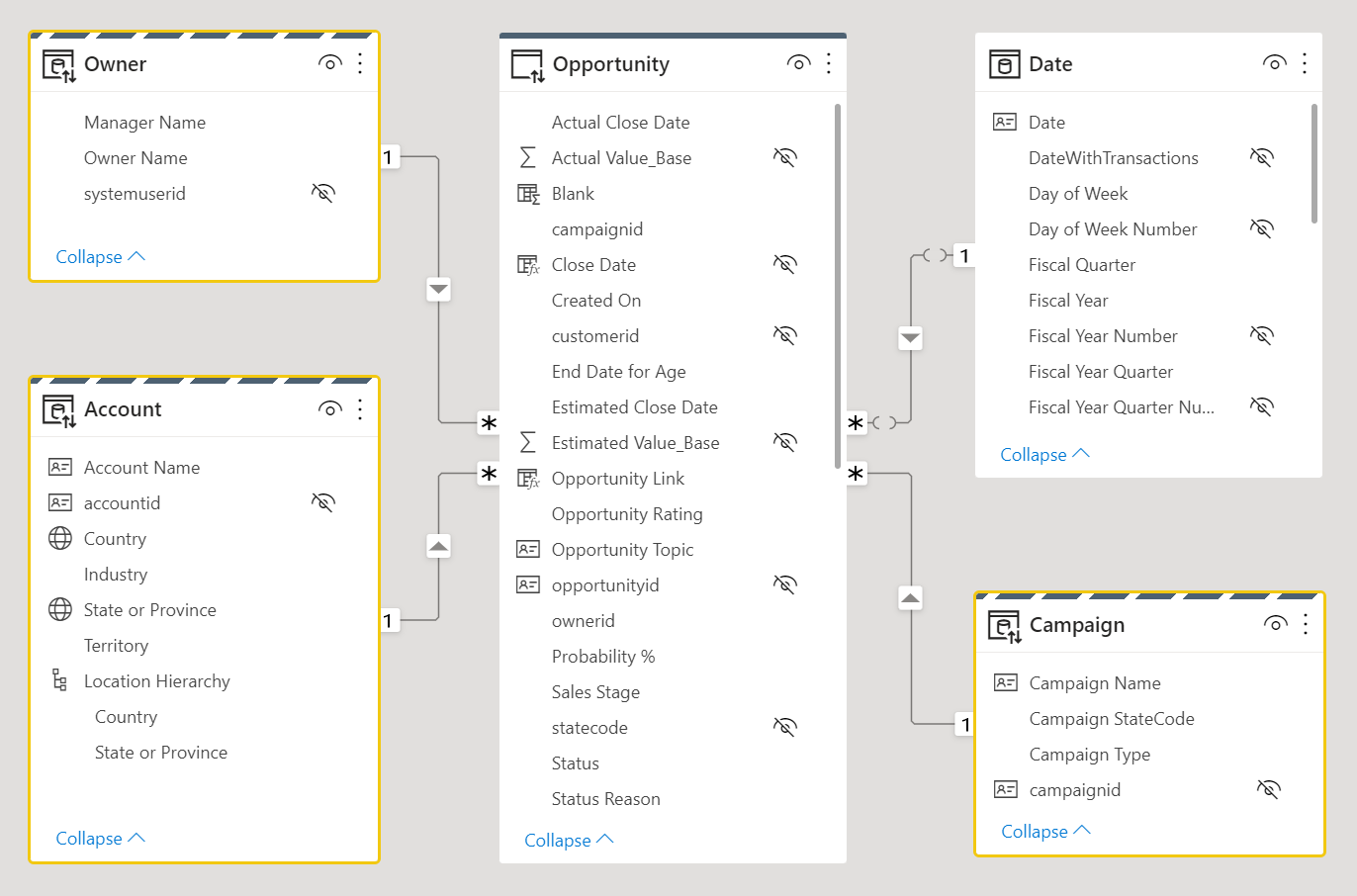
Weitere Informationen zu Tabellenspeichermodi wie dem dualen Speichermodus finden Sie unter Verwalten des Speichermodus in Power BI Desktop.
Aktivieren der einmaligen Anmeldung
Wenn Sie ein DirectQuery-Modell im Power BI-Dienst veröffentlichen, können Sie die Einstellungen zu semantischen Modellen verwenden, um einmaliges Anmelden (Single Sign-On, SSO) mithilfe von Microsoft Entra ID (ehemals Azure Active Directory) OAuth2 für Ihre Berichtsbenutzer*innen zu aktivieren. Sie sollten diese Option aktivieren, wenn Dataverse-Abfragen im Sicherheitskontext der Berichtsbenutzer*innen ausgeführt werden müssen.
Wenn SSO aktiviert ist, sendet Power BI die authentifizierten Microsoft Entra-Anmeldeinformationen der Berichtsbenutzer*innen in den Abfragen an Dataverse. Mit dieser Option kann Power BI die Sicherheitseinstellungen berücksichtigen, die in der Datenquelle eingerichtet sind.
Weitere Informationen finden Sie unter Einmaliges Anmelden (SSO) für DirectQuery-Quellen.
Replizieren von „My“-Filtern in Power Query
Wenn Sie Microsoft Dynamics 365 Customer Engagement (CE) und modellgesteuerte Power Apps-Apps verwenden, die auf Dataverse basieren, können Sie Ansichten erstellen, die nur Datensätze anzeigen, bei denen ein Benutzernamenfeld (wie Besitzer) dem aktuellen Benutzer entspricht. Sie können beispielsweise Ansichten mit dem Namen „Meine offenen Verkaufschancen“, „Meine aktiven Anfragen“ und andere erstellen.
Sehen Sie sich ein Beispiel dafür an, wie die Dynamics 365-Ansicht Meine aktiven Konten einen Filter enthält, in dem Besitzer gleich dem aktuellen Benutzer gilt.
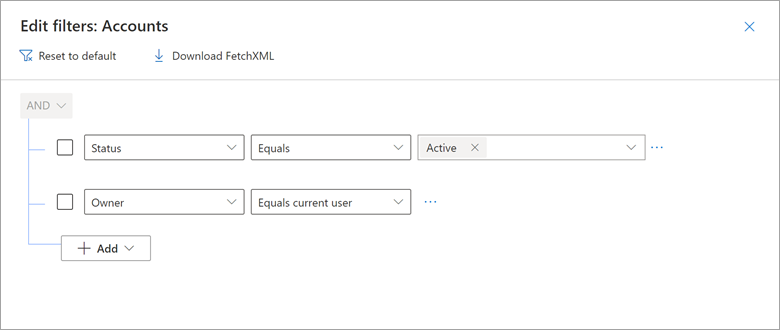
Sie können dieses Ergebnis in Power Query reproduzieren, indem Sie eine native Abfrage verwenden, in der das CURRENT_USER-Token eingebettet ist.
Sehen Sie sich das folgende Beispiel an, das eine native Abfrage zeigt, die die Konten des aktuellen Benutzers zurückgibt. Beachten Sie in der WHERE-Klausel, dass die ownerid-Spalte nach dem CURRENT_USER-Token gefiltert wird.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Wenn Sie das Modell im Power BI-Dienst veröffentlichen, müssen Sie einmaliges Anmelden (SSO) aktivieren, damit Power BI die authentifizierten Microsoft Entra-Anmeldeinformationen der Berichtsbenutzer*innen an Dataverse sendet.
Erstellen zusätzlicher Importmodelle
Sie können ein DirectQuery-Modell erstellen, das Dataverse-Berechtigungen erzwingt, wobei Sie wissen, dass die Leistung langsam sein wird. Anschließend können Sie dieses Modell mit Importmodellen ergänzen, die auf bestimmte Themen oder Zielgruppen ausgerichtet sind und RLS-Berechtigungen erzwingen könnten.
Ein Importmodell könnte beispielsweise Zugriff auf alle Dataverse-Daten bieten, aber keine Berechtigungen erzwingen. Dieses Modell eignet sich für Führungskräfte, die bereits Zugriff auf alle Dataverse-Daten haben.
Ein weiteres Beispiel: Wenn Dataverse rollenbasierte Berechtigungen nach Vertriebsregion erzwingt, können Sie ein Importmodell erstellen und diese Berechtigungen mithilfe von RLS replizieren. Alternativ können Sie ein Modell für jede Vertriebsregion erstellen. Sie können dann den Vertriebsmitarbeiter*innen jeder Region Leseberechtigungen für diese Modelle (semantische Modelle) erteilen. Um die Erstellung dieser regionalen Modelle zu vereinfachen, können Sie Parameter und Berichtsvorlagen verwenden. Weitere Informationen finden Sie unter Erstellen und Verwenden von Berichtsvorlagen in Power BI Desktop.
Zugehöriger Inhalt
Weitere Informationen zu den Themen dieses Artikels finden Sie in den folgenden Ressourcen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für