Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
In diesem Artikel erfahren Sie, wie Sie die häufigsten Probleme mit einem serverlosen SQL-Pool in Azure Synapse Analytics behandeln.
Weitere Informationen zu Azure Synapse Analytics finden Sie in den Themen in der Übersicht.
Synapse Studio
Synapse Studio ist ein einfach zu verwendendes Tool, mit dem Sie über einen Browser auf Ihre Daten zugreifen können, ohne Datenbankzugriffstools installieren zu müssen. Synapse Studio ist nicht für das Lesen großer Datenmengen oder die vollständige Verwaltung von SQL-Objekten konzipiert.
Serverloser SQL-Pool (Vorschauversion) in Synapse Studio abgeblendet
Wenn von Synapse Studio keine Verbindung mit einem serverlosen SQL-Pool hergestellt werden kann, ist der serverlose SQL-Pool abgeblendet oder hat den Status Offline.
In der Regel tritt dieses Problem aus einem von zwei Gründen auf:
- Ihr Netzwerk verhindert die Kommunikation mit dem Azure Synapse Analytics-Back-End. Dies ist meistens auf eine Blockierung des TCP-Ports 1443 zurückzuführen. Heben Sie die Blockierung dieses Ports auf, damit ein serverloser SQL-Pool verwendet werden kann. Andere Probleme könnten ebenfalls verhindern, dass der SQL-Pool funktioniert. Weitere Informationen finden Sie im Leitfaden zur Problembehandlung.
- Sie haben keine Berechtigung, sich bei dem serverlosen SQL-Pool anzumelden. Damit Sie Zugriff erhalten, muss ein Azure Synapse-Arbeitsbereichsadministratoren Ihnen die Rolle Arbeitsbereichsadministrator oder SQL-Administrator zuweisen. Weitere Informationen finden Sie unter Azure Synapse-Zugriffssteuerung.
Unerwartet geschlossene WebSocket-Verbindung
Bei Ihrer Abfrage könnte die Fehlermeldung Websocket connection was closed unexpectedly. angezeigt werden. Dies bedeutet, dass Ihre Browserverbindung mit Synapse Studio unterbrochen wurde, z. B. aufgrund eines Netzwerkproblems.
- Führen Sie Ihre Abfrage erneut aus, um dieses Problem zu beheben.
- Probieren Sie die MSSQL-Erweiterung für Visual Studio Code oder SQL Server Management Studio für dieselben Abfragen anstelle von Synapse Studio aus, um weitere Untersuchungen zu erhalten.
- Wenn diese Meldung in Ihrer Umgebung häufig auftritt, wenden Sie sich an Ihren Netzwerkadministrator. Sie können auch Firewalleinstellungen überprüfen und die Problembehandlung für Synapse Studio zu Rate ziehen.
- Wenn das Problem weiterhin auftritt, erstellen Sie über das Azure-Portal ein Supportticket.
Serverlose Datenbanken werden in Synapse Studio nicht angezeigt
Wenn die Datenbanken, die im serverlosen SQL-Pool erstellt werden, nicht angezeigt werden, überprüfen Sie, ob Ihr serverloser SQL-Pool gestartet wurde. Wenn der serverlose SQL-Pool deaktiviert ist, werden die Datenbanken nicht angezeigt. Führen Sie eine beliebige Abfrage wie SELECT 1 für den serverlosen Pool aus, um ihn zu aktivieren. Danach sollten die Datenbanken angezeigt werden.
Synapse: Serverloser SQL-Pool wird als nicht verfügbar angezeigt
Die Ursache für dieses Verhalten ist oftmals eine falsche Netzwerkkonfiguration. Stellen Sie sicher, dass die Ports ordnungsgemäß konfiguriert sind. Wenn Sie eine Firewall oder private Endpunkte verwenden, überprüfen Sie diese Einstellungen auch.
Stellen Sie außerdem sicher, dass die entsprechenden Rollen gewährt und nicht widerrufen wurden.
Die neue Datenbank kann nicht erstellt werden, da die Anforderung den alten/abgelaufenen Schlüssel verwendet.
Dieser Fehler wird durch das Ändern des kundenseitig verwalteten Schlüssels für den Arbeitsbereich verursacht, der für die Verschlüsselung verwendet wird. Sie können auswählen, dass alle Daten im Arbeitsbereich mit der aktuellen Version des aktiven Schlüssels erneut verschlüsselt werden. Wenn die Daten erneut verschlüsselt werden sollen, ändern Sie im Azure-Portal den Schlüssel in einen temporären Schlüssel, und wechseln Sie dann zurück zu dem Schlüssel, den Sie für die Verschlüsselung verwenden möchten. Erfahren Sie, wie Sie die Arbeitsbereichsschlüssel verwalten.
Der serverlose SQL-Pool von Synapse ist nach der Übertragung eines Abonnements an einen anderen Microsoft Entra-Mandanten nicht verfügbar.
Wenn Sie ein Abonnement in einen anderen Microsoft Entra-Mandanten verschoben haben, treten möglicherweise Probleme mit dem serverlosen SQL-Pool auf. Erstellen Sie ein Supportticket. Der Azure-Support wird Sie kontaktieren, um das Problem zu beheben.
Speicherzugriff
Wenn Sie beim Versuch, auf Dateien im Azure-Speicher zuzugreifen, Fehlermeldungen erhalten, vergewissern Sie sich, dass Sie die Berechtigung zum Zugriff auf die Daten haben. Der Zugriff auf öffentlich verfügbare Dateien sollte möglich sein. Wenn Sie versuchen, ohne Anmeldeinformationen auf Daten zugreifen, stellen Sie sicher, dass Ihre Microsoft Entra-Identität direkten Zugriff auf die Dateien hat.
Wenn Sie über einen SAS-Schlüssel (Shared Access Signature) verfügen, den Sie für den Zugriff auf Dateien verwenden sollten, stellen Sie sicher, dass die Anmeldeinformationen (auf Serverebene oder datenbankspezifisch) erstellt wurden. Die Anmeldeinformationen sind erforderlich, wenn Sie mithilfe einer verwalteten Identität des Arbeitsbereichs und des benutzerdefinierten Dienstprinzipalnamens (Service Principal Name, SPN) auf Daten zugreifen.
Lesen und Auflisten von Dateien sowie der Zugriff darauf ist in Azure Data Lake Storage nicht möglich
Wenn Sie eine Microsoft Entra-Anmeldung ohne spezifische Anmeldeinformationen verwenden, stellen Sie sicher, dass Ihre Microsoft Entra-Identität Zugriff auf die Dateien im Speicher hat. Um auf die Dateien zugreifen zu können, muss Ihre Microsoft Entra-Identität über die Berechtigung Blobdatenleser oder über Berechtigungen zum Auflisten und Lesen von Zugriffssteuerungslisten (ACL) in ADLS verfügen. Weitere Informationen finden Sie unter Abfragefehler, da die Datei nicht geöffnet werden kann.
Wenn Sie mithilfe von Anmeldeinformationen auf den Speicher zugreifen, stellen Sie sicher, dass Ihre verwaltete Identität oder Ihr SPN über die Rolle Datenleser oder Mitwirkender bzw. bestimmte ACL-Berechtigungen verfügt. Wenn Sie ein Shared Access Signature-Token verwendet haben, stellen Sie sicher, dass es über die Berechtigung rl verfügt und nicht abgelaufen ist.
Wenn Sie die SQL-Anmeldung und die OPENROWSET-Funktion ohne Datenquelle verwenden, stellen Sie sicher, dass Sie über Anmeldeinformationen auf Serverebene verfügen, die dem Speicher-URI entsprechen und Berechtigung für den Zugriff auf den Speicher haben.
Abfrage nicht erfolgreich, da Datei nicht geöffnet werden kann
Wenn bei Ihrer Abfrage der Fehler File cannot be opened because it does not exist or it is used by another process auftritt und Sie sicher sind, dass beide Dateien vorhanden sind und nicht von einem anderen Prozess verwendet werden, kann vom serverlosen SQL-Pool nicht auf die Datei zugegriffen werden. Dieses Problem tritt in der Regel auf, weil Ihre Microsoft Entra-Identität keine Zugriffsberechtigungen für die Datei hat oder eine Firewall den Zugriff auf die Datei blockiert.
Vom serverlosen SQL-Pool wird standardmäßig versucht, unter Verwendung Ihrer Microsoft Entra-Identität auf die Datei zuzugreifen. Um dieses Problem zu beheben, benötigen Sie die entsprechenden Zugriffsrechte für die Datei. Dies können Sie am einfachsten erreichen, indem Sie sich die Rolle „Mitwirkender an Storage-Blobdaten“ für das Speicherkonto zuweisen, für das Sie Abfragen durchführen möchten.
Weitere Informationen finden Sie unter
- Microsoft Entra ID-Zugriffssteuerung für Speicher
- Steuern des Speicherkontozugriffs für einen serverlosen SQL-Pool in Synapse Analytics
Alternative zur Rolle „Mitwirkender an Storage-Blobdaten“
Anstatt sich selbst die Rolle „Mitwirkender an Storage-Blobdaten“ zu gewähren, können Sie auch für eine Teilmenge der Dateien präzisere Berechtigungen erteilen.
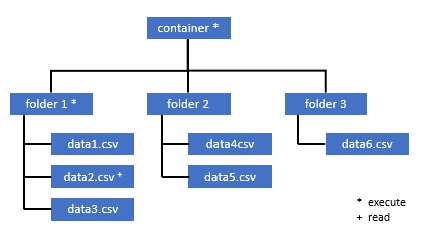
Alle Benutzer, die Zugriff auf einige Daten in diesem Container benötigen, müssen auch über die EXECUTE-Berechtigung für alle übergeordneten Ordner bis hinauf zum Stammordner (Container) verfügen.
Hier erfahren Sie mehr zum Festlegen von ACLs in Azure Data Lake Storage Gen2.
Hinweis
Die Ausführungsberechtigung auf der Containerebene muss innerhalb von Azure Data Lake Storage Gen2 festgelegt werden. Die Berechtigungen für den Ordner können in Azure Synapse festgelegt werden.
Wenn Sie in diesem Beispiel „data2.csv“ abfragen möchten, sind die folgenden Berechtigungen erforderlich:
- Ausführungsberechtigung für Container
- Ausführungsberechtigung für „folder1“
- Leseberechtigung für „data2.csv“
Melden Sie sich bei Azure Synapse mit einem Admin-Benutzer an, der volle Berechtigungen für die Daten hat, auf die Sie zugreifen möchten.
Klicken Sie im Datenbereich mit der rechten Maustaste auf die Datei, und wählen Sie Zugriff verwalten aus.
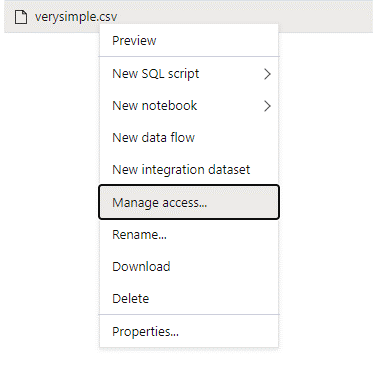
Wählen Sie mindestens die Berechtigung Lesen aus. Geben Sie den UPN oder die Objekt-ID des Benutzers ein, z. B.
user@contoso.com. Wählen Sie Hinzufügen.Erteilen Sie diesem Benutzer die Leseberechtigung.

Hinweis
Bei Gastbenutzern muss dieser Schritt direkt mit Azure Data Lake erfolgen, da er nicht direkt über Azure Synapse möglich ist.
Inhalt des Verzeichnisses im Pfad kann nicht aufgelistet werden
Dieser Fehler zeigt an, dass der Benutzer, der Azure Data Lake abfragt, die Dateien im Speicher nicht auflisten kann. Es gibt mehrere Szenarien, in denen dieser Fehler auftreten kann:
- Microsoft Entra-Benutzer*innen, die Microsoft Entra-Passthrough-Authentifizierung verwenden, haben keine Berechtigungen zum Auflisten der Dateien in Data Lake Storage.
- Microsoft Entra ID- oder SQL-Benutzer*innen lesen Daten mithilfe eines Shared Access Signature-Schlüssels oder einer verwalteten Arbeitsbereichsidentität, und dieser Schlüssel bzw. diese Identität verfügt nicht über die Berechtigung, die Dateien im Speicher aufzulisten.
- Der Benutzer, der auf Dataverse-Daten zugreift, hat keine Berechtigung zur Abfrage von Daten in Dataverse. Dieses Szenario kann auftreten, wenn Sie SQL-Benutzer verwenden.
- Der Benutzer, der auf Delta Lake zugreift, hat möglicherweise keine Berechtigung, das Delta Lake-Transaktionsprotokoll zu lesen.
Dieses Problem können Sie am einfachsten lösen, indem Sie sich die Rolle Mitwirkender an Storage-Blobdaten für das Speicherkonto zuweisen, für das Sie Abfragen durchführen möchten.
Weitere Informationen finden Sie unter
- Microsoft Entra ID-Zugriffssteuerung für Speicher
- Steuern des Speicherkontozugriffs für einen serverlosen SQL-Pool in Synapse Analytics
Inhalt der Dataverse-Tabelle kann nicht aufgelistet werden
Wenn Sie Azure Synapse Link für Dataverse verwenden, um die verknüpften DataVerse-Tabellen zu lesen, müssen Sie ein Microsoft Entra-Konto verwenden, um über den serverlosen SQL-Pool auf die verknüpften Daten zuzugreifen. Weitere Informationen finden Sie unter Azure Synapse Link für Dataverse mit Azure Data Lake.
Wenn Sie versuchen, mit einem SQL-Login eine externe Tabelle zu lesen, die auf die DataVerse-Tabelle verweist, erhalten Sie die folgende Fehlermeldung: External table '???' is not accessible because content of directory cannot be listed.
Externe Dataverse-Tabellen verwenden immer Microsoft Entra-Passthrough-Authentifizierung. Sie können sie nicht konfigurieren, um einen Shared Access Signature-Schlüssel oder eine verwaltete Arbeitsbereichsidentität zu verwenden.
Inhalt des Delta Lake-Transaktionsprotokolls kann nicht aufgelistet werden
Der folgende Fehler wird zurückgegeben, wenn der serverlose SQL-Pool den Delta Lake-Ordner mit dem Transaktionsprotokoll nicht lesen kann.
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Stellen Sie sicher, dass der Ordner _delta_log vorhanden ist. Vielleicht fragen Sie einfache Parquet-Dateien ab, die nicht in das Delta Lake-Format konvertiert werden. Stellen Sie bei Vorhandensein des Ordners _delta_log sicher, dass Sie für die zugrunde liegenden Delta Lake-Ordner sowohl über die Berechtigung zum Lesen als auch zum Auflisten verfügen. Versuchen Sie, JSON-Dateien direkt zu lesen, indem Sie FORMAT='csv' verwenden. Platzieren Sie Ihren URI im BULK-Parameter:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Wenn diese Abfrage zu einem Fehler führt, verfügt der Aufrufer nicht über die Berechtigung zum Lesen der zugrunde liegenden Speicherdateien.
Abfrageausführung
Möglicherweise werden während der Abfrageausführung in den folgenden Fällen Fehlermeldungen angezeigt:
- Der Aufrufer kann auf einige nicht Objekte zugreifen.
- Die Abfrage kann nicht auf externe Daten zugreifen.
- Die Abfrage enthält einige Funktionen, die in serverlosen SQL-Pools nicht unterstützt werden.
Abfrage nicht erfolgreich, da sie aufgrund aktueller Ressourceneinschränkungen nicht ausgeführt werden kann
Bei Ihrer Abfrage tritt möglicherweise die Fehlermeldung This query cannot be executed due to current resource constraints. auf. Diese Meldung bedeutet, dass der serverlose SQL-Pool derzeit nicht ausgeführt werden kann. Einige Möglichkeiten zur Problembehandlung:
- Vergewissern Sie sich, dass Datentypen mit passener Größe verwendet werden.
- Bei Abfragen für Parquet-Dateien empfiehlt sich ggf. das Definieren von expliziten Typen für Zeichenfolgenspalten, da für sie standardmäßig „VARCHAR(8000)“ verwendet wird. Abgeleitete Datentypen überprüfen
- Bei Abfragen für CSV-Dateien empfiehlt sich ggf. das Erstellen von Statistiken.
- Informationen zur Optimierung Ihrer Abfrage finden Sie unter Bewährte Methoden für die Leistung von serverlosen SQL-Pools.
Abfragetimeout abgelaufen
Der Fehler Query timeout expired wird zurückgegeben, wenn die Abfrage mehr als 30 Minuten im serverlosen SQL-Pool ausgeführt wurde. Dieser Grenzwert für den serverlosen SQL-Pool kann nicht geändert werden.
- Versuchen Sie, Ihre Abfrage durch Anwendung bewährter Methoden zu optimieren.
- Versuchen Sie alternativ, Teile Ihrer Abfragen zu materialisieren, indem Sie eine externe Tabelle als Auswahl erstellen (Create External Table As Select, CETAS).
- Überprüfen Sie, ob eine parallele Workload im serverlosen SQL-Pool ausgeführt wird, da andere Abfragen die Ressourcen möglicherweise in Anspruch nehmen. In diesem Fall können Sie die Workload auf mehrere Arbeitsbereiche aufteilen.
Ungültiger Objektname
Der Fehler Invalid object name 'table name' gibt an, dass Sie ein Objekt (etwa eine Tabelle oder Ansicht) verwenden, das in der serverlosen SQL-Pooldatenbank nicht existiert. Probieren Sie diese Optionen aus:
Listen Sie die Tabellen oder Sichten auf, und prüfen Sie, ob das Objekt existiert. Verwenden Sie SQL Server Management Studio oder Visual Studio Code, da Synapse Studio möglicherweise einige Tabellen anzeigt, die im serverlosen SQL-Pool nicht verfügbar sind.
Wenn Sie das Objekt sehen, prüfen Sie, ob Sie eine Groß-/Kleinschreibung- oder Binärdatenbank-Sortierung verwenden. Vielleicht stimmt der Objektname nicht mit dem Namen überein, den Sie in der Abfrage verwendet haben. Bei einer binären Datenbanksortierung sind
Employeeundemployeezwei verschiedene Objekte.Wenn Sie das Objekt nicht sehen, versuchen Sie vielleicht, eine Tabelle aus einer Lake- oder Spark-Datenbank abzufragen. Die Tabelle ist möglicherweise aus einem der folgenden Gründe nicht im serverlosen SQL-Pool verfügbar:
- Die Tabelle verfügt über einige Spaltentypen, die im serverlosen SQL-Pool nicht dargestellt werden können.
- Die Tabelle hat ein Format, das im serverlosen SQL-Pool nicht unterstützt wird. Beispiele sind Avro oder ORC.
String- oder binary-Daten würden abgeschnitten
Dieser Fehler tritt auf, wenn die Länge des Zeichenfolgen- oder Binärspaltentyps (z. B VARCHAR, VARBINARY oder NVARCHAR) kürzer als die tatsächliche Größe der Daten ist, die Sie lesen. Sie können diesen Fehler beheben, indem Sie die Länge des Spaltentyps erhöhen:
- Wenn Ihre Zeichenfolgenspalte als
VARCHAR(32)-Typ definiert ist und der Text 60 Zeichen umfasst, verwenden Sie denVARCHAR(60)-Typ (oder länger) in Ihrem Spaltenschema. - Wenn Sie den Schemarückschluss verwenden (ohne das
WITH-Schema), werden alle Zeichenfolgenspalten automatisch alsVARCHAR(8000)-Typ definiert. Wenn sie diesen Fehler erhalten, definieren Sie das Schema explizit in einerWITH-Klausel mit dem größerenVARCHAR(MAX)-Spaltentyp, um diesen Fehler zu beheben. - Wenn sich Ihre Tabelle in der Lake-Datenbank befindet, versuchen Sie, die Größe der Zeichenfolgenspalte im Spark-Pool zu erhöhen.
- Versuchen Sie,
SET ANSI_WARNINGS OFFauszuführen, um dem serverlosen SQL-Pool das automatische Abschneiden der VARCHAR-Werte zu ermöglichen, wenn sich dies nicht auf Ihre Funktionen auswirkt.
Kein schließendes Anführungszeichen nach der Zeichenfolge
In seltenen Fällen, in denen Sie den LIKE-Operator in einer Zeichenfolgenspalte oder einen Vergleich mit den Zeichenfolgenliteralen verwenden, erhalten Sie möglicherweise folgende Fehlermeldung:
Unclosed quotation mark after the character string
Dieser Fehler kann auftreten, wenn Sie die Latin1_General_100_BIN2_UTF8-Sortierung in der Spalte verwenden. Versuchen Sie, die Latin1_General_100_CI_AS_SC_UTF8-Sortierung anstelle der Latin1_General_100_BIN2_UTF8-Sortierung in der Spalte festzulegen, um das Problem zu beheben. Wenn der Fehler weiterhin zurückgegeben wird, führen Sie eine Supportanfrage über das Azure-Portal aus.
tempdb-Speicherplatz konnte beim Übertragen von Daten von einer Verteilung in eine andere nicht zugeordnet werden.
Der Fehlermeldung Could not allocate tempdb space while transferring data from one distribution to another wird zurückgegeben, wenn die Abfrageausführungs-Engine keine Daten verarbeiten und zwischen den Knoten übertragen kann, die die Abfrage ausführen. Dies ist ein Sonderfall im Hinblick auf generische Abfragefehler, da die Abfrage aufgrund von aktuellen Ressourceneinschränkungen nicht ausgeführt werden kann. Dieser Fehler wird zurückgegeben, wenn die der tempdb Datenbank zugeordneten Ressourcen nicht ausreichen, um die Abfrage auszuführen.
Wenden Sie bewährte Methoden an, bevor Sie ein Supportticket erstellen.
Abfragefehler bei der Fehlerbehandlung einer externen Datei (maximale Fehleranzahl erreicht)
Wenn bei Ihrer Abfrage der Fehler error handling external file: Max errors count reached auftritt, bedeutet das, dass ein Konflikt in Bezug auf einen angegebenen Spaltentyp und die zu ladenden Daten besteht.
Um weitere Informationen zum Fehler und zu den relevanten Zeilen und Spalten zu erhalten, sollten Sie die Parserversion von 2.0 in 1.0 ändern.
Beispiel
Wenn Sie die Datei names.csv mit dieser Abfrage 1 abfragen möchten, gibt der serverlose SQL-Pool von Azure Synapse folgende Fehlermeldung zurück: Error handling external file: 'Max error count reached'. File/External table name: [filepath].. Beispiel:
Die Datei names.csv enthält Folgendes:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Abfrage 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Ursache
Nachdem die Parserversion von Version 2.0 in 1.0 geändert wurde, dienen die Fehlermeldungen als Hilfe beim Identifizieren des Problems. Die neue Fehlermeldung lautet jetzt wie folgt: Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Das Abschneiden ist ein Hinweis darauf, dass der Spaltentyp für unsere Daten zu klein ist. Der längste Vorname in der Datei names.csv hat sieben Zeichen. Aus diesem Grund sollte mindestens „VARCHAR(7)“ als Datentyp verwendet werden. Der Fehler wird durch diese Codezeile verursacht:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Wenn Sie die Abfrage entsprechend ändern, wird der Fehler behoben. Ändern Sie nach dem Debuggen die Parserversion wieder in „2.0“, um die höchste Leistung zu erzielen.
Weitere Informationen zum Verwenden der Parserversion finden Sie unter Verwenden von „OPENROWSET“ mit einem serverlosen SQL-Pool in Azure Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Massenladen nicht möglich, weil die Datei nicht geöffnet werden konnte
Der Fehler Cannot bulk load because the file could not be opened wird zurückgegeben, wenn eine Datei während der Abfrageausführung geändert wird. In der Regel erhalten Sie möglicherweise eine Fehlermeldung wie Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Die serverlosen SQL-Pools können keine Dateien lesen, die während der Ausführung der Abfrage geändert werden. Die Abfrage kann die Dateien nicht sperren. Wenn Sie wissen, dass der Änderungsvorgang append lautet, können Sie versuchen, die folgende Option festzulegen: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Weitere Informationen finden Sie unter Abfragen von nur anfügbaren Dateien oder Erstellen von Tabellen für nur anfügbare Dateien.
Abfragefehler aufgrund von Datenkonvertierungsfehlern
Die Fehlermeldung Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. für Ihre Abfrage bedeutet, dass Ihre Datentypen nicht zu den tatsächlichen Daten für die Zeilennummer n und die Spalte m gepasst haben.
Falls Sie beispielsweise erwarten, dass Ihre Daten nur ganze Zahlen (Integer) enthalten, während Zeile „n“ aber ggf. eine Zeichenfolge enthält, erhalten Sie die folgende Fehlermeldung.
Untersuchen Sie die Datei und die von Ihnen ausgewählten Datentypen, um dieses Problem zu beheben. Überprüfen Sie auch, ob Ihre Einstellungen für Zeilentrennzeichen und Feldabschlusszeichen korrekt sind. Das folgende Beispiel zeigt, wie Sie die Überprüfung mit „VARCHAR“ als Spaltentyp durchführen können.
Weitere Informationen zu Feldabschlusszeichen, Zeilentrennzeichen und Escapezeichen finden Sie unter Abfragen von CSV-Dateien.
Beispiel
Wenn Sie die Datei names.csv abfragen möchten:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Dazu führen Sie die folgende Abfrage aus:
Abfrage 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Für den serverlosen SQL-Pool von Azure Synapse wird der Fehler Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath]. zurückgegeben.
Für die Behandlung dieses Problems ist es erforderlich, die Daten zu durchsuchen und eine fundierte Entscheidung zu treffen. Damit die Daten, die dieses Problem verursachen, untersucht werden können, muss zunächst der Datentyp geändert werden. Anstatt die Spalte „ID“ mit dem Datentyp „SMALLINT“ abzufragen, wird nun „VARCHAR(100)“ verwendet, um dieses Problem zu analysieren.
Mit der geringfügig geänderten Abfrage 2 können die Daten jetzt verarbeitet werden, und die Liste mit den Namen wird zurückgegeben.
Abfrage 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Sie werden feststellen, dass die Daten unerwartete Werte für „ID“ in der fünften Zeile enthalten. Unter solchen Umständen ist es wichtig, sich mit dem geschäftlichen Besitzer der Daten darüber abzustimmen, wie das Auftreten von beschädigten Daten wie in diesem Beispiel vermieden werden kann. Falls die Verhinderung auf Anwendungsebene nicht möglich ist, ist die Verwendung von „VARCHAR“ mit einer angemessenen Größe hier ggf. die einzige Option.
Tipp
Versuchen Sie, die Größe für „VARCHAR()“ möglichst gering zu halten. Vermeiden Sie nach Möglichkeit die Verwendung von „VARCHAR(MAX)“, da dies die Leistung beeinträchtigen kann.
Das Abfrageergebnis sieht nicht wie erwartet aus
Ihre Abfrage ist vielleicht erfolgreich, aber möglicherweise wird angezeigt, dass ihr Resultset nicht den Erwartungen entspricht. Die resultierenden Spalten sind möglicherweise leer, oder unerwartete Daten werden zurückgegeben. In diesem Szenario wurde wahrscheinlich ein Zeilentrennzeichen oder ein Feldabschlusszeichen falsch ausgewählt.
Um dieses Problem zu beheben, sehen Sie sich die Daten noch einmal, und ändern Sie die entsprechenden Einstellungen. Das Debuggen dieser Abfrage ist einfach, wie im folgenden Beispiel gezeigt.
Beispiel
Wenn Sie die Datei names.csv mit der Abfrage in Abfrage 1 abfragen möchten, gibt der serverlose Azure Synapse-SQL-Pool ein Ergebnis zurück, das merkwürdig aussieht:
In names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Die Spalte Firstname scheint keinen Wert zu enthalten. Stattdessen befinden sich alle Werte in der Spalte ID. Diese Werte werden durch ein Komma voneinander getrennt. Das Problem wurde durch diese Codezeile verursacht, da das Komma anstelle des Semikolons als Feldabschlusszeichen ausgewählt werden muss:
FIELDTERMINATOR =';',
Das Problem kann behoben werden, indem nur dieses Zeichen geändert wird:
FIELDTERMINATOR =',',
Das von Abfrage 2 erstellte Resultset sieht jetzt wie erwartet aus:
Abfrage 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Rückgabewerte:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Spalte des Typs ist mit dem externen Datentyp nicht kompatibel
Wenn für Ihre Abfrage die Fehlermeldung Column [column-name] of type [type-name] is not compatible with external data type […], angezeigt wird, wurde ein PARQUET-Datentyp wahrscheinlich einem falschen SQL-Datentyp zugeordnet.
Wenn Ihre Parquet-Datei beispielsweise einen Spaltenpreis mit Gleitkommazahlen (z. B. 12,89) enthält, und Sie versucht haben, die Zuordnung zu INT durchzuführen, wird diese Fehlermeldung angezeigt.
Untersuchen Sie die Datei und die von Ihnen ausgewählten Datentypen, um dieses Problem zu lösen. Als Hilfe beim Auswählen eines richtigen SQL-Datentyps kann Ihnen diese Zuordnungstabelle als Hilfe dienen. Geben Sie als bewährte Methode die Zuordnung nur für Spalten an, für die andernfalls die Auflösung in den Datentyp „VARCHAR“ erfolgen würde. Sie können die Leistung von Abfragen verbessern, indem Sie die Verwendung von „VARCHAR“ nach Möglichkeit vermeiden.
Beispiel
Wenn Sie die Datei taxi-data.parquet mit dieser Abfrage 1 abfragen möchten, gibt der serverlose SQL-Pool von Azure Synapse folgende Fehlermeldung zurück:
Die Datei taxi-data.parquet enthält Folgendes:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Abfrage 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Diese Fehlermeldung ist ein Hinweis darauf, dass Datentypen nicht kompatibel sind, und sie enthält den Vorschlag, FLOAT anstelle von INT zu verwenden. Der Fehler wird durch diese Codezeile verursacht:
SumTripDistance INT,
Mit der geringfügig geänderten Abfrage 2 können die Daten jetzt verarbeitet werden, und alle drei Spalten werden angezeigt:
Abfrage 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Die Abfrage verweist auf ein Objekt, das im verteilten Verarbeitungsmodus nicht unterstützt wird
Die Fehlermeldung The query references an object that is not supported in distributed processing mode weist darauf hin, dass Sie ein Objekt oder eine Funktion verwendet haben, die beim Abfragen von Daten in Azure Storage oder im Azure Cosmos DB-Analysespeicher nicht verwendet werden kann.
Einige Objekte wie Systemsichten und Funktionen können nicht verwendet werden, wenn in Azure Data Lake oder im Azure Cosmos DB-Analysespeicher gespeicherte Daten abgefragt werden. Vermeiden Sie die Verwendung von Abfragen, die externe Daten mit Systemsichten verknüpfen, externe Daten in eine temporäre Tabelle laden oder einige Sicherheits- oder Metadatenfunktionen verwenden, um externe Daten zu filtern.
Fehler beim WaitIOCompletion-Aufruf
Die Fehlermeldung WaitIOCompletion call failed gibt an, dass während der Abfrage beim Warten auf den Abschluss des E/A-Vorgangs zum Lesen von Daten aus dem Remotespeicher (Azure Data Lake) ein Fehler aufgetreten ist.
Die Fehlermeldung ist nach folgendem Muster aufgebaut: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Vergewissern Sie sich, dass sich Ihr Speicher in derselben Region wie der serverlose SQL-Pool befindet. Überprüfen Sie die Speichermetriken, und vergewissern Sie sich, dass auf der Speicherebene keine anderen Workloads (wie etwa Hochladen neuer Dateien) vorliegen, die zu einer E/A-Anforderungsüberlastung führen könnten.
Das Feld HRESULT enthält den Ergebniscode. Im Folgenden werden die am häufigsten auftretenden Fehlercodes zusammen mit ihren potenziellen Lösungen aufgelistet.
Dieser Fehlercode bedeutet, dass sich die Quelldatei nicht im Speicher befindet.
Dieser Fehlercode kann aus verschiedenen Gründen auftreten:
- Die Datei wurde von einer anderen Anwendung gelöscht.
- In diesem häufig auftretenden Szenario wird die Abfrageausführung gestartet, und die Dateien werden aufgelistet und gefunden. Später wird während der Ausführung der Abfrage eine Datei gelöscht. Sie könnte z. B. durch Databricks, Spark oder Azure Data Factory gelöscht werden. Die Abfrage ist erfolglos, weil die Datei nicht gefunden wurde.
- Dieses Problem kann auch im Delta-Format auftreten. Die Abfrage kann bei erneuter Ausführung erfolgreich sein, da eine neue Version der Tabelle vorhanden ist und die gelöschte Datei nicht erneut abgefragt wird.
- Ein ungültiger Ausführungsplan wird zwischengespeichert.
- Führen Sie als vorübergehende Gegenmaßnahme den Befehl
DBCC FREEPROCCACHEaus. Wenn das Problem weiterhin besteht, erstellen Sie ein Supportticket.
- Führen Sie als vorübergehende Gegenmaßnahme den Befehl
Falsche Syntax in der Nähe von 'NOT'
Die Fehlermeldung Incorrect syntax near 'NOT' weist darauf hin, dass die Spaltendefinition der Spalten einiger externer Tabellen die Einschränkung NOT NULL enthält.
- Aktualisieren Sie die Tabelle, um NOT NULL aus der Spaltendefinition zu entfernen.
- Dieser Fehler kann manchmal auch vorübergehend bei Tabellen auftreten, die aus einer CETAS-Anweisung erstellt wurden. Wenn das Problem nicht behoben ist, können Sie versuchen, die externe Tabelle zu löschen und neu zu erstellen.
Partitionsspalte gibt NULL-Werte zurück
Wenn Ihre Abfrage NULL-Werte anstelle von Partitionierungsspalten zurückgibt oder die Partitionsspalten nicht finden kann, sind einige Schritte zur Problembehandlung möglich:
- Wenn Sie Tabellen zum Abfragen eines partitionierten Datasets verwenden, beachten Sie, dass Tabellen keine Partitionierung unterstützen. Ersetzen Sie die Tabelle durch die partitionierten Sichten.
- Wenn Sie die partitionierten Sichten mit dem OPENROWSET verwenden, das partitionierte Dateien mithilfe der FILEPATH()-Funktion abfragt, achten Sie darauf, dass Sie das Platzhaltermuster im Speicherort ordnungsgemäß angegeben und den richtigen Index zum Verweis auf den Platzhalter verwendet haben.
- Wenn Sie die Dateien direkt im partitionierten Ordner abfragen, beachten Sie, dass die Partitionierungsspalten nicht Bestandteile der Dateispalten sind. Die Partitionierungswerte werden in den Ordnerpfaden und nicht in den Dateien platziert. Aus diesem Grund enthalten die Dateien nicht die Partitionierungswerte.
Fehler beim Einfügen eines Werts in den Batch für den Spaltentyp DATETIME2.
Der Fehler Inserting value to batch for column type DATETIME2 failed gibt an, dass der serverlose Pool die Datumswerte aus den zugrunde liegenden Dateien nicht lesen kann. Der in der Parquet- oder Delta Lake-Datei gespeicherte datetime-Wert kann nicht als DATETIME2-Spalte dargestellt werden.
Untersuchen Sie den Mindestwert in der Datei mithilfe von Spark, und überprüfen Sie, ob frühere Datumsangaben als 0001-01-03 vorliegen. Wenn Sie die Dateien mithilfe der höheren Spark-Version gespeichert haben, die weiterhin das Legacy-Speicherformat datetime verwendet, werden die datetime-Vorgängerwerte unter Verwendung des julianischen Kalenders geschrieben, der nicht mit dem in serverlosen SQL-Pools verwendeten proleptischen gregorianischen Kalender übereinstimmt.
Es könnte ein Unterschied von 2 Tagen bestehen zwischen dem julianischen Kalender, der (in einigen Spark-Versionen) zum Schreiben der Werte in Parquet verwendet wird, und dem proleptischen gregorianischen Kalender, der im serverlosen SQL-Pool verwendet wird. Dieser Unterschied kann zur Konvertierung in einen (ungültigen) negativen Datumswert führen.
Versuchen Sie, diese Werte mit Spark zu aktualisieren, da sie in SQL als ungültige Datumswerte behandelt werden. Das folgende Beispiel zeigt, wie die Werte, die außerhalb der SQL-Datumsbereiche liegen, in Delta Lake auf NULL aktualisiert werden:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Diese Änderung entfernt die Werte, die nicht dargestellt werden können. Die anderen Datumswerte können vielleicht korrekt geladen werden, werden aber falsch dargestellt, da es noch einen Unterschied zwischen dem julianischen und dem gregorianischen proleptischen Kalender gibt. Wenn Sie Spark 3.0 oder eine ältere Version verwenden, können auch für Daten vor 1900-01-01 unerwartete Datumsverschiebungen auftreten.
Erwägen Sie die Migration zu Spark 3.1 oder einer höheren Version und den Wechsel zum proleptischen gregorianischen Kalender. Die neuesten Spark-Versionen verwenden standardmäßig einen proleptischen gregorianischen Kalender, der mit dem Kalender im serverlosen SQL-Pool übereinstimmt. Laden Sie Ihre Altdaten mit der höheren Version von Spark neu, und verwenden Sie die folgende Einstellung, um die Daten zu korrigieren:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Abfragefehler aufgrund einer Topologieänderung oder eines Computecontainerfehlers
Dieser Fehler kann darauf hindeuten, dass ein internes Prozessproblem im serverlosen SQL-Pool aufgetreten ist. Erstellen Sie ein Supportticket mit allen erforderlichen Details, die dem Azure-Supportteam bei der Untersuchung des Problems helfen könnten.
Beschreiben Sie alles, was im Vergleich zur regulären Workload ungewöhnlich sein könnte. Vielleicht gab es beispielsweise eine große Anzahl gleichzeitiger Anforderungen, oder die Ausführung einer speziellen Workload oder Abfrage begann, bevor dieser Fehler aufgetreten ist.
Timeout für Platzhaltererweiterung
Wie im Abschnitt Abfragen von Ordnern und mehreren Dateien beschrieben, unterstützt der serverlose SQL-Pool das Lesen mehrerer Dateien/Ordner mithilfe von Platzhaltern. Es gibt eine Obergrenze von zehn Platzhalterzeichen pro Abfrage. Sie müssen sich darüber im Klaren sein, dass diese Funktionalität mit einem gewissen Aufwand verbunden ist. Es dauert eine Weile, bis der serverlose Pool alle Dateien auflistet, die dem Platzhalter entsprechen können. Die so entstehende Wartezeit kann sich zusätzlich verlängern, wenn eine große Zahl von Dateien abgefragt wird. In diesem Fall erhalten Sie möglicherweise den folgenden Fehler:
"Wildcard expansion timed out after X seconds."
Sie können verschiedene Maßnahmen ergreifen, um dies zu verhindern:
- Wenden Sie die unter Best Practices für serverlose SQL-Pools beschriebenen bewährten Methoden an.
- Versuchen Sie, die Anzahl der abzufragenden Dateien zu verringern, indem Sie sie in größeren Dateien zusammenfassen. Versuchen Sie, die Dateigrößen über 100 MB zu halten.
- Achten Sie darauf, dass nach Möglichkeit eine Filterung über Partitionierungsspalten durchgeführt wird.
- Wenn Sie das Delta-Dateiformat verwenden, nutzen Sie die Funktion zum optimierten Schreiben in Spark. Dies kann die Leistung von Abfragen verbessern, da weniger Daten gelesen und verarbeitet werden müssen. Informationen zur Verwendung optimierter Schreibvorgänge finden Sie unter Optimieren von Apache Spark-Schreibvorgängen in Delta Lake.
- Zur Vermeidung einiger Platzhalter auf oberster Ebene durch das effiziente Hartcodieren der impliziten Filter über Partitionierungsspalten verwenden Sie dynamisches SQL.
Fehlende Spalte bei Verwendung des automatischen Schemarückschlusses
Sie können mühelos Dateien abfragen, ohne das Schema zu kennen oder anzugeben, indem Sie die WITH-Klausel weglassen. In diesem Fall werden Spaltennamen und Datentypen aus den Dateien abgeleitet. Beachten Sie, dass das Schema beim gleichzeitigen Lesen mehrerer Dateien aus dem ersten Dateidienst abgeleitet wird, der aus dem Speicher abgerufen wird. Dies kann bedeuten, dass einige der erwarteten Spalten weggelassen werden, weil die vom Dienst zum Definieren des Schemas verwendete Datei diese Spalten nicht enthielt. Wenn Sie das Schema explizit angeben möchten, verwenden Sie die Klausel OPENROWSET WITH. Wenn Sie das Schema angeben (mithilfe einer externen Tabelle oder einer OPENROWSET WITH-Klausel), wird der Standardmodus für den laxen Pfad verwendet. Das bedeutet, dass die Spalten, die in einigen Dateien nicht vorhanden sind, als NULL-Werte (für Zeilen aus diesen Dateien) zurückgegeben werden. Um zu verstehen, wie der Pfadmodus verwendet wird, lesen Sie die folgende Dokumentation und das folgende Beispiel.
Konfiguration
Serverlose SQL-Pools ermöglichen die Verwendung von T-SQL zum Konfigurieren von Datenbankobjekten. Hierbei gibt es einige Einschränkungen:
- Sie können keine Objekte in
master- undlakehouse- oder Spark-Datenbanken erstellen. - Sie müssen über einen Hauptschlüssel verfügen, um Anmeldeinformationen zu erstellen.
- Sie müssen über die Berechtigung verfügen, auf Daten zu verweisen, die in den Objekten verwendet werden.
Fehler beim Erstellen einer Datenbank
Wenn der Fehler CREATE DATABASE failed. User database limit has been already reached. angezeigt wird, haben Sie die maximale Anzahl von Datenbanken erstellt, die in einem Arbeitsbereich unterstützt werden. Weitere Informationen finden Sie unter Einschränkungen.
- Wenn Sie die Objekte trennen müssen, verwenden Sie Schemas innerhalb der Datenbanken.
- Wenn Sie auf Azure Data Lake-Speicher verweisen müssen, erstellen Sie Lakehouse-Datenbanken oder Spark-Datenbanken, die im serverlosen SQL-Pool synchronisiert werden.
Fehler beim Erstellen oder Ändern der Tabelle, da die mindeste Zeilengröße die maximal zulässige Tabellenzeilengröße von 8060 Byte überschreitet
Jede Tabelle kann eine Größe von bis zu 8 KB pro Zeile aufweisen (ausschließlich off-row VARCHAR(MAX)/VARBINARY(MAX)-Daten). Wenn Sie eine Tabelle erstellen, in der die Gesamtgröße der Zellen in der Zeile 8060 Byte überschreitet, erhalten Sie den folgenden Fehler:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Dieser Fehler kann auch in der Lake-Datenbank auftreten, wenn Sie eine Spark-Tabelle mit den Spaltengrößen erstellen, die 8060 Bytes überschreiten. Außerdem kann der serverlose SQL-Pool keine Tabelle erstellen, die auf die Spark-Tabellendaten verweist.
Vermeiden Sie als Gegenmaßnahme die Verwendung der Typen fester Größe wie CHAR(N) und ersetzen Sie sie durch VARCHAR(N)-Typen mit variabler Größe, oder verringern Sie die Größe in CHAR(N). Siehe 8 KB Zeilengruppeneinschränkung in SQL Server.
Erstellen Sie einen Hauptschlüssel in der Datenbank, oder öffnen Sie den Hauptschlüssel in der Sitzung, bevor Sie diesen Vorgang ausführen.
Das Auftreten der Fehlermeldung Please create a master key in the database or open the master key in the session before performing this operation. für Ihre Abfrage bedeutet, dass Ihre Benutzerdatenbank derzeit keinen Zugriff auf einen Hauptschlüssel hat.
Vermutlich haben Sie eine neue Benutzerdatenbank erstellt, aber noch keinen Hauptschlüssel.
Erstellen Sie einen Hauptschlüssel mit der folgenden Abfrage, um dieser Problem zu behandeln:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Hinweis
Ersetzen Sie 'strongpasswordhere' hier durch ein anderes Geheimnis.
CREATE-Anweisung wird in der Masterdatenbank nicht unterstützt
Wenn bei Ihrer Abfrage ein Fehler mit dem Hinweis Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database. auftritt, bedeutet dies, dass die master-Datenbank im serverlosen SQL-Pool die Erstellung von Folgendem nicht unterstützt:
- Externe Tabellen.
- Externe Datenquellen.
- Datenbankweit gültige Anmeldeinformationen.
- Externe Dateiformate.
Die Lösung:
Erstellen Sie eine Benutzerdatenbank:
CREATE DATABASE <DATABASE_NAME>Führen Sie eine CREATE-Anweisung im Kontext von <DATABASE_NAME> aus, die zuvor bei der
master-Datenbank erfolglos war.Hier sehen Sie ein Beispiel für die Erstellung eines externen Dateiformats:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Fehler beim Erstellen von Microsoft Entra-Anmeldenamen oder -Benutzer*innen
Wenn beim Erstellen neuer Microsoft Entra-Anmeldenamen oder -Benutzer*innen in einer Datenbank ein Fehler auftritt, überprüfen Sie, welche Anmeldung Sie zum Herstellen einer Verbindung mit Ihrer Datenbank verwendet haben. Der Anmeldename, der versucht, neue Microsoft Entra-Benutzer*innen zu erstellen, muss über die Berechtigung für den Zugriff auf die Microsoft Entra-Domäne verfügen. Überprüfen Sie auch, ob die Benutzer*innen vorhanden sind. Beachten Sie Folgendes:
- SQL-Anmeldenamen verfügen nicht über diese Berechtigung, deshalb erhalten Sie diese Fehlermeldung immer, wenn Sie die SQL-Authentifizierung verwenden.
- Wenn Sie eine Microsoft Entra-Anmeldung verwenden, um neue Anmeldungen zu erstellen, überprüfen Sie, ob Sie über die Berechtigung zum Zugriff auf die Microsoft Entra-Domäne verfügen.
Azure Cosmos DB
Serverlose SQL-Pools ermöglichen Ihnen, den Azure Cosmos DB-Analysespeicher mithilfe der OPENROWSET-Funktion abzufragen. Stellen Sie sicher, dass der Azure Cosmos DB-Container über Analysespeicher verfügt. Stellen Sie sicher, dass Sie Konto, Datenbank und Containername richtig angegeben haben. Stellen Sie außerdem sicher, dass Ihr Azure Cosmos DB-Kontoschlüssel gültig ist. Weitere Informationen finden Sie unter Voraussetzungen.
Azure Cosmos DB kann nicht mithilfe der OPENROWSET-Funktion abgefragt werden
Wenn Sie keine Verbindung mit Ihrem Azure Cosmos DB-Konto herstellen können, sehen Sie sich die Voraussetzungen an. In der folgenden Tabelle werden mögliche Fehler und entsprechende Problembehebungsmaßnahmen aufgelistet.
| Fehler | Grundursache |
|---|---|
| Syntaxfehler: – Falsche Syntax in der Nähe von OPENROWSET.- ... wird nicht als BULK OPENROWSET-Anbieteroption erkannt.– Falsche Syntax in der Nähe von .... |
Mögliche Grundursachen: – Azure Cosmos DB wird nicht als erster Parameter verwendet. – Verwendung eines Zeichenfolgenliterals anstelle eines Bezeichners im dritten Parameter. – Fehlende Angabe des dritten Parameters (Containername). |
| Fehler in der Azure Cosmos DB-Verbindungszeichenfolge. | – Keine Angabe von Konto, Datenbank oder Schlüssel. – Eine Option in einer Verbindungszeichenfolge wird nicht erkannt. – Am Ende einer Verbindungszeichenfolge befindet sich ein Semikolon ( ;). |
| Beim Auflösen des Azure Cosmos DB-Pfads ist der Fehler „Falscher Kontoname“ oder „Falscher Datenbankname“ aufgetreten. | Der angegebene Kontoname, Datenbankname oder Container wurde nicht gefunden, oder der Analysespeicher wurde nicht für die angegebene Sammlung aktiviert. |
| Beim Auflösen des Azure Cosmos DB-Pfads ist der Fehler „Falscher Geheimniswert“ oder „Geheimnis ist NULL oder leer“ aufgetreten. | Der Kontoschlüssel ist nicht gültig oder fehlt. |
Beim Lesen von Azure Cosmos DB-Zeichenfolgentypen wird eine UTF-8-Sortierungswarnung zurückgegeben
Ein serverloser SQL-Pool gibt eine Kompilierzeitwarnung zurück, wenn die OPENROWSET-Spaltensortierung keine UTF-8-Codierung aufweist. Sie können die Standardsortierung für alle OPENROWSET-Funktionen, die in der aktuellen Datenbank ausgeführt werden, ganz einfach mit der T-SQL-Anweisung ändern:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Die Sortierung Latin1_General_100_BIN2_UTF8 bietet die beste Leistung, wenn Sie Ihre Daten mithilfe von Zeichenfolgenprädikaten filtern.
Fehlende Zeilen im Azure Cosmos DB-Analysespeicher
Einige Elemente aus Azure Cosmos DB werden möglicherweise nicht von der OPENROWSET-Funktion zurückgegeben. Beachten Sie Folgendes:
- Zwischen dem Transaktions- und Analysespeicher kommt es zu einer Synchronisierungsverzögerung. Das Dokument, das Sie in den Azure Cosmos DB-Transaktionsspeicher eingegeben haben, wird unter Umständen erst nach zwei oder drei Minuten im Analysespeicher angezeigt.
- Es kann sein, dass das Dokument gegen einige Schemaeinschränkungen verstößt.
Abfrage gibt NUL-Werte in einigen Azure Cosmos DB-Elementen zurück
In den folgenden Fällen gibt Azure Synapse SQL NULL anstelle der Werte zurück, die im Transaktionsspeicher angezeigt werden:
- Zwischen dem Transaktions- und Analysespeicher kommt es zu einer Synchronisierungsverzögerung. Der Wert, den Sie in den Azure Cosmos DB-Transaktionsspeicher eingegeben haben, wird unter Umständen erst nach zwei bis drei Minuten im Analysespeicher angezeigt.
- Möglicherweise enthält die WITH-Klausel einen falschen Spaltennamen oder Pfadausdruck. Der Spaltenname (oder der Pfadausdruck nach dem Spaltentyp) in der WITH-Klausel muss mit den Eigenschaftsnamen in der Azure Cosmos DB-Sammlung übereinstimmen. Beim Vergleich wird die Groß-/Kleinschreibung beachtet. Beispielsweise sind
productCodeundProductCodeunterschiedliche Eigenschaften. Stellen Sie sicher, dass Ihre Spaltennamen genau mit den Azure Cosmos DB-Eigenschaftennamen übereinstimmen. - Die Eigenschaft wird unter Umständen nicht in den Analysespeicher verschoben, da sie gegen einige Schemaeinschränkungen verstößt, z. B. aufgrund von mehr als 1.000 Eigenschaften oder mehr als 127 Schachtelungsebenen.
- Wenn Sie eine klar definierte Schemadarstellung verwenden, weist der Wert im Transaktionsspeicher ggf. einen falschen Typ auf. Bei Verwendung eines klar definierten Schemas werden die Typen für jede Eigenschaft gesperrt, indem Stichproben aus den Dokumenten entnommen werden. Jeder im Transaktionsspeicher hinzugefügte Wert, der nicht mit dem richtigen Typ übereinstimmt, wird als falscher Wert behandelt und nicht zum Analysespeicher migriert.
- Stellen Sie bei der Nutzung einer Schemadarstellung mit vollständiger Genauigkeit sicher, dass Sie nach Eigenschaftennamen wie
$.price.int64das Typsuffix hinzufügen. Falls für den referenzierten Pfad kein Wert angezeigt wird, sind die Daten unter Umständen unter einem anderen Pfadtyp gespeichert, z. B.$.price.float64. Weitere Informationen finden Sie unter Abfragen von Elementen mit einem Schema mit vollständiger Genauigkeit.
Spalte ist mit dem externen Datentyp nicht kompatibel
Der Fehler Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. wird zurückgegeben, wenn der in der WITH-Klausel angegebene Spaltentyp nicht mit dem Typ im Azure Cosmos DB-Container übereinstimmt. Versuchen Sie, den Spaltentyp zu ändern, so wie im Abschnitt Zuordnung von SQL-Typen zu Azure Cosmos DB beschrieben, oder verwenden Sie den Typ VARCHAR.
Fehler beim Auflösen des Cosmos DB-Pfads
Wenn der Fehler Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. angezeigt wird, überprüfen Sie, ob Sie in Azure Cosmos DB private Endpunkte nutzen. Um dem serverlosen SQL-Pool den Zugriff auf einen Analysespeicher mit privatem Endpunkt zu gewähren, müssen Sie private Endpunkte für den Azure Cosmos DB-Analysespeicher konfigurieren.
Azure Cosmos DB-Leistungsprobleme
Wenn unerwartete Leistungsprobleme auftreten, vergewissern Sie sich, dass die bewährten Methoden angewandt wurden, z. B.:
- Stellen Sie sicher, dass Sie die Clientanwendung, den serverlosen Pool und den Azure Cosmos DB-Analysespeicher in derselben Region platziert haben.
- Stellen Sie sicher, dass Sie die WITH-Klausel mit den optimalen Datentypen verwenden.
- Verwenden Sie unbedingt die Sortierung Latin1_General_100_BIN2_UTF8, wenn Sie Ihre Daten mithilfe von Zeichenfolgenprädikaten filtern.
- Wenn Sie wiederholte Abfragen haben, die möglicherweise zwischengespeichert werden, versuchen Sie, CETAS zum Speichern von Abfrageergebnissen in Azure Data Lake Storage zu verwenden.
Delta Lake
Es gibt einige Einschränkungen, die bei der Delta Lake-Unterstützung in serverlosen SQL-Pools ggf. auftreten können:
- Stellen Sie sicher, dass Sie auf den Delta Lake-Stammordner in der OPENROWSET-Funktion oder an einem externen Tabellenspeicherort verweisen.
- Der Stammordner muss über einen Unterordner mit dem Namen
_delta_logverfügen. Die Abfrage ist erfolglos, wenn kein_delta_log-Ordner vorhanden ist. Falls dieser Ordner nicht angezeigt wird, verweisen Sie auf einfache Parquet-Dateien, die über Apache Spark-Pools für Delta Lake konvertiert werden müssen. - Geben Sie keine Platzhalter an, um das Partitionsschema zu beschreiben. Die Delta Lake-Partitionen werden von der Delta Lake-Abfrage automatisch identifiziert.
- Der Stammordner muss über einen Unterordner mit dem Namen
- Delta Lake-Tabellen, die in Apache Spark-Pools erstellt werden, sind automatisch im serverlosen SQL-Pool verfügbar, aber das Schema wird nicht aktualisiert (Einschränkung der öffentlichen Vorschauversion). Wenn Sie Spalten in der Delta-Tabelle mithilfe eines Spark-Pools hinzufügen, werden die Änderungen nicht in der serverlosen SQL-Pooldatenbank angezeigt.
- Externe Tabellen unterstützen keine Partitionierung. Verwenden Sie partitionierte Sichten im Delta Lake-Ordner, um die Partitionsentfernung zu nutzen. Weitere Informationen finden Sie in diesem Artikel in den Abschnitten zu bekannten Problemen und Problemumgehungen.
- Serverlose SQL-Pools unterstützen keine Zeitreiseabfragen. Verwenden Sie Apache Spark-Pools in Synapse Analytics, um Verlaufsdaten zu lesen.
- Serverlose SQL-Pools unterstützen keine Aktualisierung von Delta Lake-Dateien. Sie können einen serverlosen SQL-Pool verwenden, um die neueste Version von Delta Lake abzufragen. Verwenden Sie Apache Spark-Pools in Synapse Analytics, um Delta Lake zu aktualisieren.
- Sie können mit dem CETAS-Befehl keine Abfrageergebnisse im Delta Lake-Format speichern. Der CETAS-Befehl unterstützt nur Parquet und CSV als Ausgabeformate.
- Serverlose SQL-Pools in Synapse Analytics sind mit Delta Reader Version 1 kompatibel.
- Serverlose SQL-Pools in Synapse Analytics unterstützen keine Datasets mit dem BLOOM-Filter. Der serverlose SQL-Pool ignoriert die BLOOM-Filter.
- Delta Lake-Unterstützung ist in dedizierten SQL-Pools nicht verfügbar. Stellen Sie sicher, dass Sie serverlose SQL-Pools verwenden, um Delta Lake-Dateien abzufragen.
- Weitere Informationen zu bekannten Problemen mit serverlosen SQL-Pools finden Sie unter Bekannte Probleme in Azure Synapse Analytics.
Serverlose Unterstützung der Delta 1.0-Version
Serverlose SQL-Pools lesen nur Version Delta Lake 1.0. Serverlose SQL-Pools sind ein Delta Reader mit Ebene 1 und unterstützen die folgenden Features nicht:
- Spaltenzuordnungen werden ignoriert: Serverlose SQL-Pools geben ursprüngliche Spaltennamen zurück.
- Löschvektoren werden ignoriert, und die alte Version von gelöschten/aktualisierten Zeilen wird zurückgegeben (möglicherweise falsche Ergebnisse).
- Die folgenden Delta Lake-Features werden nicht unterstützt: V2-Prüfpunkte, Zeitstempel ohne Zeitzone, VACUUM-Protokollüberprüfung
Löschvektoren werden ignoriert.
Wenn Ihre Delta Lake-Tabelle für die Verwendung von Delta Writer Version 7 konfiguriert ist, werden gelöschte Zeilen und alte Versionen aktualisierter Zeilen in Löschvektoren gespeichert. Da serverlose SQL-Pools die Ebene Delta Reader 1 aufweisen, ignorieren sie die Löschvektoren und erzeugen wahrscheinlich falsche Ergebnisse beim Lesen nicht unterstützter Delta Lake-Version.
Das Umbenennen von Spalten in der Delta-Tabelle wird nicht unterstützt.
Der serverlose SQL-Pool unterstützt das Abfragen von Delta Lake-Tabellen mit den umbenannten Spalten nicht. Der serverlose SQL-Pool kann keine Daten aus der umbenannten Spalte lesen.
Der Wert einer Spalte in der Delta-Tabelle ist NULL.
Wenn Sie ein Delta-Dataset verwenden, für das Delta-Reader Version 2 oder höher erforderlich ist; und Features nutzen, die in Version 1 nicht unterstützt werden (z. B. Umbenennen von Spalten, Löschen von Spalten oder Spaltenzuordnung), werden die Werte in den Spalten, auf die verwiesen wird, möglicherweise nicht angezeigt.
JSON-Text ist nicht korrekt formatiert
Dieser Fehler gibt an, dass der serverlose SQL-Pool das Delta Lake-Transaktionsprotokoll nicht lesen kann. Wahrscheinlich wird der folgende Fehler angezeigt:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Stellen Sie zunächst sicher, dass Ihr Delta Lake-Dataset nicht beschädigt ist. Überprüfen Sie, ob Sie den Inhalt des Delta Lake-Ordners unter Verwendung des Apache Spark-Pools in Azure Synapse lesen können. Auf diese Weise stellen Sie sicher, dass die _delta_log-Datei nicht beschädigt ist.
Problemumgehung
Versuchen Sie, mithilfe eines Apache Spark-Pools einen Prüfpunkt für das Delta Lake-Dataset zu erstellen, und führen Sie die Abfrage erneut aus. Der Prüfpunkt aggregiert transaktionale JSON-Protokolldateien und behebt das Problem möglicherweise.
Wenn das Dataset gültig ist, erstellen Sie ein Supportticket, und geben Sie weitere Informationen an:
- Nehmen Sie keine Änderungen wie das Hinzufügen oder Entfernen der Spalten oder das Optimieren der Tabelle vor, da dies den Status der Delta Lake-Transaktionsprotokolldateien ändern könnte.
- Kopieren Sie den Inhalt des
_delta_log-Ordners in einen neuen leeren Ordner. Kopieren Sie nicht die.parquet data-Dateien. - Versuchen Sie, den Inhalt zu lesen, den Sie in den neuen Ordner kopiert haben, und überprüfen Sie, ob Sie die gleiche Fehlermeldung erhalten.
- Senden Sie den Inhalt der kopierten
_delta_logDatei an Azure-Support.
Jetzt können Sie den Delta Lake-Ordner mit dem Spark-Pool weiter verwenden. Sie stellen dem Microsoft-Support kopierte Daten zur Verfügung, wenn Sie die Berechtigung zur Freigabe dieser Informationen haben. Das Azure-Team überprüft den Inhalt der delta_log-Datei und stellt weitere Informationen zu möglichen Fehlern und Problemumgehungen zur Verfügung.
Fehler beim Auflösen von Delta-Protokollen
Der folgende Fehler gibt an, dass der serverlose SQL-Pool keine Delta-Protokolle auflösen kann: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. Die häufigste Ursache dafür ist, dass last_checkpoint_file im Ordner _delta_log größer als 200 Bytes ist, weil das Feld checkpointSchema in Spark 3.3 hinzugefügt wurde.
Es gibt zwei Möglichkeiten, wie Sie diesen Fehler umgehen können:
- Ändern Sie die entsprechende Konfiguration im Spark-Notebook, und generieren Sie einen neuen Prüfpunkt, sodass
last_checkpoint_fileneu erstellt wird. Wenn Sie Azure Databricks verwenden, sieht die Konfigurationsänderung wie folgt aus:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Führen Sie ein Downgrade auf Spark 3.2.1 durch.
Unser Entwicklungsteam arbeitet derzeit an einer vollständigen Unterstützung für Spark 3.3.
Die in Spark erstellte Delta-Tabelle wird im serverlosen Pool nicht angezeigt.
Hinweis
Die Replikation von Delta-Tabellen, die in Spark erstellt werden, befindet sich noch in der öffentlichen Vorschau.
Wenn Sie eine Delta-Tabelle in Spark erstellt haben, die im serverlosen SQL-Pool nicht angezeigt wird, überprüfen Sie Folgendes:
- Warten Sie einige Zeit (in der Regel 30 Sekunden), da die Spark-Tabellen mit Verzögerung synchronisiert werden.
- Wenn die Tabelle nach einiger Zeit nicht im serverlosen SQL-Pool angezeigt wurde, überprüfen Sie das Schema der Spark-Delta-Tabelle. Spark-Tabellen mit komplexen Typen oder Typen, die in serverlosen Versionen nicht unterstützt werden, sind nicht verfügbar. Versuchen Sie, eine Spark-Parquet-Tabelle mit demselben Schema in einer Lake-Datenbank zu erstellen, und überprüfen Sie, ob diese Tabelle im serverlosen SQL-Pool angezeigt wird.
- Überprüfen Sie, ob die verwaltete Arbeitsbereichsidentität auf den Delta Lake-Ordner zugreifen kann, auf den in der Tabelle verwiesen wird. Der serverlose SQL-Pool verwendet die verwaltete Identität des Arbeitsbereichs, um die Tabellenspalteninformationen aus dem Speicher abzurufen, um die Tabelle zu erstellen.
Lake-Datenbank
Die Lake-Datenbanktabellen, die mithilfe von Spark oder Synapse Designer erstellt werden, stehen automatisch im serverlosen SQL-Pool für Abfragen zur Verfügung. Sie können den serverlosen SQL-Pool verwenden, um die Parquet-, CSV- und Delta Lake-Tabellen abzufragen, die mithilfe von Spark-Pool erstellt wurden, und Ihrer Lake-Datenbank andere Schemata, Sichten, Prozeduren, Tabellenwertfunktionen und Microsoft Entra-Benutzerkonten in der Rolle db_datareader hinzufügen. Mögliche Probleme sind in diesem Abschnitt aufgeführt.
Eine in Spark erstellte Tabelle ist im serverlosen Pool nicht verfügbar.
Tabellen, die erstellt werden, sind möglicherweise nicht sofort im serverlosen SQL-Pool verfügbar.
- Die Tabellen werden mit einer gewissen Verzögerung in serverlosen Pools verfügbar sein. Es kann sein, dass Sie nach der Erstellung einer Tabelle in Spark 5-10 Minuten warten müssen, um sie im serverlosen SQL-Pool zu sehen.
- Nur die Tabellen, die auf die Formate Parquet, CSV und Delta verweisen, sind im serverlosen SQL-Pool verfügbar. Andere Tabellenarten sind nicht verfügbar.
- Eine Tabelle, die einige nicht unterstützte Spaltentypen enthält, ist im serverlosen SQL-Pool nicht verfügbar.
- Der Zugriff auf Delta-Tabellen in Lake-Datenbanken befindet sich in der öffentlichen Vorschauversion. Überprüfen Sie andere Probleme in diesem Abschnitt oder im Abschnitt „Delta Lake“.
Eine in Spark erstellte externe Tabelle zeigt unerwartete Ergebnisse in einem serverlosen Pool an.
Es kann vorkommen, dass zwischen der externen Spark-Quelltabelle und der replizierten externen Tabelle im serverlosen Pool ein Konflikt auftritt. Dies kann passieren, wenn die Dateien, die beim Erstellen externer Spark-Tabellen verwendet werden, keine Erweiterung aufweisen. Um die richtigen Ergebnisse zu erzielen, stellen Sie sicher, dass alle Dateien Erweiterungen wie „.parquet“ haben.
Vorgang ist für eine replizierte Datenbank nicht zulässig
Dieser Fehler wird zurückgegeben, wenn Sie versuchen, eine Lake-Datenbank zu ändern, externe Tabellen, externe Datenquellen, datenbankbezogene Anmeldeinformationen oder andere Objekte in Ihrer Lake-Datenbank zu erstellen. Diese Objekte können nur für SQL-Datenbanken erstellt werden.
Die Lake-Datenbanken werden aus dem Apache Spark-Pool repliziert und von Apache Spark verwaltet. Daher können Sie mithilfe der Sprache T-SQL keine Objekte wie in SQL-Datenbanken erstellen.
Nur die folgenden Vorgänge sind in Lake-Datenbanken zulässig:
- Erstellen, Ablegen oder Ändern von Ansichten, Prozeduren und Inlinetabellen-Wertfunktionen (iTVF) in anderen Schemas als
dbo. - Erstellen und Trennen der Datenbankbenutzer*innen aus Microsoft Entra ID.
- Hinzufügen oder Entfernen von Datenbankbenutzern aus dem
db_datareader-Schema.
Andere Vorgänge sind in Lake-Datenbanken nicht zulässig.
Hinweis
Wenn Sie eine Sicht, Prozedur oder Funktion im dbo-Schema erstellen (oder das Schema auslassen und die Standardeinstellung, in der Regel dbo, verwenden), wird die Fehlermeldung angezeigt.
Delta-Tabellen in Lake-Datenbanken sind im serverlosen SQL-Pool nicht verfügbar
Stellen Sie sicher, dass die verwaltete Identität Ihres Arbeitsbereichs Lesezugriff auf den ADLS-Speicher hat, der den Delta-Ordner enthält. Der serverlose SQL-Pool liest das Delta-Tabellenschema aus den Delta-Protokollen, die in ADLS abgelegt sind, und verwendet die verwaltete Identität des Arbeitsbereichs für den Zugriff auf die Delta-Transaktionsprotokolle.
Versuchen Sie, eine Datenquelle in SQL-Datenbank einzurichten, die mithilfe von Anmeldeinformationen für die verwaltete Identität auf Ihren Azure Data Lake-Speicher verweist, und versuchen Sie, eine externe Tabelle über der Datenquelle mithilfe der verwalteten Identität zu erstellen, um zu bestätigen, dass eine Tabelle mit der verwalteten Identität auf Ihren Speicher zugreifen kann.
Delta-Tabellen in Lake-Datenbanken haben kein identisches Schema in Spark- und serverlosen Pools.
Serverlose SQL-Pools ermöglichen Ihnen den Zugriff auf Parquet-, CSV- und Delta-Tabellen, die in einer Lake-Datenbank mit Spark- oder Synapse-Designer erstellt werden. Der Zugriff auf die Delta-Tabellen befindet sich weiterhin in der öffentlichen Vorschau, und derzeit synchronisiert ein serverloser Pool eine Delta-Tabelle mit Spark zum Zeitpunkt der Erstellung, aktualisiert aber das Schema nicht, wenn die Spalten später mithilfe der ALTER TABLE-Anweisung in Spark hinzugefügt werden.
Dies ist eine Einschränkung der öffentlichen Vorschauversion. Löschen Sie die Delta-Tabelle, und erstellen Sie sie in Spark neu (falls möglich), anstatt Tabellen zu ändern, um dieses Problem zu beheben.
Abfragetimeout oder Leistungsbeeinträchtigung in einer Tabelle
Wenn die ursprüngliche Tabelle in Spark oder Dataverse geändert wird, werden die entsprechenden Tabellen im serverlosen Pool automatisch neu erstellt. Dieser Prozess führt zu einem Verlust vorhandener Statistiken in der Tabelle. Ohne diese Statistiken kann es bei Abfragen der Tabelle zu Verzögerungen oder sogar Timeouts kommen.
Wenn dieses Problem auftritt, sollten Sie einen Auftrag einrichten, um Statistiken zu den Tabellen nach Änderungen in Spark/Dataverse oder nach einem regelmäßigen Zeitplan neu zu erstellen.
Leistung
Der serverlose SQL-Pool weist den Abfragen die Ressourcen auf der Grundlage der Größe des Datasets und der Komplexität der Abfrage zu. Es ist nicht möglich, die für die Abfragen bereitgestellten Ressourcen zu ändern oder zu begrenzen. Es gibt einige Fälle, in denen Sie unerwartete Leistungseinbußen bei Abfragen feststellen können und möglicherweise die Grundursachen dafür identifizieren müssen.
Die Abfragezeit ist sehr lang
Bei Abfragen, deren Abfragedauer 30 Minuten überschreitet, werden die Ergebnisse langsam an den Client zurückgegeben. Für den serverlosen SQL-Pool gilt ein Ausführungsgrenzwert von 30 Minuten. Jegliche weitere Zeit wird für das Ergebnisstreaming genutzt. Probieren Sie die folgenden Problemumgehungen aus:
- Wenn Sie Synapse Studio verwenden, versuchen Sie, die Probleme mit einer anderen Anwendung wie SQL Server Management Studio oder Visual Studio Code zu reproduzieren.
- Wenn Ihre Abfrage langsam ist, wenn sie mithilfe von SQL Server Management Studio, Visual Studio Code, Power BI oder einer anderen Anwendung ausgeführt wird, überprüfen Sie Netzwerkprobleme und bewährte Methoden.
- Platzieren Sie die Abfrage im CETAS-Befehl, und messen Sie die Abfragedauer. Der CETAS-Befehl speichert die Ergebnisse in Azure Data Lake Storage und hängt nicht von der Clientverbindung ab. Wenn der CETAS-Befehl schneller als die ursprüngliche Abfrage abgeschlossen ist, überprüfen Sie die Bandbreite der Netzwerkverbindung zwischen Client und serverlosem SQL-Pool.
Langsame Abfrage bei Ausführung mit Synapse Studio
Wenn Sie Synapse Studio verwenden, versuchen Sie, einen Desktopclient wie SQL Server Management Studio oder Visual Studio Code zu verwenden. Synapse Studio ist ein Webclient, der mithilfe des HTTP-Protokolls eine Verbindung mit serverlosen SQL-Pool herstellt, was im Allgemeinen langsamer als die systemeigenen SQL-Verbindungen ist, die in SQL Server Management Studio oder Visual Studio Code verwendet werden.
Langsame Abfrage bei Ausführung mit einer Anwendung
Prüfen Sie, ob die folgenden Probleme vorliegen, wenn die Abfrageausführung langsam ist:
- Stellen Sie sicher, dass die Client-Anwendungen mit dem Endpunkt des serverlosen SQL-Pools verbunden sind. Die Ausführung einer Abfrage über die Region hinweg kann zusätzliche Wartezeit und langsames Streaming der Ergebnismenge verursachen.
- Stellen Sie sicher, dass Sie keine Netzprobleme haben, die ein langsames Streaming der Ergebnismenge verursachen können
- Vergewissern Sie sich, dass die Client-Anwendung über genügend Ressourcen verfügt (z. B. keine 100%ige CPU-Auslastung).
- Stellen Sie sicher, dass sich das Speicherkonto oder der Azure Cosmos DB-Analysespeicher in derselben Region wie Ihr serverloser SQL-Endpunkt befindet.
Siehe die bewährten Praktiken für die Zusammenfassung von Ressourcen.
Starke Schwankungen in der Abfragedauer
Wenn Sie bei mehreren Ausführungen derselben Abfrage Schwankungen in der Abfragedauer beobachten, kann dies mehrere Ursachen haben:
- Überprüfen Sie, ob dies die erste Ausführung einer Abfrage ist. Bei der ersten Ausführung einer Abfrage werden die für die Erstellung eines Plans erforderlichen Statistiken gesammelt. Die Statistiken werden durch das Scannen der zugrunde liegenden Dateien gesammelt und können die Abfragedauer erhöhen. In Synapse Studio sehen Sie in der Liste der SQL-Anforderungen Abfragen zur „Erstellung globaler Statistiken“, die vor Ihrer Abfrage ausgeführt werden.
- Statistiken laufen möglicherweise nach einiger Zeit ab. In regelmäßigen Abständen könnten Sie eine Beeinträchtigung der Leistung feststellen, da der serverlose Pool die Statistiken scannen und neu erstellen muss. Vielleicht bemerken Sie weitere Abfragen zur „Erstellung globaler Statistiken" in der Liste der SQL-Anforderungen, die vor Ihrer Abfrage ausgeführt werden.
- Prüfen Sie, ob eine andere Workload auf demselben Endpunkt ausgeführt wurde, als Sie die Abfrage mit der längeren Dauer ausführten. Der serverlose SQL-Endpunkt verteilt die Ressourcen gleichmäßig auf alle parallel ausgeführten Abfragen, und die Abfrage wird möglicherweise verzögert.
Verbindungen
Mit einem serverlosen SQL-Pool können Sie eine Verbindung mithilfe des TDS-Protokolls herstellen und Daten mit der Programmiersprache T-SQL abfragen. Die meisten Tools, die eine Verbindung mit SQL Server oder Azure SQL-Datenbank herstellen können, können auch eine Verbindung mit serverlosen SQL-Pools herstellen.
SQL-Pool wird aufgewärmt
Der serverlos SQL-Pool wird nach einem längeren Zeitraum der Inaktivität deaktiviert. Die Aktivierung erfolgt automatisch bei der nächsten Aktivität, z. B. dem ersten Verbindungsversuch. Der Aktivierungsprozess kann etwas länger dauern als ein einzelner Verbindungsversuch, daher wird die Fehlermeldung angezeigt. Es sollte ausreichend sein, den Verbindungsversuch zu wiederholen.
Es hat sich bewährt, für Clients, die dies unterstützen, die Schlüsselwörter ConnectionRetryCount und ConnectRetryInterval in der Verbindungszeichenfolge zu verwenden, um das Verhalten bei erneuten Verbindungen zu steuern. Die meisten SQL-Clienttreiber haben das standardmäßige Verbindungstimeout auf 15 Sekunden festgelegt. Stellen Sie sicher, dass das Verbindungstimeout so konfiguriert ist, dass alle Wiederholungsversuche zulässig sind. Die ausgewählten Werte sollten beispielsweise die folgende Bedingung erfüllen: Verbindungstimeout > ConnectRetryCount * ConnectionRetryInterval.
Wenn die Fehlermeldung weiterhin angezeigt wird, erstellen Sie über das Azure-Portal ein Supportticket.
Es ist nicht möglich, eine Verbindung von Synapse Studio herzustellen
Siehe den Abschnitt Synapse Studio.
Eine Verbindung mit dem Azure Synapse-Pool kann nicht über ein Tool hergestellt werden
Einige Tools verfügen möglicherweise nicht über eine explizite Option, mit der Sie eine Verbindung mit dem serverlosen SQL-Pool in Azure Synapse herstellen können. Verwenden Sie eine Option, mit der Sie eine Verbindung mit SQL Server oder SQL-Datenbank herstellen. Das Verbindungsdialogfeld muss nicht „Synapse“ enthalten, da der serverlose SQL-Pool das gleiche Protokoll wie SQL Server oder SQL-Datenbank verwendet.
Selbst wenn Sie mit einem Tool nur einen logischen Servernamen und die vordefinierte Domäne database.windows.net eingeben können, fügen Sie den Namen des Azure Synapse-Arbeitsbereichs gefolgt vom Suffix -ondemand und der Domäne database.windows.net ein.
Sicherheit
Stellen Sie sicher, dass die Benutzer über Berechtigungen für den Zugriff auf Datenbanken, Berechtigungen zum Ausführen von Befehlen und Berechtigungen für den Zugriff auf Azure Data Lake oder Azure Cosmos DB-Speicher verfügen.
Zugriff auf ein Azure Cosmos DB-Konto nicht möglich
Sie müssen einen schreibgeschützten Azure Cosmos DB-Schlüssel verwenden, um auf Ihren Analysespeicher zuzugreifen. Stellen Sie daher sicher, dass er nicht abgelaufen ist und nicht neu generiert wurde.
Wenn Sie die Fehlermeldung Beim Auflösen des Azure Cosmos DB-Pfads ist ein Fehler aufgetreten erhalten, stellen Sie sicher, dass Sie eine Firewall konfiguriert haben.
Kein Zugriff auf Lakehouse- oder Spark-Datenbank
Wenn Benutzer nicht auf eine Lakehouse- oder Spark-Datenbank zugreifen können, verfügen sie möglicherweise nicht über Berechtigungen zum Zugreifen auf die Datenbank und zum Lesen der Datenbank. Benutzer mit der Berechtigung CONTROL SERVER sollten Vollzugriff auf alle Datenbanken haben. Als eingeschränkte Berechtigung können Sie CONNECT ANY DATABASE und SELECT ALL USER SECURABLES verwenden.
Kein Zugriff auf Dataverse-Tabellen durch SQL-Benutzer
Dataverse-Tabellen greifen mithilfe der Microsoft Entra-Identität der aufrufenden Funktion auf den Speicher zu. Ein SQL-Benutzer mit umfangreichen Berechtigungen versucht möglicherweise, Daten aus einer Tabelle auszuwählen, aber die Tabelle kann nicht auf Dataverse-Daten zugreifen. Dieses Szenario wird nicht unterstützt.
Microsoft Entra-Dienstprinzipal-Anmeldefehler, wenn der SPI eine Rollenzuweisung erstellt
Wenn Sie eine Rollenzuweisung für einen Dienstprinzipalbezeichner (Service Principal Identifier, SPI) oder eine Microsoft Entra-App mithilfe eines anderen SPI erstellen möchten oder wenn Sie bereits eine erstellt haben und sich nicht anmelden können, erhalten Sie wahrscheinlich folgende Fehlermeldung: Login error: Login failed for user '<token-identified principal>'..
Für Dienstprinzipale sollte die Anmeldung mit einer Anwendungs-ID als Sicherheits-ID (SID) erstellt werden, nicht mit einer Objekt-ID. Eine bekannte Einschränkung für Dienstprinzipale verhindert, dass der Azure Synapse-Dienst die Anwendungs-ID aus Microsoft Graph abruft, wenn eine Rollenzuweisung für eine andere SPI oder App erstellt wird.
Lösung 1
Navigieren Sie zum Azure-Portal>Synapse Studio>Verwalten>Zugriffssteuerung, und fügen Sie Synapse-Administrator oder Synapse SQL-Administrator für den gewünschten Dienstprinzipal manuell hinzu.
Lösung 2
Sie müssen eine ordnungsgemäße Anmeldung manuell mit SQL-Code erstellen:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Lösung 3
Sie können einen Dienstprinzipal-Azure-Synapse-Administrator auch mithilfe von PowerShell einrichten. Das Az.Synapse-Modul muss installiert sein.
Die Lösung besteht in der Verwendung des Cmdlets New-AzSynapseRoleAssignment mit -ObjectId "parameter". Geben Sie in diesem Parameterfeld die Anwendungs-ID anstelle der Objekt-ID mithilfe der Dienstprinzipal-Anmeldeinformationen des Arbeitsbereichsadministrators für Azure an.
PowerShell-Skript:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Hinweis
In diesem Fall zeigt die Synapse Data Studio-Benutzeroberfläche nicht die von der oben beschriebenen Methode hinzugefügte Rollenzuweisung an. Daher wird empfohlen, die Rollenzuweisung gleichzeitig sowohl der Objekt-ID als auch der Anwendungs-ID hinzuzufügen, damit sie auch auf der Benutzeroberfläche angezeigt werden kann.
New-AzSynapseRoleAssignment -WorkspaceName „<workspaceName>“-RoleDefinitionName „Synapse Administrator“ -ObjectId „<object_id_to_add_as_admin>“ [-Debug]
Überprüfung
Stellen Sie eine Verbindung mit dem serverlosen SQL Endpunkt her, und überprüfen Sie, ob die externe Anmeldung mit der SID (app_id_to_add_as_admin im vorherigen Beispiel) erstellt wurde:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Versuchen Sie alternativ, sich über den serverlosen SQL-Endpunkt mit der festgelegten Administrator-App anzumelden.
Einschränkungen
Einige allgemeine Systemeinschränkungen könnten sich auf Ihre Workload auswirken:
| Eigenschaft | Einschränkung |
|---|---|
| Maximale Anzahl von Azure Synapse-Arbeitsbereichen pro Abonnement | Siehe Grenzwerte. |
| Maximale Anzahl von Datenbanken pro serverlosem Pool | 100 (ohne Datenbanken, die aus einem Apache Spark-Pool synchronisiert werden). |
| Maximale Anzahl von Datenbanken, die aus einem Apache Spark-Pool synchronisiert werden | Nicht begrenzt. |
| Maximale Anzahl von Datenbankobjekten pro Datenbank | Die Summe aller Objekte in einer Datenbank darf nicht höher als 2.147.483.647 sein. Siehe Einschränkungen in SQL Server-Datenbank-Engine. |
| Maximale Bezeichnerlänge in Zeichen | 128 (siehe Einschränkungen in SQL Server-Datenbank-Engine). |
| Maximale Abfragedauer | 30 Minuten |
| Maximale Größe des Resultsets | Bis zu 400 GB zur gemeinsamen Nutzung durch gleichzeitig ausgeführte Abfragen. |
| Maximale Parallelität | Nicht begrenzt und abhängig von der Komplexität der Abfrage und der Menge der gescannten Daten. Ein serverloser SQL-Pool kann gleichzeitig 1.000 aktive Sitzungen behandeln, die einfache Abfragen ausführen. Die Zahlen sinken, wenn die Abfragen komplexer sind oder eine größere Datenmenge gescannt wird. In diesem Fall sollten Sie daher in Betracht ziehen, die Parallelität zu verringern und Abfragen nach Möglichkeit über einen längeren Zeitraum auszuführen. |
| Maximale Größe des Namens der externen Tabelle | 100 Zeichen. |
Fehler beim Erstellen einer Datenbank im serverlosen SQL-Pool
Für serverlose SQL-Pools gelten Einschränkungen, und Sie können nicht mehr als 100 Datenbanken pro Arbeitsbereich erstellen. Wenn Sie Objekte trennen und isolieren müssen, verwenden Sie Schemas.
Wenn der Fehler CREATE DATABASE failed. User database limit has been already reached angezeigt wird, haben Sie die maximale Anzahl von Datenbanken erstellt, die in einem Arbeitsbereich unterstützt werden.
Sie müssen keine separaten Datenbanken verwenden, um Daten für verschiedene Mandanten zu isolieren. Alle Daten werden extern in einem Data Lake und in Azure Cosmos DB gespeichert. Die Metadaten wie Tabelle, Sichten, Funktionsdefinitionen können mithilfe von Schemas erfolgreich isoliert werden. Die schemabasierte Isolation wird auch in Spark verwendet, wobei Datenbanken und Schemas die gleichen Konzepte sind.