In diesem Artikel wird gezeigt, wie Sie einen Suchdienst erstellen, mit dem Benutzer nach Dokumenten suchen können. Dieser Dienst berücksichtigt nicht nur den Inhalt der Dokumente, sondern auch die Metadaten, die mit den Dateien verknüpft sind.
Sie können diesen Dienst implementieren, indem Sie mehrere Indexer in Azure AI Search verwenden.
In diesem Artikel wird anhand einer Beispielworkload veranschaulicht, wie ein einzelner Suchindex erstellt wird, der auf Dateien in Azure Blob Storage basiert. Die Datei Metadaten wird in Azure Table Storage gespeichert.
Architektur
Laden Sie eine PowerPoint-Datei zu dieser Architektur herunter.
Datenfluss
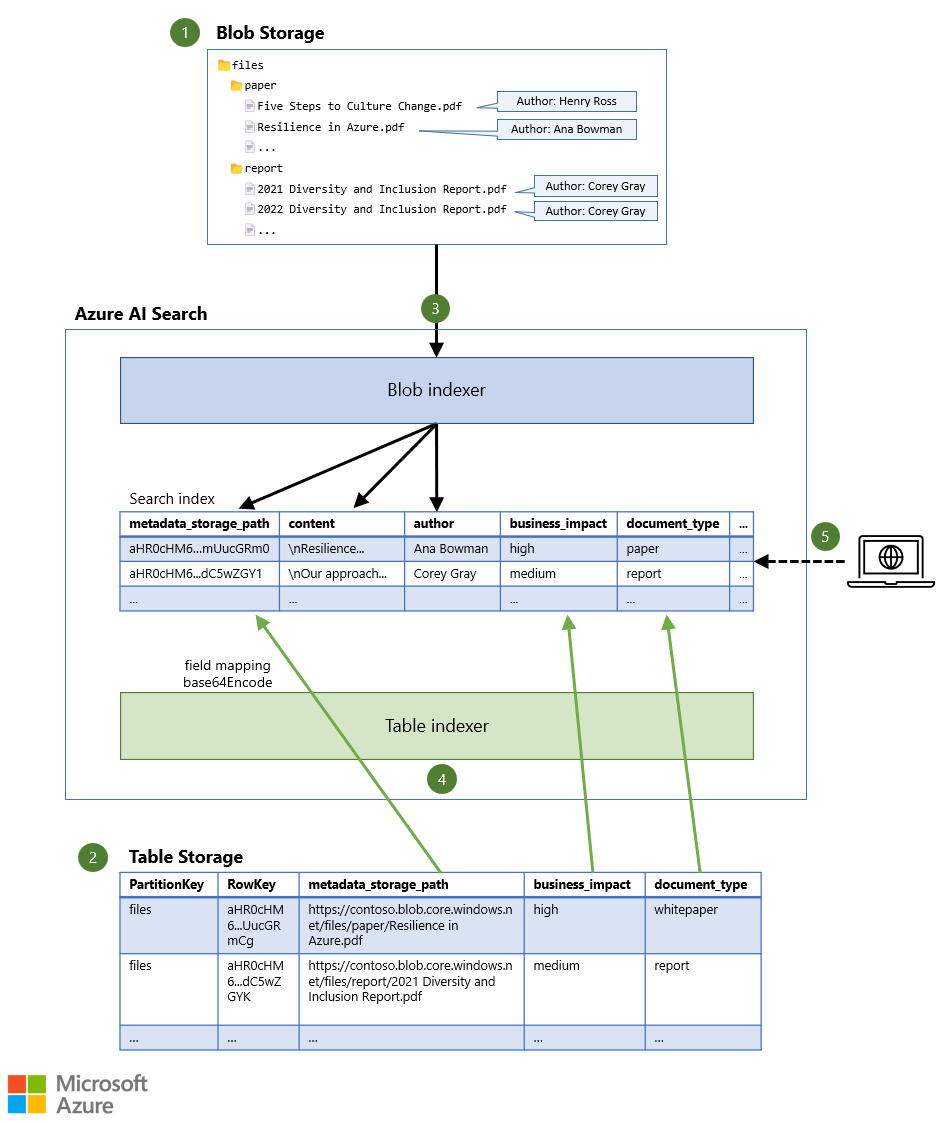
- Dateien werden in Blob Storage gespeichert, möglicherweise zusammen mit einer begrenzten Menge an Metadaten (z. B. dem Autor des Dokuments).
- Zusätzliche Metadaten werden in Table Storage gespeichert, wo deutlich mehr Informationen für jedes Dokument gespeichert werden können.
- Ein Indexer liest den Inhalt jeder Datei zusammen mit allen Blob-Metadaten und speichert die Daten im Suchindex.
- Ein anderer Indexer liest die zusätzlichen Metadaten aus der Tabelle und speichert sie im gleichen Suchindex.
- Eine Suchabfrage wird an den Suchdienst gesendet. Die Abfrage gibt übereinstimmende Dokumente basierend auf Dokumentinhalten und Dokumentmetadaten zurück.
Komponenten
- Blob Storage bietet kostengünstigen Cloud-Speicher für Dateidaten, einschließlich Daten in Formaten wie PDF, HTML und CSV sowie in Microsoft 365-Dateien.
- Table Storage bietet Speicher für nicht relationale strukturierte Daten. In diesem Szenario wird es verwendet, um die Metadaten für jedes Dokument zu speichern.
- Azure KI Search ist ein vollständig verwalteter Suchdienst, der Infrastruktur, APIs und Tools zum Erstellen einer umfassenden Suchumgebung bereitstellt.
Alternativen
In diesem Szenario werden Indexer in Azure AI Search verwendet, um automatisch neue Inhalte in unterstützten Datenquellen wie Blob- und Tabellenspeicher zu ermitteln und dann dem Suchindex hinzuzufügen. Alternativ können Sie die von Azure AI Search bereitgestellten APIs verwenden, um Daten per Push an den Suchindex zu übergeben. In diesem Fall müssen Sie jedoch Code schreiben, um die Daten in den Suchindex zu pushen und auch Text aus den binären Dokumenten zu analysieren und zu extrahieren, die Sie durchsuchen möchten. Der Blob Storage-Indexer unterstützt viele Dokumentformate, was die Textextraktion und -indizierung erheblich vereinfacht.
Wenn Sie Indexer verwenden, können Sie außerdem die Daten optional als Teil einer Indizierungspipeline anreichern. Sie können zum Beispiel Azure AI Services verwenden, um optische Zeichenerkennung (OCR) oder visuelle Analyse der Bilder in Dokumenten durchzuführen, die Sprache von Dokumenten zu erkennen oder Dokumente zu übersetzen. Sie können auch Ihre eigenen benutzerdefinierten Fähigkeiten definieren, um die Daten Ihrem Geschäftsszenario entsprechend anzureichern.
Diese Architektur verwendet Blob- und Tabellenspeicher, da sie kostengünstig und effizient sind. Dieser Entwurf ermöglicht auch die kombinierte Speicherung der Dokumente und Metadaten in einem einzigen Speicherkonto. Alternative unterstützte Datenquellen für die Dokumente selbst sind Azure Data Lake Storage und Azure Files. Dokumentmetadaten können in jeder anderen unterstützten Datenquelle gespeichert werden, die strukturierte Daten enthalten kann, z. B. Azure SQL Database und Azure Cosmos DB.
Szenariodetails
Durchsuchen von Dateiinhalten
Mit dieser Lösung können Benutzer basierend sowohl auf Dateiinhalten als auch auf zusätzlichen Metadaten, die für jedes Dokument separat gespeichert werden, nach Dokumenten suchen. Zusätzlich zum Durchsuchen des Textinhalts eines Dokuments kann ein Benutzer nach dem Autor des Dokuments, dem Dokumenttyp (z. B. Paper oder Bericht) oder dessen geschäftliche Auswirkung (hoch, mittel oder niedrig) suchen.
Azure AI Search ist ein vollständig verwalteter Suchdienst, der Suchindizes erstellen kann, die die Informationen enthalten, nach denen Sie die Benutzer suchen lassen möchten.
Da es sich bei den in diesem Szenario durchsuchten Dateien um binäre Dokumente handelt, können Sie sie in Blob Storage speichern. Wenn sie dies tun, können Sie den integrierten Blob Storage-Indexer in Azure AI Search verwenden, um automatisch Text aus den Dateien zu extrahieren und deren Inhalt dem Suchindex hinzuzufügen.
Durchsuchen der Dateimetadaten
Wenn Sie zusätzliche Informationen zu den Dateien einschließen möchten, können Sie den Blobs direkt Metadaten zuordnen, ohne einen separaten Speicher zu verwenden. Der integrierte Blob Storage-Suchindexer kann diese Metadaten sogar lesen und im Suchindex ablegen. Dies ermöglicht es den Benutzern, neben dem Dateiinhalt auch nach Metadaten zu suchen. Die Menge der Metadaten ist jedoch auf 8 KB pro Blob beschränkt, sodass die Menge an Informationen, die Sie in jedem Blob platzieren können, relativ klein ist. Möglicherweise möchten Sie nur die wichtigsten Informationen direkt in den Blobs speichern. In diesem Szenario wird nur der Autor des Dokuments im Blob gespeichert.
Um diese Speicherbeschränkung zu umgehen, können Sie zusätzliche Metadaten in einer anderen Datenquelle platzieren, die über einen unterstützten Indexer verfügt, z. B. Table Storage. Sie können den Dokumenttyp, die geschäftliche Auswirkung und andere Metadatenwerte als separate Spalten in der Tabelle hinzufügen. Wenn Sie den integrierten Table Storage-Indexer so konfigurieren, dass er auf denselben Suchindex wie der Blob-Indexer ausgerichtet ist, werden die Blob- und Tabellenspeichermetadaten für jedes Dokument im Suchindex kombiniert.
Verwenden mehrerer Datenquellen für einen einzelnen Suchindex
Um sicherzustellen, dass beide Indexer auf dasselbe Dokument im Suchindex zeigen, wird der Dokumentschlüssel im Suchindex auf einen eindeutigen Bezeichner der Datei festgelegt. Dieser eindeutige Bezeichner wird dann verwendet, um in beiden Datenquellen auf die Datei zu verweisen. Der Blob-Indexer verwendet standardmäßig metadata_storage_path als Dokumentschlüssel. Die Eigenschaft metadata_storage_path speichert die vollständige URL der Datei in Blob Storage, z. B. https://contoso.blob.core.windows.net/files/paper/Resilience in Azure.pdf. Der Indexer führt die Base64-Codierung für den Wert durch, um sicherzustellen, dass der Dokumentschlüssel keine ungültigen Zeichen enthält. Das Ergebnis ist ein eindeutiger Dokumentschlüssel, z. B. aHR0cHM6...mUucGRm0.
Wenn Sie metadata_storage_path in Table Storage als Spalte hinzufügen, wissen Sie genau, zu welchem Blob die Metadaten in den anderen Spalten gehören, sodass Sie in der Tabelle beliebige Werte für PartitionKey und RowKey verwenden können. Sie können beispielsweise den Blob-Containernamen als PartitionKey und die Base64-codierte vollständige URL des Blobs als RowKeyverwenden, um sicherzustellen, dass auch in diesen Schlüsseln keine ungültigen Zeichen vorhanden sind.
Anschließend können Sie eine Feldzuordnung im Tabellenindexer verwenden, um die Spalte metadata_storage_path (oder eine andere Spalte) in Table Storage dem Dokumentschlüsselfeld metadata_storage_path im Suchindex zuzuordnen. Wenn Sie die base64Encode-Funktion auf die Feldzuordnung anwenden, erhalten Sie denselben Dokumentschlüssel (aHR0cHM6...mUucGRm0 im vorherigen Beispiel), und die Metadaten aus Table Storage werden demselben Dokument hinzugefügt, das aus Blob Storage extrahiert wurde.
Hinweis
In der Dokumentation zum Tabellenindexer wird angegeben, dass Sie keine Feldzuordnung zu einem alternativen eindeutigen Zeichenfolgenfeld in Ihrer Tabelle definieren sollten. Das liegt daran, dass der Indexer PartitionKey und RowKey standardmäßig als Dokumentschlüssel verkettet. Da Sie sich bereits auf den vom Blob-Indexer konfigurierten Dokumentschlüssel (dabei handelt es sich um die base64-codierte vollständige URL des Blobs) verlassen, ist die Erstellung einer Feldzuordnung, die sicherstellt, dass beide Indexer im Suchindex auf dasselbe Dokument verweisen, für dieses Szenario angemessen und wird unterstützt.
Alternativ können Sie RowKey (der auf die Base64-codierte vollständige URL des Blobs festgelegt ist) direkt dem Dokumentschlüssel metadata_storage_path zuordnen, ohne ihn separat zu speichern und als Teil der Feldzuordnung base64 zu codieren. Durch das Beibehalten der nicht codierten URL in einer separaten Spalte lässt sich jedoch feststellen, auf welches Blob sie sich bezieht, und Sie können beliebige Partitions- und Zeilenschlüssel wählen, ohne dass sich dies auf den Suchindexer auswirkt.
Mögliche Anwendungsfälle
Dieses Szenario gilt für Anwendungen, die eine Suche nach Dokumenten auf der Grundlage ihres Inhalts und zusätzlicher Metadaten ermöglichen sollen.
Überlegungen
Diese Überlegungen bilden die Säulen des Azure Well-Architected Framework, einer Reihe von Leitprinzipien, die Sie zur Verbesserung der Qualität eines Workloads verwenden können. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Zuverlässigkeit
Zuverlässigkeit stellt sicher, dass die Anwendung Ihre Verpflichtungen gegenüber den Kunden erfüllen kann. Weitere Informationen finden Sie in der Überblick über die Säule „Zuverlässigkeit“.
Azure KI-Suche bietet eine Vereinbarung für einen hohen Servicelevel (SLA) für Lesevorgänge (Abfragen), wenn Sie über mindestens zwei Replikate verfügen. Es bietet eine hohe SLA für Updates (Aktualisieren der Suchindizes), wenn Sie über mindestens drei Replikate verfügen. Daher sollten Sie mindestens zwei Replikate bereitstellen, wenn Sie möchten, dass Ihre Kunden zuverlässig suchen können. Stellen Sie drei Replikate bereit, wenn die tatsächlichen Änderungen am Index ebenfalls Hochverfügbarkeitsvorgänge sein müssen.
Azure Storage speichert immer mehrere Kopien Ihrer Daten, um sie vor geplanten und ungeplanten Ereignissen zu schützen. Azure Storage bietet zusätzliche Redundanzoptionen für die regionsübergreifende Replikation von Daten. Diese Sicherheitsvorkehrungen gelten für Daten im Blob- und Tabellenspeicher.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Azure AI Search bietet robuste Sicherheitskontrollen, die Sie bei der Implementierung von Netzwerksicherheit, Authentifizierung und Autorisierung, Datenresidenz und -schutz sowie administrativen Kontrollen unterstützen, die Ihnen helfen, Sicherheit, Datenschutz und Compliance zu gewährleisten.
Verwenden Sie nach Möglichkeit die Microsoft Entra-Authentifizierung, um den Zugriff auf den Suchdienst selbst bereitzustellen, und verbinden Sie Ihren Suchdienst mit anderen Azure-Ressourcen (z. B. in diesem Szenario: Blob- und Tabellenspeicher), indem Sie eine verwaltete Identität verwenden.
Sie können mithilfe eines privaten Endpunkts eine Verbindung vom Suchdienst mit dem Speicherkonto herstellen. Wenn Sie einen privaten Endpunkt verwenden, können die Indexer eine private Verbindung verwenden, ohne dass der Blob- und Tabellenspeicher öffentlich zugänglich sein muss.
Kostenoptimierung
Bei der Kostenoptimierung geht es darum, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Informationen zu den Kosten für die Ausführung dieses Szenarios finden Sie in dieser vorkonfigurierten Schätzung im Azure-Preisrechner. Alle hier beschriebenen Dienste sind in diese Schätzung einbezogen. Die Schätzung gilt für eine Workload mit einer Gesamtdokumentgröße von 20 GB in Blob Storage und 1 GB Metadaten in Table Storage. Zwei Sucheinheiten werden verwendet, um die SLA für Lesezwecke zu erfüllen, wie im Abschnitt Zuverlässigkeit dieses Artikels beschrieben. Wenn Sie wissen möchten, welche Kosten für Ihren spezifischen Anwendungsfall entstehen, können Sie die entsprechenden Variablen an Ihre voraussichtliche Nutzung anpassen.
Wenn Sie sich die Schätzung genauer ansehen, werden Sie feststellen, dass die Kosten für Blob- und Tabellenspeicher relativ niedrig sind. Der größte Teil der Kosten fällt für Azure AI Search an, da hier die eigentliche Indizierung und Berechnung für die Ausführung von Suchanfragen durchgeführt wird.
Bereitstellen dieses Szenarios
Informationen zum Bereitstellen dieser Beispielworkload finden Sie unter Indizieren von Dateiinhalten und Metadaten in Azure AI Search. Sie können dieses Beispiel für Folgendes verwenden:
- Erstellen der erforderlichen Azure-Dienste.
- Hochladen einiger Beispieldokumente in Blob Storage.
- Befüllen des Metadatenwerts für den Autor im Blob.
- Speichern der Metadatenwerte für den Dokumenttyp und die geschäftliche Auswirkung in Table Storage.
- Erstellen der Indexer, die den Suchindex verwalten.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Jelle Druyts | Principal Customer Experience Engineer
Andere Mitwirkende:
- Mick Alberts | Technical Writer
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Erste Schritte mit Azure AI Search
- Erhöhen der Relevanz mithilfe der semantischen Suche in Azure AI Search
- Sicherheitsfilter zum Einschränken von Ergebnissen in Azure KI Search
- Tutorial: Indizieren von mehreren Datenquellen mithilfe des .NET SDK