Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In der Azure KI-Suche bezieht sich die KI-Anreicherung auf die Integration mit Azure KI-Diensten auf, um Inhalte zu verarbeiten, für deren Rohform keine Suche möglich ist. Durch Anreicherung, Analyse und Rückschließen werden durchsuchbare Inhalte und Strukturen geschaffen, wo vorher keine vorhanden waren.
Azure KI-Suche wird für Text- und Vektorabfragen verwendet, und der Zweck der KI-Anreicherung besteht darin, den Nutzen Ihrer Inhalte in suchbezogenen Szenarien zu verbessern. Unformatierter Inhalt muss Text oder Bilder sein (Sie können Vektoren nicht anreichern), aber die Ausgabe einer Anreicherungspipeline kann vektorisiert und in einem Suchindex mithilfe von Fähigkeiten wie der Text-Split-Fähigkeit für die Aufteilung in Teile und der AzureOpenAIEmbedding-Fähigkeit für die Vektorcodierung indiziert werden. Weitere Informationen zur Verwendung von Skills in Vektorszenarien finden Sie unter Integrierte Datenblockerstellung und Einbettung.
KI-Anreicherung basiert auf Fähigkeiten.
Integrierte Fähigkeiten für Azure KI Services. Sie wenden die folgenden Transformationen und Verarbeitungsschritte auf unverarbeitete Inhalte an:
- Übersetzungs- und Spracherkennung für mehrsprachige Suche
- Entitätserkennung, um Personennamen, Orte und andere Entitäten aus großen Textblöcken zu extrahieren
- Schlüsselbegriffserkennung, um wichtige Begriffe zu identifizieren und auszugeben
- Optische Zeichenerkennung (Optical Character Recognition, OCR), um gedruckten und handschriftlichen Text in Binärdateien zu erkennen
- Bildanalyse, um Bildinhalte zu beschreiben, und die Beschreibungen als durchsuchbare Textfelder auszugeben
Benutzerdefinierte Fähigkeiten führen Ihren externen Code aus. Benutzerdefinierte Fertigkeiten können für jede benutzerdefinierte Verarbeitung verwendet werden, die Sie in die Pipeline aufnehmen möchten.
Die KI-Anreicherung ist eine Erweiterung einer Indexerpipeline, die eine Verbindung mit Azure-Datenquellen herstellt. Eine Anreicherungspipeline enthält alle Komponenten einer Indexerpipeline (Indexer, Datenquelle, Index) sowie ein skillset, das atomare Anreicherungsschritte angibt.
Das folgende Diagramm zeigt den Fortschritt der KI-Anreicherung:
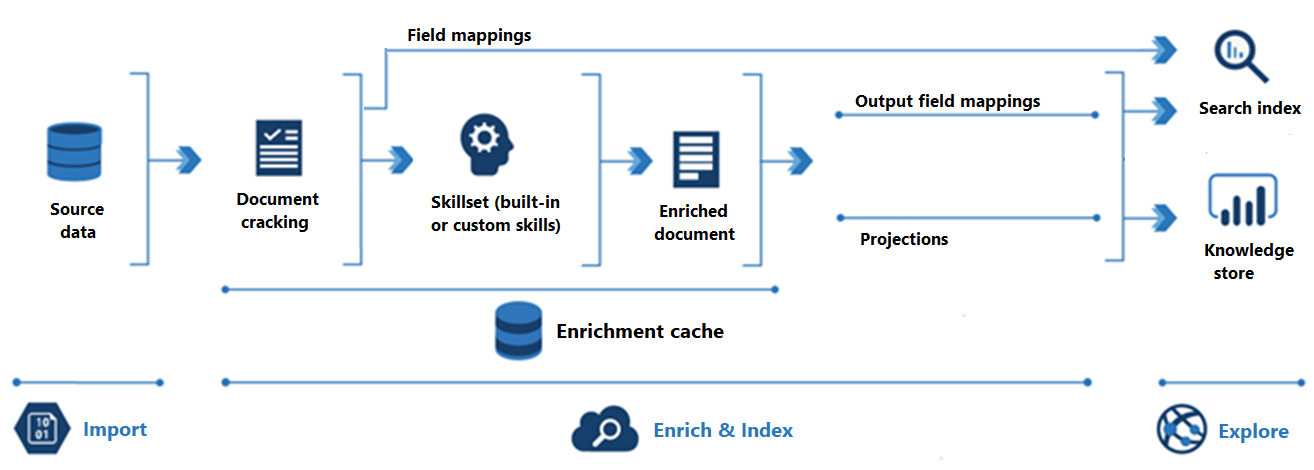
Importieren ist der erste Schritt. Hier stellt der Indexer eine Verbindung mit einer Datenquelle her und pullt Inhalte (Dokumente) in den Suchdienst. Azure Blob Storage ist die am häufigsten verwendete Ressource in KI-Anreicherungsszenarien, aber jede unterstützte Datenquelle kann Inhalte bereitstellen.
Anreichern und Index umfasst den Großteil der KI-Anreicherungspipeline:
Die Anreicherung beginnt, wenn der Indexer „Dokumente bricht“ und Bilder und Text extrahiert. Die nächste Art der Verarbeitung hängt davon ab, welche Daten Sie verwenden und welche Skills Sie einem Skillset hinzugefügt haben. Wenn Sie Bilder haben, können sie an Fertigkeiten weitergeleitet werden, die die Bildverarbeitung ausführen. Textinhalte werden für die Verarbeitung von Text und natürlicher Sprache in eine Warteschlange gestellt. Intern erstellen Fertigkeiten ein „angereichtertes Dokument“, das die Transformationen erfasst, während sie auftreten.
Angereicherte Inhalte werden während der Ausführung des Skillsets generiert und sind temporär, es sei denn, Sie speichern sie. Sie können einen Anreicherungs-Cache aktivieren, um geknackte Dokumente und Skill-Ausgaben für die spätere Wiederverwendung bei zukünftigen Skillset-Ausführungen beizubehalten.
Um Inhalte in einen Suchindex zu bekommen, muss der Indexer über Zuordnungsinformationen verfügen, um angereicherte Inhalte an das Zielfeld zu senden. Feldzuordnungen (explizit oder implizit) legen den Datenpfad von Quelldaten zu einem Suchindex fest. Ausgabefeld-Zuordnungen legen den Datenpfad von angereicherten Dokumenten zu einem Index fest.
Die Indizierung ist der Prozess, bei dem rohe und angereicherte Inhalte in die physischen Datenstrukturen eines Suchindex (seine Dateien und Ordner) aufgenommen werden. Lexikalische Analyse und Tokenisierung erfolgen in diesem Schritt.
Erkundung ist der letzte Schritt. Die Ausgabe ist immer ein Suchindex, den Sie aus einer Client-App abfragen können. Die Ausgabe kann optional ein Wissensspeicher sein, der aus Blobs und Tabellen in Azure Storage besteht, auf die über Datenexplorierungstools oder nachgelagerte Prozesse zugegriffen wird. Wenn Sie einen Wissensspeicher erstellen, bestimmen Projektionen den Datenpfad für angereicherte Inhalte. Derselbe angereicherte Inhalt kann sowohl in Indizes als auch in Wissensspeichern erscheinen.
Einsatzgebiete der KI-Anreicherung
Die Anreicherung ist hilfreich, wenn es sich bei Ihren unformatierten Inhalten um unstrukturierten Text, um Bildinhalte oder um Inhalte handelt, für die Spracherkennung und -übersetzung benötigt werden. Die Anwendung von KI durch die eingebauten Fertigkeiten kann diese Inhalte für die Volltextsuche und Data-Science-Anwendungen erschließen.
Sie können auch benutzerdefinierte Fähigkeiten für die externe Bearbeitung erstellen. Open-Source-Code oder Code von Drittanbietern oder Erstanbietern kann als benutzerdefinierte Fertigkeit in die Pipeline integriert werden. Zu dieser Kategorie gehören Klassifizierungsmodelle, mit denen wichtige Merkmale verschiedener Dokumenttypen identifiziert werden. Es könnte aber jedes beliebige externe Paket verwendet werden, das den Nutzen Ihrer Inhalte erhöht.
Anwendungsfälle für integrierte Skills
Integrierte Skills basieren auf den folgenden APIs von Azure KI Services: Maschinelles Sehen von Azure KI und Sprachdienst. Bei der Ausführung größerer Workloads müssen Sie wahrscheinlich eine abrechenbare Azure KI Services-Ressource anfügen.
Ein Skillset mit integrierten Fähigkeiten eignet sich sehr gut für die folgenden Anwendungsszenarien:
Zu den Funktionen der Bildverarbeitung gehören Optical Character Recognition (OCR) und die Identifizierung von visuellen Merkmalen, wie z. B. Gesichtserkennung, Bildinterpretation, Bilderkennung (berühmte Personen und Wahrzeichen) oder Attribute wie Bildausrichtung. Diese Skills erstellen Textdarstellungen von Bildinhalten für die Volltextsuche in Azure KI Search.
Die Maschinenübersetzung wird durch die Fertigkeit Textübersetzung bereitgestellt, oft gepaart mit Spracherkennung für mehrsprachige Lösungen.
Natürliche Sprachverarbeitung analysiert Textblöcke. Fertigkeiten in dieser Kategorie umfassen die Entitätserkennung, die Stimmungserkennung (einschließlich Opinion Mining) und die Erkennung personenbezogener Informationen. Mit diesen Fähigkeiten wird unstrukturierter Text in Form von durchsuchbaren und filterbaren Feldern in einem Index zugeordnet.
Anwendungsfälle für benutzerdefinierte Skills
Benutzerdefinierte Skills führen externen Code aus, den Sie bereitstellen und in der Webschnittstelle für benutzerdefinierte Skills umschließen. Einige Beispiele für benutzerdefinierte Skills finden Sie im GitHub-Repository azure-search-power-skills.
Benutzerdefinierte Fertigkeiten sind nicht immer komplex. Wenn Sie z. B. über ein bestehendes Paket verfügen, das einen Musterabgleich oder ein Dokumentenklassifizierungsmodell bereitstellt, können Sie es mit einer benutzerdefinierten Fertigkeit umschließen.
Speichern der Ausgabe
In Azure KI Search speichert ein Indexer die von ihm erstellte Ausgabe. Ein einzelner Indexer kann bis zu drei Datenstrukturen erstellen, die eine angereicherte und indizierte Ausgabe enthalten.
| Datenspeicher | Erforderlich | Standort | BESCHREIBUNG |
|---|---|---|---|
| durchsuchbarer Index | Erforderlich | Suchdienst | Wird für die Volltextsuche und andere Abfrageformulare verwendet. Die Angabe eines Indexes ist eine Indexeranforderung. Indexinhalte werden aus den Fertigkeitsausgaben sowie allen Quellfeldern gefüllt, die direkt den Feldern im Index zugeordnet sind. |
| Wissensspeicher | Wahlfrei | Azure Storage | Wird für nachgelagerte Apps wie Knowledge Mining oder Data Science verwendet. Ein Wissensspeicher wird durch ein Skillset definiert. Seine Definition bestimmt, ob Ihre angereicherten Dokumente als Tabellen oder Objekte (Dateien oder Blobs) in Azure Storage projiziert werden. |
| Anreicherungscache | Wahlfrei | Azure Storage | Wird für Zwischenspeicher-Anreicherungen zum Wiederverwenden in nachfolgenden Skillset-Ausführungen verwendet. Der Cache speichert importierte, nicht verarbeitete Inhalte (gespaltene Dokumente). Er speichert auch die angereicherten Dokumente, die während der Skillset-Ausführung erstellt wurden. Die Zwischenspeicherung ist hilfreich, wenn Ihr Skillset Bildanalyse oder OCR umfasst und Sie Zeit und Kosten für die erneute Verarbeitung von Bilddateien vermeiden möchten. |
Indizes und Wissensspeicher sind vollständig unabhängig voneinander. Sie müssen zwar einen Index anfügen, um die Indexeranforderungen zu erfüllen, aber wenn Ihr einziges Ziel ein Wissensspeicher ist, können Sie den Index ignorieren, nachdem er aufgefüllt wurde.
Erkunden von Inhalten
Nachdem Sie einen Suchindex oder einen Wissensspeicher definiert und geladen haben, können Sie seine Daten erkunden.
Abfragen eines Suchindex
Führen Sie Abfragen aus, um auf die von der Pipeline generierten angereicherten Inhalte zuzugreifen. Der Index ist wie jeder andere Index, den Sie für Azure KI Search erstellen können: Sie können die Textanalyse durch benutzerdefinierte Analysen ergänzen, Fuzzysuchabfragen aufrufen, Filter hinzufügen oder zur Optimierung der Suchrelevanz mit Bewertungsprofilen experimentieren.
Verwenden von Datenexplorationstools für einen Wissensspeicher
In Azure Storage kann ein Wissensspeicher die folgenden Formen annehmen: Blobcontainer mit JSON-Dokumenten, Blobcontainer mit Bildobjekten oder Tabellen in Table Storage. Sie können Storage Explorer, Power BI oder eine beliebige App verwenden, die eine Verbindung mit Azure Storage herstellt, um auf Ihre Inhalte zuzugreifen.
Ein Blobcontainer erfasst angereicherte Dokumente in ihrer Gesamtheit, was nützlich ist, wenn Sie einen Feed für andere Prozesse erstellen.
Eine Tabelle ist nützlich, wenn Sie Segmente von angereicherten Dokumenten benötigen oder bestimmte Teile der Ausgabe ein- oder ausschließen möchten. Für die Analyse in Power BI sind Tabellen die empfohlene Datenquelle für die Datenuntersuchung und -visualisierung in Power BI.
Verfügbarkeit und Preismodell
Die Anreicherung ist in Regionen mit Azure KI Services verfügbar. Sie können die Verfügbarkeit der Anreicherung auf der Seite Regionenliste überprüfen.
Die Abrechnung folgt einem Standard-Preismodell. Die Kosten für die Verwendung integrierter Skills werden weitergegeben, wenn ein multiregionaler Azure KI Services-Schlüssel im Skillset angegeben ist. Auch bei der Bildextraktion fallen Kosten an, die von Azure KI Search berechnet werden. Fertigkeiten zur Textextraktion und Hilfsprogramme sind jedoch nicht abrechenbar. Weitere Informationen finden Sie unter Kosten von Azure KI Search.
Prüfliste: Typischer Workflow
Eine Anreicherungspipeline besteht aus Indexern, die über bestimmte Skillsets verfügen. Nach der Indizierung können Sie einen Index abfragen, um Ihre Ergebnisse zu validieren.
Beginnen Sie mit einer Teilmenge von Daten in einer unterstützten Datenquelle. Die Entwicklung von Indexern und Skillsets ist ein iterativer Prozess. Mit einem kleinen repräsentativen Datensatz geht die Arbeit schneller.
Erstellen Sie eine Datenquelle, die eine Verbindung zu Ihren Daten angibt.
Erstellen eines Skillsets. Sofern Ihr Projekt nicht klein ist, sollten Sie eine Azure AI-Dienste-Multi-Service-Ressource anfügen. Wenn Sie einen Wissensspeicher erstellen, definieren Sie ihn im Rahmen des Skillsets.
Erstellen Sie ein Indexschema, das einen Suchindex definiert.
Erstellen Sie einen Indexer, der alle oben genannten Komponenten zusammenführt, und führen Sie ihn aus. Dieser Schritt ruft die Daten ab, führt das Skillset aus und lädt den Index.
Ein Indexer ist auch der Ort, an dem Sie Feldzuordnungen und Ausgabefeldzuordnungen angeben, die den Datenpfad zu einem Suchindex einrichten.
Optional können Sie das Anreicherungs-Caching aktivieren in der Indexer-Konfiguration. Mit diesem Schritt können Sie vorhandene Anreicherungen später wiederverwenden.
Führen Sie Abfragen ausum die Ergebnisse zu bewerten, oderstarten Sie eine Debugging-Sitzung um Probleme mit dem Skill-Set zu lösen.
Um einen der oben genannten Schritte zu wiederholen, setzen Sie den Indexer zurück, bevor Sie ihn ausführen. Alternativ können Sie die Objekte bei jeder Ausführung löschen und neu erstellen (empfohlen, wenn Sie den Free-Tarif verwenden). Bei aktivierter Zwischenspeicherung pullt der Indexer Daten aus dem Cache, wenn sich die Daten in der Quelle nicht geändert haben und Ihre Pipelinebearbeitungen den Cache nicht ungültig machen.