Kundenaktivitäten erforderlich
Vor dem Vorfall
Für Azure-Dienste
- Machen Sie sich mit Azure Service Health im Azure-Portal vertraut. Diese Seite dient während eines Vorfalls als zentrale Anlaufstelle.
- Ziehen Sie die Verwendung von Service Health-Warnungen in Betracht. Diese können so konfiguriert werden, dass sie bei Azure-Vorfällen automatisch Benachrichtigungen generieren.
Für Power BI
- Machen Sie sich mit Service Health im Microsoft 365 Admin Center vertraut. Diese Seite dient während eines Vorfalls als zentrale Anlaufstelle.
- Erwägen Sie die Verwendung der mobilen App Microsoft 365 Admin, um automatische Benachrichtigungen über Dienstvorfälle zu erhalten.
Während des Vorfalls
Für Azure-Dienste
- Azure Service Health innerhalb des Azure-Verwaltungsportals stellt die neuesten Updates bereit
- Wenn Probleme beim Zugriff auf Service Health auftreten, beachten Sie die Informationen auf der Seite Azure-Status.
- Wenn es einmal Probleme beim Zugriff auf die Statusseite geben sollte, wechseln Sie zu @AzureSupport auf X ( ehemals Twitter)
- Wenn die Auswirkungen/Probleme nicht zum Vorfall passen (oder nach der Entschärfung weiter bestehen), kontaktieren Sie den Support, um ein Supportticket zu öffnen.
Für Power BI
- Auf der Seite Dienststatus im Microsoft 365 Admin Center werden die neuesten Updates bereitgestellt
- Wenn Probleme beim Zugriff auf Service Health auftreten, beachten Sie die Informationen auf der Seite zum Microsoft 365-Status.
- Wenn die Auswirkungen/Probleme nicht zum Vorfall passen (oder nach der Entschärfung weiter bestehen), sollten Sie ein Supportticket öffnen.
Nach der Wiederherstellung durch Microsoft
Weitere Informationen finden Sie in den folgenden Abschnitten.
Nach einem Vorfall
Für Azure-Dienste
- Microsoft veröffentlicht einen PIR (Post Incident Report) zur Überprüfung in Azure-Portal – Service Health.
Für Power BI
- Microsoft veröffentlicht einen PIR (Post Incident Report) zur Überprüfung in Microsoft 365 Admin Center – Service Health.
Prozess „Warten auf Microsoft“
Der Prozess „Warten auf Microsoft“ bedeutet einfach, dass Sie abwarten, bis Microsoft alle Komponenten und Dienste in der betroffenen primären Region wiederhergestellt hat. Überprüfen Sie nach der Wiederherstellung die Bindung der Datenplattform an gemeinsam genutzte Unternehmensdienste oder andere Dienste sowie das Datum des Datasets. Führen Sie anschließend die erforderlichen Prozesse aus, um das System auf den aktuellen Stand zu bringen.
Sobald dieser Vorgang abgeschlossen ist, kann eine Validierung durch technische und geschäftliche Fachleute (SME) durchgeführt werden, um die Dienstwiederherstellung durch die Projektbeteiligten zu bestätigen.
Neubereitstellung bei einem Notfall
Für eine Strategie zur Neubereitstellung bei einem Notfall kann der folgende allgemeine Prozessablauf beschrieben werden.
Wiederherstellung von Contoso – gemeinsam genutzte Unternehmensdienste und Quellsysteme

- Dieser Schritt ist eine Voraussetzung für die Wiederherstellung der Datenplattform.
- Er wird von den verschiedenen Contoso-Gruppen für den operativen Support durchgeführt, die für die gemeinsam genutzten Unternehmensdienste und die operativen Quellsysteme verantwortlich sind.
Wiederherstellung der Azure-Dienste: Der Begriff „Azure-Dienste“ bezieht sich auf die Anwendungen und Dienste, aus denen sich das Azure-Cloudangebot zusammensetzt und die in der sekundären Region für die Bereitstellung zur Verfügung stehen.

Der Begriff „Azure-Dienste“ bezieht sich auf die Anwendungen und Dienste, aus denen sich das Azure-Cloudangebot zusammensetzt und die in der sekundären Region für die Bereitstellung zur Verfügung stehen.
- Dieser Schritt ist eine Voraussetzung für die Wiederherstellung der Datenplattform.
- Dieser Schritt würde von Microsoft und anderen Platform-as-a-Service (PaaS)-/Software-as-a-Service (SaaS)-Partnern durchgeführt werden.
Wiederherstellung der grundlegenden Systeme der Datenplattform
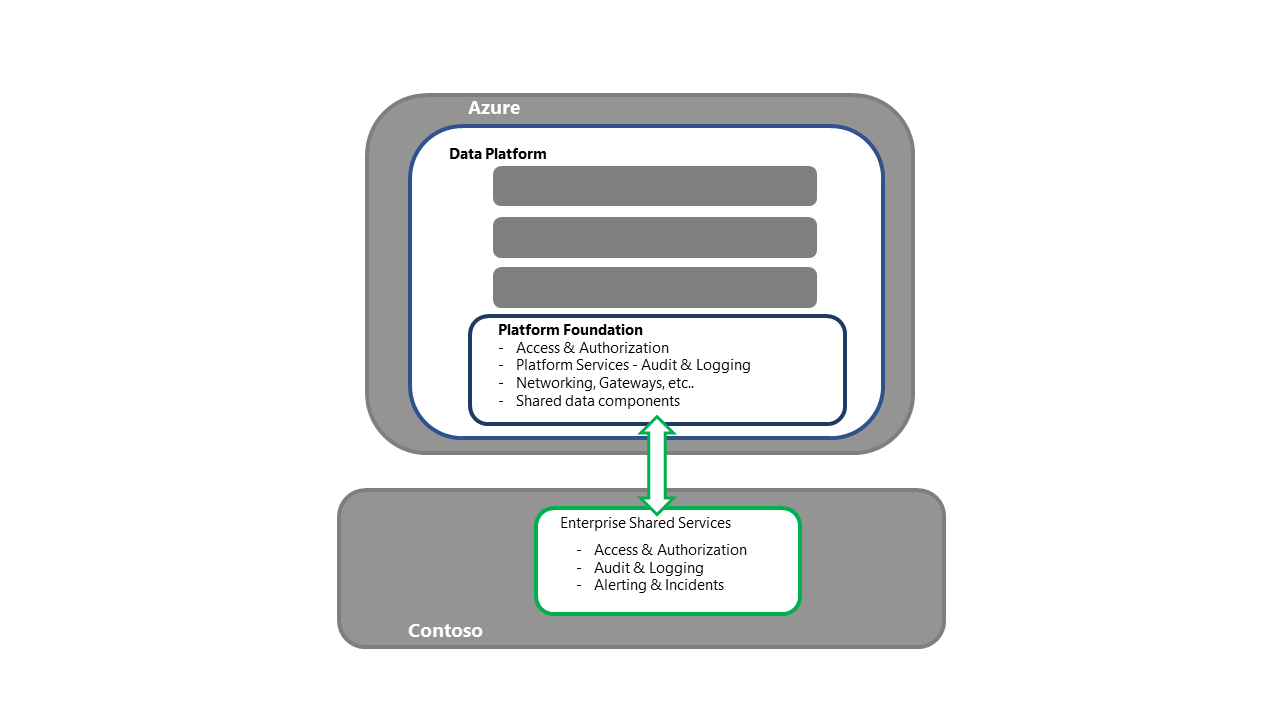
- Dieser Schritt ist der Einstiegspunkt für die Aktivitäten zur Plattformwiederherstellung.
- Für die Strategie einer Neubereitstellung wird jede benötigte Komponente/jeder Dienst beschafft und in der sekundären Region bereitgestellt
- Im Abschnitt Azure-Dienst und Komponenten dieser Reihe finden Sie eine detaillierte Aufschlüsselung der Komponenten und Bereitstellungsstrategien.
- Dieser Prozess sollte auch Aktivitäten wie die Bindung an die gemeinsam genutzten Unternehmensdienste, das Sicherstellen der Verbindung per Zugriff/Authentifizierung und die Überprüfung der ordnungsgemäßen Funktion der Protokollabladung umfassen, während gleichzeitig die Konnektivität mit vor- und nachgelagerten Prozessen sichergestellt wird.
- Daten und Verarbeitung müssen überprüft werden. Beispielsweise muss der Zeitstempel der wiederhergestellten Plattform validiert werden
- Wenn Zweifel hinsichtlich der Datenintegrität bestehen, kann ein Rollback auf einen früheren Zeitpunkt erwogen werden, bevor die Plattform durch Ausführung der neuen Prozesse auf den neuesten Stand gebracht wird.
- Eine Prioritätsreihenfolge für Prozesse (basierend auf den geschäftlichen Auswirkungen) hilft bei der Orchestrierung der Wiederherstellung.
- Dieser Schritt sollte durch eine technische Überprüfung ergänzt werden, sofern die Geschäftsbenutzer nicht direkt mit den Diensten interagieren. Bei direktem Zugriff ist ein Schritt zur Geschäftsvalidierung erforderlich.
- Sobald die Validierung abgeschlossen ist, erfolgt eine Übergabe an die einzelnen Lösungsteams, damit diese ihren eigenen Prozess für die Notfallwiederherstellung (DR) starten können.
- Diese Übergabe sollte eine Bestätigung des aktuellen Zeitstempels der Daten/Prozesse beinhalten.
- Wenn zentrale Unternehmensdatenprozesse ausgeführt werden sollen, müssen die verschiedenen Lösungsteams darüber in Kenntnis gesetzt werden – z. B. in Bezug auf eingehende/ausgehende Datenflüsse.
Wiederherstellung der einzelnen Lösungen, die von der Plattform gehostet werden
- Für jede Lösung sollte ein eigenes Runbook für die Notfallwiederherstellung vorhanden sein. Die Runbooks sollten dabei zumindest die vorgesehenen geschäftlichen Projektbeteiligten enthalten, die für den Test und zur Bestätigung der erfolgten Dienstwiederherstellung zuständig sind
- In Abwägung von Ressourcenkonflikten oder Prioritäten können wichtige Lösungen/Workloads anderen vorgezogen werden – z. B. Kernprozesse des Unternehmens gegenüber Ad-hoc-Labs.
- Sobald die Validierungsschritte durchgeführt wurden, erfolgt eine Übergabe an die nachgelagerten Lösungsteams, um deren Prozess zur Notfallwiederherstellung zu starten.
Übergabe an nachgelagerte, abhängige Systeme
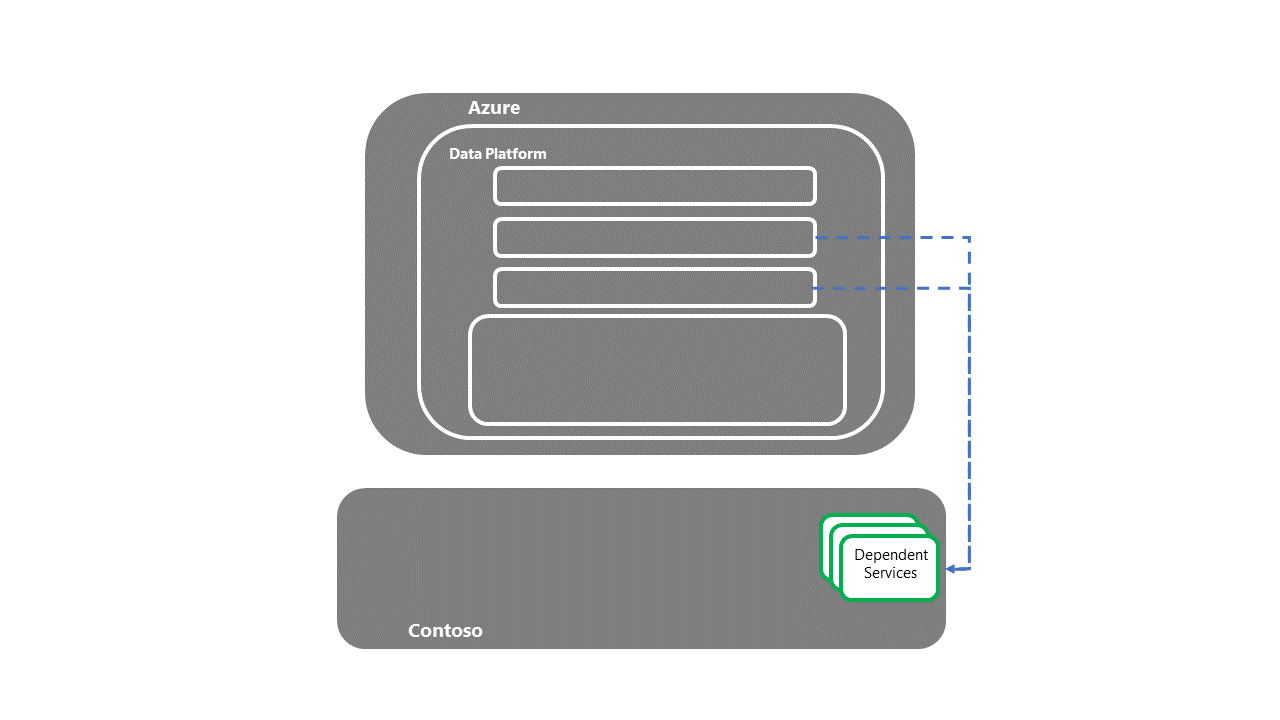
- Sobald die abhängigen Dienste wiederhergestellt wurden, ist der Prozess zur E2E-Notfallwiederherstellung (End-to-End) abgeschlossen.
Hinweis
Obwohl es theoretisch möglich ist, einen Prozess zur E2E-Notfallwiederherstellung vollständig zu automatisieren, ist dies angesichts des Risikos des Ereignisses im Vergleich zu den Kosten der zur Abdeckung des E2E-Prozesses erforderlichen SDLC-Aktivitäten unwahrscheinlich.
Fallback auf primäre Region: Ein Fallback ist der Prozess, bei dem der Datenplattformdienst und die zugehörigen Daten in die primäre Region zurückverlagert werden, sobald diese wieder für den normalen Geschäftsbetrieb zur Verfügung stehen.
Je nach Art der Quellsysteme und der verschiedenen Datenprozesse kann ein Fallback der Datenplattform unabhängig von anderen Teilen des Datenökosystems erfolgen.
Kunden wird empfohlen, die Abhängigkeiten ihrer eigenen Datenplattform zu überprüfen (sowohl vor- als auch nachgelagert), um die richtige Entscheidung zu treffen. Im folgenden Abschnitt wird von einer unabhängigen Wiederherstellung der Datenplattform ausgegangen.
- Sobald alle erforderlichen Komponenten/Dienste in der primären Region wieder verfügbar sind, führen die Kunden eine Feuerprobe durch, um die Wiederherstellung durch Microsoft zu bestätigen.
- Validierung der Komponenten-/Dienstkonfiguration. Abweichungen werden durch eine Neubereitstellung über die Quellcodeverwaltung behoben.
- Das Systemdatum in der primären Region wird über zustandsabhängige Komponenten festgelegt. Die Abweichung zwischen dem festgelegten Datum und dem Datums-/Zeitstempel in der sekundären Region sollte durch eine erneute Ausführung oder Wiedergabe der Datenerfassungsprozesse von diesem Zeitpunkt an behoben werden.
- Mit Genehmigung durch die geschäftlichen und technischen Projektbeteiligten wird ein Fallbackfenster ausgewählt. Im Idealfall sollte dieses Zeitfenster in einer Phase mit geringer System- und Verarbeitungsaktivität liegen.
- Während des Fallbacks wird die primäre Region mit der sekundären Region synchronisiert, bevor das System umgeschaltet wird.
- Nach einer gewissen Zeit des Parallelbetriebs wird die sekundäre Region offline geschaltet.
- Je nach gewählter Strategie für die Notfallwiederherstellung werden die Komponenten in der sekundären Region entweder getrennt oder entfernt.
Warm-Spare-Prozess
Bei einer „Warm-Spare“-Strategie ist der allgemeine Prozessablauf eng an die Strategie zur Neubereitstellung bei einem Notfall angelehnt. Der Hauptunterschied besteht darin, dass die Komponenten in der sekundären Region bereits beschafft wurden. Bei dieser Strategie entfällt das Risiko von Ressourcenkonflikten mit anderen Organisationen, die ihre eigene Notfallwiederherstellung in dieser Region durchführen möchten.
Hot-Spare-Prozess
Bei der „Hot-Spare“-Strategie bleiben die Plattformdienste (PaaS- und Infrastructure-as-a-Service (IaaS)-Systeme eingeschlossen) auch im Katastrophenfall erhalten, da die sekundären Systeme parallel zu den primären Systemen betrieben werden. Wie bei der „Warm-Spare“-Strategie entfällt bei dieser Strategie das Risiko von Ressourcenkonflikten mit anderen Organisationen, die ihre eigene Notfallwiederherstellung in dieser Region durchführen möchten.
Kunden mit einem Hot-Spare-System überwachen die Wiederherstellung der Komponenten/Dienste in der primären Region durch Microsoft. Nach Abschluss der Wiederherstellung validieren die Kunden die Systeme der primären Region und führen ein Fallback zur primären Region durch. Dieser Prozess ähnelt dem Failoverprozess bei der Notfallwiederherstellung, d. h. die verfügbare Codebasis und die Daten werden überprüft und bei Bedarf neu bereitgestellt.
Hinweis
Achten Sie hier besonders darauf, dass alle Systemmetadaten zwischen den beiden Regionen konsistent sind.
- Sobald das Fallback auf die primäre Region abgeschlossen ist, können die Lastenausgleichsmodule des Systems aktualisiert werden, um die primäre Region wieder in die Systemtopologie aufzunehmen. Sofern verfügbar, kann ein Canary-Release-Ansatz genutzt werden, um die primäre Region stufenweise für das System zu aktivieren.
Aufbau des Notfallwiederherstellungsplans
Ein effizienter DR-Plan enthält eine Schrittanleitung für die Dienstwiederherstellung, die von einem Mitglied des technischen Azure-Teams ausgeführt werden kann. Deshalb wird im Folgenden eine MVP-Struktur für einen Notfallwiederherstellungsplan vorgeschlagen.
- Verfahrensanforderungen
- Alle kundenspezifischen Details für den Notfallwiederherstellungsprozess, z. B. die richtige Autorisierung zum Starten der Notfallwiederherstellung, das Treffen wichtiger Entscheidungen zur Wiederherstellung nach Bedarf (einschließlich der Definition, wann eine Aufgabe als erledigt gilt), Referenz zur Erstellung eines Supporttickets für die Notfallwiederherstellung und Details zur Notfallzentrale.
- Bestätigung der verantwortlichen Personen, einschließlich Leitung der Notfallwiederherstellung (DR) und einer Stellvertretung für die ausführenden Mitarbeiter. Alle Beteiligten sollten mit primären und sekundären Kontakten, Eskalationspfaden und Urlaubskalendern dokumentiert werden. In kritischen Notfallsituationen müssen möglicherweise Dienstplansysteme in Betracht gezogen werden.
- Laptop, Netzteile und/oder Notstromversorgung, Netzwerkkonnektivität und Mobiltelefondaten für den DR-Verantwortlichen, die DR-Stellvertretung und alle Eskalationspunkte.
- Der zu befolgende Prozess, wenn eine der Prozessanforderungen nicht erfüllt ist.
- Kontaktlisten
- DR-Leitung und Supportgruppen
- Geschäftliche Fachleute, die den Test-/Überprüfungszyklus für die technische Wiederherstellung durchführen
- Betroffene geschäftliche Besitzer, einschließlich der für die Bestätigung der Dienstwiederherstellung zuständigen Personen
- Betroffene technische Besitzer, einschließlich der für die Bestätigung der technischen Wiederherstellung zuständigen Personen
- Unterstützung durch Fachleute in allen betroffenen Bereichen, einschließlich der wichtigsten von der Plattform gehosteten Lösungen
- Betroffene nachgelagerte Systeme – operativer Support
- Betroffene vorgelagerte Systeme – operativer Support
- Kontaktinformationen für gemeinsam genutzte Unternehmensdienste Beispiel: Support für Zugriff/Authentifizierung, Sicherheitsüberwachung und Gatewaysupport
- Alle externen Anbieter oder Drittanbieter, darunter auch Supportkontakte für Cloudanbieter
- Architektur
- Beschreiben Sie das E2E-Szenario im Detail, und fügen Sie alle zugehörigen Unterlagen bei.
- Abhängigkeiten
- Listen Sie alle Beziehungen und Abhängigkeiten der Komponente auf.
- DR-Voraussetzungen
- Es wurde bestätigt, dass die vorgelagerten Quellsysteme wie erforderlich verfügbar sind.
- Den Ressourcen für die Ausführung der Notfallwiederherstellung wurde im gesamten Stapel erweiterter Zugriff gewährt.
- Azure-Dienste sind nach Bedarf verfügbar.
- Das zu befolgende Verfahren, wenn eine der Voraussetzungen nicht erfüllt ist.
- Technische Wiederherstellung – Schrittanweisungen
- Ausführungsreihenfolge
- Beschreibung des Schritts
- Voraussetzung für Schritt
- Detaillierte Verfahrensschritte für jede einzelne Aktion, einschließlich URLs
- Validierungsanweisungen, einschließlich der erforderlichen Nachweise
- Erwartete Zeit zur Durchführung für jeden Schritt, einschließlich Zeitreserve
- Das zu befolgende Verfahren, wenn der Schritt fehlschlägt
- Eskalationspunkte bei Ausfall oder Unterstützung durch Fachleute
- Erforderliche Aufgaben nach der technischen Wiederherstellung
- Bestätigen Sie für alle Schlüsselkomponenten des Systems, dass der Datumszeitstempel aktuell ist.
- Bestätigen Sie die URLs und IP-Adressen des DR-Systems.
- Bereiten Sie den Überprüfungsprozess durch die geschäftlichen Projektbeteiligten vor, einschließlich der Bestätigung des Systemzugriffs und der Validierung und Genehmigung durch die geschäftlichen Fachleute.
- Überprüfung und Genehmigung durch die geschäftlichen Projektbeteiligten
- Kontaktdaten der Geschäftsressourcen
- Schritte zur geschäftlichen Validierung gemäß der oben beschriebenen technischen Wiederherstellung
- Nachweispfad für den Geschäftsverantwortlichen, der die Wiederherstellung abzeichnet
- Erforderliche Aufgaben nach der Wiederherstellung
- Übergabe an den operativen Support, damit dieser die Datenprozesse ausführt, um das System auf den neuesten Stand zu bringen
- Übergabe der nachgelagerten Prozesse und Lösungen – Bestätigung des Datums und der Verbindungsdetails für das DR-System
- Bestätigung des Abschlusses des Wiederherstellungsprozesses mit der DR-Leitung – Bestätigung des Nachweispfads und des ausgeführten Runbooks
- Benachrichtigung an die Sicherheitsabteilung, dass dem DR-Team die erhöhten Zugriffsrechte entzogen werden können
Aufrufe
- Es wird empfohlen, Systemscreenshots für jeden Schritt beizufügen. Diese Screenshots tragen dazu bei, die Abhängigkeit von Systemfachleuten bei der Erfüllung der Aufgaben zu verringern
- Um die Risiken durch sich schnell weiterentwickelnde Clouddienste zu minimieren, sollte der DR-Plan regelmäßig überprüft, getestet und von Ressourcen mit aktuellen Kenntnissen über Azure und die zugehörigen Dienste ausgeführt werden.
- Die Schritte zur technischen Wiederherstellung sollten die Priorität der Komponente und der Lösung für die Organisation widerspiegeln. Beispielsweise werden wichtige Unternehmensdatenflüsse vor Ad-hoc-Labs zur Datenanalyse wiederhergestellt.
- Die Schritte für die technische Wiederherstellung sollten sich an der Reihenfolge der Arbeitsabläufe orientieren (in der Regel von links nach rechts), sobald die grundlegenden Komponenten/Dienste (wie z. B. Key Vault) wiederhergestellt wurden. Diese Strategie stellt sicher, dass vorgelagerte Abhängigkeiten verfügbar sind und die Komponenten entsprechend getestet werden können.
- Sobald der Plan mit den Einzelschritten fertiggestellt ist, sollte die Gesamtdauer der Aktivitäten unter Berücksichtigung einer Zeitreserve ermittelt werden. Wenn die Gesamtdauer über der vereinbarten Recovery Time Objective (RTO) liegt, gibt es mehrere Möglichkeiten:
- Automatisieren Sie ausgewählte Wiederherstellungsprozesse (sofern möglich).
- Suchen Sie nach Möglichkeiten, ausgewählte Wiederherstellungsschritte parallel auszuführen (sofern möglich). Beachten Sie jedoch, dass diese Strategie zusätzliche Ressourcen für die DR-Ausführung erforderlich machen kann.
- Verlagern Sie Schlüsselkomponenten auf höhere Dienstebenen (wie beispielsweise PaaS), in denen Microsoft mehr Verantwortung für die Wiederherstellung von Diensten übernimmt.
- Erweitern Sie die RTO in Absprache mit den Projektbeteiligten.
DR-Tests
Die Beschaffenheit des Azure Cloud-Dienstangebots führt zu Einschränkungen bei allen DR-Testszenarien. Daher wird empfohlen, für die Notfallwiederherstellung ein Abonnement mit den Komponenten der Datenplattform so einzurichten, wie sie in der sekundären Region verfügbar wären.
Ausgehend von dieser Baseline kann das Runbook für den DR-Plan selektiv ausgeführt werden, wobei ein besonderes Augenmerk auf die Dienste und Komponenten gelegt wird, die bereitgestellt und validiert werden können. Für diesen Prozess wird ein kuratiertes Testdataset benötigt, das die Bestätigung der technischen und geschäftlichen Validierungsprüfungen gemäß Plan ermöglicht.
Ein DR-Plan sollte regelmäßig getestet werden. So wird nicht nur sichergestellt, dass der Plan auf dem neuesten Stand ist, sondern auch, dass die zur Durchführung der Failover- und Wiederherstellungsaktivitäten verantwortlichen Teams sich die Verfahren einprägen können.
- Daten- und Konfigurationssicherungen sollten ebenfalls regelmäßig getestet werden, um sicherzustellen, dass sie für die Unterstützung von Wiederherstellungsaktivitäten geeignet sind.
Bei einem DR-Test müssen Sie vor allem gewährleisten, dass die festgelegten Schritte weiterhin korrekt sind und dass die veranschlagten Zeiträume eingehalten werden.
- Wenn die Anweisungen sich auf Anleitungen in Portalen und nicht direkt auf den Code beziehen, sollten sie angesichts der Häufigkeit von Änderungen in der Cloud mindestens alle 12 Monate validiert werden.
Auch wenn ein vollständig automatisierter DR-Prozess angestrebt wird, ist eine vollständige Automatisierung aufgrund der Seltenheit des Ereignisses eher unwahrscheinlich. Deshalb ist es empfehlenswert, mit DSC-IaC (Desired State Configuration Infrastructure-as-Code) die Basis für die Wiederherstellung der Plattform zu schaffen und diese dann zu erweitern, wenn neue Projekte auf dieser Basis erstellt und durchgeführt werden.
- Im Laufe der Zeit, wenn Komponenten und Dienste erweitert werden, sollte mithilfe der Erzwingung einer NFR die Pipeline für die Produktionsbereitstellung so umgestaltet werden, dass sie die Notfallwiederherstellung abdeckt.
Wenn die Zeitvorgaben im Runbook Ihre RTO überschreiten, gibt es mehrere Möglichkeiten:
- Erweitern Sie die RTO in Absprache mit den Projektbeteiligten.
- Verringern Sie den Zeitaufwand für die Wiederherstellungsaktivitäten durch Automatisierung, parallele Ausführung von Aufgaben oder eine Migration auf höhere Cloudserverebenen.
Azure Chaos Studio
Azure Chaos Studio ist ein verwalteter Dienst zur Verbesserung der Resilienz durch Einschleusung von Fehlern in Ihre Azure-Anwendungen. Mit Chaos Studio können Sie auf sichere und kontrollierte Weise Experimente zur Fehlereinschleusung bei Ihren Azure-Ressourcen durchführen. Eine Beschreibung der derzeit unterstützten Fehlertypen finden Sie in der Produktdokumentation.
Die aktuelle Iteration von Chaos Studio deckt nur eine Teilmenge von Azure-Komponenten und -Diensten ab. Bis weitere Fehlerbibliotheken hinzugefügt werden, empfiehlt sich Chaos Studio eher für isolierte Resilienztests als für DR-Tests des gesamten Systems.
Weitere Informationen zu Chaos Studio finden Sie hier.
Azure Site Recovery
Bei IaaS-Komponenten schützt Azure Site Recovery die meisten Workloads, die auf einer unterstützten VM oder einem physischen Server ausgeführt werden.
Es stehen dringende Empfehlungen für folgende Themen zur Verfügung:
- Ausführen eines Notfallwiederherstellungsverfahrens für virtuelle Azure-Computer
- Ausführen eines Failovers in eine sekundäre Region für Azure-VMs
- Ausführen des Failbacks einer Azure-VM in die primäre Region
- Ermöglichen der Automatisierung eines DR-Plans
Zugehörige Ressourcen
- Entwickeln einer Architektur zur Erzielung von Resilienz und Verfügbarkeit
- Business Continuity & Disaster Recovery
- Sicherung und Notfallwiederherstellung von Azure-Anwendungen
- Resilienz in Azure
- Übersicht über Vereinbarungen zum Servicelevel (SLAs)
- Fünf bewährte Methoden zum Antizipieren von Fehlern
Nächste Schritte
Nachdem Sie nun wissen, wie Sie das Szenario bereitstellen, können Sie mit der Zusammenfassung der Reihe zur Notfallwiederherstellung (DR) für eine Azure-Datenplattform fortfahren.